
卷积神经网络CNN(二)
CNN基础知识储备:
(一)卷积计算
通过这部分的学习,将会清楚卷积是如何计算的。
举个例子,现有一张6×6的灰度图像(灰度图像代表6×6×1的矩阵,RGB图片则是6×6×3,因为它有红绿蓝3个维度),比如
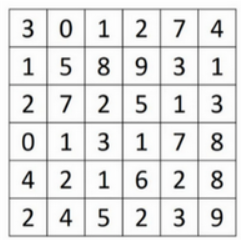
为了检测图像中的垂直边缘,可以构造一个3×3矩阵。在卷积神经网络的术语中,它被称为过滤器,又叫核,比如
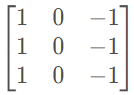
对这个6×6的图像进行卷积运算,卷积运算用 * 来表示,用3×3的过滤器对其进行卷积。这个卷积运算的输出将会是一个4×4的矩阵,可以将它看成一个4×4的图像。
具体的运算流程为:
为了计算第一个元素,使用3×3的过滤器,将其覆盖在输入图像,如下图所示:
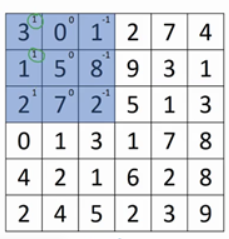
然后进行元素乘法(element-wise products)运算:
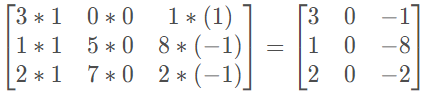
最后将该矩阵每个元素相加得到最左上角的元素,即 3 + 1 + 2 + 0 + 0 + 0 + ( − 1 ) + ( − 8 ) + ( − 2 ) = − 5 。
接下来计算第二个元素,将3×3过滤器向右移动一步,再对输入图像进行覆盖,如图:
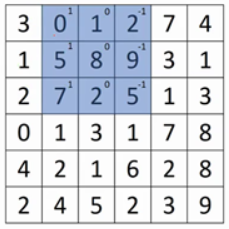
以此类推,最终可得到最后的4×4矩阵,将其中与代码部分(参见我的另一篇博客:卷积神经网络CNN(一) - Tzy0425 - 博客园 (cnblogs.com))进行对应:
in_channels表示输入图像的高度,灰度为1,RGB为3;
out_channels表示输入图像在经过过滤器的卷积运算后,可得到多少个特征,本例中计算后得到4×4矩阵,即16个特征;
kernel_size表示过滤层的大小,本例中过滤层是3×3的矩阵,所以该值为3;
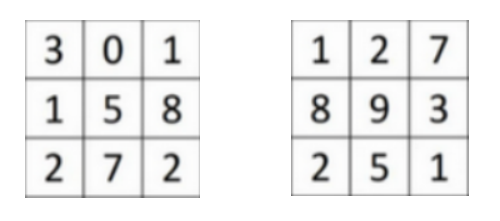
stride表示过滤层移动的步长,本例中为1,就是过滤层覆盖了第一个部分后,只需要移动一步就可以开始覆盖第二部分。若为2,那么本例中前两个覆盖的部分分别为:
padding下一部分具体说明。
(二)Padding
在上个例子中,会发现卷积运算有三个问题,一是边缘部分的数据没有被充分利用,比如输入图像的第一个数据3,只被过滤器在第一步覆盖,之后就再没访问过,而中间部分的数据则被反复访问,造成了数据资源的利用不完善;二是在过滤器向右或向下移动时,如果出现所剩区域小于过滤器的大小,那么过滤器此时就无法覆盖区域,比如上个例子中,移动步长若为2,再覆盖掉[1,8,2;2,9,5;7,3,1]之后,移动到下一区域,此时所剩区域是3×2的矩阵,对于3×3的过滤器就无法覆盖;三是在一步一步的卷积运算后,输入图像会慢慢变小,这就导致特征越来越丢失掉,造成浪费。
为了解决这一问题,可以事先在输入图像的边缘填充若干层像素,每个像素点的值均为0,若p = 2,则输入图像变为: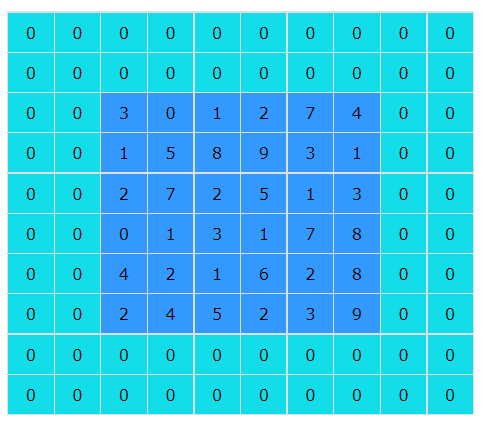
这样一来,所有的缺点都被解决,输出矩阵的维数变为(n为输入图像的维度,p为padding值,f为过滤器的维度,s为步长):
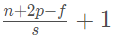
(三)池化层(Pooling Layers)
卷积网络经常使用池化层来缩减模型的大小,提高计算速度,同时提高所提取特征的健壮性。
最大池化(max pooling)
和上面的例子相似,在过滤器进行每一步覆盖时,不需要进行元素乘法然后相加,只需要选取覆盖区域的最大值作为这部分的输出值。对上述例子中的矩阵进行最大池化,得到的结果为:
| 8 | 9 | 9 | 9 |
| 8 | 9 | 9 | 9 |
| 7 | 7 | 7 | 8 |
| 5 | 6 | 7 | 9 |
当然,设置不同的步长会得到不同的结果。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号