
DQN
DQN简介
DQN,全称Deep Q Network,是一种融合了神经网络和Q-learning的方法。这种新型结构突破了传统强化学习的瓶颈,下面具体介绍:
神经网络的作用
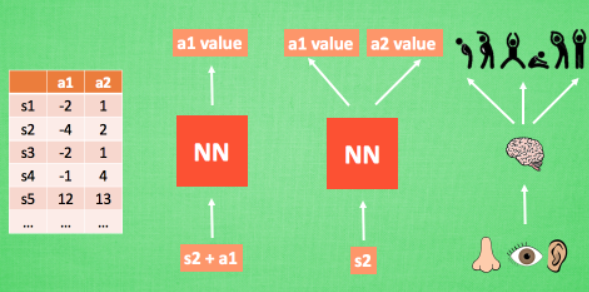
传统强化学习使用表格形式来存储每一个状态state和状态对应的action的Q值,例如下表表示状态s1对应了两种动作action,每种action对应的Q值为-2和1。
| a1 | a2 | |
| s1 |
-2 |
1 |
| s2 | 2 | 3 |
| ... | ... | ... |
但当我们有很多数据时,首先,内存不够是第一个问题;其次,搜索某个状态对应的动作也相当不便,这时就想到了引入神经网络。
我们可以把状态和动作当作神经网络的输入,然后经过神经元的分析得到每个动作对应的Q值,这样我们就没有必要用表格记录Q值;或者我们也可以只输入状态,输出所有的动作,然后根据Q-learning的原则,直接选择具有最大Q值的动作作为下一步要做的动作。就好比相当于眼睛鼻子耳朵收集信息, 然后通过大脑加工输出每种动作的值, 最后通过强化学习的方式选择动作。
更新神经网络
神经网络需要被训练才能预测出正确的值。如何更新呢?
假设已存在Q表,当前状态s1有两个对应的action,分别是a1和a2,根据Q表,选择最大价值的a2,此时进入到状态s2,而 s2也有两个对应的action,分别是a1和a2,选择最大价值的动作,乘以衰减率gamma,加上奖励reward,此时得到的值便是Q(s1,a2)的现实值,而Q(s1,a2)的估计值直接由Q表给出,此时便有了Q现实与Q估计的差距,然后该差距乘以学习率,再加之前的参数,便得到了最新神经网络的参数。
DQN两大特点
DQN 有一个记忆库用于存储学习之前的经历。Q learning 是一种 off-policy 离线学习法,它能学习当前经历着的, 也能学习过去经历过的, 甚至是学习别人的经历。所以每次 DQN 更新的时候, 我们都可以随机抽取一些之前的经历进行学习。 随机抽取这种做法打乱了经历之间的相关性, 也使得神经网络更新更有效率。而 Fixed Q-targets 也是一种打乱相关性的机理, 如果使用 fixed Q-targets, 我们就会在 DQN 中使用到两个结构相同但参数不同的神经网络,代码中用target_net、eval_net表示这两种不同的神经网络。
DQN代码实现
在设计该算法之前,需要设定很多超参数的值(以训练小车立杆子为例):
BATCH_SIZE = 32 # 每个批量的大小 LR = 0.01 # 学习率 EPSILON = 0.9 # 最优选择动作百分比 greedy policy GAMMA = 0.9 # 奖励衰减率 TARGET_REPLACE_ITER = 100 # Q 现实网络(target)的更新频率 MEMORY_CAPACITY = 2000 # 记忆库的大小 env = gym.make('CartPole-v0') # 立杆子游戏 env = env.unwrapped N_ACTIONS = env.action_space.n # 杆子会做的动作 N_STATES = env.observation_space.shape[0] # 杆子能获得的环境信息数
对神经网络进行初始化,定义可以输出所有动作的Q值的函数:
class Net(nn.Module): def __init__(self, ): super(Net, self).__init__() self.fc1 = nn.Linear(N_STATES, 50) # 输入状态,对应着50个输出 self.fc1.weight.data.normal_(0, 0.1) # 通过正态分布随机生成参数值 self.out = nn.Linear(50, N_ACTIONS) # 输入fc1层的输出,对应着多个动作 self.out.weight.data.normal_(0, 0.1) def forward(self, x): x = self.fc1(x) x = F.relu(x) actions_value = self.out(x) # 有可用的两种Action,输出每个动作对应的价值,之后会根据价值选取动作 return actions_value
上面介绍过,DQN的特点是,会使用到两个结构相同但参数不同的神经网络,下面是构建这两个神经网络的过程:
# DQN框架:与环境互动的过程,有两个Net,包含选择动作机制、存储经历机制、学习机制 class DQN(object): def __init__(self): # 建立target_net、eval_net、memory self.eval_net, self.target_net = Net(), Net() # 两个一样的Net,但参数不一样,要经常把eval_net的参数转换到target_net中,以达到延迟的更新效果 self.learn_step_counter = 0 # 学习了多少步 self.memory_counter = 0 # 记忆库中的位置 self.memory = np.zeros((MEMORY_CAPACITY, N_STATES * 2 + 2)) # 初始化记忆库, self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=LR) self.loss_func = nn.MSELoss()
该框架中应有三个函数,分别实现根据观测值选择动作、存储到记忆库中、从记忆库提取记忆然后进行强化学习
# 根据观测值选择动作机制 def choose_action(self, x): # 根据观测值x选择动作 x = torch.unsqueeze(torch.FloatTensor(x), 0) # 存在随机选取动作的概率,当该概率<EPSILON时,执行greedy行为 # forward()最后输出所有action的价值,选取高价值的动作;这里就是90%的情况下,选取高价值动作 if np.random.uniform() < EPSILON: # greedy actions_value = self.eval_net.forward(x) # 输出actions_value action = torch.max(actions_value, 1)[1].data.numpy() # 选取最大价值 action = action[0] if ENV_A_SHAPE == 0 else action.reshape(ENV_A_SHAPE) # return the argmax index # 反之随机选取一个动作即可 else: action = np.random.randint(0, N_ACTIONS) action = action if ENV_A_SHAPE == 0 else action.reshape(ENV_A_SHAPE) # 返回最后选取的动作 return action
# 选取完Action之后,存储到记忆库中 def store_transition(self, s, a, r, s_): #记忆库存储的内容为四元组:状态、动作、奖励、下一个状态 # 存储记忆 transition = np.hstack((s, [a, r], s_)) # 如果memory_counter已经超过记忆库容量MEMORY_CAPACITY,那么重新开始索引,用新记忆代替旧记忆 index = self.memory_counter % MEMORY_CAPACITY self.memory[index, :] = transition self.memory_counter += 1
# 学习机制:从记忆库中提取记忆然后用RL的方法进行学习 def learn(self): # 检测是否需要进行 target 网络更新 # 检测标准:Q现实网络要隔多少步进行一次更新,如果达到那个步数就进行更新 if self.learn_step_counter % TARGET_REPLACE_ITER == 0: # eval_net的参数全部复制到target_net中,实现更新 # target_net是时不时更新,而eval_net是每一步都要更新 self.target_net.load_state_dict(self.eval_net.state_dict()) self.learn_step_counter += 1 # 实现eval_net的每一步更新,从记忆库中随机抽取BATCH_SIZE个记忆,然后打包 sample_index = np.random.choice(MEMORY_CAPACITY, BATCH_SIZE) b_memory = self.memory[sample_index, :] # 按照存储时的格式进行打包,然后就可以放入神经网络中进行学习 b_s = torch.FloatTensor(b_memory[:, :N_STATES]) b_a = torch.LongTensor(b_memory[:, N_STATES:N_STATES+1].astype(int)) b_r = torch.FloatTensor(b_memory[:, N_STATES+1:N_STATES+2]) b_s_ = torch.FloatTensor(b_memory[:, -N_STATES:]) # 学习过程:输入现在的状态b_s,通过forward()生成所有动作的价值,根据价值选取动作,把它的价值赋值给q_eval q_eval = self.eval_net(b_s).gather(1, b_a) # 把target网络中下一步的状态对应的价值赋值给q_next;此处有时会反向传播更新target,但此处不需更新,故加.detach() q_next = self.target_net(b_s_).detach() # 选取下一步动作的最大值,乘衰减率GAMMA,然后加奖励b_r;max函数返回索引加最大值,索引是1最大值是0 q_target = b_r + GAMMA * q_next.max(1)[0].view(BATCH_SIZE, 1) # 。view(BATCH_SIZE, 1)表示最大项会放在batch的第一位 # 通过预测值与真实值计算损失 loss = self.loss_func(q_eval, q_target) # 反向传递误差,进行参数更新 self.optimizer.zero_grad() loss.backward() self.optimizer.step() # 学习过程总结:首先检验是否需要将target_net更新为eval_net,然后进行批训练,就是从记忆库中提取一批记忆, # 最后计算出q_eval、q_next等以及误差后,通过误差反向传递进行学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号