
批训练
每次进行数据训练时,如果数据集过多不适合把整个数据打包进行训练,那么这种时候就需要把训练数据分批进行训练。
设置数据:
x = torch.linspace(1, 10, 10) # x data (torch tensor) y = torch.linspace(10, 1, 10) # y data (torch tensor)
DataLoader是torch中用来包装数据的工具,而torch又只能识别tensor,所以先把数据形式转换为tensor,然后用DataLoader包装。
#转换为tensor形式的数据集Dataset torch_dataset = Data.TensorDataset(x, y) #把DataLoader放入DataLoader loader = Data.DataLoader( dataset = torch_dataset, #数据集的形式 batch_size = 5, #批量大小为5 shuffle = True, #每次取数据都要先打乱顺序 num_workers = 2 #一共10个数据,每个批量有5个,所以2个线程来读数据就足够了 ) for epoch in range(3): #训练3次,每次训练一整套数据 for step, (batch_x, batch_y) in enumerate(loader): #enumerate作用是给每个step设置索引 #假设此处进行训练... #打印训练后的数据 print('Epoch: ', epoch, '| Step: ', step, '| batch x: ', batch_x.numpy(), '| batch y: ', batch_y.numpy())
运行结果如下:

上面的例子批量大小为5,正好可以被总的训练数整除;如果批量大小不能被总的数据量进行整除呢?
假设batch_size = 8:
运行结果如下:
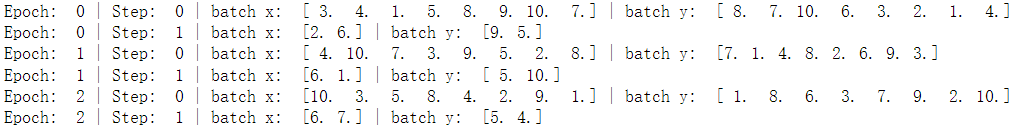
可见,如果不能被整除,那么在第一批数据训练后,剩下的数据量自动作为下一批训练即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号