论文阅读笔记《Sim-to-real learning for bipedal locomotion under unsensed dynamic loads》
Sim-to-real learning for bipedal locomotion under unsensed dynamic loads
介绍
发表于ICRA 2022
无感知动态负载下双足运动的虚实迁移学习
Dao J, Green K, Duan H, et al. Sim-to-real learning for bipedal locomotion under unsensed dynamic loads[C]//2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022: 10449-10455.
背景
机器人携带负载时的运动控制问题还没有得到充分的研究,尤其是动态负载。
在这项工作中,我们特别感兴趣的是动态载荷,比如一个附加的推车或液体容器,而不是简单的静态载荷,比如刚性附着的固定质量。
研究现状
结合动态负载的一种策略是使用先前经过训练的控制器,以简单的步态非常缓慢地行走,以避免干扰负载并影响整体动态。
本文贡献
我们的目标是实现在带负载的情况下与这些先前的控制器相似的动态行走性能水平。为此,我们研究了RL方法来学习许多性质不同的动态负载的运动策略,除了本体感知之外没有额外的负载感知。
学习策略
无负载策略的训练
通过PPO算法对网络进行模拟训练。仿真环境基于cassie-mujoco-sim库和MuJoCo物理引擎。我们在训练中使用动力学随机化,其中我们随机化关节阻尼、关节质量和地面摩擦。
有负载策略的训练
与以上保持一致,唯一的不同是奖励函数增加一个与负载属性相关的项,例如惩罚溢出液体。
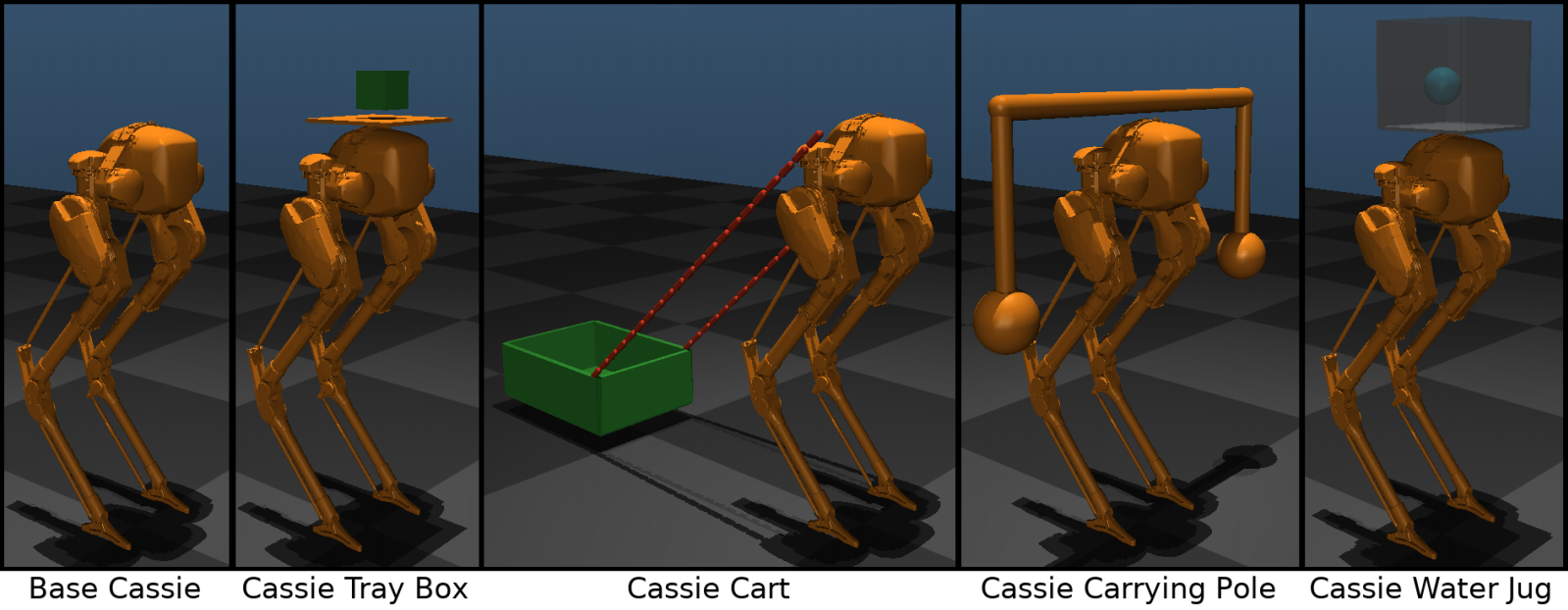
该文测试了5个性质不同的负载Cassie机器人模型。
-
无负载Cassie模型,常规Cassie模型,没有附加负载,基本行走策略是从它训练的。
-
Cassie托盘盒,由一个自由移动的5公斤的盒子在托盘上连接到骨盆顶部组成。策略必须学会处理一个自由的外部物体,这样它就不会掉下来,就像服务员端着一个杯子一样。
-
Cassie车,由一辆车组成,车上用绳子系在卡西的骨盆上,沿着地面拖动。这个载荷是用来测试向后拉力的。
-
Cassie负重杆,由一个固定在骨盆上的负重杆组成,两端悬挂5公斤重物。由于重物可以向各个方向自由摆动,这种困难的负载很容易引起横向和扭转力,从而引起不稳定的循环并破坏运动。
-
Cassie水壶,由一个固定在盆骨上的盒子组成,里面有水。为了模拟液体动力学而不必进行流体模拟,我们在每个轴上的弹簧上施加一个重量来近似晃动动力学。
最后,我们尝试了三种策略训练方式。
- 我们考虑从随机神经网络开始从头训练特定于负载的策略。
- 我们考虑通过从基本策略引导来训练特定于负载的策略,它被初始化为没有负载的情况下训练的高性能策略的学习,然后针对特定应用进行微调。
- 我们考虑训练一个通用负载策略,该策略在所有负载模型上都是平等的。这意味着对于每个训练迭代,采样的50000个时间步骤在5个模型之间平均分配,确保策略从每个负载中看到等量的经验。
实验
模拟器实验
我们考虑以下指标来评估在动态载荷下的行走性能。
通过率。我们随机抽取5000个命令集,其中包括2个随机速度命令和2个随机方向命令,并测量它能成功执行多少个命令集。每2.5秒执行一次新命令。速度命令是随机选择在0.5和2.0米/秒之间高于或低于之前的命令(在0到4米/秒的命令限制内)和方向变化命令是相似的30◦到60◦左或右。如果机器人在任何一个点摔倒,就被认为是一次试验失败。
平均速度误差。对于机器人没有摔倒的命令集情况,我们还跟踪机器人在轨迹上的期望速度和实际速度的平均差值。当通过率低于50%时,我们不报告这项措施。
平均的力量。为了评估推送扰动的鲁棒性,我们在每个方向上执行直线搜索,以找到策略能够抵抗的最大力。该策略有3.0秒的时间从施加在机器人骨盆上的0.2秒脉冲中恢复过来。如果机器人在3秒后没有摔倒,则认为它成功了。我们测试每10◦从50 N开始,增加10 N,直到力量太大,摔倒。然后,我们对每个方向求平均值,得到一个数字,让我们知道该策略可以抵抗多大的力量。
最大速度。我们测试策略在不摔倒的情况下能够行走的最大速度是多少。
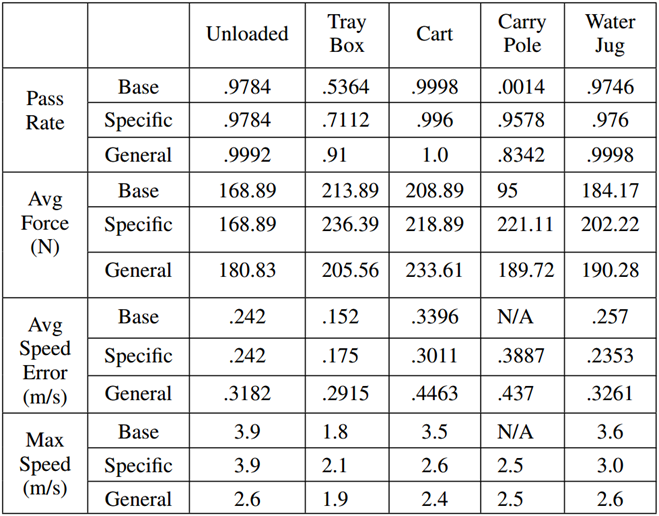
专用策略和基础策略相比,只有最大速度指标略低,其余指标均高于基础策略。不过也正常,策略的首要任务是保证重物不掉下来,而不是走得快。让一个策略可以走得像没有负载的时候一样快是不合理的。
专用策略和通用策略相比,在大多数情况下,两者之间的性能是相当的。在通过率指标上,只有Carry Pole环境的性能比专用策略低,其余环境中都比专用策略更高。这表明,由于需要处理各种动态条件,通用策略获得了更强的健壮性。
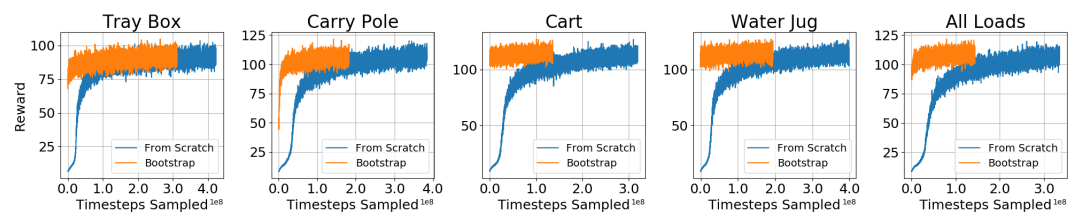
该文还研究了从一个基本的无负载行走策略开始学习(Bootstrap),与从头开始学习(Scratch)每个特定的负载策略相比的训练效果。
虚实迁移实验
启动机器人后持续增加机器人的速度,直到机器人跌倒或策略不能使机器人走得更快来进行硬件测试。在我们的测试中,能够在一分钟内不摔倒地行走被认为是成功的策略。
所有负载策略在硬件上达到的最高速度都比在模拟中低得多。
在更困难的Carry Pole负载上,From Scratch的一般负载失败了,而Bootstrap的能够成功地负载行走。这可能是因为From Scratch的策略在训练期间看到了所有额外的噪音,额外噪声可能会降低其迁移能力。
总结
本文的贡献
- 在这项工作中,我们已经证明了训练能够在人类规模的双足机器人移动时处理动态负载的策略是可能的。我们发现不需要额外的传感,并且学习正常运动策略所需的唯一修改是在所需负载的背景下进行训练。
- 我们还表明,可以学习一个单一的通用负载策略,它可以处理许多不同的动态负载,同时保持在单个特定负载上训练的专门策略的行走性能。
- 此外,我们发现,与从头训练的策略相比,我们可以从先前训练的卸载行走策略引导快速学习加载行走策略,而不会损失性能。
- 我们成功地演示了负载策略的模拟到真实转移,在机器人两侧各携带两个5公斤的摇摆重物时,实现了0.8米/秒的速度。
对研究方向的启发
提出了一个有趣的虚实迁移问题,增加动态载荷极大地扩大了模拟与真实的差距。此状态下的稳健虚实迁移需要更好的方法。

