
强化学习,策略梯度,REINFORCE,最经典样例

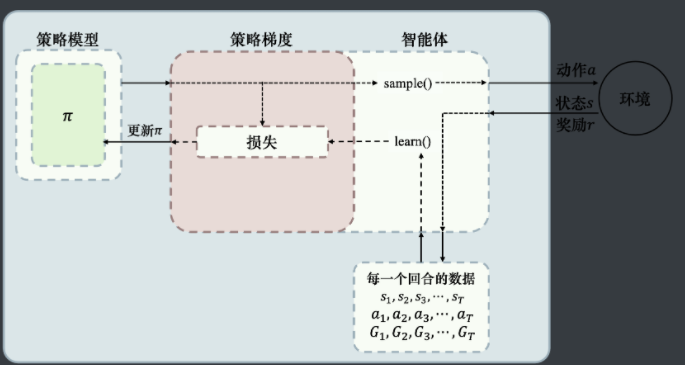
改进
Gt = Gt - mean(Gt)
代码
model.py
import torch
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = nn.Linear(4, 128)
self.linear2 = nn.Linear(128, 2)
def forward(self, x):
out = self.linear1(x)
out = F.relu(out)
out = self.linear2(out)
out = F.softmax(out, dim=-1)
return out
agent.py
import numpy as np
import torch
from DRL.策略梯度.REINFORCE.model import Model
class Agent:
def __init__(self):
self.model = Model()
self.gamma = 0.9
self.lr = 0.01
self.p_list = []
self.r_list = []
def pay_one_times(self, env):
# 玩一次积累经验:p、r
p_list = []
r_list = []
done = False
state = env.reset()
while not done:
x = torch.Tensor(state)
x = torch.unsqueeze(x, 0)
p = self.model(x)
action = torch.multinomial(p, 1).item()
p = p[0][action].unsqueeze(0)
state, r, done, _ = env.step(action)
p_list.append(p)
r_list.append(r)
self.p_list = p_list
self.r_list = r_list
return sum(r_list)
def learn(self):
# 在pay_one_times之后调用;使用经验学习
# 计算G_t
gt_list = np.zeros_like(self.r_list)
gt_len = len(gt_list)
gt_list[gt_len - 1] = self.r_list[gt_len - 1]
for i in reversed(range(gt_len - 1)):
gt_list[i] = self.r_list[i] + self.gamma * gt_list[i + 1]
gt_list = torch.from_numpy(gt_list)
gt_list = gt_list - torch.mean(gt_list)
# 损失函数就是 gamma^t * G_t * logP
gamma_t = torch.pow(self.gamma, torch.arange(len(gt_list)))
p_list = torch.cat(self.p_list)
logp_list = torch.log(p_list)
# loss = -torch.sum(gamma_t * logp_list * gt_list)
loss = -torch.sum(logp_list * gt_list)
# 优化
opt = torch.optim.Adam(self.model.parameters(), self.lr)
opt.zero_grad()
loss.backward()
opt.step()
opt.zero_grad()
# 清除上次经验
self.p_list.clear()
self.r_list.clear()
main.py
import gym
import matplotlib.pyplot as plt
from DRL.策略梯度.REINFORCE.agent import Agent
env = gym.make("CartPole-v1")
agent = Agent()
T = 500 # 优化多少次
x, y = [], []
smooth_y = []
for t in range(T):
r = agent.pay_one_times(env)
print("{:5d} :{}".format(t, r))
agent.learn()
x.append(t)
y.append(r)
if len(smooth_y) == 0:
smooth_y.append(r)
else:
smooth_y.append(0.8 * smooth_y[-1] + 0.2 * r)
plt.plot(x, y)
plt.plot(x, smooth_y)
plt.show()
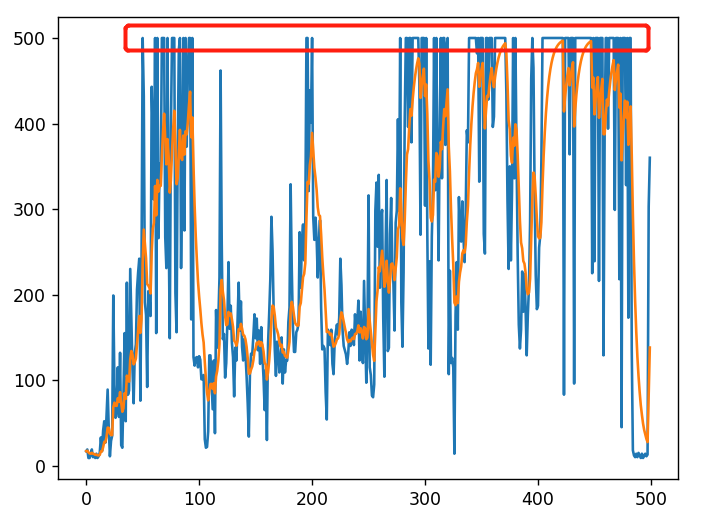
结果
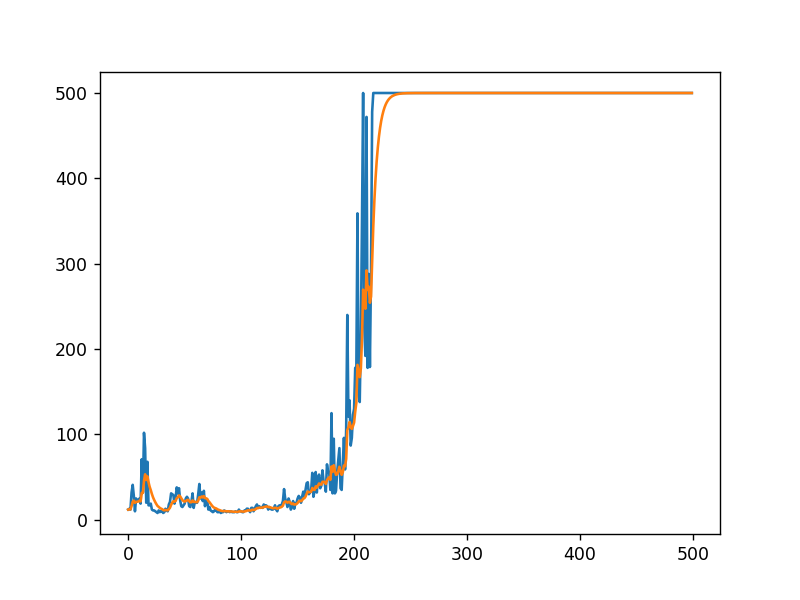
增加一行代码后效果
if r < 500:
agent.learn()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号