
强化学习,直接策略搜索,策略梯度,入门样例
策略梯度,入门样例
原文链接:
https://www.cnblogs.com/Twobox/
参考链接:
https://datawhalechina.github.io/easy-rl/#/chapter4/chapter4
https://zhuanlan.zhihu.com/p/358700228
策略网路结构
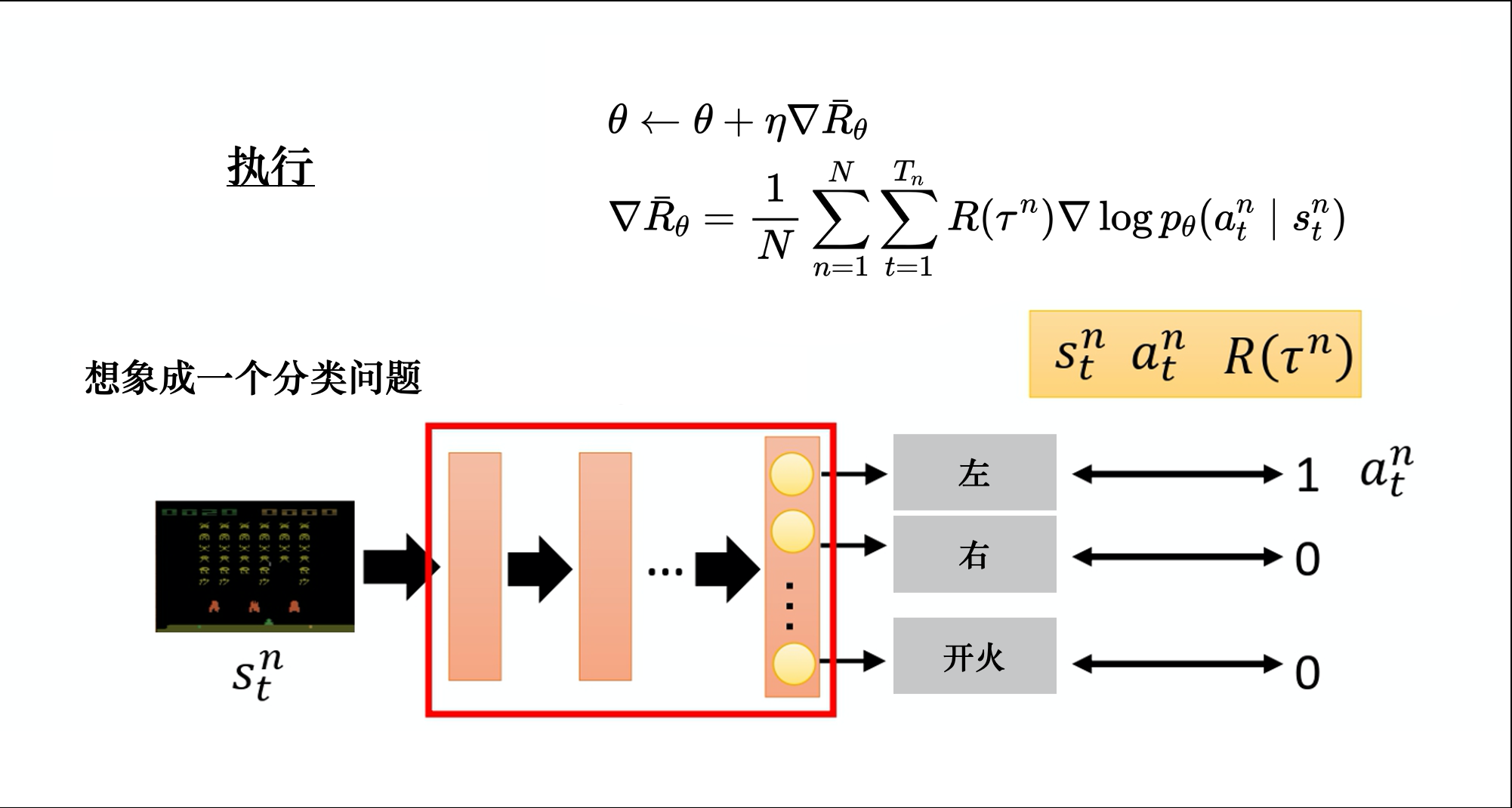
算法流程与策略梯度

添加一个基线
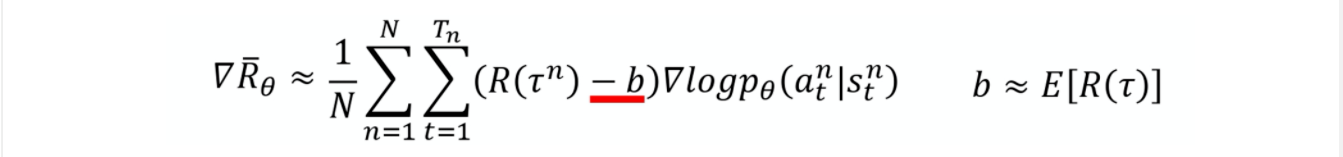
调整更合适的分数
代码结构
需要的包
import numpy as np
import gym
import matplotlib.pyplot as plt
import torch # torch.optim.SGD 内置优化器
import torch.nn as nn # 模型库
import torch.nn.functional as F # 内置loss函数
from torch.utils.data import TensorDataset # 包装
from torch.utils.data import DataLoader # 迭代器
model.py
def loss_fun(p, advantage, N):
# p就是p(a|s) advantage 就是权重优势
# p Tensor格式 advantage为数字数组1
advantage = torch.Tensor(advantage)
# 目标函数 1/N sum(sum(a' * log p'))
loss = -torch.sum(torch.log(p) * advantage) / N
return loss
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = nn.Linear(4, 128)
self.linear2 = nn.Linear(128, 2)
# self.linear3 = nn.Linear(20, 2)
def forward(self, x):
# xb = xb.view(xb.size(0), -1)
out = self.linear1(x)
out = F.relu(out)
out = self.linear2(out)
out = F.softmax(out, dim=-1)
return out
def fit(self, p, advantage, N):
opt = torch.optim.Adam(self.parameters(), 0.005)
loss = loss_fun(p, advantage, N)
opt.zero_grad()
loss.backward()
opt.step()
opt.zero_grad()
agent.py
class Agent:
def __init__(self, gamma):
self.model = Model()
# 目标函数 1/N sum(sum(a' * log p'))
self.p = []
self.advantage = []
self.N = 0
self.gamma = gamma
def get_action_p(self, state):
# 转化为Tensor , 此时为一维
state = torch.FloatTensor(state)
# 转化为二维,最外面加个[]
state = torch.unsqueeze(state, 0)
p = self.model(state)
return p # tensor
def clear(self):
self.advantage.clear()
self.p.clear()
self.N = 0
def pay_n_times(self, N, env):
# 玩N次,追加存储N次经验
self.N += N
r_sum = 0 # 所有奖励
advantage = []
for n in range(N):
state = env.reset()
r_list = [] # 一个回合 每个动作的奖励
done = False
while not done:
p = self.get_action_p(state)
# 按概率采样下表;在dim为1的位置进行采样;这里的结果为[[0 or 1]]
action = torch.multinomial(p, 1).item() # 这时候直接是数字
s_, r, done, _ = env.step(action)
state = s_
r_list.append(r)
# 后续需要对self.p使用torch.cat方法
self.p.append(p[0][action].unsqueeze(0))
r_sum += sum(r_list)
# sum(gamma^i * r)
ad_list = []
ad_temp = 0
for i in reversed(range(len(r_list))):
ad_temp = ad_temp * self.gamma + r_list[i]
ad_list.append(ad_temp)
ad_list.reverse()
advantage += ad_list
b = r_sum / N
advantage = [a - b for a in advantage]
self.advantage += advantage
# 返回平均分数
return b
def learn(self):
p = torch.cat(self.p)
advantage = torch.FloatTensor(self.advantage)
self.model.fit(p, advantage, self.N)
main.py
env = gym.make("CartPole-v1")
agent = Agent(0.95)
T = 1000 # 更新多少次梯度
N = 50 # 每次跟新需要采样多少回合的经验
x, y = [], []
for t in range(T):
avg_r = agent.pay_n_times(N, env)
x.append(t)
y.append(avg_r)
print("{} : {}".format(t, avg_r))
agent.learn()
agent.clear()
plt.plot(x,y)
plt.pause(0.1)
plt.plot(x,y)
plt.show()
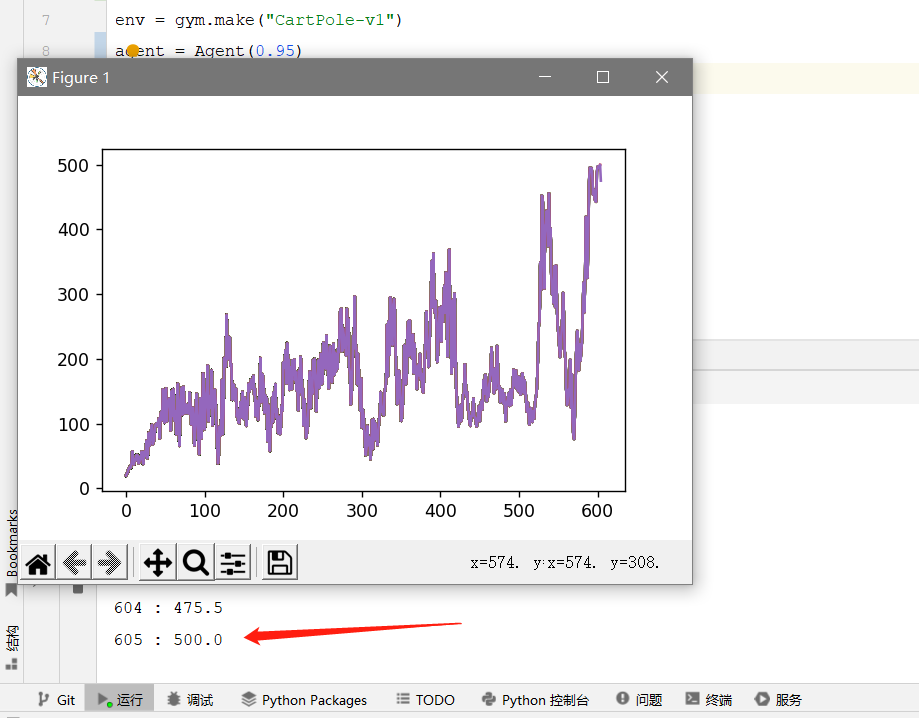
结果
本文原创作者:魏雄
原文链接:
https://www.cnblogs.com/Twobox/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号