


sql修炼笔记——入门篇2
稍探sql用法
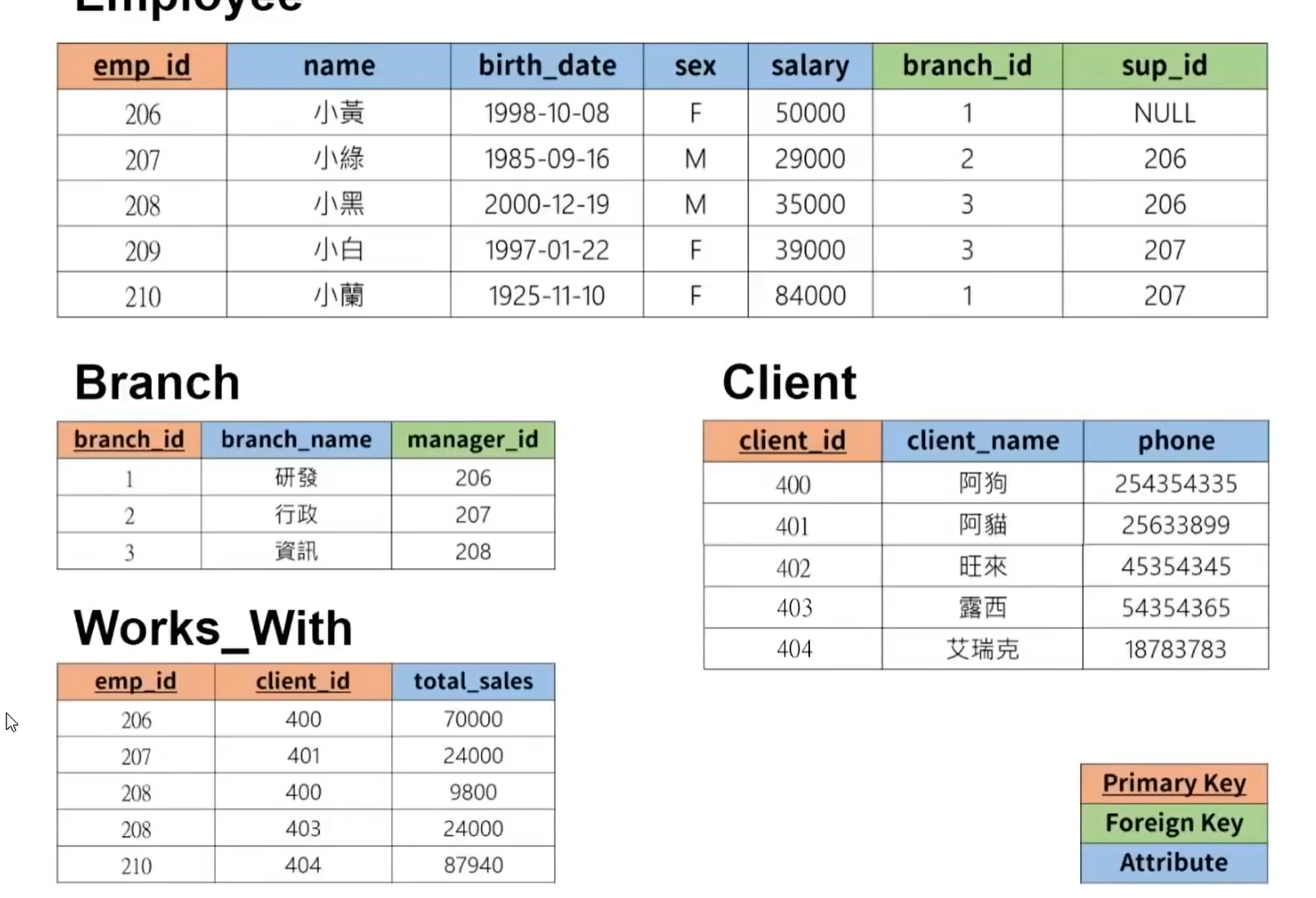 实验目标所要建立的表格
实验目标所要建立的表格
题外话 mysql中的注释语句使用的是-- 比如 --创建资料库 即注释
1.创建公司资料库 本段主要涉及数据库内多个表格的相互联系与应用
三个列表的列定义 primary key, foreign key, attribute
primary key 的设定直接在column的定义后加上primary key 即可 或者用 primary key (“column”)
foreign key 的设定 foreign key("manager_id") references "employee"(列表名)("emp_id") on delete set null
另一种写法 alter table "employee" add foreign key ("branch_id") references "branch"("branch_id") on delete set null;
一个column可以同时是primary key 和foreign key
只需 primary key(“column”) 然后再 foreign key("manager_id") references "employee"("emp_id") on delete cascade
由于foreignkey的定义是来源于其他的列表数据,所以在其他列表数据尚未定义时要先设置为null 然后才能比较方便的进行定义
2.公司资料库的操作
取得所有员工资料 : select * from employee;
取得所有客户资料:select * from client;
按照薪水高低取得员工资料: select * from employee order by salary asc;
取得薪水前三高的员工:select * from employee order by salary desc limit 3;
取得所有员工的名字: select (distinct 取消重复数据) 'name' from employee ;
3.aggregate functions 聚合函数
其实就是count()函数和avg()函数这些。例子如下
取得员工人数:SELECT COUNT(*) FROM `employee`; -- 列计数 一列有多少行 使用count(·column·)时取得的是该列中非null的行数
取得所有1970-01-01之后的女性员工人数:select count(*) from employee where birth-data > '1970-01-01' and sex = "F";
取得所有员工的平均薪水:select avg(`salary`) from employee;
取得所有员工的总薪水:select sum(`salary`) from employee;
薪水最高的员工:select max(`salary`) from employee;
4.万用字元 wildcards
%代表多个字元 _代表一个字元
取得电话号码尾号是335的客户:select * from `cilent` like "%335"; --类似的 355%就是以355开头的字符串 %354%就是只要包含354即可
取得姓艾的客户:select * from client like "艾%";
取得生日在12月的员工:select * from client where `birth_data` like "_____12%"; 五个_代表1990-
5.连集union
员工名字连集客户名字: select `name` from employee union select `name` from client; --这里的话就是将两个表格搜寻的结果依次链接,合并到结果表格中
注意合并的两个或者是多个搜索结果的列数必须是相同的 都是一列或者都是多列 同时同一列的数据类型也要是相同的 都是int 或者都是varchar
员工id 员工名字 union 客户id 客户名字:select emp_id, name from employee union select client_id, name from client; 返回的列表的列名使用的是第一个union的列名 也就是 emp_id 和name
可以对列名进行修改 使用as函数 emp_id as total_id
员工薪水union销售金额:select salary as total_money from employee union select total_sales from work_with
6.连接 join
取得所有部门经理的名字:select * from employee join branch on emp_id = manager_id ; 筛选出符合条件的部分资料进行行链接 是横向的链接 此时使用的是* 所以是所有数据进行的连接
可以使用select选出所需要的数据 对列名相同的数据进行筛选判断时可以使用employee.emp_id = branch.manage_id; select中的选择同理 employee.emp_id,branch.branch_name
join使用时可以用 left join 此时无论条件是否成立 左边表格的资料都会回传 右边表格则会传回null
from employee left join branch 在join的左边就是左边表格 右边就是右边表格
同理还有right join
7.子查询 subquery
子查询就是一层查询嵌套另一层 用法可以是查询使用的判断条件是使用查询来得到的,如
找出研发部门的经理名字:select name from employee where emp_id = ( select manager_id from branch where branch_name = "研发" );
找出对单一客户的销售金额超过50000的员工id:select name from employee where emp_id in ( select emp_id from employee where 'total_sales' > 50000 );
8.on delete
此前的用法 foreign key ('manager_id') references 'employee'('emp_id') on delete set null 意思就是当指向的empid删除时设置为null而非空
foreign key ('emp_id') references 'employee'('emp_id') on delete cascade 对应不到时同时一起删除 此处使用cascade的原因是该表格中的empid同时是主键和foreignkey 主键不可为空
9.python连接mysql
入门篇的最后一部 到此已经对于mysql有了初步的认知与掌握 接下来便没有了固定的路程 天高任鸟飞,海阔凭鱼跃 共勉吧
import mysql.connector
connection = mysql.connector.connect(host = "local", port = "3306", user = "root", password = "373750073")
cursor = connection.cursor
执行语句:cursor.excute("show databases;")
records = cursor.fetchall()获得所有回传资料
cursor.close()
connection.commit()
connection.close()
BYE!
