神经网络中的常用表示方式
标量(OD 张量)
数字组成的数组叫作向量(vector)或一维张量(1 D 张量)。一维张量只有一个轴。下面是一个 Numpy 向量。
(tensorflowcv) turing@localhost ~ % python
Python 3.7.5 (v3.7.5:5c02a39a0b, Oct 14 2019, 18:49:57)
[Clang 6.0 (clang-600.0.57)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import numpy as np
>>> x = np.array(23)
>>> x
array(23)
向量(1 D 张量)
数字组成的数组叫做向量(vector)或一维(1D张量).一维张量只有一个轴.
>>> y = np.array([12,24,36,48])
>>> y
array([12, 24, 36, 48])
>>> y.ndim
1
这个向量有4个元素,所以被称作4D向量. 不要把4D向量和4D张量混淆i了.向量只有一个轴,但是表示了4个维度,而4D张量有4个轴.维度(dimensionality)可以表示沿着某个轴上的元素个数(比如 4 D 向量),也可以表示张量中轴的个数(比如 4 D 张量),这有时会令人感到混乱。对于后一种情况,技术上更准确的说法是 4 阶张量(张量的阶数即轴的个数),但 4 D 张量这种模糊的写法更常见。
矩阵(2 D 张量)
向量组成的数组叫做矩阵(matrix)或者二维张量(2D张量). 矩阵有2个轴.
>>> z = np.array([[5,78,24,1],
... [1,2,3,4],
... [4,6,7,8]])
>>> z
array([[ 5, 78, 24, 1],
[ 1, 2, 3, 4],
[ 4, 6, 7, 8]])
>>> z.ndim
2
3 D 张量与更高维张量关键属性
将多个矩阵组合成一个新的矩阵就可以得到一个3D张量
>>> q = np.random.randn(3,4,2)
>>> q
array([[[-0.01620116, -0.17436912],
[ 0.4581523 , -1.52342501],
[-0.8196764 , -1.56960572],
[-0.14080388, -1.08867946]],
[[ 0.22365678, 0.80081233],
[ 0.44461579, -0.10655642],
[ 1.04337676, 0.57167161],
[-0.45150608, 0.2777626 ]],
[[-0.39876745, 0.21239111],
[-1.91937848, -0.56022366],
[ 0.20022585, 1.96652715],
[-1.4904011 , 0.27641009]]])
>>> q.ndim
3
以此类推,将多个3D张量组合成一个数组,将会变成4D张量.后面使用的Objection Detection里面都是4D的张量进行计算的.
在 Numpy 中操作张量
在MNIST例子中,使用语法 train_ Images ]来选择沿着第一个轴的特定数字。选择张量的特定元素叫作张量切片(tensor slicing)。我们来看一下 Numpy 数组上的张量切片运算。
下面这个例子选择第 10~100 个数字(不包括第 100 个),并将其放在形状为(90,28 28) 的数组中。
my_slice=train_images [10: 100]
print (my_slice shape)
> (90,28,28)
它等同于下面这个更复杂的写法,给出了切片沿着每个张量轴的起始索引和结束索引。注意,:等同于选择整个轴。
my_slice =train_images [10: 100]
等同于前面的例子
my_slice=train_images [10: 100, 0: 28, 0: 281
你可以沿着每个张量轴在任意两个索引之间进行选择。例如,你可以在所有图像的右下角选出 14 像素 x14 像素的区域
my_slice=train_images [: 14]
也可以使用负数索引。与 Python 列表中的负数索引类似,它表示与当前轴终点的相对位置你可以在图像中心裁剪出 14 像素 x14 像素的区域:
my slice=train images [: 7: -7, 7: -7 ]
数据批量的概念
通常来说,深度学习中所有数据张量的第一个轴(0 轴,因为索引从 0 开始)都是样本轴(samples axis,有时也叫样本维度)。在 MINIST 的例子中,样本就是数字图像。
此外,深度学习模型不会同时处理整个数据集,而是将数据拆分成小批量。具体来看,下面是 MINST 数据集的一个批量,批量大小为 128。
batch train images [: 128]
然后是下一个批量。
batch =train images [128: 256)
然后是第 n 个批量。
batch train _images [128*n: 128 * (n +1)]
对于这种批量张量,第一个轴(0 轴)叫作批量轴(batch axis)或批量维度(batch dimension)。在使用 Keras 和其他深度学习库时,你会经常遇到这个术语。
现实世界中的数据张量
向量数据:2 D 张量,形状为(samp1 es, features)。
时间序列数据或序列数据:3 D 张量,形状为(samples, timesteps, features 图像:4 D 张量,形状为(samples, height, width, channells)或(samples, Channels height, width
视频:5 D 张量,形状为(samples, frames, height, width, channe1 s)或(samples frames, channels, height, width)
向量数据
二维向量和高数当中的概念一样,通过x,y来表示两者之间的关系
时间序列数据或序列数据
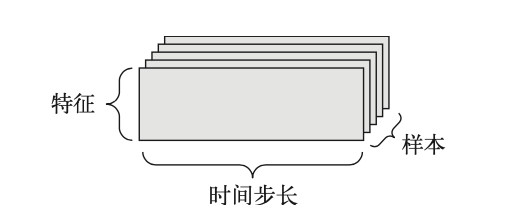
当时间(或序列顺序)对于数据很重要时,应该将数据存储在带有时间轴的 3 D 张量中。每个样本可以被编码为一个向量序列(即 2 D 张量),因此一个数据批量就被编码为一个 3 D 张量(见下图)。
图像数据
图像通常具有三个维度:高度、宽度和颜色深度。虽然灰度图像(比如 MINSTT 数字图像)只有一个颜色通道,因此可以保存在 2 D 张量中,但按照惯例,图像张量始终都是 3 D 张量,灰度图像的彩色通道只有一维。因此,如果图像大小为 256×256, 那么 128 张灰度图像组成的批量可以保存在一个形状为(128,256,256,1) 的张量中,而 128 张彩色图像组成的批量则可以保存在一个形状为(128,256,256,3) 的张量中(见下图)。
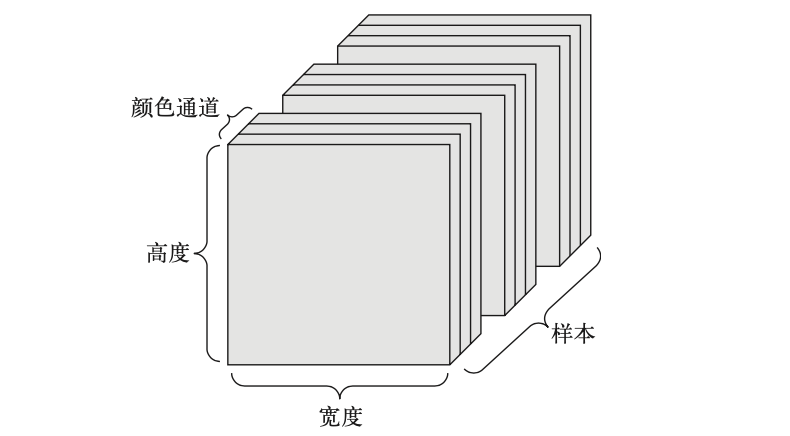
图像张量的形状有两种约定:通道在后(channels-last)的约定(在 Tensorelow 中使用)和通道在前(channels-first)的约定(在 Theano 中使用)。Google 的 Tensorelow 机器学习框架将颜色深度轴放在最后:(samples, height, width, co1 or_ depth)。与此相反,Thean 将图像深度轴放在批量轴之后:(samples, co1 or_ depth, height, width)。如果采用 Theano 约定,前面的两个例子将变成(128,1,256,256) 和(128,3,256,256)。Keras 框架同时支持这两种格式。
视频数据
视频数据是现实生活中需要用到 5 D 张量的少数数据类型之一。视频可以看作一系列帧,
每一帧都是一张彩色图像。由于每一帧都可以保存在一个形状为(height, width, color depth)的 3 D 张量中,因此一系列帧可以保存在一个形状为(frames, height, width, color_ depth)的 4 D 张量中,而不同视频组成的批量则可以保存在一个 5 D 张量中,其形状为
(samples, frames, height, width, color-depth
举个例子,一个以每秒 4 帧采样的 60 秒 Youtube 视频片段,视频尺寸为 144×x256, 这个视频共有 240 帧。4 个这样的视频片段组成的批量将保存在形状为(4,240,144,256,3) 的张量中。总共有 106168320 个值!如果张量的数据类型(dtype)是 f1 oat32, 每个值都是 32 位,那么这个张量共有 405 MB。好大!你在现实生活中遇到的视频要小得多,因为它们不以 f1 oat32 格式存储,而且通常被大大压缩,比如 MPEG 格式。
posted on 2020-03-18 22:42 TuringEmmy 阅读(674) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号