
【python3】爬取鼠绘汉化的海贼王漫画
特别说明:
因为早些时候鼠绘的接口调整,之前的代码已经不能用了。
正好最近在学习scrapy,于是重新写了一个,项目放在github https://github.com/TurboWay/ishuhui
一、起因:
很喜欢看海贼漫画,其中鼠绘汉化的海贼王无疑是最好的,更新最快的。但是由于版权的问题,迫于压力,鼠绘官网早一点的海贼王已经看不了,但是。。。重点是,我发现接口还是可以用的,于是就写了个爬虫把鼠绘翻译的海贼王漫画都爬了下来。分享下源码,供有需要的海迷使用。另外建议不要在高峰时段爬取,毕竟我们都爱鼠绘。
二、如何使用:
有安装python环境的,直接复制源码,运行.py
三、代码如下:
# -*- coding: utf-8 -*- import requests,json,time,os,shutil,logging,sys from PIL import Image from io import BytesIO logger = logging.getLogger('log') logger.setLevel(logging.DEBUG) # log format formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s') # console log ch = logging.StreamHandler() ch.setLevel(logging.DEBUG) ch.setFormatter(formatter) logger.addHandler(ch) def get_url(url): headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)' ' Chrome/62.0.3202.75 Safari/537.36'} response = requests.get(url=url, headers=headers, timeout=5) js = json.loads(response.text) if js["errNo"] == 0: return js["data"] else: logger.warning("请求失败:{0}".format(js)) # 去掉文件名禁止符号 def clean(text): kws = ['/','\\',':','*','"','<','>','|','?'] for kw in kws: text = text.replace(kw,'.') return text # 新建文件夹 def makefile(path,istruncate): if os.path.exists(path) and istruncate: shutil.rmtree(path) os.mkdir(path) elif not os.path.exists(path): os.mkdir(path) # 下载图片 def save_pic(img_src,picname): try: response = requests.get(img_src) image = Image.open(BytesIO(response.content)) image = image.convert('RGB') image.save(picname) logger.info("{0}图片下载成功".format(picname)) flag = True except Exception as e: logger.info("{0}图片下载失败:{1}".format(picname,e)) flag = False return flag # 保存图片 def resave_pic(img_src,picname): count,flag = 0,save_pic(img_src,picname) while not flag: flag = save_pic(img_src, picname) count += 1 if count > 5: break def get_data(path,nextid): url = 'http://hhzapi.ishuhui.com/cartoon/post/ver/76906890/id/{0}.json'.format(nextid) data = get_url(url) if data: server = 'http://pic04.ishuhui.com/' source, id, title, book, number = data['source'], data['id'], data['title'], data['book_text'], data['number'] content_img = eval(data['content_img']) if data['content_img'] else {} if source == 1: # 鼠绘汉化 makefile(path + '\\' + book, False) title = clean(title) filepath = path + '\{0}\{0} 第 {1} 话 {2}'.format(book,number,title) makefile(filepath, True) # 新建文件夹 if content_img: # 下载图片 for img, imgurl in content_img.items(): imgurl = server + imgurl.replace('/upload/','') picname = filepath + '\\'+ img resave_pic(imgurl,picname) logger.info("ID:{2} 第 {0} 话 {1}下载完成".format(number,title,id)) next = data['prev'] if next: return next['id'] elif nextid == 900: # 900的时候会找不到上一页 return 899 if __name__ == "__main__": path=sys.path[0] nextid=get_data(path,10881) while nextid: nextid=get_data(path,nextid) time.sleep(3)
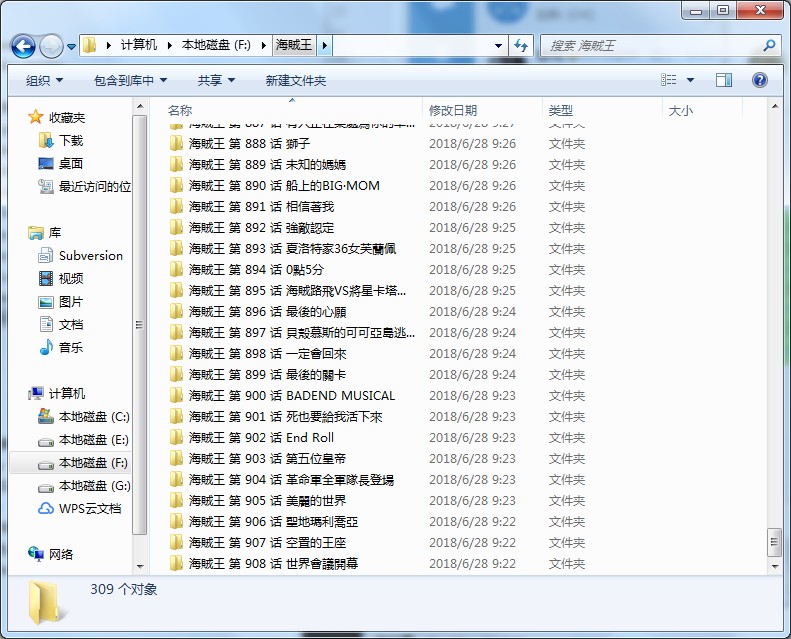
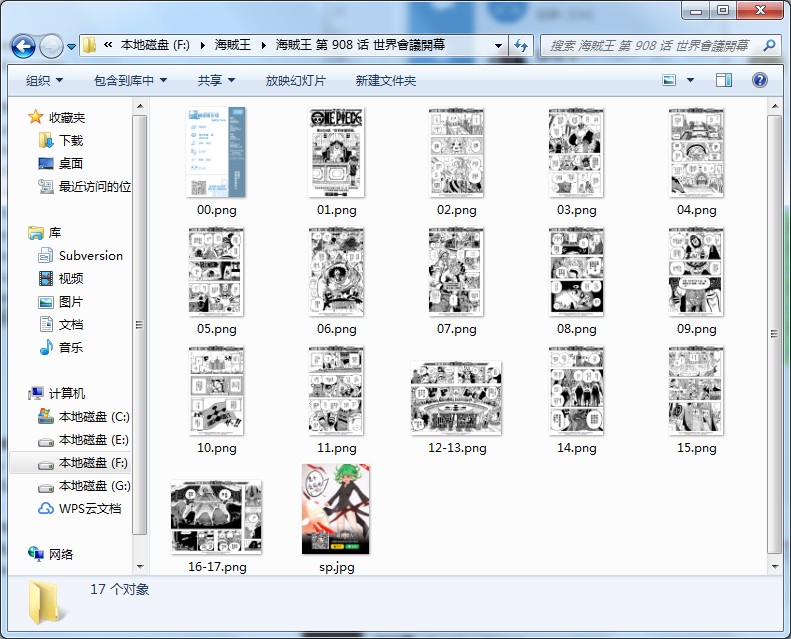
四、结果如下:
第598话 2年后 -- 第908话 世界會議開幕,共309话,3.22G,其中680和681话缺失了,接口扫了一下也没找到。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号