
【python3】基于scrapyd + scrapydweb 的可视化部署
一、部署组件概览
该部署方式适用于 scrapy项目、scrapy-redis的分布式爬虫项目
需要安装的组件有:
1、scrapyd 服务端 【运行打包后的爬虫代码】(所有的爬虫机器都要安装)
2、logparser 服务端 【解析爬虫日志,配合scraoydweb做实时分析和可视化呈现】(所有的爬虫机器都要安装)
3、scrapyd-client 客户端 【将本地的爬虫代码打包成 egg 文件】(只要本地开发机安装即可)
4、Scrapydweb 可视化web管理工具 【爬虫代码的可视化部署管理】(只要在一台服务器安装即可,可以直接用爬虫机器,这边直接放在172.16.122.11)
二、各组件安装步骤
1、scrapyd 服务端 (所有的爬虫机器都要安装)
用途:运行打包后的爬虫代码,可以通过api调用访问
安装命令: pip install scrapyd
修改配置: 安装完成后,修改 default_scrapyd.conf ,文件路径 /home/spider/workspace/env/lib/python3.6/site-packages/scrapyd
修改绑定地址,允许外部访问;另外,建议修改以下相关的文件路径 ,否则这些文件夹默认生成在 安装路径下;
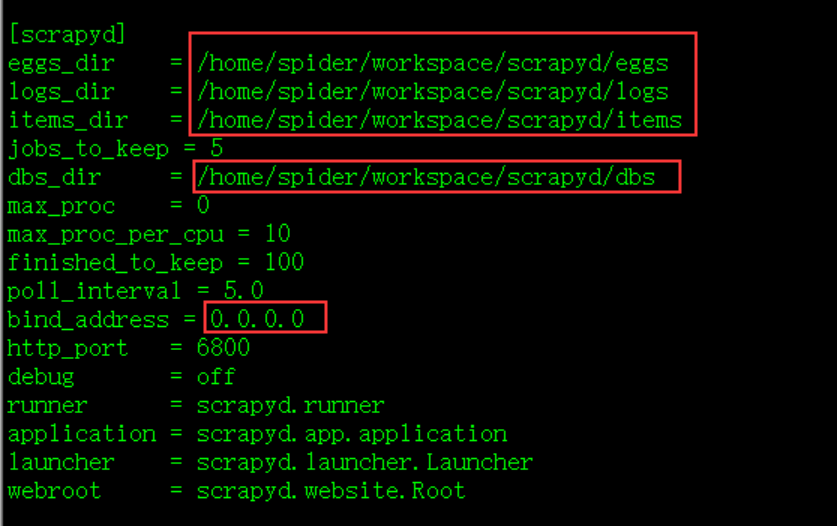
运行命令:nohup scrapyd > /dev/null &
访问地址:http://172.16.122.11:6800/

2、logparser 服务端 (所有的爬虫机器都要安装)
用途:解析爬虫日志,配合scraoydweb做实时分析和可视化呈现
安装命令: pip install logparser
修改配置: 安装完成后,修改 settings.py,文件路径 /home/spider/workspace/env/lib/python3.6/site-packages/logparser
将要解析的日志路径修改为 scrapyd 的日志路径
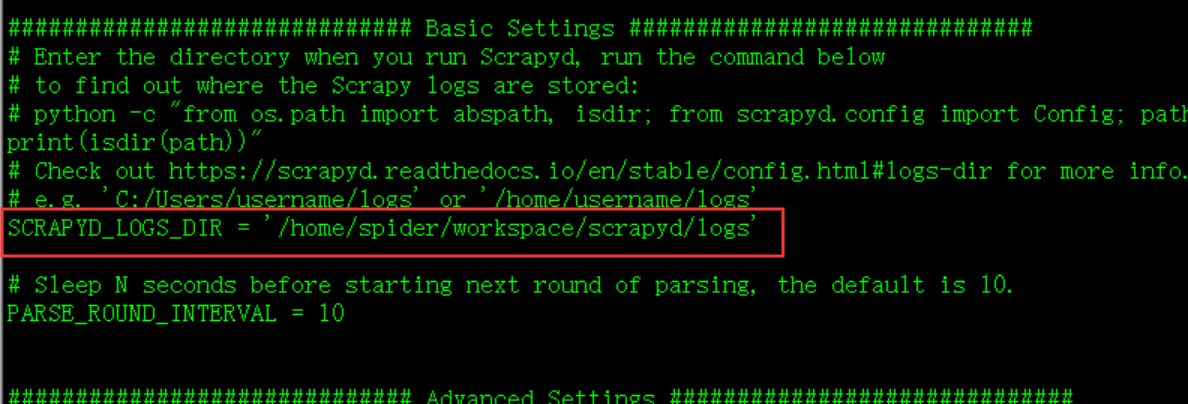
运行命令:nohup logparser > /dev/null &
3、scrapyd-client 客户端 (只要本地开发机安装即可)
用途:将本地的爬虫代码打包成 egg 文件
安装命令: pip install scrapyd-client
修改配置: 安装完后,执行 scrapyd-deploy -h ,如果找不到命令,则单独写一个bat文件 scrapyd-deploy.bat 放到 script 目录下即可
@echo off
D:\Anaconda3\python.exe D:\Anaconda3\Scripts\scrapyd-deploy %*

4、Scrapydweb 可视化web管理工具(只要在一台服务器安装即可,可以直接用爬虫机器,这边直接放在172.16.122.11)
用途: 爬虫代码的可视化部署管理
安装命令: pip install Scrapydweb
创建文件夹:mkdir scrapydweb; cd scrapydweb
执行命令:scrapydweb (会在当前目录下生成配置文件 scrapydweb_settings_v10.py)
修改配置: scrapydweb_settings_v10.py 【另外, 修改data路径时如果不会生效,那么同时要修改默认配置文件的data路径,可能是个bug, 默认配置文件路径: /home/spider/workspace/scrapydweb_env/lib/python3.6/site-packages/scrapydweb/default_settings.py 】 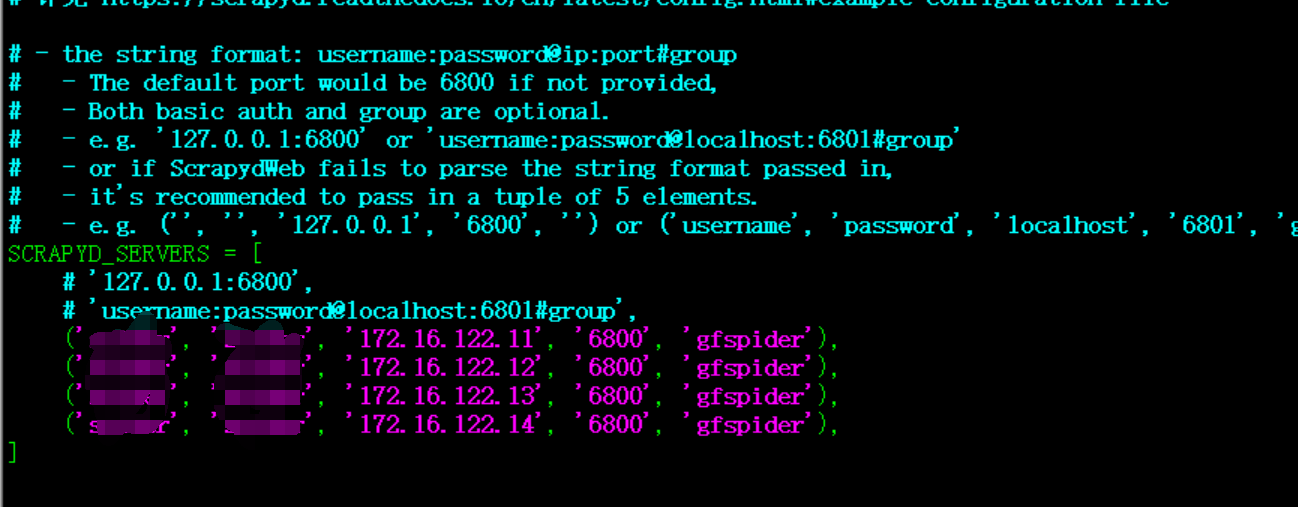
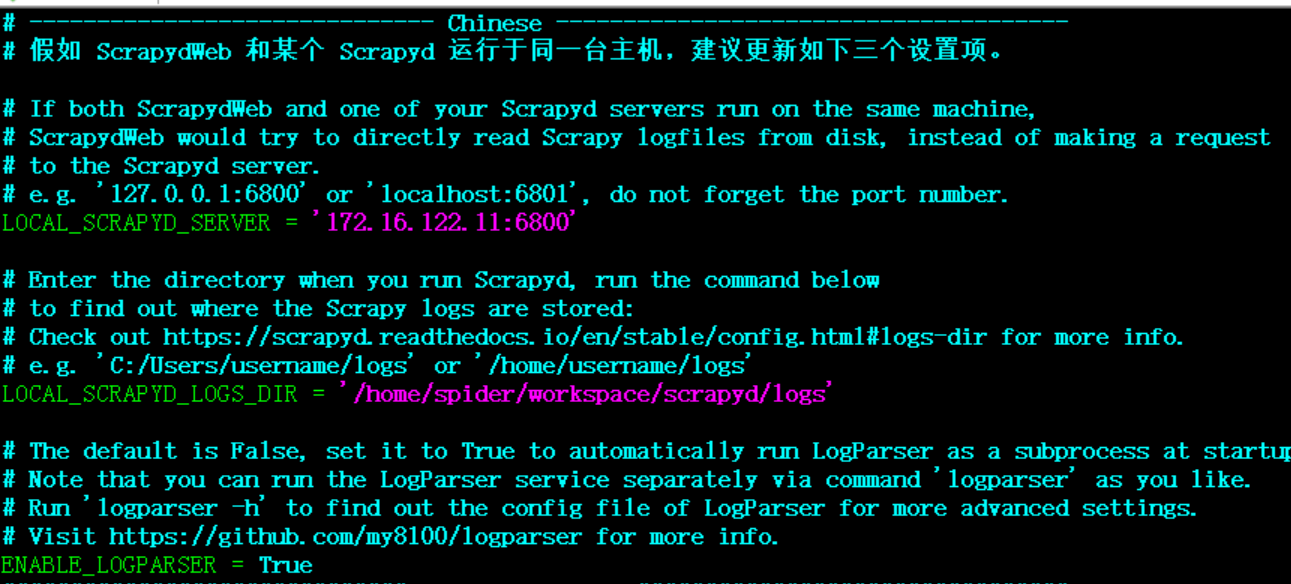

修改完配置文件后,再次执行 nohup scrapydweb > /dev/null &
访问地址:http://172.16.122.11:5000
三、爬虫代码打包
工具:scrapyd-client (在上一步已安装)
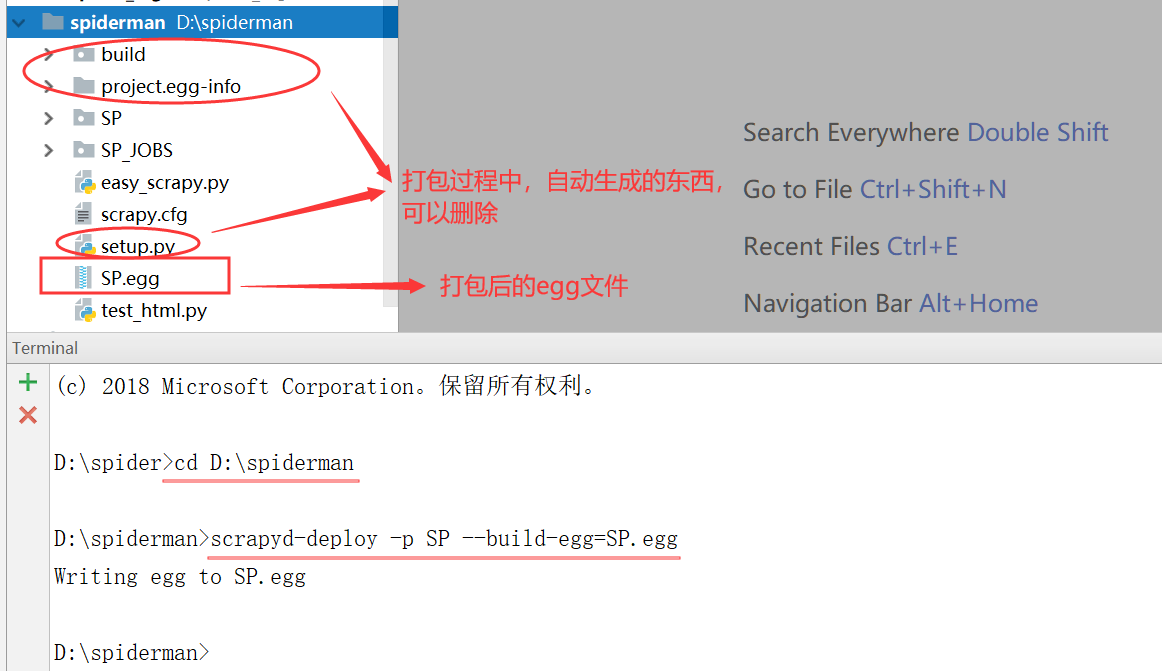
打包命令:在工程目录下执行,SP是工程名称 scrapyd-deploy -p SP --build-egg=SP.egg
关于爬虫代码需要注意的事项和egg文件说明:
1. 打包后的egg文件其实就是爬虫代码编译后的压缩文件,所以比原来的代码文件要小很多;
2. egg文件只打包了爬虫代码,不包含环境代码,也就是说,在scrapyd服务端运行的时候,python环境需要先安装好爬虫运行所需的所有包;
3. 在工程代码中,比如 setting 中最好不要有生成文件路径的做法(比如默认生成日志文件夹),否则打包成egg后,上传时可能会报错;因为上传的时候,也会在服务端编译,这个时候就可能会出现 生成文件夹 的 权限报错;
4. 如果想要使用 scrapydweb 的实时日志分析,那么在爬虫代码中,不要指定日志路径,否则运行时,日志会写到你指定的路径而无法分析;不指定路径,运行爬虫时,日志会输出到 scrapyd 预先设置好的 logs 里面,前面 logparser(日志解析服务)已经配置好 读取该位置的日志,从而实现实时分析;
四、可视化管理Scrapydweb教程
1、部署工程(有两种方式,方式1:是配置里面写死路径,自动打包;方式2:上传打包好的egg文件;举例为方式2 )
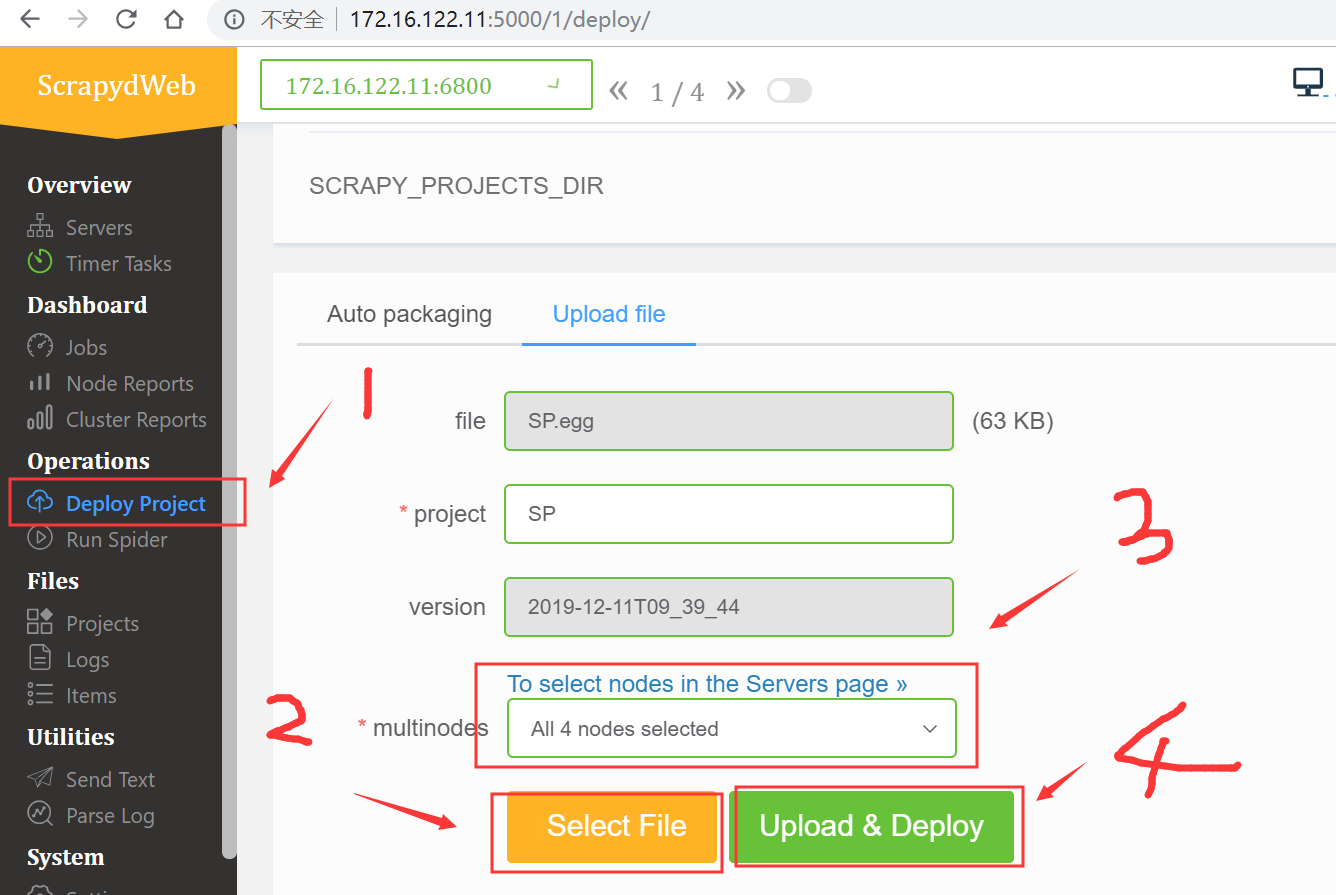
部署成功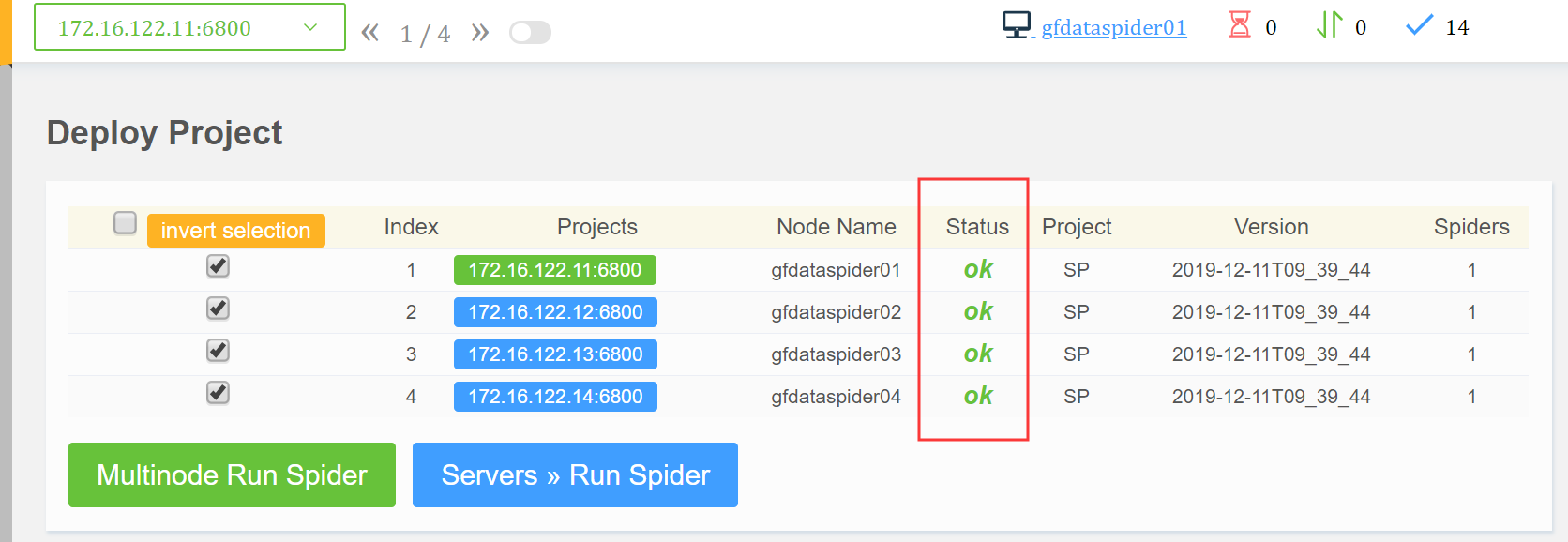
2、运行爬虫,启动一次爬虫就是一个作业,会自动分配一个作业号;后续可以根据这个作业号,查看作业情况
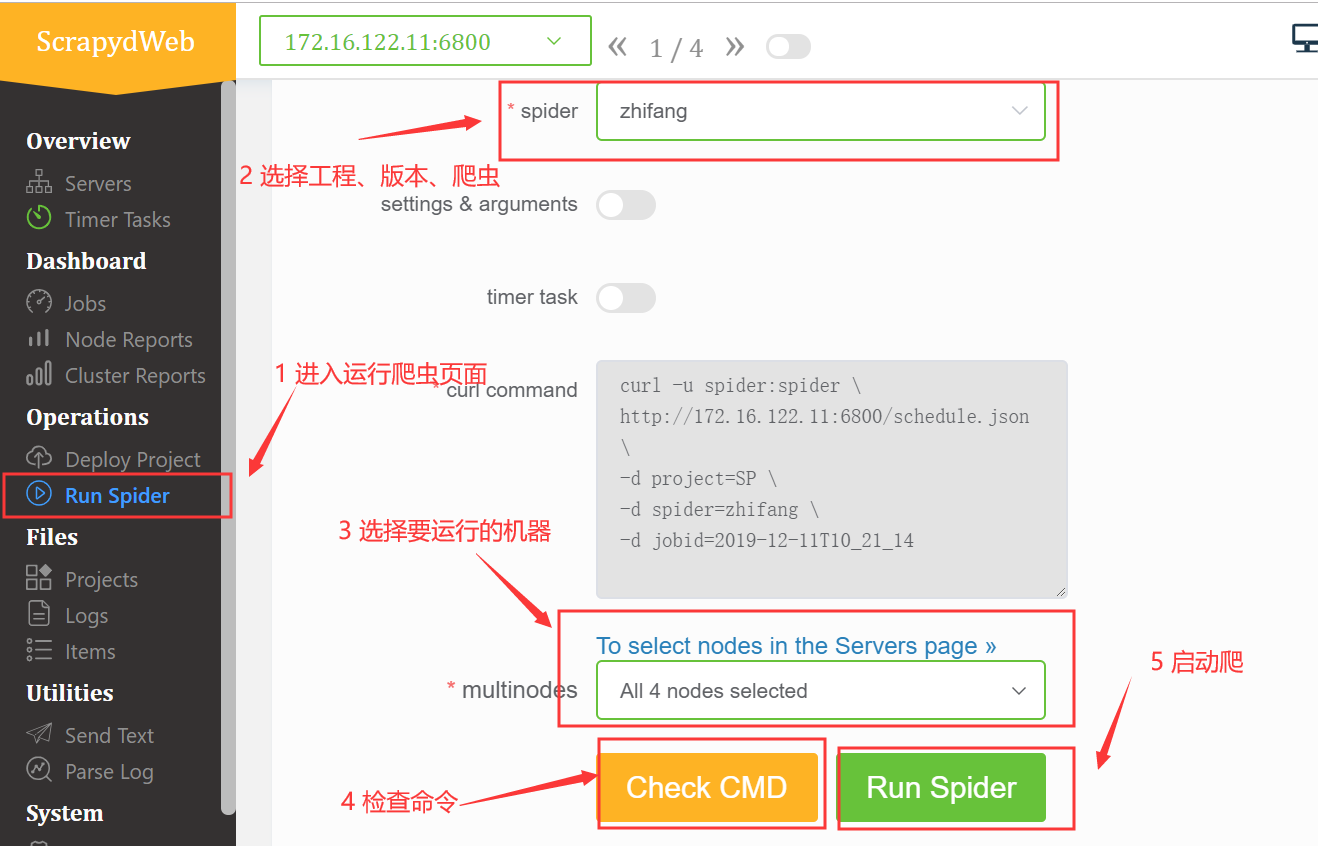
爬虫启动成功
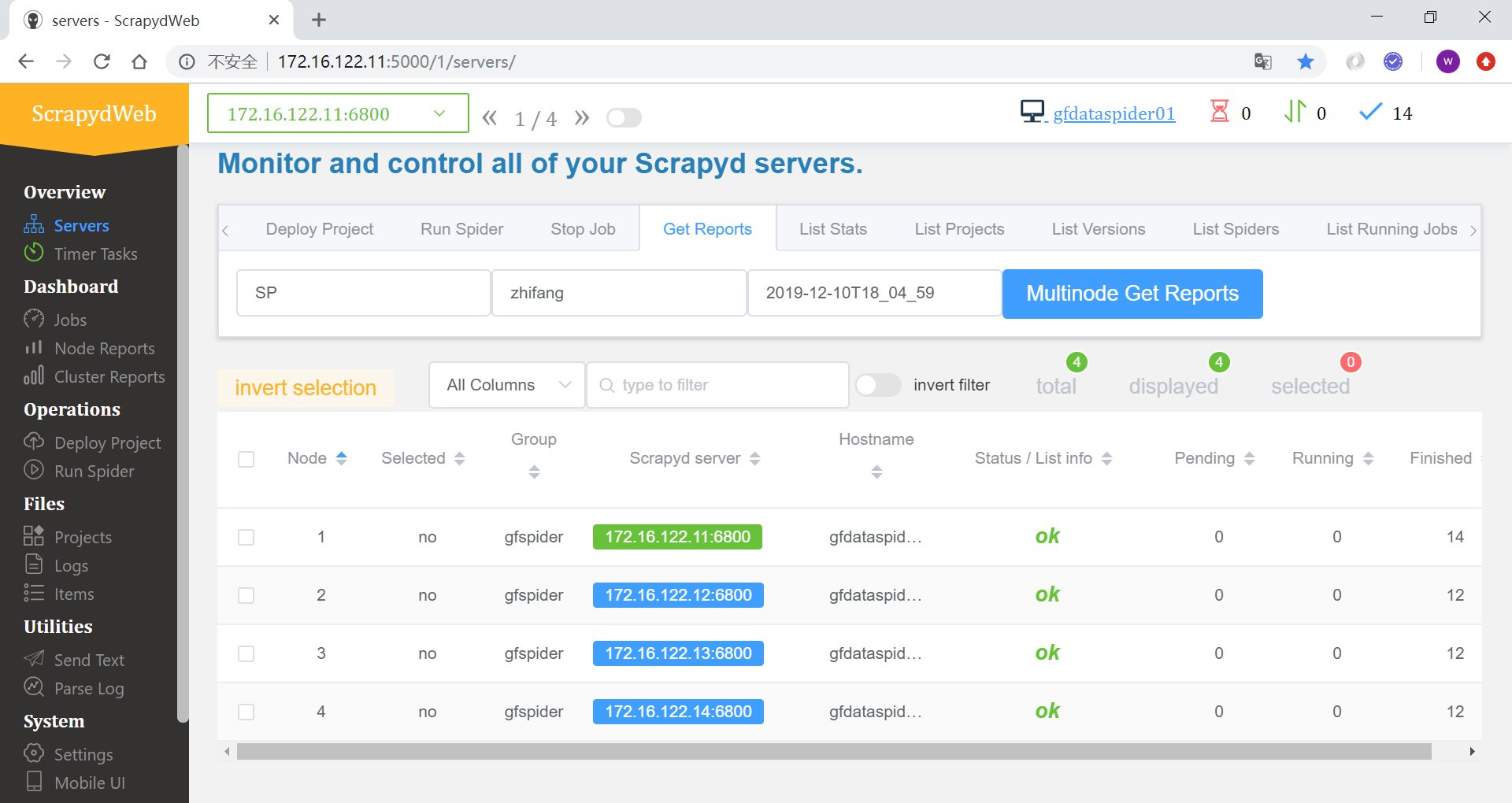
查看所有爬虫服务器的作业队列
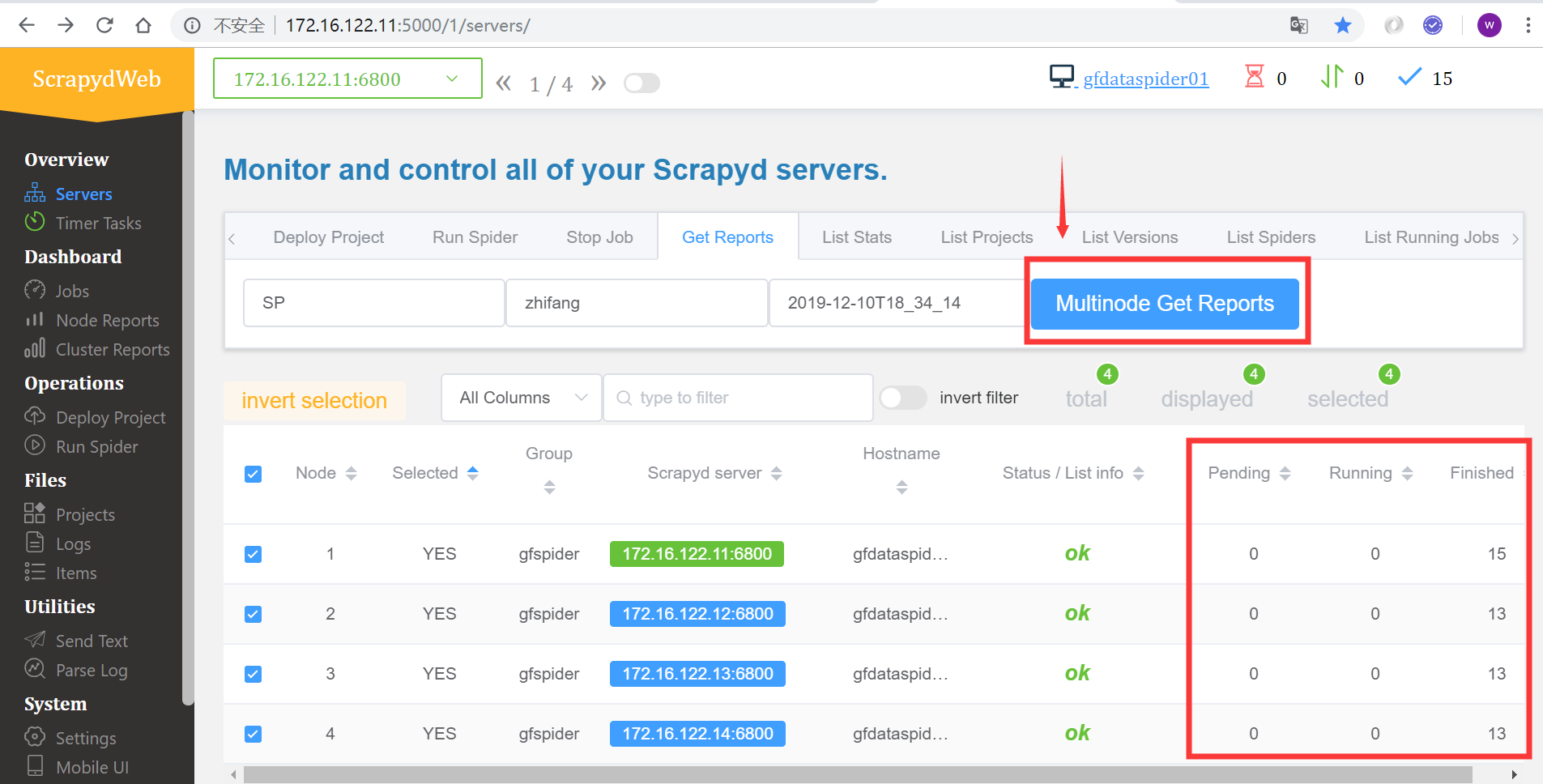
查看作业报告 
3、作业相关(查看历史作业情况)

日志分析

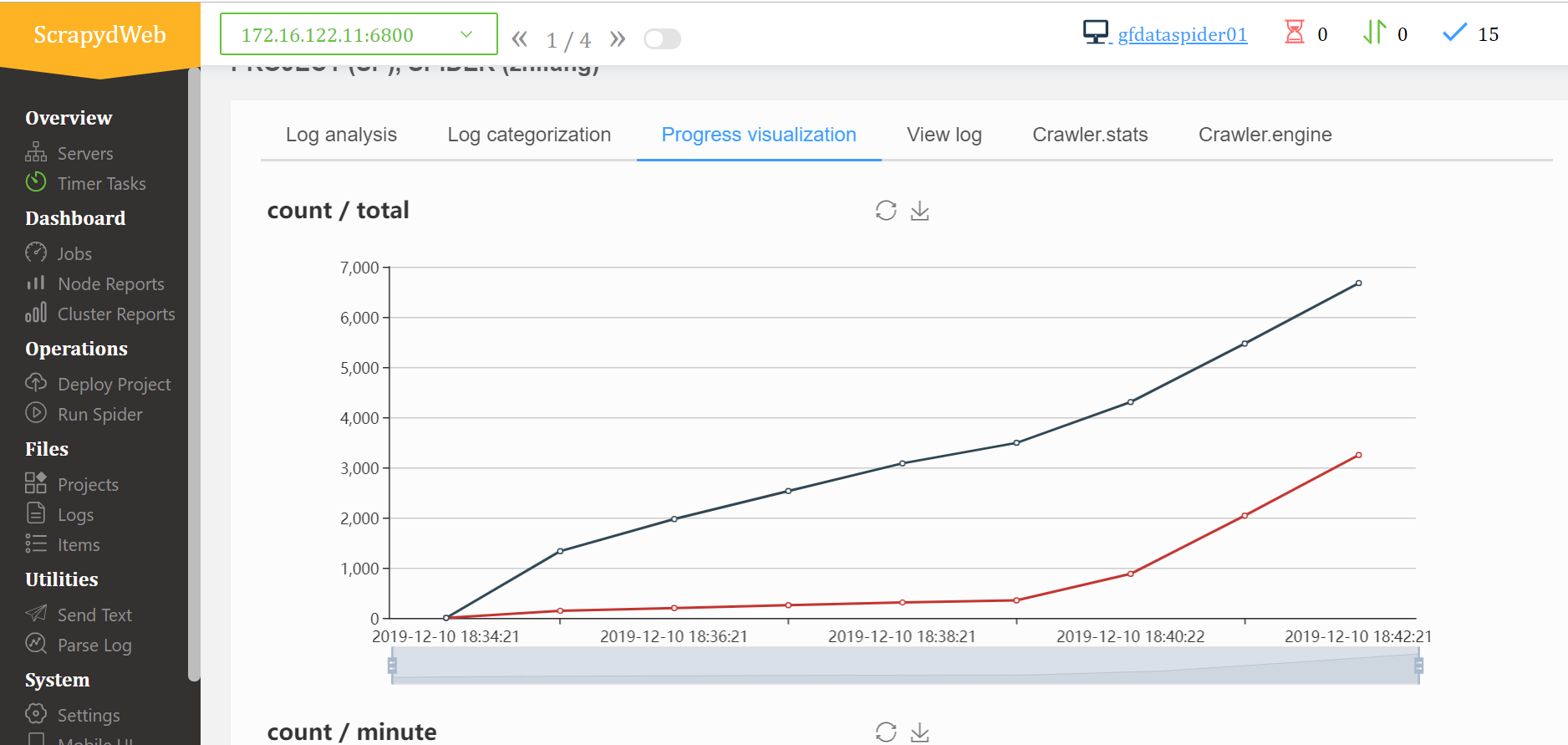
4、增加定时作业,具体的操作和运行爬虫一样,无非就是多个时间的设置
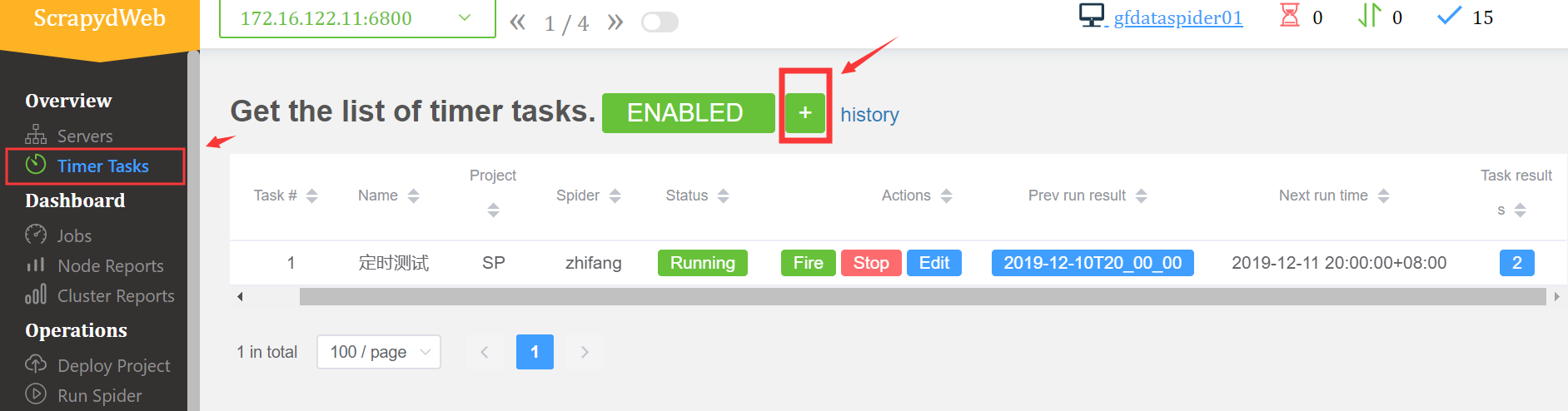
5、还有其他的一些功能,上传本地日志进行分析;设置邮件之类的,有兴趣的再自行摸索

 浙公网安备 33010602011771号
浙公网安备 33010602011771号