补天挖洞经验贴
转载自:
补天付费厂商漏洞挖掘小技巧
1、子域名收集
不要想着去撸主站,主站一出来几乎被人轮了个遍,跟大牛抢肉吃,难,放弃。
所以我们一般都是百度找子域名 例如www.xxxxx.com是主站,关键字 inurl:xxxxx.com。如果这样能找到不少子域名。
1.1 补天不收的漏洞
1、反射XSS
2、CSRF
3、目录遍历
4、二进制(据补天审核说,他们没人看的懂,没法审,所以不收)
5、密码处的验证码爆破
6、http.sys远程代码执行漏洞
7、URL爆出了数据库
8、jquery version泄露
9、绝对路径泄露
10、Slow attack满攻击
11、短文件漏洞
12、DOS不收
2、尝试常用漏洞
2.1 爆破
找到一个系统,如果没验证码,那么爆破吧,得到一发账号,进后台才有意思。
不怕神一样的队友,就怕猪一般的对手~

2.2 CMS通用漏洞
如果网站是利用某CMS建站的,可以去试试CMS通用漏洞,特别是如果有前台高危漏洞,那就很有意思。
比如dedeCMS爆管理员账号密码的,siteserver后台密码重置漏洞等等经典案例。有时候用起来,事半功倍。
2.3 SQL注入漏洞
有人网站是第三方开发的,第三方的水平又不行,所到之处,全是注入。

2.4 XSS漏洞
补天不收反射XSS,所以我们得找存储型,根据挖付费的经验,能弹个框就行了。哪怕是self-XSS。
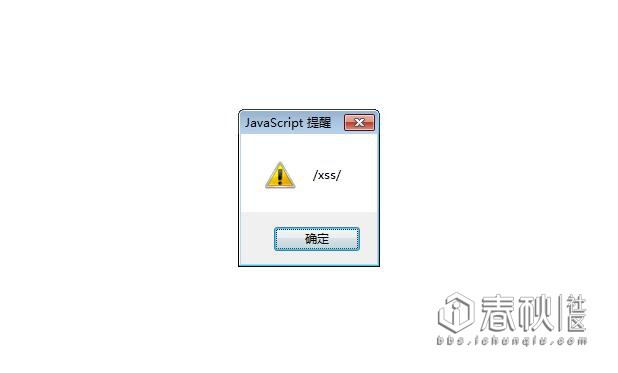
如果是盲打的话,少数网站做了cookie的httponly。这样JS是无法读取到cookie的,难不成我们就真没办法了?教大家一个猥琐的小技巧,XSS的本身是在网页上插入你自己的html代码,但我干嘛非要用JS读取你cookie,我可以构造一个表单让你填啊~理由是登录过期、二次验证啥的,这不就得到账号密码了么?

2.5 越权和逻辑漏洞
2.5.1 越权
付费厂商多见于ID参数,比如typeID、OrderID等等,这里只是举例。更改ID,可以越权看其他ID的信息。还有AWVS扫目录,有的后台未授权访问,可以利用。
2.5.2 逻辑漏洞
比如四位验证码,没做错误次数限制,0000-9999一共一万种搭配方式,burp跑一下,很快就得到了。或者支付逻辑漏洞(多见于商城或者网站账户充值),任 意用户密码重置(补天说这是高危漏洞)

2.6 任意文件上传/下载
任意文件上传,找个上传点,上传你的文(mu)件(ma),这时候啥00截断啊,解析漏洞啊~霹雳啪啦往脸上糊啊~
任意文件下载,找数据库配置文件呗。如果有网站备份(一般是压缩包),嘿嘿嘿~赶紧看看里面有没有数据库啊
2.7 非web问题
IIS的解析漏洞、struts2框架的命令执行漏洞、java反序列化命令执行漏洞、等等等等。。。。。

3、我想说的
有人问我为什么不再说一点其他的漏洞,我只想用一张图来表示。

所用到的图片,全部是复制i春秋的图片地址。如果图片不在说明被管理员删了,或者移动了位置
我自己会在挖洞过程中补充以上未提到的点。。
最后说句

2.14
记录下,今天凌晨,疯狂刷补天的公益SRC中的大学和学院。
因为前不久看了一个漏洞,感觉出现的学校还是很多的,并且正方的使用也是很多。
结果发现:大部分学校用 青果,URP,新、旧版正方 的CMS比较多,感觉可以三分天下了,其他的都是些大学配合当地公司的或者学校牛逼自己写一个。
并且善用百度,谷歌的搜索语言,对查找是一种捷径。
再提下,刚才的CMS如果有源码更好了,但是如果没有,自己一个个试。(PS:我感觉还是要一个个试,因为这种商业应用不可能有源码公开的)
其次,今天,搜一个学校时,尽然搜到了学校网站的管理后台,这是我第一次遇见,一般会把这种重要的站点放在内网里面,结果放在外网。。hhhh
不过,不清楚是什么,有可能对IP加了白名单吧,用户名和密码都没做过滤,万能密码尝试过后,会提示 错误:62
不知啥意思啦。。。
并且,对于这种刷洞的,那个学校心理要有点number,什么985,211就不要搭理了,因为自己根本没他们学校的学生牛逼哈。
今天情人节,你和谁过呢?

并晒下近期的挖洞情况。。
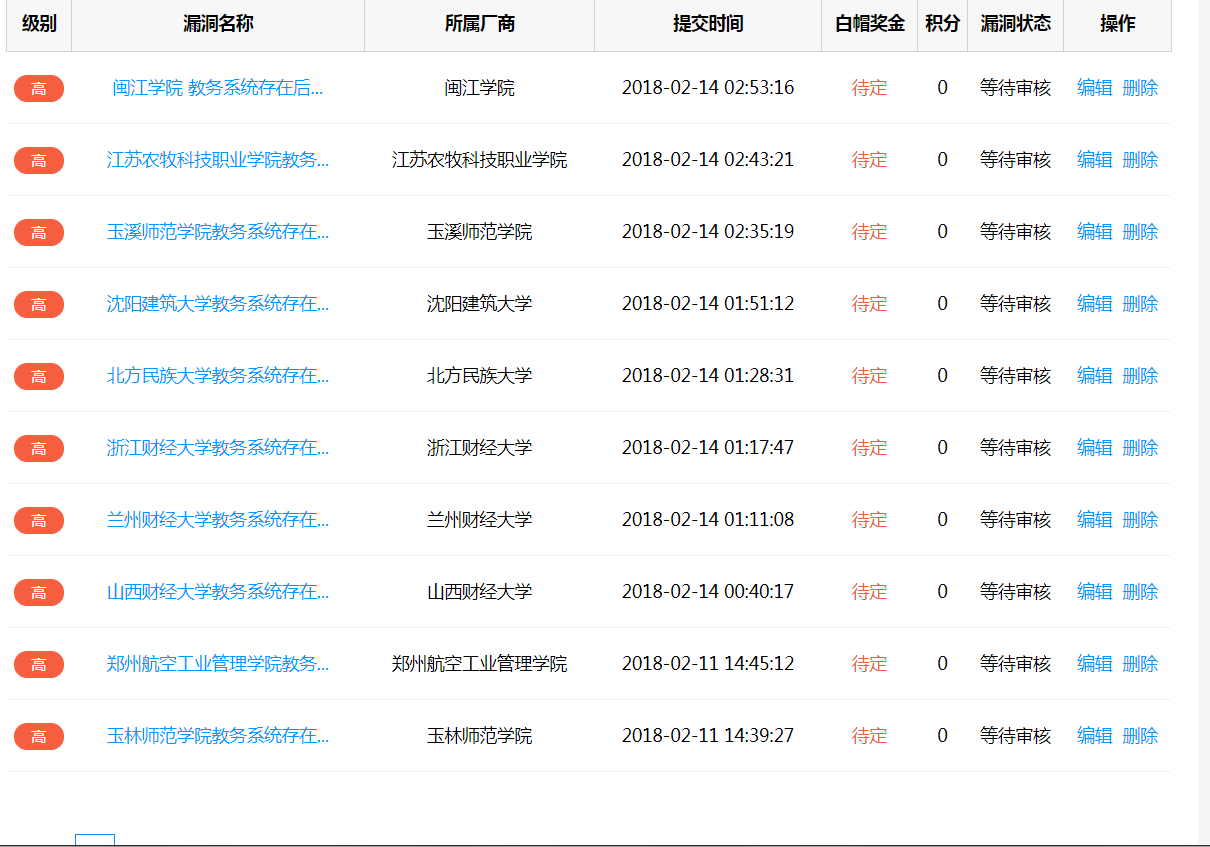
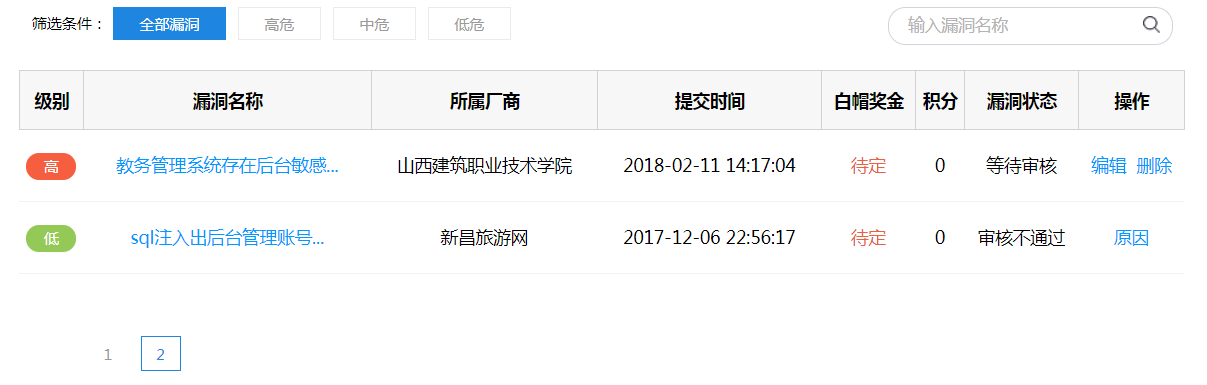
2018.3.1
放一个爬补天公益SRC的厂商URL的爬虫
1 import json 2 import requests 3 import time 4 from bs4 import BeautifulSoup 5 6 def spider(): 7 ''' 8 爬取所有公益厂商的ID 9 保存为id.txt 10 :return: 11 ''' 12 headers = { 13 'Host': 'butian.360.cn', 14 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0', 15 'Accept': 'application/json, text/javascript, */*; q=0.01', 16 'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3', 17 'Accept-Encoding': 'gzip, deflate', 18 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 19 'X-Requested-With': 'XMLHttpRequest', 20 'Referer': 'http://butian.360.cn/Reward/pub//Message/send', 21 'Cookie': #放你登录时的cookies 22 'Connection': 'keep-alive' 23 } 24 for i in range(1,149): 25 data={ 26 'p': i, 27 'token': '' 28 } 29 time.sleep(3) 30 try: 31 res = requests.post('http://butian.360.cn/Reward/pub/Message/send', data=data,headers=headers,timeout=(4,20)) 32 except requests.exceptions.ConnectionError as identifier: 33 print(identifier) 34 allResult = {} 35 allResult = json.loads(res.text) 36 currentPage = str(allResult['data']['current']) 37 currentNum = str(len(allResult['data']['list'])) 38 print('正在获取第' + currentPage + '页厂商数据') 39 print('本页共有' + currentNum + '条厂商') 40 for num in range(int(currentNum)): 41 print('厂商名字:'+allResult['data']['list'][int(num)]['company_name']+'\t\t厂商类型:'+allResult\ 42 ['data']['list'][int(num)]['industry']+'\t\t厂商ID:'+allResult['data']['list'][int(num)]['company_id']) 43 base='http://butian.360.cn/Loo/submit?cid=' 44 with open('id.txt','a') as f: 45 f.write(base+allResult['data']['list'][int(num)]['company_id']+'\n') 46 def Url(): 47 ''' 48 遍历所有的ID 49 取得对应的域名 50 保存为target.txt 51 :return: 52 ''' 53 headers={ 54 'Host':'butian.360.cn', 55 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0', 56 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 57 'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3', 58 'Accept-Encoding': 'gzip, deflate', 59 'Referer':'http://butian.360.cn/Reward/pub', 60 'Cookie': #放你登录时的cookies 61 'Connection':'keep-alive', 62 'Upgrade-Insecure-Requests': '1', 63 'Cache-Control':'max-age=0' 64 } 65 with open('id.txt','r') as f: 66 for target in f.readlines(): 67 target=target.strip() 68 getUrl=requests.get(target,headers=headers,timeout=(4,20)) 69 result=getUrl.text 70 info=BeautifulSoup(result,'lxml') 71 time.sleep(5) 72 url=info.find(name='input', attrs={"name":"host"}) 73 name = info.find(name='input', attrs={"name": "company_name"}) 74 lastUrl=url.attrs['value'] 75 print('厂商:' + name.attrs['value'] + '\t网址:' + url.attrs['value']) 76 with open('target.txt','a') as t: 77 t.write(lastUrl+'\n') 78 time.sleep(5) 79 print('The target is right!') 80 if __name__=='__main__': 81 82 data = { 83 's': '1', 84 'p': '1', 85 'token': '' 86 } 87 res = requests.post('http://butian.360.cn/Reward/pub/Message/send', data=data) 88 allResult = {} 89 allResult = json.loads(res.text) 90 allPages = str(allResult['data']['count']) 91 print('共' + allPages + '页') 92 spider() 93 Url()

