
[翻译]Broker Vs. Brokerless
原文地址 : http://wiki.zeromq.org/whitepapers:brokerless
本文由 : https://www.cnblogs.com/TssiNG-Z 翻译
Broker vs. Brokerless
简介
本文介绍了几种消息队列模型的实现方式. 其中会针对每一种(模型的)实现讨论其优缺点, 这意味着本文可以作为基础知识来帮助各位读者理解ZeroMQ和其他传统消息队列(AMQP)之间的区别.
Broker
大多数消息队列的实现方式是在(整个业务系统的)中心构建一个独立的服务端("broker", 即消息代理服务器). 我们可以简单的把这种模型理解成传统的"星形"模型结构, 在此模型结构中, 所有的app都连接在broker上, app之间互相不存在任何通讯, 任何通讯请求/应答都通过broker进行传递.
这种消息队列模型有以下三大优点:
- 每一个app都不关心其他app的通讯地址, (为了进行通讯请求/应答)app所需要的信息仅为broker的网络地址而不是物理拓扑地址(ip地址, host名称等), broker会根据业务种类(在AMQP中指 "queue name", "routing key", "topic", "message properties"等属性)将消息分发给对应的app.
- 消息生产者和消息消费者在彼此的生命周期中不一定需要有交集. 生产者向broker发送消息后就可以停止运行(业务层面开始处理其他业务/软件生命周期结束), 而相应的消息可以在消费者准备就绪时随心所欲的从broker中取出并消费掉.
- broker模型有着较好的可靠性, 当(broker上连接的)程序出现BUG等异常情况时, 已经被存入broker的消息可被持久化(消息不会丢失或缺损).
尽管如此, broker模型存在以下两个缺点:
-
在通讯上, broker模型会造成巨大的网络通讯开销.
-
所有消息都要经由broker进行分发会导致broker(的性能)成为整个系统的性能瓶颈, 在broker忙的不可开交进行消息转发时, (broker上连接的)各个app(由于阻塞等待消息而)在绝大多数时间都处于闲置状态.
为了论证上文描述的broker模型的缺点, 我们假设一个业务场景, 该场景中的业务需要被4个独立的app按顺序处理, 该场景对应的伪代码如下 :
1 function AppA (x) 2 { 3 y = do_business_logic_A (x); 4 return AppB (y); 5 } 6 7 function AppB (x) 8 { 9 y = do_business_logic_B (x); 10 return AppC (y); 11 } 12 13 function AppC (x) 14 { 15 y = do_business_logic_C (x); 16 return AppD (y); 17 } 18 19 function AppD (x) 20 { 21 return do_business_logic_D (x); 22 }
traditional broker
首先, 针对上述业务场景, 我们套用传统的broker模型使用SOA(面向服务架构, 请求/应答)架构. 该架构基于RPC(远程过程调用), 任意一个程序可以通过对一个接口的参数进行组包并通过网络发送到另一个程序来调用该远端程序中的函数(function), 参数会被远端程序解析并调用相应的函数进行处理(和响应), 而最终的响应结果会(在远端程序中)被组包并返回给调用程序, 调用程序对该返回包的处理方式如是.
在此场景和架构下, 我们(完成一次业务操作)需要12次网络跳转(输入/输出我们假设是本地客户端操作, 不存在网络开销), 跳转过程如图所示 :
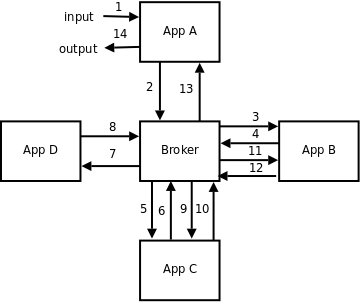
更离谱的是, broker需要处理6次消息(1轮IO记为1次消息处理, 即12次网络跳转), 这个场景下6次消息处理对于broker而言或许无伤大雅, 但是在高频业务处理的场景下(大概每秒10万次业务调用), broker或许会达到性能瓶颈(broker每秒处理60万次消息), 同时硬件(CPU, RAM, SOCKET文件描述符等)或许也会被消耗殆尽.
为了降低broker的负载并消除业务处理延迟, 我们可能会选择使用流水线来代替SOA模型, 以此来避免一半数量的消息处理(12跳 -> 6跳). 这种解决方案图示如下:
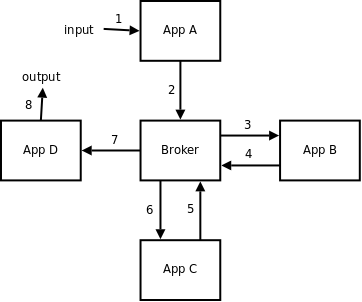
(译者注 : 这里 5 和 6箭头方向画反了, 截至本文时间2022年, 11年了原文作者还没有改这个箭头方向, 哈哈哈哈哈)
在以broker为通讯中心的("星型")架构下, 这或许是最有效的一种优化方案. 在此方案下, 如果broker仍然表现出性能瓶颈或仍存在较高的处理延迟, 将broker从该架构中移除便是唯一的优化手段了.
No Broker
下方展示了没有broker作为(业务系统)中心的结构:
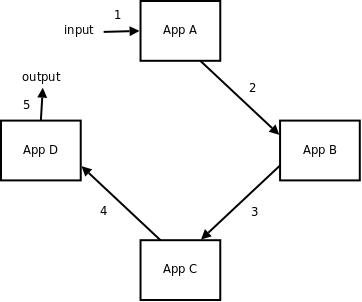
在上图展示的结构下, 网络跳转数肉眼可见的被降低到了3次且不再有鹤立鸡群的性能瓶颈点. 虽说此类结构乃是专门针对低延时,高并发场景设计的解决方案, 但这种负载均衡使得系统的易用性大打折扣, 因为每一个app都需要和与其有通讯需求的app进行连接, 这就要求app必须要知道每一个对端app的网络地址. 虽然对于上图所示的结构来讲, 对端app的网络地址是很轻易就能获取到的(一共只有4个app), 但在实际商用级别的项目中, 面对成百上千的app(微服务)时, app之间的交互管理将会是一场噩梦(无论是对使用者还是开发者).
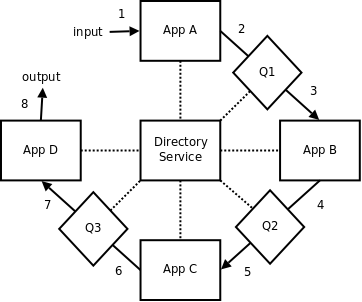
Broker as a Directory Service
基于上述内容, 我们可以将broker的功能分为两大类:
- broker需要具备一个可以在当前网络中指明 app X --> host Y (X所运行的地址是Y) 的目录, 这样app X的消息就会被分发给host Y, 如此运作的broker可以被看做是一个目录访问服务(路由表).
- broker服务内部进行消息分发.
下图展示了这种结构:
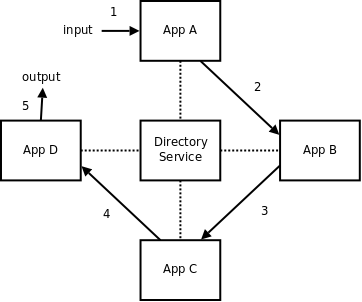
这样我们就兼顾了高性能和易用性. 如果想了解更多关于这种架构的信息, 可以参考ZeroMQ exchange的例子.
虽然但是, (基于上述架构)我们或多或少仍会有一些问题需要解决.
Distributed broker
正如我们上面所说, brokerless模型虽然兼顾了高性能和易用性, 却并不具备broker模型的优点.即我们没有必要捆绑生产者和消费者的生命周期, (在broker模型中)消息可以在消费者没有就绪前就被生产出来并进行持久化, 而当app异常时, 已经发给broker的消息也不会缺损丢失.
为了完善这两点, 我们需要在(两个通讯app)中间构建一个app(类似broker, 用于分发消息), 显而易见, (当在系统中加入这个app时)2次网络跳转不可避免的出现在了消息收发的过程中, 但是, 这种处理方式要好过broker沦落成(业务系统的)性能瓶颈(即所有消息收发都交给broker来做).
这种结构我们称之为 "distributed broker" , 结构如下图所示:
如图所示, 每一个消息队列都被(从broker中)拆分出来实现, 每当app连接一个队列(进行消息收发)时, 这个队列可能(和上一次连接的队列)是同一个, 也可能不是. 上图方块可能指代多个队列, 也可能只指代一个单独的队列(取决于代码实现), 每一个队列都在broker注册了(路由信息), 这样队列就对该网络中所有的app都是可见的(通过查询路由表, 回顾 Broker as a Directory Service 小节). 不仅如此, 队列(被拆分的这个操作)将其功能定义的非常简单 : 把生产者的消息推送给消费者. 这种设计相比起(将分发工作混入)充满复杂业务逻辑的程序而言, 大大降低了错误的发生概率.
如果你对上述这种设计感兴趣, ZeroMQ chat 的例子就是以 "distributed broker" 架构实现的, 你可以在tutorial章节查看.
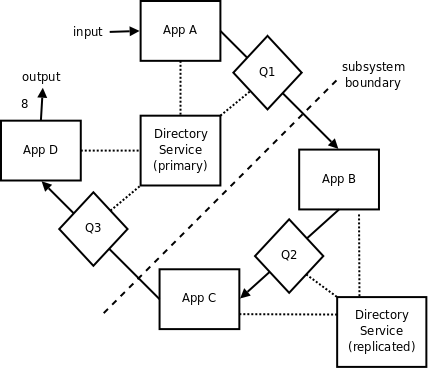
Distributed directory service
在部分生产环境中, 要尽可能避免"一颗老鼠屎坏了一锅汤". 换句话说, 如果(一个业务系统中的)一个子系统异常了或挂掉了, 那么(该业务系统中的)其他子系统应该保持正常运作. 对于上文所说的模型(distributed broker), 虽然我们做到了分布式消息队列(distributed message-wise), 但是上述模型的各个节点配置信息仍然和处于系统中心的目录访问服务(地址路由)息息相关(需要向核心服务查询以获取路由关系), 一旦目录访问服务异常或挂掉, 那么整个系统便一起挂掉了.
为了解决这个问题, 我们需要用到分布式目录访问服务(distributed directory service). 最先简单的例子就是生产流水线(production line) : 在开发过程中, 开发者仍然采用集中式目录访问服务(centralised directory service), 无需考虑单个节点的异常处理, 当系统开发完毕, 准备部署上线时, 把相关配置信息都拷贝一份并配置在系统中的每一个节点里(每一个app)即可(类似git, 每台PC只要pull了最新的代码, 都有一份备份).
这种解决方案的思想是 : 一旦系统部署完成, 整个系统的业务流程相关的网络拓扑结构就固定下来了, 这样任何(对单个app的)配置都不会(对其他app)咋成影响.
下图展示了上述的架构 (小方块代表了配置信息的备份):

尽管如此, 在大多数生产环境, 既要求"多活"(no single point of failure)也要求能够动态的配置网络拓扑关系(路由表). 就比如大型商业银行系统, 单个节点异常(路由服务)不能导致整个银行系统瘫痪, 同时, 单个业务下架, 也不应该导致整个业务线都无法正常工作(即拓扑关系变化了 X --> Y --> Z 变成了 X --> Z). 另一方面, 银行系统的网络拓扑结构也在不断演变, 诸如服务器升级, 软件迭代, 网络组织结构更新等.
考虑到这些因素, LDAP服务或许是可供参考的例子, 且该例已在某些银行中有应用. LDAP服务的思想是, 即使某业务已经下架, 该业务对应的路由配置仍然是可达的, 这种操作通过在该节点复制一个LDAP server来实现(这个架构译者没有看很明白, 纠结的话可以去原帖看一下). 下图展示了该架构的大致逻辑:
PS : 最后还有一段总结, 主要是宣传了一下ZeroMQ, 有兴趣可以去原帖看, 没有特别的技术内容, 这里就不翻译了
