hadoop入门
hadoop入门(面试需要)
MapReduce简介:(参考)
- MapReduce是一种分布式计算模型,主要应用于搜索领域,解决海量数据的计算问题。
- 有两个阶段map(),reduce(),实现这两个阶段即可实现分布式计算。
MapReduce执行过程:

MapReduce原理:
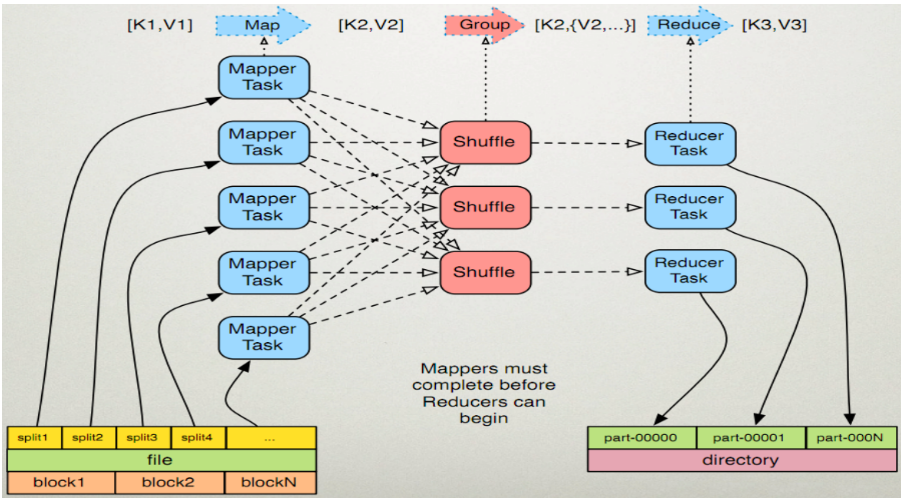
MapReduce执行步骤:
map过程
- 读取hdfs中的文件,逐行解析成key-value键值对,并对每个key-value键值对调用一次map函数。
eg.<hadoop hello \n hadoop bigdata>====》<1,hadoop hello><2,hadoop bigdata> - 覆盖上一次的map(),对执行的结果(<k,v>)继续进行处理,转换成新的<k,v>
eg.<hadoop,1><hello,1><hadoop,1><bigdata,1> - 对输出的<k,v>进行分区,默认分为一个区(partitioner)
- 对不同分区中的数据进行排序(按照k)、分组。分组指的是相同key的value放到一个集合中。
排序后:<bigdata,1> <hadoop,1> <hadoop,1> <hello,1> 分组后:<bigdata,{1}><hadoop,{1,1}><hello,{1}> - 对分组后的数据进行规约(可有)
combiner
- 每一个map可能会产生大量的输出,combiner的作用就是在map端对输出先做一次合并,以减少传输到reducer的数据量。
- combiner最基本是实现本地key的归并,combiner具有类似本地的reduce功能。 如果不用combiner,那么,所有的结果都是reduce完成,效率会相对低下。使用combiner,先完成的map会在本地聚合,提升速度。
- 注意:Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。所以从我的想法来看,Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。
为什么使用Combiner?Combiner发生在Map端,对数据进行规约处理,数据量变小了,传送到reduce端的数据量变小了,传输时间变短,作业的整体时间变短。为什么Combiner不作为MR运行的标配,而是可选步骤呢?因为不是所有的算法都适合使用Combiner处理,例如求平均数。Combiner本身已经执行了reduce操作,为什么在Reducer阶段还要执行reduce操作呢?combiner操作发生在map端的,处理一个任务所接收的文件中的数据,不能跨map任务执行;只有reduce可以接收多个map任务处理的数据。
Reduce过程
- 多个map任务的输出,按照不同的分区,通过网络将输出复制到不同的节点上,shuffle过程
- 对多个map的输出进行合并,排序。覆盖Reduce函数,接收的是分组后的数组,实现自己的业务逻辑。
<bigdata,1><hadoop,2><hello,1> - 将Reduce产生的结果输出到hdfs中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号