
爬取B站用户资料
点击这两个url,你会发现b站不同用户主页只有最后面的那个数字是不同的,我试了下大概有5亿多注册的,我们来获取他的关注,粉丝,获赞,播放这类基本信息
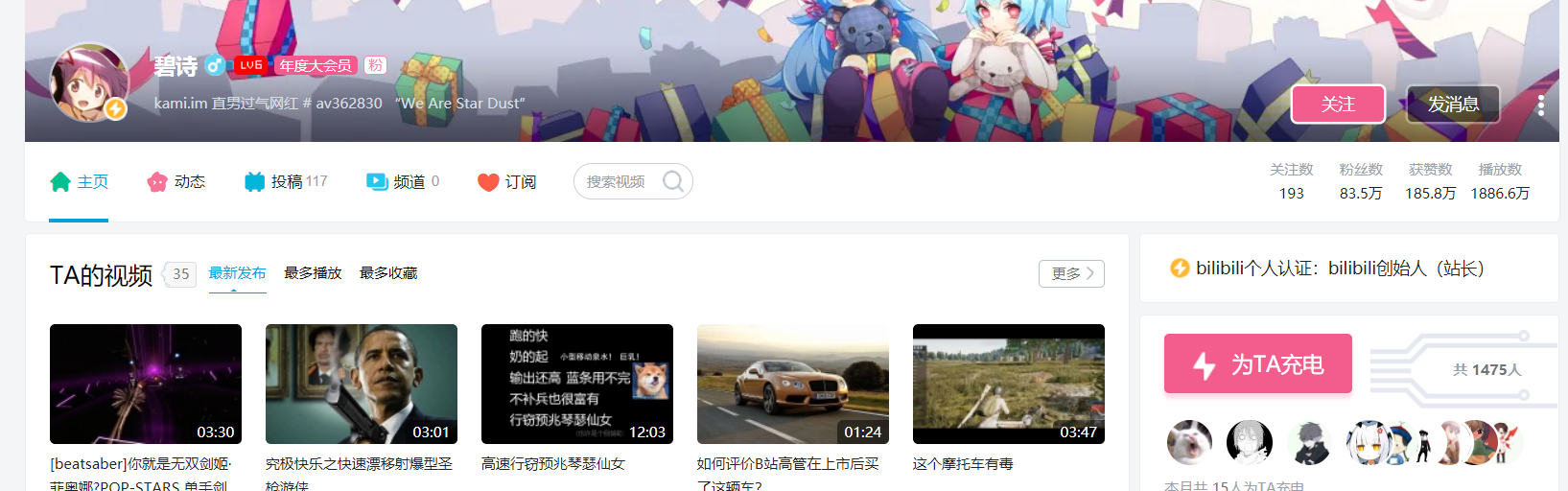
第一步请求该url
1 url = 'https://space.bilibili.com/1' 2 html = requests.get(url,headers) 3 print(html.text)
结果它给我们返回了以下这个结果,表示我们想要的数据不在这里,所以我们切换到network下刷新开始找我们要的数据
最后我找到了对应数据


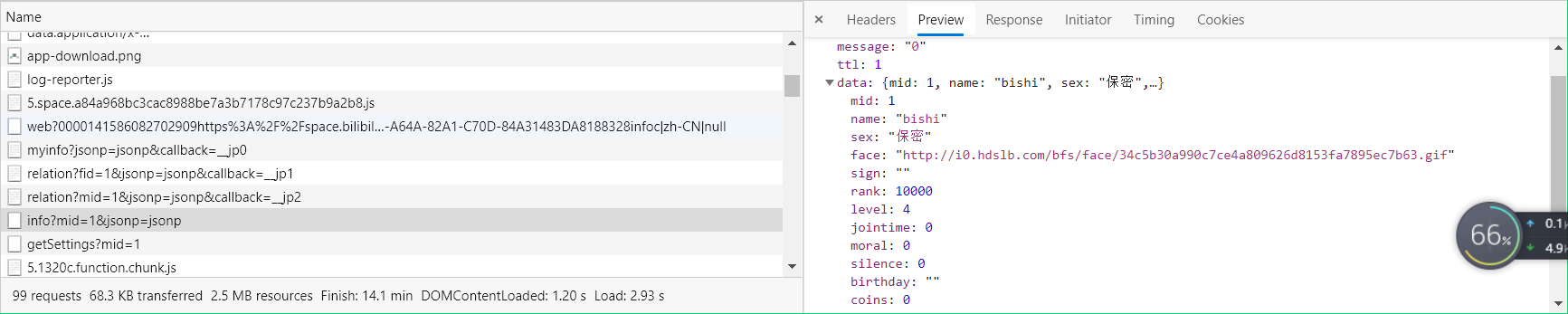
好了这样就可以开始编写代码了,接下来就用json.loads()一个一个解析,然后获取到数据就行了
这里我说一个雷区,请求b站最后在headers里把refer这个参数带上,不然可能会出错
代码如下:

1 import requests 2 import json,threading 3 import os,time 4 from xlrd import open_workbook 5 from xlutils.copy import copy 6 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36 Edg/80.0.361.69' 7 ,'Referer': 'https://space.bilibili.com/1' 8 } 9 #获取基本信息 10 def get_data(url): 11 data = requests.get(url,headers=headers).json() 12 json_data = data['data'] 13 vip = json_data['vip']['type'] 14 name = json_data['name'] 15 sex = json_data['sex'] 16 sign = json_data['sign'] 17 level = json_data['level'] 18 birthday = json_data['birthday'] 19 coins = json_data['coins'] 20 face = json_data['face'] 21 print(name,sex,level) 22 # excel_paper.write(n, 0, name) 23 # excel_paper.write(n, 1, sex) 24 # excel_paper.write(n, 2, level) 25 # #excel_paper.write(n, 3, coins)爬不到 26 # excel_paper.write(n, 4, vip) 27 28 #获取粉丝数和关注数 29 def get_fans(url): 30 html = requests.get(url,headers=headers) 31 html_text = html.text 32 start = html_text.find('{"code":0') 33 end = html_text.find('r":69924}}') 34 json_data= json.loads(html_text[start:end]) 35 data = json_data['data'] 36 following = data['following'] 37 follower = data['follower'] 38 excel_paper.write(n, 5, following) 39 excel_paper.write(n, 6, follower) 40 #获取视频播放数和获赞数 41 def get_achieve(url): 42 html = requests.get(url,headers=headers) 43 html_text = html.text 44 start = html_text.find('{"code":0,') 45 end = html_text.find('s":28112}}') 46 json_data = json.loads(html_text[start:end])['data'] 47 view = json_data['archive']['view'] 48 likes = json_data['likes'] 49 excel_paper.write(n, 7, view) 50 excel_paper.write(n, 8, likes) 51 52 def download(face,name): 53 if not os.path.exists('B站用户头像'): 54 os.mkdir('B站用户头像') 55 url = face 56 image = requests.get(url).content 57 with open("B站用户头像/{}.jpg".format(name),'wb') as f: 58 f.write(image) 59 print("正在下载图片") 60 61 62 url = 'https://api.bilibili.com/x/space/acc/info?mid=2&jsonp=jsonp' 63 get_data(url) 64 65 if __name__ == '__main__': 66 print("start:",time.time()) 67 r_excel = open_workbook("b站用户信息.xls") 68 excel = copy(r_excel) 69 excel_paper = excel.get_sheet(0) 70 n = 14101 71 for i in range(14101,15000): 72 # 用户信息 73 print(i) 74 url = 'https://api.bilibili.com/x/space/acc/info?mid={}&jsonp=jsonp'.format(i) 75 #粉丝和关注信息 76 url2 = 'https://api.bilibili.com/x/relation/stat?vmid={}&jsonp=jsonp&callback=__jp3'.format(i) 77 #成就信息 78 url3 = 'https://api.bilibili.com/x/space/upstat?mid={}&jsonp=jsonp&callback=__jp4'.format(i) 79 thr1 = threading.Thread(target=get_data,args=(url,)) 80 thr2 = threading.Thread(target=get_fans,args=(url2,)) 81 thr3 = threading.Thread(target=get_achieve, args=(url3,)) 82 thr1.start() 83 thr2.start() 84 thr3.start() 85 thr1.join() 86 thr2.join() 87 thr3.join() 88 n += 1 89 excel.save("b站用户信息.xls") 90 print("end:",time.time())
爬取的速度很慢,因为还不懂多线程,大概半个小时可以爬1万条,期间被封了一次。
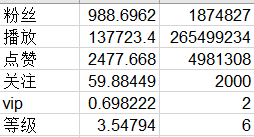
这个是前15000用户的各个平均值和最大值
keep real ,stay hungry ,and dream future
本文作者:TrueDZ
本文链接:https://www.cnblogs.com/Truedragon/p/12683983.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步