集英社-富硒土壤对茶叶品质影响 调查报告
谨以此文,悼念我炸裂的计应数期中考试。下次不仅要带一个脑子做题,还得带一个脑子盯着它做题,不然第一个脑子容易跑偏刹不住车。得去黑市看一眼最近脑子市价如何,如果太贵还得卖点东西凑一凑。
简介:你说的对,但是「集英社」是「茶园」自主研发的一款全新开放问题探究项目。课题发生在一个被称作「六教-A016」的演播教室,在这里,被姚选中的人将被授予「指数级别作业」,导引「复分析」之力。你将扮演一位名为「学生」的神秘角色,在自由的「授课」中邂逅参数各异、能力独特的「公式」们,用它们一起研究开放问题,找回失散的大脑——同时,逐步发掘「挂科」的真相。
Section 1.课堂内容总结
Week 1.
Probability Space \(P=(U,p)\) 是用来描述随机事件的工具,其中 \(U\) 被称作 universe,\(p\) 是 probability function。
event 是 \(U\) 的一个子集。
Union Bound Formula:令事件 \(T,T_1,\dots\),且 \(T\sube\bigcup T_i\),则 \(\Pr(T)\leq\sum\Pr(T_i)\);如果 \(T_i\) 构成 \(T\) 的一组划分,则有 \(\Pr(T)=\sum\Pr(T_i)\)。
Conditional Probability \(\Pr(S|T)=\dfrac{\Pr(S\cap T)}{\Pr(T)}\)。特别地,如果 \(\Pr(T)=0\) 那么条件概率为零。
Chain Law of Conditional Probability \(\Pr(S_1\cap S_2\cap\dots)=\prod\Pr(S_i\mid S_1\cap S_2\cap\dots\cap S_{i-1})\)。
Law of total probability:如果 \(T\sube\bigcup T_i\),则 \(\Pr(T)\leq\sum\Pr(T_i)\Pr(T|T_i)\)。如果 \(T_i\) 不交则取等号。
常用的处理 \(\prod(1+x)\),其中 \(x\) 接近 \(0\) 的方法是,放缩为 \(\prod e^x\)。
Week 2.
Random Variable \(X\) 是 \(U\to\R\) 的映射。event 可以被看作是 \(U\to\{0,1\}\) 的一种特殊概率。期望是概率与权值之积的和。
Law of Linear Expectation。概率具有线性性,就算不同事件间彼此并非独立。
Distributive Law for Expectation:若 \(T_i\) 构成 \(U\) 的划分,则 \(E(X)=\sum\Pr(W_i)E(X|W_i)\)。
Markov's Inequality:对于定义在非负集合 \(U\) 上的随机变量 \(X\),\(\Pr(X>cE(X))<\dfrac1c\)。
Chebyshev's Inequality:\(\Pr(|X-E(X)|>c\sigma(X))<\dfrac1{c^2}\)。或者,\(\Pr(|X-E(X)|>c)<\dfrac{V(X)}{c^2}\)。
Chernoff Bound:对于独立的掷硬币实验 \(X_1,\dots,X_n\),第 \(i\) 次以 \(b_i\) 的概率取 \(1\),\(1-b_i\) 取 \(0\),则 \(\Pr(X\geq(1+\delta)\mu)\leq\left(\dfrac{e^\delta}{(1+\delta)^{1+\delta}}\right)^\mu\)。\(\Pr(X\leq(1-\delta)\mu)\leq\left(\dfrac{e^{-\delta}}{(1-\delta)^{1-\delta}}\right)^\mu\)。同时有推论:\(\Pr(X\geq(1+\delta)\mu)\leq e^{-1/3\delta^2\mu}\),\(\Pr(X\leq(1-\delta)\mu)\leq e^{-1/2\delta^2\mu}\)。
Chernoff Bound 仅适用于重复抛硬币问题,但并非所有问题都能通过重复抛硬币描述。在更广泛的场合,我们有如下的:
Hoeffding's Inequality:对于 \(X_i\in(a,b)\),有 \(\Pr(|\sum X_i-E(X_i)|\geq t)\leq2\exp(\dfrac{-2t^2}{n(b-a)^2})\)。在其不同分布时,也有 \(\Pr(|\sum X_i-E(X_i)|\geq t)\leq2\exp(\dfrac{-2t^2}{\sum(b_i-a_i)^2})\)。事实上,如果把内层的绝对值撤掉,那么右侧外部的 \(2\) 亦可撤掉。
Week 3.
要证明一个东西的级别,一个通用的想法是,用 Union Bound 证下界,用 Chebyshev's Inequality 证上界。但是 Chebyshev 需要算方差。
例如,Ramsay Number 枚举所有的 \(K\)-子集并计算其成团/独立集概率并求和,当 \(n\) 充分小时求和得到的值小于 \(1\),因此必然存在所有子集均不合法的概率。同理,随机图最大团的下界也是用 Union Bound 证。随机图最大团贪心算法的下界同理。
上界的话,Ramsay Number 是证了递推关系 \(R(s,t)\leq R(s-1,t)+R(s,t-1)\),而随机图最大团则是 Chebyshev's Inequality,但是 Variance 很难证(也没办法)。随机图最大团贪心算法也是。
Randomized BSA:\(i\) 要送到 \(v_i\)。算法是随机一组 \(\sigma(i)\),先送到 \(\sigma\) 再送到 \(v\)。每步以 \(1-o(1)\) 的概率在 \(6n\) 内达成。
Week 4.
-
Cauchy-Goursat 基本定理:若 \(f(z)\) 在简单闭曲线 \(C\) 及其围成区域内处处解析,那么 \(f(z)\) 沿 \(C\) 积分为零,也即 \(\oint_Cf(z)\d z=0\)。【注意:要求是简单、且自身及围成的区域处处解析)
-
直接推论:单连通域内处处解析函数沿任意简单闭曲线积分为零。
-
进一步推广至多连通域,得到 复合闭路定理:令 \(C\) 是多联通域 \(D\) 中简单闭曲线,\(C_1,\dots,C_k\) 是 \(C\) 内部两两不交、不互相包含的曲线集合,且有 \(C,C_1,\dots,C_k\) 所夹区域被完全包含于多连通域内(也即,\(C_1,\dots,C_k\) 从多连通域内“挖掉”了若干不属于多连通域的部分),则对于在 \(D\) 中解析的 \(f\),那么:
- \(\oint_Cf(z)\d z=\sum\oint_{C_i}f(z)\d z\),其中所有曲线均取(自然)正向。
- \(\oint_\Gamma f(z)\d z=0\),其中 \(\Gamma\) 指取正向的 \(C\) 和取负向的 \(C_1,\dots,C_k\)。
-
同时又有推论 闭路变形原理:解析函数沿闭曲线积分不因闭曲线的连续变形而改变值,只要闭曲线的变形不经过奇点。
-
\(\dfrac{f(z)}{z-z_0}\) 在 \(z_0\) 可能不解析;但是可以通过不断向 \(z_0\) 缩小,让 \(f(z)\) 的值逐渐接近 \(f(z_0)\),\(\oint_C\dfrac{f(z)}{z-z_0}\d z\) 接近 \(\oint_C\dfrac{f(z_0)}{z-z_0}\d z\);后者因为 \(\oint_C\dfrac1{z-z_0}\d z\) 可以连续变形为套着 \(z_0\) 的圆,而这个圆上 \(\dfrac1{z-z_0}\) 的积分前面提到过是 \(2\pi\i\),因此这个值有接近 \(f(z_0)2\pi\i\) 的期望。
-
事实上,有 Cauchy 积分公式:在区域 \(D\) 内处处解析的 \(f\),内部完全含于 \(D\) 的 \(C\),\(C\) 内部任一点 \(z_0\),有 \(f(z_0)=\dfrac1{2\pi\i}\oint_C\dfrac{f(z)}{z-z_0}\d z\)。通过 \(\epsilon-\delta\) 语言可证得。
-
取 \(C\) 为套着 \(z_0\) 的圆周,得到 \(f(z_0)=\dfrac1{2\pi}\int_0^{2\pi}f(z_0+Re^{i\pi})\d\theta\),也即,解析函数在圆心处的值等于其在圆周上的平均。
-
解析函数的导数仍为解析函数,事实上解析函数 \(\in\scr C^\infty\),且 \(f^{(n)}(z)=\dfrac{n!}{2\pi i}\oint_C\dfrac{f(\xi)}{(\xi-z)^{n+1}}\d\xi\)(高阶导数公式),其中 \(C\) 是任一环绕 \(z\) 的正向简单闭曲线,其内部全含于 \(D\)。证明就靠嗯归纳。Cauchy 积分公式是高阶导数公式 \(n=0\) 时的特例。
-
虽然其是通过积分来表示导数,不过最常见的应用还是通过高阶导数来算环路积分。
-
Cauchy 不等式:\(|f^{(n)}(z_0)|\leq\dfrac{n!M(R)}{R^n}\),其中 \(M(R)\) 是以 \(z_0\) 为圆心的 \(R\)-圆周上 \(|f(z)|\) 的 \(\max\)。
-
解析函数的 Laurent 展开定理:设 \(f(z)\) 在圆环域 \(R_1<|z-z_0|<R_1\) 内解析,则在圆环域内 \(f\) 必可以唯一展成双边幂级数 \(f(z)=\sum c_n(z-z_0)^n\),其中 \(c_n=\dfrac1{2\pi\i}\oint_C\dfrac{f(\xi)}{(\xi-z_0)^{n+1}}\d\xi\),其中 \(C\) 是环绕 \(z_0\) 的任一正向简单闭曲线。这个双边幂级数被称作 Laurent 级数,正幂项部分被称作 解析部分,负幂项部分被称作 主要部分。
-
称 \(z_0\) 是一个 极点
pole,如果其主要部分有有限项;其主要部分的最高(?)项次数如果是 \(-n\),则称其是一个 \(n\) 阶奇点,或者是a pole of order n。其主要部分中负一次项系数被称作 留数residue。 -
\(n\) 阶零点,如果其解析,并且可以写成 \((z-z_0)^m\varphi(z)\),且 \(\varphi(z_0)\neq0\)。
-
\(f\) 有 \(n\) 阶极点是 \(\dfrac1f\) 有 \(n\) 阶零点的充要条件。
-
留数定理:对于 \(m\) 阶极点 \(z_0\),\(\text{Res}(f,z_0)=\dfrac1{(m-1)!}\lim\limits_{z\to z_0}\dfrac{\d^{m-1}}{\d z^{m-1}}((z-z_0)^mf(z))\)。
-
无穷远处留数的定义是 \(\dfrac1{2\pi i}\int_{C^-}f(z)\d z\),其中 \(C^-\) 是绕原点负向,即为绕无穷远正向。此时,得到结论:如果包含无穷远极点在内仅有有限个极点,且极点都是孤立极点,那么所有留数和为零。
-
\(\text{Res}(f,\infty)=-\text{Res}(f(z^{-1})z^{-2},0)\)。算内极点的留数可以转为算外极点的留数。
矩阵树定理。证明可以使用 Cauchy-Binet,也可以容斥,即钦定根后随机选邻边为父亲然后容斥环。
另有 \(\#SP=\dfrac1n\lambda_2\dots\lambda_n\),其中 \(\lambda_1=0\)。这是因为,\(\prod(\lambda-\lambda_i)=\det(\lambda I-L_G)'=(-1)^{n-1}\sum\det\left(L_G^{(i)}(\lambda)\right)\)。代入 \(\lambda=0\),得到 \((-1)^{n-1}\prod\lambda_i=(-1)^{n-1}n\#SP\).
Week 5.
FKT 算法。
对于反对称矩阵,定义 \(\text{Pf}=\sum\limits_\sigma\text{sgn}(\sigma)\prod A_{\sigma_{2i-1},\sigma_{2i}}\)。
考虑任两个 Pfaffian 中元素 \(M_1,M_2\),其中的边拼起来拼成一组排列的 cycle 形式。因此 \(\det=\text{Pf}^2\)。
Pfaffian 中元素如果被恰当定向,使得所有的完美匹配的 \(\text{sgn}\) 都同号,则直接对行列式开根即得 Pfaffian 的绝对值,也即完美匹配数目。使得每个面上顺时针边数目都是偶数即可。
算法是随机生成树并定向,然后定向其它东西。
Pfaffian 除了被用于平面图完美匹配计数,亦可判定任意图是否存在完美匹配(用 Schwartz-Zippel 定理),乃至解决尚无确定性解法的恰出现 \(K\) 条红边的完美匹配计数(引入额外元 \(y\))
还是记一下 Schwartz-Zippel 定理吧。对于元数任意,但是次数不超过 \(d\) 的多项式,任意在有限集 \(S\) 中赋值并赋到根的概率是 \(d/|S|\)。证明关于元数归纳。
Week 6.
复杂度概念。
L:\(\text{polylog}(n)\) 空间 可解。
PSPACE:\(\text{poly}(n)\) 空间 可解。
EXP:\(2^{\text{poly}(n)}\) 时间 可解。
BPP:以一个恒概率出错(即,原本有解被判无解)。不断重复可以让出错概率趋于零。
\(L\sube P\sube NP\sube PSPACE\sube EXP\)。
NP-Hard:所有 NP 都可以规约到的问题。
NP-Complete:同时是 NP-Hard 和 NP。
如果一个 NPC 问题可以规约到另一个 NP 问题,则该问题亦是 NPC 的。
Section 2.[Wasserman] 书上内容总结
Chapter 1.
两个变量独立有着 \(A\amalg B\) \amalg 的奇怪符号;不独立则有着 \(A\operatorname{一圈奇怪的弹簧符号}B\) 的写法。
Bayes 公式:对于 \(U\) 的划分 \(T\),\(\Pr(T_i|B)=\dfrac{\Pr(B|T_i)\Pr(T_i)}{\sum\Pr(B|T_j)\Pr(T_j)}\)。其中,分母其实是 \(\Pr(B)\),分子其实是 \(\Pr(B\cap T_i)\)。
Chapter 2.
对于随机变量 \(X\),其大写 \(F_X(x)=\Pr(X\leq x)\),被称作 cumulative distribution function 或者 CDF。其是 \(\R\to[0,1]\) 的函数,不论离散的 \(X\) 还是连续的 \(X\) 都有如此定义。
一切非降、正则(在负无穷处趋于 \(0\),正无穷处趋于 \(1\))、右连续的函数都可以是某个随机变量的 CDF。
离散型随机变量是仅能取到可数个取值的随机变量。离散变量可以定义 probability function 或 probability mass function \(f_X=\Pr(X=x)\)。
连续性随机变量是存在全积分为 \(1\) 的函数 \(f_X\) 且满足 \(\Pr(a<X<b)=\int_a^bf_X(x)\d x\) 的随机变量。\(f_X\) 被称作 probability density function,且在所有 \(F_X\) 可微处均有 \(f_X(x)=F'_X(x)\)。
inverse CDF 或者 quantile function \(F^{-1}(q)=\inf\{x:F(x)>q\}\)。如果 \(F\) 单增且连续那么 \(F,F^{-1}\) 互为反函数。可以由此定义各种 first quantile, median, third quantile。
两个 \(F\) 相同的函数被称作 equal in distribution,但并不意味着它们是同一个变量。





marginal mass function 是对二维的 probability mass function 投到一维的结果。同理有 marginal density function。
两个随机变量独立,如果对于一切 \(A,B\),\(\Pr(X\in A,Y\in B)=\Pr(X\in A)\Pr(Y\in B)\)。
对于连续随机变量,如果 \(f(x,y)=g(x)h(y)\)(\(g,h\) 不一定是 PDF)那么 \(X,Y\) 独立。
条件 PMF \(f_{X|Y}(x|y)=\Pr(X=x|Y=y)\)。同理有条件 PDF \(f_{X|Y}(x|y)=\dfrac{f_{X,Y}(x,y)}{f_Y(y)}\)。
称若干随机变量 IID(independend and identically distributed),如果它们独立并且服从于同一组分布 \(F\),记作 \(x_1,\dots,x_n\sim F\)。


如果对于随机变量 \(X\),定义比如说 \(Y=r(X)\),如何计算 \(Y\) 的分布?
求出 \(A_y=\{x|r(x)\leq y\}\),则 \(F_Y(y)=\int_{A_y}f_X(x)\d x\)。
Chapter 3.
期望。expectation 也被叫做 mean 或者 first moment 一阶矩。
期望的懒惰计算(The Rule of Lazy Statistician):若 \(Y=r(X)\),则 \(E(Y)=E(r(X))=\int r(x)\d F_X(x)=\int r(x)f_X(x)\d x\)。
\(K\) 阶矩 Kth moment 为 \(E(X^K)\)。\(K\) 阶矩存在如果该期望对应积分收敛。高阶矩存在则低阶矩必然存在。
期望线性性。如果变量独立则积的期望等于期望的积。
\(V(aX+b)=a^2V(X)\)。独立的 \(X\) 有和的方差等于方差的和。
对于一组随机变量 \(X_1,\dots,X_n\),定义样本均值 sample mean \(\bar X_n=\dfrac1n\sum X_i\),样本方差 sample variance \(S_n^2=\dfrac1{n-1}\sum(X_i-\bar X_i)^2\)。
- 为什么是 \(n-1\)?因为 \(\bar X_n\) 提供了一个自由度。
协方差 covariance \(\text{Cov}(X,Y)=E((X-\mu_X)(Y-\mu_Y))\)。相关系数 correlation \(\rho_{X,Y}=\dfrac{\text{Cov}(X,Y)}{\sigma_X\sigma_Y}\)。
\(-1\leq\rho\leq1\)。如果 \(Y=aX+b\)(前提是 \(a\neq0\)),那么当 \(a>0\) 时 \(\rho=1\),\(a<0\) 时 \(\rho=-1\)。独立变量的协方差与相关系数均为零,但是反之不亦然。

随机向量 \(\begin{bmatrix}X_1\\\vdots\\X_n\end{bmatrix}\) 的平均值向量为 \(\mu=\begin{bmatrix}\mu_1\\\vdots\\\mu_n\end{bmatrix}\)。方差-协方差矩阵(variance-covariance matrix)\(\Sigma\) 被定义为 \(V(X)=\begin{bmatrix}V(X_1)&\text{Cov}(X_1,X_2)&\dots\\\text{Cov}(X_2,X_1)&V(X_2)&\dots\\\vdots&\vdots&\ddots\end{bmatrix}\)。
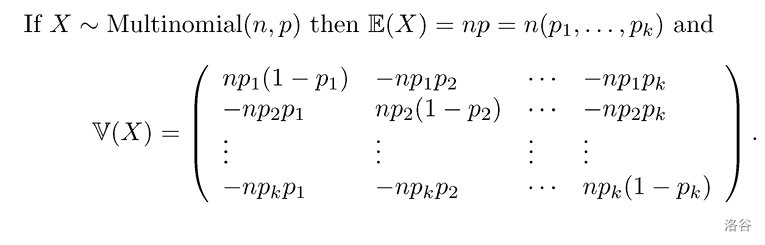
条件期望 \(E(X|Y=y)\) 是关于 \(y\) 的函数。
The Rule of Iterated Expectations:\(E(E(Y|X))=E(Y),E(E(X|Y))=E(X)\)。事实上,\(E(E(r(X,Y)|X))=E(E(r(X,Y)|Y))=E(r(X,Y))\)。
条件方差 \(V(X|Y=y)\) 亦是关于 \(y\) 的函数。\(V(X|Y=y)=\int(x-\mu(X|Y=y))^2f(x|y)\d x\)。
\(V(Y)=EV(Y|X)+VE(Y|X)\)。
矩量生成函数 Moment Generating Function, MGF,或称为 Laplace 变换 Laplace Transform,满足 \(\psi_X(t)=E(e^{tX})=\int e^{tx}\d F(x)=\int e^{tx}f(x)\d x\)。我们希望,MGF 在 \(0\) 的邻域中有定义。这样,便可得到 \(\psi'(0)=E(X)\)。事实上,\(\psi^{(k)}(0)=E(X^k)\)。
当变量彼此独立时,MGF 的积等于 和 的 MGF。
若 \(Y=aX+b\),则 \(\psi_Y(t)=e^{bt}\psi_X(at)\)。
如果 \(\psi_X(t)=\psi_Y(t)\) 在 \(0\) 的邻域中相等,则 \(X,Y\) 有相同分布。

特别地,PGF 的一些优秀性质(注意区别 PGF 与 PDF)(注意区分 PGF 与 MGF):
- \(p(1)=1\)。
- \(p'(1)=E(X)\)。
- \(p''(1)+p'(1)-p'(1)^2=V(X)\)。
Chapter 4.
另一种 Hoeffding's Inequality 的表述:
对于独立随机变量 \(Y_1,\dots,Y_n\),且每个变量的期望均为 \(0\),且满足 \(a_i\leq Y\leq b_i\)。令一个 \(\epsilon>0\),则对于一切 \(t>0\),都有 \(\Pr(\sum Y_i\geq\epsilon)\leq e^{-t\epsilon}\prod\exp(t^2(b_i-a_i)^2/8)\)。
Mill's Inequality:对于 \(Z\sim N(0,1)\),则 \(\Pr(|Z|>t)\leq\sqrt{\dfrac2\pi}\dfrac{e^{-t^2/2}}t\)。
Cauchy-Schwarz Inequality:对于方差有限的变量 \(X,Y\),\(E|XY|\leq\sqrt{E(X^2)E(Y^2)}\)。
Jensen's Inequality:对于凸的 \(g\),\(E(g(X))\geq g(E(X))\)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号