Python爬虫学习笔记之模拟登陆并爬去GitHub
(1)环境准备:
请确保已经安装了requests和lxml库
(2)分析登陆过程:
首先要分析登陆的过程,需要探究后台的登陆请求是怎样发送的,登陆之后又有怎样的处理过程。
如果已经登陆GitHub,则需要先退出登陆,同时清除Cookies
打开GitHub的登陆页面,链接为https://github.com/login,输入GitHub的用户名和密码,打开开发者工具
,将Preserver Log选项勾选上,这表示持续日志,如下图所示
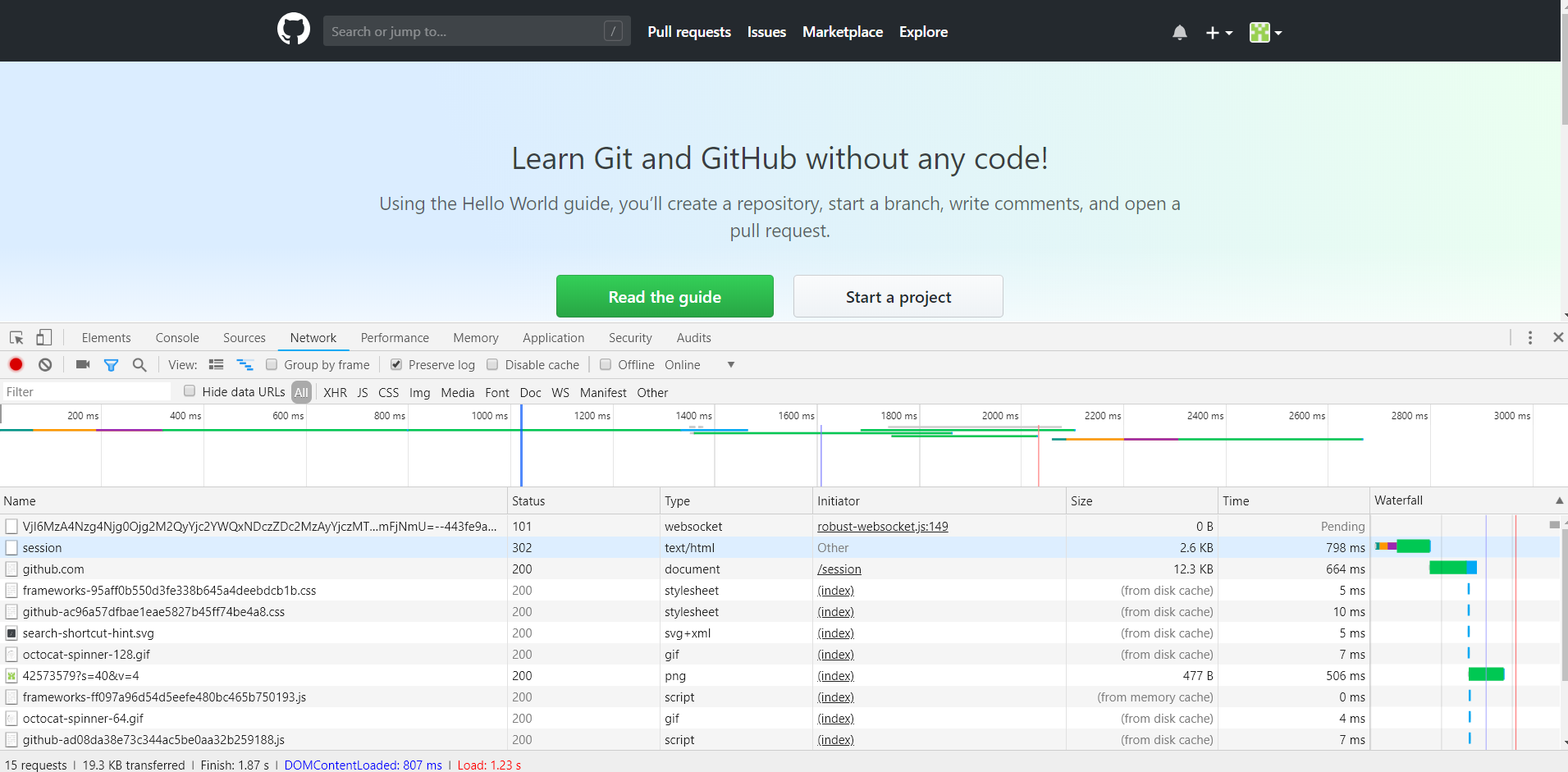
点击登录按钮,这时便会看到开发者工具下方显示了各个请求过程,如下图所示:
点击session请求,进入其详情,如下图所示:
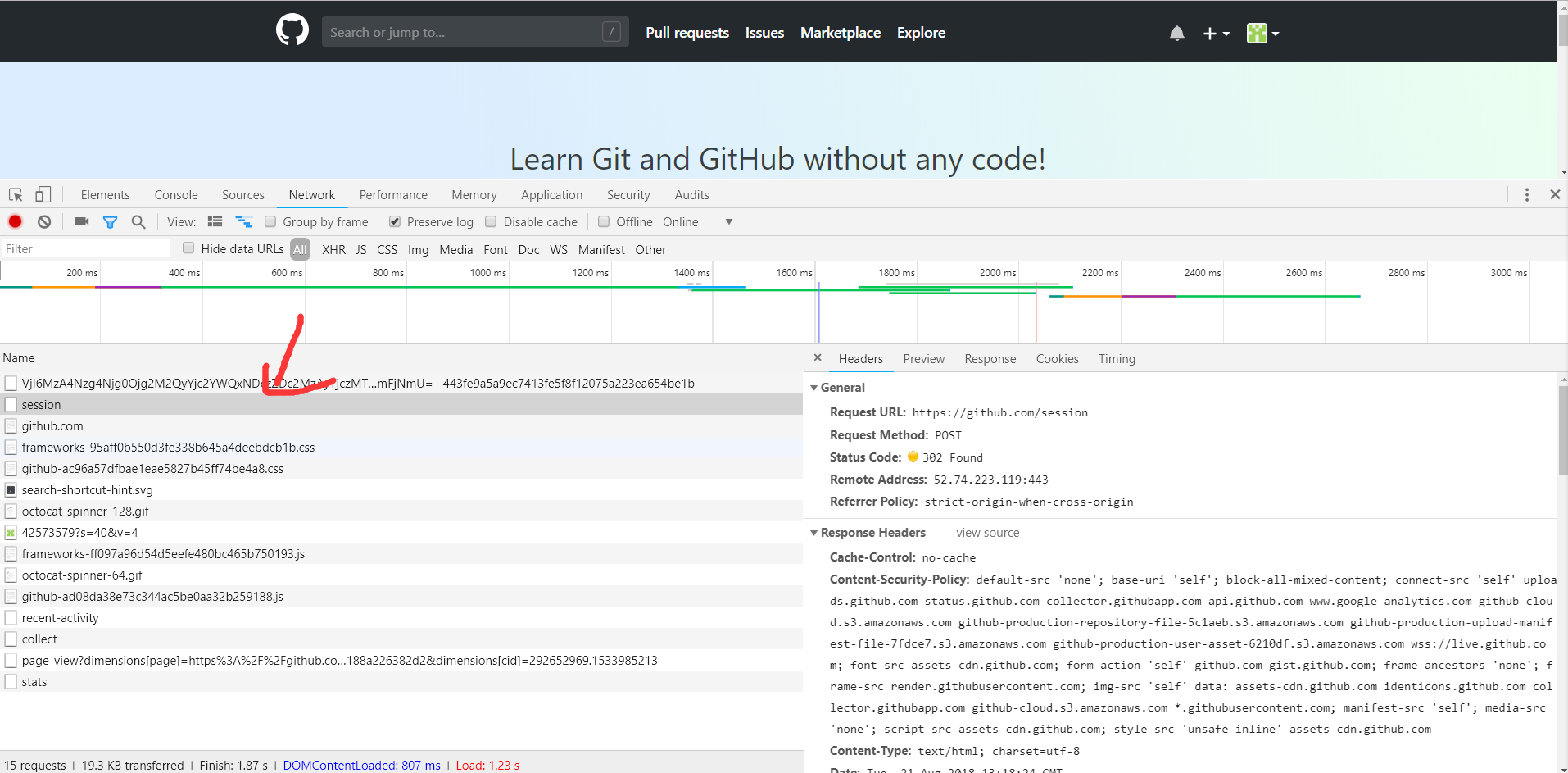
可以看到请求的URL为https://www.github.com/session,请求方式为POST。再往下看,我们观察到他的Form Data和Headers这两部分内容,
如下图所示:
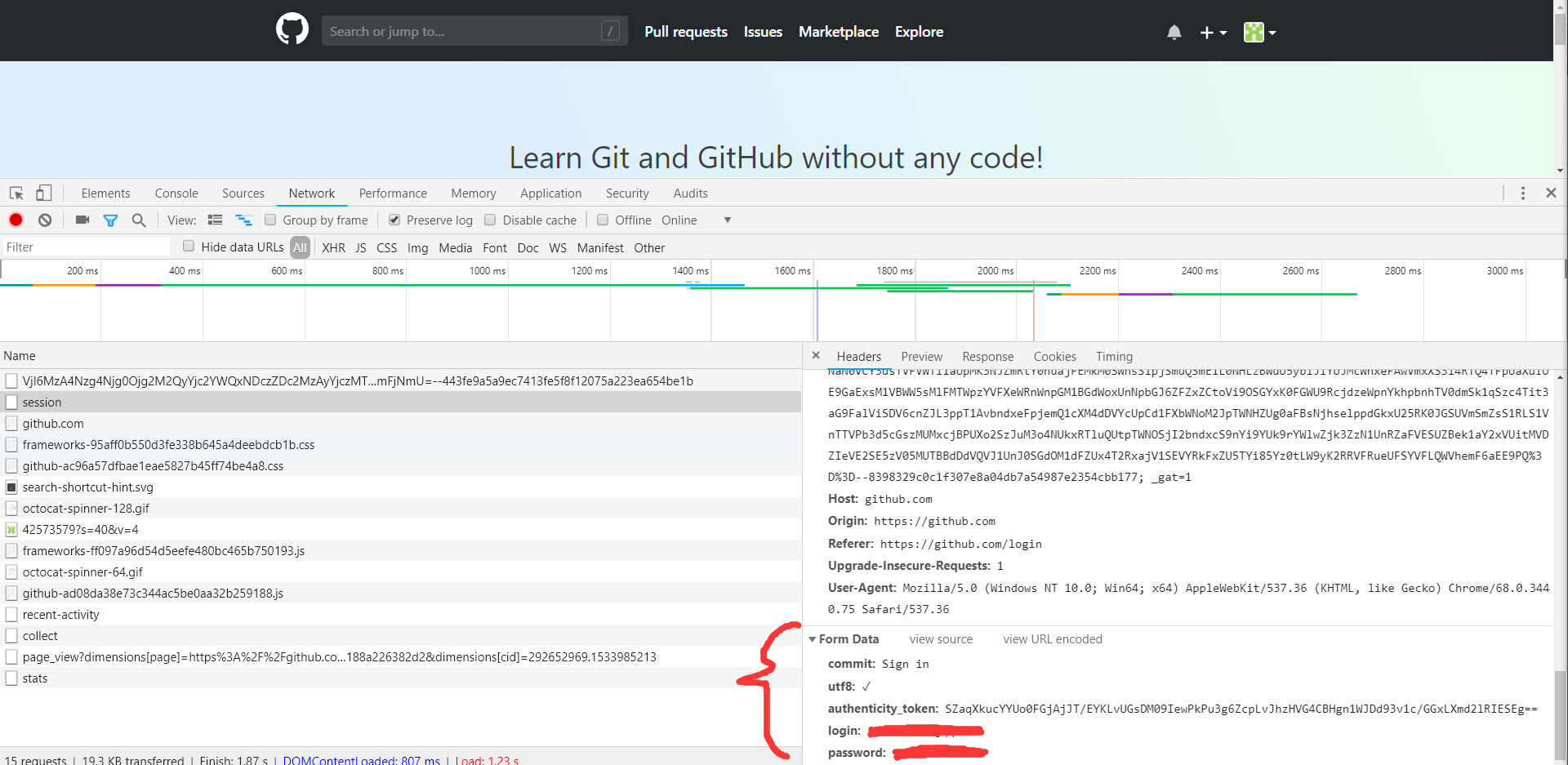
Headers里面包含了Cookies,Host,Origin,Refer,User-Agent等信息。Form Data包含了5个字段,commit是固定的字符串Sign in,utf8
是一个勾选字符,authenticity_token较长,其初步判断是一个Base64加密的字符串,login是登陆的用户名,password是登陆的密码。
综上所述,我们现在无法直接构造的内容有Cookies和authenticity_token。下面我们再来探寻一下这部分内容如何获取。
在登陆之前我们会访问到一个登陆页面,此页面是通过GET形式访问的。输入用户名和密码,点击登录按钮,浏览器发送这两部分信息,也就是
说Cookies和authenticity_token一定在访问扥估页面时候设置的。
这时在退出登陆,回到登录页,同时清除Cookies,重新访问登录页,截获发生的请求,如下图所示:
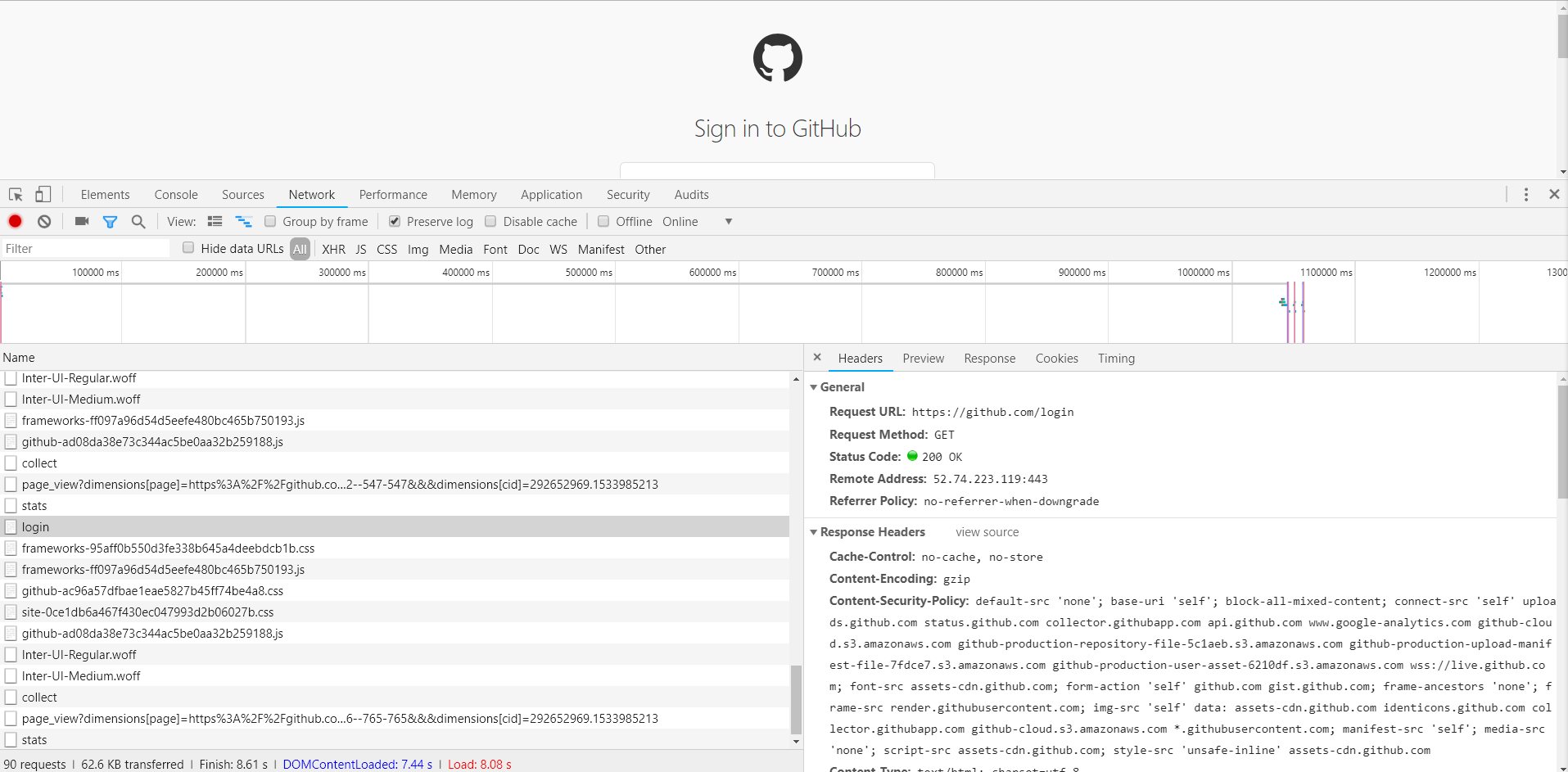
访问登陆页面的请求如上,Response Headers有一个Set-Cookie字段。这就是设置Cookies的过程。
另外,我们发现Response Headers没有和authenticity_token相关的信息,所以可能authenticity_token还隐藏在其他的地方或者是计算出来的
。我们再从网页的源码探寻,搜索相关字段,发现源代码里面还隐藏着此信息,他是一个隐藏式表单元素,如下图所示:
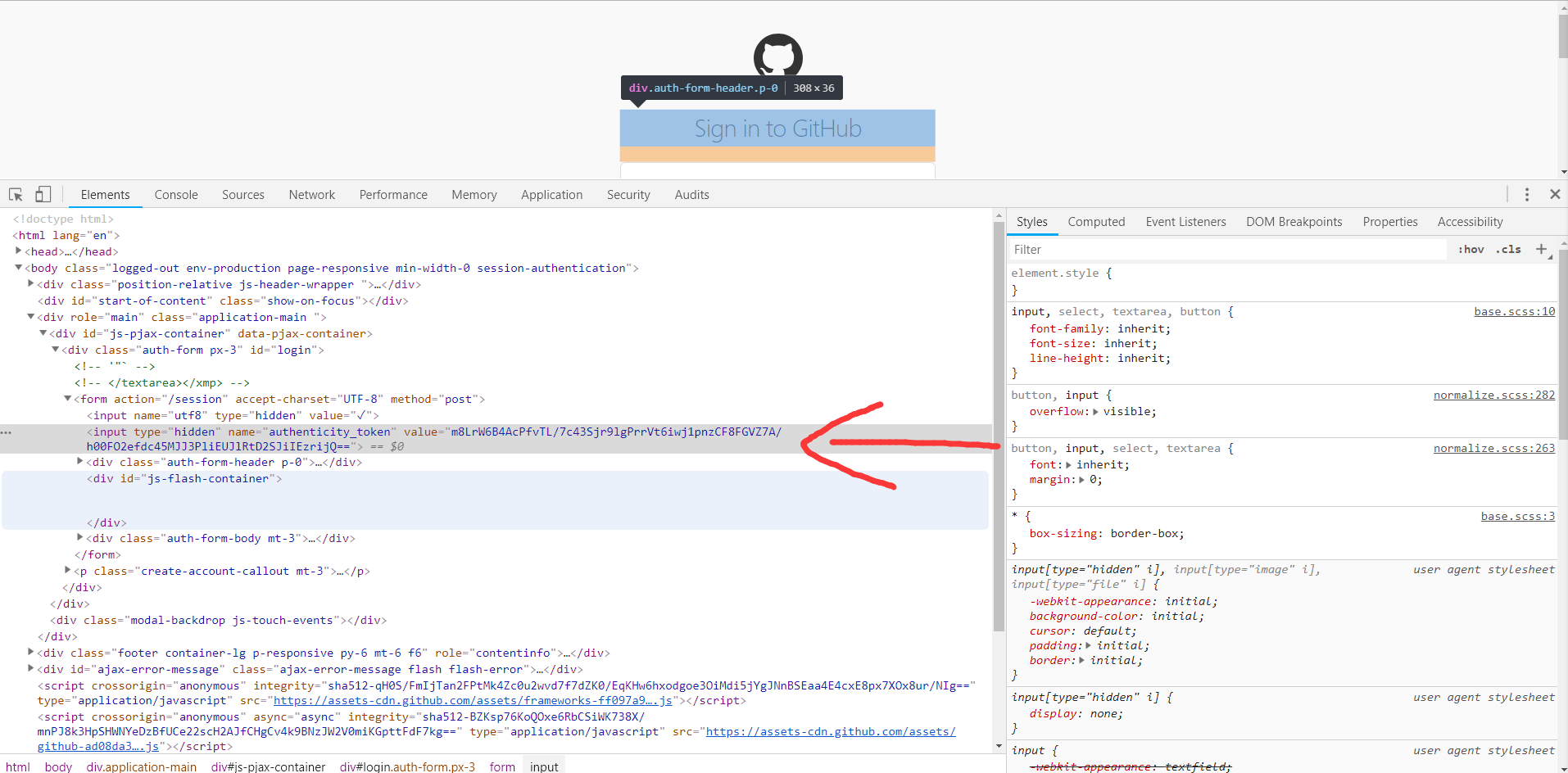
现在我们已经获取到网页所有信息,接下来让我们 实现模拟登陆
(3)代码如下:
1 import requests 2 from lxml import etree 3 4 class Login(object): 5 def __init__(self): 6 self.headers = { 7 'Refer': 'https://github.com', 8 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 9 'Chrome/68.0.3440.75 Safari/537.36', 10 'Host': 'github.com' 11 } 12 self.login_url = 'https://github.com/login' 13 self.post_url = 'https://github.com/session' 14 self.logined_url = 'https://github.com/settings/profile' 15 self.session = requests.Session() # 此函数可以帮助我们维持一个会话,而且可以自动处理cookies,我们不用再去担心cookies的问题 16 17 def token(self): 18 response = self.session.get(self.login_url, headers=self.headers) # 访问GitHub的登录页面 19 selector = etree.HTML(response.text) 20 token = selector.xpath('//div//input[2]/@value')[0] # 解析出登陆所需的authenticity_token信息 21 return token 22 23 def login(self, email, password): 24 post_data = { 25 'commit': 'Sign in', 26 'utf-8': '✓', 27 'authenticity_token': self.token(), 28 'login': email, 29 'password': password 30 } 31 response = self.session.post(self.post_url, data=post_data, headers=self.headers) 32 if response.status_code == 200: 33 self.dynamics(response.text) 34 35 response = self.session.get(self.logined_url, headers=self.headers) 36 if response.status_code == 200: 37 self.profile(response.text) 38 39 def dynamics(self, html): # 使用此方法提取所有动态信息 40 selector = etree.HTML(html) 41 dynamics = selector.xpath('//div[contains(@class, "news")]//div[contains(@class, "alert")]') 42 for item in dynamics: 43 dynamics = ' '.join(item.xpath('.//div[@class="title"]//text()')).strip() 44 print(dynamics) 45 46 def profile(self, html): # 使用此方法提取个人的昵称和绑定的邮箱 47 selector = etree.HTML(html) 48 name = selector.xpath('//input[@id="user_profile_name"]/@value')[0] 49 email = selector.xpath('//select[@id="user_profile_email"]/option[@value!=""]/text()') 50 print(name, email) 51 52 if __name__ == "__main__": 53 login = Login() 54 login.login(email='', password='') # 此处填自己的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号