讲一讲Synchronized 和 volatile?
原子性:
- volatile不保证原子性,特例是保证32位系统中double和long类型
- sychronized保证通过加锁的方式保证原子性,如下图:
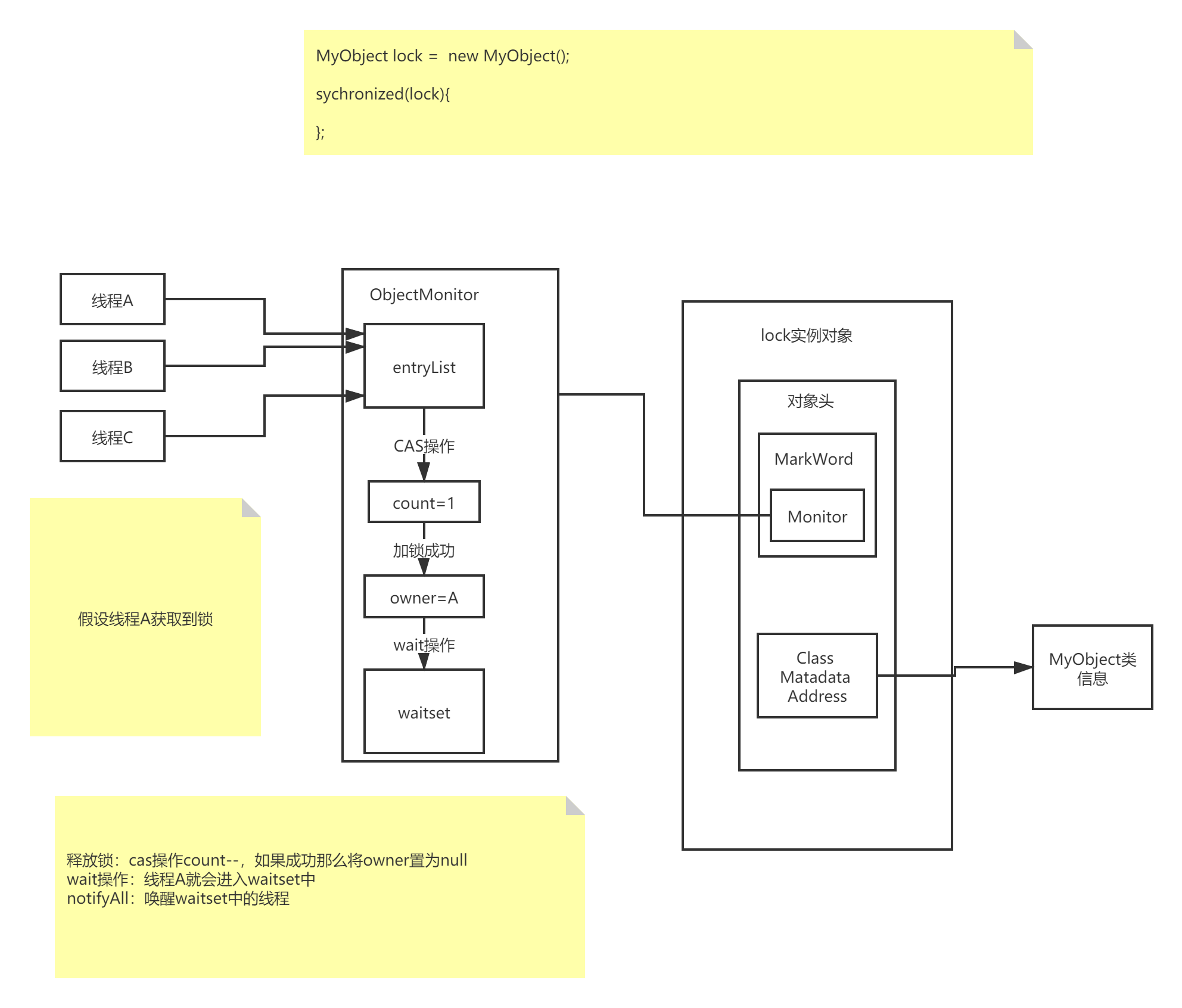
硬件层面:由于计算机的存储设备和处理器的运算速度差距非常大,所以引入了高速缓存来作为内存和处理器之间的缓冲。画一下结构图:其中包含MESI协议和优化引入的写缓冲器和无效队列
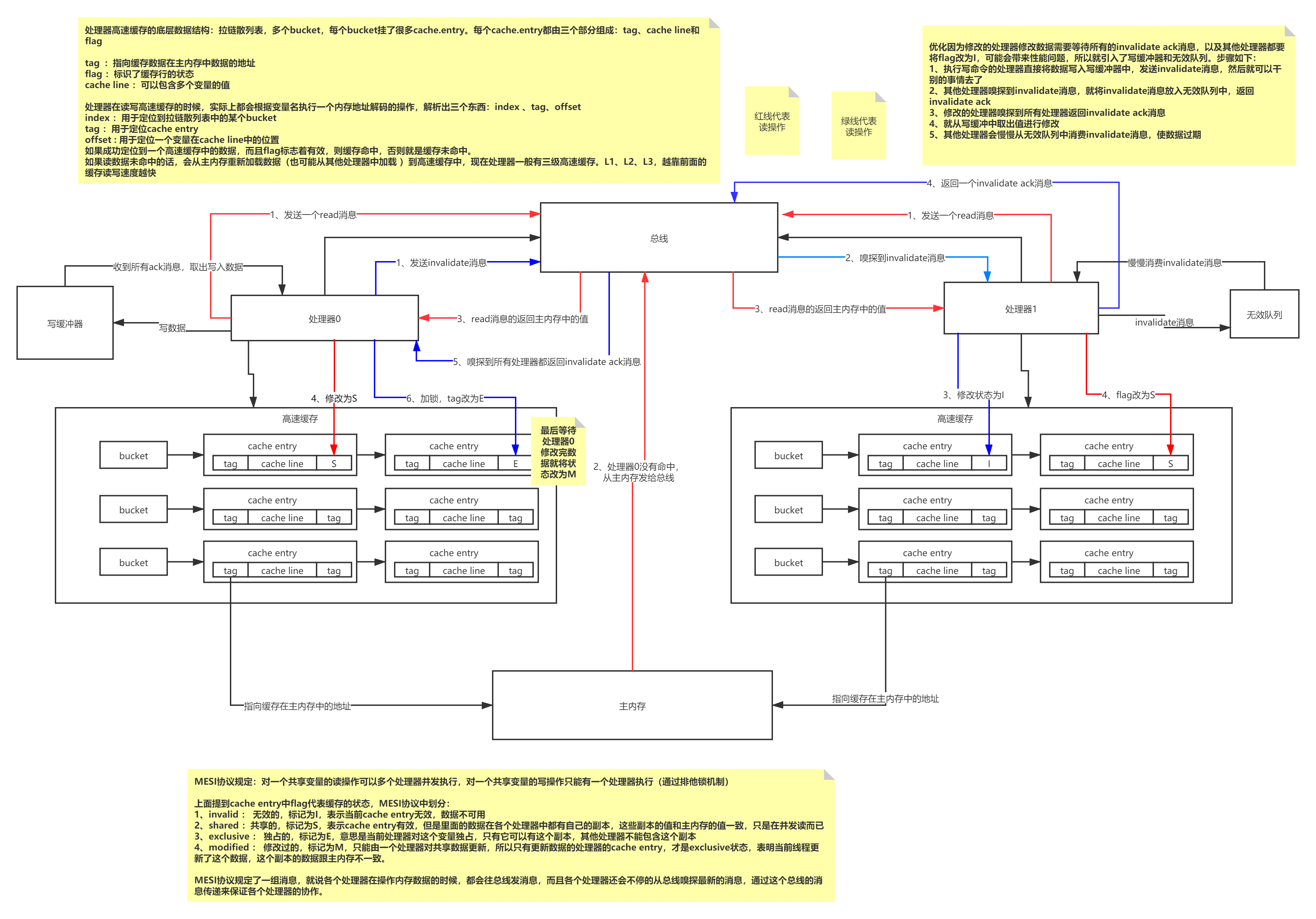
上述带来的可见性有序性的问题?
可见性:写缓冲器和无效队列导致的,写数据不一定立马写入自己的高速缓存(或者主内存)是因为可能写入了写缓冲器;读数据不一定立马从别人的高速缓存(或者主内存)刷新最新的值,或者因为invalidate消息还在无效队列中,还没来得及消费使数据过期,读到旧数据。
有序性:
StoreLoad重排: 第一个store操作写到写缓冲器里去了,第二个Load操作成功执行了。
StoreStore重排: 第一个store写到写缓冲了(flag = S),第二个直接写入了缓存(flag = M,拿到锁修改过它,证明其处理器的缓存都过期了,那么可以不用往写缓冲写,直接修改高速缓存)
内存屏障解决办法:
可见性:
Store屏障(加在写之后) + Load屏障(加在读之前):
如果加了store屏障(StoreLoad屏障可充当加载屏障),就会强制要求你对写操作必须阻塞等待到其他处理器都返回invalidate ack之后,对数据加锁然后修改数据到高速缓存中
如果加了load操作(StoreLoad屏障可充当加载屏障),从高速缓存中读取数据的时候,如果发现无效队列中有一个invalidate消息,立马会强制把本地高速缓存的数据flag改为I,然后从其他处理器的高速缓存获取最新的值
有序性:
Acquire屏障(相当于LoadLoad屏障与LoadStore屏障的组合)+ Release屏障 (相当于LoadStore屏障与StoreStore屏障的组合)
Acquire屏障:在读操作后插入,禁止该读操作与其后的任何读写操作发生重排序
Release屏障:强制先将写缓冲器里的数据写入高速缓存中,接着读数据的时候强制消费清空无效队列中的validate消息,然后强制读取最新数据 (在一个写操作之前插入,禁止该写操作与其前面的任何读写操作发生重排序)
java内存模型对底层的硬件模型,提供了一个抽象和同一的模型易于理解。
Volatile 和 Sychronized如何通过内存屏障解决可见性和有序性
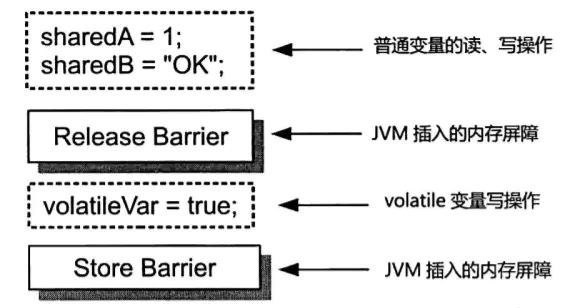
volatile :
写操作:
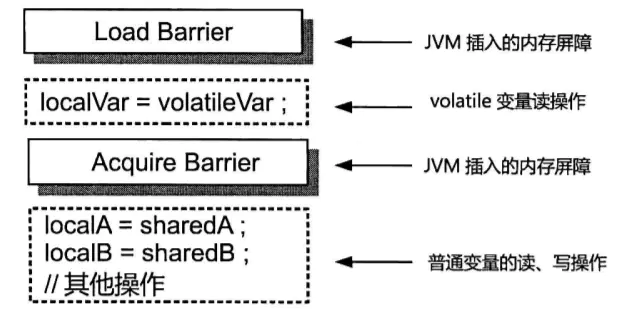
读操作:
sychronized:
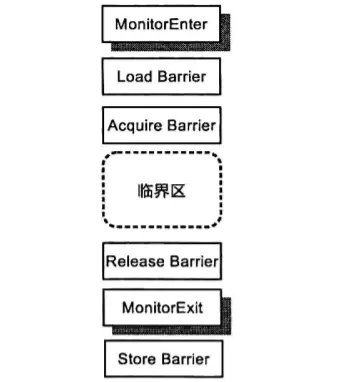
sychronized优化
- 锁消除 : JIT编译器对sychronized锁做的优化,在编译的时候JIT编译器会通过逃逸分析技术,判断锁对象如果不存在锁竞争情况,那么编译的时候就不用加入monitorenter 和 monitorexit的指令
- 锁粗化:JIT编译器如果发现代码有连续加锁放锁的操作,会合并为一个锁,就是锁粗化。避免频繁加锁释放锁
- 偏向锁:monitorenter 和 monitorexit是要使用CAS操作加锁和释放锁的,开销较大。因此如果发现大概率只有一个线程会主要竞争一个锁,那么会给这个锁维护一个偏好(Bias),后面它加锁和释放锁都是基于Bias执行,不需要通过CAS,提升性能。但是如果有偏好外的线程来竞争,就会收回之前分配的偏好
- 轻量级锁:偏向锁没有成功,尝试使用轻量级锁。就是将对象头的Mark Word里有一个轻量级锁指针,尝试指向持有锁的线程。然后判断是不是自己加的锁,如果是自己加的锁就执行代码。如果不是自己加的锁就加锁失败,膨胀为重量级锁。
- 自旋锁和自适应自旋:共享数据的锁定状态只会持续很短一段时间,为了这段时间去频繁的挂起和恢复线程不值得。所以就让后面请求锁的线程稍等一会,执行一个忙循环(自旋默认十次),这就是自旋锁。JDK6引入了自适应自旋,意味着自选时间不再是固定的,而是根据你之前获得锁的情况,如果jvm认为你很大可能获得锁,那么就多自旋一会。如果认为你获取锁的机会概率很小,那么自旋的时间就会很短甚至取消。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号