软件工程个人作业 词频统计
软件工程个人作业
——单词频率统计
曾子轩
School of information,USTC
一、项目介绍与分析(作业要求:http://www.cnblogs.com/denghp83/p/8627840.html)
项目介绍:
1. 统计文件的字符数
2. 统计文件的单词总数
3. 统计文件的总行数
4. 统计文件中各单词的出现次数,对给定文件夹及其递归子文件夹下的所有文件进行统计
5. 统计词组的频率,在Linux系统下,进行性能分析,过程写到blog中
项目分析:
1、前三个要求限定了对单个字符的读取和处理
2、第四个要求限定了对文件夹进行遍历、单词字符串的判别、处理和存储
3、第五个要求限定了对前后字符串关系的存储
数据结构的选定:
1、因为对单词的判定是至少以四个字母开始,而之后的位数不定,为了体现各个不同前缀之间的区别,也是为了分散各个单词,所以采用通过前四个字母算出地址码(不同前缀对应不同地址)的方法将数据分散 在26^4=456976个单元中(命名为HashSet[456976])。
2、为了存储不定数目单词,又因为每一个单词节点数据较多,所以采用链表形式,且将带头结点的链表首地址存放在数组单元中。
为了将词组更高效的存储,将跟在这个单词后面的单词的指针存储在前面这个单词结构体所指向列表(自行编写的变长数组)里。
WordNode 
NextWord 
3、在最后遍历时,因为只需要频率最大的十个单词、词组,所以采用数组的插入排序法,考虑到大多数单词/词组的出现次数只会比这个TopTen数组的最小出现次数小,所以从第十位开始比较、移动。
TopWordStru 
TopPhraseStru 
二、项目进展
各部分估计用时与实际用时:
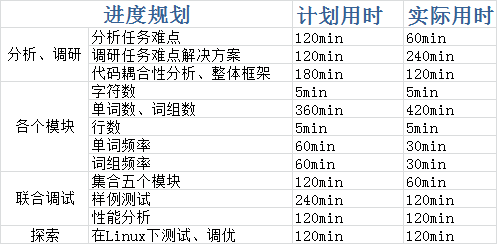
实际中,为了充分地考虑到问题可能导致的各种bug,我对关键函数在草纸上删删改改写满了不只10页,当然结果也是显著的,在细致分析的函数中只出现过一个bug。
三、样例分析
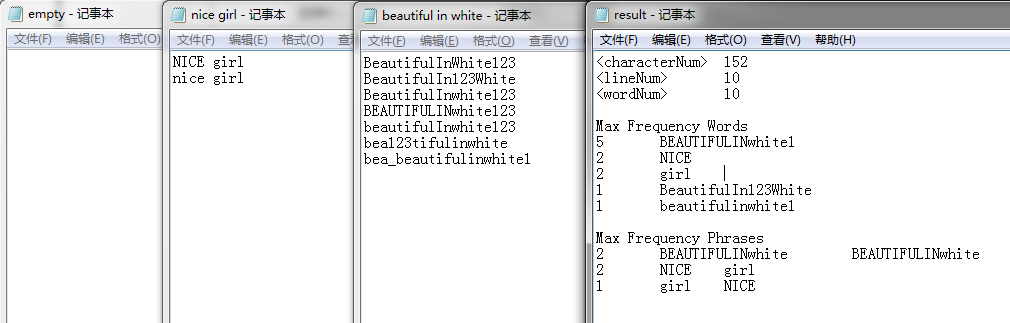
主要对一些偏难怪的单词进行调用分析。
1、以只有3个字母开头的(不算单词)。
2、空文件也算一行,不能简单地根据'\n'进行判断。
3、相同词频的按照ASCII顺序进行排列。
4、词组打印时,打印出两个单词各自的最小的ASCII出现。
文件1: 文件2: 文件3: 结果:
接下来对助教提供的大小为176MB的文件夹进行读取分析:
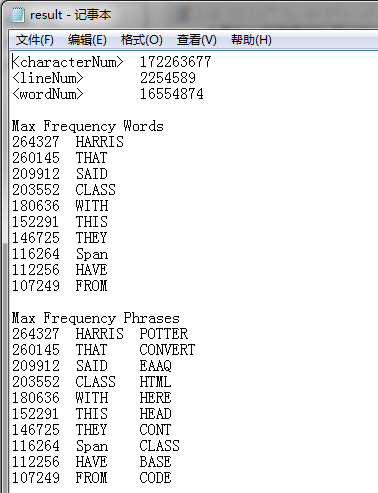
在windows cmd命令下,处理只花费了15s左右,这样的速度是相当可观的,然而遗憾是正确性:
最后的答案因为在提交前的改动而产生了错误,焦躁的内心让一个本该完美的项目黯然失色,也让一周以来的劳苦失去意义。
四、代码优化
1、减少堆栈调用
我之前在一些调用次数极多的函数中还多次调用子函数,这样堆栈访问颇为频繁。之后我直接将这个小子函数的代码拷贝入调用它的函数,消耗时间一下子减少了七个百分点。
修改前: 修改后:


2、对可以预知次数的循环函数进行拆分
这是一种比较过分的优化,目的是消除计数器count自加、空间消耗的影响。实际上这样的影响甚微,反倒让代码难读,以致最后优化阶段出现失误,得不偿失。
3、对If函数进行细分、优化
如果一个if判断中包含多个或(||),不妨分成几个if嵌套,这样可以让操作分流,减少一些数据的判断次数,实际上这样的操作让我的代码快了数秒(因为调用次数实在太多)。
4、对sizeof的优化
因为数据结构的选择,让运行过程中充满了动态内存申请、分配,而每一次分配都计算一次sizeof显然是很不值得的,当然可以先通过编译器跑一次,然后作为宏定义值替换,但这样移植性受到限制,更好的做法是在函数中作 为静态变量调用。
五、项目经验与反思
1、关于本次程序本身
1) 分配不均。根据前四个单词算出地址码是最简单的一种操作,但也不适应用实际中一些较大的应用,因为单词的出现频率并不是均匀的,比如以e开头的单词就明显多于以i、j、k字母开头的单词,当然我们这 样设计的程序是最适应于未知情况的。
2、关于过程的体验
1) 编码前细致入微的思考。本次工程很得益于实际编码前周全的思考,让最重要的代码很流畅地通过,以致最后出错的也不是这一部分的代码。在接下来的团队项目中,我也将继续这一设计理念,在功能确定 后,实际编码前细致地考虑每一步的实现,考虑可能出现的漏洞。
2) deadline的急躁。为了进行尽可能的所谓的优化,就跳过了严密的分析阶段,结果把程序改错而逾期,无力回天。
3) 程序数据结构与接口定义清晰、参数没有歧义。在编写稍微大一点的程序的时候,就算是一人编写,也需要注意这个问题,否则编写到最后很可能一团糟,幸好本次较早地意识到这个问题,代码编写较为流 畅。
六、跨平台的思考与实践
在实现了Windows平台上的词频统计,便转到Linux平台上测试,其中程序中最重要的变化莫过于文件的遍历,因为Linux系统是不支持io.h的(但支持stdio.h)。
一些比较重要的注意点归纳 参考(https://www.jianshu.com/p/f2fcd4628c12)
open系统调用
open系统调用建立了一条从到文件或设备的访问路径,该调用将得到与该文件相关联的文件描述符(file discriptor)
#include <fcntl.h> #include <sys/types.h> #include <sys/stat.h> int open(const char *path, int oflags); int open(const char *path, int oflags, mode_t mode);
write系统调用
write系统调用把缓冲区buf中的前n个bytes写入与文件描述符fd相关的文件中。
#include <stdio.h> size_t write(int fd, const void *buf, size_t nbytes)
read系统调用
read系统调用从与文件描述符fd相关联的文件中读入nbytes字节的数据,并把它们放到buf中。
#include <unistd.h> size_t read(int fd, void *buf, size_t nbytes);
close系统调用
close调用终止文件描述符fd与其对应文件之间的关联。文件描述符被释放并能够重新使用。close调用成功时候返回0,出错时返回-1。
#include <unistd.h> int close(int fd);
lseek系统调用
lseek系统调用对文件描述符的读写指针位置进行设置> 参数whence定义该偏移量offset的用法,可取下列值
#include <unistd.h> #include <sys/types.h> off_t lseek(int fd, off_t offset, int whence);
fstat stat lstat系统调用
fstat系列调用返回与打开的文件描述符相关联的文件的状态信息,该信息将被写入buf中。
stat和lstat返回的使通过文件名查询到的状态信息。它们产生相同效果,但当文件是符号链接时,lstat返回的是该符号链接本身的信息,而stat返回的使该链接指向文件的信息。
#include <unistd.h> #include <sys/types.h> #include <sys/stat.h> int fstat(int fd, struct stat *buf); int stat(const char *path, struct stat *buf); int lstat(const char *paht, struct stat *buf);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号