
Django之MTV
Django是Python中的一个模块,用于做网站后端管理的。在学Djang之前,了解一下Web框架
Web框架
Web框架可分为两类,MVC和MTV,本质上是同一个Web框架,只是名称不同。
1、MVC:Modal(数据库)、View(模板文件)、Controller(业务处理)
2、MTV:Modal(数据库),Template(模板文件)、View(业务处理)
Django使用的Web框架是MTV。
安装
windows系统:
pip3 install django
创建工程流程
方法一、
1、添加python、django-admin到环境变量(不是必需的)
2、django-admin startproject <project_name>
3、测试:cd <project_name>
python manage.py runserver
4、网页浏览测试
方法二、
在pycharm(professional)中创建project
Django初次使用
初次感受Djang的流程图:
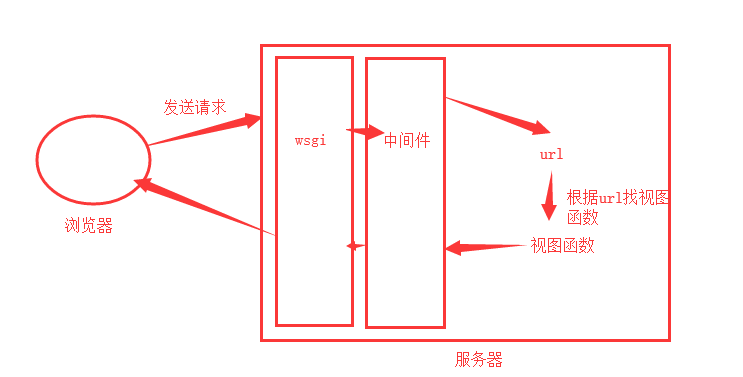
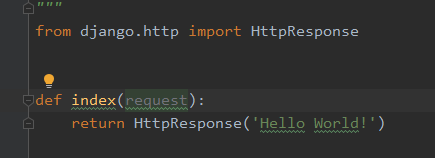
1、添加一个视图函数
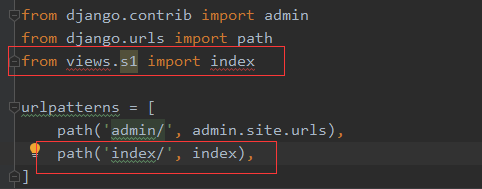
2、在urls.py中添加路径和其对应的视图函数。
目录结构
<project_name>
<project_name>
__init__.py
settings.py # 配置文件
urls.py # url与view的对应关系
wsgi.py # 遵循wsgi规范,上线后建议用uwsgi+nginx
manage.py # 管理Django程序:
python manage.py runserver 127.0,0.1:8000
python manage.py startapp <app_name>
python manage.py makemigrations
python manage.py migrate
python manage.py makemigrations --empty <App名字> # 清空app中的数据库
APP相关
一、创建APP
python manage.py start app <app_name>
创建新的APP,就是方便把视图函数放到APP中。
二、APP目录结构
migrations # 数据表结构操作记录
__init__.py
admin.py # 为用户提供后台管理,主要是管理数据库
apps.py # 当前appr的配置文件
models.py # 表结构类
tests.py # 单元测试
views.py # 业务处理
初试登录页面
步骤一、在Django工作中创建templates文件夹,按如下新建一个html页面


1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <title>Title</title> 6 <style> 7 .content{ 8 width:80px; 9 text-align: right; 10 display: inline-block; 11 } 12 </style> 13 </head> 14 <body> 15 <form action="/login" method="post"> 16 <p> 17 <label class="content" for="username">用户名:</label> 18 <input type="text" id="username"\> 19 </p> 20 <p> 21 <label class="content" for="password">密码:</label> 22 <input type="password" id="password" \> 23 <input type="submit" value="提交" \> 24 </p> 25 </form> 26 </body> 27 </html>
步骤二、新建一个app
步骤三、在工程urls中建立对应关系。
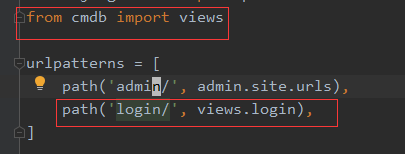
步骤四、在app的views中定义处理函数,有两种方法
方法1、利用HttpResponse模块
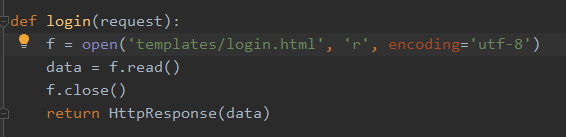
方法2、利用render模块(推荐)
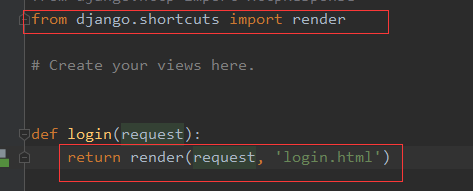
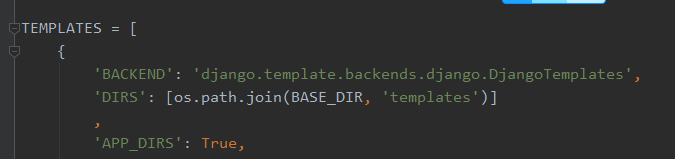
神奇的render:需要传入两个参数,request和模板。但模板好像不用加路径就会找到?那是因为在工程的settings.py中已经配置了模板的路径,如下:
VIEWS
响应方式
HttpResponse 导入:from django.http import HttpResponse
用法:HttpResponse(<字符串>)
作用:返回字符串给浏览器
render 导入:from django.shortcut import render
用法:render(request, <模板名称>, <传递给模板的键值对>),注意键值对可用locals()函数,则代表用会把此视图的所有变量,以变量名作为键传递。
作用:利用键值对渲染模板,然后把渲染后的字符串返回给客户端
redirect 导入:from django.shortcut import redirect
用法:redirect(<路径>)
作用:重定向到路径,然后重新用路径对应的视图函数返回给客户端
JsonResponse 把数据格式化为Json格式传递给客户端
关于request.POST:如果需要更新数据库的数据,可update(**request.POST.dict())
注意要加dict方法,把列表转换成字符串格式。
后端向模板中的js传送数据
要注意两点
1、后端要序列化
2、模板中要使用safe过滤器
例子如下:
# 视图函数
def show_chart(self, request):
result = models.Department.objects.annotate(hosts_count=Count('host__id')). \
values_list('name', 'hosts_count')
result_list_json = json.dumps(list(result)) # 序列化才能提供给js用,列表格式才能序列化
return render(request, 'chart.html', {'result': result_list_json})
# 模板中
<!-- 需要加上safe过滤器
alert({{ result|safe }})
请求数据处理方法
会自动传入一个客户请求信息给视图函数,其中包含头部信息、参数内容等,一般有以下函数
request.method # 获取请求方式
request.POST.get(<key>) # 获取POST请求头中键值为key的值
request.GET.get(<key>) # 获取GET请求头中键值为key的值
request.POST.getlist(<key>,None) # 主要是针对checkbox、select(可多选)等这些会返回多个值的标签而使用的,可参考上面的views。
request.URL # 获取当前URl
request.COOKIES # 获取客户端相关Cookie的操作
request.body # 由于django只帮我们封装了get、post的请求,但put、delete
# 请求并没有封装。如果需要处理这一些请求,请在此处处理。是徐了请求头
# 的所有源生数据
request.environ # 以字典的形式获取请求的所有信息
request.Meta # 请求头的所有源生数据
request.FILES.get(<key>, None) # 用于类型为file的input标签,上传文件所使用
obj.name # 获取文件名称,obj为上面函数生成的对象
obj.chunks() # 一个生成器,通过循环可获取其内容,然后写到文件里
request.path # 获取请求路径
request.path_info # 好像和上面差不多
request.get_full_path_info # 获取全路径,即使是get请求在路径中带有数据,也会获取
request.is_ajax() # 判断是否ajax请求
request.get._multable = True # 设置request.get的数据可修改,不过一般通过deepcopy,再修改其中的值
request.get.urlencode() # 对数据生成url,如page=1&key=1
上传文件案例如下:
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <title>Title</title> 6 </head> 7 <body> 8 <form action="/index/" method="post" enctype="multipart/form-data"> 9 <p> 10 篮球<input type="checkbox" name="favor" value="basketball"> 11 足球<input type="checkbox" name="favor" value="football"> 12 网球<input type="checkbox" name="favor" value="tennis"> 13 台球<input type="checkbox" name="favor" value="snooker"> 14 </p> 15 <p> 16 <select name="city" multiple> 17 <option value="bj">北京</option> 18 <option value="sh">上海</option> 19 <option value="gz">广州</option> 20 <option value="gl">桂林</option> 21 </select> 22 </p> 23 <p> 24 <input type="file" name="filetransfer"> 25 </p> 26 <p> 27 <input type="submit"> 28 </p> 29 </form> 30 </body> 31 </html>
1 from django.shortcuts import render 2 from django.http import HttpResponse 3 import os 4 5 6 # Create your views here. 7 8 9 def index(request): 10 # request.POST.getlist测试 11 # if request.method == 'POST': 12 # favors = request.POST.getlist('favor', None) 13 # cities = request.POST.getlist('city', None) 14 # print(favors, cities) 15 # 上传文件 16 obj = request.FILES.get('filetransfer', None) 17 file = os.path.join('upload', obj.name) 18 f = open(file, mode='wb') 19 for item in obj.chunks(): 20 f.write(item) 21 f.close() 22 return render(request, 'index.html')
其它函数
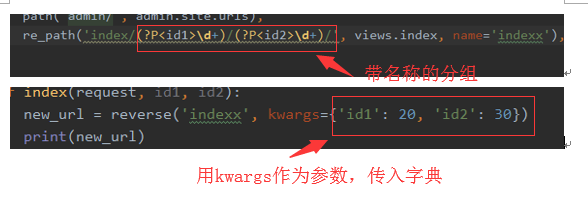
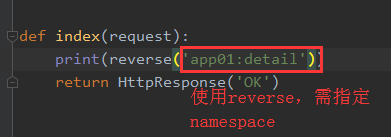
reverse函数
导入:from django.urls import reverse
作用:反解url条目中的name参数,即别名。


用法:在视图函数中使用,reverse(<url别名>, <参数1>, <参数2>......)
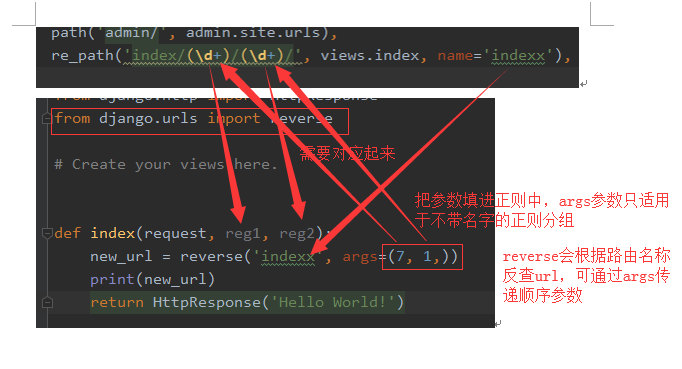
注意:如果url中带有正则分组,则需要用到参数,参数使用的方法也不同,分两种情况:
情况1、不带名称的正则分组
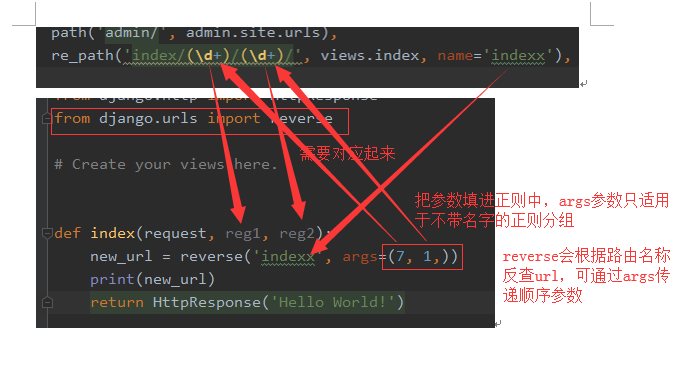
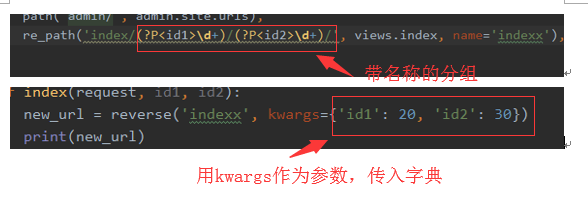
情况2、带名称的正则分组
FBV和CBV
一、FBV:是function base views的简称,意思即是视图以函数的方式编写。
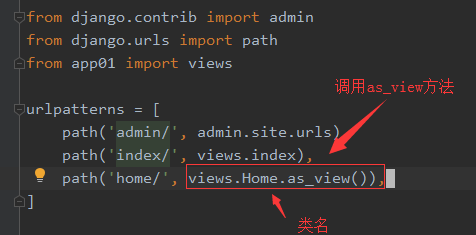
二、CBV:是class base views的简称,视图以类的方式编写。这里重点说明这种方式的使用步骤
1、
1 from django.contrib import admin 2 from django.urls import path 3 from app01 import views 4 5 urlpatterns = [ 6 path('admin/', admin.site.urls), 7 path('index/', views.index), 8 path('home/', views.Home.as_view()), 9 ]
2、
1 from django.shortcuts import render 2 from django.http import HttpResponse 3 from django.views import View 4 import os 5 6 # Create your views here. 7 8 9 def index(request): 10 # request.POST.getlist测试 11 # if request.method == 'POST': 12 # favors = request.POST.getlist('favor', None) 13 # cities = request.POST.getlist('city', None) 14 # print(favors, cities) 15 # 上传文件 16 # obj = request.FILES.get('filetransfer', None) 17 # file = os.path.join('upload', obj.name) 18 # f = open(file, mode='wb') 19 # for item in obj.chunks(): 20 # f.write(item) 21 # f.close() 22 return render(request, 'index.html') 23 24 25 class Home(View): 26 def post(self, request): 27 return HttpResponse('POST产生的页面') 28 29 def get(self, request): 30 return HttpResponse('Get产生的页面')
导入模块

创建类

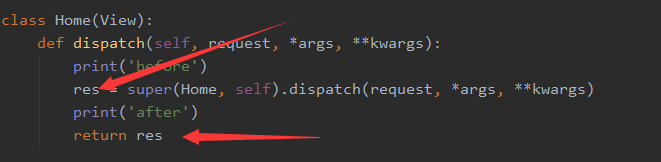
关于View类中的dispatch方法
这个方法是所有请求的入口,也是请求的出口。这是个分配器,会找到子类中定义的处理请求方法,如get、post等,然后把请求发到对应的方法。当相应的方法处理完成后,就又会返回给dispatch函数,再返回给客户端。所以我们如果需要定义一些在请求前和请求后的自定义功能,可重写此类。如下:
Cookies
什么是Cookies?
Cookies主要用于需要登录的网站。当用户名、密码正确时,则返回一个cookies给客户端并且记录在服务器上。cookies实际上是键值对。此时以后客户端需要登录时,如果还没失效则拿着此cookie去服务器验证。
认证通过时Cookies从服务器端发送到客户端
<HttpResponse对象>.set_cookie(<key>,<value>......)
此cookies会在响应头处返回给用户。
默认情况下,关闭浏览器则cookie失效。
rep = HttpResponse(...) 或 rep = render(request, ...)
rep.set_cookie(key,value,...)rep.set_signed_cookie(key,value,salt='加密盐',...) 参数: key, 键 value='', 值 max_age=None, 超时时间(秒为单位)
expires=None, 设置超时的日期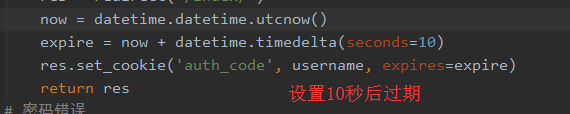
path='/', Cookie生效的路径,/ 表示根路径,特殊的:跟路径的cookie可以被任何url的页面访问 domain=None, Cookie生效的域名 secure=False, https传输 httponly=False 只能http协议传输,无法被JavaScript获取(不是绝对,底层抓包可以获取到也可以被覆盖)获取客户端cookie
一、非加密cookie
request.COOKIES.get(<key>)
二、加密cookie
request.get_signed_cookie(<key>,salt=<salt>)
session
由于cookie是保存在客户端浏览器的,所以cookies这种认证方式不适用于敏感信息的认证。这时候可以用session认证了
什么是session
其实session也是依赖于cookie的,因为如果登陆成功,session流程是这样的:
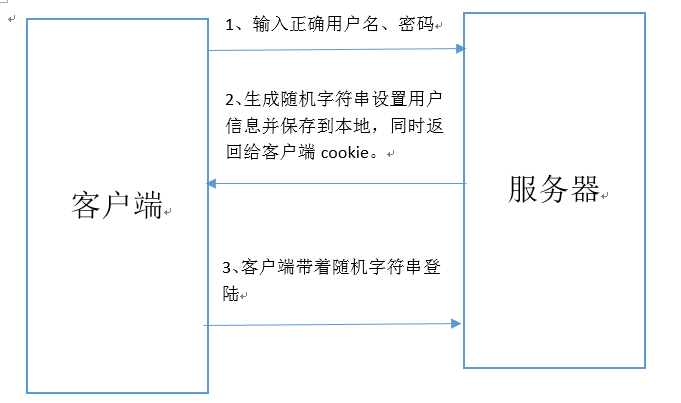
使用步骤
一、由于默认情况下,session保存在本地的数据库,所以需要在本地创建数据库
python manage.py makemigrations
python manage.py migrate
Django中默认支持Session,其内部提供了5种类型的Session供开发者使用:
- 数据库(默认)
- 缓存
- 文件
- 缓存+数据库
- 加密cookie
1、数据库Session(默认情况下)
2、缓存session
a. 配置 settings.py SESSION_ENGINE = 'django.contrib.sessions.backends.cache' # 引擎 SESSION_CACHE_ALIAS = 'default' # 使用的缓存别名(默认内存缓存,也可以是memcache),此处别名依赖缓存的设置 CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache', 'LOCATION': [ '172.19.26.240:11211', '172.19.26.242:11211', ] } }
3、文件session
1 SESSION_ENGINE = 'django.contrib.sessions.backends.file' # 引擎 2 SESSION_FILE_PATH = None # 缓存文件路径,如果为None,则使用tempfile模块获取一个临时地址tempfile.gettempdir()
4、缓存+数据库Session
1 数据库用于做持久化,缓存用于提高效率 2 3 a. 配置 settings.py 4 5 SESSION_ENGINE = 'django.contrib.sessions.backends.cached_db' # 引擎
二、Views中的使用
1 from django.shortcuts import render, redirect 2 from django.http import HttpResponse 3 4 # Create your views here. 5 6 7 def login(request): 8 if request.method == 'GET': 9 return render(request, 'login.html') 10 else: 11 username = request.POST.get('username') 12 password = request.POST.get('pwd') 13 if username == 'root' and password == 'abc123': 14 # 如果用户密码输入正确,会做以下事情 15 # 在数据库生成随机字符串,以作为键 16 # 以随机字符串为键的值中,写入用户信息到数据库 17 # 把随机字符串写入到客户端浏览器的cookie中 18 # django只需要以下的语句就可以完成 19 request.session['username'] = 'root' 20 request.session['is_login'] = True 21 if request.POST.get('excess_time', None) == '10': 22 request.session.set_expiry(10) 23 return redirect('/index/') 24 else: 25 return redirect('/login/') 26 27 28 def index(request): 29 auth_res = request.session.get('is_login', None) 30 if auth_res: 31 return render(request, 'index.html') 32 else: 33 return HttpResponse('滚') 34 35 36 def logout(request): 37 request.session.clear() 38 return redirect('/login/')
注意session的配置和操作。
1 a. 配置 settings.py 2 3 SESSION_ENGINE = 'django.contrib.sessions.backends.db' # 引擎(默认) 4 5 SESSION_COOKIE_NAME = "sessionid" # Session的cookie保存在浏览器上时的key,即:sessionid=随机字符串(默认) 6 SESSION_COOKIE_PATH = "/" # Session的cookie保存的路径(默认) 7 SESSION_COOKIE_DOMAIN = None # Session的cookie保存的域名(默认) 8 SESSION_COOKIE_SECURE = False # 是否Https传输cookie(默认) 9 SESSION_COOKIE_HTTPONLY = True # 是否Session的cookie只支持http传输(默认) 10 SESSION_COOKIE_AGE = 1209600 # Session的cookie失效日期(2周)(默认) 11 SESSION_EXPIRE_AT_BROWSER_CLOSE = False # 是否关闭浏览器使得Session过期(默认) 12 SESSION_SAVE_EVERY_REQUEST = False # 是否每次请求都保存Session,默认修改之后才保存(默认)。如果为True,则每次有session操作,则会更新过期时间为此操作后的SESSION_COOKIE_AGE时间。。 13 14 15 16 b. 使用 17 18 def index(request): 19 # 获取、设置、删除Session中数据 20 request.session['k1'] 21 request.session.get('k1',None) 22 request.session['k1'] = 123 23 request.session.setdefault('k1',123) # 存在则不设置 24 del request.session['k1'] 25 26 # 所有 键、值、键值对 27 request.session.keys() 28 request.session.values() 29 request.session.items() 30 request.session.iterkeys() 31 request.session.itervalues() 32 request.session.iteritems() 33 34 35 # 用户session的随机字符串 36 request.session.session_key 37 38 # 将所有Session失效日期小于当前日期的数据删除 39 request.session.clear_expired() 40 41 # 检查 用户session的随机字符串 在数据库中是否 42 request.session.exists("session_key") 43 44 # 删除当前用户的所有Session数据 45 request.session.delete("session_key") 46 47 request.session.set_expiry(value) 48 * 如果value是个整数,session会在些秒数后失效。 49 * 如果value是个datatime或timedelta,session就会在这个时间后失效。 50 * 如果value是0,用户关闭浏览器session就会失效。 51 * 如果value是None,session会依赖全局session失效策略,即配置文件
FBV和CBV的装饰器
FBV装饰器
1 from django.shortcuts import render, redirect 2 from django.http import HttpResponse 3 from django.urls import reverse 4 from django.utils.safestring import mark_safe 5 import datetime 6 7 # Create your views here. 8 player_list = ['Scholes', 'Keane', 'Beckham', 'Giggs'] 9 10 11 def auth(func): 12 def inner(request, *args, **kwargs): 13 username = request.COOKIES.get('authcode') 14 if not username: 15 return redirect('/login/') 16 return func(request, *args, **kwargs) 17 return inner 18 19 20 class Pagination(object): 21 def __init__(self, itemcount_per_page, item_count, current_page=1, pagination_show_count=11): 22 self.itemcount_per_page = itemcount_per_page 23 self.item_count = item_count 24 self.current_page = current_page 25 self.pagination_show_count = pagination_show_count 26 27 @property 28 def start(self): 29 """计算条目起始索引""" 30 return (self.current_page - 1) * self.itemcount_per_page 31 32 @property 33 def end(self): 34 """计算条目结束索引""" 35 return self.current_page * self.itemcount_per_page 36 37 @property 38 def page_count(self): 39 """计算总页数""" 40 total_count, remainder = divmod(self.item_count, self.itemcount_per_page) 41 if remainder: 42 total_count += 1 43 return total_count 44 45 def make_page_str(self): 46 """生成页码html""" 47 # 如果总页数少于要显示的页数 48 page_str_list = [] 49 if self.page_count <= self.pagination_show_count: 50 pagination_start = 1 51 pagination_end = self.page_count + 1 52 else: 53 # 如果是页码在中间的情况 54 pagination_start = self.current_page - (self.pagination_show_count - 1)/2 55 pagination_end = self.current_page + (self.pagination_show_count + 1)/2 56 # 页码在头 57 if self.current_page <= (self.pagination_show_count + 1)/2: 58 pagination_start = 1 59 pagination_end = self.pagination_show_count + 1 60 # 页码在后面 61 if self.current_page + (self.pagination_show_count - 1)/2 >= self.page_count: 62 pagination_end = self.page_count + 1 63 pagination_start = self.page_count - self.pagination_show_count + 1 64 if self.current_page != 1: 65 page_str_list.append('<a class="pagination" href="/user_list/?p=%s">上一页</a>' % (self.current_page - 1)) 66 else: 67 page_str_list.append('<a class="pagination">上一页</a>') 68 for i in range(int(pagination_start), int(pagination_end)): 69 if i == self.current_page: 70 page_str_list.append('<a class="pagination active" href="/user_list/?p=%s">%s</a>' % (i, i)) 71 else: 72 page_str_list.append('<a class="pagination" href="/user_list/?p=%s">%s</a>' % (i, i)) 73 if self.current_page != self.page_count: 74 page_str_list.append('<a class="pagination" href="/user_list/?p=%s">下一页</a>' % (self.current_page + 1)) 75 else: 76 page_str_list.append('<a class="pagination">下一页</a>') 77 page_str = ''.join(page_str_list) 78 page_str = mark_safe(page_str) 79 return page_str 80 81 82 items_list = [] 83 for i in range(200): 84 items_list.append(i) 85 86 87 def user_list(request): 88 # 当前页码 89 current_page = request.GET.get('p', 1) 90 # 由于获取的是字符串,所以需要转换成数字 91 current_page = int(current_page) 92 # 每页显示的条目数 93 itemcount_per_page = request.COOKIES.get('items_count_per_page', 10) 94 itemcount_per_page = int(itemcount_per_page) 95 # 显示的页码数 96 pagination_show_count = 11 97 page_obj = Pagination(itemcount_per_page, len(items_list), current_page, pagination_show_count) 98 html_str = page_obj.make_page_str() 99 items_show_list = items_list[page_obj.start:page_obj.end] 100 return render(request, 'user_list.html', {'items_show_list': items_show_list, 'page_str': html_str}) 101 102 103 auth_db = {'Treelight': 'abc123'} 104 105 106 def login(request): 107 # 处理get请求 108 if request.method == 'GET': 109 return render(request, 'login.html') 110 # 处理post请求 111 else: 112 username = request.POST.get('username', None) 113 password = request.POST.get('pwd', None) 114 # 获取用户名是否存在的结果 115 db_pwd = auth_db.get(username) 116 # 用户名不存在 117 if not db_pwd: 118 return redirect('/login/') 119 # 用户存在 120 else: 121 # 密码正确 122 if password == db_pwd: 123 res = redirect('/index/') 124 now = datetime.datetime.utcnow() 125 expire = now + datetime.timedelta(seconds=10) 126 res.set_cookie('auth_code', username, expires=expire) 127 return res 128 # 密码错误 129 else: 130 return redirect('/login/') 131 132 133 @auth 134 def index(request): 135 username = request.COOKIES.get('auth_code') 136 # if not username: 137 # return redirect('/login/') 138 return render(request, 'index.html', {'username': username})
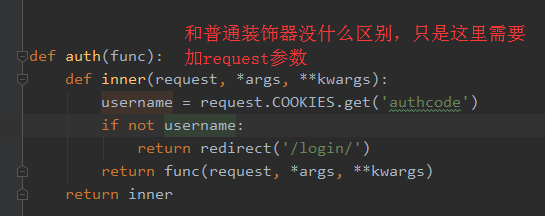
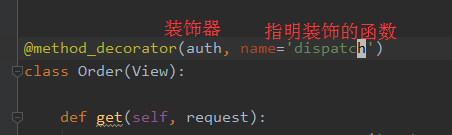
CBV装饰器
使用方式有三种,但都需要导入一个模块
from django.utils.decorators import method_decorator
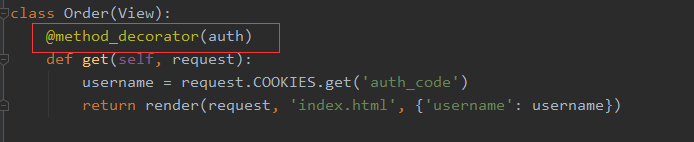
方式一、直接在类里面的函数添加
1 from django.shortcuts import render, redirect 2 from django.utils.safestring import mark_safe 3 from django.views import View 4 from django.utils.decorators import method_decorator 5 import datetime 6 7 # Create your views here. 8 player_list = ['Scholes', 'Keane', 'Beckham', 'Giggs'] 9 10 11 def auth(func): 12 def inner(request, *args, **kwargs): 13 username = request.COOKIES.get('authcode') 14 if not username: 15 return redirect('/login/') 16 return func(request, *args, **kwargs) 17 return inner 18 19 20 class Pagination(object): 21 def __init__(self, itemcount_per_page, item_count, current_page=1, pagination_show_count=11): 22 self.itemcount_per_page = itemcount_per_page 23 self.item_count = item_count 24 self.current_page = current_page 25 self.pagination_show_count = pagination_show_count 26 27 @property 28 def start(self): 29 """计算条目起始索引""" 30 return (self.current_page - 1) * self.itemcount_per_page 31 32 @property 33 def end(self): 34 """计算条目结束索引""" 35 return self.current_page * self.itemcount_per_page 36 37 @property 38 def page_count(self): 39 """计算总页数""" 40 total_count, remainder = divmod(self.item_count, self.itemcount_per_page) 41 if remainder: 42 total_count += 1 43 return total_count 44 45 def make_page_str(self): 46 """生成页码html""" 47 # 如果总页数少于要显示的页数 48 page_str_list = [] 49 if self.page_count <= self.pagination_show_count: 50 pagination_start = 1 51 pagination_end = self.page_count + 1 52 else: 53 # 如果是页码在中间的情况 54 pagination_start = self.current_page - (self.pagination_show_count - 1)/2 55 pagination_end = self.current_page + (self.pagination_show_count + 1)/2 56 # 页码在头 57 if self.current_page <= (self.pagination_show_count + 1)/2: 58 pagination_start = 1 59 pagination_end = self.pagination_show_count + 1 60 # 页码在后面 61 if self.current_page + (self.pagination_show_count - 1)/2 >= self.page_count: 62 pagination_end = self.page_count + 1 63 pagination_start = self.page_count - self.pagination_show_count + 1 64 if self.current_page != 1: 65 page_str_list.append('<a class="pagination" href="/user_list/?p=%s">上一页</a>' % (self.current_page - 1)) 66 else: 67 page_str_list.append('<a class="pagination">上一页</a>') 68 for i in range(int(pagination_start), int(pagination_end)): 69 if i == self.current_page: 70 page_str_list.append('<a class="pagination active" href="/user_list/?p=%s">%s</a>' % (i, i)) 71 else: 72 page_str_list.append('<a class="pagination" href="/user_list/?p=%s">%s</a>' % (i, i)) 73 if self.current_page != self.page_count: 74 page_str_list.append('<a class="pagination" href="/user_list/?p=%s">下一页</a>' % (self.current_page + 1)) 75 else: 76 page_str_list.append('<a class="pagination">下一页</a>') 77 page_str = ''.join(page_str_list) 78 page_str = mark_safe(page_str) 79 return page_str 80 81 82 items_list = [] 83 for i in range(200): 84 items_list.append(i) 85 86 87 def user_list(request): 88 # 当前页码 89 current_page = request.GET.get('p', 1) 90 # 由于获取的是字符串,所以需要转换成数字 91 current_page = int(current_page) 92 # 每页显示的条目数 93 itemcount_per_page = request.COOKIES.get('items_count_per_page', 10) 94 itemcount_per_page = int(itemcount_per_page) 95 # 显示的页码数 96 pagination_show_count = 11 97 page_obj = Pagination(itemcount_per_page, len(items_list), current_page, pagination_show_count) 98 html_str = page_obj.make_page_str() 99 items_show_list = items_list[page_obj.start:page_obj.end] 100 return render(request, 'user_list.html', {'items_show_list': items_show_list, 'page_str': html_str}) 101 102 103 auth_db = {'Treelight': 'abc123'} 104 105 106 def login(request): 107 # 处理get请求 108 if request.method == 'GET': 109 return render(request, 'login.html') 110 # 处理post请求 111 else: 112 username = request.POST.get('username', None) 113 password = request.POST.get('pwd', None) 114 # 获取用户名是否存在的结果 115 db_pwd = auth_db.get(username) 116 # 用户名不存在 117 if not db_pwd: 118 return redirect('/login/') 119 # 用户存在 120 else: 121 # 密码正确 122 if password == db_pwd: 123 res = redirect('/index/') 124 now = datetime.datetime.utcnow() 125 expire = now + datetime.timedelta(seconds=10) 126 res.set_cookie('auth_code', username, expires=expire) 127 return res 128 # 密码错误 129 else: 130 return redirect('/login/') 131 132 133 @auth 134 def index(request): 135 username = request.COOKIES.get('auth_code') 136 return render(request, 'index.html', {'username': username}) 137 138 139 class Order(View): 140 @method_decorator(auth) 141 def get(self, request): 142 username = request.COOKIES.get('auth_code') 143 return render(request, 'index.html', {'username': username}) 144 145 def post(self, request): 146 pass
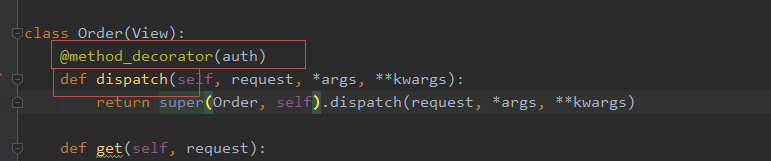
方式二、在dispatch方法中装饰,如此一来,此类中的所有方法都会使用此装饰器
class Order(View): @method_decorator(auth) def dispatch(self, request, *args, **kwargs): return super(Order, self).dispatch(request, *args, **kwargs) def get(self, request): username = request.COOKIES.get('auth_code') return render(request, 'index.html', {'username': username}) def post(self, request): pass
方式三、把整个类都装饰了,效果和方式二是一样的
再试登录页面
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> <link rel="stylesheet" href="/static/commons.css"> <style> .content{ width:80px; text-align: right; display: inline-block; } .error{ color:red; } </style> </head> <body> <form action="/login/" method="post"> <p> <label class="content" for="username">用户名:</label> <input type="text" id="username" name="user" \> </p> <p> <label class="content" for="password">密码:</label> <input type="password" id="password" name="pwd" \> <input type="submit" value="提交" \> <span class="error">{{ error_msg }}</span> </p> </form> <script src="/static/jquery-1.12.4.js"></script> </body> </html>
from django.shortcuts import render from django.shortcuts import redirect from django.http import HttpResponse # Create your views here. def login(request): # request参数是客户端改过来的数据,包括头数据 # request.method获取请求方法 error_msg = '' if request.method == 'POST': # 从客户的请求中找到name为user的标签的值,如果没有则返回None username = request.POST.get('user', None) pwd = request.POST.get('pwd', None) if username == 'Treelight' and pwd == 'dczx5501': # 跳转到百度 return redirect('https://www.baidu.com') else: error_msg = '用户名或密码错误' return render(request, 'login.html', {'error_msg': error_msg})
关键点:
Views

Html:

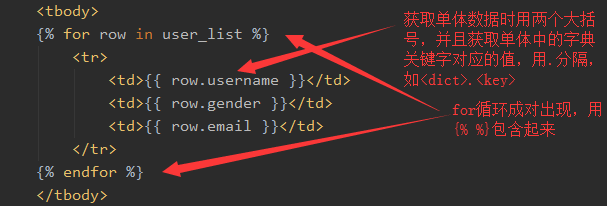
案例:登录页面与后台交互,并且能添加数据
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> <style> .header { background-color: #eeeeee; height: 40px; } </style> </head> <body style="margin: 0 auto"> <div class="header"></div> <form action="/home/" method="post"> <input type="text" name="username" placeholder="用户名"> <input type="text" name="gender" placeholder="性别"> <input type="text" name="email" placeholder="邮箱"> <input type="submit" value="添加"> </form> <table border="1"> <thead> <tr> <th>用户名</th> <th>性别</th> <th>邮箱</th> </tr> </thead> <tbody> {% for row in user_list %} <tr> <td>{{ row.username }}</td> <td>{{ row.gender }}</td> <td>{{ row.email }}</td> </tr> {% endfor %} </tbody> </table> </body> </html>
from django.shortcuts import render from django.shortcuts import redirect from django.http import HttpResponse # Create your views here. def login(request): # request参数是客户端改过来的数据,包括头数据 # request.method获取请求方法 error_msg = '' if request.method == 'POST': # 从客户的请求中找到name为user的标签的值,如果没有则返回None username = request.POST.get('user', None) pwd = request.POST.get('pwd', None) if username == 'Treelight' and pwd == 'dczx5501': # 跳转到百度 return redirect('/home/') else: error_msg = '用户名或密码错误' return render(request, 'login.html', {'error_msg': error_msg}) user_list = [ {'username': 'Scholes', 'gender': 'male', 'email': 'Scholes@MU.com'}, {'username': 'Keane', 'gender': 'male', 'email': 'Keane@MU.com'}, {'username': 'Beckham', 'gender': 'male', 'email': 'Beckham@MU.com'}, {'username': 'Giggs', 'gender': 'female', 'email': 'Scholes@MU.com'}, ] def home(request): if request.method == 'POST': username = request.POST.get('username', None) gender = request.POST.get('gender', None) email = request.POST.get('email', None) user_list.append( {'username': username, 'gender': gender, 'email': email}, ) return render(request, 'home.html', {'user_list': user_list})
新知识点:
一、在Djang模板中
Django模板语言
由于浏览器不会直接识别模板语言,所以Django中的render函数在渲染时会把模板语言解析成html语言。而在模板语法中分为两类:变量和标签
变量
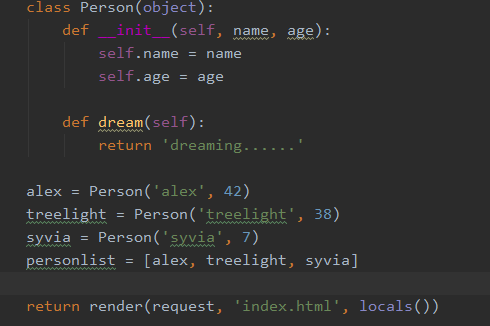
变量:在模板中用两个大括号获取变量值。也可以从render渲染对象,在模板中可以使用对象的属性、方法。在模板中使用对象的方法和属性可使用句点符号,即<对象>.<属性或方法>。但要注意的是,与python语言不同的是,调用其方法时不需要加()。
类的调用,dream是一个方法,但调用时不用加()

for循环中的变量
注意:在for循环中,有5个特殊的变量,
{{ forloop.counter }}:序号计数器,从1开始
{{ forloop.counter0 }}:序号计数器,从0开始
{{ forloop.revcounter }}:序号计数器,倒序,从大到小,最后一个是1
{{ forloop.revcounter0 }}:序号计数器,倒序,从大到小,最后一个是0
{{ forloop.last }}:判断是否是最后一个
{{ forloop.first }}:判断是否是第一个
{{ forloop.parentloop }}:不知道怎么表达。。。
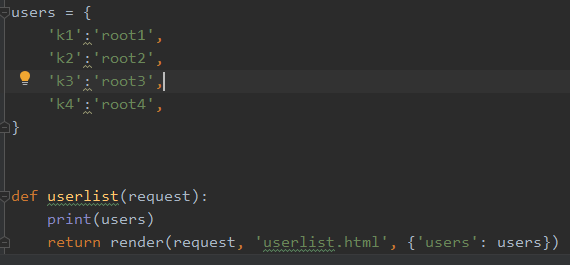
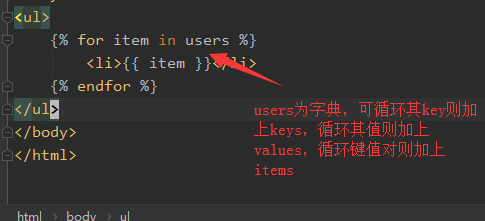
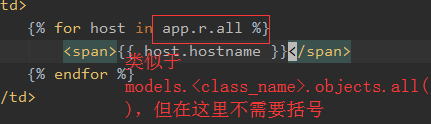
字典的值的获取与循环
一、字典值的获取:通过<dict>.<key>获取值
二、循环字典
过滤器
为了在模板中对数据进行处理,如进行加法、截取字符串等,在模板语言中提供了过滤器,其实就是函数来进行处理。
常见的过滤器
add # 加法运算 date # 日期格式化 default # 默认值 length # 长度 filesizeformat # 字节转换成方便阅读的格式 slice # 切片 truncatechars # 截断字符 truncatewords # 截断单词 safe # 把标签注明为安全的 first # 取首个字符 upper # 转换成大写 lower # 转换成小写
一般用法:{{ <变量名>|<过滤器>:<参数> }},注意只能用一个参数,用法例子如下:
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <title>Title</title> 6 </head> 7 <body> 8 <h3>主页</h3> 9 {#过滤器:add#} 10 <p>{{ name }} --- {{ age|add:10 }}</p> 11 {#过滤器:date,参数为时间格式#} 12 <p>{{ time|date:'Y-m-d' }}</p> 13 {#过滤器:default#} 14 <p>{{ l|default:'值为空' }}</p> 15 {#过滤器:length,不用参数#} 16 <p>{{ l2|length }}</p> 17 {#过滤器:filesizeformat,把字节转换成人方便阅读的格式,不用带参数#} 18 <p>{{ 112435566775|filesizeformat }}</p> 19 {#过滤器:slice,切片,与python的用法一样#} 20 <p>{{ 'hello world'|slice:"3:-1" }}</p> 21 {#过滤器:truncatechars,截取从开头开始的N个字符,其它的用省略号代替#} 22 <p>{{ 'hello world'|truncatechars:4 }}</p> 23 {#过滤器:truncatewords,其它的用省略号代替#} 24 <p>{{ 'hello world treelight alex syvia diana'|truncatewords:2 }}</p> 25 {#过滤器:safe,主要用于标明此标签安全的#} 26 <p>{{ a_ele|safe }}</p> 27 </body> 28 </html>
自定义过滤器
但是模板语言提供的过滤器比较少,Django提供了一种可以自定义过滤器的机制,自定义过滤器的步骤如下:
一、在<app名称目录>中新建一个templatetags文件夹,注意此文件夹名称是固定的,不能更改。
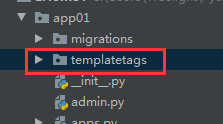
二、在templatetags文件夹中新建一个py文件,名字可自己起
三、在新建的py文件中需按以下步骤做:
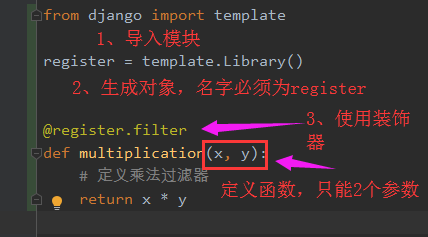
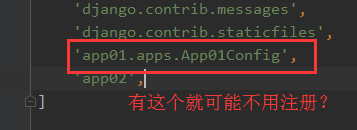
四、注册APP?(好像在新版本的django中不用)
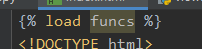
五、使用方法:
1、在html顶部中添加{% load <自定义过滤器py文件名称> %}
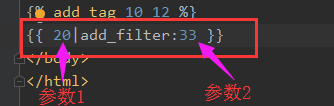
2、在需要使用的地方添加{ <参数1>|<过滤器名称>:<参数2>}
标签
for 循环标签
格式如下:
{% for obj in objs %}
<!--遍历变量-->
<相关操作>
{% empty %}
<!--如果为空的处理-->
<相关代码>
{% endfor %}
说明:
empty是可选标签,其作用是如果objs为空时则会执行相关的代码
if标签
格式如下:
{% if <条件> %}
...
{% elif <条件> %}
...
{% else %}
...
{% endif %}
with标签
格式如下:
{% with <被代替的名称>=<别名> %}
...
{% endwith %}

extends标签
格式如下:{% extends <基板.html> %}
作用:引入基板
load标签
格式:{% load <py文件> %}
在模板中引入自定义的过滤器或标签
url标签
格式:{% url <url_name> arg1 arg2... %}
作用:在URL系统中,条目中定义了name参数,即别名参数,模板则可用此别名标签进行渲染。起到绑定的作用,无论前面的怎么变,只要用此别名即可获取此url。

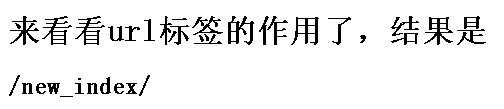
但注意:由于url可能带有正则表达式,则分两种情况:
情况1、不带名称的正则分组


情况2、带名称的正则分组


自定义标签
步骤如下:
一、在<app_name>中新建一个templatetags文件夹,注意此文件夹名称是固定的,不能更改。
二、在templatetags文件夹中新建一个py文件,名字可自己起
三、在新建的py文件中需按以下步骤做:
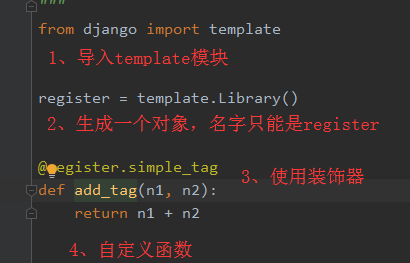
四、注册APP?(好像在新版本的django中不用)
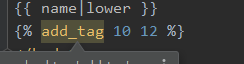
五、使用方法:
1、在html顶部中添加{% load <py_name> %}
2、在需要使用的地方添加{% <fun_name> arg1 arg2 %}
特殊标签-inclusion_tag的定义
以以下例子说明他的作用
inclusion_tag标签例子
from django.template import Library
from django.conf import settings
import re
register = Library()
@register.inclusion_tag('menu.html') # 渲染给menu.html
def menu(request):
permissions_menu_list = request.session.get(settings.PERMISSIONS_MENU_SESSION_KEY)
# print(permissions_menu_list)
per_dict = {}
current_path = request.path_info
for item in permissions_menu_list: # 获取菜单
if not item['pid']:
per_dict[item['id']] = item
# 把被选中的菜单设置为'active'=True
for item in permissions_menu_list:
url = settings.REX_FORMAT % item['url']
if not re.match(url, current_path):
continue
if item['pid']:
per_dict[item['pid']]['active'] = True
else:
item['active'] = True
# print(per_dict)
menu_result = {}
for item in per_dict.values():
menu_id = item['menu_id']
if menu_id in menu_result:
temp = {'id': item['id'], 'title': item['title'], 'url': item['url'], 'active': item.get('active', False)}
menu_result[menu_id]['children'].append(temp)
if item.get('active', False):
menu_result[menu_id]['active'] = item.get('active', False)
else:
menu_result[menu_id] = {
'menu_name': item['menu_name'],
'active': item.get('active', False),
'children': [
{'id': item['id'], 'title': item['title'], 'url': item['url'], 'active': item.get('active', False)}
]
}
return {'menu_result': menu_result} # 此字典会给模板渲染
一、作用:把menu_result渲染给menu.html,然后会把渲染的结果代替标签{% menu result %}
二、定义步骤:基本上和普通标签一样,只是装饰器不同:@register.inclusion_tag(模板名称)
三、使用:和普通标签一样
自定义标签和过滤器的优缺点
一、自定义标签
优点:可传多个参数,多个参数之间可有多个空格分隔
缺点:不能作为if的条件判断
二、filter
优点:作为if的条件判断
缺点:只能传两个参数,中间不能有空格
模板的继承
你应该会经常发现,在多个网页中,这些网页都使用到类似的html,但有个别位置的内容又不同。比如在一个网站的后台管理页面中,网页的头部和网页的左边菜单是一样的,但网页的右边的内容是不同的。这时候为了代码的简化,可以使用继承和引入,如下:
继承
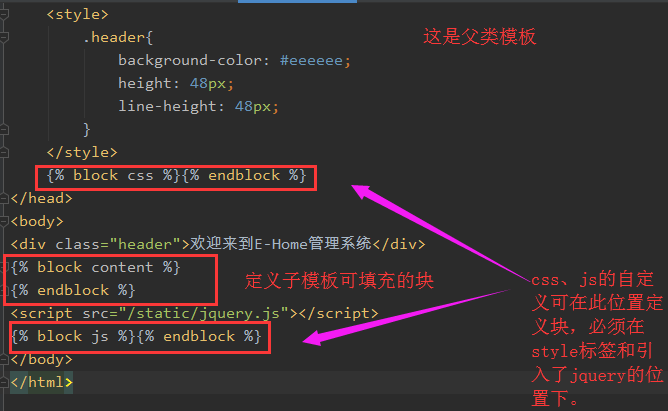
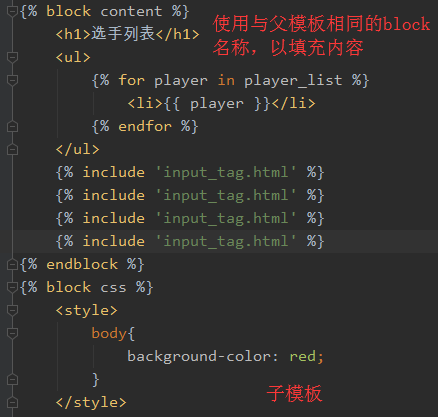
更进一步、其实在基板中可在{% block %}中加值,此为默认值。默认情况下,如果子板中不修改此block,则会使用此值;否则将会覆盖默认值。但如果在子板中{% block %}添加了{{ block.super }},则会使用基板block的值。
引入
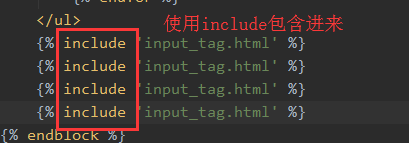
路由系统URL
路由系统其实是一个映射关系,把请求的url交给对应的视图处理,一般有以下两种关系:
1、可建立一个url对应一个视图的关系,不使用正则表达式即可。
2、可建立多个url对应一个视图的关系,使用正则表达式。使用步骤如下:
(1)导入模块
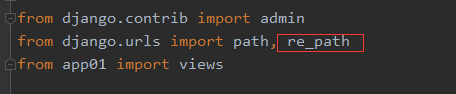
(2)、写正则表达式在UR中的分组L

(3)、此时django会把正则表达式的分组作为参数传进视图函数。如有多个正则分组,则会按顺序传多个参数。类似于python中的位置参数
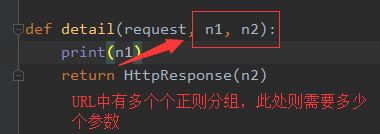
request为请求的数据,n1、n2为url正则匹配的值
3、也可使用正则表达式,然后分组加名称,则在视图函数中需要有对应的正则分组名称。如下:

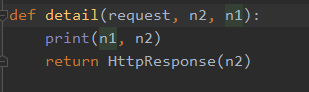
必须要对应起来。
路由名称
概念
什么是路由名称?其实是一个别名,此别名就会绑定此路由条目,如下:

作用
大家想一想,如果以上路由的url即home/在项目中使用了100次,以后某一天,你要修改此url,那就需要改100个地方!!!。而如果你使用了路由名称,那就根本不用改。因为无论是在视图函数还是在模板中,都可以通过路由条目中的name参数找到url,也就是此name参数会绑定到此路由条目的url中
具体用法
情况1、URL中没有带有正则表达式
模板语言
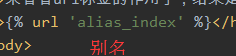
视图函数

情况2、带有正则表达式,但正则表达式不带名称
模板语言

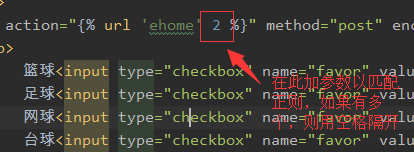
视图函数
情况3、带有正则表达式且正则表达式带名称
模板语言


视图函数
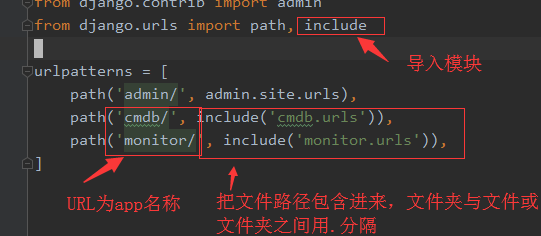
URL分发器
到目前为此,我们的路由系统条目都写在<project_name>.urls.py文件中。但这样不太好,为什么这样说呢?
1、一个django项目可以有多个app,这就要求里面的条目URL不能重复
2、每个app开发人员都要编辑url,这样就会编辑同一个urls.py文件。
解决办法:每个app中也有自己的路由系统,这样就可以只编辑自己的路由系统,不会产生冲突了。具体做法如下:
路由分发中的namespace的应用
应用场景:一个项目中的多个app使用路由分发(include),有可能在各自定义的路由条目中name参数相同,如下:
monitor中
urlpatterns = [
path('index/', views.index, name='hosts'),
]
openstack中
urlpatterns = [
path('index/', views.index, name='hosts'),
]
这时候在视图函数中使用url = reverse('hosts'),由于都是同一个name,所以不能区分。
解决办法:在include中加入namespace参数。如下:
path('openstack/', include('openstack.urls', namespace='o')),
path('monitor/', include('monitor.urls', namespace='m')),
同时在被保住的urls中添加app_name,如下
openstack中
app_name = 'openstack'
urlpatterns = [
path('index/', views.index, name='hosts'),
]
monitor中
app_name = 'monitor'
urlpatterns = [
path('index/', views.index, name='hosts'),
]
而在视图函数中这样使用reverse:
url=reverse('o:hosts') # 参数为'命名空间:命名',此处会获取命名空间为o中hosts的路径。
路由分发Include的本质
现有使用了include的案例,如下:
# 在项目名称目录下的urls.py
path('openstack/', include('openstack.urls', namespace='o')),
# 在应用openstack中的urls.py
path('index/', views.index, name='hosts'),
path('users/', views.users, name='users'),
其实这相当于项目名称目录下的如下urls.py,不用使用应用中的urls
path('openstack/', ([
path('index/', oviews.index, name='hosts'),
path('users/', oviews.users, name='users'),
], 'openstack', 'o')), # 需指定app_name,namespace设定为'o'
以上只是二级路径,其实可以有三级路径或者更多层级路径,以下是三级路径
path('openstack/', ([
path('index/', oviews.index, name='hosts'),
path('users/', oviews.users, name='users'),
path('hosts/', ([
path('add/', oviews.add, name='add'),
], None, None)), # 此处可不指定app_name
], 'openstack', 'o')),
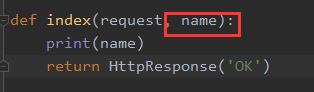
在路由系统中传递默认值给视图函数
步骤如下:
1、在urls.py的path参数中添加一个字典,则此字典会把参数传递给对应的视图函数

2、views需添加参数以接收此参数
命名空间
有可能出现以下情况:
有多个app,在<project_name>.urls.py中,使用路由分发(即使用include),urlpattern中前缀不同,但指向的视图函数相同,如果需要反向解析url,则需要在<project_name>.urls.py中使用命名空间(namespace),以此区分app前缀的不同。案例如下:
父urls.py

子urls.py
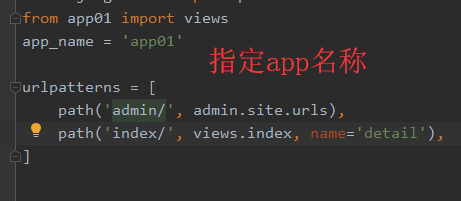
模板语言
{% url '<namespace>:<name> args... %}'
数据库
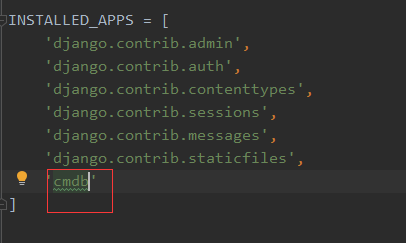
创建步骤
一、在<project_name>.settings.py中的INSTALL_APPS中添加app名称,这个的意义就是要告诉django去哪里创建数据库
二、在app中的models中添加数据库类。

跨表model类的继承
注意点:
1、基类中,需要使用到类中类
2、基类中如果有一对多或者多对多,则to参数不要加双引号或者在加上App名称
3、派生类中继承基类
例子如下:
# 基类
class Group(models.Model):
name = models.CharField(max_length=32)
class UserInfo(models.Model):
"""基类,但数据库不生成此表"""
username = models.CharField(max_length=32)
password = models.CharField(max_length=64)
# 基类的一对多和多对多关系
# 方式一、to参数如果有双引号,则需要加上App名称
# gp = models.ForeignKey(to='app02.Group', on_delete=models.CASCADE)
# 方式二、to参数把双引号去掉
gp = models.ForeignKey(to=Group, on_delete=models.CASCADE)
class Meta:
abstract = True # 此条语句会使得不会生成此表.
# 派生类
class User(app02_models.UserInfo):
"""派生类,继承了app02的UserInfo"""
email = models.EmailField()
null=True可加在字段类型里。
多字段联合唯一需要在models表中定义一个原类:
class Meta:
unique_together = [
('article', 'user'),
]
注意:如果需要跨表,则需要在表里添加关系外表的字段,此字段怎么写呢?可分为以下三种情况建立表关系:
1、一对多:<关联字段名> = models.ForeignKey(to='关联表名', on_delete=<值>) 注意:ForeignKey字段只可以在多的那张表建立
这样会在此表中多了字段:关联表名_id

其实这样在此表中添加了一个字段,名为user_group_id,记录的是关联表的主键。
这样就会与外表建立关系。
2、一对一:<关联字段名> = models.OneToOneField(to='关联表名', on_delete=<值>)
3、多对多:<关联字段名> = models.ManyToManyField(to='关联表名')
4、跨App关联:
from rbac.models import Role
class UserInfo(models.Model):
"""用户表"""
username = models.CharField(max_length=32)
password = models.CharField(max_length=64)
email = models.EmailField()
roles = models.ManyToManyField(to='rbac.Role', verbose_name='拥有的角色') # 参数to必须要有跨app名
创建方式一、手动创建
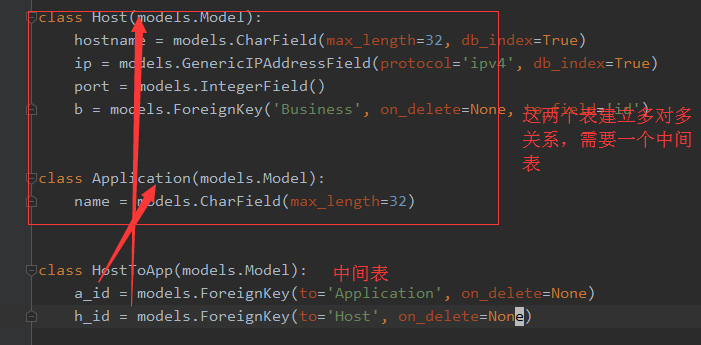
此种方式创建的多对多可这样创建数据记录,HostToApp.objects.create(a_id=<application_id>,h_id=<host_id>)
方式二、自动创建,使用models.ManyToManyField方法。但这种方法不灵活,只会在中间表创建三列。
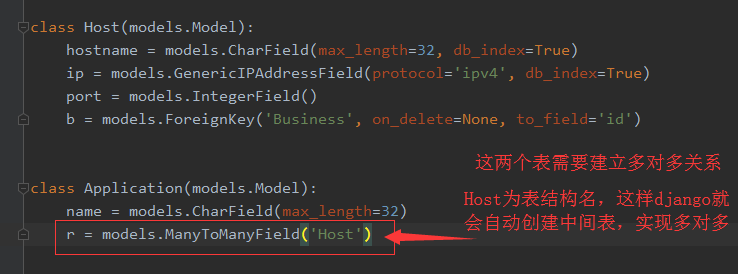
这种方式创建多对多,有三种方法创建中间表记录
方式三、有时候需要在第三张表中记录一些数据,如以下的Membership表,可记录此人加入此组的时间和原因,这就需要通过ManyToManyField中的through参数创建,示例如下:
from django.db import models
class Person(models.Model):
name = models.CharField(max_length=128)
def __str__(self):
return self.name
class Group(models.Model):
name = models.CharField(max_length=128)
members = models.ManyToManyField(Person, through='Membership')
def __str__(self):
return self.name
class Membership(models.Model):
person = models.ForeignKey(Person, on_delete=models.CASCADE)
group = models.ForeignKey(Group, on_delete=models.CASCADE)
date_joined = models.DateField()
invite_reason = models.CharField(max_length=64)
三、运行命令:python manage.py makemigrations
python manage.py migrate
此时数据库已经创建完毕。
数据库的操作(单表)
注意:如果需要在使用models操作时在console查看对应的sql操作,可点此链接。
以下操作都是基于以下models
class Book(models.Model):
title = models.CharField(max_length=32)
authors = models.ManyToManyField(to='Author')
price = models.DecimalField(max_digits=6, decimal_places=2)
publish = models.ForeignKey(to='Publish', on_delete='PROTECT', related_name='books')
pub_date = models.DateField()
read_num = models.IntegerField(default=0)
comment_num = models.IntegerField(default=0)
class Author(models.Model):
name = models.CharField(max_length=32)
tel = models.CharField(max_length=32)
age = models.IntegerField()
class Publish(models.Model):
name = models.CharField(max_length=32)
addr = models.CharField(max_length=32)
tel = models.CharField(max_length=32)
class AuthorDetail(models.Model):
addr = models.CharField(max_length=32)
author = models.OneToOneField(to='Author', on_delete='PROTECT')
特殊属性
记录对象.pk # 获取此记录对象的主键
常见的ORM操作
# 获取QuerySet对象的操作
models.<class_name>.objects.filter(,) # 有多个条件,则用逗号分隔表明与查询。返回的是QuerySet类型,相当于列表。
models.<class_name>.objects.exclude() # 排除不符合条件的,返回QuerySet
models.<class_name>.objects.all().order_by('<字段名>') # 按字段排序,如需反向排序,则在字段名前加-,返回QuerySet
models.<class_name>.objects.distinct() # 剔除相同的,返回QuerySet
# QuerySet的操作
<QuerySet>.first() # 返回QuerySet的第一个对象
<QuerySet>.last() # 返回QuerySet的最后一个对象
<QuerySet>.query # 返回执行此QuerySet的SQL语句
<QuerySet>.values('<字段1>', '<字段2>'...) # 返回QuerySet,但返回的是记录中的字段1、和字段2,QuerySet中每个元素是字典,字典形式是{'字段1':v1,'字段2':v2}
<QuerySet>.values_list() # 返回QuerySet,但返回的是记录中的字段1、和字段2,QuerySet中每个元素是元组,元组形式是(字段1的值,字段2的值)
<QuerySet>.count() # 个数
<QuerySet>.reverse() # 排序返转
<QuerySet>.exists() # 是否查询出对象
<QuerySet>.extract(select={键:值}) # 临时在数据库添加字段
# 获取对象的操作
models.<class_name>.objects.get(,...) # 返回符合条件的对象
models.模型类名._meta.app_label # 获取模型的app名称
models.模型类名._meta.model_name # 获取模型名称
models.模型类名._meta.get_field(字段名).verbose_name # 获取字段的verbose_name
关于字段中带有choice参数的一些用法,例子如下:
# models.py
class UserInfo(models.Model):
name = models.CharField(max_length=32, verbose_name='用户名')
email = models.CharField(max_length=32, verbose_name='邮箱')
gender_choice = (
(1, '男'),
(2, '女'),
)
gender = models.IntegerField(verbose_name='性别', choices=gender_choice, default=1)
status_choice = (
(1, '在线'),
(2, '离线'),
)
status = models.IntegerField(verbose_name='状态', choices=status_choice, default=1)
# 如果需要显示gender中值对应的名称,则如下
user_obj = models.UserInfo.objects.get(id=1)
print(user_obj.get_gender_display) # get_字段名_display是固定的用法。
# 显示status中对应的名称
print(user_obj.get_status_display)
这里特别举个例子说明一下extract函数的用法,比较复杂
article_fmt_date = models.Article.objects.extra(
select={'fmt_date': 'strftime("%%Y-%%m", create_time)'}).\
filter(user=user).values_list('fmt_date').\
annotate(articles_count_by_month=Count('nid'))
# 功能:生成临时字段fm_date,保存的是格式化后的日期
# extra方法会临时添加一个fmt_date字段到数据库
# 而strftime("%%Y-%%m", create_time)是sqlite的一个函数中会格式化日期格式,
# 所以值是可以经过原生的语句加工得出来的
# 把得出来的值给fmt_date字段保存,
# 在mysql中就使用函数date_format(create_time, "%%Y-%m")
articles_fmt_date = models.Article.objects.extra(where=['create_time like %s'], params=['2020-01%'])
# 利用extra调用select语句进行模糊查询
models.类名._meta.get_fields("字段名").related_model # 获取字段的关联表
常见的数据库操作可参考https://www.cnblogs.com/yuanchenqi/articles/7250680.html
数据库的操作主要有增删改查,这些操作都要在views.py中导入models文件,如下

新增数据
例子、新增一本书,名为'python',价格113元
方法一、
obj = models.Book.objects.create(title='python', price=113)
同时会返回创建的对象给变量
方法二、
先创建一个对象:obj = models.BOOK(title='python', price=113)
再使用此对象的save方法:obj.save()。但由于此方法会刷新所有的字段,效率比较低

方法三、以字典的形式添加,是方法一的变种
格式:models.Book.objects.create(**{'title:'python','price':113})

如果是使用request.POST作为参数传递,必须以**request.POST.dict()作为参数。
方法四、models.Book.objects.bulk_create(<books_list>) 参数为列表,批量新增
删除数据
例子、删除书名为python的书
models.Book.objects.filter(title='python')>.delete()

注意:此处会级联删除,例如,书本与作者是多对多的关系,把书删除了,则会把此书在多对多的第三张表中也会删除相应的数据。
更新数据
例子、更新书籍为python的价格为100元
models.Book.objects.filter(title='python').update(price=100)
查询
查询条件(适用于单表和跨表)
普通查询条件
id=1 # id为1 id__gt=1 # id大于1 id__lt=1 # id小于1 id__gte=1 # id大于等于1 id__lte=1 # id小于等于1 id__range=[1,3] # 查找范围1-2的 id__in=[1,2,3,4] # 查找在列表范围内的值 name__startswith='liang' # 查找名字以liang开头的记录 name__endwith='hui' # 查找名字以'hui'结尾的记录 name__contains='shu' # 查找名字包含shu的记录 name__icontains='alex' # 查找名字包含alex的记录,不区分大小写
F查询和Q查询(也适合用跨表)
如果需要比较数据库中同一条记录的两个字段或者在查询条件的条件是或关系,用常用查询是不能实现。这时候可以用到F查询和Q查询
导入:from django.db.modes import F, Q
一、F查询
作用1:主要是用于从字段获取值,但注意这个是在数据库级别获取的,不会放在python的内存空间中。
作用2:主要是解决竞争的问题。因为比如要进行投票,有多个用户同时进行投票,用户每提交一次就会对字段的值进行更新。但如果A用户获取了数据,同时B用户也获取了同一个字段数据,而A首先提交数据了。但B用户的数据还是A提交数据前的数据。这就会出现了问题。正常应该B用户获取的是A用户更新了字段后的数据值。此函数可以帮我们解决这个问题,这是因为F更新数据是在数据库保存或者更新后。
场景一、筛选出书本中评论数大于阅读数的书籍。
ret = models.Book.objects.filter(comment_num__gt=F('read_num')).values_list('title')
场景二、每本书涨价10元。
models.Book.objects.update(price=F('price') + 10)
二、Q查询
作用:之前的filter不能查两个条件是或关系的,而Q()可用于连接多个条件,一般用法Q(<条件>)。两个Q之间可用|表示或,&表示与。
注意:如<queryset>.filter(<cond1>,<cond2>,<cond3>...),如有Q查询和普通查询使用,Q查询必须在后面
例子一、查询评论数或阅读数大于100的书籍
ret = models.Book.objects.filter(Q(read_num__gt=100) | Q(comment_num__gt=100)).values('title')
另外一种使用方式
from django.db.models import Q
condition = Q()
condition.connector = 'OR' # 条件用或连接
condition.children.append(('read_num__gt', 100))
condition.children.append(('comment_num__gt', 100))
result = models.Book.objects.filter(condition)
例子二 、查询阅读数或评论数大于100而价格低于80的书籍。
ret = models.Book.objects.filter((Q(read_num__gt=100) | Q(comment_num__gt=100)) & Q(price__lt=80)).values_list('title')
查询
models.<class_name>.objects.filter(<con1>,<cond2>) # 有多个条件,则用逗号分隔表明与查询。返回的是QuerySet类型,相当于列表。
models.<class_name>.objects.exclude() # 排除不符合条件的,返回QuerySet
models.<class_name>.objects.all().order_by('<字段名>') # 按字段排序,如需反向排序,则在字段名前加-,返回QuerySet
models.<class_name>.objects.distinct() # 剔除相同的,返回QuerySet
models.<class_name>.objects.all().reverse() # 查询出来的结果反向排序,返回QuerySet

数据库操作(跨表)
新增数据
一对一和一对多
一对一和一对多新增书本的方式是一样的
新增一本书,出版社是东涌出版社的
方法1、publish_obj = models.Publish.objects.get(name='东涌出版社')
models.Book.objects.create(title=<v1>, price=<v2>, publish=publish_obj)
方法2、publish_obj = models.Publish.objects.get(name='东涌出版社')
models.Book.objects.create(title=<v1>, price=<v2>, publish_id=publish_obj.id)
多对多
新增书名为python,价格为100,作者是alex
author_obj = models.Author.objects.get(name='alex')
book_obj=models.Book.objects.create(title='python',price=100)
book_obj.authors.add(author_obj) # 用关联字段添加
新增书名为python,价格为100,作者是alex、diana
方法一、
author_obj1 = models.Author.objects.get(name='alex')
author_obj2 = models.Author.objects.get(name='diana')
book_obj=models.Book.objects.create(title='python',price=100)
book_obj.authors.add(author_obj1, author_obj2) # 用关联字段添加
方法二、
authors_list = [author_obj1, author_obj2]
book_obj.authors.add(*authors_list)
删除数据和更新数据
这些操作和单表操作一样的,请点此查看。
多对多关系解除与更新
关系解除:
例子、把python这本书的作者diana移动
book = models.Book.objects.get(name='python')
author_obj2 = models.Author.objects.get(name='diana')
book.authors.remove(author_obj2)
关系清除:
例子:名为python的书籍的所有作者移除
book = models.Book.objects.get(name='python')
book.authors.clear()
关系更新:
例子:名为python的书籍的作者更新为chen、zhen
author_obj1 = models.Author.objects.get(name='chen')
author_obj2 = models.Author.objects.get(name='zhen')
book = models.Book.objects.get(name='python')
book.set([author_obj1, author_obj2])
查询数据
在讲跨表查询前,首先要搞清楚正向查询和反向查询的概念
概念:在models的A表中有一个关联字段,关联到B表,从A表查B表的数据就是正向查询。B表查A表就是反向查询。
正向查询是用字段查,而反向查询是用表名(小写)查
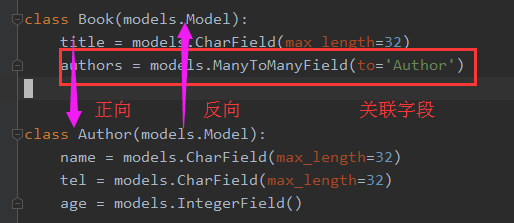
而查询是可基于对象或双下划线查询的。
基于对象
一对多(书本对出版社)
一、正查步骤
例子、查找书名为'python'的出版社名称
1、先获取书本对象:obj = models.Book.objects.filter(title='python').first()或obj = models.Book.objects.get(title='python')
注意是获取对象,而不是QuerySet
2、obj.publish.name # obj.<关联字段>获取一个对象
二、反查步骤
例子、查找出版社为东涌出版社出版过的书籍名称
1、获取出版社对象:obj = models.Publish.objects.filter(name="东涌出版社").first()或obj = models.Publish.objects.get(name="东涌出版社")
2、obj.books_set # 格式obj.<表名>_set返回相关的书籍QuerySet,注意如果在models中的关联字段有定义related_name参数(一般用于反查),则用此参数关联,否则用表名关联,以下反查均适合使用。
多对多(书本对作者)
一、正查步骤
例子、查找书名为'python'的作者名称
1、先获取书本对象:obj = models.Book.objects.filter(title='python').first()或obj = models.Book.objects.get(title='python')
2、obj.authors # obj.<关联字段>获取QuerySet
二、反查步骤
例子、查找作者为Syvia社出版过的书籍名称
1、获取出版社对象:obj = models.Author.objects.filter(name="Syvia").first()或obj = models.Author.objects.get(name="Syvia")
2、obj.book_set # 格式obj.<表名>_set 返回相关的书籍QuerySet
一对一(作者对作者明细)
一、正查步骤
例子、查找住在东涌的作者名称
1、先获取authordetail对象:obj = models.AuthorDetail.objects.filter(addr='东涌').first()或obj = models.AuthorDetail.objects.get(addr='东涌')
2、obj.author # obj.<关联字段>获取作者对象
二、反查步骤
例子、查找作者Syvia的地址
1、获取author社对象:obj = models.Author.objects.filter(name="Syvia").first()或obj = models.Author.objects.get(name="Syvia")
2、obj.authordetail # obj.<表名> 获取关联的明细表
总结:正向查询按字段,反向查询按表名查询,如果在models中定义了related_name,则反向用related_name。
基于双下划线
这种情况一般是在配合QuerySet中的values或values_list方法使用的,比基于对象的常用,也是正查按字段,反查按表名查询
一对多
例子、查找书名为'python'的出版社名称
正向查询的方法:
obj = models.Book.objects.filter(title='python').values('publish__name') # 先过滤出书,再定位到出版社名称
反向查询的方法
models.Publish.objects.filter(books__title='python').values('name') # 先查出版过python的出版社对象
多对多
例子、查找书名为'python'的作者名称
正向查询方法:
models.Book.objects.filter(title='python').values('authors__name') # 过滤出书本,再正向查询作者名称
反向查询方法:
models.Author.objects.filter(book__title='python').values('name') # 通过书本名称反查出作者
一对一
例子、查找住在东涌的作者名称
正向查询的方法:
models.AuthorDetail.filter(addr='东涌').values('author__name')
反向查询的方法:
models.Author.filter(authordetail__addr='东涌').values('name')
跨多表查询
例子、查询地址在东涌的作者出版过的书本名称
models.Book.objects.filter(authors__authordetail__addr="东涌").value('title')
models.Author.objects.filter(authordetail__addr='东涌').values('book__title')
高阶查询
以上查询只是从表中查出原始数据,而高阶查询除了可查数据,也可对数据进行统计,分为聚合查询和分组查询
聚合查询
什么是聚合?可对数据表某一字段进行算平均分、最大值、最小值、总数、计数等计算,一般配合分组查询使用
使用步骤
一、from django.db.modes import Sum, Avg, Max, Min, Count
二、
分组查询
分组查询:相当于Excel中的分类汇总功能,主要用到QuerySet中的annotate函数,用于生成新的QuerySet。

例子如下:
def aggregation_query(request): from django.db.models import Sum, Avg, Max, Min, Count # ret = models.Book.objects.aggregate(Avg('price')) # print(ret) # 统计每一本书的价格 # ret2 = models.Book.objects.annotate(jiage=Sum('price')).values('title', 'jiage', 'id') # print(ret2) # 统计每一本书的作者数 # ret3 = models.Book.objects.annotate(authors_num=Count('authors')).values('title', 'authors_num') # print(ret3) # 统计出版社出版的书籍的总价格 # 方法1 # ret4 = models.Publish.objects.annotate(sum_price=Sum('books__price')).values('name', 'sum_price') # print(ret4) # 方法2(常用的方法) # ret5 = models.Book.objects.values('publish__name').annotate(sum_price=Sum('price')).values('publish__name', 'sum_price') # print(ret5) # 统计每个出版社最便宜的书 # 方法1 # ret6 = models.Publish.objects.annotate(min_price=Min('books__price')).values('name', 'min_price') # print(ret6) # 方法2 # ret7 = models.Book.objects.values('publish__name').annotate(min_price=Min('price')).values('publish__name', 'min_price') # print(ret7) # 统计每个以Py开头的书籍的作者数 # 方法1 # ret8 = models.Book.objects.filter(title__startswith='Py').annotate(authors_count=Count('authors')).values('title', 'authors_count') # print(ret8) # 方法2 # ret9 = models.Author.objects.filter(book__title__istartswith='Py').values('book__title').annotate( # authors_count=Count('name')).values('book__title', 'authors_count') # print(ret9) # 统计不止一个作者的图书 # 方法1 # ret10 = models.Book.objects.annotate(authors_count=Count('authors')).filter(authors_count__gt=1).values('title', # print(ret10) # 方法2 ret11 = models.Author.objects.values('book__title').annotate(authors_count=Count('book__title')).filter( authors_count__gt=1).values('book__title', 'authors_count') print(ret11) return HttpResponse('OK')
数据库的事务操作
有时候数据库需要保持两个操作必须都要同时完成,有一个没完成就需要回滚。比如A转钱给B,必须要A的钱数据减少了,而B的增加了才算成功转钱。如果A的少了B又有增加,那就不行了。步骤如下:
from django.db import transaction # 导入事备操作
with transaction.atomic(): # 把需要事务操作的包起来
models.ArticleUpDown.objects.create(article_id=article_id, user_id=user_id)
models.Article.objects.filter(nid=article_id).update(up_count=F('up_count') + 1)
中间件
什么是Django的中间件
完整django请求的生命周期
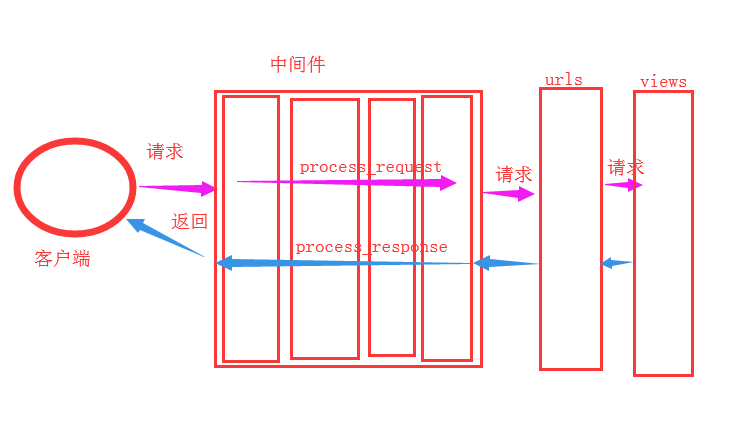
如果有中间件其中的请求不通过会这样:
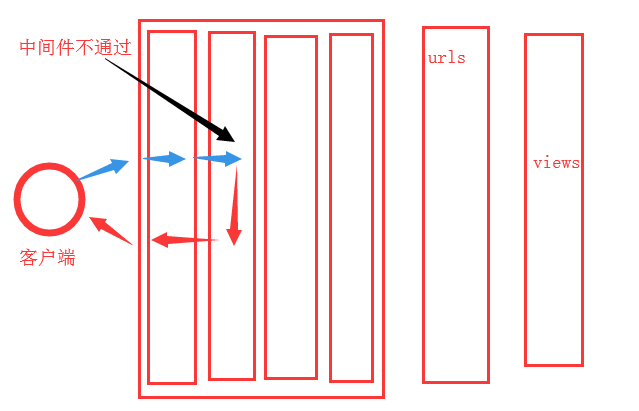
所以说中间件其实是在路由系统前就会发生的,在django中是一个类,用其中的process_request函数处理;如果views中函数处理完了以后,则也是要经过中间件来处理,通过相关类中的procee_response处理;其实也可以用process_view对视图函数处理,process_exception对view中函数出现异常处理,process_template_response是在视图中返回的对象中含有render方法才执行。
作用:例如可以对于所有的客户请求,在到达路由系统前,作一些验证的工作。也可以作一些视图函数处理后的后期工作。其实就是对请求的事前事后的统一处理。
关于process_view

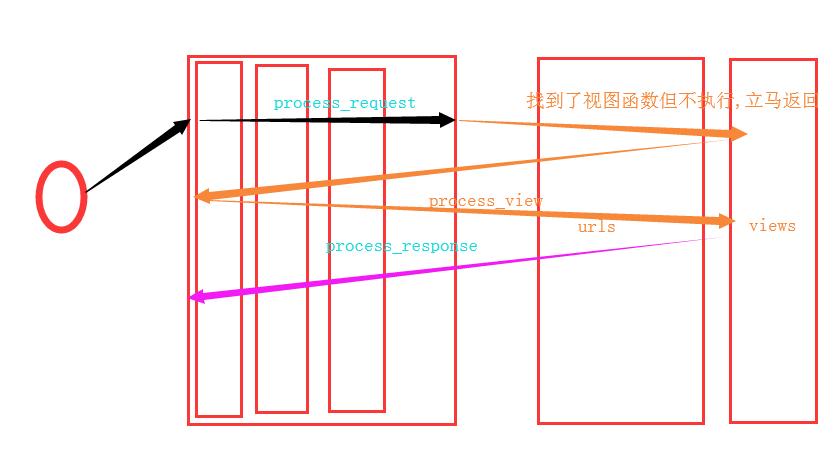
process_exception

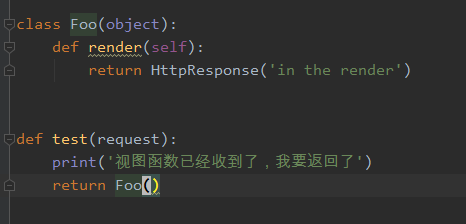
process_template_response

执行条件:就是views中返回的对象中含有render方法
自定义中间件
步骤一、创建文件夹
步骤二、写中间件的类
(1)、导入:from django.utils.deprecation import MiddlewareMixin
(2)、写类,需继承MiddlewareMixin,但注意写以下方法:process_request和process_response、process_view、process_exception、process_template_response
1 from django.utils.deprecation import MiddlewareMixin 2 3 4 class route1(MiddlewareMixin): 5 def process_request(self, request): 6 print('路由1') 7 8 def process_response(self, request, response): 9 print('返回1') 10 return response 11 12 13 class route2(MiddlewareMixin): 14 def process_request(self, request): 15 print('路由2') 16 17 def process_response(self, request, response): 18 print('返回2') 19 return response 20 21 class route3(MiddlewareMixin): 22 def process_request(self, request): 23 print('路由3') 24 25 def process_response(self, request, response): 26 print('返回3') 27 return response
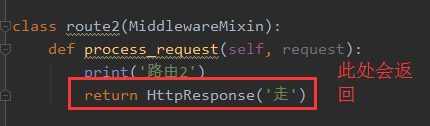
1 from django.utils.deprecation import MiddlewareMixin 2 from django.http import HttpResponse 3 4 5 class route1(MiddlewareMixin): 6 def process_request(self, request): 7 print('路由1') 8 9 def process_response(self, request, response): 10 print('返回1') 11 return response 12 13 14 class route2(MiddlewareMixin): 15 def process_request(self, request): 16 print('路由2') 17 return HttpResponse('走') 18 19 def process_response(self, request, response): 20 print('返回2') 21 return response 22 23 class route3(MiddlewareMixin): 24 def process_request(self, request): 25 print('路由3') 26 27 def process_response(self, request, response): 28 print('返回3') 29 return response
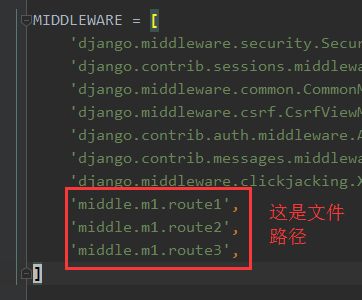
步骤三、在settings.py中加入路径
缓存
现在网络上基本上都是动态网页,而如果所有数据都要经过view函数处理渲染,这必然要耗费内存、CPU资源。而如果有缓存,则不需要函数处理,直接从缓存中返回数据给客户端,如此一来,则会大大减轻了计算机的负担。
6种缓存引擎
一、开发调试
1 # 此为开始调试用,实际内部不做任何操作 2 # 配置: 3 CACHES = { 4 'default': { 5 'BACKEND': 'django.core.cache.backends.dummy.DummyCache', # 引擎 6 'TIMEOUT': 300, # 缓存超时时间(默认300,None表示永不过期,0表示立即过期) 7 'OPTIONS':{ 8 'MAX_ENTRIES': 300, # 最大缓存个数(默认300) 9 'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3) 10 }, 11 'KEY_PREFIX': '', # 缓存key的前缀(默认空) 12 'VERSION': 1, # 缓存key的版本(默认1) 13 'KEY_FUNCTION' 函数名 # 生成key的函数(默认函数会生成为:【前缀:版本:key】) 14 } 15 } 16 17 18 # 自定义key 19 def default_key_func(key, key_prefix, version): 20 """ 21 Default function to generate keys. 22 23 Constructs the key used by all other methods. By default it prepends 24 the `key_prefix'. KEY_FUNCTION can be used to specify an alternate 25 function with custom key making behavior. 26 """ 27 return '%s:%s:%s' % (key_prefix, version, key) 28 29 def get_key_func(key_func): 30 """ 31 Function to decide which key function to use. 32 33 Defaults to ``default_key_func``. 34 """ 35 if key_func is not None: 36 if callable(key_func): 37 return key_func 38 else: 39 return import_string(key_func) 40 return default_key_func
注意此引擎的配置均可用于以下5种
二、内存
# 此缓存将内容保存至内存的变量中 # 配置: CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.locmem.LocMemCache', 'LOCATION': 'unique-snowflake', } } # 注:其他配置同开发调试版本
三、文件
1 # 此缓存将内容保存至文件 2 # 配置: 3 4 CACHES = { 5 'default': { 6 'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache', 7 'LOCATION': '/var/tmp/django_cache', 8 } 9 } 10 # 注:其他配置同开发调试版本
四、数据库
1 # 此缓存将内容保存至数据库 2 3 # 配置: 4 CACHES = { 5 'default': { 6 'BACKEND': 'django.core.cache.backends.db.DatabaseCache', 7 'LOCATION': 'my_cache_table', # 数据库表 8 } 9 } 10 11 # 注:执行创建表命令 python manage.py createcachetable
五、Memcache缓存(python-memcached模块)
1 # 此缓存使用python-memcached模块连接memcache 2 3 CACHES = { 4 'default': { 5 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache', 6 'LOCATION': '127.0.0.1:11211', 7 } 8 } 9 10 CACHES = { 11 'default': { 12 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache', 13 'LOCATION': 'unix:/tmp/memcached.sock', 14 } 15 } 16 17 CACHES = { 18 'default': { 19 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache', 20 'LOCATION': [ 21 '172.19.26.240:11211', 22 '172.19.26.242:11211', 23 ] 24 } 25 }
六、Memcache缓存(pylibmc模块)
1 # 此缓存使用pylibmc模块连接memcache 2 3 CACHES = { 4 'default': { 5 'BACKEND': 'django.core.cache.backends.memcached.PyLibMCCache', 6 'LOCATION': '127.0.0.1:11211', 7 } 8 } 9 10 CACHES = { 11 'default': { 12 'BACKEND': 'django.core.cache.backends.memcached.PyLibMCCache', 13 'LOCATION': '/tmp/memcached.sock', 14 } 15 } 16 17 CACHES = { 18 'default': { 19 'BACKEND': 'django.core.cache.backends.memcached.PyLibMCCache', 20 'LOCATION': [ 21 '172.19.26.240:11211', 22 '172.19.26.242:11211', 23 ] 24 } 25 }
七、Redis缓存(依赖:pip3 install django-redis)
1 CACHES = { 2 "default": { 3 "BACKEND": "django_redis.cache.RedisCache", 4 "LOCATION": "redis://127.0.0.1:6379", 5 "OPTIONS": { 6 "CLIENT_CLASS": "django_redis.client.DefaultClient", 7 "CONNECTION_POOL_KWARGS": {"max_connections": 100} 8 # "PASSWORD": "密码", 9 } 10 } 11 }
from django_redis import get_redis_connection conn = get_redis_connection("default")
应用方法(以文件为例说明)
步骤一、在settings.py中导入缓存引擎
CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache', 'LOCATION': os.path.join(BASE_DIR, 'cache'), } }
步骤二、缓存的应用
根据范围的不同,缓存的应用分了三个级别
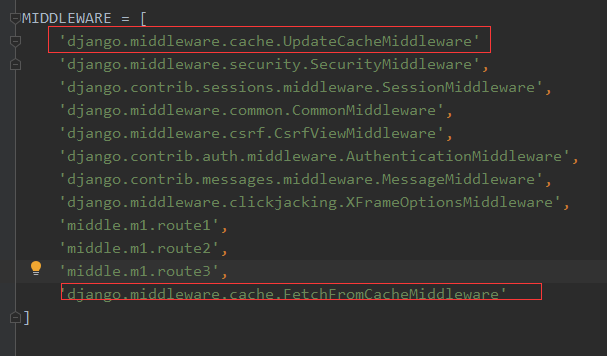
一、全网站应用
在setting.py中的中间件的头尾添加中间件
1 MIDDLEWARE = [ 2 'django.middleware.cache.UpdateCacheMiddleware' 3 'django.middleware.security.SecurityMiddleware', 4 'django.contrib.sessions.middleware.SessionMiddleware', 5 'django.middleware.common.CommonMiddleware', 6 'django.middleware.csrf.CsrfViewMiddleware', 7 'django.contrib.auth.middleware.AuthenticationMiddleware', 8 'django.contrib.messages.middleware.MessageMiddleware', 9 'django.middleware.clickjacking.XFrameOptionsMiddleware', 10 'middle.m1.route1', 11 'middle.m1.route2', 12 'middle.m1.route3', 13 'django.middleware.cache.FetchFromCacheMiddleware' 14 ]
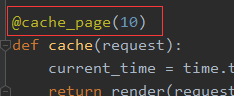
二、单视图
1、先导入模块from django.views.decorators.cache import cache_page
2、在对应的view函数中加上加上装饰器@cache_page(seconds)
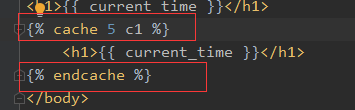
三、模板中的使用
1、在模板中引入模块{% load cache %}
2、然后在需要缓存的地方加上{% cache <seconds> <key> %}
....
{% endcache %}
信号
什么是信号
信号其实很简单。想想,在体育课上,老师发出口令“向左转”,学生就会根据口令做动作。其实你可以这样理解,口令即是个信号,指令即是个信号。而在django里面,其实就内置了大量的信号供我们使用,只要触发这些信号,就可以做“动作”,在django中即是做出对应的函数的动作。可注册多个函数。
Django内置信号
Model signals pre_init # django的modal执行其构造方法前,自动触发 post_init # django的modal执行其构造方法后,自动触发 pre_save # django的modal对象保存前,自动触发 post_save # django的modal对象保存后,自动触发 pre_delete # django的modal对象删除前,自动触发 post_delete # django的modal对象删除后,自动触发 m2m_changed # django的modal中使用m2m字段操作第三张表(add,remove,clear)前后,自动触发 class_prepared # 程序启动时,检测已注册的app中modal类,对于每一个类,自动触发 Management signals pre_migrate # 执行migrate命令前,自动触发 post_migrate # 执行migrate命令后,自动触发 Request/response signals request_started # 请求到来前,自动触发 request_finished # 请求结束后,自动触发 got_request_exception # 请求异常后,自动触发 Test signals setting_changed # 使用test测试修改配置文件时,自动触发 template_rendered # 使用test测试渲染模板时,自动触发 Database Wrappers connection_created # 创建数据库连接时,自动触发
以信号post_init说明信号量的使用
步骤一、创建一个python文件,注册信号绑定的事件,具体步骤
1、导入模块,相关的信号模块如下:
from django.core.signals import request_finished
from django.core.signals import request_started
from django.core.signals import got_request_exception
from django.db.models.signals import class_prepared
from django.db.models.signals import pre_init, post_init
from django.db.models.signals import pre_save, post_save
from django.db.models.signals import pre_delete, post_delete
from django.db.models.signals import m2m_changed
from django.db.models.signals import pre_migrate, post_migrate
from django.test.signals import setting_changed
from django.test.signals import template_rendered
from django.db.backends.signals import connection_created
2、定义函数
3、绑定信号和函数
1 from django.db.models.signals import post_init 2 3 4 def callback(sender, **kwargs): 5 print('in the signal callback func') 6 7 8 post_init.connect(callback)
步骤二、在<project_name>.__init__.py中导入步骤一创建的py文件。为什么在这里导入?那是因为每次django运行时都会运行此文件。
这样每一次创建数据时都会触发callback函数
自定义信号
一、定义信号
1 import django.dispatch 2 pizza_done = django.dispatch.Signal(providing_args=["toppings", "size"])
b. 注册信号
def callback(sender, **kwargs): print("callback") print(sender,kwargs) pizza_done.connect(callback)
c. 触发信号
在view中触发信号
1 from 路径 import pizza_done 2 3 pizza_done.send(sender='seven',toppings=123, size=456)
由于内置信号的触发者已经集成到Django中,所以其会自动调用,而对于自定义信号则需要开发者在任意位置触发。
表单验证
表单验证是在views函数中执行的,如下:
from django.shortcuts import render, redirect from django import forms from app01 import models from django.views.decorators.cache import cache_page from django.http import HttpResponse import time class FM(forms.Form): """验证表单""" # 此名称必须要与需要验证的html中的name属性对应 user = forms.CharField(error_messages={'required': '用户名不能为空'}) pwd = forms.CharField( min_length=6, max_length=12, error_messages={'required': '密码不能为空', 'min_length': '密码至少需要6位', 'max_length': "密码不多于12位"} ) email = forms.EmailField(error_messages={'required': '邮箱不能为空'}) def fm(request): if request.method == 'GET': return render(request, 'fm.html') elif request.method == 'POST': # 获取验证对象 obj = FM(request.POST) res = obj.is_valid() # 验证通过 if res: print(obj.cleaned_data) # 验证不通过 else: # 以下加上as_json()就作为字典呈现,如果需要以字符串呈现则需要删除as_json() print(obj.errors.as_json()) return redirect('/fm/')
关键点:
1、导入:from django import forms
2、创建类,需继承forms.Form
3、类中的属性名需与表单提交的标签name属性一致
4、获取名单验证结果对象obj = FM(request.POST)
5、obj.is_valid():表单验证结果,True或False
6、obj.cleaned_data:表单通过的数据
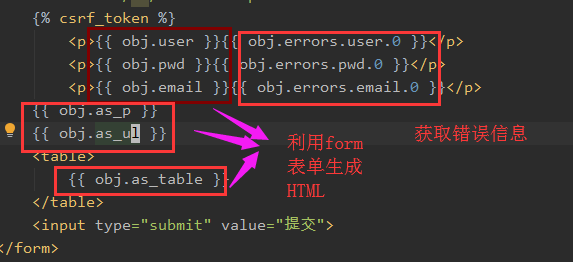
7、obj.errors:表单不通过的所有信息
obj.errors['user'][0] 获取user不能通过的第一条信息
8、obj.errors.as_json():表单不通过的信息用json格式显示
9、用了表单验证,在HTML中不用单独写input标签了
在Form表单生成的HTML写类
这个就需要用到widget,这个插件可以帮我们生成HTML,几乎写所有的input系列的标签都靠这个插件完成,具体步骤如下:
一、导入:from django.forms import widgets, fields
二、在form表单类中,在写表单属性时添加widget参数,如下:
1 from django.shortcuts import render, redirect 2 from django import forms 3 from django.forms import widgets, fields 4 class FM(forms.Form): 5 """验证表单""" 6 # 此名称必须要与需要验证的html中的name属性对应 7 user = fields.CharField(error_messages={'required': '用户名不能为空'}, 8 widget=widgets.Textarea(attrs={'class': 'c1'})) 9 pwd = fields.CharField( 10 min_length=6, 11 max_length=12, 12 error_messages={'required': '密码不能为空', 13 'min_length': '密码至少需要6位', 14 'max_length': "密码不多于12位"} 15 ) 16 email = fields.EmailField(error_messages={'required': '邮箱不能为空'})

其实总的来说,widget生成的是HTML,字段是用来验证的。
Django内置和插件
Field required=True, 是否允许为空 widget=None, HTML插件 label=None, 用于生成Label标签或显示内容 initial=None, 初始值 help_text='', 帮助信息(在标签旁边显示) error_messages=None, 错误信息 {'required': '不能为空', 'invalid': '格式错误'} show_hidden_initial=False, 是否在当前插件后面再加一个隐藏的且具有默认值的插件(可用于检验两次输入是否一直) validators=[], 自定义验证规则 localize=False, 是否支持本地化 disabled=False, 是否可以编辑 label_suffix=None Label内容后缀 CharField(Field) max_length=None, 最大长度 min_length=None, 最小长度 strip=True 是否移除用户输入空白 IntegerField(Field) max_value=None, 最大值 min_value=None, 最小值 FloatField(IntegerField) ... DecimalField(IntegerField) max_value=None, 最大值 min_value=None, 最小值 max_digits=None, 总长度 decimal_places=None, 小数位长度 BaseTemporalField(Field) input_formats=None 时间格式化 DateField(BaseTemporalField) 格式:2015-09-01 TimeField(BaseTemporalField) 格式:11:12 DateTimeField(BaseTemporalField)格式:2015-09-01 11:12 DurationField(Field) 时间间隔:%d %H:%M:%S.%f ... RegexField(CharField) regex, 自定制正则表达式 max_length=None, 最大长度 min_length=None, 最小长度 error_message=None, 忽略,错误信息使用 error_messages={'invalid': '...'} EmailField(CharField) ... FileField(Field) allow_empty_file=False 是否允许空文件 ImageField(FileField) ... 注:需要PIL模块,pip3 install Pillow 以上两个字典使用时,需要注意两点: - form表单中 enctype="multipart/form-data" - view函数中 obj = MyForm(request.POST, request.FILES) URLField(Field) ... BooleanField(Field) ... NullBooleanField(BooleanField) ... ChoiceField(Field) ... choices=(), 选项,如:choices = ((0,'上海'),(1,'北京'),) required=True, 是否必填 widget=None, 插件,默认select插件 label=None, Label内容 initial=None, 初始值 help_text='', 帮助提示 ModelChoiceField(ChoiceField) ... django.forms.models.ModelChoiceField queryset, # 查询数据库中的数据 empty_label="---------", # 默认空显示内容 to_field_name=None, # HTML中value的值对应的字段 limit_choices_to=None # ModelForm中对queryset二次筛选 ModelMultipleChoiceField(ModelChoiceField) ... django.forms.models.ModelMultipleChoiceField TypedChoiceField(ChoiceField) coerce = lambda val: val 对选中的值进行一次转换 empty_value= '' 空值的默认值 MultipleChoiceField(ChoiceField) ... TypedMultipleChoiceField(MultipleChoiceField) coerce = lambda val: val 对选中的每一个值进行一次转换 empty_value= '' 空值的默认值 ComboField(Field) fields=() 使用多个验证,如下:即验证最大长度20,又验证邮箱格式 fields.ComboField(fields=[fields.CharField(max_length=20), fields.EmailField(),]) MultiValueField(Field) PS: 抽象类,子类中可以实现聚合多个字典去匹配一个值,要配合MultiWidget使用 SplitDateTimeField(MultiValueField) input_date_formats=None, 格式列表:['%Y--%m--%d', '%m%d/%Y', '%m/%d/%y'] input_time_formats=None 格式列表:['%H:%M:%S', '%H:%M:%S.%f', '%H:%M'] FilePathField(ChoiceField) 文件选项,目录下文件显示在页面中 path, 文件夹路径 match=None, 正则匹配 recursive=False, 递归下面的文件夹 allow_files=True, 允许文件 allow_folders=False, 允许文件夹 required=True, widget=None, label=None, initial=None, help_text='' GenericIPAddressField protocol='both', both,ipv4,ipv6支持的IP格式 unpack_ipv4=False 解析ipv4地址,如果是::ffff:192.0.2.1时候,可解析为192.0.2.1, PS:protocol必须为both才能启用 SlugField(CharField) 数字,字母,下划线,减号(连字符) ... UUIDField(CharField) uuid类型 ...
1 TextInput(Input) 2 NumberInput(TextInput) 3 EmailInput(TextInput) 4 URLInput(TextInput) 5 PasswordInput(TextInput) 6 HiddenInput(TextInput) 7 Textarea(Widget) 8 DateInput(DateTimeBaseInput) 9 DateTimeInput(DateTimeBaseInput) 10 TimeInput(DateTimeBaseInput) 11 CheckboxInput 12 Select 13 NullBooleanSelect 14 SelectMultiple 15 RadioSelect 16 CheckboxSelectMultiple 17 FileInput 18 ClearableFileInput 19 MultipleHiddenInput 20 SplitDateTimeWidget 21 SplitHiddenDateTimeWidget 22 SelectDateWidget
常用的选择插件
1 # 单radio,值为字符串 2 # user = fields.CharField( 3 # initial=2, 4 # widget=widgets.RadioSelect(choices=((1,'上海'),(2,'北京'),)) 5 # ) 6 7 # 单radio,值为字符串 8 # user = fields.ChoiceField( 9 # choices=((1, '上海'), (2, '北京'),), 10 # initial=2, 11 # widget=widgets.RadioSelect 12 # ) 13 14 # 单select,值为字符串 15 # user = fields.CharField( 16 # initial=2, 17 # widget=widgets.Select(choices=((1,'上海'),(2,'北京'),)) 18 # ) 19 20 # 单select,值为字符串 21 # user = fields.ChoiceField( 22 # choices=((1, '上海'), (2, '北京'),), 23 # initial=2, 24 # widget=widgets.Select 25 # ) 26 27 # 多选select,值为列表 28 # user = fields.MultipleChoiceField( 29 # choices=((1,'上海'),(2,'北京'),), 30 # initial=[1,], 31 # widget=widgets.SelectMultiple 32 # ) 33 34 35 # 单checkbox 36 # user = fields.CharField( 37 # widget=widgets.CheckboxInput() 38 # ) 39 40 41 # 多选checkbox,值为列表 42 # user = fields.MultipleChoiceField( 43 # initial=[2, ], 44 # choices=((1, '上海'), (2, '北京'),), 45 # widget=widgets.CheckboxSelectMultiple 46 # )
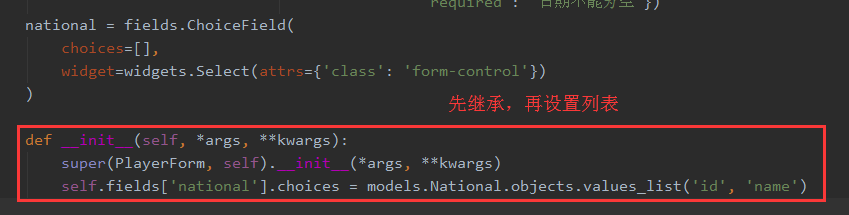
但以上选择插件使用时,比如Select插件,只会静态生成一个选择列表,当有新数据添加到数据库时,此列表不会自动更新。解决办法是重写构造函数,如下:
自定义验证规则
1 from django.forms import Form 2 from django.forms import widgets 3 from django.forms import fields 4 from django.core.validators import RegexValidator 5 6 class MyForm(Form): 7 user = fields.CharField( 8 validators=[RegexValidator(r'^[0-9]+$', '请输入数字'), RegexValidator(r'^159[0-9]+$', '数字必须以159开头')], 9 )
1 import re 2 from django.forms import Form 3 from django.forms import widgets 4 from django.forms import fields 5 from django.core.exceptions import ValidationError 6 7 8 # 自定义验证规则 9 def mobile_validate(value): 10 mobile_re = re.compile(r'^(13[0-9]|15[012356789]|17[678]|18[0-9]|14[57])[0-9]{8}$') 11 if not mobile_re.match(value): 12 raise ValidationError('手机号码格式错误') 13 14 15 class PublishForm(Form): 16 17 18 title = fields.CharField(max_length=20, 19 min_length=5, 20 error_messages={'required': '标题不能为空', 21 'min_length': '标题最少为5个字符', 22 'max_length': '标题最多为20个字符'}, 23 widget=widgets.TextInput(attrs={'class': "form-control", 24 'placeholder': '标题5-20个字符'})) 25 26 27 # 使用自定义验证规则 28 phone = fields.CharField(validators=[mobile_validate, ], 29 error_messages={'required': '手机不能为空'}, 30 widget=widgets.TextInput(attrs={'class': "form-control", 31 'placeholder': u'手机号码'})) 32 33 email = fields.EmailField(required=False, 34 error_messages={'required': u'邮箱不能为空','invalid': u'邮箱格式错误'}, 35 widget=widgets.TextInput(attrs={'class': "form-control", 'placeholder': u'邮箱'}))
1 from django import forms 2 from django.forms import fields 3 from django.forms import widgets 4 from django.core.exceptions import ValidationError 5 from django.core.validators import RegexValidator 6 7 class FInfo(forms.Form): 8 username = fields.CharField(max_length=5, 9 validators=[RegexValidator(r'^[0-9]+$', 'Enter a valid extension.', 'invalid')], ) 10 email = fields.EmailField() 11 12 def clean_username(self): 13 """ 14 Form中字段中定义的格式匹配完之后,执行此方法进行验证 15 :return: 16 """ 17 value = self.cleaned_data['username'] 18 if "666" in value: 19 raise ValidationError('666已经被玩烂了...', 'invalid') 20 return value
1 from django.forms import Form 2 from django.forms import widgets 3 from django.forms import fields 4 5 from django.core.validators import RegexValidator 6 7 8 ############## 自定义字段 ############## 9 class PhoneField(fields.MultiValueField): 10 def __init__(self, *args, **kwargs): 11 # Define one message for all fields. 12 error_messages = { 13 'incomplete': 'Enter a country calling code and a phone number.', 14 } 15 # Or define a different message for each field. 16 f = ( 17 fields.CharField( 18 error_messages={'incomplete': 'Enter a country calling code.'}, 19 validators=[ 20 RegexValidator(r'^[0-9]+$', 'Enter a valid country calling code.'), 21 ], 22 ), 23 fields.CharField( 24 error_messages={'incomplete': 'Enter a phone number.'}, 25 validators=[RegexValidator(r'^[0-9]+$', 'Enter a valid phone number.')], 26 ), 27 fields.CharField( 28 validators=[RegexValidator(r'^[0-9]+$', 'Enter a valid extension.')], 29 required=False, 30 ), 31 ) 32 super(PhoneField, self).__init__(error_messages=error_messages, fields=f, require_all_fields=False, *args, 33 **kwargs) 34 35 def compress(self, data_list): 36 """ 37 当用户验证都通过后,该值返回给用户 38 :param data_list: 39 :return: 40 """ 41 return data_list 42 43 ############## 自定义插件 ############## 44 class SplitPhoneWidget(widgets.MultiWidget): 45 def __init__(self): 46 ws = ( 47 widgets.TextInput(), 48 widgets.TextInput(), 49 widgets.TextInput(), 50 ) 51 super(SplitPhoneWidget, self).__init__(ws) 52 53 def decompress(self, value): 54 """ 55 处理初始值,当初始值initial不是列表时,调用该方法 56 :param value: 57 :return: 58 """ 59 if value: 60 return value.split(',') 61 return [None, None, None]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号