
Mysql
在Linux上的安装
1、yum install mariadb mariadb-server -y
2、service mariadb start
3、chkconfig mariadb on
Linux上的启动、关闭、连接、密码设置
1、启动服务:service mariadb start
开机启动:chkconfig mariadb on
2、关闭服务:mysqladmin -u root -p shutdown
3、连接:mysql -u<username> -p
4、为root用户添加密码
mysqladmin -uroot password
有时候会输入任意一个帐号都能登陆
原因:因为在mysql数据库中的user表中含User为空的用户
解决办法:删除这些用户
用户授权
grant <privileges> on <database>.<table> to <username>@<hostname> identified <password>
1、privileges权限:SELECT,INSERT,UPDATE,DELETE,CREATE,DROP或All privileges
2、<database>、<table>:对应的名称,或可使用通配符*
3、username、hostname:为允许远程登陆的主机或IP,可使用通配符%代表全部,不用加'
4、password:必须要加单引号
如果root不能登陆,可使用以下命令跳过权限的检测
mysqld_safe --user=root --skip-grant-tables
常用命令
1、show databases;
查看数据库
2、use <database>;
进入某一数据库
3、show tables;
查看某数据库中的表
4、desc <table_name>;
查看表结构
5、select * from user\G
查看user表中的内容。
6、show grants for <username>;
显示username的权限
7、show columns from <table>;
类似于desc,查看表结构
8、show create database <databasename> <charset utf8>;
查看已经创建的数据库,charset 可指定字符集
9、drop database <databasename>:
删除数据库
数据类型
MySQL中定义数据字段的类型对你数据库的优化是非常重要的。
MySQL支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。
数值类型
MySQL支持所有标准SQL数值数据类型。
这些类型包括严格数值数据类型(INTEGER、SMALLINT、DECIMAL和NUMERIC),以及近似数值数据类型(FLOAT、REAL和DOUBLE PRECISION)。
关键字INT是INTEGER的同义词,关键字DEC是DECIMAL的同义词。
BIT数据类型保存位字段值,并且支持MyISAM、MEMORY、InnoDB和BDB表。
作为SQL标准的扩展,MySQL也支持整数类型TINYINT、MEDIUMINT和BIGINT。下面的表显示了需要的每个整数类型的存储和范围。
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 字节 | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 字节 | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 字节 | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 字节 | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 字节 | (-9 233 372 036 854 775 808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 字节 | (-3.402 823 466 E+38,1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 字节 | (1.797 693 134 862 315 7 E+308,2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
日期和时间类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
每个时间类型有一个有效值范围和一个"零"值,当指定不合法的MySQL不能表示的值时使用"零"值。
TIMESTAMP类型有专有的自动更新特性,将在后面描述。
| 类型 | 大小 (字节) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2037 年某时 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。该节描述了这些类型如何工作以及如何在查询中使用这些类型。
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255字节 | 定长字符串 |
| VARCHAR | 0-65535 字节 | 变长字符串 |
| TINYBLOB | 0-255字节 | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255字节 | 短文本字符串 |
| BLOB | 0-65 535字节 | 二进制形式的长文本数据 |
| TEXT | 0-65 535字节 | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215字节 | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215字节 | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295字节 | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295字节 | 极大文本数据 |
CHAR和VARCHAR类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
BINARY和VARBINARY类类似于CHAR和VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值值。
BLOB是一个二进制大对象,可以容纳可变数量的数据。有4种BLOB类型:TINYBLOB、BLOB、MEDIUMBLOB和LONGBLOB。它们只是可容纳值的最大长度不同。
有4种TEXT类型:TINYTEXT、TEXT、MEDIUMTEXT和LONGTEXT。这些对应4种BLOB类型,有相同的最大长度和存储需求。
创建数据库、表,插入数据
1、创建数据库create database <name> <charset utf8>;
并且支持utf8字符集
2、创建表:create table(column_name column_type)
create table student(
-> id int auto_increment,
-> name char(32) not null,
-> age int not null,
-> register_date date not null,
-> primary key(id));
3、插入数据:insert into <table_name>(column_name1,column_name2...) values(val1,val2);
insert into student(name,age,register_date) values('Treelight',30,'2019-6-27');
查询数据
格式:select <col>,<col2>... from <table> where <clause> <limit m> <offset n>
offset:默认为0,就是从第n+1条记录开始查
limit:显示多少条记录
col:可以是多个字段名称,也可以用*代替所有字段
clause:条件,可用and或or连接多个条件,也可以用like进行模糊查询。
模糊查询,如:select * from student where register_date like '2019-06%'
升序降序:把查出来的结果按照某字段排序,使用关键字order by,默认是升序,加上desc为降序
升序:select * from student order by age
降序:select * from student order by age desc
修改数据:
格式:update <table> set col1=val1,col2=val2... where <clause>
数据的分组统计:
类似于excel的分类汇总:
+----+-----------+-----+---------------+
| id | name | age | register_date |
+----+-----------+-----+---------------+
| 1 | Treelight | 30 | 2019-06-27 |
| 2 | Treelight | 20 | 2019-06-27 |
| 3 | Treelight | 10 | 2019-06-27 |
| 4 | Treelight | 15 | 2018-04-27 |
| 5 | Alex | 20 | 2018-04-27 |
| 6 | Alex | 30 | 2019-06-27 |
+----+-----------+-----+---------------+
select coalesce(name,'总数'),count(name) as name_num from student group by name with rollup;
+-------------------------+----------+
| coalesce(name,'总数') | name_num |
+-------------------------+----------+
| Alex | 2 |
| Treelight | 4 |
| 总数 | 6 |
+-------------------------+----------+
select col1,col2...,func(col) <
说明:
1、coalesce(name,'总数'):设置rollup这个记录的名称,返回的是第一个非null参数
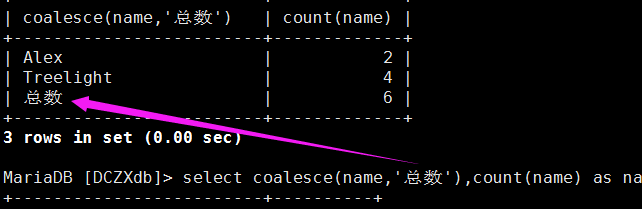
2、count(name):对name这个字段进行计数,count是一个函数,常见的有avg、max、min、count
3、as是一个别名:
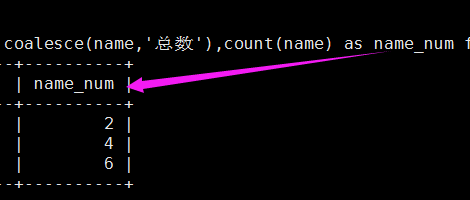
4、group by:按某字段分组
5、with rollup:对整个表的字段再进行func统计
添加删除字段、修改字段类型、名称
1、添加字段:alter table <table> add <colname> <type>
2、删除字段:alter table <table> drop <col_name>;
删除table中的col_name字段
3、修改字段类型:alter table <table> modify <col_name> <new_type>;
修改字段中的类型为new_type.
4、修改字段名称:alter table <table> change <old_col_name> <new_col_name> <type>
创建外键
create table study_record(
-> id int auto_increment primary key,
-> day int not null,
-> status char(32) not null default 'Yes',
-> stu_id int not null,
-> foreign key(stu_id) reference student(id));
MySQL NULL 值处理
我们已经知道MySQL使用 SQL SELECT 命令及 WHERE 子句来读取数据表中的数据,但是当提供的查询条件字段为 NULL 时,该命令可能就无法正常工作。
为了处理这种情况,MySQL提供了三大运算符:
IS NULL: 当列的值是NULL,此运算符返回true。
IS NOT NULL: 当列的值不为NULL, 运算符返回true。
<=>: 比较操作符(不同于=运算符),当比较的的两个值为NULL时返回true。
关于 NULL 的条件比较运算是比较特殊的。你不能使用 = NULL 或 != NULL 在列中查找 NULL 值 。
在MySQL中,NULL值与任何其它值的比较(即使是NULL)永远返回false,即 NULL = NULL 返回false 。
MySQL中处理NULL使用IS NULL和IS NOT NULL运算符。
MySql的连接(left join、right join、inner join、full join)
1、内连接:select * from A inner join B on A.a=B.b;就是求A表与B表的某段数据的交集,再符合条件的记录查询出来。
select A.*,B.* from A,B where A.a=B.b;与上一样
2、左连接:select * from A left join B on A.a=B.b;求A与B的差集
3、右连接:select * from A Right join B on A.a=B.b;求B与A的差集
4、全连接:mysql并不支持并集,但也有办法解决
select * from A left join B on A.a=B.b union select * from A right join B on A.a=B.b;
例子:
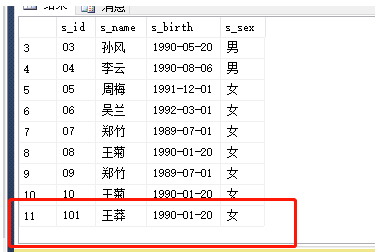
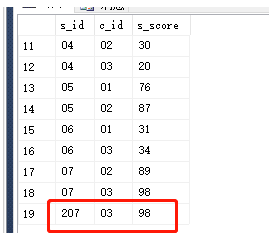
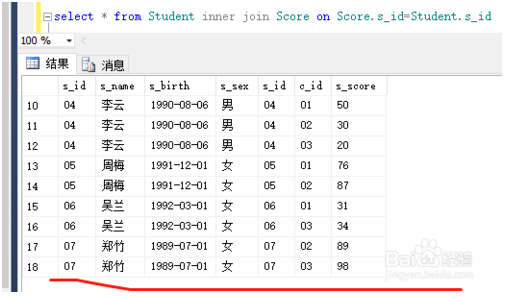
内连接:select * from Student inner join Score on Score.s_id=Student.s_id
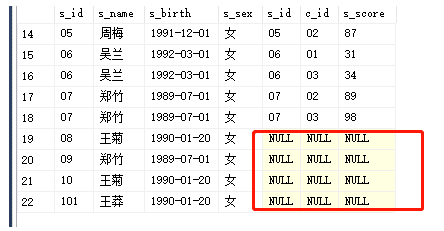
左连接(左外连接):
将返回右表的所有行。如果左表的某行在右表中没有匹配行,则将为右表返回空值左连接:select *from Student LEFT JOIN Score ON Student.s_id=Score.s_id
以左表为主表,右表没数据为null
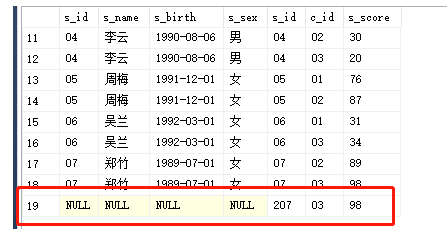
右连接(右外连接):
将返回右表的所有行。如果右表的某行在左表中没有匹配行,则将为左表返回空值;
以右表为主表,左表中没数据的为null
select *from Student right JOIN Score ON Student.s_id=Score.s_id
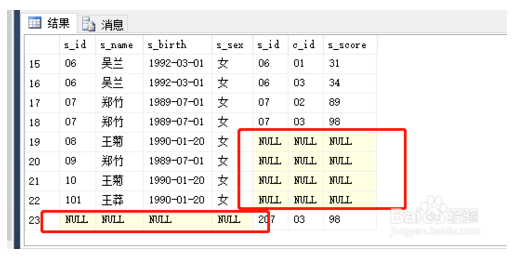
全外连接(FULL JOIN 或 FULL OUTER JOIN):
完整外部联接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。
select *from Student full JOIN Score ON Student.s_id=Score.s_id
select *from Student full outer JOIN Score ON Student.s_id=Score.s_id
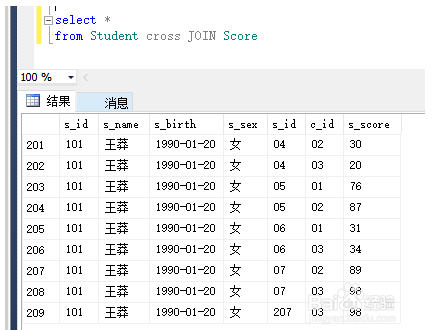
笛卡尔积:
交叉连接即笛卡尔积,结果为A×B
select *from Student cross JOIN Score
事务
MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务!
- 在MySQL中只有使用了Innodb数据库引擎的数据库或表才支持事务
- 事务处理可以用来维护数据库的完整性,保证成批的SQL语句要么全部执行,要么全部不执行
- 事务用来管理insert,update,delete语句
一般来说,事务是必须满足4个条件(ACID): Atomicity(原子性)、Consistency(稳定性)、Isolation(隔离性)、Durability(可靠性)
- 1、事务的原子性:一组事务,要么成功;要么撤回。
- 2、稳定性 : 有非法数据(外键约束之类),事务撤回。
- 3、隔离性:事务独立运行。一个事务处理后的结果,影响了其他事务,那么其他事务会撤回。事务的100%隔离,需要牺牲速度。
- 4、可靠性:软、硬件崩溃后,InnoDB数据表驱动会利用日志文件重构修改。可靠性和高速度不可兼得, innodb_flush_log_at_trx_commit选项 决定什么时候吧事务保存到日志里。
在Mysql控制台使用事务来操作
|
1
2
3
4
5
|
mysql> begin; #开始一个事务mysql> insert into a (a) values(555);mysql>rollback; 回滚 , 这样数据是不会写入的 |
当然如果上面的数据没问题,就输入commit提交命令就行;
begin:开始事务
rollback:回滚,也就是把提交的操作都撤回
commit:提交操作,把操作结果保存到硬盘。
索引
1、什么是索引:就是对某一字段的数据做一个hash,然后进行排序,得出来的值就是索引
2、索引的优点:在大量数据中能迅速查找数据
3、索引的缺点:如果经常对表进行增删改的操作,速度就会慢。因为要更新索引值、索引表,还要写进硬盘
查看索引:
show index from <tablename>
创建普通索引方法:
1、create index <index_name> on <table_name>(<col_name>(<num));
2、alter table <table_name> add index <index_name> (<col_name>(<num>));
删除索引:
1、drop index <index_name> on <table_name>;
创建唯一索引方法:
alter table <table_name> add unique <index_name> (<col_name>(<num>));
Python操作mysql
一、使用步骤(pymysql):
1、创建连接:conn = pymysql.connect(host=<host>,user=<user>,password=<password>,port=3306,db=<dbname>)
2、创建游标:cur = conn.cursor()
3、调用sql命令:cur.execute(cmd)
4、获取命令结果:
print(cur.fetchone()):只获取结果中的一条记录
print(cur.fetchall()):获取当前游标下的所有记录
print(cur.fetchmany(num)):获取N条记录
import pymysql # 创建连接 conn = pymysql.connect(host='10.62.36.58', user='Treelight', password='dczx_5501', port=3306, db='DCZXdb') # 创建游标 cur = conn.cursor() result = cur.execute('select * from student') # 查看一条记录 print(cur.fetchone()) # 查看游标当前位置下的所有记录 print(cur.fetchall())
默认是开启事务的。
5、游标的相关命令:
1、cur.scroll(value,mode):游标移动,value为数值,mode为'relative‘时是相对当前位置移动,为'absolute'是绝对位置的移动
2、cur = conn.cursor(cursor=pymysql.cursors.DictCursor):默认游标类型是元组,可设置为字典类型。
插入数据例子:
import pymysql # 创建连接 conn = pymysql.connect(host='10.62.36.58', user='Treelight', password='dczx_5501', port=3306, db='DCZXdb') # 创建游标 cur = conn.cursor() # data为插入的数据 data = [ ['N1', '2018-10-11', 'M'], ['N2', '2018-01-11', 'M'], ['N3', '2018-09-11', 'F'], ] # 调用excutemany插入多条数据 cur.executemany('insert into student (name,register_date,gender) values(%s,%s,%s)', data) # 提交数据 conn.commit()
在Centos中备份数据
mysqldump -uroot -h127.0.0.1 -p books > ~/books.sql

 浙公网安备 33010602011771号
浙公网安备 33010602011771号