ResNet 修改
https://github.com/tornadomeet/ResNet
apache 开源项目
修改如下:
训练模块
import argparse,logging,os import mxnet as mx from symbol_resnet import resnet logger = logging.getLogger() logger.setLevel(logging.INFO) def multi_factor_scheduler(begin_epoch, epoch_size, step=[60, 75, 90], factor=0.1): step_ = [epoch_size * (x-begin_epoch) for x in step if x-begin_epoch > 0] return mx.lr_scheduler.MultiFactorScheduler(step=step_, factor=factor) if len(step_) else None def main(): if args.data_type == "cifar10": args.aug_level = 1 args.num_classes = 10 # depth should be one of 110, 164, 1001,...,which is should fit (args.depth-2)%9 == 0 if((args.depth-2)%9 == 0 and args.depth >= 164): per_unit = [(args.depth-2)/9] filter_list = [16, 64, 128, 256] bottle_neck = True elif((args.depth-2)%6 == 0 and args.depth < 164): per_unit = [(args.depth-2)/6] filter_list = [16, 16, 32, 64] bottle_neck = False else: raise ValueError("no experiments done on detph {}, you can do it youself".format(args.depth)) units = per_unit*3 symbol = resnet(units=units, num_stage=3, filter_list=filter_list, num_class=args.num_classes, data_type="cifar10", bottle_neck = bottle_neck, bn_mom=args.bn_mom, workspace=args.workspace, memonger=args.memonger) elif args.data_type == "imagenet": args.num_classes = 3 if args.depth == 18: units = [2, 2, 2, 2] elif args.depth == 34: units = [3, 4, 6, 3] elif args.depth == 50: units = [3, 4, 6, 3] elif args.depth == 101: units = [3, 4, 23, 3] elif args.depth == 152: units = [3, 8, 36, 3] elif args.depth == 200: units = [3, 24, 36, 3] elif args.depth == 269: units = [3, 30, 48, 8] else: raise ValueError("no experiments done on detph {}, you can do it youself".format(args.depth)) symbol = resnet(units=units, num_stage=4, filter_list=[64, 256, 512, 1024, 2048] if args.depth >=50 else [64, 64, 128, 256, 512], num_class=args.num_classes, data_type="imagenet", bottle_neck = True if args.depth >= 50 else False, bn_mom=args.bn_mom, workspace=args.workspace, memonger=args.memonger) else: raise ValueError("do not support {} yet".format(args.data_type)) kv = mx.kvstore.create(args.kv_store) devs = mx.cpu() if args.gpus is None else [mx.gpu(int(i)) for i in args.gpus.split(',')] epoch_size = max(int(args.num_examples / args.batch_size / kv.num_workers), 1) begin_epoch = args.model_load_epoch if args.model_load_epoch else 0 if not os.path.exists("./model"): os.mkdir("./model") model_prefix = "model/resnet-{}-{}-{}".format(args.data_type, args.depth, kv.rank) checkpoint = mx.callback.do_checkpoint(model_prefix) arg_params = None aux_params = None if args.retrain: _, arg_params, aux_params = mx.model.load_checkpoint(model_prefix, args.model_load_epoch) if args.memonger: import memonger symbol = memonger.search_plan(symbol, data=(args.batch_size, 3, 32, 32) if args.data_type=="cifar10" else (args.batch_size, 3, 128, 128)) train = mx.io.ImageRecordIter( path_imgrec = os.path.join(args.data_dir, "cifar10_train.rec") if args.data_type == 'cifar10' else os.path.join(args.data_dir, "train_256_q90.rec") if args.aug_level == 1 else os.path.join(args.data_dir, "train_480_q90.rec"), label_width = 1, data_name = 'data', label_name = 'softmax_label', data_shape = (3, 32, 32) if args.data_type=="cifar10" else (3, 128, 128), batch_size = args.batch_size, pad = 4 if args.data_type == "cifar10" else 0, fill_value = 127, # only used when pad is valid rand_crop = True, max_random_scale = 1.0, # 480 with imagnet, 32 with cifar10 min_random_scale = 1.0 if args.data_type == "cifar10" else 1.0 if args.aug_level == 1 else 0.533, # 256.0/480.0 max_aspect_ratio = 0 if args.data_type == "cifar10" else 0 if args.aug_level == 1 else 0.25, random_h = 0 if args.data_type == "cifar10" else 0 if args.aug_level == 1 else 36, # 0.4*90 random_s = 0 if args.data_type == "cifar10" else 0 if args.aug_level == 1 else 50, # 0.4*127 random_l = 0 if args.data_type == "cifar10" else 0 if args.aug_level == 1 else 50, # 0.4*127 max_rotate_angle = 0 if args.aug_level <= 2 else 10, max_shear_ratio = 0 if args.aug_level <= 2 else 0.1, rand_mirror = True, shuffle = True, num_parts = kv.num_workers, part_index = kv.rank) val = mx.io.ImageRecordIter( path_imgrec = os.path.join(args.data_dir, "cifar10_val.rec") if args.data_type == 'cifar10' else os.path.join(args.data_dir, "val_256_q90.rec"), label_width = 1, data_name = 'data', label_name = 'softmax_label', batch_size = args.batch_size, data_shape = (3, 32, 32) if args.data_type=="cifar10" else (3, 128, 128), rand_crop = False, rand_mirror = False, num_parts = kv.num_workers, part_index = kv.rank) model = mx.model.FeedForward( ctx = devs, symbol = symbol, arg_params = arg_params, aux_params = aux_params, num_epoch = 200 if args.data_type == "cifar10" else 120, begin_epoch = begin_epoch, learning_rate = args.lr, momentum = args.mom, wd = args.wd, optimizer = 'nag', # optimizer = 'sgd', initializer = mx.init.Xavier(rnd_type='gaussian', factor_type="in", magnitude=2), lr_scheduler = multi_factor_scheduler(begin_epoch, epoch_size, step=[120, 160], factor=0.1) if args.data_type=='cifar10' else multi_factor_scheduler(begin_epoch, epoch_size, step=[30, 60, 90], factor=0.1), ) model.fit( X = train, eval_data = val, eval_metric = ['acc', 'ce'] if args.data_type=='cifar10' else ['acc','ce', mx.metric.create('top_k_accuracy', top_k = 5)], kvstore = kv, batch_end_callback = mx.callback.Speedometer(args.batch_size, args.frequent), epoch_end_callback = checkpoint) # logging.info("top-1 and top-5 acc is {}".format(model.score(X = val, # eval_metric = ['acc', mx.metric.create('top_k_accuracy', top_k = 5)]))) if __name__ == "__main__": parser = argparse.ArgumentParser(description="command for training resnet-v2") parser.add_argument('--gpus', type=str, default='0', help='the gpus will be used, e.g "0,1,2,3"') parser.add_argument('--data-dir', type=str, default='./data/imagenet/', help='the input data directory') parser.add_argument('--data-type', type=str, default='imagenet', help='the dataset type') parser.add_argument('--list-dir', type=str, default='./', help='the directory which contain the training list file') parser.add_argument('--lr', type=float, default=0.1, help='initialization learning reate') parser.add_argument('--mom', type=float, default=0.9, help='momentum for sgd') parser.add_argument('--bn-mom', type=float, default=0.9, help='momentum for batch normlization') parser.add_argument('--wd', type=float, default=0.0001, help='weight decay for sgd') parser.add_argument('--batch-size', type=int, default=256, help='the batch size') parser.add_argument('--workspace', type=int, default=512, help='memory space size(MB) used in convolution, if xpu ' ' memory is oom, then you can try smaller vale, such as --workspace 256') parser.add_argument('--depth', type=int, default=50, help='the depth of resnet') parser.add_argument('--num-classes', type=int, default=1000, help='the class number of your task') parser.add_argument('--aug-level', type=int, default=2, choices=[1, 2, 3], help='level 1: use only random crop and random mirror\n' 'level 2: add scale/aspect/hsv augmentation based on level 1\n' 'level 3: add rotation/shear augmentation based on level 2') parser.add_argument('--num-examples', type=int, default=1281167, help='the number of training examples') parser.add_argument('--kv-store', type=str, default='device', help='the kvstore type') parser.add_argument('--model-load-epoch', type=int, default=0, help='load the model on an epoch using the model-load-prefix') parser.add_argument('--frequent', type=int, default=50, help='frequency of logging') parser.add_argument('--memonger', action='store_true', default=False, help='true means using memonger to save momory, https://github.com/dmlc/mxnet-memonger') parser.add_argument('--retrain', action='store_true', default=False, help='true means continue training') args = parser.parse_args() logging.info(args) main()
为减小网络大小,将图片全部缩放为128*128大小,平时使用ResNet-50的网络,将num_classes 改为需要的分类数目。
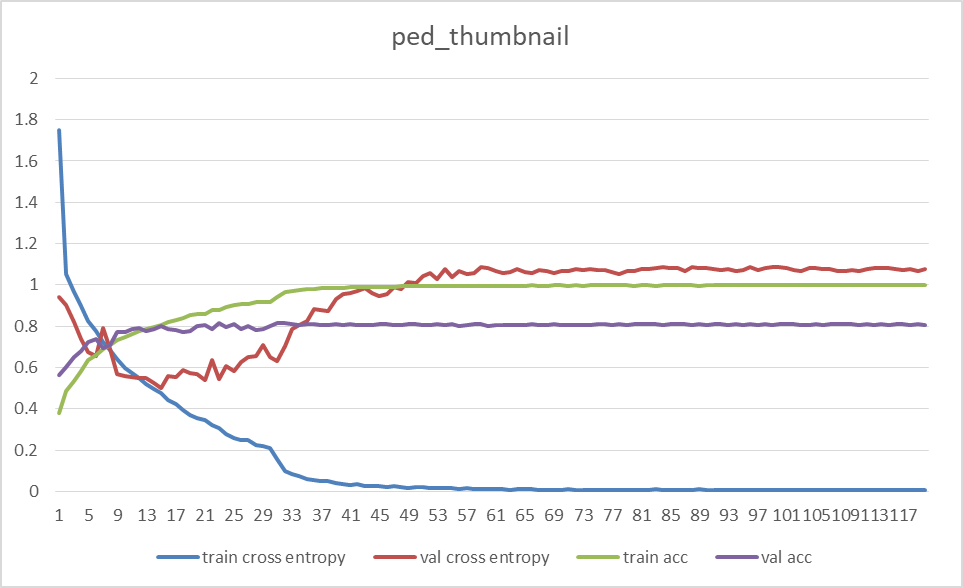
train acc可以在99.9%水平,val acc 稳定在80%左右
预测模块
import numpy as np import cv2 import mxnet as mx import argparse def ch_dev(arg_params, aux_params, ctx): new_args = dict() new_auxs = dict() for k, v in arg_params.items(): new_args[k] = v.as_in_context(ctx) for k, v in aux_params.items(): new_auxs[k] = v.as_in_context(ctx) return new_args, new_auxs def predict(img): # compute the predict probabilities mod.forward(Batch([img])) prob = mod.get_outputs()[0].asnumpy() # print the top-5 prob = np.squeeze(prob) a = np.argsort(prob)[::-1] for i in a[0:3]: print('probability=%f, class=%s' %(prob[i], labels[i])) def main(): synset = [l.strip() for l in open(args.synset).readlines()] # 添加预测 ctx = mx.gpu(args.gpu) sym, arg_params, aux_params = mx.model.load_checkpoint(args.prefix, args.epoch) mod = mx.mod.Module(symbol=sym, context=ctx, label_names=None) mod.bind(for_training=False, data_shapes=[('data', (1,3,128,128))],label_shapes=mod._label_shapes) mod.set_params(arg_params, aux_params, allow_missing=True) from collections import namedtuple Batch = namedtuple('Batch', ['data']) if args.lst: file = open('instances_test.lst') for line in file: src = "" for i in range(len(line)-1,0,-1): if line[i] == '\t': break src += line[i] src = src[::-1] src = "/mnt/hdfs-data-4/data/jian.yin/ped_thumbnail/instances_test/" + src print(src[0:-1]) # convert into format (batch, RGB, width, height) img = mx.image.imdecode(open(src[0:-1],'rb').read()) img = mx.image.imresize(img, 128, 128) # resize img = img.transpose((2, 0, 1)) # Channel first img = img.expand_dims(axis=0) # batchify img = img.astype('float32') # for gpu context mod.forward(Batch([img])) prob = mod.get_outputs()[0].asnumpy() # print the top-3 prob = np.squeeze(prob) a = np.argsort(prob)[::-1] for i in a[0:3]: print('probability=%f, class=%s' %(prob[i], synset[i])) # img = cv2.cvtColor(cv2.imread(src[0:-1]), cv2.COLOR_BGR2RGB) # img = cv2.resize(img, (128, 128)) # resize to 224*224 to fit model # img = np.swapaxes(img, 0, 2) # img = np.swapaxes(img, 1, 2) # change to (c, h,w) order # img = img[np.newaxis, :] # extend to (n, c, h, w) # ctx = mx.gpu(args.gpu) # sym, arg_params, aux_params = mx.model.load_checkpoint(args.prefix, args.epoch) # arg_params, aux_params = ch_dev(arg_params, aux_params, ctx) # arg_params["data"] = mx.nd.array(img, ctx) # arg_params["softmax_label"] = mx.nd.empty((1,), ctx) # exe = sym.bind(ctx, arg_params ,args_grad=None, grad_req="null", aux_states=aux_params) # exe.forward(is_train=False) # prob = np.squeeze(exe.outputs[0].asnumpy()) # pred = np.argsort(prob)[::-1] # print("Top1 result is: ", synset[pred[0]]) # # print("Top5 result is: ", [synset[pred[i]] for i in range(5)]) file.close() if __name__ == "__main__": parser = argparse.ArgumentParser(description="use pre-trainned resnet model to classify one image") parser.add_argument('--img', type=str, default='test.jpg', help='input image for classification') # add --lst parser.add_argument('--lst',type=str,default='test.lst',help="input image's lst for classification") parser.add_argument('--gpu', type=int, default=0, help='the gpu id used for predict') parser.add_argument('--synset', type=str, default='synset.txt', help='file mapping class id to class name') parser.add_argument('--prefix', type=str, default='resnet-50', help='the prefix of the pre-trained model') parser.add_argument('--epoch', type=int, default=0, help='the epoch of the pre-trained model') args = parser.parse_args() main()
添加了--lst可选参数,可以批处理序列化文件预测。
原文预测模块效率较低,改用mxnet标准的predict写法:https://mxnet.incubator.apache.org/tutorials/python/predict_image.html
添加一个脚本,防止忘记一些参数的写法:
#!/usr/bin/ python -u predict.py --lst instances_test.lst --prefix resnet-50 --synset ped_thumbnail.txt --gpu 0
记得运行的时候添加管道命令 >
/mnt/1/385_328_428_402_6.jpg probability=0.994927, class=1 Cyclist probability=0.003335, class=2 Others probability=0.001739, class=0 Pedestrian /mnt2/439_359_481_428_0.jpg probability=0.994793, class=2 Others probability=0.002817, class=0 Pedestrian probability=0.002390, class=1 Cyclist /mnt/2/619_337_658_401_16.jpg probability=0.992218, class=2 Others probability=0.007275, class=1 Cyclist probability=0.000507, class=0 Pedestrian /mnt1/511_288_561_385_1.jpg probability=0.997837, class=1 Cyclist probability=0.001525, class=0 Pedestrian probability=0.000638, class=2 Others
分析预测结果
可以先把各种分类的路径记录下来。
import itertools import numpy as np import matplotlib.pyplot as plt from sklearn import svm, datasets from sklearn.model_selection import train_test_split from sklearn.metrics import confusion_matrix file = open('myPredict.txt') cnt = 0 true = [] pred = [] for line in file: if cnt%4 == 0: pos =-1 for i in range(len(line)-1,-1,-1): if line[i]=='/': pos = i - 1 break true.append(int(line[pos])) if cnt%4 == 1: pos = -1 for i in range(len(line)-1,-1,-1): if line[i] == ' ': pos = i - 1 break pred.append(int(line[pos])) cnt+=1 print(true) print(pred) print(confusion_matrix(true,pred)) file.close() zero_zero = [] zero_one = [] zero_two = [] one_zero = [] one_one = [] one_two = [] two_zero = [] two_one = [] two_two = [] cnt = 0 pos = 0 file = open('myPredict.txt') for line in file: if cnt%4==0: if true[pos] == 0 and pred[pos] == 0: zero_zero.append(line) if true[pos] == 0 and pred[pos] == 1: zero_one.append(line) if true[pos] == 0 and pred[pos] == 2: zero_two.append(line) if true[pos] == 1 and pred[pos] == 0: one_zero.append(line) if true[pos] == 1 and pred[pos] == 1: one_one.append(line) if true[pos] == 1 and pred[pos] == 2: one_two.append(line) if true[pos] == 2 and pred[pos] == 0: two_zero.append(line) if true[pos] == 2 and pred[pos] == 1: two_one.append(line) if true[pos] == 2 and pred[pos] == 2: two_two.append(line) pos+=1 cnt+=1 file.close() print(len(zero_one)+len(zero_two)+len(one_zero)+len(one_two)+len(two_zero)+len(two_one)) # 0 - 0 write_zero_zero = open('zero_zero.txt','w') for i in range(len(zero_zero)): write_zero_zero.write(zero_zero[i]) write_zero_zero.close() # 0 - 1 write_zero_one = open('zero_one.txt','w') for i in range(len(zero_one)): write_zero_one.write(zero_one[i]) write_zero_one.close() # 0 - 2 write_zero_two = open('zero_two.txt','w') for i in range(len(zero_two)): write_zero_two.write(zero_two[i]) write_zero_two.close() # 1 - 0 write_one_zero = open('one_zero.txt','w') for i in range(len(one_zero)): write_one_zero.write(one_zero[i]) write_one_zero.close() # 1 - 1 write_one_one = open('one_one.txt','w') for i in range(len(one_one)): write_one_one.write(one_one[i]) write_one_one.close() # 1 - 2 write_one_two = open('one_two.txt','w') for i in range(len(one_two)): write_one_two.write(one_two[i]) write_one_two.close() # 2 - 0 write_two_zero = open('two_zero.txt','w') for i in range(len(two_zero)): write_two_zero.write(two_zero[i]) write_two_zero.close() # 2 - 1 write_two_one = open('two_one.txt','w') for i in range(len(two_one)): write_two_one.write(two_one[i]) write_two_one.close() # 2 - 2 write_two_two = open('two_two.txt','w') for i in range(len(two_two)): write_two_two.write(two_two[i]) write_two_two.close()
混淆矩阵如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号