Spark Streaming 概述+DStream工作原理+与Storm对比+实时WordCount
Spark Streaming简介
Spark Streaming,其实就是一种Spark提供的,对于大数据,进行实时计算的一种框架。它的底层,其实,也是基于我们之前讲解的Spark Core的。基本的计算模型,还是基于内存的大数据实时计算模型。而且,它的底层的组件或者叫做概念,其实还是最核心的RDD。
只不多,针对实时计算的特点,在RDD之上,进行了一层封装,叫做DStream。其实,学过了Spark SQL之后,你理解这种封装就容易了。之前学习Spark SQL是不是也是发现,它针对数据查询这种应用,提供了一种基于RDD之上的全新概念,DataFrame,但是,其底层还是基于RDD的。所以,RDD是整个Spark技术生态中的核心。要学好Spark在交互式查询、实时计算上的应用技术和框架,首先必须学好Spark核心编程,也就是Spark Core。
Spark Streaming 类似于 Apache Storm,用于流式数据的处理。根据其官方文档介绍,Spark Streaming 有高吞吐量和容错能力强等特点。Spark Streaming 支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ 和简单的 TCP 套接字等等。数据输入后可以用 Spark 的高度抽象,如:map、reduce、join、window 等进行运算。而结果也能保存在很多地方,如 HDFS,数据库等。另外 Spark Streaming 也能和 MLlib(机器学习)以及 Graphx 完美融合。

和 Spark 基于 RDD 的概念很相似,Spark Streaming 使用离散化流(discretized stream)作为抽象表示,叫作 DStream。DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为 RDD 存在,而 DStream 是由这些 RDD 所组成的序列(因此得名“离散化”)。

DStream 可以从各种输入源创建,比如 Flume、Kafka 或者 HDFS。创建出来的 DStream 支持两种操作,一种是转化操作(transformation),会生成一个新的 DStream,另一种是输出操作(output operation),可以把数据写入外部系统中。DStream 提供了许多与 RDD 所支持的操作相类似的操作支持,还增加了与时间相关的新操作,比如滑动窗口。
Spark Streaming 的关键抽象

DStream:Discretized Stream 离散化流
基于Spark Streaming的大数据实时计算框架流程

Spark Streaming基本工作原理

DStream简介
Spark Streaming提供了一种高级的抽象,叫做DStream,英文全称为Discretized Stream,中文翻译为“离散流”,它代表了一个持续不断的数据流。DStream可以通过输入数据源来创建,比如Kafka、Flume和Kinesis;也可以通过对其他DStream应用高阶函数来创建,比如map、reduce、join、window。
DStream的内部,其实一系列持续不断产生的RDD。RDD是Spark Core的核心抽象,即,不可变的,分布式的数据集。DStream中的每个RDD都包含了一个时间段内的数据。
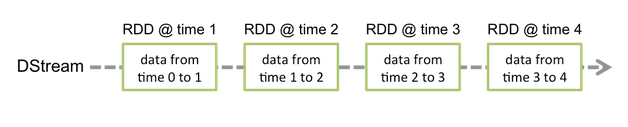
对DStream应用的算子,比如map,其实在底层会被翻译为对DStream中每个RDD的操作。比如对一个DStream执行一个map操作,会产生一个新的DStream。但是,在底层,其实其原理为,对输入DStream中每个时间段的RDD,都应用一遍map操作,然后生成的新的RDD,即作为新的DStream中的那个时间段的一个RDD。底层的RDD的transformation操作,其实,还是由Spark Core的计算引擎来实现的。Spark Streaming对Spark Core进行了一层封装,隐藏了细节,然后对开发人员提供了方便易用的高层次的API。

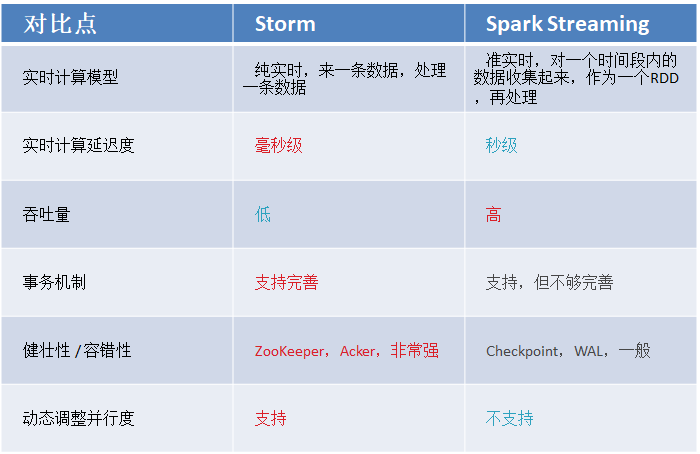
Spark 与 Storm 的对比

实时wordcount程序开发:基于Socket
public class WordCount {
public static void main(String[] args) throws Exception {
// 创建SparkConf对象
// 但是这里有一点不同,我们是要给它设置一个Master属性,但是我们测试的时候使用local模式
// local后面必须跟一个方括号,里面填写一个数字,数字代表了,我们用几个线程来执行我们的
// Spark Streaming程序
SparkConf conf=new SparkConf().setMaster("local[2]").setAppName("WordCount");
// 创建JavaStreamingContext对象
// 该对象,就类似于Spark Core中的JavaSparkContext,就类似于Spark SQL中的SQLContext
// 该对象除了接收SparkConf对象对象之外
// 还必须接收一个batch interval参数,就是说,每收集多长时间的数据,划分为一个batch,进行处理
// 这里设置一秒
JavaStreamingContext jsc=new JavaStreamingContext(conf,Duration.apply(1000));
// 首先,创建输入DStream,代表了一个从数据源(比如kafka、socket)来的持续不断的实时数据流
// 调用JavaStreamingContext的socketTextStream()方法,可以创建一个数据源为Socket网络端口的
// 数据流,JavaReceiverInputStream,代表了一个输入的DStream
// socketTextStream()方法接收两个基本参数,第一个是监听哪个主机上的端口,第二个是监听哪个端口
JavaReceiverInputDStream lines=jsc.socketTextStream("localhost",9999);
// 到这里为止,你可以理解为JavaReceiverInputDStream中的,每隔一秒,会有一个RDD,其中封装了
// 这一秒发送过来的数据
// RDD的元素类型为String,即一行一行的文本
// 所以,这里JavaReceiverInputStream的泛型类型<String>,其实就代表了它底层的RDD的泛型类型
// 开始对接收到的数据,执行计算,使用Spark Core提供的算子,执行应用在DStream中即可
// 在底层,实际上是会对DStream中的一个一个的RDD,执行我们应用在DStream上的算子
// 产生的新RDD,会作为新DStream中的RDD
JavaDStream<String> words=lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
});
// 这个时候,每秒的数据,一行一行的文本,就会被拆分为多个单词,words DStream中的RDD的元素类型
// 即为一个一个的单词
// 接着,开始进行flatMap、reduceByKey操作
JavaPairDStream<String,Integer> pairs=words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<String,Integer>(s,1);
}
});
// 这里,正好说明一下,其实大家可以看到,用Spark Streaming开发程序,和Spark Core很相像
// 唯一不同的是Spark Core中的JavaRDD、JavaPairRDD,都变成了JavaDStream、JavaPairDStream
JavaPairDStream<String,Integer> wordCounts=pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer+integer2;
}
});
// 到此为止,我们就实现了实时的wordcount程序了
// 大家总结一下思路,加深一下印象
// 每秒中发送到指定socket端口上的数据,都会被lines DStream接收到
// 然后lines DStream会把每秒的数据,也就是一行一行的文本,诸如hell world,封装为一个RDD
// 然后呢,就会对每秒中对应的RDD,执行后续的一系列的算子操作
// 比如,对lins RDD执行了flatMap之后,得到一个words RDD,作为words DStream中的一个RDD
// 以此类推,直到生成最后一个,wordCounts RDD,作为wordCounts DStream中的一个RDD
// 此时,就得到了,每秒钟发送过来的数据的单词统计
// 但是,一定要注意,Spark Streaming的计算模型,就决定了,我们必须自己来进行中间缓存的控制
// 比如写入redis等缓存
// 它的计算模型跟Storm是完全不同的,storm是自己编写的一个一个的程序,运行在节点上,相当于一个
// 一个的对象,可以自己在对象中控制缓存
// 但是Spark本身是函数式编程的计算模型,所以,比如在words或pairs DStream中,没法在实例变量中
// 进行缓存
// 此时就只能将最后计算出的wordCounts中的一个一个的RDD,写入外部的缓存,或者持久化DB
// 最后,每次计算完,都打印一下这一秒钟的单词计数情况
// 并休眠5秒钟,以便于我们测试和观察
Thread.sleep(5000);
wordCounts.print();
// 首先对JavaSteamingContext进行一下后续处理
// 必须调用JavaStreamingContext的start()方法,整个Spark Streaming Application才会启动执行
// 否则是不会执行的
jsc.start();
jsc.awaitTermination();
jsc.close();
}
}
运行的shell脚本如下
~/bigdatasoftware/spark-2.1.3-bin-hadoop2.7/bin/spark-submit \
--class com.hzk.sparkStreaming.WordCount \
--driver-java-options "-Dspark.testing.memory=471859200" \
--num-executors 3 \
--driver-memory 100m \
--executor-memory 512m \
--executor-cores 3 \
~/bigdatasoftware/spark-2.1.3-bin-hadoop2.7/study/SparkStudy-1.0-SNAPSHOT.jar \
如果executor-memory不够大的话,有可能会报错:Spark-submit:System memory 466092032 must be at least 471859200
运行shell脚本,且启动netcat监听:nc -lk 9999

实时计算结果如下

实时wordcount程序开发:基于HDFS
package com.hzk.sparkStreaming; import org.apache.spark.SparkConf; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.streaming.Durations; import org.apache.spark.streaming.api.java.JavaDStream; import org.apache.spark.streaming.api.java.JavaPairDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; import scala.Tuple2; import java.util.Arrays; import java.util.Iterator; public class HDFSWordCount { public static void main(String[] args) throws InterruptedException { SparkConf conf = new SparkConf() .setMaster("local[2]") .setAppName("HDFSWordCount"); JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(5)); // 首先,使用JavaStreamingContext的textFileStream()方法,针对HDFS目录创建输入数据流 JavaDStream<String> lines = jssc.textFileStream("hdfs://hadoop-001:9000/datas"); // 执行wordcount操作 JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; @Override public Iterator<String> call(String line) throws Exception { return Arrays.asList(line.split(" ")).iterator(); } }); JavaPairDStream<String, Integer> pairs = words.mapToPair( new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(String word) throws Exception { return new Tuple2<String, Integer>(word, 1); } }); JavaPairDStream<String, Integer> wordCounts = pairs.reduceByKey( new Function2<Integer, Integer, Integer>() { private static final long serialVersionUID = 1L; @Override public Integer call(Integer v1, Integer v2) throws Exception { return v1 + v2; } }); wordCounts.print(); jssc.start(); jssc.awaitTermination(); jssc.close(); } }
运行shell脚本如下
~/bigdatasoftware/spark-2.1.3-bin-hadoop2.7/bin/spark-submit \
--class com.hzk.sparkStreaming.HDFSWordCount \
--driver-java-options "-Dspark.testing.memory=471859200" \
--num-executors 3 \
--driver-memory 100m \
--executor-memory 512m \
--executor-cores 3 \
~/bigdatasoftware/spark-2.1.3-bin-hadoop2.7/study/SparkStudy-1.0-SNAPSHOT.jar \
运行shell脚本后,将文本put进hdfs
hadoop fs -put ./wc.txt /datas
结果如下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号