Elasticsearch 使用Kibana实现基本的增删改查+mget批量查询+bulk批量操作
使用ElasticSearch API 实现CRUD
添加索引:
指定分片和副本:
PUT /lib/
{
"settings":{
"index":{
"number_of_shards": 5,
"number_of_replicas": 1
}
}
}
不指定分片和副本:
PUT lib
查看索引信息:
GET /lib/_settings
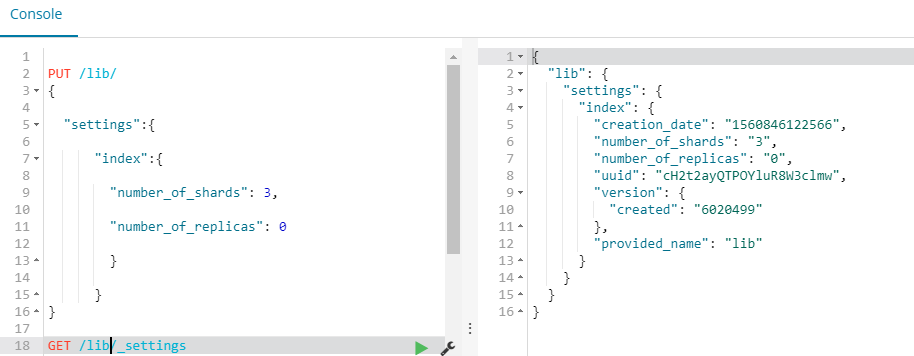
GET _all/_settings

添加文档:
指定ID:
PUT /lib/user/1
{
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 32,
"about" : "I like to collect rock albums",
"interests": [ "music" ]
}
不指定ID:
POST /lib/user/
{
"first_name" : "Douglas",
"last_name" : "Fir",
"age" : 23,
"about": "I like to build cabinets",
"interests": [ "forestry" ]
}
查看文档:
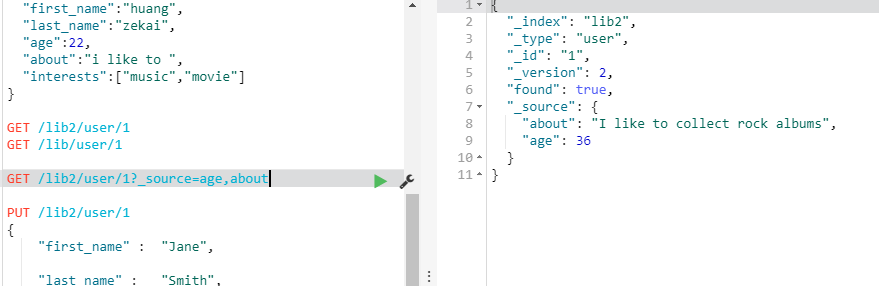
GET /lib/user/1
GET /lib/user/
GET /lib/user/1?_source=age,interests
更新文档:
PUT /lib/user/1
{
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 36,
"about" : "I like to collect rock albums",
"interests": [ "music" ]
}
删除一个文档
DELETE /lib/user/1
删除一个索引
DELETE /lib
批量获取文档
使用es提供的Multi Get API:
使用Multi Get API可以通过索引名、类型名、文档id一次得到一个文档集合,文档可以来自同一个索引库,也可以来自不同索引库
使用curl命令:
curl 'http://hadoop-001:9200/_mget' -d '{
"docs":[
{
"_index": "lib",
"_type": "user",
"_id": 1
},
{
"_index": "lib",
"_type": "user",
"_id": 2
}
]
}'
在客户端工具中:
GET /_mget
{
"docs":[
{
"_index": "lib",
"_type": "user",
"_id": 1
},
{
"_index": "lib",
"_type": "user",
"_id": 2
},
{
"_index": "lib",
"_type": "user",
"_id": 3
}
]
}
可以指定具体的字段:
GET /_mget
{
"docs":[
{
"_index": "lib",
"_type": "user",
"_id": 1,
"_source": "interests"
},
{
"_index": "lib",
"_type": "user",
"_id": 2,
"_source": ["age","interests"]
}
]
}
获取同索引同类型下的不同文档:
GET /lib/user/_mget
{
"docs":[
{
"_id": 1
},
{
"_type": "user",
"_id": 2
}
]
}
GET /lib/user/_mget
{
"ids": ["1","2"]
}
使用Bulk API 实现批量操作
bulk的格式:
{action:{metadata}}\n
{requstbody}\n
action:(行为)
create:文档不存在时创建
update:更新文档
index:创建新文档或替换已有文档
delete:删除一个文档
metadata:_index,_type,_id
create 和index的区别
如果数据存在,使用create操作失败,会提示文档已经存在,使用index则可以成功执行。
示例:
{"delete":{"_index":"lib","_type":"user","_id":"1"}}
批量添加:
POST /lib2/books/_bulk
{"index":{"_id":1}}
{"title":"Java","price":55}
{"index":{"_id":2}}
{"title":"Html5","price":45}
{"index":{"_id":3}}
{"title":"Php","price":35}
{"index":{"_id":4}}
{"title":"Python","price":50}
批量获取:
GET /lib2/books/_mget
{
"ids": ["1","2","3","4"]
}
删除:没有请求体
POST /lib2/books/_bulk
{"delete":{"_index":"lib2","_type":"books","_id":4}}
{"create":{"_index":"tt","_type":"ttt","_id":"100"}}
{"name":"lisi"}
{"index":{"_index":"tt","_type":"ttt"}}
{"name":"zhaosi"}
{"update":{"_index":"lib2","_type":"books","_id":"4"}}
{"doc":{"price":58}}
bulk一次最大处理多少数据量:
bulk会把将要处理的数据载入内存中,所以数据量是有限制的,最佳的数据量不是一个确定的数值,它取决于你的硬件,你的文档大小以及复杂性,你的索引以及搜索的负载。
一般建议是1000-5000个文档,大小建议是5-15MB,默认不能超过100M,可以在es的配置文件(即$ES_HOME下的config下的elasticsearch.yml)中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号