Storm 编程实例一:生成及接收数据+实例二:wordcount
实例一:生成及接收数据
程序结构如下
DataSpout
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import java.util.Map;
import java.util.Random;
/*
* 定义一个数据源
* */
public class DataSpout extends BaseRichSpout
{
private SpoutOutputCollector collector;
private static String datas[]=new String[]{
"hello","world","java","hadoop"
};
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector=collector;
}
/*
* 循环调用
* */
@Override
public void nextTuple() {
//生成此数据
String data=datas[new Random().nextInt(datas.length)];
//发送数据到下游组件
collector.emit(new Values(data));
}
/**
* 此方法是对发送数据进行声明
* */
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
DataBolt
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import java.util.Map;
public class DataBolt extends BaseRichBolt
{
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
@Override
public void execute(Tuple input) {
String word=input.getStringByField("word");
System.out.println("DataBolt="+word);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
TopologiesDataMainApp
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.topology.TopologyBuilder;
public class TopologiesDataMainApp {
public static void main(String[] args) throws InvalidTopologyException, AuthorizationException, AlreadyAliveException {
TopologyBuilder builder=new TopologyBuilder();
builder.setSpout("dataSpout", new DataSpout());
builder.setBolt("dataBolt",new DataBolt()).shuffleGrouping("dataSpout");
//部署有两种方式
//1、一种是本地部署
//2、二种是集群部署
Config config = new Config();
if(args !=null && args.length >0){
//集群部署
StormSubmitter.submitTopology(args[0],config,builder.createTopology());
}else{
//本地部署
LocalCluster cluster = new LocalCluster();
//提交拓扑对象
cluster.submitTopology("TopologiesDataMainApp",config,builder.createTopology());
}
}
}
运行如下:
storm jar stormDemo-1.0-SNAPSHOT.jar com.gec.demo.TopologiestDataMainApp TopologiestDataMainApp


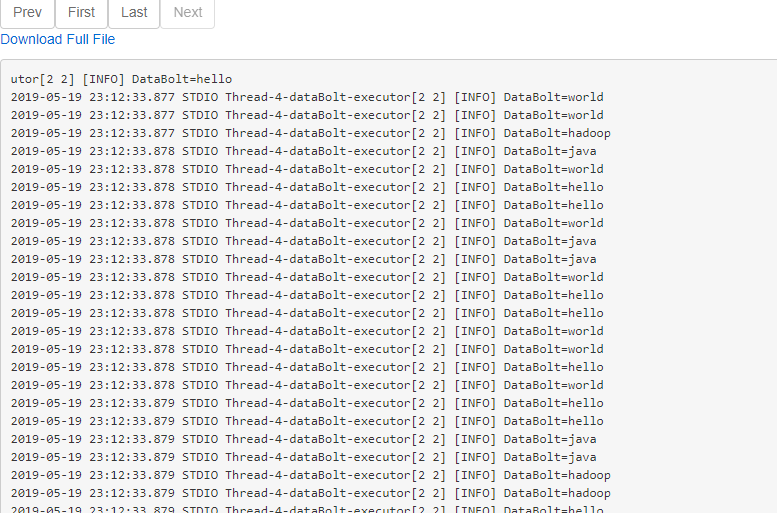
查看DataBolt的接收到的数据
实例二:wordcount
DataSpout
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import java.util.Map;
import java.util.Random;
/*
* 不断产生行数据
* */
public class DataSpout extends BaseRichSpout
{
private SpoutOutputCollector collector;
private String []datas=new String[]{
"hadoop,yarn,mapreduce",
"yarn,yarn,hadoop",
"mapreduce,yarn,mapreduce",
"hadoop,yarn,mapreduce",
"mapreduce,hadoop,mapreduce",
"yarn,yarn,mapreduce"
};
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector=collector;
}
@Override
public void nextTuple() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
this.collector.emit(new Values(datas[new Random().nextInt(datas.length)]));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("lineData"));
}
}
SplitBolt
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Map;
public class SplitBolt extends BaseRichBolt
{
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
}
@Override
public void execute(Tuple input) {
String lineData=input.getStringByField("lineData");
String words[]=lineData.split(",");
for (String word : words) {
//将word和1两个数据值发给下游组件
this.collector.emit(new Values(word,1));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//要对数据作命名
declarer.declare(new Fields("word","value"));
}
}
CountBolt
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class CountBolt extends BaseRichBolt
{
//private HashMap<String,Integer> map=new HashMap<>();
private static ConcurrentHashMap<String,Integer> map=new ConcurrentHashMap<>();
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
@Override
public void execute(Tuple input) {
//获取单词
String word=input.getStringByField("word");
//获取值
int value=input.getIntegerByField("value");
if(map.containsKey(word))
{
map.put(word,map.get(word)+value);
}else{
map.put(word,value);
}
System.out.println(map);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
TopologiesWcApp
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.topology.TopologyBuilder;
public class TopologiesWcApp {
public static void main(String[] args) throws InvalidTopologyException, AuthorizationException, AlreadyAliveException {
TopologyBuilder builder=new TopologyBuilder();
//运行dataSpout组件,需要3个线程运行
builder.setSpout("dataSpout", new DataSpout(),3);
//设置splitBolt数据来自上游组件dataSpout
builder.setBolt("splitBolt",new SplitBolt(),3).shuffleGrouping("dataSpout");
//设置countBolt数据来自上游组件splitBolt
builder.setBolt("countBolt",new CountBolt(),3).shuffleGrouping("splitBolt");
//部署有两种方式
//1、一种是本地部署
//2、二种是集群部署
Config config = new Config();
//配置进程数
config.setNumWorkers(3);
if(args !=null && args.length >0){
//集群部署
StormSubmitter.submitTopology(args[0],config,builder.createTopology());
}else{
//本地部署
LocalCluster cluster = new LocalCluster();
//提交拓扑对象
cluster.submitTopology("TopologiesWcApp",config,builder.createTopology());
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号