软件工程第四次作业
结对编程
| Github项目地址 | https://github.com/Tracerlyh/WordCount.git |
|---|---|
| 结对伙伴学号 | 201831061219 |
| 结对伙伴作业地址 | 结对伙伴博客 |
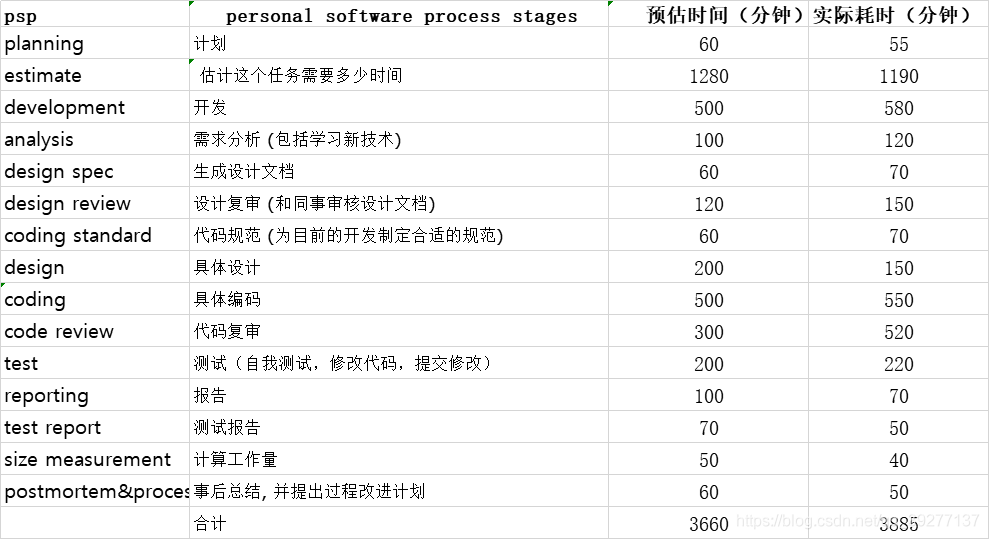
一、psp表格
二、结对编程的过程
在编程之前,我们先一起讨论了该程序结构的设想,然后一起编写了本次项目的PSP表格,然后再商量了如何对各个模块的开发进行分工。
分工情况如下
我:
1、统计最多的10个单词及其词频
2、统计指定长度的单词的数量
3、两人代码的合成
结对伙伴:
1、统计字符数模块
2、统计单词数模块
代码规范
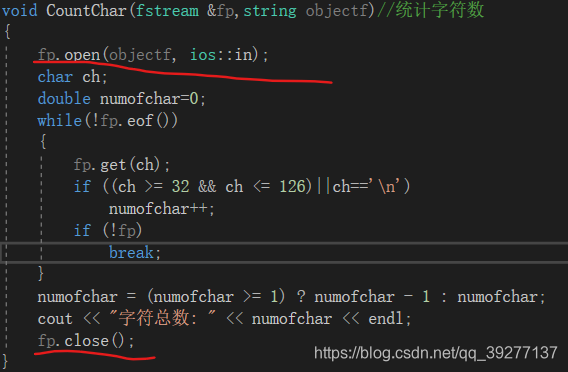
1、在使用文件之后要关闭文件。
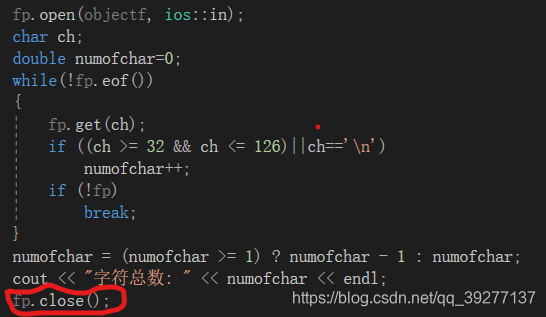
2、主要的功能函数的参数中要有一个参数为文件类型。

3、在函数中打开和关闭文件。
4、在声明函数时在函数声明后面添加注释说明函数的功能。
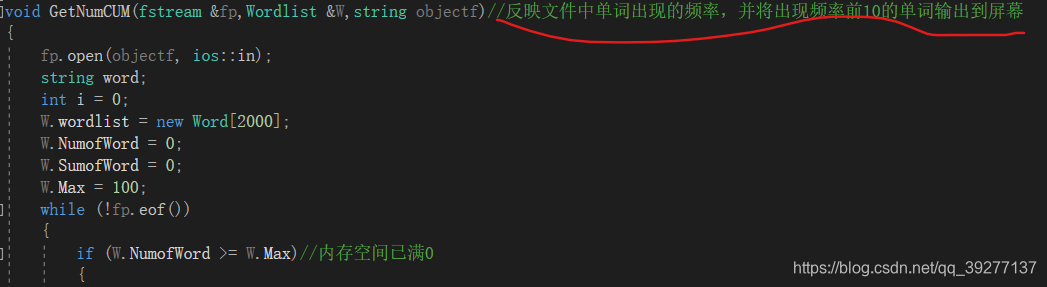
5、在主函数中调用写的功能函数时添加注释说明函数得功能。
6、主函数中只进行与用户交互的提示信息的输出到屏幕。
7、各个功能的运行结果的输出都在相应的函数中输出到屏幕。
工作照片:


在结对编程过程之中,发现问题时及时沟通,尽量尽早地发现问题。
三、解题思路
按程序要实现的功能分别进行分析:
1、由用户输入文件的路径及名字。
解决思路:在屏幕输入提示信息,提示用户输入文件路径,将用户输入的文件的路径及名称存放在一个字符串中,在打开文件流时使用该字符串打开。
2、统计文件中字符的数量并在屏幕上输出。
解决思路:利用C++文件操作的fget()函数从文件中读取字符,如果是满足条件的字符就给计数器加一。
3、统计文件中单词的数量并在屏幕上输出。
解决思路:在此使用了c语言的结构体。我构造了两个结构体,然后将其中一个结构体以结构体数组的方式嵌套在另外一个结构体中,内结构体用于存储单词的拼写以及相应的频次。然后构造循环依次从文件中读取字符串,判断该字符串是否为满足条件的单词,如果是的话,再判断结构体数组中是否已有该单词,如果有的话找到单词的位置,将该位置的单词的频次加1,如果没有的话,将该单词的拼写及频次写入到一个未存有单词信息的位置中。
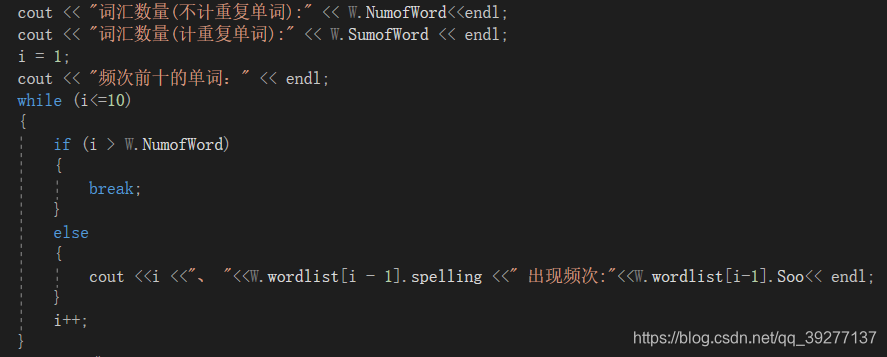
4、统计出现的单词的频次并将频次前十的单词输出到屏幕。
解决思路:在功能3的基础上,按单词的频率对结构体数组进行排序。
5、统计由用户输入的指定字符长度的单词的数量。
解决思路:在功能3的基础上遍历结构体数组,遇到符合长度的单词将计数器加一。
四、设计实现过程(关键代码)
1、统计出现的单词的频次并将频次前十的单词输出到屏幕。(含统计单词数功能)
为了更好的对单词信息进行处理,构造了两个结构体,结构体Wordlist,结构体Word.
typedef struct
{
string spelling;//单词的拼写(小写)
int Soo;//单词出现次数
}Word;
typedef struct
{
Word *wordlist;
int NumofWord;//词汇数(不计重复单词)
int SumofWord;//词汇数(计重复单词)
int Max;
}Wordlist;
构造循环,循环的条件是当前读取位置未到文件的结尾,在循环中采用c++默认的流的操作将txt文件中的字符串读取到一个string类型的变量中去。
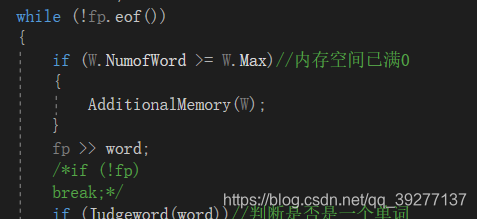
通过函数Judgeword对字符串进行判断,看是否是满足条件的单词。
函数Judgeword:
bool Judgeword(string s1)//判断字符串是否为单词
{
unsigned int i;
int j = 0;
for (i = 0; i < s1.length(); ++i)
{
if (('a' <= s1[i]&&s1[i] <= 'z') ||( 'A' <= s1[i]&&s1[i] <= 'Z'))
j++;
}
if (j >= 4) return true;
else return false;
}
如果是满足条件的单词则进入下一流程,检查单词表是否已经有该单词,通过函数CFDuplicates对单词表进行遍历,并在遍历过程中检查是否有该单词,如果有的话返回该单词在单词表中的位置,如果没有,则返回-1
int CFDuplicates(string a, Wordlist W)//查找是否有重复单词如果有返回其所在位置,如果没有返回-1
{
for (int i = 0; i < W.NumofWord; ++i)
{
if (W.wordlist[i].spelling == a)
{
return i;
}
else if(W.wordlist[i].spelling.length()==a.length()-1)
{
int num = 0;
for (unsigned int j = 0; j < W.wordlist[i].spelling.length(); ++j)
{
if (a[j] == W.wordlist[i].spelling[j])
num++;
}
if ((num ==a.length()-1) &&((a[a.length()-1]>='!'&&a[a.length()-1]<='/') || (a[a.length() - 1] >= ':'&&a[a.length() - 1] <= '@') || (a[a.length() - 1] >= '['&&a[a.length() - 1] <= '`') || (a[a.length() - 1] >= '{'&&a[a.length() - 1] <= '`')))
{
return i;
}
}
}
return -1;
}
如果单词表中已有该单词信息,则将该单词的频率、单词表的成员Sumofword加一即可,,如果没有,在一个新的位置将该单词的拼写录入进去,并且将频率设为一,单词表的成员Sumofword和Numofword都加一。
最后将单词表按词频进行从高到低的排序即可,然后将单词表的单词总数(计重复单词)Sumofword、单词总数(不计重复单词)Numofword以及单词表前十个单词信息输出到屏幕即可。
整个模块完整代码:
void GetNumCUM(fstream &fp,Wordlist &W,string objectf)//反映文件中单词出现的频率,并将出现频率前10的单词输出到屏幕
{
fp.open(objectf, ios::in);
string word;
int i = 0;
W.wordlist = new Word[2000];
W.NumofWord = 0;
W.SumofWord = 0;
W.Max = 100;
while (!fp.eof())
{
if (W.NumofWord >= W.Max)//内存空间已满0
{
AdditionalMemory(W);
}
fp >> word;
/*if (!fp)
break;*/
if (Judgeword(word))//判断是否是一个单词
{
Togglecase(word);
if (CFDuplicates(word, W) != -1)//如果有重复
{
W.wordlist[CFDuplicates(word, W)].Soo++;//对应的单词的频率加1
W.SumofWord++;
}
else
{
W.wordlist[i].Soo = 0;
if ((word[word.length() - 1] >= '!'&&word[word.length() - 1] <= '/') || (word[word.length() - 1] >= ':'&&word[word.length() - 1] <= '@') || (word[word.length() - 1] >= '['&&word[word.length() - 1] <= 96) || (word[word.length() - 1] >= 123 && word[word.length() - 1] <= 126))
{
W.wordlist[i].spelling = word.substr(0, word.length() - 1);
W.wordlist[i].Soo++;
W.NumofWord++;
W.SumofWord++;
i++;
}
else
{
W.wordlist[i].spelling = word;
W.wordlist[i].Soo++;
W.NumofWord++;
W.SumofWord++;
i++;
}
}
}
}
int j = 0;
int k = 0;
for (i = 0; i < W.NumofWord; ++i)//将前十排出来
{
for (j = 0; j < W.NumofWord; ++j)
{
if (W.wordlist[j].Soo < W.wordlist[j + 1].Soo)
{
word = W.wordlist[j].spelling;
k = W.wordlist[j].Soo;
W.wordlist[j].spelling = W.wordlist[j + 1].spelling;
W.wordlist[j].Soo = W.wordlist[j + 1].Soo;
W.wordlist[j + 1].spelling=word;
W.wordlist[j + 1].Soo=k;
}
if (W.wordlist[j].Soo == W.wordlist[j + 1].Soo&&W.wordlist[j].spelling > W.wordlist[j + 1].spelling)
{
word = W.wordlist[j].spelling;
k = W.wordlist[j].Soo;
W.wordlist[j].spelling = W.wordlist[j + 1].spelling;
W.wordlist[j].Soo = W.wordlist[j + 1].Soo;
W.wordlist[j + 1].spelling = word;
W.wordlist[j + 1].Soo = k;
}
}
}
cout << "词汇数量(不计重复单词):" << W.NumofWord<<endl;
cout << "词汇数量(计重复单词):" << W.SumofWord << endl;
i = 1;
cout << "频次前十的单词:" << endl;
while (i<=10)
{
if (i > W.NumofWord)
{
break;
}
else
{
cout <<i <<"、 "<<W.wordlist[i - 1].spelling <<" 出现频次:"<<W.wordlist[i-1].Soo<< endl;
}
i++;
}
fp.close();
}
2、统计用户指定的长度的单词的数量。
通过函数Findgoalword
遍历单词表,并对单词进行匹配,如果有满足字符长度的单词就将计数器加一,然后将频次累加到另一个计数器中去。
void Findgoalword(Wordlist W,int n)//统计指定长度的单词的数量
{
int num=0;
int sum = 0;
for (int i = 0; i < W.NumofWord; ++i)
{
if (W.wordlist[i].spelling.length() == n)
{
num++;
sum = sum + W.wordlist[i].Soo;
}
}
cout << n << "个字符长度的单词数量(不计重复单词): " << num << endl;
cout<<n<< "个字符长度的单词数量(计重复单词): " << sum << endl;
}
五、测试(含单元测试和程序测试)
内存追加模块测试:
最初为单词表开辟内存时使用的是c语言的malloc函数,但是会出现访问失败的情况,最后使用了c++语言中的new为Word数组开辟内存空间。
在解决掉上述问题后,随之发现,当txt文件中的数据过大,导致单词表的的内存溢出。在网上查找资料后没发现适合当前情况的为结构体数组追加内存的方法,于是采用了在以前在学数据结构时的办法。
内存追加模块测试代码:
测试代码:
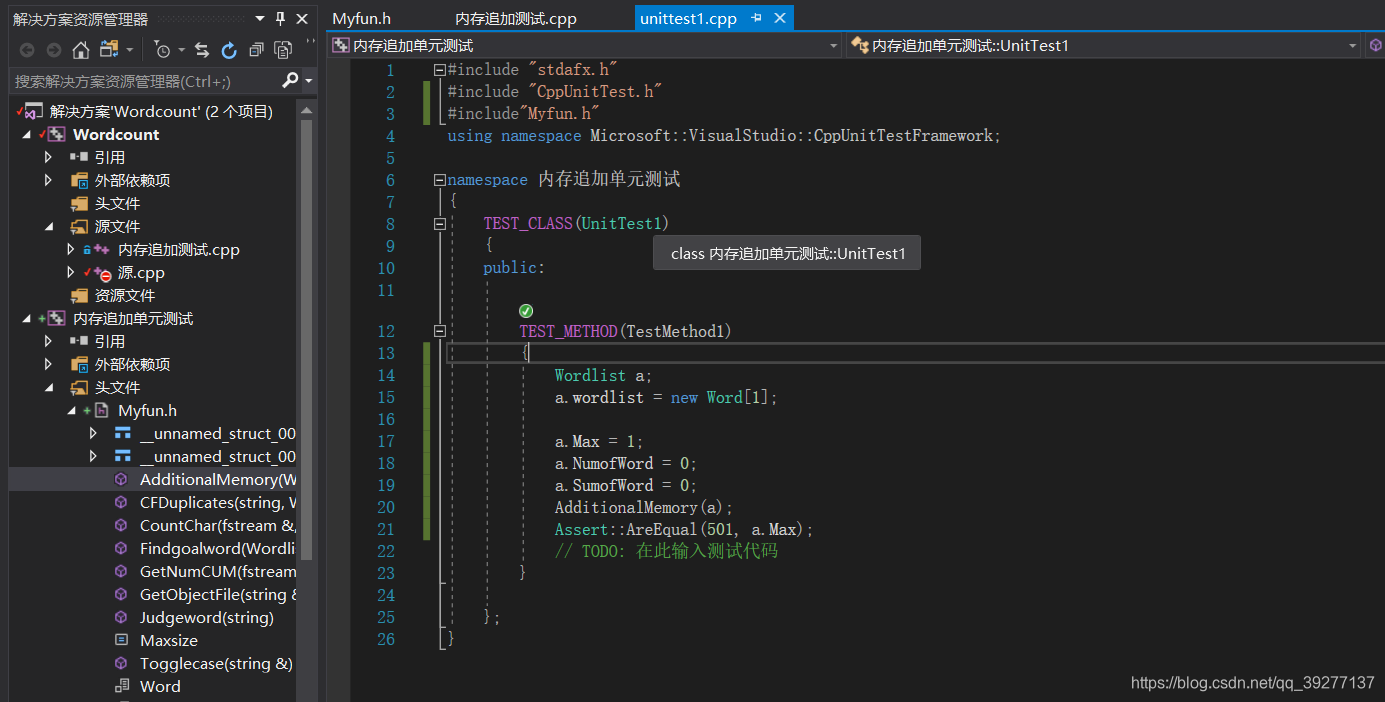
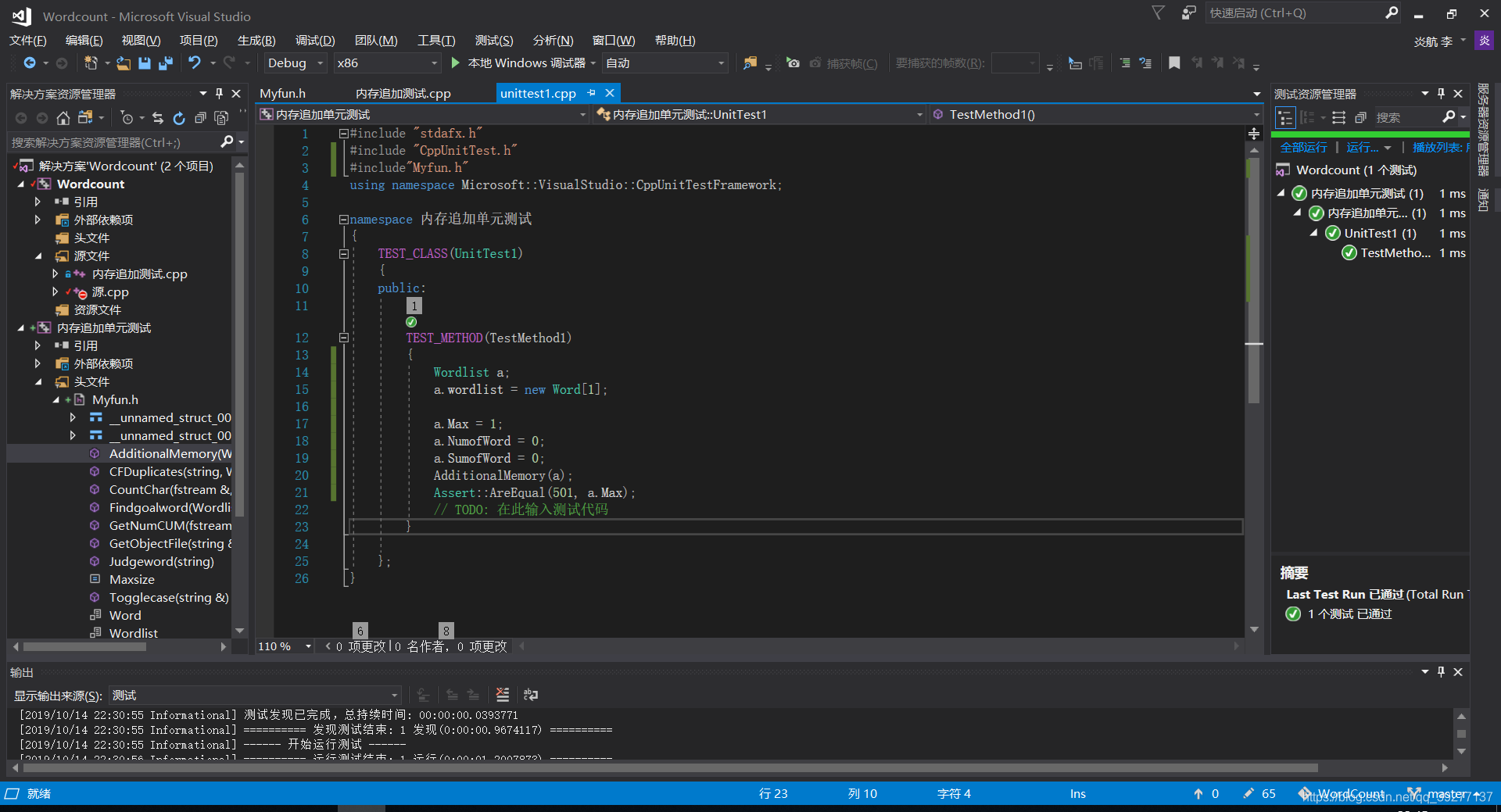
测试通过:
单词查重模块测试
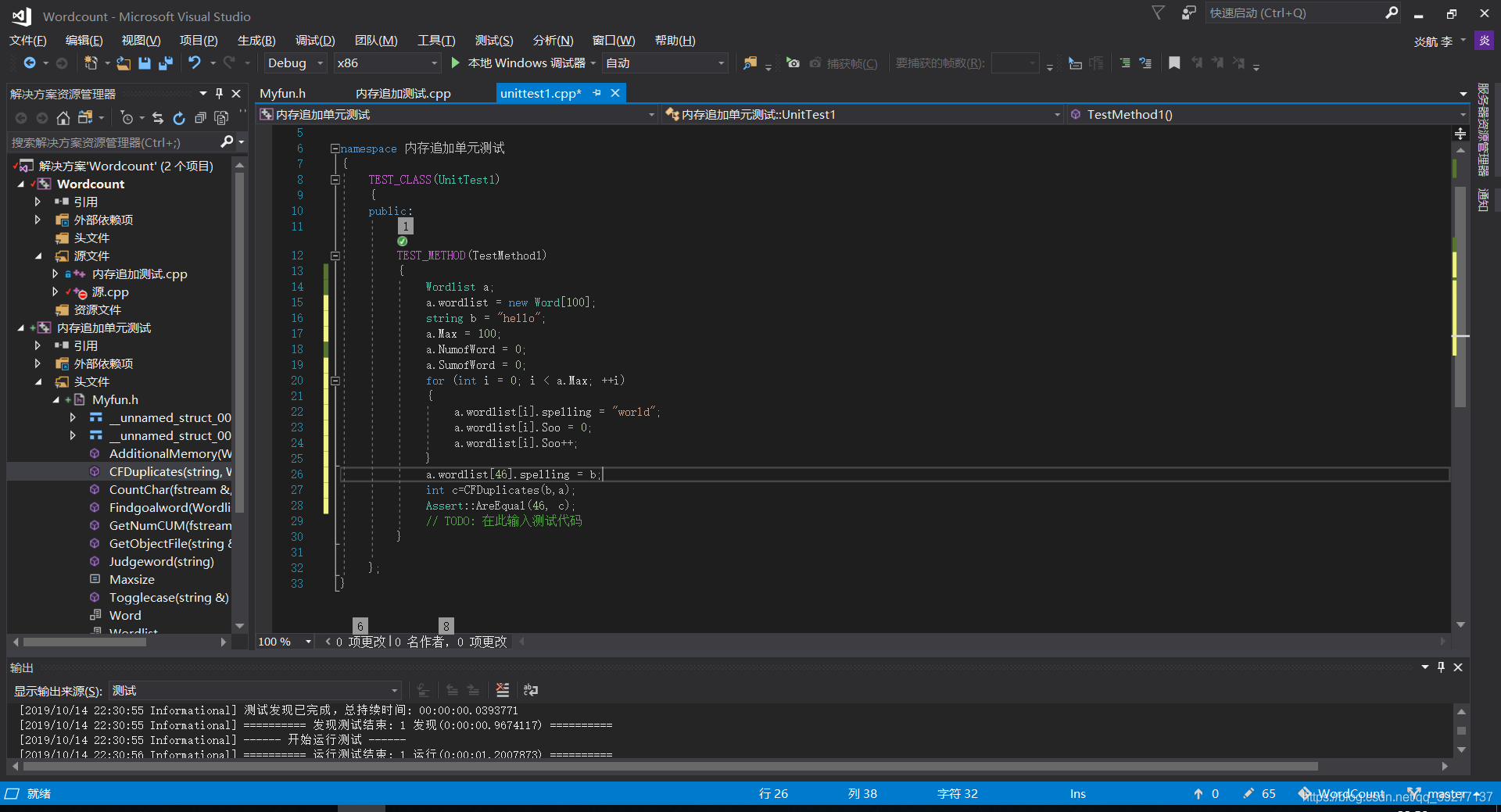
测试结果:
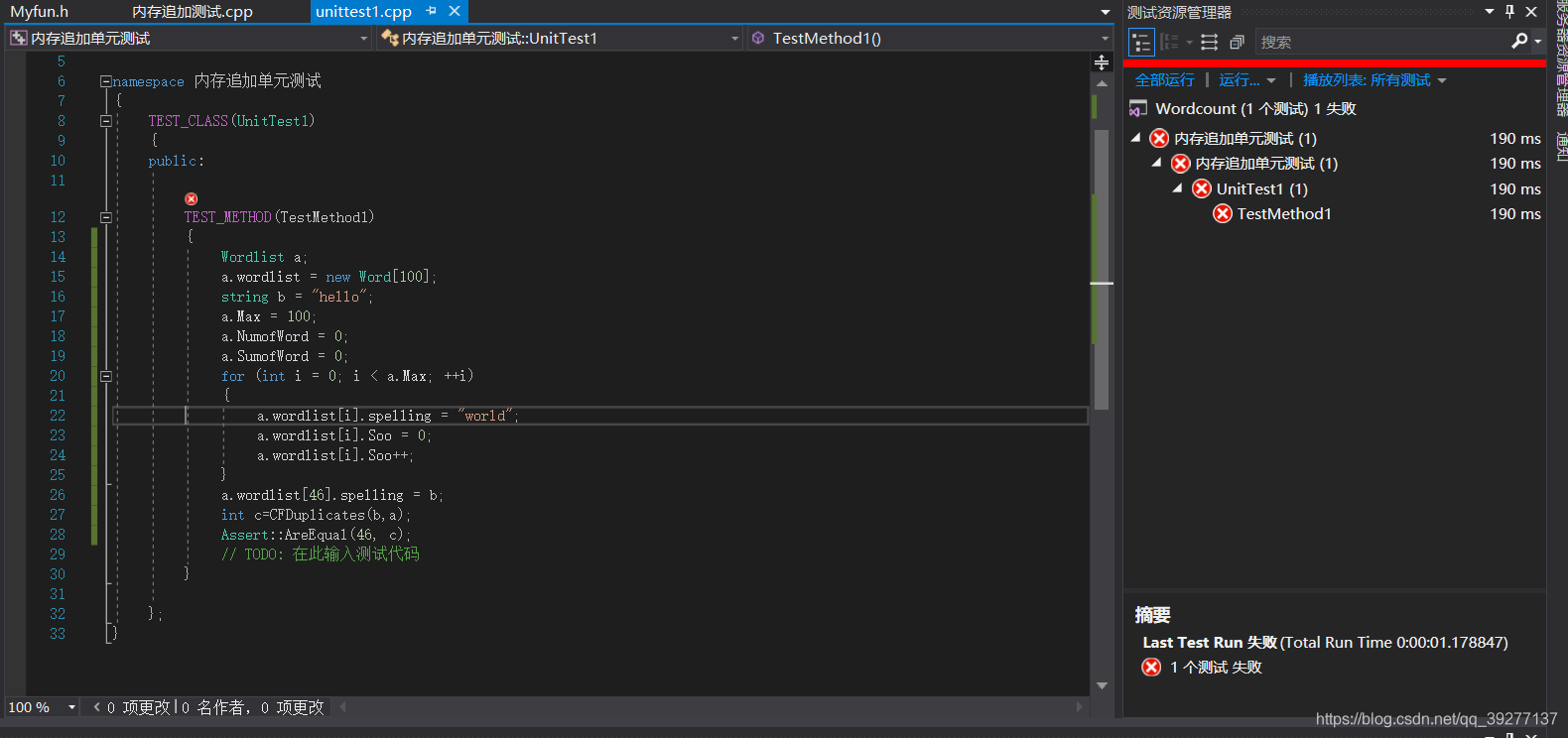
测试未通过原因:在单词查重函数中的循环条件为i<W.Numofword,而在测试代码中对单词表a的NumofWord值初始化为0,故无法进入循环。
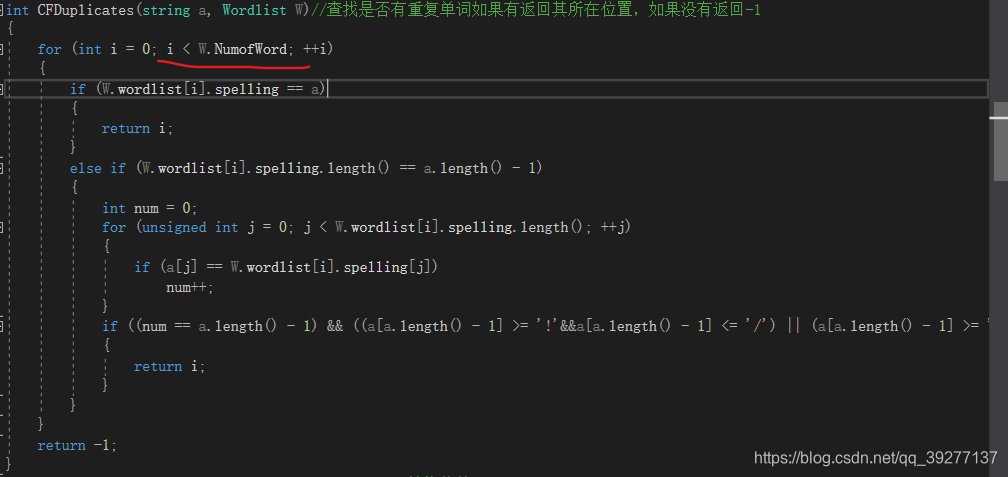
将在调用函数之前将a.Numofword的值设为a.Max
再次测试,测试通过:
程序运行测试:当文档中为空时
运行结果:
程序运行测试:当文档中有中文时:
运行结果:
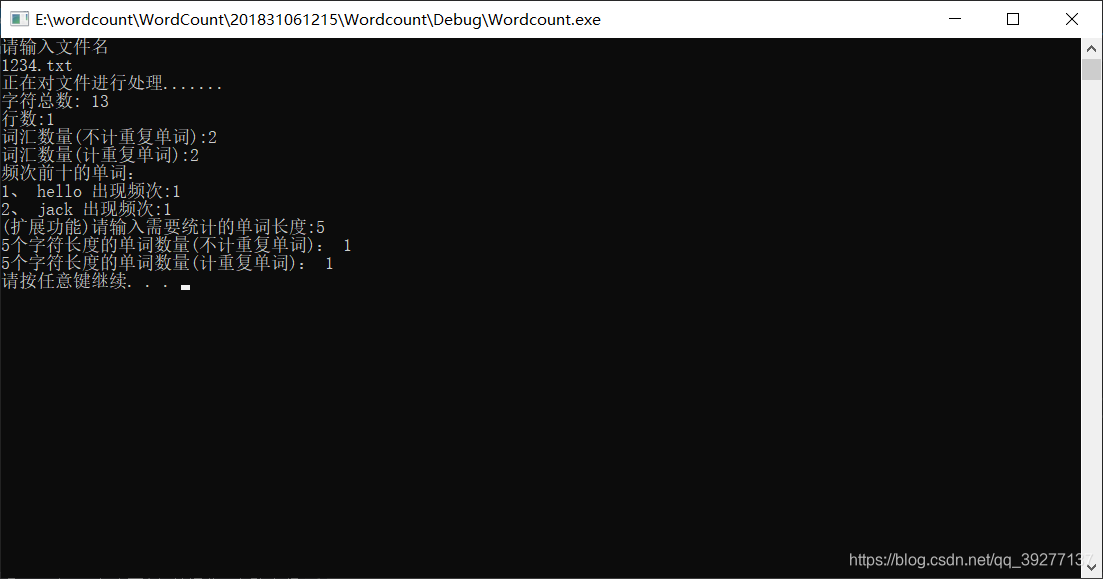
程序运行测试:当文档中全是中文时:
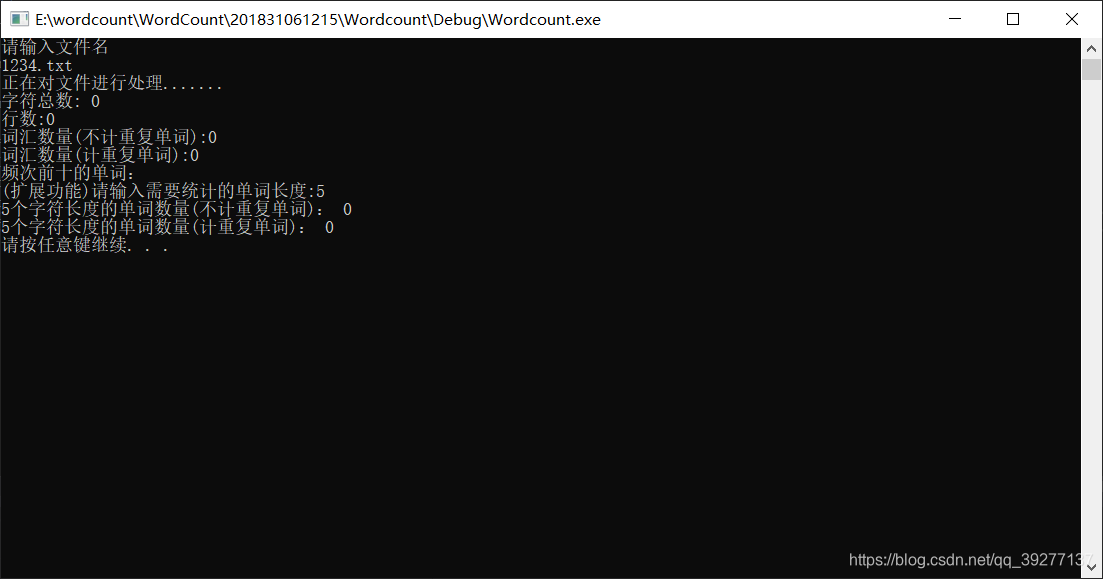
程序能够判断出来的字符中没有汉字以及一些中文里的标点符号,所以字符数显示为零。
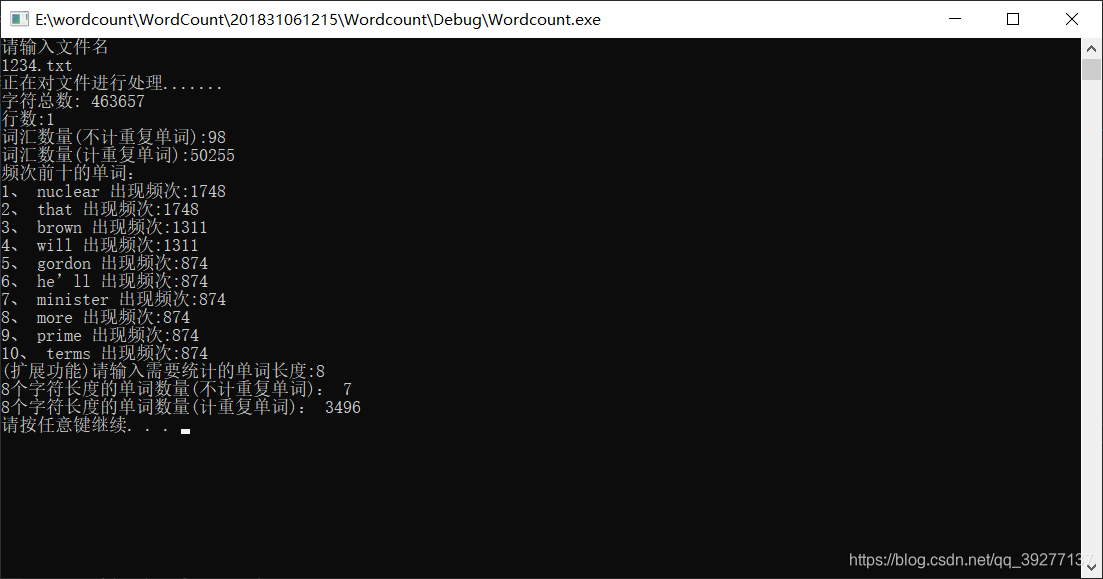
程序运行测试:当文档中的内容很大时

测试通过:
程序运行测试:当文档中有特殊符号时
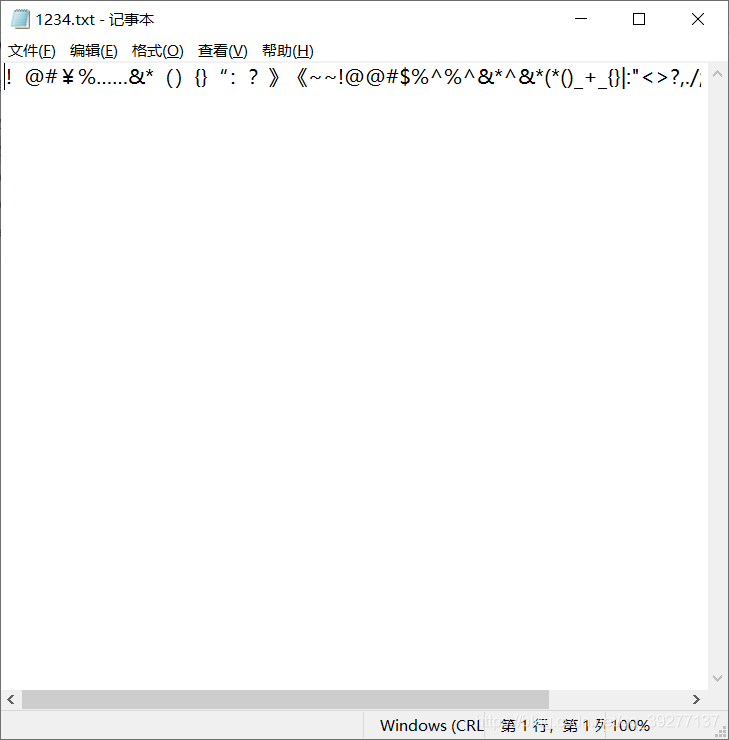
测试通过:
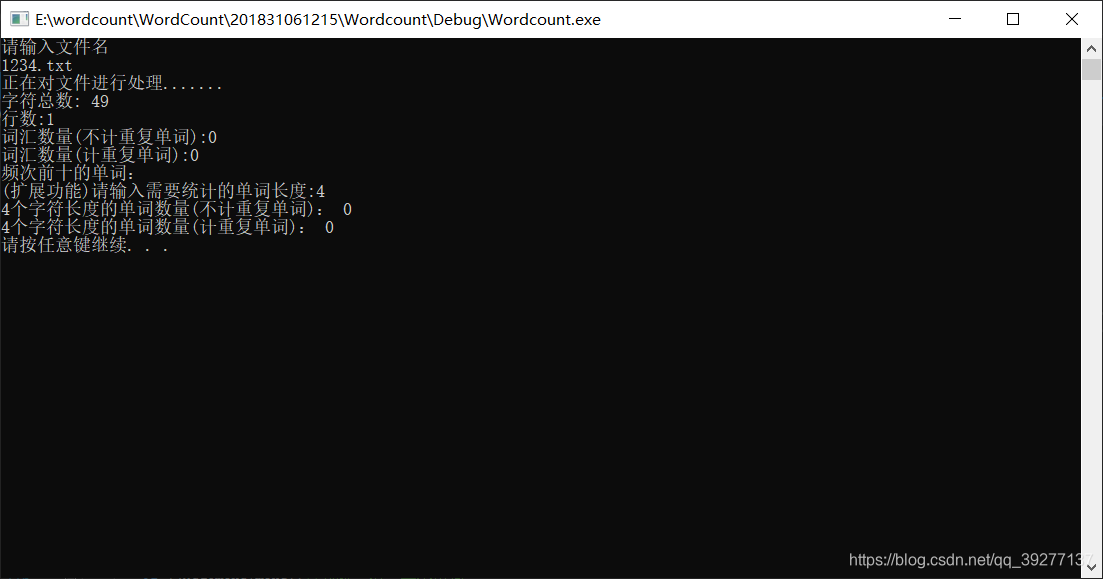
程序运行测试:用户输入的文件不存在时:
测试结果:
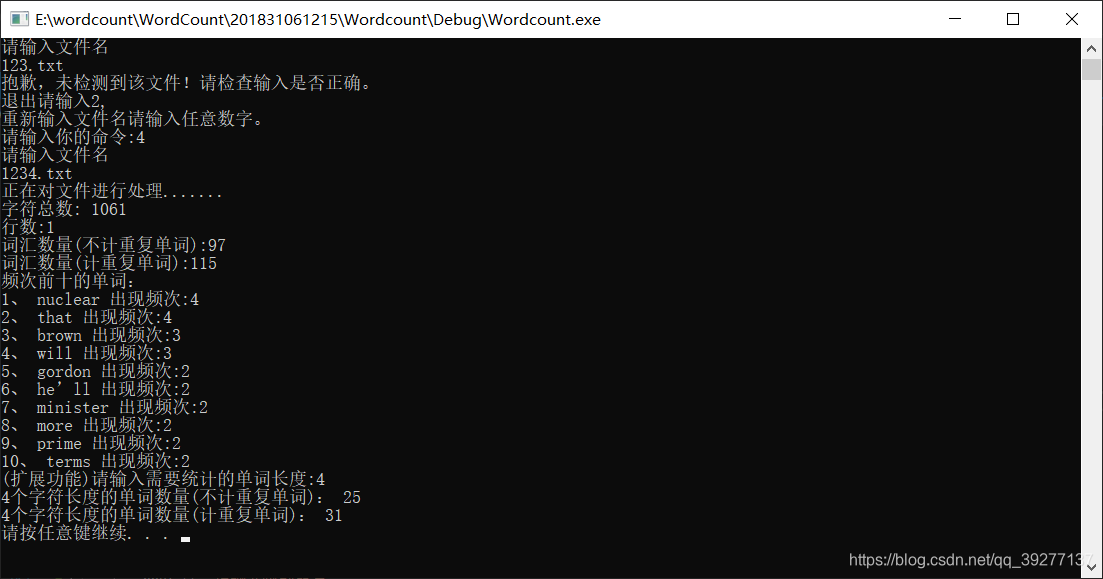
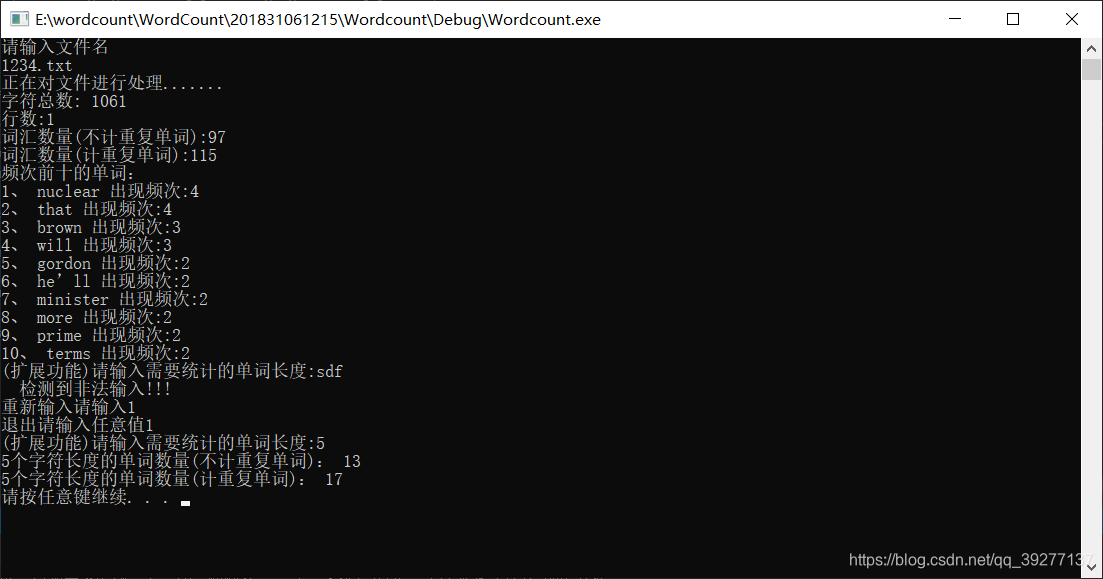
程序运行测试:用户输入的需要统计的单词长度不是数字时.
测试结果:通过
六、性能改进
程序效能分析:
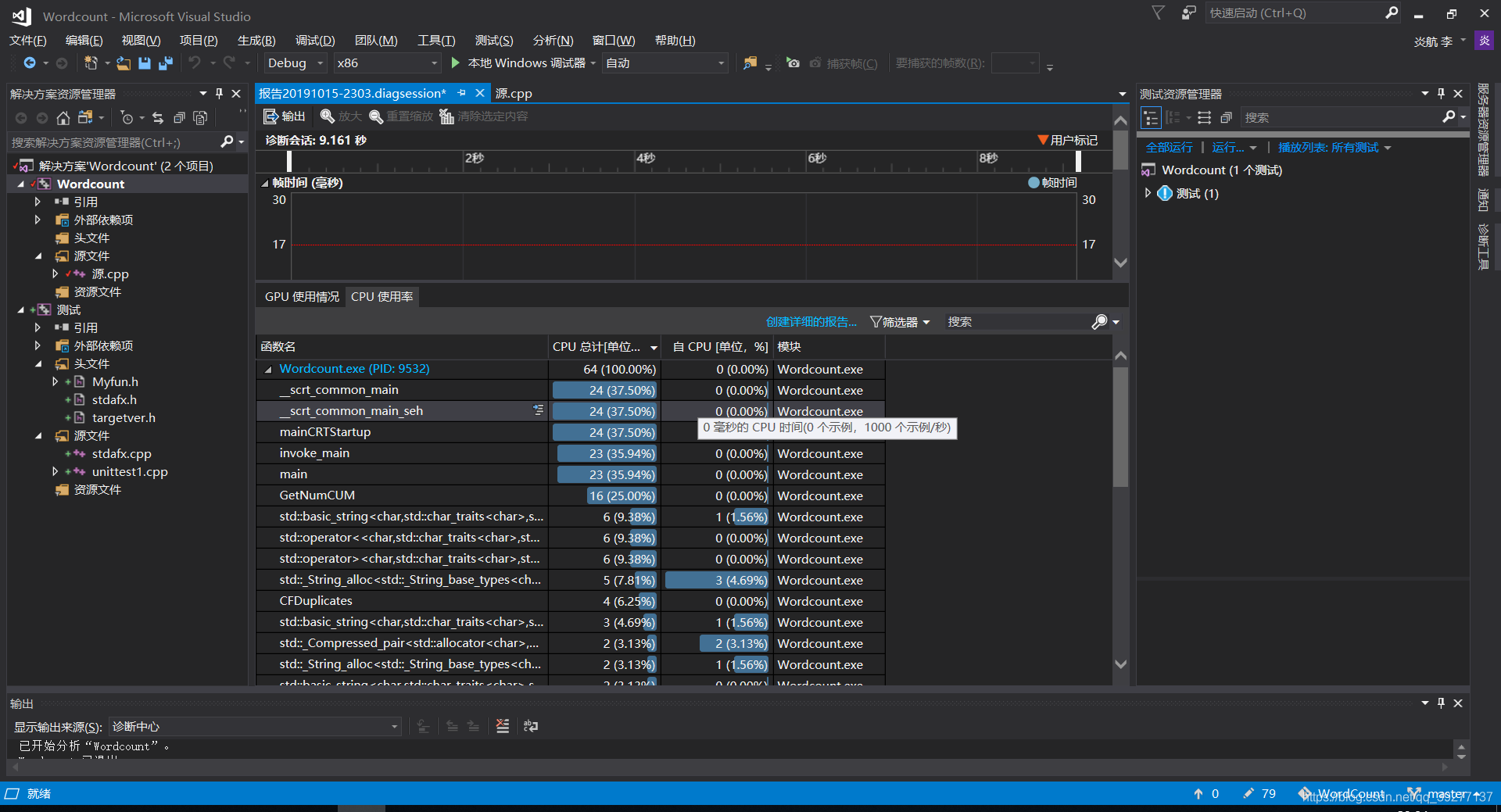
性能改进:
由图可知耗费资源最多的函数是GetNumCUM函数,该函数的功能是统计单词数目,并统计词频前十的单词。在该函数中还实现了对程序数据结构单词表的初始化,内存开辟以及追加,以及对文件的浏览,所以耗费整个程序的资源最多。改进方面,对其中的循环进行了优化,减少循环次数,但不影响其功能,更多的性能改进还在继续中。
七、代码复审
进行代码复审时,发现的一些问题,在发现问题之后我们及时改正和总结。一些是一些例子。
在声明变量时未注释变量的功能及作用:

改进:

调用主要函数时未声明函数的功能

改正:

八、项目版本提交:
在提交之前已排除掉所有warning。
第二次提交:
第五次提交:
九、结对感受
结对编程的好处就在于当遇见问题时,两个人解决问题的速度好过一个人解决问题。在代码复审方面也是有很大的好处,当自己被自己的代码困住时,结对伙伴是个让你摆脱困境的不二选择。1+1>2是有前提条件的,这取决于结对伙伴之间的默契程度等众多因素。


