

上篇文章尝试着使用head lock和tail lock分别在Get和Add元素时,对队列进行上锁,这样就避免了每次操作都锁住整个队列,缩小了锁的粒度。这里还有个问题,队列中持有的T对象指针,均是由调用者动态分配和释放的,如果调用量特别大,new/delete操作频繁,同样会导致性能下降,可能使系统产生大量的内存碎片。对于这个问题,我最开始想到的是让队列中不持有原生指针,而是使用带引用计数的智能指针,但后来想想,这样只可能避免内存泄露和赋值拷贝时大量内存复制的情况,而队列中元素只有存取两种行为,要解决大量的内存分配和释放操作,这样的做法显然不能对性能带来大的提高。
那么如何才能避免大量的内存分配和释放呢,仔细思考,想到两种方式:
- 使用内存池。我们知道,内存池的原理是,“内存分配调用预先一次性申请适当大小的内存作为一个内存池,之后应用程序自己对内存的分配和释放则可以通过这个内存池来完成。只有当内存池大小需要动态扩展时,才需要再调用系统的内存分配函数,其他时间对内存的一切操作都在应用程序的掌控之中。” 我们可以将自定义的内存池,加入T类的声明中,对T类的operator new和operator delete进行重载,实际使用内存池的分配和释放函数,这样对象分配的内存要比缺省operator new更少,而且运行得更快。需要注意的是,在多线程环境中,内存池有可能被多个线程共享,因此需要在每次分配和释放内存时加锁,而这样一来,元素构造析构时需要加锁,在队列中进行Add和Get同样需要加锁,是否能够使性能提高还需要实际的测试来验证。
- 如果我们不使用动态分配的方式,让队列保存栈上的对象,而不是堆中的指针,这样一来不用管理指针的生命周期,二来不用进行大量的new/delete调用。那么问题是当元素的个数是未知数是,我们可以动态的分配,而如果要将元素对象像数组元素一样保存在队列中,我们无法确定这个队列中这个数组容器的大小,这就需要事先明确了缓冲区的最大容量的情形,可以使用循环队列来处理。
这里我们主要讨论下循环队列在生产者消费者模式中的应用。循环队列是一段固定大小的连续内存空间,它保存的元素不需要进行动态的内存释放和分配,使用固定大小的内存空间反复使用,当一个数据元素被用掉后,其余数据元素不需要移动其存储位置。
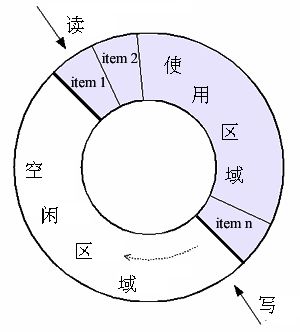
从图中的循环队列可以看出,两个指针head和tail来分别表示读和写的位置,开始时队列为空,head和tail指向第一个元素。向队列中Add元素时,head指针向后移动,从队列中Get元素时,tail指针向后移动。当Add操作频率远大于Get时,head指针追赶上tail指针,说明队列中元素已满,需要等待Get操作,而如果Get操作频率远大于Add时,tail元素会追赶上head元素,说明队列已经空了,需要等待Add操作。这里有两个阻塞动作,那么我们需要用两个条件变量分别控制队列已满还是队列为空,让线程等待。
同时注意如果head和tail指针相等,指向同一个位置时,既可以表示队列为空,也可以表示队列已满,那么如何区分是队满还是队空。我们可以少用一个元素的空间,约定入队前,测试tail指针在循环意义下加1后是否等于head指针,若相等则认为队满。这意味着缓冲区中总是有一个存储单元保持未使用状态。缓冲区最多存入size-1个数据。我们对之前的BlockQueue进行修改,来实现循环队列:
1 #define MAXSIZE 1024
2
3 template<class T>
4 class CircleQueue
5 {
6 public:
7 CircleQueue(unsigned int size = MAXSIZE);
8 ~CircleQueue();
9
10 bool Add(const T &cData, int timeout = 0);
11 bool Get(T &cData, int timeout = 0);
12 bool IsFull();
13 bool IsEmpty();
14 private:
15 T *buffer;
16 int head, tail;
17 unsigned int maxsize;
18 int m_nBlockOnAdd; //阻塞在Add操作中的线程个数
19 int m_nBlockOnGet; //阻塞在Get操作中的线程个数
20 CMutex m_cLock;
21 CCond m_addCond; //队列满时,Add操作阻塞
22 CCond m_getCond; //队列空时,Get操作阻塞
23 };
24
25 template<class T>
26 CircleQueue<class T>::CircleQueue(unsigned int size):head(0), tail(0), maxsize(size), m_nBlockOnAdd(0), m_nBlockOnGet(0)
27 {
28 buffer = new T[maxsize];
29 }
30
31 template<class T>
32 CircleQueue<class T>::~CircleQueue()
33 {
34 if(buffer != NULL)
35 delete[] buffer;
36 buffer == NULL;
37 head = tail = 0;
38 m_nBlockOnAdd = m_nBlockOnGet = 0;
39 }
40
41 template<class T>
42 bool CircleQueue<class T>::IsFull()
43 {
44 return (tail+1) % maxsize == head;
45 }
46
47 template<class T>
48 bool CircleQueue<class T>::IsEmpty()
49 {
50 return head == tail;
51 }
52
53 template<class T>
54 bool CircleQueue<class T>::Add(const T &cData, int timeout)
55 {
56 m_cLock.EnterMutex();
57 while(isFull())
58 {
59 m_nBlockOnAdd++;
60 if(m_addCond.WaitLock(m_cLock.GetMutex(), timeout) == 1)
61 {
62 m_cLock.LeaveMutex();
63 m_nBlockOnAdd--;
64 return false;
65 }
66 m_nBlockOnAdd--;
67 }
68
69 buffer[tail] = cData;
70 tail = (tail+1) % maxsize;
71
72 if(m_nBlockOnGet > 0)
73 m_getQueue.Signal();
74
75 m_cLock.LeaveMutex();
76
77 return true;
78 }
79
80 template<class T>
81 void CircleQueue<class T>::Get(T &cData, int timeout)
82 {
83 m_cLock.EnterMutex();
84 while (isEmpty())
85 {
86 m_nBlockOnGet++;
87 if (m_getCond.WaitLock(m_cLock.GetMutex(), timeout) == 1)
88 {
89 m_cLock.LeaveMutex();
90 m_nBlockOnGet--;
91 return false;
92 }
93 m_nBlockOnGet--;
94 }
95
96 cData = buffer[head];
97 head = (head+1) % maxsize;
98
99 if(m_nBlockOnAdd > 0)
100 m_addCond.Signal();
101
102 m_cLock.LeaveMutex();
103
104 return true;
105 }
对上面的代码进行分析,可以看出:
- 代码中这个阻塞循环队列,在构造函数中用new操作符新建了一块连续的内存,而用于存储的T类型需要提供默认构造函数。
- Add和Get函数都加上超时限制,布尔类型的返回值表示函数是否调用成功,而函数的出参和入参为引用方式,避免了不必要的数据拷贝。
- m_nBlockOnAdd和m_nBlockOnGet分别表示阻塞在Add函数和Get函数的线程个数,通过这两个值,可以高效的对阻塞线程进行唤醒操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号