

BS4解析库
Beautiful Soup简称BS4(4表示版本号),是一个python第三方库,它可以从HTML或XML文档中快速提取指定的数据。
BS4安装
pip3 install bs4
#BS4解析页面时,需要依赖文档解析器,所以还需要安装lxml作为解析库
pip3 install lxml
BS4解析对象
创建BS4解析对象是万事开头的第一步
#导入解析包
from bs4 import BeautifulSoup
#创建beautifulsoup解析对象
soup = BeautifulSoup(html_doc,"lxml")
#注:如果是外部文档,可以通过open()方式打开读取,格式如下:
soup = BeautifulSoup(open('html_doc.html',encoding="utf-8"),"lxml")
BS4常用语法
Beautiful Soup将HTML文档转换成一个树形结构,该结构有利于快速的遍历和搜索HTML文档。
<html><head><title>c语言中文网</title></head><h1>c.biancheng.net</h1><p><b>一个学习编程的网站</b></p></body></html>
对应树状图如下:
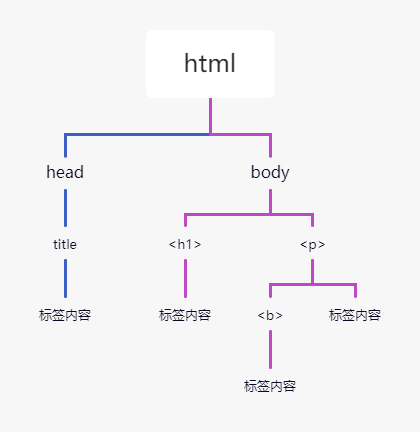
文档树中的每个节点都是python对象,这些对象大致可分为四类:Tag、NavigableString、BeautifulSoup、Comment。其中使用最多的是Tag和NavigableString。
- Tag:标签类,HTML文档中所有的标签都可以看做Tag对象
- NavigableString:字符串类,指的是标签中的文本内容,使用text、string、strings来获取文本内容
- BeautifulSoup:表示一个HTML文档的全部内容,可以将其当做一个特殊的tag对象
- Comment:表示HTML文档中的注释内容以及特殊字符串,它是一个特殊的NavigableString
Tag节点
标签是组成HTML文档的基本元素。在BS4中,通过标签名和标签属性可以提取出想要的内容。示例如下:
#!/usr/bin/python3
#coding=utf-8
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p class="Web site url"><b>c.biancheng.net</b></p>',"lxml")
#获取整个p标签的html代码
print("soup.p输出结果:")
print(soup.p)
#获取b标签
print("soup.p.b输出结果:")
print(soup.p.b)
#获取p标签内容,使用NavigableString类中的string、text、get_text()
print("soup.p.text输出结果:")
print(soup.p.text)
#获取p标签属性
print("soup.p.attrs输出结果:")
print(soup.p.attrs)
#查看返回的数据类型
print("type(soup.p)输出结果:")
print(type(soup.p))
#根据属性,获取标签的属性值,返回值为列表】
print("soup.p['class']输出结果是")
print(soup.p["class"])
#给class属性赋值,此时属性值由列表转换为字符串
soup.p["class"] = ["Torres","Web"]
print(soup.p)
执行结果如下:
soup.p输出结果:
<p class="Web site url"><b>c.biancheng.net</b></p>
soup.p.b输出结果:
<b>c.biancheng.net</b>
soup.p.text输出结果:
c.biancheng.net
soup.p.attrs输出结果:
{'class': ['Web', 'site', 'url']}
type(soup.p)输出结果:
<class 'bs4.element.Tag'>
soup.p['class']输出结果是
['Web', 'site', 'url']
<p class="Torres Web"><b>c.biancheng.net</b></p>
遍历节点
Tag对象提供了许多遍历tag节点的属性,比如concents、children用来遍历子节点;parent和parents用来遍历父节点;而next_sibling和previous_sibling则用来遍历兄弟节点。示例如下:
#!/usr/bin/python3
#coding=utf-8
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>"c语言中文网"</title></head>
<body>
<p class="title"><b>c.biancheng.net</b></p>
<p class="website">一个学习编程的网站</p>
<a href="http://c.biancheng.net/python/" id="link1">python教程</a>,
<a href="http://c.biancheng.net/c/" id="link2">c语言教程</a> and
"""
soup = BeautifulSoup(html_doc,"html.parser")
body_tag = soup.body
print(body_tag)
print(body_tag.contents)
#Tag的children属性会生成一个可迭代对象,可用来遍历子节点
for child in body_tag.children:
print(child)
输出结果:
<body>
<p class="title"><b>c.biancheng.net</b></p>
<p class="website">一个学习编程的网站</p>
<a href="http://c.biancheng.net/python/" id="link1">python教程</a>,
<a href="http://c.biancheng.net/c/" id="link2">c语言教程</a> and
</body>
#以列表形式输出
['\n', <p class="title"><b>c.biancheng.net</b></p>, '\n', <p class="website">一个学习编程的网站</p>, '\n', <a href="http://c.biancheng.net/python/" id="link1">python教程</a>, ',\n', <a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>, ' and\n']
#child
<p class="title"><b>c.biancheng.net</b></p>
<p class="website">一个学习编程的网站</p>
<a href="http://c.biancheng.net/python/" id="link1">python教程</a>
,
<a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>
and
find()和find_all()
find()和find_all()是解析HTML文档的常用方法,它们可以在HTML文档中按照一定的条件(相当于过滤器)查找所需内容。
find_all()
find_all()方法用来搜索当前tag的所有子节点,并判断这些节点是否符合过滤条件,最后以列表形式将符合条件的内容返回,语法格式如下:
find_all(name,attrs,recursive,text,limit)
参数说明:
- name:查找所有名字为name的tag标签,字符串对象会被自动忽略
- attrs:按照属性名和属性值搜索tag标签(注意:由于class是python的关键字,所以要用“class_”)
- recursive:find_all()会搜素tag的所有子孙节点,设置recursive=False可以只搜索tag的直接子节点
- text:用来搜索文档中的字符串内容,该参数可以接收字符串、正则表达式、列表、True。
- limit:由于find_all()会返回所有的搜索结果,这样会影响执行效率,通过limit参数可以限制返回结果的数量
使用示例如下:
#!/usr/bin/python3
#coding=utf-8
import re
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>"c语言中文网"</title></head>
<body>
<p class="title"><b>c.biancheng.net</b></p>
<p class="website">一个学习编程的网站</p>
<a href="http://c.biancheng.net/python/" id="link1">python教程</a>
<a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>
<a href="http://c.biancheng.net/django/" id="link3">django教程</a>
<p class="vip">加入我们阅读所有教程</p>
<a href="http://vip.biancheng.net/?from=index" id="link4">成为vip</a>
"""
#创建soup解析对象
soup = BeautifulSoup(html_doc,"lxml")
#查找所有a标签并返回
print(soup.find_all("a"))
#查找前两条标签
print(soup.find_all("a",limit=2))
返回结果如下:
>>> soup = BeautifulSoup(html_doc,"lxml")
>>> print(soup.find_all("a"))
[<a href="http://c.biancheng.net/python/" id="link1">python教程</a>, <a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>, <a href="http://c.biancheng.net/django/" id="link3">django教程</a>, <a href="http://vip.biancheng.net/?from=index" id="link4">成为vip</a>]
#只返回前两条结果
>>> print(soup.find_all("a",limit=2))
[<a href="http://c.biancheng.net/python/" id="link1">python教程</a>, <a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>]
#列表查询tag标签
>>> print(soup.find_all(['b','a']))
[<b>c.biancheng.net</b>, <a href="http://c.biancheng.net/python/" id="link1">python教程</a>, <a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>, <a href="http://c.biancheng.net/django/" id="link3">django教程</a>, <a href="http://vip.biancheng.net/?from=index" id="link4">成为vip</a>]
#正则表达式匹配id属性值
>>> print(soup.find_all("a",id=re.compile(r".\d")))
[<a href="http://c.biancheng.net/python/" id="link1">python教程</a>, <a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>, <a href="http://c.biancheng.net/django/" id="link3">django教程</a>, <a href="http://vip.biancheng.net/?from=index" id="link4">成为vip</a>]
#True可以匹配任何值,以下返回相应的tag名称
>>> for tag in soup.find_all(True):
... print(tag.name)
...
html
head
title
body
p
b
p
a
a
a
p
a
#输出所有以b开始的tag标签
>>> for tag in soup.find_all(re.compile("^b")):
... print(tag.name)
...
body
b
find()
find()和find_all()类似,不同之处在于:find_all()会将文档这是所有符合条件的结果返回,而find()仅返回第一个符合条件的结果,所以find()方法没有limit参数。示例如下:
#!/usr/bin/python3
#coding=utf-8
import re
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>"c语言中文网"</title></head>
<body>
<p class="title"><b>c.biancheng.net</b></p>
<p class="website">一个学习编程的网站</p>
<a href="http://c.biancheng.net/python/" id="link1">python教程</a>
<a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>
<a href="http://c.biancheng.net/django/" id="link3">django教程</a>
<p class="vip">加入我们阅读所有教程</p>
<a href="http://vip.biancheng.net/?from=index" id="link4">成为vip</a>
"""
#创建soup解析对象
soup = BeautifulSoup(html_doc,"lxml")
#查找第一个a标签并返回
print(soup.find_("a"))
#查找title
print(soup.find("title"))
#匹配指定herf属性的a标签
print(soup.find("a",href='http://c.biancheng.net/python/'))
#根据属性值正则匹配
print(soup.find(class_=re.compile("tit")))
#attr参数值
print(soup.find(attrs={"class":"vip"}))
结果如下:
#查找第一个a标签并返回
>>> print(soup.find("a"))
<a href="http://c.biancheng.net/python/" id="link1">python教程</a>
#查找title
>>> print(soup.find("title"))
<title>"c语言中文网"</title>
#匹配指定herf属性的a标签
>>> print(soup.find("a",href="http://c.biancheng.net/python/"))
<a href="http://c.biancheng.net/python/" id="link1">python教程</a>
#根据属性值正则匹配
>>> print(soup.find(class_=re.compile("tit")))
<p class="title"><b>c.biancheng.net</b></p>
#attr参数值
>>> print(soup.find(attrs={"class":"vip"}))
<p class="vip">加入我们阅读所有教程</p>
CSS选择器
BS4支持大部分的CSS选择器,比如常见的标签选择器、类选择其、id选择器以及层级选择器。Beautiful Soup提供了一个select()方法,通过想该方法中添加选择器,就可以在HTML文档中搜索到与之对应的内容,示例如下:
#!/usr/bin/python3
#coding=utf-8
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>"c语言中文网"</title></head>
<body>
<p class="title"><b>c.biancheng.net</b></p>
<p class="website">一个学习编程的网站</p>
<a href="http://c.biancheng.net/python/" id="link1">python教程</a>
<a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>
<a href="http://c.biancheng.net/django/" id="link3">django教程</a>
<p class="vip">加入我们阅读所有教程</p>
<a href="http://vip.biancheng.net/?from=index" id="link4">成为vip</a>
<p class="introduce">介绍:
<a href="http://c.biancheng.net/view/8066.html" id="link5">关于网站</a>
<a href="http://c.biancheng.net/view/8092.html" id="link6">关于站长</a>
</p>
"""
soup = BeautifulSoup(html_doc,"lxml")
#根据元素标签查找
print(soup.select("title"))
#根据属性选择器查找
print(soup.select("a[href]"))
#根据类查找
print(soup.select(".vip"))
#后代节点查找
print(soup.select("html head title"))
#查找兄弟节点
print(soup.select("p + a"))
#根据id选择p标签的兄弟节点
print(soup.select("p ~ #link3"))
#nth-of-type(n)选择器,用于匹配同类型中的第n个同级兄弟元素
print(soup.select("p ~ a:nth-of-type(1)"))
#查找子节点
print(soup.select("p > a"))
print(soup.select(".introduce > #link5"))
结果如下:
[root@aliyun ~]# python3 /home/python/test.py
[<title>"c语言中文网"</title>]
[<a href="http://c.biancheng.net/python/" id="link1">python教程</a>, <a href="http://c.biancheng.net/c/" id="link2">c语言教程</a>, <a href="http://c.biancheng.net/django/" id="link3">django教程</a>, <a href="http://vip.biancheng.net/?from=index" id="link4">成为vip</a>, <a href="http://c.biancheng.net/view/8066.html" id="link5">关于网站</a>, <a href="http://c.biancheng.net/view/8092.html" id="link6">关于站长</a>]
[<p class="vip">加入我们阅读所有教程</p>]
[<title>"c语言中文网"</title>]
[<a href="http://c.biancheng.net/python/" id="link1">python教程</a>, <a href="http://vip.biancheng.net/?from=index" id="link4">成为vip</a>]
[<a href="http://c.biancheng.net/django/" id="link3">django教程</a>]
[<a href="http://c.biancheng.net/python/" id="link1">python教程</a>]
[<a href="http://c.biancheng.net/view/8066.html" id="link5">关于网站</a>, <a href="http://c.biancheng.net/view/8092.html" id="link6">关于站长</a>]
[<a href="http://c.biancheng.net/view/8066.html" id="link5">关于网站</a>]


 浙公网安备 33010602011771号
浙公网安备 33010602011771号