
Selenium是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。对于一些JavaScript动态渲染的页面来说,此种爬取方式非常有效。
1、基本用法
#!/usr/bin/python3
#coding=utf-8
from selenium import webdriver
#要想调用键盘按键操作需引入keys包
from selenium.webdriver.common.keys import keys
#创建浏览器对象
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
#打印页面标题“百度一下你就知道”
print(driver.title)
#生成当前页面快照
driver.save_screenshot("baidu.png")
#id="kw"是百度搜索框,输入字符串“微博”,跳转到搜索中国页面
driver.find_element_by_id("kw").send_keys(u"微博")
#id="su"是百度搜素按钮,click()是模拟点击
driver.find_element_by_id("su").click()
#获取新的页面快照
driver.save_screenshot(u"微博.png")
#打印页面渲染后的源代码
print(driver.page_source)
#获取当前页面的Cookie
print(driver.get_cookies())
#ctrl + a全选输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,"a")
#ctrl + x剪切输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,"x")
#输入框重新输入内容
driver.find_element_by_id("kw").send_keys("test")
#模拟Enter回车键
driver.find_element_by_id("su").send_keys(Keys.RETURN)
#清除输入框内容
driver.find_element_by_id("kw").clear()
#生成新的页面快照
driver.save_screenshot("test.png")
#获取当前的url
print(driver.current_url)
#关闭当前页面,如果只有一个页面,会关闭浏览器
driver.close()
#关闭浏览器
driver.quit()
2、页面操作
假如有以下输入框
<input type="text" name="user-name" id="passwd-id" />
寻找方法
#获取id标签值
element = driver.find_element_by_id("passwd-id")
#获取name标签值
element = driver.find_element_by_name("user-name")
#获取标签名值
element = driver.find_element_by_tag_name("input")
#也可通过Xpath来匹配
element = driver.find_element_by_xpath("//input[@id='passwd-id']")
3、定位元素的方法
定位表单框架或“有效数据”位置,Selenium本身自带有18个函数,总共8种方法从返回数据中定位“有效数据位置”。
find_element(self,by="id",value=None)
find_element_by_class_name(self,name)
find_element_by_css_selector(self,css_selector)
find_element_by_id(self,id)
find_element_by_link_text(self,link_text)
find_element_by_name(self,name)
find_element_by_partial_link_text(self,link_text)
find_element_by_tag_name(self,name)
find_element_by_xpath(self,xpath)
find_elements(self,by="id",value=None)
find_elements_by_class_name(self,name)
find_elements_by_css_selector(self,css_selector)
find_elements_by_id(self,id)
find_elements_by_link_text(self,link_text)
find_elements_by_name(self,name)
find_elements_by_partial_link_text(self,link_text)
find_elements_by_tag_name(self,name)
find_elements_by_xpath(self,xpath)
这18个函数前面9个带element的函数将返回第一个符合参数要求的element。后面9个带elements的函数将返回一个列表,列表中包含所有符合参数要求的element。
命名是9个函数,为何只有8种方法呢?
上面函数中,不带by的函数,配合参数可以替代其他的函数。例如:find_element(self,by="id",value="abc")就可以代替find_element_by_id(‘abc’);同理,find_elements(self,by="id",value="abc")可以代替find_elements_by_id(‘abc’)
ps:
在使用浏览器请求数据时,用find_element_by_id、find_element_by_name、find_element_by_tag_name、find_element_by_class_name会比较方便,一般的表单、元素都会有name、class、id。如果仅仅是为了获取"有效数据"的位置,强烈推荐find_element_by_xpath。
4、鼠标动作
#!/usr/bin/python3
#coding=utf-8
from selenium import webdriver
#要想调用键盘按键操作需引入keys包
from selenium.webdriver.common.keys import keys
from selenium.webdriver import ActionChains
#创建浏览器对象
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
#鼠标移动到某处
action1 = driver.find_element_by_id("su")
ActionChains(driver).move_to_element(action1).perform()
#鼠标移动到某处单击
action2 = driver.find_element_by_id("su")
ActionChains(driver).move_to_element(action2).click(action2).perform()
#鼠标移动到某处双击
action3 = driver.find_element_by_id("su")
ActionChains(driver).move_to_element(action3).double_click(action3).perform()
#鼠标移动到某处右击
action4 = driver.find_element_by_id("su")
ActionChains(driver).move_to_element(action4).context_click(action4).perform()
5、Select表单
#!/usr/bin/pyhton3
#coding=utf-8
from selenium.webdriver.support.ui import Select
#找到name的选项卡
select = Select(driver.find_element_by_name("status"))
select.select_by_index(1)
select.select_by_value("0")
select/select_by_visible_text(u"xxx")
#全部取消方法
select.deselect_all()
PS:
以上是三种选择下拉框的方式,它可以根据索引来选择,可以根据值来选择,可以根据文字来选择。注意:
- index索引从0开始
- value是option标签的一个属性值,并不是显示在下拉框中的值
- visible_text是在option标签文本的值,是显示在下拉框的值
6、弹框处理
当页面出现了弹框提示
alert = driver.switch_to_alert()
7、页面切换
一个浏览器肯定会有很多窗口,所以我们肯定要有方法来实现窗口的切换,切换窗口的方法如下:
driver.switch_to.window("this is window name")
8、页面前进和后退
操作页面的前进和后退功能:
#前进
driver.forward()
#后退
driver.back()
实战一:模拟登陆豆瓣网站
#!/usr/bin/python3
#coding=utf-8
import time
from selenium import webdriver
from selenium.webdriver.common.keys import keys
driver = webdriver.Firefox()
driver.get("http://www.douban.com")
#输入账号密码
driver.find_element_by_name("form_email").send_keys("13545******")
driver.find_element_by_name("form_password").send_keys("tt*****")
#模拟点击登陆
driver.find_element_by_xpath("//input[@class='bn-submit']").click()
#等待3秒
time.sleep(3)
#生成登陆后快照
driver.save_screenshot(u"douban.pag")
#退出浏览器
driver.quit()
实战二:爬取斗鱼所有房间名和观众人数
(1)首先分析“下一页”的class变化,如果不是最后一页的时候,‘下一页’的class如下:

(2)到了最后一页,“下一页”变为隐藏,点击不了,class如下:

(3)找到具体某个房间的名字和观众人数的class
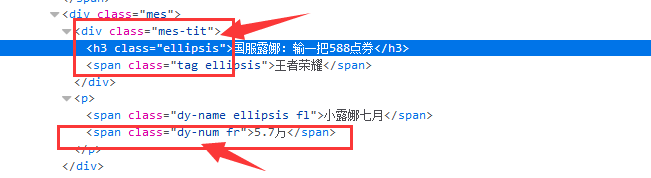
实现代码如下:
#!/usr/bin/python3
#coding=utf-8
import unittest
from selenium import webdriver
from bs4 import BeautifulSoup as bs
class Douyu(unittest.TestCase):
#初始化方法,必须是setUp()
def setUp(self):
self.driver = webdriver.Firefox()
self.num = 0
self.count = 0
#测试方法必须有test字样开头
def test_douyu(self):
self.driver.get("https://www.douyu.com/directory/all")
while True:
soup = bs(self.driver.page_source,"lxml")
#房间名,返回列表
names_list = soup.findall("h3",{"class" : "ellipsis"})
#观众人数,返回列表
numbers_list = soup.findall("span",{"class" : "dy-num fr"})
#zip(names_list,numbers_list)将names_list和number_list这两个列表合并为一个元组
for name,number in zip(names_list,numbers_list):
print("观众人数:%s,房间名:%s" % (number.get_text().strip(),name.get_text().strip()))
self.num += 1
#如果在页面源码中找到“下一页”为隐藏的标签,就退出循环
if self.driver.page_source.find("shark-pager-disable-next") != -1:
break
#一直点击下一页
self.driver.find_element_by_class_name("shark-pager-next").click()
#测试结束执行的方法
def tear_down(self):
#退出Firefox()浏览器
print("当前网站直播人数:%s" % str(self.num))
print("当前网站观众人数:%s" % str(self.count))
self.driver.quit()
if __name__ == "__main__":
#启动测试模块
unittest.main()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号