Python爬取京东商品列表
爬取代码:
import requests from bs4 import BeautifulSoup def page_url(url): for i in range(1, 3): if (i % 2) == 1: message(url.format(i)) def message(url): res = requests.get(url) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') n = 0 for news in soup.select('.gl-i-wrap'): title = news.select('.p-name')[0].text.strip() price = news.select('.p-price')[0].text.strip() commit = news.select('.p-commit')[0].text.strip() urls = r'http://' + news.select('.p-img')[0].contents[1]['href'] n += 1 print("%d、 \n 名称:%s \n 价格:%s \n 评价:%s \n 链接:%s" % (n, title, price, commit, urls)) f = open('info.txt', 'a+', encoding='utf-8') f.write(str(str(n)+title+price+commit+urls)) url = 'https://search.jd.com/Search?keyword=%E9%9E%8B%E5%AD%90&enc=utf-8&wq=%E9%9E%8B%E5%AD%90&pvid=2cb987320c55495393d8b67cce3532b3' page_url(url)

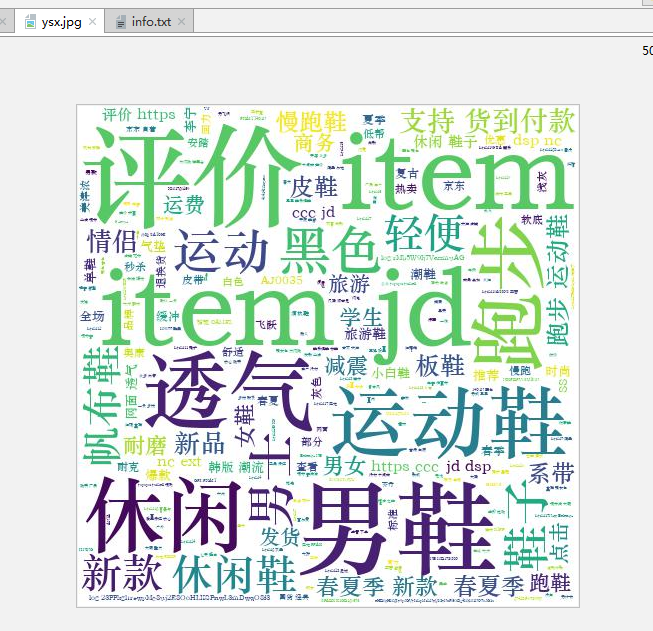
生成词云:
import jieba from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator from scipy.misc import imread text='' info = open('info.txt', 'r', encoding='utf-8').read() text += ' '.join(jieba.lcut(info)) wc = WordCloud( width=500, height=500, margin=2, background_color='white', # 设置背景颜色 font_path='C:\Windows\Fonts\STZHONGS.TTF', # 若是有中文的话,这句代码必须添加,不然会出现方框,不出现汉字 max_words=2000, # 设置最大现实的字数 stopwords=STOPWORDS, # 设置停用词 max_font_size=150, # 设置字体最大值 random_state=42 # 设置有多少种随机生成状态,即有多少种配色方案 ) wc.generate_from_text(text) wc.to_file('ysx.jpg')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号