记一次线上高并发环境 TCP 握手丢包的故障处理
背景
业务场景需要有客户端通过 tcp 连接线上环境 emqx 集群环境,集群规模有 5 台node节点承载emqx业务,每台节点在业务端口上都有 15w 左右的tcp连接保持。
近期发现与 emqx 相关的业务功能会出现间歇性的连接等待状态,索性运维同学在内网环境进行网络层的连接测试,确实复现了连接间歇性延迟的现象。
问题现象
发现在内网节点 telnet 端口会出现间歇性的 Connecting... 状态

按理说内网环境不应该存在连接链路拥堵丢包等的情况,所以在其中一台 server 节点上进行抓包排查,看看 tcp 握手包是否正常到达目标节点。
排查
我们先排查到底这个丢包是在传输过程中的某一环丢包了,还是在 server 端丢包了。
tcpdump 抓包
我们先直接在目标节点进行 tcpdump 抓包

由此发现,数据包不存在传输途中丢包的情况,而是 server 端在已经收到 syn 握手包时,内核层在 TCP/IP 协议栈上直接就丢弃,没有响应 ack 。
头脑风暴过往类似现象可能的原因
记得,还在 Kernel 2.6.x(CentOS 5/6)的时候,处理过与这种现象类似的故障,当初也是在服务器入口层出现不同程度的收到 syn 但是协议栈不应答的现象。
我们知道,在内核参数中,有一个 net.ipv4.tcp_tw_recycle = 1 的配置开关,这个开关模式是出于关闭状态(即0),主要是为了解决服务器上 TIME_WAIT 连接状态过多的问题。
在 TCP 断联的四次挥手阶段,
TIME_WAIT为TCP状态机的最后一步,主要是该状态是为了防止四次挥手阶段最后一个FIN包由于网络丢包导致对端没有收到的问题。这个状态在Linux内核代码上直接硬编码了 60s 的状态保持时长,不可配置。
话说回来,这个参数生效的条件是 net.ipv4.tcp_timestamps = 1 和 net.ipv4.tcp_tw_recycle = 1 两个参数均为打开状态,而且建连的tcp会话两端均需要有 TS Val 标志位,即都需要开启 tcp_timestamps 内核参数,其中 tcp_timestamps 默认为开启状态。
加之如今互联网设备大多都基于 Linux 内核或者其衍生版进行开发,TCP/IP 协议栈的逻辑早都被证明是非常成熟高效可靠的逻辑,tcp_timestamps 内核参数默认又是打开状态,所以无论手机、平板、电脑、物联网设备、智能网联车机系统、路由器、游戏机 甚至洗衣机家电都默认支持 tcp timestamp 机制。
所以,一般情况下,对于现代互联网应用来说,要进行服务器上 TIME_WAIT 连接状态的快速收敛,通常在只需要服务器端开启 net.ipv4.tcp_tw_recycle = 1 便可。
毕竟,在网络上搜索 linux 回收 TIME_WAIT 等关键字时,跳出来10篇文章有9篇都建议开启 tcp_tw_recycle 参数。
这么描述下来,开启
tcp_tw_recycle视乎是一个很不错的参数咯?
错! 它在一些特定的网络环境下会出现严重的后果。
虽然 IPv6 普及了很多年,但如今现代互联网环境中仍然充斥着大量的 IPv4 网络通信,IPv4 地址早已是稀缺资源,自然就逃不开 NAT 这个技术,虽然 NAT 网络地址翻译技术被吐槽了很多年,但它在大多数场景下仍然是必不可少的互联网冲浪手段。
当 NAT 在遇到 tcp_tw_recycle 和 tcp_timestamps 时,就会开启内核上的一个保护逻辑,具体来说如下:
当用户终端(手机、电脑等)通过互联网访问到 网络负载均衡器再到具体的应用服务器,其数据包已经经过了多层的数据 NAT 地址翻译。
在服务器上通过 ss 来看,TCP 会话全都是 LB 的负载均衡器地址池与本机建立的 tcp 会话。
TCP 头部的 Timestamp 时间戳并非我们理解的真正意义上的传统日期时间戳,这个时间戳代表操作系统启动开启至今的运行秒数,所以每个终端的网络数据包中 TS val 值都是不一样的,而且差别很大。
当内核协议栈在收到同一个IP 同一个目标地址 同一个目标端口 的相同 TCP 协议数据包时,会对比其前后脚数据包中 TS Val 时间戳是否符合自然增长逻辑,如果时间戳跳差过大,超过一定的容错阈值,那么内核就会认为是无效数据包,内核协议栈收到 syn 数据包后直接丢弃处理,不会回复 ACK 。
在网络层上就表现为连接发起端认为是数据丢包,会进行重传逻辑。
又是 tcp_tw_recycle 的锅 ?
我们通过命令直接查看有没有开启 tcp_tw_recycle 的内核参数。
sysctl -a | grep tcp_tw_recycle
查询返回为空!
看看内核版本呢:
uname -a
5.15.0-205.149.5.1.el8uek.x86_64
查阅相关资料后发现。
噢,原来在 Kernel 4.10 版本开始变更了时间戳的生成机制,从 Kernel 4.12 已经废弃掉了 tcp_tw_recycle 内核配置参数,当前服务器已经是 5.15.x 版本了。
如果不是 tcp_tw_recycle 内核参数的锅,那又是什么问题呢?
头脑风暴其他的可能性
查看相应指标发现有两个指标的计数器和丢包现象 在时间点上具有高度吻合性。
使用命令查看溢出指标:
watch -d -n 1 "netstat -s | grep -E 'overflow|drop'"

使用相同命令查看其他节点的现象
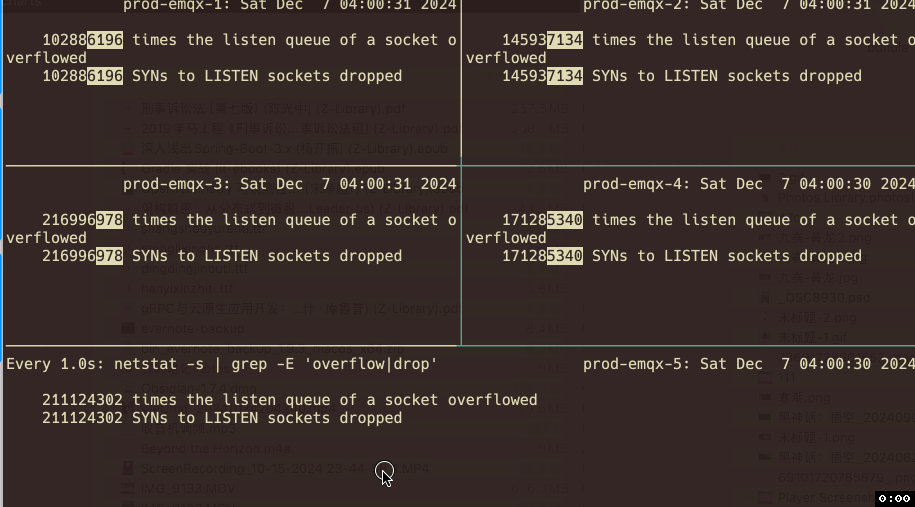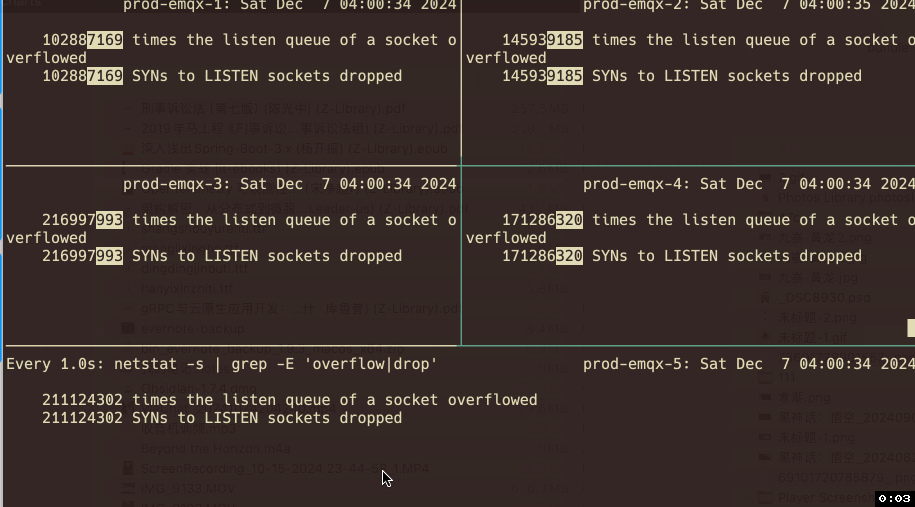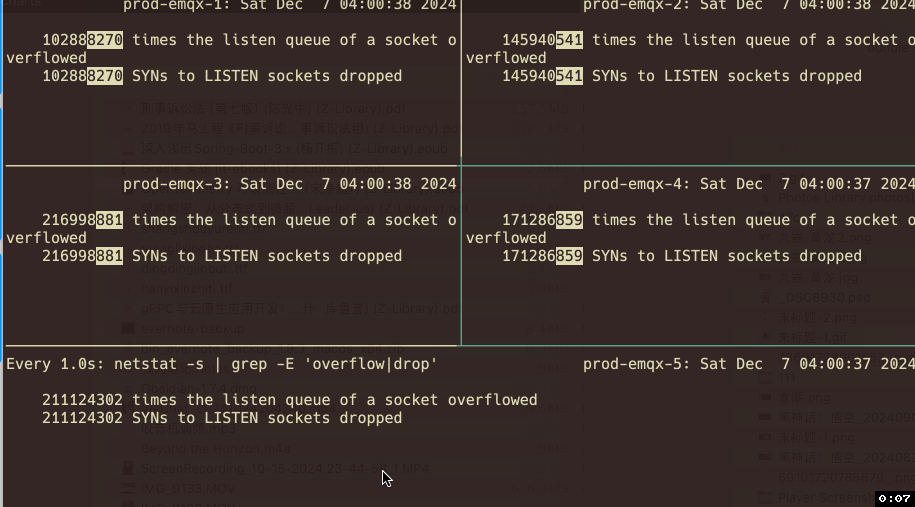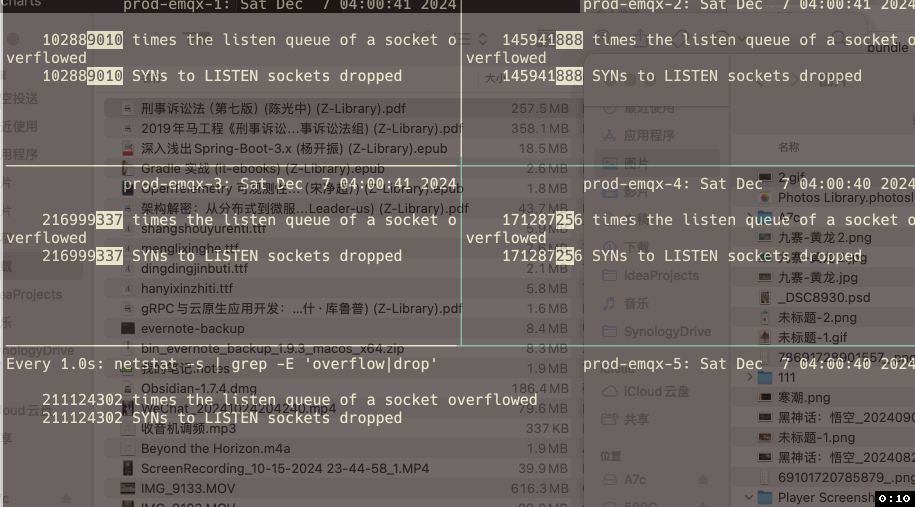
每个节点确实持续有全连接队列溢出的现象,而且现象会随着业务的高并发情况越发频繁。
内核协议栈源码片段
简单看下 Kernel 的源代码:
Kernel-4.9:
## file: net/ipv4/tcp_input.c
int tcp_conn_request(struct request_sock_ops *rsk_ops,
const struct tcp_request_sock_ops *af_ops,
struct sock *sk, struct sk_buff *skb)
{
....
/* Accept backlog is full. If we have already queued enough
* of warm entries in syn queue, drop request. It is better than
* clogging syn queue with openreqs with exponentially increasing
* timeout.
*/
if (sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1) {
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}
....
}
Kernel-4.10:
# tag: kernel v4.10
# file: net/ipv4/tcp_input.c
int tcp_conn_request(struct request_sock_ops *rsk_ops,
const struct tcp_request_sock_ops *af_ops,
struct sock *sk, struct sk_buff *skb)
{
....
if (sk_acceptq_is_full(sk)) {
NET_INC_STATS(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}
....
}
可以看到在内核版本 4.9 及其之前,会判断 sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1,大概意思是 全连接队列满了,且有 young_ack(表示刚刚有SYN到达),那么就会被丢弃。
在内核版本 4.9 之后,只会判断 sk_acceptq_is_full(sk) 全连接队列是否满了。
服务端相应第三次握手的时候,还会再次判断全连接队列是否满。
如果满了,同样丢弃握手请求。
解决全连接队列溢出
服务端在执行 listen() 的时候就确定好了版链接队列和全连接队列的长度。
对于全连接队列来说,其最大长度是 listen() 时传入的 backlog 和 net.core.somaxconn 两个配置值之间较小的那个值。
如果需要加大全连接队列长度,那么需要调整 backlog 和 somaxconn 两个内核参数,然后重启应用。
>_ sysctl -a | grep -E 'backlog|somaxconn'
net.core.somaxconn = 16384
net.ipv4.tcp_max_syn_backlog = 16384
将这两个值的 16384 改大,重启应用即可。
监控
内核代码已经包含诸如 LINUX_MIB_LISTENOVERFLOWS 相关 SNMP 指标。
手动查看指标
如前所述,可以手动通过:
netstat -s | grep -E 'overflowed|dropped'
493989 times the listen queue of a socket overflowed
493997 SYNs to LISTEN sockets dropped
两个指标。
node-exporter 监控
线上环境基本都是 prometheus + node-exporter 方案,其中 node-exporter 已经默认已经开启采集 --collector.netstat 指标。
所以,可以通过指标 node_netstat_TcpExt_ListenDrops > 0 或 node_netstat_TcpExt_ListenOverflows > 0 来查找。
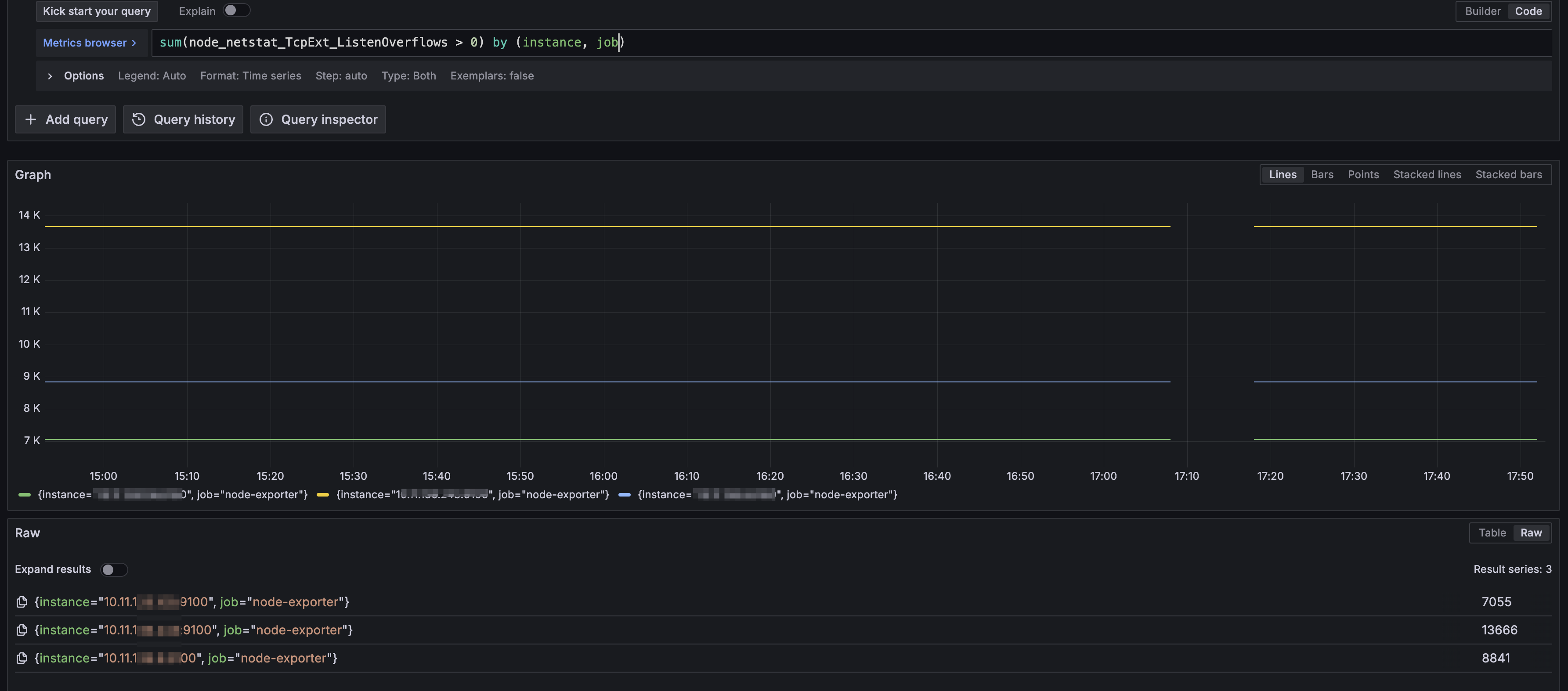
其中,
node_netstat_TcpExt_ListenOverflows代表的是* times the listen queue of a socket overflowed,三次握手最后一步完成之后,Accept queue队列(完全连接队列,其大小为min(/proc/sys/net/core/somaxconn, backlog))超过上限时指标加1.node_netstat_TcpExt_ListenDrops代表的是* SYNs to LISTEN sockets dropped,任何原因,包括Accept queue超限,创建新连接,继承端口失败等,加1.
该指标包含ListenOverflows的情况,也就是说当出现ListenOverflows时,ListenDrops也会增加1;除此之外,当内存不够无法为新的连接分配socket相关的数据结构时,也会增加1,当然还有别的异常情况下会增加1。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号