Docker/Linux 底层网络基础
Docker 底层网络基础
一. 网络命名空间
为了支持网络协议栈的多个实例,Linux 在网络栈中引入了网络命名空间,这些独立的协议栈被隔离到不同的命名空间中。 处于不同命名空间中的网络栈是完全隔离的,彼此之间无法通信,就好像两个“平行宇宙”。
通过对网络资源的隔离,就能在一个宿主机上虚拟多个不同的网络环境。
Docker 正式利用了网络的命名空间特性,实现了不同容器之间的网络隔离。
network namespace,它在Linux内核2.6.24版本开始引入,作用是隔离Linux系统的设备,以及IP地址、端口、路由表、防火墙规则等网络资源。 因此,每个网络namespace里都有自己的网络设备(如IP地址、路由表、端口范围、/proc/net目录等)。
在Linux的网络命名空间中可以有自己独立的路由表及独立的iptables规则来提供包转发、NAT及IP包过滤等功能。
为了隔离出独立的协议栈,需要纳入命名空间的元素有进程、套接字、网络设备等。 进程创建的套接字必须属于某个命名空间,套接字的操作也必须在命名空间中进行。 同样,网络设备也必须属于某个命名空间。 因为网络设备属于公共资源,所以可以通过修改属性实现在命名空间之间移动。 当然,是否允许移动与设备的特性有关。
1. 网络命名空间的实现
Linux 的网络协议栈是十分复杂的,为了支持独立的协议栈,相关的这些全局变量都必须被修改为协议栈私有的。 最好的办法就是让这些全局变量成为一个 Net Namespace变量的成员,然后为协议栈的函数调用加入一个 Namespace 参数。 这就是 Linux 实现网络命名空间的核心。
同时,为了保证对已经开发的应用程序及内核代码的解耦性,内核代码隐式的提供了命名空间中的变量。 程序如果没有对命名空间有特殊的需求,就不需要编写额外的代码,网络命名空间对应用程序而言是透明的。
在简历了新的网络命名空间,并将某个进程关联到这个网络命名空间后,就出现了下图所示的内核数据结构, 所有网络栈变量都放入了网络命名空间的数据结构中。 这个网络命名空间是其进程组私有的,和其他进程组不冲突。
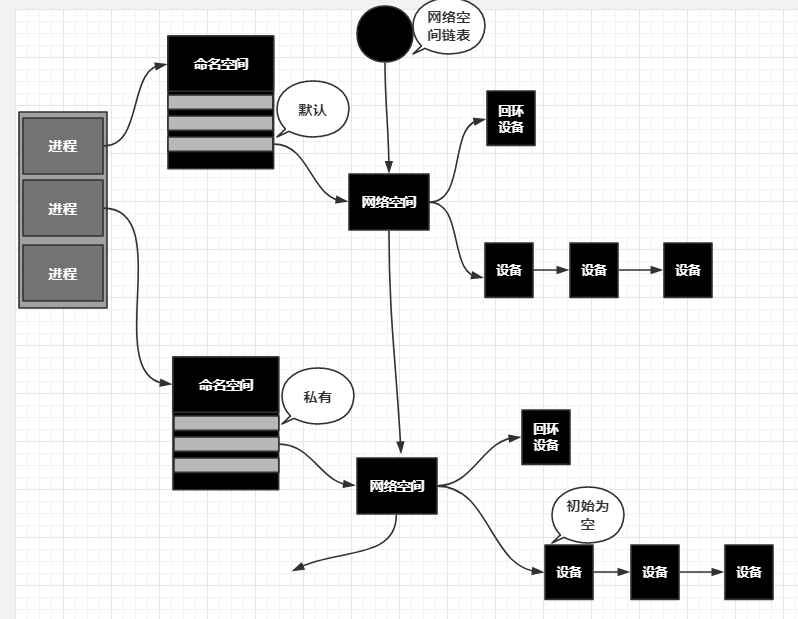
在新生成的私有命名空间中只有回环设备(lo设备而且是停止状态),其他设备默认都不存在,如果我们需要,则要一一手工建立。
Docker 容器中的各类网络栈设备都是 Docker Daemon 在启动时自动创建和配置的。
所有的网络设备都只能属于一个命名空间。 当然,物理设备(连接实际硬件的设备)通常只能关联到 root 这个命名空间中。 虚拟的网络设备(虚拟的以太网接口或者虚拟网口对)则可以被创建并关联到一个给定的命名空间中,而且可以在这些命名空间之间移动。
前面提到,由于网络命名空间代表的是一个独立的协议栈,所以它们之间是相互隔离的,彼此无法通信,在协议栈内部都看不到对方。
那么有没有办法打破这种限制,让处于不同命名空间的网络相互通信,甚至和外部的网络进行通信呢? 答案就是“有,使用Veth设备对即可”。
Veth设备对的一个重要作用就是打通互相看不到的协议栈之间的壁垒,它就像一条管子,两端分别连着不同的网络命名空间的协议栈。 所以如果想在两个命名空间之间通信,就必须有一个Veth设备对。 后面会详细介绍如何操作Veth设备对来打通不同的网络命名空间之间的网络。
2. 网络命名空间的操作
下面列举网络命名空间的一些操作。
我们可以使用 Linux iproute2 系列配置工具中的ip命令来操作网络命名空间。
注意,这个命令需要由 root 用户运行。
### 创建一个命名空间:
ip netns add <name>
### 在命名空间中执行命令:
ip netns exec <name> <command>
### 也可以先通过 bash 命令进入内部的 shell 界面,然后执行各种命令:
ip netns exec <name> bash
### 退出到外面的命名空间时,输入 Ctrl-D 或者 exit 即可
3. 网络命名空间的实用技巧
我们可以在不同的网络命名空间之间转移设备,例如下面会提到的Veth设备对转移。
因为一个设备只能属于一个命名空间,所以转移后在这个命名空间中就看不到这个设备了。
在设备里面有一个重要的属性:NETIF_F_ETNS_LOCAL,如果这个属性为on,就不能被转移到其他命名空间中。
Veth设备属于可以转移的设备,而很多其他设备如lo设备、vxlan设备、ppp设备、bridge设备等都是不可以转移的。
将无法转移的设备移动到别的命名空间时,会得到无效参数的错误提示。
### 添加bridge设备
ip link add br0 type bridge
### 尝试移动 bridge 设备到其他网络命名空间
# ip link set br0 netns ns1
RTNETLINK answers: Invalid argument
如何知道这些设备是否可以转移呢? 可以使用ethtool工具查看:
# ethtool -k br0 | grep netns-local
netns-local: on [fixed]
二. Veth设备对
引入Veth设备对是为了在不同的网络命名空间之间通信,利用它可以直接将两个网络命名空间连接起来。
由于要连接两个网络命名空间,所以Veth设备都是成对出现的,很像一对以太网卡,并且中间有一根直连的网线。 既然是一对网卡,那么我们将其中一端称为另一端的peer。
在Veth设备的一端发送数据时,它会将数据直接发送到另一端,并触发另一端的接收操作。
整个Veth的实现非常简单,有兴趣的小伙伴可以参考源码drivers/net/veth.c的实现。
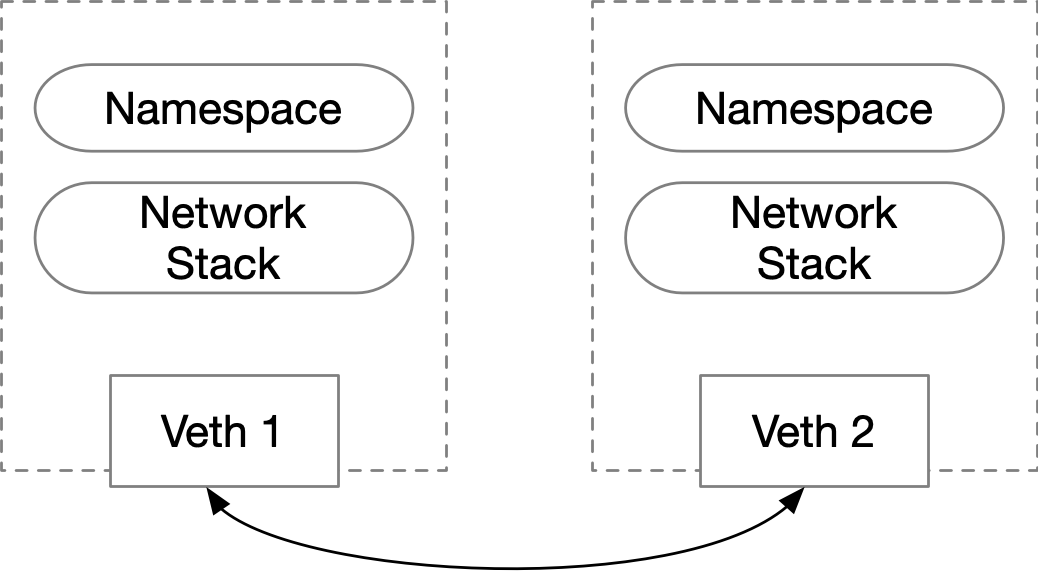
1. Veth设备对的操作命令
接下来看看如何创建Veth设备对,如何连接到不同的命名空间,并设置它们的地址,让它们通信。
### 创建 Veth设备对
ip link add veth0 type veth peer name veth1
### 查看网络设备列表
# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 00:15:5d:ff:0a:03 brd ff:ff:ff:ff:ff:ff
3: br0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 82:d0:b6:65:f5:88 brd ff:ff:ff:ff:ff:ff
8: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 6a:9f:50:af:8c:68 brd ff:ff:ff:ff:ff:ff
9: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 92:73:36:8e:08:0e brd ff:ff:ff:ff:ff:ff
如上,编号8 9的两个设备为Veth设备对,名称为veth1@veth0和veth0@veth1,使用@分隔,符号前面称为本端,@veth0中的veth0为对端Veth设备。
现在这两个设备都在自己的命名空间中,那么怎么能行呢? 好了,如果将Veth看做网线,那么我们将另一头甩给另一个命名空间:
### 将 veth1 设备添加到另一个网络命名空间中
ip link set veth1 netns netns1
### 我们再来看看外面这个命名空间两个设备的情况
# ip -o -c link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000\ link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000\ link/ether 00:15:5d:ff:0a:03 brd ff:ff:ff:ff:ff:ff
3: br0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000\ link/ether 82:d0:b6:65:f5:88 brd ff:ff:ff:ff:ff:ff
9: veth0@if8: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000\ link/ether 92:73:36:8e:08:0e brd ff:ff:ff:ff:ff:ff link-netns netns1
目前当前命名空间只剩下veth0设备了,而且对端设备名称也发生了变化(@符号后面变为 if8),veth1设备已经被转移到另一个命名空间中了。
在netns1网络命名空间中可以看到veth1设备了,符合预期:
# ip netns exec netns1 ip -o -c link ls
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000\ link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
8: veth1@if9: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000\ link/ether 6a:9f:50:af:8c:68 brd ff:ff:ff:ff:ff:ff link-netnsid 0
现在看到的结果是,两个不同的命名空间各自有一个Veth的"网线头",各显示为一个Device (在Docker的实现里面,它除了将Veth放入容器内,还将它的名字改成了eth0,简直以假乱真,你以为它是一个本地网卡吗)。
现在还不能通信,因为还没有配置任何地址,我们可以给它们分配IP地址:
### 为veth1 和 veth0 分别添加IP地址
ip netns exec netns1 ip addr add 10.1.1.1/24 dev veth1
ip addr add 10.1.1.2/24 dev veth0
### 启动veth1 和 veth0 网卡状态为up
ip netns exec netns1 ip link set dev veth1 up
ip link set dev veth0 up
### 查看网卡 up 状态
# ip netns exec netns1 ip -o -c link ls
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000\ link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
8: veth1@if9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000\ link/ether 6a:9f:50:af:8c:68 brd ff:ff:ff:ff:ff:ff link-netnsid 0
### 测试网络连通性
# ping 10.1.1.1
PING 10.1.1.1 (10.1.1.1) 56(84) bytes of data.
64 bytes from 10.1.1.1: icmp_seq=1 ttl=64 time=0.069 ms
64 bytes from 10.1.1.1: icmp_seq=2 ttl=64 time=0.036 ms
64 bytes from 10.1.1.1: icmp_seq=3 ttl=64 time=0.038 ms
# ip netns exec netns1 ping 10.1.1.2
PING 10.1.1.2 (10.1.1.2) 56(84) bytes of data.
64 bytes from 10.1.1.2: icmp_seq=1 ttl=64 time=0.036 ms
64 bytes from 10.1.1.2: icmp_seq=2 ttl=64 time=0.049 ms
64 bytes from 10.1.1.2: icmp_seq=3 ttl=64 time=0.036 ms
至此,我们就能够理解Veth设备对的原理和用法了。
在 Docker 内部,Veth设备对也是联通容器与宿主机的主要网络设备,离开它是不行的。
2. Veth设备对如何查看对端
我们在操作Veth设备对时有一些实用技巧。
一旦将Veth设备对的对端放入另一个命名空间时,本命名空间就看不到它了。
那么我们怎么知道这个Veth设备对的对端在哪里呢,也就是说它到底连接到哪个命名空间呢?
可以使用ethtool工具来查看。
首先,在命名空间netns1中查询Veth设备对端接口在设备列表中的序列号:
# ip netns exec netns1 ethtool -S veth1 | grep peer_ifindex
NIC statistics:
peer_ifindex: 9
得知另一端的接口设备的序号是 9 ,我们再到命名空间netns2中查看序列号9代表什么设备:
# ip netns exec netns2 ip link | grep 9:
9: veth0@if8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
还有另一种简便的方法:
# ip -o -c link ls veth0 | grep -Eo 'link-netns.*' link-netns netns1 # ip netns exec netns1 ip -o -c link ls veth1 | grep -Eo 'link-netns.*' link-netnsid 0
三. 网桥
Linux 可以支持多个不同的网络,它们之间能够相互通信,如何讲这些网络连接起来并实现各网络中主机的相互通信呢?
可以使用网桥。
网桥是一个二层的虚拟网络设备,把若干个网络接口“连接”起来,以使得网络接口之间的报文能够相互转发。
网桥能够解析收发的报文,读取目标MAC地址的信息,和自己记录的MAC表结合,来决策报文的转发目标网络接口。
为了实现这些功能,网桥会学习源MAC地址。 在报文转发时,网桥只需要向特定的网口进行转发,来避免不必要的网络交互。
如果它遇到一个自己从未学习到的MAC地址,就无法知道这个报文应该向哪个网络接口转发,就将报文广播给所有的网络接口(报文来源的接口除外)。
在实际的网络中,网络拓扑不可能永远不变。 设备如果被移动到另一个端口上,却没有发送任何数据,网桥设备就无法感知到这个变化,网桥还是向原来的端口转发数据包,这种情况下数据就会丢失。
所以网桥还要对学习到的MAC地址表加上超时时间(默认为5min)。 如果网桥收到了对应端口MAC地址回发的包,则重置超时时间,否则过了超时时间后,就认为设备已经不在那个端口上了,他就会重新发送广播。
过去Linux主机一般都只有一个网卡,现在多网卡的机器越来越多,而且有很多虚拟的设备存在,所以Linux的网桥提供了在这些设备之间互相转发数据的二层设备。
Linux内核支持网口的桥接(目前只支持以太网口)。 但是与淡村的交换机不同,交换机只是一个二层设备,对于接收到的报文,要么转发,要么丢弃。 运行着Linux内核的机器本身就是一台主机,有可能是网络报文的目的地,其收到的报文除了转发和丢弃,还可能被送到网络协议栈的上层(网络层),从而被自己(这台主机本身的协议栈)消化,所以我们既可以把它看做一个二层设备,也可以看做是一个三层设备。
1. Linux 网桥的实现
Linux 内核是通过一个虚拟的网桥设备(Net Device)来实现桥接的。 这个虚拟设备可以绑定若干个以太网接口设备,从而将它们桥接起来。
这种 Net Device 网桥和普通的设备不同,最明显的一个特性是它还可以有一个IP地址。
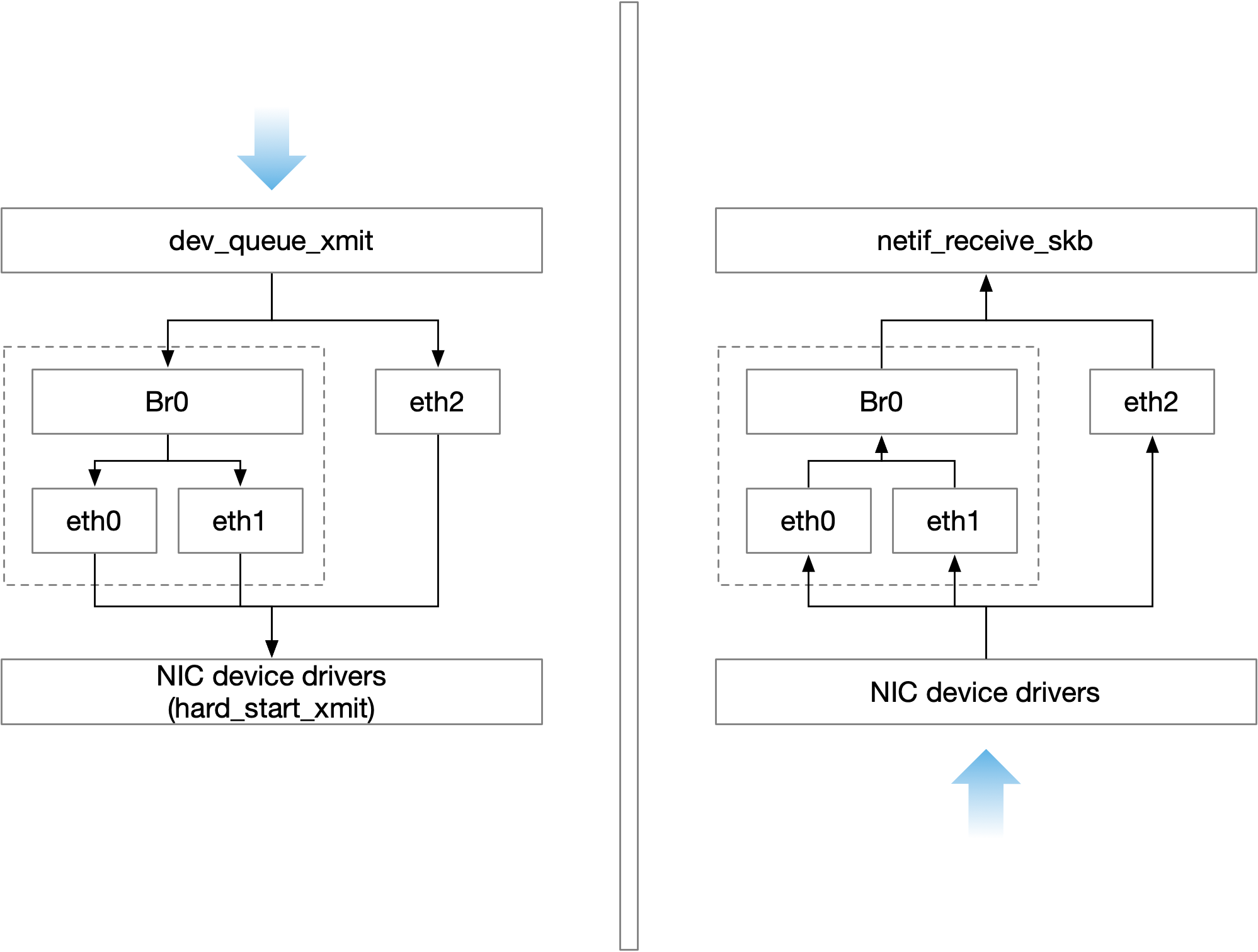
网桥设备br0绑定了eth0和eth1。 对于网络协议栈的上层来说,只看得到br0就行。 因为桥接是在数据链路层实现的,上层不需要关心桥接的细节,所以协议栈上层需要发送的报文被送到br0,网桥设备的处理代码判断报文被转发到eth0还是eth1,或者两者皆转发; 翻过来,从eth0或eth1接收到的报文被提交给网桥的处理代码,在这里会判断报文应该被转发、丢弃、还是被提交到协议栈上层。
而有时eth0、eth1也坑能会作为报文的原地址或目的地址,直接参与报文的发送与接收,从而绕过网桥。
2. 网桥的常用操作命令
Docker 自动完成了对网桥的创建和维护。 为了进一步理解网桥,下面举几个常用的网桥操作例子,对网桥进行手工操作:
### 新增一个网桥设备,使用 iproute2 方式
ip link add name br0 type bridge
ip link set br0 up
### brctl 命令方式(需要安装bridge-utils软件包)
brctl addbr br0
之后可以为网桥增加网口,在Linux 中,一个网口其实就是一个物理网卡。 将物理网卡和网桥连接起来:
### 谨防ssh失联掉线,同步给 br0 配置eth0 网卡的IP
brctl addif br0 eth0; ifconfig br0 192.168.22.22
### 查看网桥设备学习的 mac 地址表
# brctl showmacs br0
port no mac addr is local? ageing timer
1 00:15:5d:ff:0a:03 yes 0.00
1 00:15:5d:ff:0a:03 yes 0.00
1 68:ab:bc:5d:0d:95 no 27.51
1 a0:18:28:f2:26:35 no 77.50
1 a4:5e:61:e8:cb:07 no 124.73
1 d4:3d:7e:4e:82:e8 no 0.00
1 f8:2d:89:7c:61:b7 no 60.60
1 fc:6c:02:ff:e4:d1 no 5.67
### 从br0删除桥接的网络接口,同步删除网桥设备的IP地址
# brctl delif br0 eth0; ip addr delete 192.168.22.22/24 dev br0
### 启动网卡br0的混杂模式
ifconfig br0 promisc
ip link set br0 promisc on
### 关闭网卡br0的混杂模式
ifconfig br0 -promisc
ip link set br0 promisc off
网桥的物理网卡作为一个网口,由于在链路层工作,就不需要IP地址了,这样上面的IP地址自然失效。
这样网桥就有了一个IP地址,而连接到上面的网卡就是一个纯链路层设备了。
混杂模式(Promiscuousmode),简称Promiscmode,俗称“监听模式”。 混杂模式通常被网络管理员用来诊断网络问题,但也会被无认证的、想偷听网络通信的人利用。 根据维基百科的定义,混杂模式是指一个网卡会把它接收的所有网络流量都交给CPU,而不是只把它想转交的部分交给CPU。 在IEEE802定的网络规范中,每个网络帧都有一个目的MAC地址。 在非混杂模式下,网卡只会接收目的MAC地址是它自己的单播帧,以及多播及广播帧; 在混杂模式下,网卡会接收经过它的所有帧!我们可以使用ifconfig或者netstat命令查看一个网卡是否开启了混杂模式。
### 查看网卡的混杂模式状态
# ip a
3: br0: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
# ifconfig br0
br0: flags=4419<UP,BROADCAST,RUNNING,PROMISC,MULTICAST> mtu 1500
当veth设备加入Linux bridge后,可以通过查看内核日志看到veth0自动进入混杂模式,而且无法退出,直到将veth0从Linux bridge中移除。
[Aug 8 03:41] docker0: port 1(vethce34bdb) entered blocking state
[ +0.000005] docker0: port 1(vethce34bdb) entered disabled state
[ +0.000033] device vethce34bdb entered promiscuous mode
四. iptables 和 Netfilter
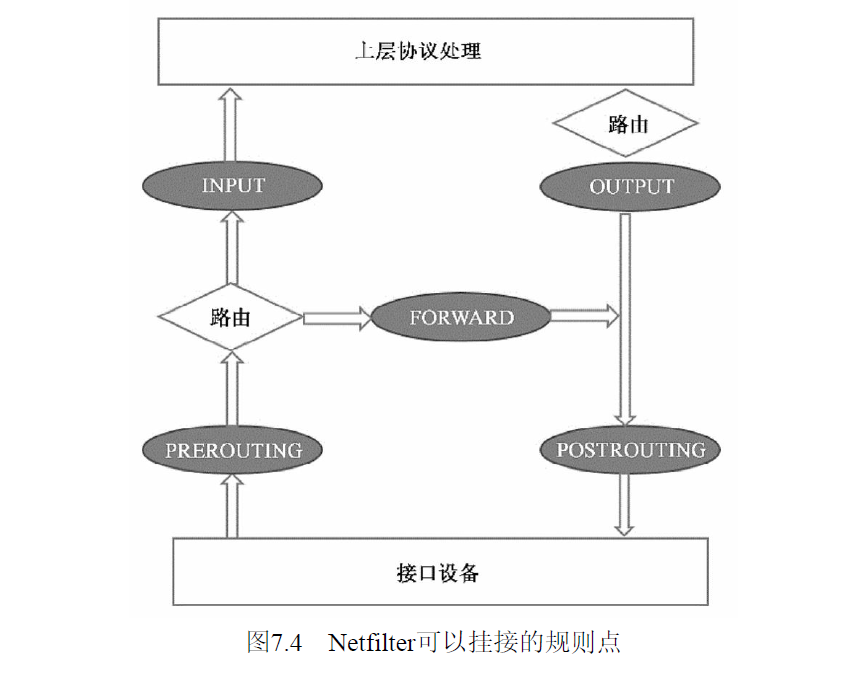
在Linux网络协议栈中有一组回调函数挂接点,通过这些挂接点挂接的钩子函数可以在Linux网络栈处理数据包的过程中对数据包进行一些操作,比如过滤、修改、丢弃等。
整个挂接点技术叫做 Netfilter 和 iptables 。
Netfilter 负责在内核中执行各种挂接的规则,运行在内核模式中; 而iptables是在用户模式下运行的进程,负责协助和维护内核中Netfilter的各种规则表。 二者相互配合来实现整个 Linux 网络协议栈中灵活的数据包处理机制。
1. 规则表 Table
这些挂接点能挂接的规则也分不同的类型(也就是规则表Table),我们可以在不同类型的Table中加入我们的规则。 目前主要支持的Table类型有:RAW、MANGLE、NAT和FILTER。
上述4个Table(规则链)的优先级是RAW最高,FILTER最低。
在实际应用中,不同的挂接点需要的规则类型通常不同。 例如,在Input的挂接点上明显不需要FILTER过滤规则,因为根据目标地址已经选择好本机的上层协议栈了,所以无需再挂接FILTER过滤规则。
目前,Linux系统支持的不同挂接点能挂接的规则类型如下图。
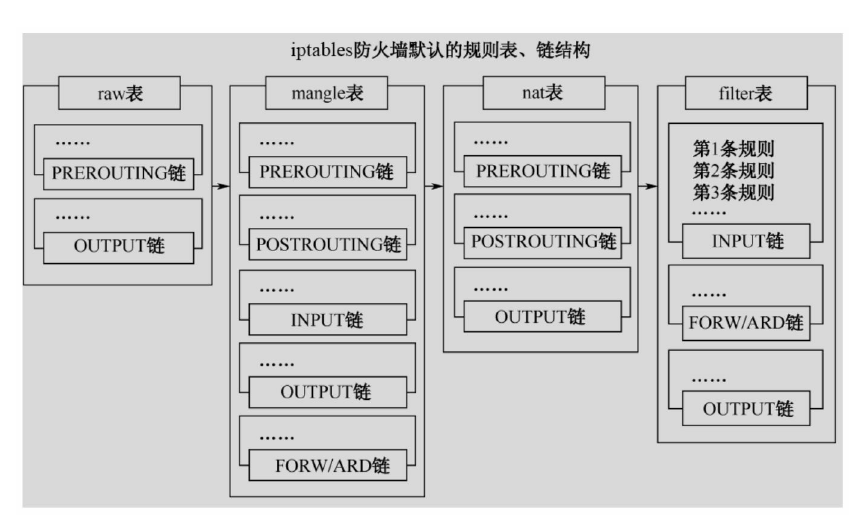
当Linux协议栈的数据处理运行到挂接点时,它会依次调用挂接点上所有的挂钩函数,直到数据包的处理结果是明确的接收或者拒绝。
2. 处理规则
每个规则的特性都分为以下几部分。
- 表类型(准备干什么事儿)
- 什么挂载点(什么时候起作用)
- 匹配的参数是什么(针对什么样的数据包)
- 匹配后有什么动作(匹配后具体的操作是什么)
(1) 匹配的参数
匹配的参数用于对数据包或者TCP数据连接的状态进行匹配。 当有多个条件存在时,它们一起发挥作用,来达到只针对某部分数据进行修改的目的。
常见的匹配参数如下
- 流入、流出的网络接口
- 来源、目的地址
- 协议类型
- 来源、目的端口
- 匹配后的动作
一旦有数据匹配,就会执行相应的动作。
动作类型既可以是标准的预定义的几个动作,也可以是自定义的模块注册的动作,或者是一个新的规则链,以便更好的组织一组动作。
3. iptables命令
iptables命令用于协助用户维护各种规则。
我们在使用 Kubernetes、Docker 的过程中,通常都会去查看相关的 Netfilter 配置。这里只介绍如何查看规则表,详细的介绍请参照Linux的iptables 帮助文档。
查看系统中已有规则的方法如下。
iptables-save:按照命令的方式打印iptables的内容iptables -nvL:以另一种格式显示 Netfilter 表的内容
五. 路由
Linux 系统包含一个完整的路由功能。
当IP层在处理数据发送或者转发时,会使用路由表来决定发往哪里。
在通常情况下,如果主机与目的主机直接相连,那么主机可以直接发送IP报文到目的主机,这个过程比较简单。
如果主机与目的主机没有直连,那么主机将IP报文发送给默认的路由器,然后由路由器来决定往哪里发送IP报文。
路由功能由IP层维护的一张路由表来实现。 当主机收到数据报文时,它用此表来决策接下来应该做什么操作。
当从网络侧接收到数据报文时,IP层首先会检查报文的IP地址是否与主机自身的地址相同。 如果数据报文中的IP地址是主机自身的地址,那么报文将被发送到传输层相应的协议中。
如果报文中的IP地址不是主机自身的地址,并且主机配置了路由功能,那么报文将被转发,否则,报文将被丢弃。
路由表中的数据一般是以条目形式存在的。
一个典型的路由表条目通常包含一下主要的条目项:
-
- 目的IP地址(Destination):此字段表示目标的IP地址。 这个IP地址可以是某主机的地址,也可以是一个网段地址。 如果这个条目包含的是一个主机地址,那么它的主机ID奖杯标记为非零; 如果这个条目包含的是一个网络地址,那么它的主机ID奖杯标记为零。
-
- 下一个路由器的IP地址(下一跳):这里采用“下一个”的说法,是因为下一个路由器并不总是最终的目的路由器,它很可能是一个中间路由器。 条目给出的下一个路由器地址用来转发在相应接口接收到的IP数据报文。
-
- 标志(Flags):这个字段提供了另一组重要信息,例如,目的IP地址是一个主机地址还是一个网络地址。 此外,从标志中可以得知下一个路由器是一个真是路由器还是一个直接相连的接口。
-
- 网络接口规范:为一些数据报文的网络接口规范,该规范将与报文一起被转发。
目的地址精确的IP(子网掩码更精确),匹配优先级更高。 在通过路由表转发时,如果任何条目的第一个字段完全匹配目的IP地址(主机)或部分匹配条目的IP地址(网络),它将指示下一个路由器的IP地址。
这是一个重要的信息,因为这些信息直接告诉主机(具备路由功能的)数据包应该被转发到哪个路由器。 而条目中的所有其他字段将提供更多的辅助信息来为路由转发做决定。
如果没有找到一个完全匹配的IP,就接着搜索相匹配的网络ID。 如果找到,那么该数据报文会被转发到指定的路由器上。
可以看出,网络上的所有主机都通过这个路由表中的单个条目进行管理。
如果上述两个条件都不匹配,那么该数据报文将被转发到一个默认的路由器上。
如果上述步骤都失败,默认路由器也不存在,那么该数据报文最终无法被转发。
任何无法被投递的数据报文都将产生一个 ICMP 主机不可达或 ICMP 网络不可达的错误,并将此错误返回给生成此数据报文的应用程序。
1. 路由表的创建
Linux 的路由表至少包括两个表(当启用策略路由时,还会有其他表):一个是LOCAL,另一个是MAIN。
在 LOCAL 表中会包含所有的本地设备地址。 LOCAL路由表是在配置网络设备地址时自动创建的。
LOCAL表用于供Linux协议栈识别本地地址,以及进行本地各个不同网络设备接口之间的数据转发。
### 查看策略路由表列表
# ip rule list
0: from all lookup local
32766: from all lookup main
32767: from all lookup default
可以通过下面的命令查看 LOCAL 表的内容:
# ip route show table local type local
local 127.0.0.0/8 dev lo proto kernel scope host src 127.0.0.1
local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1
local 192.168.22.22 dev eth0 proto kernel scope host src 192.168.22.22
MAIN标用于各类网络IP地址的转发。
它的简历可以使用静态配置生成,也可以使用动态路由发现协议生成。 动态路由发现协议一般使用组播功能来通过发送路由发现数据,动态的交换和获取网络的路由信息,并更新到路由表中。
Linxu下支持路由发现协议的开源软件有许多,常用的有Quagga、Zebra等。
后续会介绍如何使用Quagga动态容器路由发现的机制来实现Kubernetes的网络组网。
2. 路由表的查看
我们可以使用ip route list命令查看当前的路由表:
# ip route list
default via 192.168.22.1 dev eth0 proto static metric 100
192.168.22.0/24 dev eth0 proto kernel scope link src 192.168.22.22 metric 100
在上面的例子代码中只有一个子网的路由,源原地址是192.168.22.22(本机),目标地址在192.168.22.0/24网段的数据包都将通过eth0接口发送出去。
netstat -rn是另一个查看路由表的工具:
# netstat -rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
0.0.0.0 192.168.22.1 0.0.0.0 UG 0 0 0 eth0
192.168.22.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
在它显示的信息中,如果标志Flags是U,这说明是可达路由; 如果标志Flags是G,则说明这个网络接口连接的是网关,否则说明这个接口直连主机。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号