

每天学习亿点点day 7.4: HCI 统计基础
1. 首先先上结论然后我们再谈一些名词的意义:
零假设: H0一般是认为没有显著差异
H1一般是认为有显著差异
当我们拿到两组数据的时候我们要计算这两组是否有显著差异,当我们假定H0是正确的时候,因为他们是来自同一个分布所以应该会遵循某种分布,这样我们用一些统计量(t)来计算当前样本的统计量值,如果这个统计量出落在概率很大的位置那么我们就可以认为确实是来自同一个分布,但是如果落在一个非常山沟沟的位置,比如说在双尾检测的位置,那么就认为,和我们原先的想想不一样啊,那么在这个极其罕见的位置我们就只能说,抱歉了,这么稀罕的位置的数据都出现了那么我只能认为我们一开始的想法就是错的,也就是说我们要拒绝来自从一个分布这个想法,转而认为是有明显差异的. 所以所谓的α值只是我们自己预设的一个阈值而已,当低于这个值的时候我们就自我觉得很自信认为,可以这么判断而已.
| 拒绝零假设 | 接受零假设 | |
|---|---|---|
| 零假设为真 | 类型一错误p | 1-p |
| 零假设为假 | b | 类型2错误1-b (power) |
power分析需要用到
-
样本大小,
-
效应尺寸 (对于总体而不是样本的),
-
α
-
Beta
We just need three of the above information. Power analysis then estimates the rest. Based on what you estimate, power analysis often has different names.
-
A priori power analysis: Estimating the sample size given the effect size, alpha and power,
-
Sensitivity analysis: Estimating the effect size given the sample size, alpha and power.
-
Criterion analysis: Estimating the alpha given the sample size, effect size, and power.
-
Post hoc power analysis: Estimating the power given the sample size, effect size, alpha.
Here, we focus on a priori power analysis because I think it is the most important application of power analysis.
| Interval/Ratio (Normality assumed) | Interval/Ratio (Normality not assumed), Ordinal | Dichotomy (Binomial) | |
|---|---|---|---|
| Compare two unpaired groups | Unpaired t test | Mann-Whitney test | Fisher's test |
| Compare two paired groups | Paired t test | Wilcoxon test | McNemar's test |
| Compare more than two unmatched groups | ANOVA | Kruskal-Wallis test | Chi-square test |
| Compare more than two matched groups | Repeated-measures ANOVA | Friedman test | Cochran's Q test |
| Find relationship between two variables | Pearson correlation | Spearman correlation | Cramer's V |
| Predict a value with one independent variable | Linear/Non-linear regression | Non-parametric regression | Logistic regression |
| Predict a value with multiple independent variables or binomial variables | Multiple linear/non-linear regression | Multiple logistic regression | |
四种主要数据类型名义的(分类的),序数的,间隔和比率。
-
名义的: 显示类别的数据,在名义数据中没有排序的概念,例如 技术(技术A,技术B,…),性别(男性,女性),职业(学生,专业程序员,…)。
-
序数:可以排序的数据(有小或大的概念),但这两个值之间的差异可能不总是相等的。例如李克特量表问题的回答。
-
间隔:你可以排序的数据以及任何两个值之间的差是相同的,但没有绝对的零,这允许我们有有意义的负值。最著名的例子是使用C或F的温度,0 C或0 F是人为定义的,这些单位可以使用负值。但是0℃和1℃之间的差异和100℃和101℃之间的差异是相同的。
-
比率:你可以排序的数据和任何两个值之间的差是相同的(所以它们是间隔),有绝对零。这意味着(在统计数据中)不存在有意义的区间数据负值。这些例子包括重量、高度、长度、时间、速度和错误率。计数通常被认为是比率。
不同类型的数据具有不同的数学运算特征
| 运算 | 名义 | 序数 | 间隔 | 比率 |
| 频率计数,模态,卡方 | O | O | O | O |
| 中位数, 百分比 | X | O | O | O |
| 加、减、平均数、方差、相关、回归 | X | X | O | O |
| 几何/调和平均数,变异系数,对数 | X | X | X | O |
-
独立变量:用于测试数据的维度
-
因变量:用于测试的值。通常一次测试只有一个因变量
参数化 vs. 非参数
参数化:参数化意味着可以用一些常用参数来数据,特别是平均值和标准偏差。要用平均值和标准差描述数据(更准确地说,数据的分布),必须假定总体是正态分布。对一些参数检验有额外的要求,但正态性假设是最重要的假设。
什么时候使用非参数检验。粗略地说,有两种情况你想要使用非参数检验:
顺序数据:如果数据是顺序的(如李克特量表问题的结果),则应使用非参数测试。
非正态数据:不能假设数据是正态的。
正态性和数据转换
直观观察正态性: 直方图和QQ-plot
数据转换的一个重要方面是,您必须保证数据转换是合法的。您不能进行任意的数据转换以获得想要的结果。确保您阐明了为什么要进行数据转换以及为什么它是合适的。
正态性的统计检验
如果你的数据的直方图看起来不像一个正态分布,你应该尝试一个统计测试来检查正态性。幸运的是,在r中这非常简单。有两种常用的测试可以用于正态性检查。
Shapiro-Wilk测试
一个常用的检验方法是夏皮罗-威尔克测试。这个测试即使在小样本量下也能很好地工作,所以通常你只需要使用这个。
Kolmogorov-Smirnov测试
另一个检验正态性的方法是Kolmogorov-Smirnov检验。这个测试主要检查两个数据集是否来自同一个分布,但它可以用于将一个数据集与理想分布(在这种情况下,是正态分布)进行比较。这个测试在R中也很容易做。
数据转换
一旦您决定进行数据转换,您需要选择使用哪个转换。尽管您可以进行任何类型的转换,但有一些转换是常用的。您可以进行其他类型的转换,但是不管转换如何,您必须说明为什么决定使用该转换以及它为什么是合适的。
在进行数据转换之后,可以进行参数测试。然而,当您报告描述性统计数据(例如,平均值和标准偏差)时,您需要在转换之前使用数据。这是因为将转换后的数据用于这些类型的信息没有意义。澄清您使用转换数据和未转换数据的分析可能是一个好主意。
两种最常见的数据转换是对数转换和平方根转换。对数变换对于各种因素相乘产生的数据非常有用。如果数据中有零值或负值,请注意。您需要为每个数据点添加一个常数,使它们更大且非零。如果您有计数数据,并且有些计数为零,那么通常为每个数据点添加0.5。平方根转换对于计数数据很有用。确保你没有任何零或负值。最终,您需要根据上面解释的直方图和统计测试确定使用什么数据转换。
异常值的检测和去除
当你得到样本时,数据中很可能会有一些异常值。离群值是指与其他数据点相比看起来非常不规则的数据点。例如,如果您有一系列数据点,如[1,2,1,3,2,100],100可能是一个离群值。这种异常值的出现可能有许多不同的原因:系统在特定的试验中出现了一些故障,参与者没有很好地专注于任务,或者她只是做了一些随机的事情。我们想要删除这些异常值,因为我们通常使用的统计数据可能会受到它们的极大影响。例如,上面有异常值的数据点的平均值是18.2,而没有异常值的数据点的平均值是1.8(相差10倍!)。
然而,你必须以令人信服的方式证明离群值的定义。当然,你不能把所有你不喜欢的数据都看作是离群值。
两个检测离群值的标准方法:
1. 标准差方法: 现在,让我们设置离群值的阈值。通常,大于2或3。这意味着,如果某个数据点偏离均值超过+/- 2或3个标准差,我们将其视为离群值。这里,我们将阈值设置为3SD。
2. Smirnov‐Grubbs Test:
这是零假设显著性检验,零假设中没有异常值。备择假设是数据集中至少有一个离群值。然而,这个测试并没有告诉我们有多少异常值存在。但它能告诉我们最远的数据点。
各种检测以及注意事项:
F Test:
F检验是一种使用F分布作为原假设的统计检验。例如,方差分析实际上是F检验的一种。但在很多情况下,F检验指的是检验两个方差是否相等(或同质)的统计检验。在这一页中,我也将F测试引用到这样的测试中。
不幸的是,F检验现在被认为是检验两个方差相等的较不可靠的检验。其中一个原因是f检验对非正态性非常敏感。为了解决这个问题,人们使用其他测试,如Levene检验或Bartlett检验来检查方差的同质性。尽管如此,理解F检验对统计学初学者仍然是有益的,因为它与其他种类的常见统计检验密切相关,如t检验和方差分析检验。
F检验的基本思想是看从抽样数据计算出的两个方差的比率。零假设是两个正态总体有相同的方差。请记住,检验关心的是总体的方差,而不是抽样数据的方差。如果比率(称为F值)太极端,您将拒绝零假设,并说您发现了显著差异。差不多就是这样。很简单,是吧?但是F值的概念——取两个值的比值并检查它是否极端——是方差分析和回归的一个关键概念。记住这一点。
其他检测方差同质性的检验:
Bartlett's test,
Fligner's test,
Levene's test
t Test
t检验是比较两组平均数的统计检验。
您可以使用Microsoft Excel(也可能是openoffice)和统计软件运行t测试。我认为做t测试是很简单的。如果你不喜欢统计学,这也是一个很好的开始方法。
和其他类型的统计检验一样,t检验也会做一些假设。第一个重要的假设是样本数据的总体分布是正态分布。t检验关心的是总体的分布,而不是样本的分布。如果你有足够的样本,这个假设不会引起很多问题。
Effect size
For t tests, you probably also want to report the effect size. The general explanation of effect sizes is available here, and here I explain how to calculate the effect size for a t test.
There are two kinds of effect size metrics for a t test: Cohen's d, and Pearson's r. Both metrics are commonly used and you can pick up either of them (there is a way to convert d to r, and vice versa, so it really doesn't matter which one you use). But remember that you cannot use Pearson's r for a paired t test. Thus, you have to use Cohen's d in this case.
It depends on the fields what size is considered as a small or large effect size, but here are some standard thresholds. Remember that you cannot use r for a paired t test.
| small size | medium size | large size | |
|---|---|---|---|
| Cohen's d | 0.2 | 0.5 | 0.8 |
| Pearson's r | 0.1 | 0.3 | 0.5 |
Effect size for a paired t test
Cohen's d for an unpaired t test can be calculated as follows:
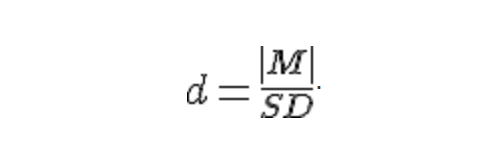
where M is the mean of differences, and SD is the standard deviation of differences.
Effect size for an unpaired t test
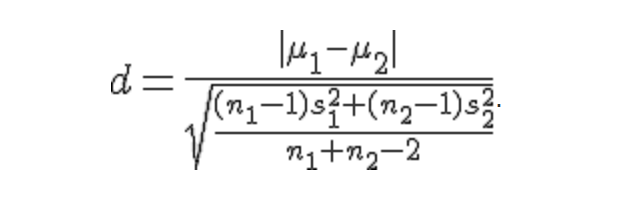
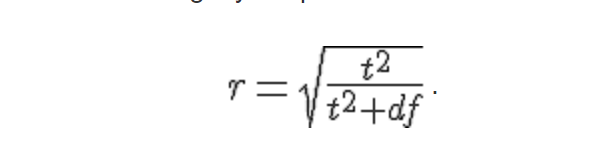
ANOVA
方差分析(ANOVA)是HCI研究中常用的一种统计检验方法。尽管它说的是"方差分析"方差分析是一种比较多个线性模型的方法,使用方差分析检验的一种非常常见的方法是检验两组以上的平均值的差异。因此,直觉是t检验,它能容纳两组以上的人进行比较。例如,当您想要比较三种交互技术的用户性能时,方差分析是您想要考虑的方法之一。
接下来的就是非参数检验了
Chi-square, Fisher's exact, and McNemar's test
Chi-square:
卡方检验是对名义(分类)数据的一种常见检验。卡方检验的一个应用是独立性检验。在这种情况下,零假设是两组结果的发生是相等的。
现在你想知道两组的结果是否在统计上相等。卡方的假设是样本是独立的或者是不配对的。配对的话,你需要使用
McNemar测试。如果样本容量很小,可以用Fisher确切检验。
Fisher's exact, McNemar's test
Cochran's Q test
简单地说,科克伦Q检验是重复测量方差分析或弗里德曼检验的二项式数据版本。因此,你有多个二项数据(如“是”或“否”的回答),你想看看回答的比例是否在不同的组(例如,方法,软件或设备的参与者使用)不同。假设你有如下数据。
| Are you using this software? (o=no, 1=yes) | |||
|---|---|---|---|
| Software A | Software B | Software C | |
| User 1 | 1 | 0 | 1 |
| User 2 | 0 | 0 | 1 |
| User 3 | 0 | 1 | 0 |
| User 4 | 0 | 1 | 1 |
| User 5 | 0 | 0 | 1 |
| User 6 | 1 | 1 | 1 |
| User 7 | 0 | 0 | 1 |
| User 8 | 0 | 1 | 1 |
| User 9 | 0 | 1 | 1 |
| User 10 | 0 | 1 | 1 |
Now, you want to compare the responses across the kinds of software with Cochran's Q test.
Mann-Whitney's U test
Introduction
Mann-Whitney's U检验也被称为Wilcoxon秩和检验,基本上是t检验的非参数版本。你想用曼-惠特尼U测试
因变量是序数的或比率,也可以是区间,但不能假设总体是正态分布。
所以,当人们有序数因变量或只有一个小样本时(因此他们不能假设正态性),你会看到人们使用Mann-Whitney' U检验。然而,Mann-Whitney' U检验仍然假设方差相等。
虽然Mann-Whitney's U检验可以被认为是t检验的非参数版本,但Mann-Whitney's U检验比较的是两组的中位数,而不是平均数。
曼-惠特尼U检验的零假设是两组的样本来自同一总体。
Wilcoxon Signed-rank test
Wilcoxon符号秩检验是配对t检验的非参数版本。您想要使用Wilcoxon Signed-rank检验的情况与Mann-Whitney's U检验相同,并且数据是成对的(即样本是独立的)。
Kruskal-Wallis and Friedman test
Kruskal-Wallis基本上是一个非参数的方差分析。因此,如果您有包含两个以上组的数据进行比较,并且您的数据是有序的,或者您的数据不能假定正态性,那么Kruskal-Wallis是正确的选择。幸运的是,在R中,Kruskal-Wallis测试的运行方式与ANOVA测试的运行方式相似。
还有一种重复测量方差分析的非参数版本,叫做弗里德曼检验。如果要将数据与主体之间的因素进行比较,可以使用Kruskal-Wallis测试。否则,您需要使用Friedman测试。
Kruskal-Wallis和Friedman测试只支持单向分析。这意味着你只能通过一个因素来比较数据,不幸的是,你不能像方差分析那样轻易地将这些测试扩展到双向或混合设计。这是你使用非参数检验时必须付出的代价之一。
相关性分析:
x,y是对称的
Pearson's product-moment coefficient
它衡量了两个变量之间的线性关系。它是一个参数检验(所以数据来自正态分布),数据必须是区间或比率。然而,众所周知,皮尔逊系数是一个相当稳健的度量,所以你可以使用这个除非你的数据是序数的。
Spearman's rank correlation coefficient
这是一个非参数检验,如果你不能假设正态性或你的数据是有序的,你可以使用它。与其他非参数测试类似,它对数据进行排序,并将其用于测试。
Kendall tau rank correlation coefficient
这也是一个非参数检验。如果你的数据在排名时有很多关联,你应该使用这个方法。
交叉表统计:
Phi-Coefficient: 如果你的交叉表是2 × 2,它就等于皮尔逊积矩相关性的绝对值。然而,这个系数取决于交叉表的大小(定义为n x m表的最小(n, m)),范围在0到(min(n, m) - 1的平方根之间。
Contingency Coefficient: 这还取决于交叉表的大小,范围在0到√(1 - 1 / min(n, m))之间
Cramer's V: 这与交叉表的大小无关,范围在0到1之间
Cohen's Kappa for Nominal Data
检测同一件事情上分歧大不大
Latent Variable Analysis:
Principal Component Analysis
主成分分析(PCA)是一个强大的工具,当你有很多变量,你想要研究的东西,这些变量可以解释。正如PCA的名字所暗示的,PCA找到解释现象的变量组合。从这个意义上说,当你想减少变量的数量时,PCA是有用的。
Factor Analysis:
主成分分析的直观意义是找到新的变量组合,形成更大的方差,主成分分析试图通过观察方差来发现包含大量信息的变量的线性组合(方差越大信息越多)
因子分析的直觉是通过观察相关性来发现隐藏的变量,这些变量会影响你观察到的变量
Correspondence Analysis
通过对应分析,我们可以分析和可视化观察数据之间的关系,并查看数据的哪些部分与数据的另一部分相关联
回归性分析
Linear Regression
线性回归是建立变量模型的一种标准方法。
你有两个变量:一个因变量和一个自变量。两个变量都是区间。
你想把因变量和自变量的关系用直线表示出来。也就是说,你想要表达像y = ax + b这样的关系,其中x和y分别是自变量和因变量。
Multiple Regression
多元回归是一种建立由多个变量描述的模型的方法。在很多情况下,你感兴趣的模型是线性的,所以你可以把它看作是线性回归的延伸。但如果你愿意,你可以包括非线性项。在这一页中,我只解释了线性多元回归的过程,但是非线性版本的过程基本上是相同的,假设您有四个因素(因子1、因子2、因子3和因子4)和您的测量(例如,时间或一些性能分数)。在多元回归中,你要做的是找到一个由四个因素的全部或子集描述的测量模型。所以,你最终会有一个这样的模型:
#;## Y = a + b *因子1 + c *因子2 + d *因子3 + e *因子4,##;
Multilevel Linear Model
Logistic Regression
