MongoDB概述&语法
Nosql DB
这是一个非关系型数据库。 通常我们的数据库有三类: 关系型数据库(RDBMS),联机分析处理数据库(OLAP),和菲关系型数据库(NoSql)。
MongoDB属于第三种,而且是一种基于文档的(document oriented)数据库。
优劣势
优势: 查询性能,在都没有建立索引的时候,明显快于MySql。 都建立了索引后,不慢于MySql。
劣势: 不支持事务。因此如果对于事务要求很高的情形,不适用这个数据库。
概念&语法
概念
collection:集合,等于关系型数据库中的table。
document:文档对象,等同于关系型数据库table中的一行记录。
field: 键值对,等同于关系型数据库中table的一个column
database:这个没啥区别。
数据在MongoDB中是以BSON的格式存储的,所谓BSON就是binary json, 也就是二进制的json数据。
语法
属性:javascript语法。
显示数据库: show dbs
使用数据库: use db (备注:这样子就好了,db不存在,则“新建”一个出来,不会报错,事实是:直到存储docuemnt对象时才创建collection和数据库)
查询数据表:db.getCollectionNames() / show collections
数据库统计信息:db.stats()
插入记录: db.your_collection.insert(json表达式) (备注:可以将关联的对象通过json表达式存储在一个document里面---如下图图2中的标注3所示,这个跟关系型数据库不同)
更新记录: db.your_collection.update(json表达式查询用, {$set:json表达式更新用}, 不存在是否插入记录-默认False, 是否更新所有数据-默认False-只更新第一条)
db.your_collection.save(json表达式) : 实际上是插入和更新操作的合并,记录不存在则insert(根据_id字段判断),存在则update。
删除记录: db.your_collection.remove(json表达式)
以上指令演示如下图所示:
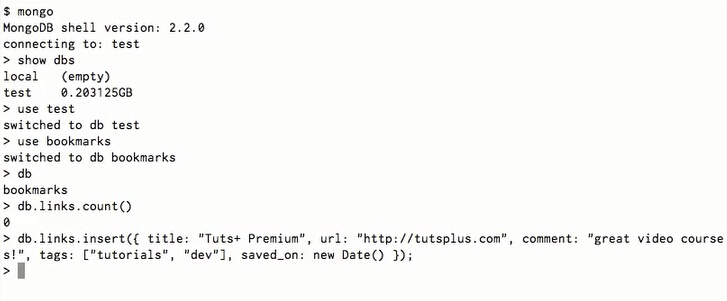
图1
查询记录:db.your_collection.find({键值对},{需要显示/隐藏的字段的键值对})/findOne({键值对},{需要显示/隐藏的字段的键值对})
注意:a) find返回的是一个cursor对象(游标对象), 而findOne返回的是一个document(一条记录)。
find的结果可以用forEach(printjson)格式化,如下图(图中标注1)所示:
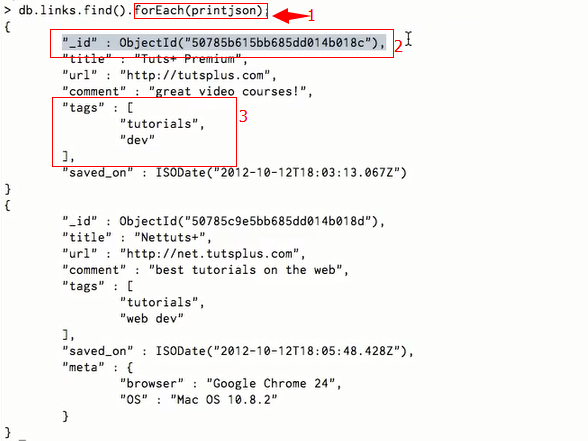
图2
b).findOne,对于有多条记录,则只返回第一条记录(最旧的那条).
c). 第二个参数:{需要显示/隐藏的字段的键值对}, 要么设为白名单,即允许显示哪些字段 ,如{ field1:1, field2:1,...},
要么设置为黑名单,即指定哪些字段不显示,如 {field1:0 , field2:0,....}
不能混用,例如 {field1:1, field2:0},这个是不受支持的。
但对于_id字段例外,这个字段可以混用。
d). 由于一个document中可能存储多级对象,引用子对象可以像js中一样用点号(.)。
例如,已知,user对应的document中存储了name字段,这个字段是一个json对象(另外一张表--在关系型数据库中),如下
{ "_id":ObjectId("a2349723424adfa14"),
"name":{"first":"John","last":"Smith"}
....
}
那么,如果要查询名为john的人,可以这样写js
db.user.find({'name.first':'John'})
其实,这样写也是ok的:
db.user.find({name:{first:'John'}})
e). 范式(normalization)与反范式(de-normalization)
通常把所有的数据存储在一个document里面,这个叫做de-normalization,即用冗余换取读取的性能。这通常使用于读数据比较多的情形,比如cms系统。
如果写数据会比较多,最好normalization一下,即通过第一,第二,第三范式将数据表(collection)重新设计。
mongodb是支持normalization的,通过_id实现(图2中标注2),_id采用了一个特殊的算法,考虑到机器,数据库,collection,时间等因素,将其综合编码到_id中,以保证数据的唯一性。
在normalization后的数据库中,通过link(链接),指向其他document。
例如,book对象可以有author对象的链接,如下:
{"_id":ObjectId("book_id1123132"),
"name":"MongoDB 30分钟精通",
"author_id": ObjectId("author_id_say_tommy"),
...
}
author document对象:
{
"_id": ObjectId("author_id_say_tommy"),
"name":"Tommy",
...
}
这个就是分离了冗余数据,从而有利于update数据操作。
f). 模糊查询
大于: $gt, 小于: $lt, 小于等于: $lte, 大于等于: $gte,
例如,找出所有的被收藏50次以上的链接,可以这样写
db.links.find({favourites:{$gt:50}})
条件:且、或
且,这个是默认的,如果要找出50~100区间的记录,则可以这样写: db.links.find({favourites:{>:50, <:100}})
或,$or,这个操作有点特殊,格式如下:
db.your_collection.find({$or:[{条件1},{条件2},{条件3},...]})
其中条件是键值对表达式,表达式中可以有多个键值对(之前且的关系),条件之间是或的关系。
还有个极端的$nor操作符,取的记录不要符合其中的任何一个条件。对比之下$or的符合其中任何一个条件就ok。
画蛇添足的,还有一个&and操作符,实现且操作的,和$or差不多。
$in , $nin , $all
$in 跟sql的in差不多, $nin根sql的not in差不多, $all,通常用于list,需要list完全匹配。
例子:
db.users.find({'name.first':{$in:['John','David']}})
$ne
相当于sql的 !=
例子:
db.users.find({age:{$ne:30}})
$exists操作符
由于mongodb的document在存放时,对于没有赋值的field,是不保存的。这点和关系型数据库不同,mysql即使某个栏位没有被赋值,那个栏位还在。
因此,可以用这个来过滤出存在或者不存在某些栏位的document。
例如: 找出有维护了age信息的user可以这样写: db.users.find({age:{$exists:true}})
反之,则这样写:db.users.find({age:{$exists:false}})
$not 操作符(取反,用法和$or类似),需要配合其他操作符使用,建议少用,能不用就不用,性能貌似不好。
格式:
db.your_collection.find({field:{$not:{$op:val}}})
$elemMath ,用于匹配含有json的list中的某个json元素的表达式。详细请参考官方: www.mongodb.org
$where
基本上,这个操作符可以做一切你想做的事情,包括替代上面的所有操作符。但是性能不好。当你发现上面的操作符都没法满足你特定要求的时候,可以考虑这个。
语法: db.your_collection.find({$where:f,$otherop:otherval}),其中f是表达式或者js函数。没有其他操作符的情况下,也可以这样写:
db.your_collection.find(f)
例子:找出所有名字含有jo的用户(作为like操作符缺失的弥补)
db.users.find('this.name.first.indexOf("jo")>-1')
转载请注明:本文来自:http://www.cnblogs.com/Tommy-Yu/p/3995997.html,谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号