
A Deep Learning-Based System for Vulnerability Detection(二)
接着上一篇,这篇研究实验和结果。
A.用于评估漏洞检测系统的指标
TP:为正确检测到漏洞的样本数量
FP:为检测到虚假漏洞样本的数量(误报)
FN:为未检真实漏洞的样本数量(漏报)
TN:未检测到漏洞样本的数量
这篇文献广泛使用指标假阳性率(FPR),假阴性率(FNR),真阳性率或者召回率(TPR),精确度(P)和F1-measure来评估漏洞检测系统[39]。
FPR=FP/(FP+TN)指标衡量的是假阳性率漏洞占不容易受到攻击的整个群体样本的比例(在非脆弱样本中误报比率);
FNR=FN/(TP+FN)指标衡量的是假阴性率漏洞与整个样本脆弱群体的比例(在脆弱样本中的漏报比率);
TPR=TP/(TP+FN)指标衡量的是真正检测到脆弱的样本在样本脆弱群体中的比例(TPR=1-FNR);
P=TP/(TP+FP)指标衡量的是正确性;
F1=2*P*TPR/(P+TPR)指标兼顾了精确度和真实阳性率。
检测系统既不漏报(FNR=0)也不误报(FPR=0)以及正确率极高接近1,这是理想情况,现实实践中是不可能的。只可能的是尽量的降低FNR和FPR。
B.准备VulDeePecker的输入
收集数据 NIST维护的漏洞数据库有两个广泛使用的来源:包含生产软件漏洞的NVD[10]和包含生成,合成和学术安全漏洞或漏洞的SARD项目[12]。在NVD中,每个漏洞都有一个唯一的公共漏洞和标识符(CVE ID)和一个公共的弱点枚举标识符(CWE ID),该标识符指示着所涉漏洞的类型。在本篇文献中,关注两种类型的漏洞:缓冲区错误(CWE-119)和资源管理错误(CWE-399),其中每一个都有许多子类型。这些漏洞非常常见,这意味着可以收集足够的数据来可进行深度学习。本片文献选择了19个流行的C/C++开源产品,包括Linux内核,Firefox,Thunderbird,Seamonkey,Firefox esr,Thunderbird esr,Wireshark,FFmpeg,Apache Http Server,Xen,OpenSSL,Qemu,Libav,Asterisk, Cups,Freetype, Gnutls,Libvirt,VLC media player。根据NVD,还在SARD中收集了包含这两种漏洞的C/C++程序。总共从NVD收集了520个有关缓冲区漏洞相关的程序,320个与资源管理错误漏洞相关的程序。还从SARD收集了8112个关于缓冲区错误的程序(测试用例)以及1729个资源管理错误相关的程序,实际上,包含漏洞的程序包含多个程序文件。
训练程序 vs 目标程序 本篇文章随机地选择80%的程序作为训练程序剩下的20%作为目标程序,当在处理一种或者同时两种类型漏洞时这种比例是相对比较平等适用的。
C.学习BLSTM神经网络
这阶段对应着系统VulDeePecker的学习阶段。作者使用Theano[24]和keras[8]在Python中实现了BLSTM神经网络。
第一步:提取函数调用和相应的程序片段。从程序中提取C/C++库/API函数调用,有6045个C/C++库/API函数调用,包括标准库函数调用[1],基本的Windows API和Linux内核API函数调用[9],[13]。总共从程序中提取了56902个库/API函数调用,包括7255个正向函数调用和49647个反向函数调用。
第二步:1.生成代码小部件
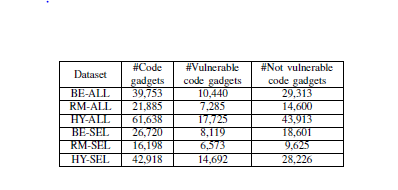
代码小部件由程序片段生成,利用训练程序的程序片段生成的48744个代码小部件和目标程序的程序片段生成的12894个代码小部件获得了一个有关61638个代码小部件的的数据库(Code Gadget Database)。生成代码小部件的时间复杂度主要依赖于数据流分析工具,例如,从SARD中随机选择100个程序(99232行语句)生成2494个代码需要花费883秒,这意味着每个代码小部件的生成平均需要354毫秒。基于效率的考虑,使用CGD(前面提到的代码小部件的数据库)总结出了以下6个数据集。
·BE-ALL:CGD的子集,针对缓冲区错误漏洞(CWE-119)和所有的库/API函数调用。
·RM-ALL:CGD的子集,针对资源管理错误漏洞(CWE-399)和所有的库/API函数调用。
·HY-ALL:和CGD一样,针对前面两种错误漏洞和所有的库/API函数调用。
·BE-SEL:CGD的子集,针对缓冲区错误漏洞(CWE-119)和手动选择的函数调用(而不是所有的函数调用)。
·RM-SEL:CGD的子集,针对资源管理错误漏洞(CWE-399)和手动选择的函数调用(而不是所有的函数调用)。
·HY-SEL:和CGD一样,针对前面两种错误漏洞和手动选择的函数调用(而不是所有的函数调用)。
2.给代码小部件做标记
对于从NVD程序中提取的代码小部件,着重关注于涉及到行删除或修改的被打补丁的漏洞。这个过程有两个步骤:第一步,如果一个代码小部件至少有一行语句通过补丁形式被删除或者修改,那么会被自动标注为“1”(脆弱的,存在安全隐患),否则,标注为“0”(安全的)。然而,这种自动标注过程会误标注一些代码小部件(不是脆弱的被标注为“1”),为了改善这种误标注,第二步,手动去检查这些标记为“1”的代码小部件,去纠正错误标注(如果有的话)。
对于从与SARD有关的程序中提取的代码小部件,,由于每个在SARD中的程序都已经被分别标注为"good"(没有安全缺陷),“bad”(包含安全缺陷),“mixed”(包含有安全缺陷的函数和修补以后的版本)。所以从带有“good”标签的程序提取的代码小部件标注为“0”(安全的),从带有“bad”或者“mixed”标签的程序提取的,代码小部件至少包含一行脆弱的语句,那么该代码小部件标记为“1”,否则为“0”。由于在SARD程序的标签中使用了启发式方法,查看了1000个随机代码小部件的标签,发现只有6个(0.6%)小部件误标注了,这是由于不容易受到攻击的代码段中的语句与容易受到攻击的代码段中的语句是相同的。由于误标注的代码小部件非常少,并且神经网络对于一小部分标记错误的样本具有健壮性,因此不需要人工手动检查SARD程序提取的代码小部件的所有标签。
可能会遇到代码小部件同时被标记为“1”和“0”,这种情况是由于数据流分析工具的不完善造成的,本篇文献的做法是将这些代码小部件删除即可。
第三步:将代码小部件转换为向量
CGD总共包含6166401个标记,其中23464个是不同的,当将用户自定义的函数名称和变量名映射成符号之后,不同的标记进一步减少到10480个。将这些符号表示被编码成向量后,作为训练一个BLSTM神经网络的输入。
第四步:训练BLSTM神经网络
对于表中描述的每个数据集,作者采用10倍交叉验证的方法训练BLSTM神经网络,并选择与有效性相对应的最佳参数值进行漏洞检测。例如。作者改变每个BLSTM神经网络的隐藏层数,观察对结果F1-measure的影响。当调整隐藏层的数量时,当参数的默认值可用时,设置参数为其默认值以及将这些参数设置为深度学习社区广泛使用的值。有关代码小部件的向量表示的标志数目(tokens)设置为50个,dropout设置为0.5,batch size设置为64,epochs设置为4,ADAMAX的minibatch随机梯度下降法(这部分我不熟悉,所以语言组织难免出错),选择300个隐藏节点,采用默认的学习率1.0来进行训练。
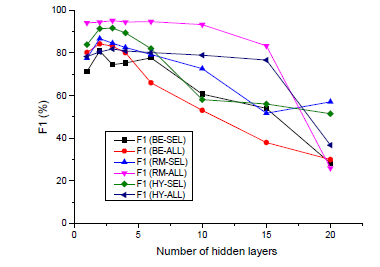
上图绘制了VulDeePecker相对于6个数据集用不同的数量的隐藏层数,每一个数据集导致了不同的神经网络,观察到6个BLSTM神经网络的F1-measure在隐藏层数的个数为2-3时达到最大,当层数大于6时,这些BLSTM神经网络的大多数F1-measure会下降。BLSTM神经网络的其他参数可以以类似的方式进行调优。
D.实验结果与意义
为了测试VulDeePecker是否可以应用于多种类型的漏洞,作者在三个数据集上进行了实验:BE-ALL,RM-ALL,HY-ALL,这分别导致了三种神经网络,其有效性如下表所示:

经结果分析得:
1.VulDeePecker可以同时检测多种类型的漏洞,但是其有效性取决于与漏洞相关的库/API函数调用的数量(即越少越好)。
2.可以利用人工专业知识来选择库/API函数调用来提高VulDeePecker的有效性,尤其是F1-measure中的整体效率。
3.利用数据流分析的优势基于深度学习的漏洞检测系统会更加有效。
4.VulDeePecker比基于代码相似性的漏洞检测系统更有效,后者无法检测出不是由于代码克隆引起的漏洞,因此,经常导致漏报,然而VulDeePecker的高效性体现在对大量的数据很敏感,这是一种深度学习的固有性质。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号