
python编写自己的base64加解密工具
0x00 Base64编码的用途
在网络传输中,不是所的的内容都是可打印字符,其中绝大多数数据是不可见字符,base64可以基于64个可打印字符来表示这些带有不可打印字符的传输数据。
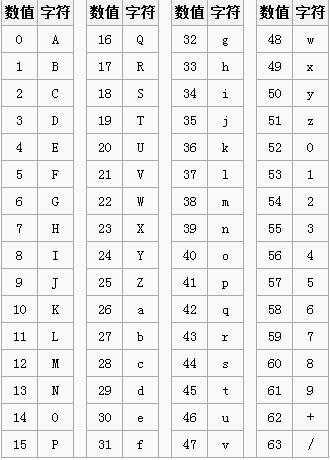
0x01 Base64映射表
标准的base64有一个映射表,将常用字符和数字对应起来,其中0-25对应这大写的A-Z,26-51对应着小写的a-z,52-61对应着数字0-9,62-63对应着+/字符。
0x02 Base64加密原理过程
将字符串转换成Base64编码的过程:
a.将字符串转成为ascii码对应的十进制数,然后转成8位二进制数
b.将所有字符串的8位二进制数以6位为一个整体进行转换成十进制数
c.根据每个整体转换后的十进制数从Base64映射表中取出对应的字符
以下以Hello!为例,其转换过程如图所示:

在这个转换过程中,如果存在不足则补0,补多少呢?这个可以推算的。base64的编码只需要6位即可,正常的字符是8位,取最小公倍数24即可保留完整的信息,添加最少的附加信息0. 这样一来,就会存在末尾出现二进制数为0,对应十进制ascii码的A,通常这种情况下,标准base64进行编码时,通常用=字符替换这个不带实际信息的附加信息0。解码则是对应最后的两个==字符,直接对应的两个6位的二进制0值,丢掉最后两个6比特二进制0值,不做处理。
0x03 具体python实现
编码阶段
a.将输入字符串进行编码,返回8位二进制数
def encode_step_a(value): list = [] for t in value: list.append('0'+bin(ord(t))[2:]) return ''.join(list)
将输入字符串value进行遍历,先通过ord()函数转换成ascii码,然后利用bin转换成二进制数,因为bin()生成的二进制数带有0b字样,所以截取0b后面需要的二进制数,然后在前面补0,凑齐8位,这就需要针对每次遍历的元素取二进制位数后进行长度的判断,是否满足8位二进制数标准,不足则补0. 可行但麻烦,有没有一种可以自动生成8位二进制数,不足自动补齐的函数呢?
应该是有一种类似格式化补齐二进制位的函数的,发现str.format()函数的参数定义如下:
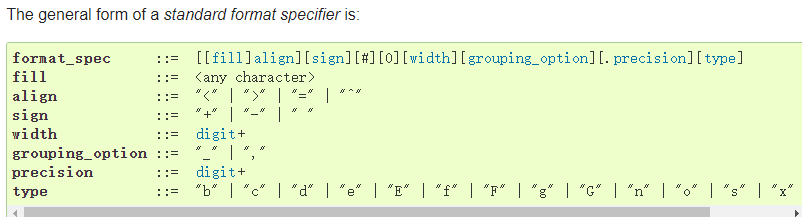
其中对齐参数选项正是想要的:


测试结果如下:

红框中的0自动补齐了。
所以a阶段的方法可以优化为:
def encode_step_a(value): list = ''.join(["{:0>8b}".format(ord(t)) for t in value]) return list
接下重点就是b阶段了,将以8位为整体的二进制数转换为以6位为整体的二进制数,
重点在于不足24位的二进制数,需要补0来填充满足格式
def encode_step_b(value): remainder = len(value) % 24 if remainder: # 存在余数,则需要补充0 padding = '0' * ( 24 - remainder) value += padding # 按照每6位为一个,进行切割字符 res = [value[i:i+6] for i in range(0, len(value), 6)] return res
然后将每6位为一个整体二进制数进行转换为十进制数
def encode_step_c(res): result = '' for i in res: # 全为0则是补充的 if i == '0'*6: encoding = 65 else: encoding = 0 for key , v in enumerate(i): # 进行二进制转十进制 val = int(v) * pow(2, len(i)-1-key) encoding += val # 从base64映射表中取值 res_str= base64_dict.get(str(encoding)) result += res_str return result
设置一个base64_dict映射表
base64_dict= {'0': 'A', '1': 'B', '2': 'C', '3': 'D', '4': 'E',
'5': 'F', '6': 'G', '7': 'H', '8': 'I', '9': 'J',
'10': 'K', '11': 'L', '12': 'M', '13': 'N', '14': 'O',
'15': 'P', '16': 'Q', '17': 'R', '18': 'S', '19': 'T',
'20': 'U', '21': 'V', '22': 'W', '23': 'X', '24': 'Y',
'25': 'Z', '26': 'a', '27': 'b', '28': 'c', '29': 'd',
'30': 'e', '31': 'f', '32': 'g', '33': 'h', '34': 'i',
'35': 'j', '36': 'k', '37': 'l', '38': 'm', '39': 'n',
'40': 'o', '41': 'p', '42': 'q', '43': 'r', '44': 's',
'45': 't', '46': 'u', '47': 'v', '48': 'w', '49': 'x',
'50': 'y', '51': 'z', '52': '0', '53': '1', '54': '2',
'55': '3', '56': '4', '57': '5', '58': '6', '59': '7',
'60': '8', '61': '9', '62': '+', '63': '/', '65': '=',
}
至此,base64的编码过程已经全部手动实现,解码过程也是同样分析,经过优化,封装后的完整代码
class Custom64: base64_dict = {'0': 'A', '1': 'B', '2': 'C', '3': 'D', '4': 'E', '5': 'F', '6': 'G', '7': 'H', '8': 'I', '9': 'J', '10': 'K', '11': 'L', '12': 'M', '13': 'N', '14': 'O', '15': 'P', '16': 'Q', '17': 'R', '18': 'S', '19': 'T', '20': 'U', '21': 'V', '22': 'W', '23': 'X', '24': 'Y', '25': 'Z', '26': 'a', '27': 'b', '28': 'c', '29': 'd', '30': 'e', '31': 'f', '32': 'g', '33': 'h', '34': 'i', '35': 'j', '36': 'k', '37': 'l', '38': 'm', '39': 'n', '40': 'o', '41': 'p', '42': 'q', '43': 'r', '44': 's', '45': 't', '46': 'u', '47': 'v', '48': 'w', '49': 'x', '50': 'y', '51': 'z', '52': '0', '53': '1', '54': '2', '55': '3', '56': '4', '57': '5', '58': '6', '59': '7', '60': '8', '61': '9', '62': '+', '63': '/', '65': '=', } def encode(self, value: str, threshold: int = 6) -> str: # 对传入的字符进行编码,并返回编码结果 value = ''.join(["{:0>8b}".format(ord(t)) for t in value]) inputs = self.shift(value, threshold) result = '' for i in inputs: if i == '0' * threshold: # 全为0则视为补位 encoding = 65 else: encoding = 0 for key, v in enumerate(i): # 二进制数按权相加得到十进制数 val = int(v) * pow(2, len(i) - 1 - key) encoding += val # 从对照表中取值 res = self.base64_dict.get(str(encoding)) result += res return result def decode(self, value: str, threshold: int, group: int = 8) -> str: """对传入的字符串解码,得到原字符""" result = [] coder = self.str2binary(value, threshold=threshold) bins = self.shift(''.join(coder), group) for i in range(len(bins)): binary = ''.join(bins)[i * group: (i + 1) * group] if binary != '0' * group: # 如果全为0则视为补位,无需处理 result.append(''.join([chr(i) for i in [int(b, 2) for b in binary.split(' ')]])) return ''.join(result) def str2binary(self, value: str, threshold: int = 6) -> list: """字符串转十进制再转二进制""" result = [] values = self.str2decimal(value) for i in values: # 判断是否为补位 if i == '65': val = '0' * threshold else: val = '{:0{threshold}b}'.format(int(i), threshold=threshold) result.append(val) return result @staticmethod def shift(value: str, threshold: int, group: int = 24) -> list: """位数转换""" remainder = len(value) % group if remainder: # 如果有余数,则说明需要用0补位 padding = '0' * (group - remainder) value += padding # 按照threshold值切割字符 result = [value[i:i + threshold] for i in range(0, len(value), threshold)] return result def str2decimal(self, value: str) -> list: """使用Base64编码表做对照,取出字符串对应的十进制数""" keys = [] for t in value: for k, v in self.base64_dict.items(): if v == t: keys.append(k) return keys
if __name__ == '__main__':
cus = Custom64()
encode_res = cus.encode('hello1!', threshold=6)
decode_res = cus.decode(encode_res, threshold=6)
# encode_res = cus.encode(';function transToDict(n,a){res="{name:"+n+",age:"+a+"}";console.log(res);return res};var ss=transToDict("P",20);', threshold=6)
# encode_res = cus.encode('alert("xss");', threshold=6)
# decode_res = cus.decode("cz1jcmVhdGVFbGVtZW50KCdzY3JpcHQnKTtib2R5LmFwcGVuZENoaWxkKHMpO3Muc3JjPSdodHRwOi8veHNzcHQuY29tL0ZweWpnUz8nK01hdGgucmFuZG9tKCk=", threshold=6)
print(encode_res)
print(decode_res)
自实现的base64小工具可以定义分组大小(threshold 6位)和任意字典映射表(base64_dict),可以满足内部小团队的加密需求。
当然python3.6 自带有base64库,使用也是极为方便简单
from base64 import b64decode from base64 import b64encode def code_fun(): code = ['aGVsbG8=', 'aGVsbG8h', "aGVsbG8hIQ=="] str_list = ["hello", "hello!", "hello!!"] for c in code: string = b64decode(c).decode('utf8') print(string) for str in str_list: encoded_str = b64encode(bytes(str, 'utf-8')) print(encoded_str) if __name__ == "__main__": code_fun()
0x04 安全小想法
base64一般来说在安全界是不作为安全加密算法的,因为过程可逆。业界中密码系统的安全性不应该依靠算法的保密,而是取决于密钥的保密性。真正能做到就算所有人知道系统的运作过程,仍然是安全的。当然不论是标准的base64或者是自实现的加密工具,作为代码混淆,还是可以为安全贡献一份力量的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号