
Elasticsearch 分片集群原理、搭建、与SpringBoot整合
单机es可以用,没毛病,但是有一点我们需要去注意,就是高可用是需要关注的,一般我们可以把es搭建成集群,2台以上就能成为es集群了。集群不仅可以实现高可用,也能实现海量数据存储的横向扩展。
新的阅读体验地址: http://www.zhouhong.icu/archives/elasticsearchfen-pian-ji-qun-yuan-li--da-jian--yu-springboot-zheng-he
一、Elasticsearch分片机制:
- 每个索引可以被分片,每个主分片都包含索引的数据。
- 副本分片是主分片的备份,主挂了,备份还是可以访问,这就需要用到集群了。
- 同一个分片的主与副本是不会放在同一个服务器里的,因为一旦宕机,这个分片就没了。
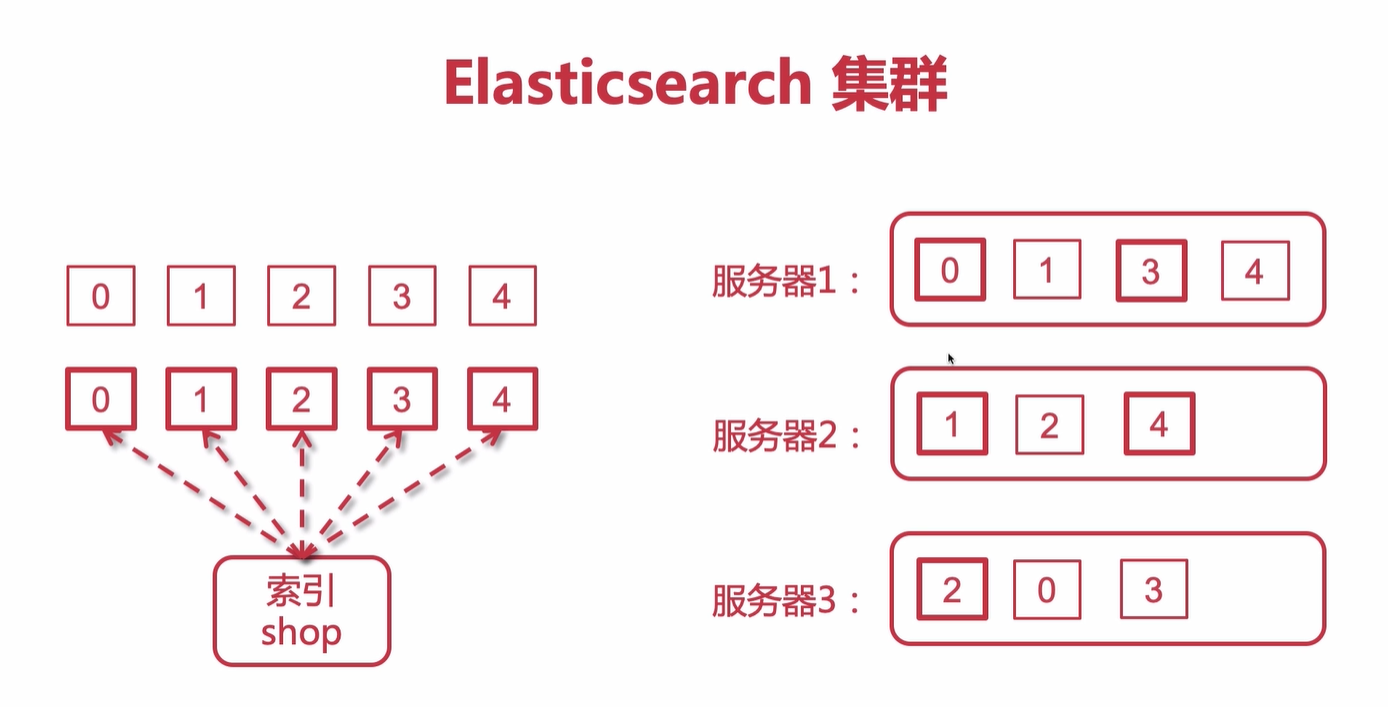
如下图:左边每个索引主备分片都会分配在三台服务器上的不同节点上面,右图粗方框表示主分片,细节点表示备节点。
二、搭建Elasticsearch集群
1、前置操作
- ES中之前的data目录,一定要清空,这里面包含了原先的索引库数据。
- 使用三台服务器:
- 192.168.1.184(主), 192.168.1.185(从), 192.168.1.186(从)
- 关于Elasticsearch单机的简介、安装配置请转到:http://www.zhouhong.icu/post/128
2、配置集群
- 修改每台服务器上ES的elasticsearch.yml这个配置文件如下,每台服务器node.name不一样分别为es-node1、es-node2、es-node3.

# 配置集群名称,保证每个节点的名称相同,如此就能都处于一个集群之内了 cluster.name: es-cluster # 每一个节点的名称,必须不一样 node.name: es-node1 # http端口(使用默认即可) http.port: 9200 # 主节点,作用主要是用于来管理整个集群,负责创建或删除索引,管理其他非master节点(相当于企业老总) node.master: true # 数据节点,用于对文档数据的增删改查 node.data: true # 集群列表 discovery.seed_hosts: ["192.168.1.184", "192.168.1.185", "192.168.1.186"] # 启动的时候使用一个master节点,未指定ES会进行选举 cluster.initial_master_nodes: ["es-node1"]
3、最后可以通过如下命令查看配置文件的内容:(过滤掉“#”后面的注释)
more elasticsearch.yml | grep ^[^#]
4、切换到esuser后启动,访问集群各个节点,查看信息:
- http://192.168.1.184:9200/
- http://192.168.1.185:9200/
- http://192.168.1.186:9200/
主节点宕机之后会从生下的两个从节点选举新的主节点,主节点恢复后成为从节点。
三、Elasticsearch集群脑裂现象
1、什么是脑裂
- 如果发生网络中断或者服务器宕机,那么集群会有可能被划分为两个部分,各自有自己的master来管理,那么这就是脑裂。

2、脑裂解决方案
- master主节点要经过多个master节点共同选举后才能成为新的主节点。就跟班级里选班长一样,并不是你1个人能决定的,需要班里半数以上的人决定。
- 解决实现原理:半数以上的节点同意选举,节点方可成为新的master。
discovery.zen.minimum_master_nodes=(N/2)+1
- N为集群的中master节点的数量,也就是那些 node.master=true 设置的那些服务器节点总数。
3、ES 7.X
- 在最新版7.x中,minimum_master_node这个参数已经被移除了,这一块内容完全由es自身去管理,这样就避免了脑裂的问题,选举也会非常快。‘’
四、Elasticsearch集群的文档读写原理
-
文档写原理:p1,p2,p0是主节点,r0,r1,r2是副本节点
- 如果客户端选择了中间节点进行写数据,那这个节点就会变成协调节点,接受用户请求,会对文档进行路由,计算这个文档会写入到哪个主分片中,有主分片把数据同步到副本分片,都写入完成之后,在跳回到协调节点,由协调节点相应请求。

-
文档读原理:p1,p2,p0是主节点,r0,r1,r2是副本节点
- 如果客户端请求到了第一个节点,那第一个节点也会变成协调节点,然后根据文档的数据进行路由,然后从主分片或者副本分片轮询读数据。不管从主分片还是副本分片读取数据,最后都会跳回到协调节点,由协调节点相应客户端

五、Elasticsearch集群与SpringBoot整合
1、创建工程,引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
<version>2.2.2.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
2、配置yml文件:客户端连接的是 9300
spring: data: elasticsearch: cluster-name: es-cluster cluster-nodes: 192.168.1.184:9300,192.168.1.185:9300,192.168.1.186:9300
版本协调:
目前springboot-data-elasticsearch中的es版本贴合为es-6.4.3,如此一来版本需要统一,把es进行降级。等springboot升级es版本后可以在对接最新版的。
3、解决启动时 Netty issue fix 问题
在启动类同一级目录下创建 ESConfig.java 配置类
@Configuration public class ESConfig { /** * 解决netty引起的issue */ @PostConstruct void init() { System.setProperty("es.set.netty.runtime.available.processors", "false"); } }
本文来自博客园,作者:Tom-shushu,转载请注明原文链接:https://www.cnblogs.com/Tom-shushu/p/14444717.html
分类:
其他分类



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律