
Julia常用包总结(深度学习、数据科学、绘图...updating...)
Julia 常用包
零.环境
IJulia 是一个以Julia为后端的交互式环境,可以方便的进行交互式编程
- 安装
using Pkg
Pkg.add("IJulia")- 使用
using IJulia
notebook()一.数据处理
常用的数据处理包包括以下几个方面:
1.基本科学计算
TODO
2.数据I/O
DataFrames
二.绘图
TODO
三.机器学习
Mocha
Mocha是一个高效的深度学习框架,包含了通用的随机梯度求解器,可以它构建层训练深、浅(卷积)网络。
- 安装
Pkg.add("Mocha) - 使用例子
using Mocha
data = HDF5DataLayer(name="train-data",source="train-data-list.txt",batch_size=64)
conv = ConvolutionLayer(name="conv1",n_filter=20,kernel=(5,5),bottoms=[:data],tops=[:conv])
pool = PoolingLayer(name="pool1",kernel=(2,2),stride=(2,2),bottoms=[:conv],tops=[:pool])
conv2 = ConvolutionLayer(name="conv2",n_filter=50,kernel=(5,5),bottoms=[:pool],tops=[:conv2])
pool2 = PoolingLayer(name="pool2",kernel=(2,2),stride=(2,2),bottoms=[:conv2],tops=[:pool2])
fc1 = InnerProductLayer(name="ip1",output_dim=500,neuron=Neurons.ReLU(),bottoms=[:pool2],
tops=[:ip1])
fc2 = InnerProductLayer(name="ip2",output_dim=10,bottoms=[:ip1],tops=[:ip2])
loss = SoftmaxLossLayer(name="loss",bottoms=[:ip2,:label])
backend = DefaultBackend()
init(backend)
common_layers = [conv, pool, conv2, pool2, fc1, fc2]
net = Net("MNIST-train", backend, [data, common_layers..., loss])
exp_dir = "snapshots"
solver_method = SGD()
params = make_solver_parameters(solver_method, max_iter=10000, regu_coef=0.0005,
mom_policy=MomPolicy.Fixed(0.9),
lr_policy=LRPolicy.Inv(0.01, 0.0001, 0.75),
load_from=exp_dir)
solver = Solver(solver_method, params)
setup_coffee_lounge(solver, save_into="$exp_dir/statistics.jld", every_n_iter=1000)
# report training progress every 100 iterations
add_coffee_break(solver, TrainingSummary(), every_n_iter=100)
# save snapshots every 5000 iterations
add_coffee_break(solver, Snapshot(exp_dir), every_n_iter=5000)
# show performance on test data every 1000 iterations
data_test = HDF5DataLayer(name="test-data",source="test-data-list.txt",batch_size=100)
accuracy = AccuracyLayer(name="test-accuracy",bottoms=[:ip2, :label])
test_net = Net("MNIST-test", backend, [data_test, common_layers..., accuracy])
add_coffee_break(solver, ValidationPerformance(test_net), every_n_iter=1000)
solve(solver, net)
destroy(net)
destroy(test_net)
shutdown(backend)2.Flux
flux是一个机器学习工具包,可以实现各种基本模型(如线性回归)到复杂模型(如神经网络)的搭建、优化和使用。
![]()
- 安装
Pkg.add("Flux")
# 可选项目 更新和测试
Pkg.update() # Keep your packages up to date
Pkg.test("Flux") # Check things installed correctly- 使用,简单模型
#定义模型
W = rand(2, 5)
b = rand(2)
predict(x) = W*x .+ b
function loss(x, y)
ŷ = predict(x)
sum((y .- ŷ).^2)
end
x, y = rand(5), rand(2) # Dummy data
loss(x, y) # ~ 3
# 求解梯度
using Flux.Tracker
W = param(W)
b = param(b)
gs = Tracker.gradient(() -> loss(x, y), Params([W, b]))
#更新权重
using Flux.Tracker: update!
Δ = gs[W]
# Update the parameter and reset the gradient
update!(W, -0.1Δ)
loss(x, y) # ~ 2.53.Tensorflow
tensorfl.jl基于tensorflow开发的julia封装。
- 安装
Pkg.add("TensorFlow")
- 使用
GPU支持
ENV["TF_USE_GPU"] = "1"
Pkg.build("TensorFlow")
简单的例子:
using TensorFlow
sess = TensorFlow.Session()
x = TensorFlow.constant(Float64[1,2])
y = TensorFlow.Variable(Float64[3,4])
z = TensorFlow.placeholder(Float64)
w = exp(x + z + -y)
run(sess, TensorFlow.global_variables_initializer())
res = run(sess, w, Dict(z=>Float64[1,2]))
Base.Test.@test res[1] ≈ exp(-1)4.MxNet
MNXET(https://github.com/dmlc/MXNet.jl)julia包
- 安装
Pkg.add("MXNet") - 使用
using MXNet
#模型定义
mlp = @mx.chain mx.Variable(:data) =>
mx.FullyConnected(name=:fc1, num_hidden=128) =>
mx.Activation(name=:relu1, act_type=:relu) =>
mx.FullyConnected(name=:fc2, num_hidden=64) =>
mx.Activation(name=:relu2, act_type=:relu) =>
mx.FullyConnected(name=:fc3, num_hidden=10) =>
mx.SoftmaxOutput(name=:softmax)
# data provider
batch_size = 100
include(Pkg.dir("MXNet", "examples", "mnist", "mnist-data.jl"))
train_provider, eval_provider = get_mnist_providers(batch_size)
# setup model
model = mx.FeedForward(mlp, context=mx.cpu())
# optimization algorithm
# where η is learning rate and μ is momentum
optimizer = mx.SGD(η=0.1, μ=0.9)
#模型训练
# fit parameters
mx.fit(model, optimizer, train_provider, n_epoch=20, eval_data=eval_provider)
#预测
probs = mx.predict(model, eval_provider)
# collect all labels from eval data
labels = reduce(
vcat,
copy(mx.get(eval_provider, batch, :softmax_label)) for batch ∈ eval_provider)
# labels are 0...9
labels .= labels .+ 1
# Now we use compute the accuracy
pred = map(i -> indmax(probs[1:10, i]), 1:size(probs, 2))
correct = sum(pred .== labels)
accuracy = 100correct/length(labels)
@printf "Accuracy on eval set: %.2f%%\n" accuracy
5.Scikit
scikitlearn流行的机器学习包julia实现,支持多种机器学习模型。
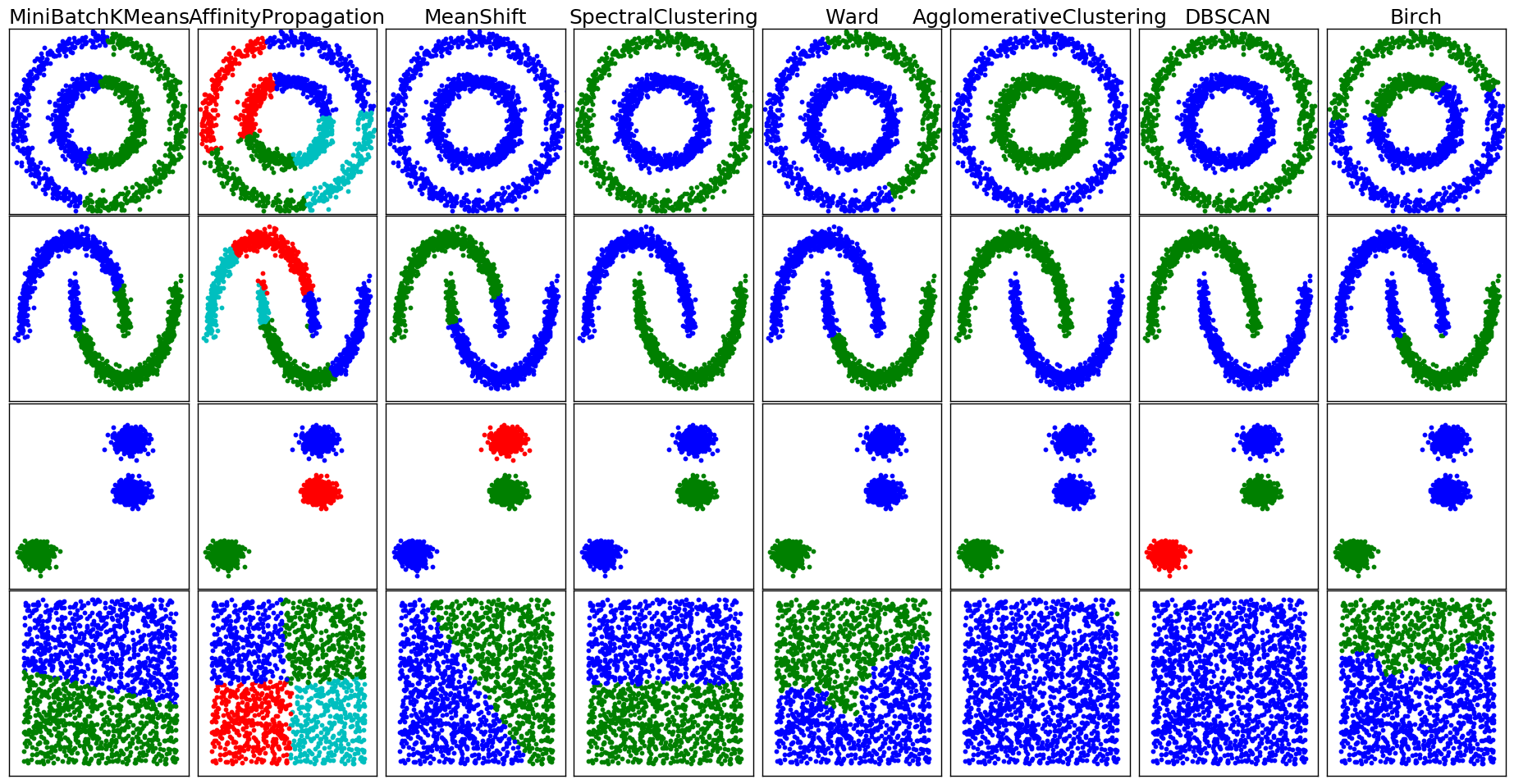
- 安装
Pkg.add("ScikitLearn")
- 使用的简单例子
using RDatasets: dataset
iris = dataset("datasets", "iris")
#定义数据
# ScikitLearn.jl expects arrays, but DataFrames can also be used - see
# the corresponding section of the manual
X = convert(Array, iris[[:SepalLength, :SepalWidth, :PetalLength, :PetalWidth]])
y = convert(Array, iris[:Species])
#载入逻辑回归模型
using ScikitLearn
# This model requires scikit-learn. See
# http://scikitlearnjl.readthedocs.io/en/latest/models/#installation
@sk_import linear_model: LogisticRegression
Every model's constructor accepts hyperparameters (such as regression strength, whether to fit the intercept, the penalty type, etc.) as keyword arguments. Check out ?LogisticRegression for details.
model = LogisticRegression(fit_intercept=true)
Then we train the model and evaluate its accuracy on the training set:
#训练
fit!(model, X, y)
#预测
accuracy = sum(predict(model, X) .== y) / length(y)
println("accuracy: $accuracy")
> accuracy: 0.96
 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}