
【今日CV 计算机视觉论文速览 92期】 2 Apr 2019
今日CS.CV 计算机视觉论文速览
Tue, 2 Apr 2019 (showing first 100 of 114 entries)
Totally 100 papers

Interesting:
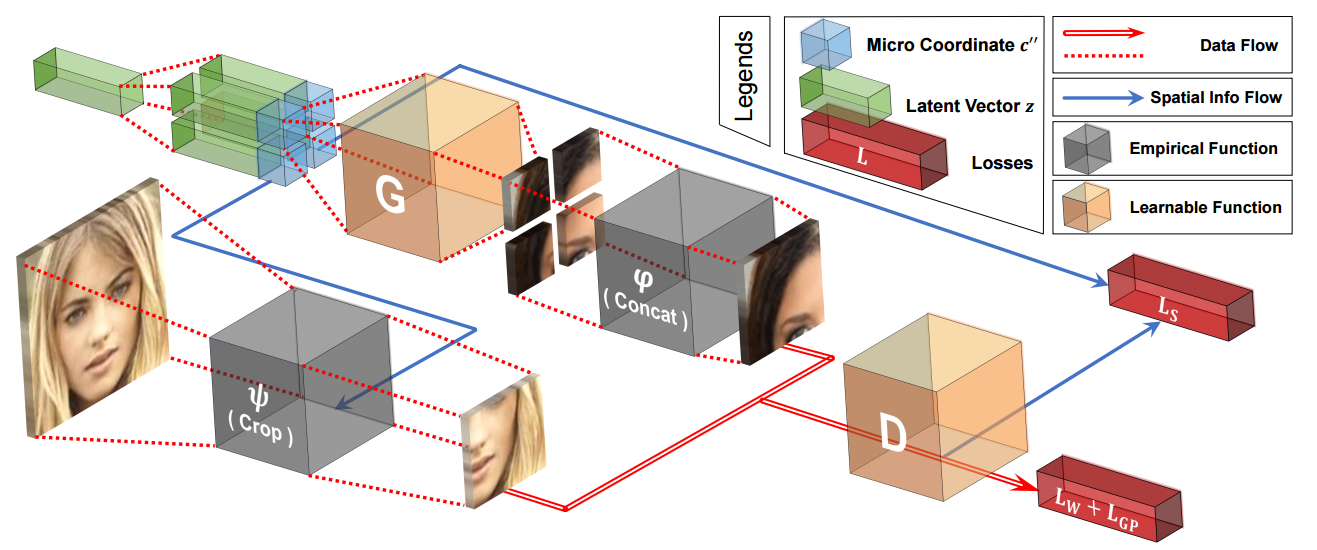
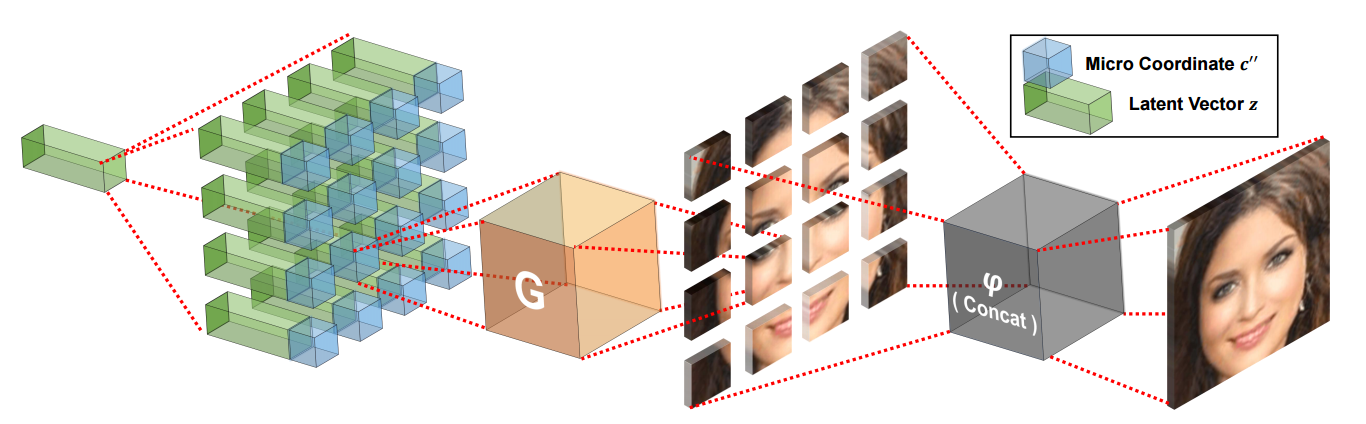
📚COCO-GAN, 基于条件坐标,由部分图像片生成完整面部图像。由于人类可以通过一部分看到的事物补全物体的全貌,研究人员也利用了类似的条件坐标方法,通过图像片和空间坐标来生成图像,判别器用于判断组合后脸的真实性、连续性。这可以生成比训练图像大的图像,超过了边界的限制。并在计算中使用了分治法来实现了更高效率。(from 国立清华大学 Google)
训练架构:
使用的测试架构:
训练中使用的几种不同的坐标系统,包含micro片层和macro片层。

📚The RGB-D Triathlon, 机器人中多种视觉任务的工具包benchmark(from 都灵理工)
三种RGB数据集:
code:https://github.com/fcdl94/RobotChallenge


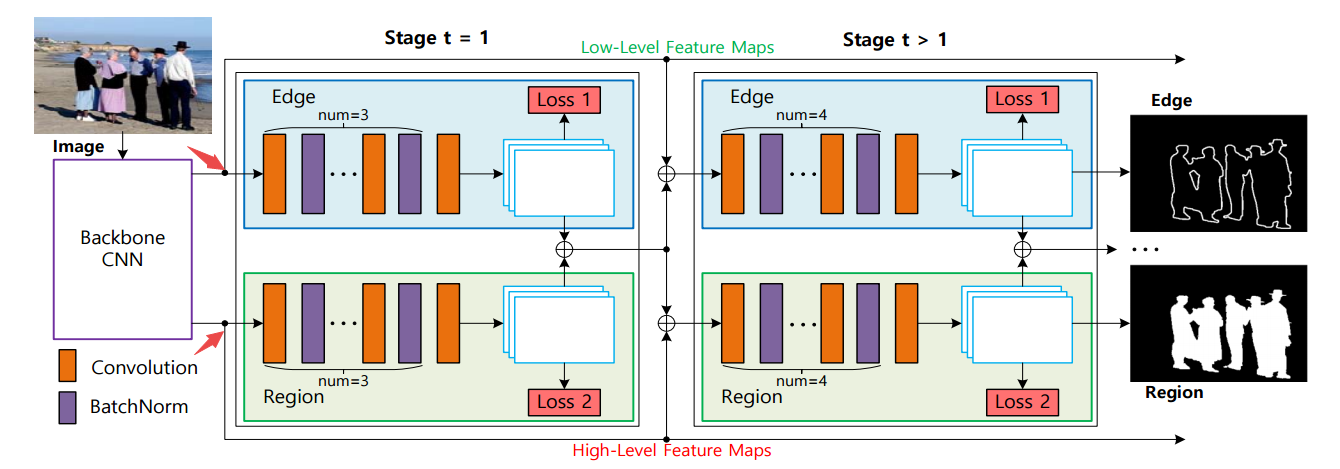
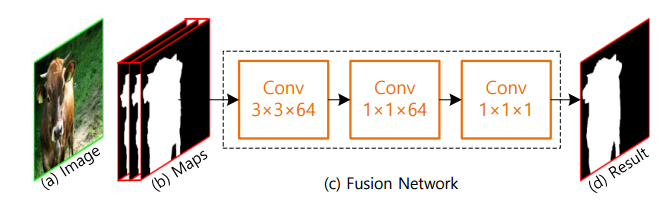
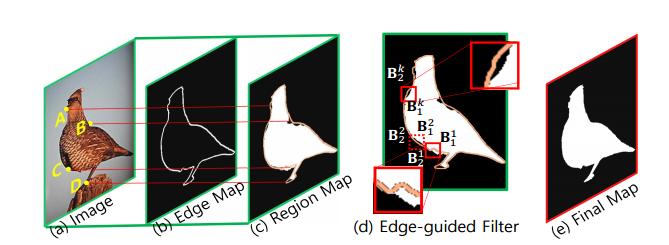
📚SE2Net, 基于Siamese的边缘提升显著性检测方法。(from 西安交大)
首先通过基础网络学习出底层与高层特征,随后将底层特征送入边缘学习网络。高层特征送入mask学习网络,最后将信息融合进行时序精炼得到最终结果。
mask融合方法与边缘引导的mask精炼conditional random fieldCRF方法 :
一些结果:
数据集:ESSCD dataset,DUTS [37], ECSSD [45], SOD [28], DUT-OMRON [46],THUR 15K [4] and HKU-IS [17]
评价指标:e F-measure score (Fβ) and Mean Absolute Error (MAE) , a better salient object detection model should have a larger Fβ and a smaller MAE.

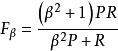
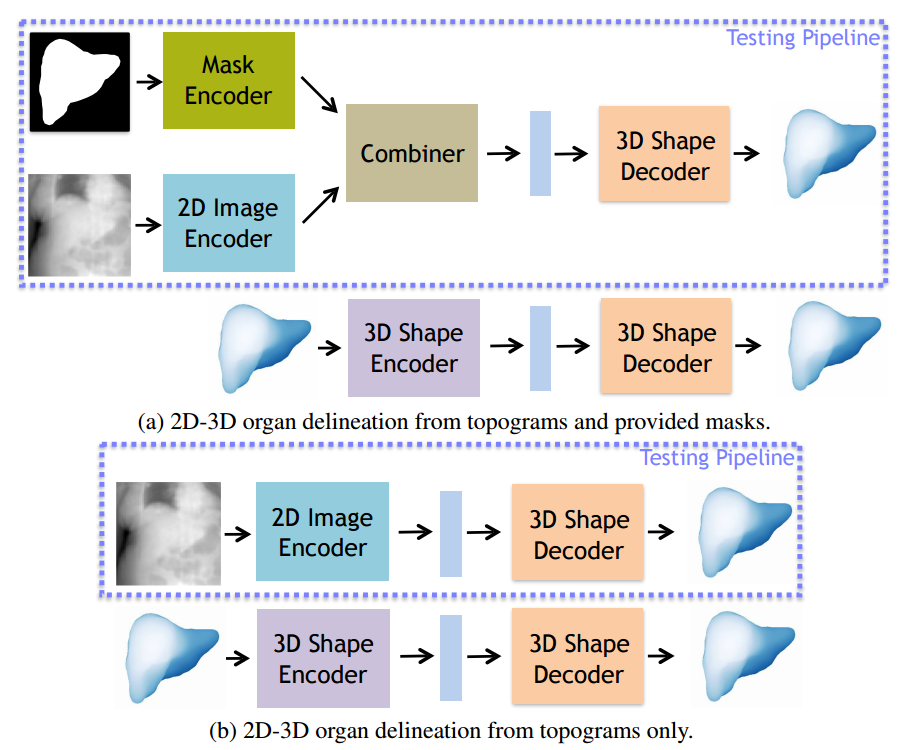
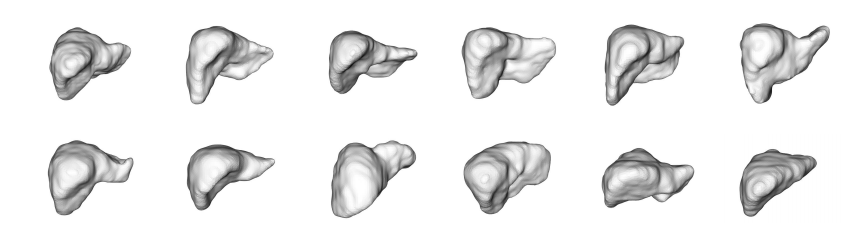
📚基于Topoogram图像的器官三维重建, 基于计算断层扫描CT的二维投影来直接重建出肝脏的三维形状,减少了辐照计量。利用单图片的3Dshape预测任务来实现肝脏外形重建。(from 普林斯顿)
方法一合成了mask的编码信息,方法二只利用了2D topogram 到三维编码的映射。
一些生成的结果:
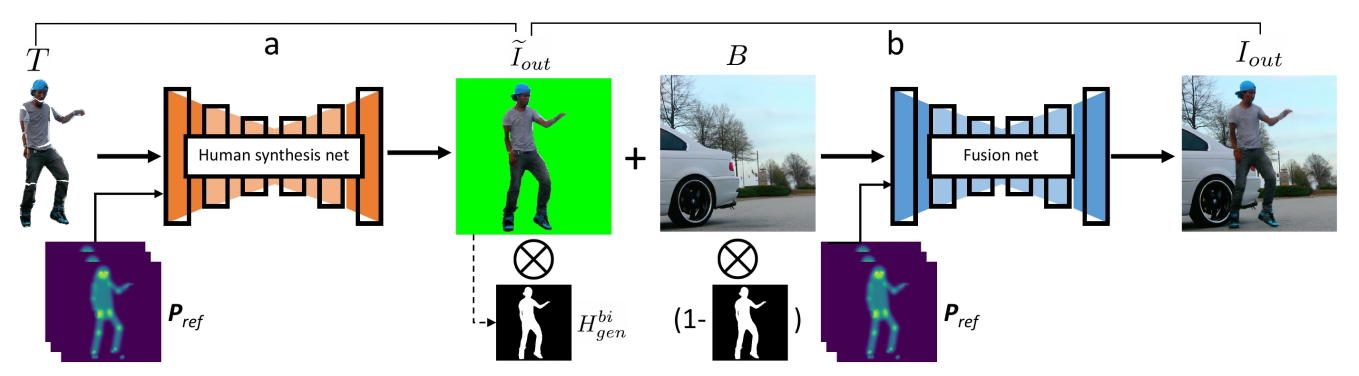
📚Dance Dance Generation, 提出了一种可以将视频中一个的动作转移到另一个人身上,通过人物生成网络来合成目标对象在新动作下的前景,并用融合网络将背景与目标融合起来,有效处理了阴影、反射和光照。(from 北卡罗来纳大学)
网络架构分为两部分,:
一些结果:


Daily Computer Vision Papers
| Equivariant Multi-View Networks Authors Carlos Esteves, Yinshuang Xu, Christine Allen Blanchette, Kostas Daniilidis 三种3D视觉任务方法通过在自然图像上预训练的深度神经网络独立处理输入的多个视图,通过在所有视图上的单轮汇集实现视图置换不变性。我们认为此操作会丢弃重要信息并导致低于全局的描述符。在本文中,我们提出了一种用于多视图聚合的组卷积方法,其中在旋转组的离散子组上执行卷积,从而能够以等变而不是不变的方式对所有视图进行联合推理,直到最后一层。我们进一步发展这个想法以在旋转组的较小的离散均匀空间上操作,其中极坐标视图表示用于仅与输入视图的数量的一小部分保持等效。我们在几个大型3D形状检索任务中设置了新的技术水平,并展示了全景场景分类的其他应用。 |
| Automatic Nonrigid Histological Image Registration with Adaptive Multistep Algorithm Authors Marek Wodzinski, Andrzej Skalski 在本文中,我们简要介绍了与IEEE ISBI 2019会议共同组织的ANHIR挑战提出的方法。我们提出了一种方法,包括预处理,初始对齐,非刚性配准算法和自动选择最佳结果的方法。该方法结果是稳健的99.792稳健性和准确的0.38平均中值rTRE。该方法的主要缺点是计算时间相对较长。但是,通过清理代码并提出GPU实现,可以轻松改善这一方面。 |
| Regional Homogeneity: Towards Learning Transferable Universal Adversarial Perturbations Against Defenses Authors Yingwei Li, Song Bai, Cihang Xie, Zhenyu Liao, Xiaohui Shen, Alan L. Yuille 本文侧重于学习专门针对防御模型模型以防御对抗性攻击的可转移对抗性示例。特别是,我们表明,简单的普遍扰动可以欺骗一系列最先进的防御。 |
| Early Diagnosis of Pneumonia with Deep Learning Authors Can Jozef Saul, Deniz Yagmur Urey, Can Doruk Taktakoglu 肺炎是致命疾病之一,并且由于肺中的液体流动导致溺水,因此有可能在短时间内导致严重后果。如果在适当的时候没有药物作用,肺炎可能导致个体死亡。因此,早期诊断是疾病进展的关键因素。本文重点介绍肺炎的生物学进展及其X射线成像检测,概述了提高诊断水平的研究,并提出了基于各种参数自动化X射线图像的方法和结果,以便检测疾病。在很早的阶段。在这项研究中,我们提出了分类任务的深度学习架构,通过多个预处理步骤,使用修改后的图像进行训练。我们的分类方法使用卷积神经网络和残余网络架构来对图像进行分类。我们的研究结果的准确率为78.73,超过了此前最高得分准确率76.8。 |
| Robustness of 3D Deep Learning in an Adversarial Setting Authors Matthew Wicker, Marta Kwiatkowska 了解现实世界物体的空间布局和性质对于许多复杂的工程任务(包括自主导航)至关重要。深度学习已经彻底改变了3D环境中任务的最新性能,然而,在对抗环境中这些方法的稳健性知之甚少。由于缺乏全面的分析,很难证明在现实世界中安全关键应用程序中部署3D深度学习模型是合理的。在这项工作中,我们开发了一种算法,用于分析在3D数据上运行的神经网络的逐点鲁棒性。我们表明,目前用于理解最先进模型弹性的方法大大高估了它们的鲁棒性。然后,我们使用我们的算法来评估一系列最先进的模型,以证明它们对遮挡攻击的脆弱性。我们表明,在最坏的情况下,在最多6.5个占用输入空间的遮挡之后,这些网络可以降低到0分类精度。 |
| Spherical U-Net on Cortical Surfaces: Methods and Applications Authors Fenqiang Zhao, Shunren Xia, Zhengwang Wu, Dingna Duan, Li Wang, Weili Lin, John H Gilmore, Dinggang Shen, Gang Li 卷积神经网络CNN已经为欧几里得空间中涉及2D 3D图像的学习相关问题提供了最先进的性能。然而,与欧几里德空间不同,医学成像中的许多结构的形状在流形空间中具有球形拓扑,例如,由三角形网格表示的大脑皮质或皮质下表面,具有大的主体间和顶部数量内的主体间变化和局部连通性。因此,没有一致的邻域定义,因此对于皮层皮质下表面数据没有直接的卷积转置卷积运算。在本文中,通过利用映射到球面空间的重采样皮层表面的规则和一致的几何结构,我们提出了一种新的卷积滤波器,类似于图像网格上的标准卷积。因此,我们开发了用于球面数据的卷积,汇集和转置卷积的相应操作,从而构造了球形CNN。具体来说,我们提出了球形U网架构,将标准U Net中的所有操作替换为其球形操作对应物。然后,我们将球形U网应用于婴儿大脑皮质表面分割和皮质属性图发展预测中的两项具有挑战性和神经科学重要性的任务。与现有技术方法相比,这两种应用都证明了我们提出的球形U网的准确性,计算效率和有效性的竞争性能。 |
| Key.Net: Keypoint Detection by Handcrafted and Learned CNN Filters Authors Axel Barroso Laguna, Edgar Riba, Daniel Ponsa, Krystian Mikolajczyk 我们介绍了一种新的关键点检测任务方法,该方法将手工和学习CNN滤波器结合在一个浅层多尺度架构中。手工过滤器为学习过滤器提供锚定结构,可对可重复的功能进行本地化,评分和排序。在网络中使用缩放空间表示来提取不同级别的关键点。我们设计了一种损失函数来检测一系列尺度上存在的稳健特征,并最大化重复性评分。我们的Key.Net模型是根据ImageNet综合创建的数据进行培训,并在HPatches基准测试中进行评估。结果表明,我们的方法在可重复性,匹配性能和复杂性方面优于最先进的检测器。 |
| Adversarial Defense by Restricting the Hidden Space of Deep Neural Networks Authors Aamir Mustafa, Salman Khan, Munawar Hayat, Roland Goecke, Jianging Shen, Ling Shao 深度神经网络容易受到对抗性攻击,这可能通过在输入图像中添加微小的扰动来欺骗它们。在白盒攻击设置下,现有防御的强大性受到很大影响,其中对手完全了解网络并且可以多次迭代以发现强烈的扰动。我们观察到存在这种扰动的主要原因是在学习的特征空间中不同类别样本的紧密接近。这允许通过在输入中添加难以察觉的扰动来完全改变模型决策。为了解决这个问题,我们建议明智地解开深层网络的中间特征表示。具体来说,我们强制每个类的特征位于一个凸多边形内,该多边形最大程度地与其他类的多边形分开。以这种方式,网络被迫为每个班级学习不同的和遥远的决策区域。我们观察到,这些对特征的简单约束极大地增强了学习模型的稳健性,甚至可以抵抗最强的白盒攻击,而不会降低干净图像的分类性能。我们报告在文本黑匣子和白盒攻击情景中进行了广泛的评估,并且与最先进的防御相比显示出显着的增益。 |
| Significance-aware Information Bottleneck for Domain Adaptive Semantic Segmentation Authors Yawei Luo, Ping Liu, Tao Guan, Junqing Yu, Yi Yang 对于无监督域适应问题,通过对抗性学习在潜在特征空间中对齐两个域的策略在图像分类方面取得了很大进展,但通常在潜在表示过于复杂的语义分割任务中失败。在这项工作中,我们为对抗性网络配备了重要意识信息瓶颈SIB,以解决上述问题。新的网络结构称为SIBAN,可在对抗性适应之前实现显着性特征净化,从而简化特征对齐并稳定对抗性训练过程。在两个领域适应任务中,即GTA5 Cityscapes和SYNTHIA Cityscapes,我们验证了与其他特征空间替代方案相比,所提出的方法可以产生领先的结果。此外,SIBAN甚至可以在分割精度上匹配最先进的输出空间方法,而后者通常被认为是域自适应分割任务的更好选择。 |
| DefectNET: multi-class fault detection on highly-imbalanced datasets Authors N. Anantrasirichai, David Bull 作为一种数据驱动方法,深度卷积神经网络CNN的性能在很大程度上依赖于训练数据。传统网络的预测结果偏向于较大的类,这往往是语义分割任务的背景。这成为故障检测的主要问题,其中目标在图像上看起来非常小并且在类型和大小上都不同。在本文中,我们提出了一种新的网络架构DefectNet,它提供了多类,包括但不限于高度不平衡数据集上的缺陷检测。 DefectNet由两个并行路径组成,它们是完全卷积网络和扩张卷积网络,分别用于检测大小物体。我们提出混合损失最大化骰子损失和交叉熵损失的有用性,并且我们还使用泄漏整流线性单元ReLU来处理训练批次中的一些目标的罕见发生。预测结果表明,我们的DefectNet在检测多级缺陷方面优于先进的网络,风力涡轮机的平均精度提高了大约10。 |
| Precise Detection in Densely Packed Scenes Authors Eran Goldman , Roei Herzig , Aviv Eisenschtat , Jacob Goldberger, Tal Hassner 人造场景可以密集包装,包含许多物体,通常是相同的,位置非常接近。我们表明,即使对于现有技术的物体检测器,在这样的场景中的精确物体检测仍然是具有挑战性的前沿。我们提出了一种新颖的,基于深度学习的精确物体检测方法,专为此类挑战性设置而设计。我们的贡献包括1层用于估计Jaccard指数作为检测质量得分2的新型EM合并单元,它使用我们的质量得分最终解决检测重叠模糊度,3广泛的注释数据集,数据集,代表包装零售环境,在如此极端的环境下发布用于培训和测试。对CARPK和PUCPR的数据集和计数测试的检测测试显示我们的方法优于现有技术水平,具有相当大的利润。代码和数据将在www.github.com上提供,例如,4000 SKU110K CVPR19。 |
| Deep, spatially coherent Inverse Sensor Models with Uncertainty Incorporation using the evidential Framework Authors Daniel Bauer, Lars Kuhnert, Lutz Eckstein 为了执行高速任务,自动驾驶汽车的传感器必须在尽可能少的时间步骤中提供尽可能多的信息。然而,雷达是自主汽车严重依赖的传感器模式之一,通常只能提供稀疏,嘈杂的探测。这些必须随着时间积累,以达到对环境静态部分足够高的信心。对于雷达,通常通过累积反向检测模型IDM来估计状态。我们采用最近提出的证据卷积神经网络,与IDM相比,它计算环境状态的密集,空间相干推断。此外,这些网络能够以原理方式结合传感器噪声,我们进一步扩展到也包含模型不确定性。我们提出的实验结果表明,这可以在更少的时间步骤中获得更密集的环境感知。 |
| Thyroid Cancer Malignancy Prediction From Whole Slide Cytopathology Images Authors David Dov, Shahar Kovalsky, Jonathan Cohen, Danielle Range, Ricardo Henao, Lawrence Carin 我们考虑基于超高分辨率全幻灯片细胞病理学图像的术前甲状腺癌预测。受人类专家如何进行诊断的启发,我们的方法首先识别并分类包含信息性甲状腺细胞的诊断图像区域,其仅占整个图像的一小部分。然后将这些局部估计汇总成甲状腺恶性肿瘤的单一预测。甲状腺细胞病理学的几个独特特征指导我们基于深度学习的方法。虽然我们的方法与多实例学习密切相关,但它通过使用监督程序来提取诊断相关区域而偏离这些方法。此外,我们建议同时预测甲状腺恶性肿瘤,以及人类专家指定的诊断评分,这进一步使我们能够设计出改进的培训策略。实验结果表明,该算法实现了与人类专家相媲美的性能,并证明了该算法用于筛选的潜力,并作为改进不确定病例诊断的辅助工具。 |
| Learning More with Less: GAN-based Medical Image Augmentation Authors Changhee Han, Kohei Murao, Shin ichi Satoh, Hideki Nakayama 使用卷积神经网络进行准确的计算机辅助诊断CNN需要大规模注释的训练数据,与专家医生相关的耗时劳动因此,使用生成性对抗网络GAN的数据增强DA在医学成像中是必不可少的,因为它们可以合成额外的注释训练数据来处理小的来自各种扫描仪的碎片化医学图像这些图像是真实的但与原始图像完全不同,填补了真实图像分布中缺乏的数据。作为教程,本文基于我们的实证经验和相关工作,介绍了基于GAN的医学图像增强的背景,以及使用它们实现高分类对象检测分割性能的技巧。此外,我们使用自动边界框注释显示我们的第一个基于GAN的DA工作,用于在256 x 256 MR图像上进行基于CNN的强大脑转移检测基于GAN的DA可以在诊断中提高10个敏感度,临床上可接受的额外假阳性,即使是高度粗糙和不一致的边界框。 |
| Depth-Aware Video Frame Interpolation Authors Wenbo Bao, Wei Sheng Lai, Chao Ma, Xiaoyun Zhang, Zhiyong Gao, Ming Hsuan Yang 视频帧插值旨在合成原始帧之间不存在的帧。虽然最近的深度卷积神经网络已经取得了显着进步,但是由于大的物体运动或遮挡,插值的质量通常会降低。在这项工作中,我们提出了一种视频帧插值方法,通过探索深度信息明确地检测遮挡。具体来说,我们开发了一种深度感知流动投影层来合成中间流,这些中间流优选地采样比更远的物体更近的物体。此外,我们学习分层功能以从相邻像素收集上下文信息。然后,所提出的模型基于用于合成输出帧的光流和局部插值核来扭曲输入帧,深度图和上下文特征。我们的模型紧凑,高效,完全可分。定量和定性结果表明,所提出的模型对于各种数据集上的现有技术帧插值方法表现良好。 |
| Training Object Detectors on Synthetic Images Containing Reflecting Materials Authors Sebastian Hartwig, Timo Ropinski 深度学习的一大挑战是需要获得大型标记的训练数据集。虽然可以使用合成数据集来克服这一挑战,但重要的是这些数据集关闭实际间隙,即,在合成图像数据上训练的模型能够推广到真实图像。然而,在几个应用场景中可以考虑将现实差距联系起来,对包含反射材料的合成图像进行培训需要进一步研究。由于具有反射材料的物体的出现受到周围环境的支配,因此在训练数据生成期间需要考虑这种相互作用。因此,在本文中,我们研究了在用于训练物体探测器的合成图像生成的背景下反射材料的效果。我们研究了用于图像合成的渲染方法的影响,域随机化的影响,以及使用的训练数据量。为了能够将我们的结果与现有技术进行比较,我们将重点放在室内场景上,因为它们已被广泛研究。在这种情况下,浴室家具是具有反射材料的物体的自然选择,我们在其中报告我们对真实和合成测试数据的发现。 |
| COCO\_TS Dataset: Pixel--level Annotations Based on Weak Supervision for Scene Text Segmentation Authors Simone Bonechi, Paolo Andreini, Monica Bianchini, Franco Scarselli 缺少具有像素级监督的大规模数据集是用于训练用于场景文本分割的深度卷积网络的重要障碍。因此,通常采用合成数据生成来扩大训练数据集。尽管如此,合成数据无法再现自然图像的复杂性和可变性。在本文中,弱监督学习方法用于减少实际和合成数据培训之间的转换。用于文本检测数据集的像素级别监督,即仅有边界框注释可用的地方被生成。特别地,创建并发布COCO文本分段COCO TS数据集,其为COCO文本数据集提供像素级监督。生成的注释用于训练深度卷积神经网络以进行语义分割。实验表明,可以使用所提出的数据集代替合成数据,这使我们只能使用一小部分训练样本并显着提高性能。 |
| DeepPoint3D: Learning Discriminative Local Descriptors using Deep Metric Learning on 3D Point Clouds Authors Siddharth Srivastava, Brejesh Lall 学习局部描述符是计算机视觉中的一个重要问题。虽然有许多技术用于学习2D图像的局部补丁描述符,但是最近已经努力学习3D点的局部描述符。最近在3D中解决该问题的进展利用了基于图像的卷积神经网络的强特征表示能力,利用RGB D或多视图表示。然而,在本文中,我们建议通过直接处理非结构化3D点云来学习3D局部描述符,而无需任何中间表示。该方法构成用于学习3D点的排列不变表示的深度网络。为了学习局部描述符,我们使用多边缘对比损失来区分表面上的相似点和不相似点,同时还利用训练时负样本之间的不相似程度。通过对强基线的综合评估,我们证明了所提出的方法优于3D点云中匹配点的最先进方法。此外,我们证明了所提出的方法对实现最新结果的各种应用的有效性。 |
| k-Same-Siamese-GAN: k-Same Algorithm with Generative Adversarial Network for Facial Image De-identification with Hyperparameter Tuning and Mixed Precision Training Authors Yi Lun Pan, Min Jhih Haung, Kuo Teng Ding, Ja Ling Wu, Jyh Shing Jang 近年来,相机和计算硬件的进步使得捕获和存储大量图像和视频数据变得容易。考虑拥有私人收集的个人数据的数据持有者,例如医院或政府实体。然后,我们如何确保数据持有者确实隐藏了个人数据图像中每个人的身份,同时在识别后仍然保留了数据的某些有用方面在这项工作中,我们提出了一种新的高分辨率面部图像方法de识别,称为k相同的Siamese GAN kSS GAN,它利用k相同匿名机制,生成性对抗网络GAN和超参数调整。为了加速训练和减少内存消耗,混合精确训练MPT技术也被应用于使kSS GAN提供关于密切形式身份的隐私保护的保证并且也被更有效地训练。最后,我们将系统专用于实际数据集RafD数据集以进行性能测试。除了保护高分辨率面部图像的隐私之外,所提出的系统还因其自动化参数调整和突破可调参数数量的限制的能力而被证明是合理的。 |
| Understanding Unconventional Preprocessors in Deep Convolutional Neural Networks for Face Identification Authors Chollette C. Olisah, Lyndon Smith 深度网络在对象和人脸识别等应用领域取得了巨大成功。性能增益归因于网络架构的不同方面,例如卷积层的深度,激活功能,池化,批量归一化,前向和后向传播等等。但是,很少强调预处理器。因此,在本文中,网络的预处理模块在不同的预处理方法中变化,同时保持网络体系结构的其他方面不变,以研究预处理对网络的贡献。常用的预处理器是数据增强和标准化,被称为传统预处理器。其他被称为非常规预处理器,它们是颜色空间转换器HSV,CIE L ab和YCBCR,灰度分辨率预处理器全基于和基于平面的图像量化,照明归一化和使用直方图均衡HE的不敏感特征预处理,局部对比度归一化LN和完整面结构模式CFSP。为了实现固定网络参数,采用具有转移学习的CNN。来自Inception V3网络的高级特征向量的知识被传送到离线预处理的LFW目标数据和使用SoftMax分类器训练的用于面部识别的特征。实验表明,在将数据馈送到CNN之前,通过HE,基于全基和基于平面的量化,rgbGELog和YCBCR预处理器预处理RGB数据,可以提高深度网络的判别能力。但是,为了获得最佳性能,需要使用扩充和/或标准化来正确设置预处理数据。发现基于平面的图像量化增加邻域像素的均匀性并利用减小的比特深度以获得更好的存储效率。 |
| Tightness-aware Evaluation Protocol for Scene Text Detection Authors Yuliang Liu, Lianwen Jin, Zecheng Xie, Canjie Luo, Shuaitao Zhang, Lele Xie 评估协议在文本检测方法的发展过程中起着关键作用。有严格的要求,以确保评估方法公平,客观和合理。然而,现有的指标显示出一些明显的缺点1它们不是面向目标2它们无法识别检测方法的紧密性3现有的一对多和多对一解决方案涉及固有的漏洞和缺陷。因此,本文提出了一种新的评估协议,称为Tightness aware Intersect over Union TIoU metric,可以量化地面实况的完整性,检测的紧凑性和匹配度的紧密性。具体而言,不是仅仅使用IoU值,而是同时适当地考虑两种常见的检测行为,直接使用TIoU的得分来识别紧密度。此外,我们进一步提出了一种简单的方法来解决注释粒度问题,它可以同时公平地评估单词和文本行检测。通过采用已发布方法和一般目标检测框架的检测结果,对ICDAR 2013和ICDAR 2015数据集进行了全面实验,以比较最近的指标和建议的TIoU指标。该比较展示了一些有希望的新前景,例如,确定检测更严格且更有益于识别的方法和框架。我们的方法非常简单,但新颖之处莫过于提议的度量标准可以利用最简单但合理的改进来产生许多有趣且富有洞察力的前景并解决以前指标的大部分问题。该代码可在以下网站公开获取 |
| Cursive Overlapped Character Segmentation: An Enhanced Approach Authors Amjad Rehman 高度倾斜和水平重叠字符的分割是一个具有挑战性的研究领域,仍然是新鲜的。在现有技术中报道了几种技术,但是对于高度倾斜的字符分割产生低精度并且导致整体低的手写识别精度。因此,本文提出了一种简单而有效的方法,用于在不使用任何倾斜校正技术的情况下对这种难以倾斜的草书单词进行字符分割。相反,引入了核心区域的新概念来分割这种难以倾斜的手写单词。然而,由于草书词的固有性质,很少有字符过度分割,因此,启发式地选择阈值来克服该问题。为了公平比较,从IAM基准数据库中提取难以理解的单词。由此进行的实验表现出有希望的结果和高速。 |
| Retinal OCT disease classification with variational autoencoder regularization Authors Max Heinrich Laves, Sontje Ihler, L der A. Kahrs, Tobias Ortmaier 据世界卫生组织统计,全球有2.85亿人患有视力障碍。眼科诊断中最常用的成像技术是光学相干断层扫描OCT。然而,视网膜OCT的分析需要经过培训的眼科医生和时间,不太可能进行全面的早期诊断。最近的一项研究建立了一种基于卷积神经网络CNN的诊断工具,该工具在大型视网膜OCT图像数据库上进行了训练。该工具在视网膜状况分类中的表现与训练有素的医学专家相当。然而,这些网络的训练基于大量标记数据,这是昂贵且难以获得的。因此,本文描述了一种基于变分自编码器正则化的方法,该方法在使用有限数量的标记数据时提高了分类性能。这项工作使用双路径CNN模型,将分类网络与自动编码器AE相结合,进行正则化。这背后的关键思想是在使用有限的训练数据集大小和少数患者时防止过度拟合。结果表明,与预训练和完全微调的基线ResNet 34相比,分类性能更优越。潜在空间与疾病类别的聚类是截然不同的。用于在OCT上进行疾病分类的神经网络可以在使用有限量的患者数据训练时使用变分自动编码器进行正则化。特别是在医学成像领域,由专家注释的数据获得的成本很高。 |
| CUSUM Filter for Brain Segmentation on DSC Perfusion MR Head Scans with Abnormal Brain Anatomy Authors Svitlana Alkhimova 本文提出了一种新的方法,用于相对准确的大脑感兴趣区域ROI检测动态磁敏度对比DSC灌注磁共振MR图像的人头部异常脑解剖。这样的图像产生自动脑分割算法的问题,结果,不良的灌注ROI检测影响定量测量和灌注数据的视觉评估。在所提出的方法中,图像分割基于CUSUM滤波器使用,其适于适用于处理DSC灌注MR图像。分割的结果是通过使用脑边界位置产生的脑ROI的二元掩模。通过CUSUM滤波器检测脑和周围组织之间的边界的每个点作为变化点。建议采用的CUSUM滤波器通过累积在轨迹上移动时观察到的和预期的图像点强度之间的偏差来操作。通过背景区域内的运动方向的迭代变化来创建运动轨迹以便到达脑区域,并且在边界交叉之后反之亦然。使用Dice指数评估所提出的分割方法,将获得的结果与参考标准进行比较。手动标记的脑区像素参考标准,以及用CUSUM过滤器使用脑ROI检测的视觉检查,由经验丰富的放射科医师提供。结果表明,所提出的方法适用于脑部解剖结构异常的人头部DSC灌注MR图像的脑ROI检测,因此可应用于DSC灌注数据分析。 |
| Improved Dynamic Time Warping (DTW) Approach for Online Signature Verification Authors Azhar Ahmad Jaini, Ghazali Sulong, Amjad Rehman 在线签名验证是验证通常从基于平板电脑的设备获得的时间序列签名数据的过程。与离线签名图像不同,在线签名图像数据由按时间顺序排列的点组成。这项研究的目的是开发一种改进的方法来映射测试和参考签名中的笔画。当前的方法利用动态时间扭曲DTW算法及其变体在比较它们的每个数据维度之前对它们进行分段。本文提出了一种改进的DTW算法,其中提出的Lost Box恢复算法旨在提高在线签名验证的映射性能 |
| Implementation of Fruits Recognition Classifier using Convolutional Neural Network Algorithm for Observation of Accuracies for Various Hidden Layers Authors Shadman Sakib, Zahidun Ashrafi, Md. Abu Bakr Siddique 使用深度卷积神经网络进行水果识别CNN是计算机视觉中最有前途的应用之一。最近,基于深度学习的分类使得从图像中识别成果成为可能。然而,由于复杂性和相似性,水果识别对于称重秤上堆积的水果仍然是一个问题。本文提出了一种利用CNN的水果识别系统。所提出的方法使用深度学习技术进行分类。我们使用Fruits 360数据集进行评估。从数据集中,我们建立了一个数据集,其中包含来自25个不同类别的17,823个图像。图像分为训练和测试数据集。此外,对于分类精度,我们对不同的情况使用了隐藏层和时期的各种组合,并对它们进行了比较。还观察到针对不同情况的网络的整体性能损失。最后,我们获得了100的最佳测试精度和99.79的训练精度。 |
| Efficient Incremental Learning for Mobile Object Detection Authors Dawei Li, Serafettin Tasci, Shalini Ghosh, Jingwen Zhu, Junting Zhang, Larry Heck 配备相机的移动设备附带的物体检测模型无法覆盖每个用户感兴趣的物体。因此,增量学习能力是许多应用程序所依赖的健壮且个性化的移动物体检测系统的关键特征。在本文中,我们提出了一个有效但实用的系统IMOD,用于逐步训练现有的对象检测模型,使其能够检测新的对象类而不会失去检测旧类的能力。 IMOD的关键组成部分是一种新颖的增量学习算法,该算法仅使用新对象类的训练数据来训练一阶段对象检测深度模型的端到端。具体来说,为了避免灾难性遗忘,该算法从旧模型中提取出三种类型的知识,以模仿旧模型在对象分类,边界框回归和特征提取上的行为。此外,由于新类别的训练数据可能不可用,因此设计实时数据集构建管道以在运行中收集训练图像并使用类别和边界框注释自动标记图像。我们在移动云和仅移动设备下实施了IMOD。实验结果表明,所提出的系统可以在短短几分钟内学会检测新的对象类,包括数据集构建和模型训练。相比之下,传统的基于微调的方法可能需要几个小时进行培训,并且在大多数情况下还需要繁琐且昂贵的手动数据集标记步骤。 |
| Cross-modal subspace learning with Kernel correlation maximization and Discriminative structure preserving Authors Jun Yu, Xiao Jun Wu 异构数据之间的度量仍然是一个悬而未决的问题。已经开发了许多研究工作来学习可以计算不同模态之间的相似性的共同子空间。然而,现有的大部分工作都集中在学习低维子空间,忽略了在减小维度过程中判别信息的丢失。因此,这些方法无法获得预期的结果。基于希尔伯特空间理论,其中不同的希尔伯特空间但具有相同的维度是同构的,我们提出了一种新的框架,其中标签信息的多次使用可以促进更多的判别子空间表示,以学习每个模态的同构希尔伯特空间。我们的模型不仅通过最大化核相关来考虑模态间相关性,而且还根据构建的图模型保留每个模态内的结构信息。进行了大量实验以评估所提出的框架,在三个公共数据集上评估具有核相关最大化的交叉模态子空间学习和保留CKD的判别结构。实验结果证明了与经典子空间学习方法相比,所提出的CKD的竞争性能。 |
| Deep Demosaicing for Edge Implementation Authors Ramchalam Kinattinkara Ramakrishnan, Jui Shangling, Vahid Patrovi Nia 大多数数码相机使用涂有彩色滤光片阵列CFA的传感器来捕捉每个像素位置的通道分量,从而产生不包含所有通道中像素值的马赛克图像。目前关于重建这些缺失通道的研究,也称为去马赛克,引入了许多伪像,例如拉链效应和假色。许多深度学习去马赛克技术在减少伪影的影响方面优于其他经典技术。但是,大多数这些模型往往过度参数化。因此,在低端边缘设备上基于深度学习的基于深度学习的去马赛克算法的边缘实现是主要挑战。我们提供了对深度神经网络架构的详尽搜索,并获得了颜色峰值信噪比CPSNR的帕累托前沿作为性能标准,而不是作为模型复杂性的参数数量,超越了现有技术水平。然后可以使用帕累托前沿的架构为各种资源约束选择最佳架构。简单的体系结构搜索方法,例如穷举搜索和网格搜索,需要一些损失函数的条件收敛到最优。我们在简短的理论研究中阐明了这些条件。 |
| Concatenated Feature Pyramid Network for Instance Segmentation Authors Yongqing Sun, Pranav Shenoy K P, Jun Shimamura, Atsushi Sagata 边缘和纹理等低级特征在精确定位神经网络中的实例方面发挥着重要作用。在本文中,我们提出了一种体系结构,该体系结构通过在金字塔的所有层中以最佳和有效的方式结合低级特征来改进通常使用的实例分割网络的特征金字塔网络。具体来说,我们引入了一个新的层,它从整体上从多个特征金字塔等级的特征图中学习新的相关性,并增强特征金字塔的语义信息以提高准确性。我们的架构很容易在实例分段或对象检测框架中实现,以提高准确性。在Mask RCNN中使用此方法,与原始特征金字塔网络相比,我们的模型在COCO数据集上实现了精确度的一致性提高和计算开销。 |
| Boosted Attention: Leveraging Human Attention for Image Captioning Authors Shi Chen, Qi Zhao 视觉注意已经在图像字幕中显示出有用性,其目的是使字幕模型能够选择性地关注感兴趣的区域。现有模型通常依赖自上而下的语言信息,并通过优化字幕目标来隐含地学习注意力。虽然有些有效,但学习到的自上而下的注意力可能无法在没有直接监督注意力的情况下关注正确的感兴趣区域受人类视觉系统启发,不仅由任务特定的自上而下信号而且还有视觉刺激驱动,我们在这项工作中建议使用两种类型的注意力来进行图像字幕。特别是,我们强调两种类型的关注的互补性,并开发一个模型Boosted Attention,将它们整合到图像字幕中。我们使用各种评估指标的最新性能来验证所提出的方法。 |
| A Weighted Multi-Criteria Decision Making Approach for Image Captioning Authors Hassan Maleki Galandouz, Mohsen Ebrahimi Moghaddam, Mehrnoush Shamsfard 图像字幕旨在以自然语言自动生成图像的描述。这是人工智能领域中的一个具有挑战性的问题,最近在计算机视觉和自然语言处理中受到了极大的关注。在现有方法中,基于视觉检索的方法已被证明是非常有效的。这些方法搜索相似的图像,然后基于检索到的图像的标题为查询图像构建标题。在本研究中,我们提出了一种基于图像字幕的视觉检索方法,其中我们使用多标准决策算法有效地将几个标准与比例影响权重相结合,以检索查询图像的最相关标题。所提出的方法的主要思想是设计一种机制,用查询图像检索更多语义相关的标题,然后通过基于加权多标准决策算法模仿人类行为来选择最合适的标题。在MS COCO基准数据集上进行的实验表明,与现有技术模型相比,通过使用具有比例冲击权重的标准,所提出的方法提供了更有效的结果。 |
| Non-rigid 3D shape retrieval based on multi-view metric learning Authors Haohao Li, Shengfa Wang, Nannan Li, Zhixun Su, Ximin Liu 本研究提出了一种新颖的多视图度量学习算法,旨在改善三维非刚性形状检索。随着非刚性三维形状分析的发展,存在许多形状描述符。可以探索内在描述符来构造非刚性3D形状检索任务的各种内在表示。不同的内在表征特征集中在不同的几何属性上以描述相同的3D形状,这使得表示是相关的。因此,有可能并且有必要共同学习不同表示的多个度量。我们提出了一种有效的多视图度量学习算法,将边际Fisher分析MFA扩展到多视图域,并将Hilbert Schmidt独立准则HSCI作为一个多样性项来共同学习新的度量。我们的方法可以通过MFA分隔不同的类。同时,HSCI被利用来使多种表示达成共识。学习的度量可以减少多个表示之间的冗余,并提高检索结果的准确性。在SHREC 10基准测试中进行了实验,结果表明该方法优于现有技术的非刚性3D形状检索方法。 |
| 3D human action analysis and recognition through GLAC descriptor on 2D motion and static posture images Authors Mohammad Farhad Bulbul, Saiful Islam, Hazrat Ali 在本文中,我们提出了一种识别深度动作视频中的动作的方法。首先,我们处理视频以基于3D运动轨迹模型3DMTM的使用获得对应于动作视频的运动历史图像MHI和静态历史图像SHI。然后,我们通过从SHI和MHI中提取梯度局部自动关联GLAC特征来表征动作视频。将来自SHI的两组特征(即来自MHI的GLAC特征和来自SHI的GLAC特征)连接起来以获得用于动作的表示向量。最后,我们通过使用l2正则化的协同表示分类器12 CRC来对所有动作样本进行分类,以有效地识别不同的人类行为。我们对三个动作数据集MSR Action3D,DHA和UTD MHAD进行了所提方法的评估。通过实验结果,我们观察到所提出的方法优于其他方法。 |
| Part-based approximations for morphological operators using asymmetric auto-encoders Authors Bastien Ponchon CMM, LTCI , Santiago Velasco Forero CMM , Samy Blusseau CMM , Jesus Angulo CMM , Isabelle Bloch LTCI 本文讨论了构建基于部件的图像数据集表示的问题。更确切地说,我们寻找在减少的原子集上的图像的非负的,稀疏的分解,以便揭示数据的形态学和可解释的结构。此外,我们希望在线计算任何不属于初始数据集的新样本的分解。因此,我们的解决方案依赖于稀疏的非负自动编码器,其中编码器的精度很高,而解码器的解释性很浅。该方法与两个数据集MNIST和Fashion MNIST的现有技术在线方法相比,根据经典度量和我们引入的新方法,基于表现形态扩张的不变性,有利地进行了比较。 |
| Approximating CNNs with Bag-of-local-Features models works surprisingly well on ImageNet Authors Wieland Brendel, Matthias Bethge 深度神经网络DNN在许多复杂的感知任务方面表现出色,但众所周知,很难理解他们如何做出决策。我们在此介绍ImageNet上的高性能DNN架构,其决策更容易解释。我们的模型是ResNet 50架构的简单变体,称为BagNet,它基于小局部图像特征的出现对图像进行分类,而不考虑它们的空间排序。这种策略与在深度学习开始之前流行的特征BoF模型密切相关,并且在ImageNet 87.6前5中获得了令人惊讶的高精度,33 x 33 px功能和Alexnet性能为17 x 17 px功能。对局部特征的约束使得可以直接分析图像的每个部分如何影响分类。此外,BagNets在特征灵敏度,误差分布和图像部分之间的相互作用方面表现类似于现有技术的深度神经网络,例如VGG 16,ResNet 152或DenseNet 169。这表明DNN在过去几年中对先前的特征分类器的改进主要通过更好的微调而不是通过质量上不同的决策策略来实现。 |
| Adversarial camera stickers: A Physical Camera Attack on Deep Learning Classifier Authors Juncheng B. Li, Frank R. Schmidt, J. Zico Kolter 最近的工作已经彻底记录了深度学习系统对对抗性示例的敏感性,但大多数此类实例直接操纵数字输入到分类器。尽管较小的工作系列考虑了物理对抗性攻击,但在所有情况下,这些涉及操纵感兴趣的对象,例如,在物体上放置物理标签以对其进行错误分类,或者制造专门用于错误分类的物体。在这项工作中,我们考虑另一个问题是,可以通过物理操纵相机本身来欺骗深度分类器,超过所有感知到的某种类型的物体。我们表明这确实是可行的,通过精心制作且主要是半透明的贴纸在相机的镜头上,人们可以创建观察到的图像的普遍扰动,这些扰动是不显眼的,但是可靠地将目标物体错误分类为不同的目标类别。为了实现这一点,我们提出了一个迭代过程,用于更新攻击扰动以使其对于给定分类器具有对抗性,以及威胁模型本身以确保其在物理上可实现。例如,我们展示了我们可以实现物理上可实现的攻击,这些攻击在49.6的时间内以有针对性的方式欺骗ImageNet分类器。这提供了一种新的可物理实现的威胁模型,可以在对抗性强大的机器学习环境中考虑。链接到我们的演示视频 |
| Value of Temporal Dynamics Information in Driving Scene Segmentation Authors Li Ding, Jack Terwilliger, Rini Sherony, Bryan Reimer, Lex Fridman 语义场景分割主要通过用监督和非监督方法形成单个图像的表示来解决。动态场景中的语义分割问题最近开始受到视频对象分割方法的关注。未知的是视觉场景的时间动态携带多少额外信息,这些信息与视频的各个帧中可用的信息互补。有证据表明,人类视觉系统可以从场景的时间动态信息中有效地感知场景,改变视觉特征,而不依赖于各个快照本身的视觉特征。我们的工作采取步骤,通过在联合学习问题中结合基于外观的表示和时间动态表示来探索机器感知是否可以表现出相似的属性,该问题揭示了每个对成功的动态场景分割的贡献。此外,我们还提供MIT驾驶场景分割数据集,这是一个大型全驱动场景分割数据集,为每个像素和5,000个视频帧中的每一个密集注释。该数据集旨在帮助进一步探索视频中语义分割的时间动态信息的价值。 |
| A Novel Pixel-Averaging Technique for Extracting Training Data from a Single Image, Used in ML-Based Image Enlargement Authors Amir Rastar 训练数据集的大小是机器学习算法性能的重要因素,医学图像处理中使用的工具也不例外。机器学习工具通常需要大量的训练数据才能有效预测目标。对于图像处理和计算机视觉,图像的数量决定了训练集的有效性和可靠性。在某些情况下,医学图像会受到质量差和适当训练集所需数量不足的影响。本研究中提出的算法通过从单个图像中提取所需数据,消除了对基于机器学习的图像放大技术中使用的大或甚至小图像数据集的需要。然后将提取的数据引入决策树回归器,用于以不同的缩放级别放大灰度医学图像。与第三方应用相比,该算法的结果相对可接受,并且有望用于未来的研究。该技术可以根据其他机器学习工具的要求进行定制,并且可以通过进一步调整工具超参数来改进结果。 |
| Mutual Linear Regression-based Discrete Hashing Authors Xingbo Liu, Xiushan Nie, Yilong Yin 标签信息因其提高精度的有效性而广泛用于散列方法。现有的散列方法总是使用两个不同的投影来表示散列码和类标签之间的相互回归。与现有方法相比,我们提出了一种新的基于学习的散列方法,在本研究中称为稳定监督离散散列和互线性回归S2DHMLR,其中只有一个稳定投影用于描述哈希码与相应标签之间的线性相关性。据我们所知,此策略以前没有用于散列。此外,我们进一步使用提升策略来提高所提方法的最终性能,而不会增加额外的约束,并且在时间和空间方面几乎没有额外的支出。在三个图像基准上进行的大量实验证明了所提出方法的优越性能。 |
| A smartphone application to detection and classification of coffee leaf miner and coffee leaf rust Authors Giuliano L. Manso, Helder Knidel, Renato A. Krohling, Jose A. Ventura 通常,植物疾病和/或害虫的鉴定和分类由专家进行。巴西咖啡农面临的问题之一是作物侵染,尤其是叶锈病Hemileia vastatrix和叶子矿工Leucoptera coffeella。疾病和/或害虫的进展在空间和暂时发生。因此,自动识别严重程度非常重要。本文的主要目标是开发一种方法及其作为应用程序的实现,允许检测使用智能手机捕获的咖啡叶图像的叶面损害,并确定它是生锈还是叶子采矿者,反过来计算其严重程度。该方法包括从图像中识别叶子并使用分割算法将其与背景分离。在分割过程中,测试使用HSV和YCbCr颜色空间的图像的各种类型的背景。在叶面损伤的分割中,使用了YCgCr颜色空间中的Otsu算法和迭代阈值算法,并与k均值进行了比较。接下来,计算分段叶面损伤的特征。对于分类,已经使用了用极端学习机训练的人工神经网络。获得的结果显示了该方法的可行性和有效性,以确定和分类叶面损伤,并自动计算严重程度。据专家介绍,所取得的成果非常有希望。 |
| Fashion Outfit Generation for E-commerce Authors Elaine M. Bettaney, Stephen R. Hardwick, Odysseas Zisimopoulos, Benjamin Paul Chamberlain 将服装组合成服装是时装零售的主要任务。推荐与特定种子项目兼容的项目集合对于向用户提供指导和灵感是有用的,但是目前是需要专业造型师的手动过程,因此不具有可扩展性或易于个性化。我们使用由视觉和文本特征馈送的多层神经网络来学习潜在风格空间中的项目嵌入,使得不同类型的兼容项目彼此紧密地嵌入。我们使用ASOS服装数据集训练我们的模型,该数据集由专业造型师创建的大量服装组成,并且我们将其发布给研究社区。我们的模型在离线装备兼容性预测任务中表现出强大的性能。我们使用我们的模型来生成服装,并且在该领域中第一次执行AB测试,将我们生成的服装与基线模型生成的服装进行比较,该模型匹配适当的产品类型但不使用样式信息。我们的模型21和34产生的服装批准的用户分别比女装和男装的基线模型生成的服装更频繁。 |
| Projectron -- A Shallow and Interpretable Network for Classifying Medical Images Authors Aditya Sriram, Shivam Kalra, H.R. Tizhoosh 本文介绍了Projectron作为一种新的神经网络结构,它使用Radon投影来分类和表示医学图像。动机是建立在医学成像领域更易解释的浅网络。 Radon变换是一种既定技术,可以从平行投影重建图像。 Projectron首先使用等距角对每个图像应用全局Radon变换,然后将这些变换馈送到单层神经元,然后是一层合适的内核,以促进投影的线性分离。最后,Projectron将编码输出作为输入提供给另外两层进行最终分类。我们在五个公开可用的数据集上验证了Projectron,一般数据集即MNIST和四个医疗数据集,即肺气肿,IDC,IRMA和肺炎。结果令人鼓舞,因为我们将投影仪的性能与原始图像和氡投影分别作为输入进行了比较。实验清楚地证明了所提出的Projectron用于表示医学图像分类的潜力。 |
| The Sixth Sense with Artificial Intelligence: An Innovative Solution for Real-Time Retrieval of the Human Figure Behind Visual Obstruction Authors Kevin Meng, Yu Meng 克服视觉障碍,发展视野,是人类长期以来的梦想之一。然而,可见光不能穿过不透明的障碍物,例如墙壁。然而,与可见光不同,射频RF信号穿透许多常见的建筑物并且高度反射人类。该项目创造了一种突破性的人工智能方法,通过该方法,即使通过视觉遮挡,也可以利用RF重建人的骨骼结构。在新颖的程序流程中,首先使用包含RGB相机和RF天线阵列收发器的共同设置同时收集视频和RF数据。接下来,使用Part Affinity Field计算机视觉模型处理RGB视频,以生成人体骨骼中每个关键点的地面实况标签位置。然后,由残余卷积神经网络,区域提议网络和递归神经网络1组成的集体深度学习模型从RF图像中提取空间特征,2检测并裁剪出场景中的所有人,并且3个聚合信息。时间步骤拼凑在不同时间将信号反射回接收器的各种肢体。创建模拟器以演示系统。该项目在医学,军事,搜索救援和机器人技术方面具有重要的应用。特别是在火灾紧急情况下,可见光和红外热成像都不能穿透烟雾或火灾,但RF可以。美国每年报告的火灾超过100万次,这项技术可以挽救数千人的生命和成千上万的伤害。 |
| Semantic Nearest Neighbor Fields Monocular Edge Visual-Odometry Authors Xiaolong Wu, Assia Benbihi, Antoine Richard, Cedric Pradalier 边缘检测和分割的深度学习的最新进展为基于语义边缘的自我运动估计开辟了新的途径。在这项工作中,我们提出了一个强大的单眼视觉测距VO框架使用类别感知语义边缘。它可以在具有挑战性的室外环境中重建大规模语义地图。我们的方法的核心是语义最近邻域,其使用语义促进跨帧的边缘的鲁棒数据关联。这在跟踪阶段期间显着地扩大了会聚半径。所提出的边缘配准方法可以容易地集成到直接VO框架中,以估计光度,几何和语义上一致的相机运动。评估不同类型的边缘,并且广泛的实验证明我们提出的系统优于现有技术的间接,直接和语义单眼VO系统。 |
| Unsupervised Concatenation Hashing with Sparse Constraint for Cross-Modal Retrieval Authors Jun Yu, Xiao Jun Wu 哈希学习具有存储成本低,效率高的优点,在检索领域备受关注。由于在语义上表示共同对象的多个模态数据是互补的,因此许多工作集中于学习统一二进制代码。然而,这些工作忽略了数据之间多种结构的重要性。实际上,直接保留汉明空间中样本之间的局部流形结构仍然是一个有趣的问题。由于不同的模态是异构的,我们采用多模态特征的级联特征来表示原始对象。在我们的框架中,引入了局部线性嵌入和局部保持投影来重建汉明空间中原始空间的流形结构。此外,L21范数正则化被强加于投影矩阵,以进一步同时利用不同模态的判别特征。在三个公开可用的数据集上进行了广泛的实验以评估所提出的方法,称为无监督级联散列UCH,并且实验结果表明UCH的优越性能优于大多数现有技术的无监督散列模型。 |
| GAN You Do the GAN GAN? Authors Joseph Suarez 生成性对抗网络GAN已成为生成模型的主导类。近年来,GAN变体在合成各种形式的数据方面取得了特别令人印象深刻的结果。示例包括引人注目的自然和艺术图像,纹理,音乐序列和3D对象文件。然而,缺少一个明显的合成候选者。在这项工作中,我们回答了一个深度学习最紧迫的问题GAN你做GAN GAN那就是,是否可以训练GAN来模拟GAN的分布我们在MIT许可下发布该项目的完整源代码。 |
| JSIS3D: Joint Semantic-Instance Segmentation of 3D Point Clouds with Multi-Task Pointwise Networks and Multi-Value Conditional Random Fields Authors Quang Hieu Pham, Duc Thanh Nguyen, Binh Son Hua, Gemma Roig, Sai Kit Yeung 深度学习技术已成为2D图像上大多数视觉相关任务的模型。然而,它们的功率尚未完全实现在3D空间中的若干任务上,例如3D场景理解。在这项工作中,我们共同解决了3D点云的语义和实例分割问题。具体来说,我们开发了一个多任务逐点网络,它同时执行两个任务,预测3D点的语义类,并将这些点嵌入高维向量中,以便相同对象实例的点由类似的嵌入表示。然后,我们提出一种多值条件随机场模型,以结合语义和实例标签,并将语义和实例分割的问题制定为联合优化场模型中的标签。对所提出的方法进行了全面评估,并与包括S3DIS和SceneNN在内的不同室内场景数据集的现有方法进行了比较。实验结果表明,所提出的联合语义实例分割方案在其单个组件上具有鲁棒性。我们的方法也在语义分割上实现了最先进的性能。 |
| Dance with Flow: Two-in-One Stream Action Detection Authors Jiaojiao Zhao, Cees G.M. Snoek 本文的目的是检测动作的时空范围。基于RGB和流的两个流检测网络以大型模型和大量计算为代价提供了现有技术的精确度。我们建议将RGB和光流嵌入到具有新层的单个二合一流网络中。运动条件层从流图像中提取运动信息,其由运动调制层利用以生成用于调制低级RGB特征的变换参数。该方法易于嵌入现有的外观或两个流动作检测网络中,并进行端到端的训练。实验表明,利用运动条件调制RGB特征可提高检测精度。由于只有一半的计算和参数采用最先进的两种流方法,我们的二合一流仍然在UCF101 24,UCFSports和J HMDB上取得了令人印象深刻的结果。 |
| Standardized Assessment of Automatic Segmentation of White Matter Hyperintensities and Results of the WMH Segmentation Challenge Authors Hugo J. Kuijf, J. Matthijs Biesbroek, Jeroen de Bresser, Rutger Heinen, Simon Andermatt, Mariana Bento, Matt Berseth, Mikhail Belyaev, M. Jorge Cardoso, Adri Casamitjana, D. Louis Collins, Mahsa Dadar, Achilleas Georgiou, Mohsen Ghafoorian, Dakai Jin, April Khademi, Jesse Knight, Hongwei Li, Xavier Llad , Miguel Luna, Qaiser Mahmood, Richard McKinley, Alireza Mehrtash, S bastien Ourselin, Bo yong Park, Hyunjin Park, Sang Hyun Park, Simon Pezold, Elodie Puybareau, Leticia Rittner, Carole H. Sudre, Sergi Valverde, Ver nica Vilaplana, Roland Wiest, Yongchao Xu, Ziyue Xu, Guodong Zeng, Jianguo Zhang, Guoyan Zheng, Christopher Chen, Wiesje van der Flier, Frederik Barkhof, Max A. Viergever, Geert Jan Biessels 脑白质高信号量的定量推测血管来源的WMH在许多神经学研究中至关重要。目前,通常仍然从脑MR图像的手动分割获得测量,这是一个费力的过程。存在自动WMH分割方法,但缺乏对这些方法的性能的标准化比较。我们组织了一次科学挑战,开发人员可以在标准化的多中心扫描仪图像数据集上评估他们的方法,对WMH分割挑战进行客观比较 |
| End-to-End Time-Lapse Video Synthesis from a Single Outdoor Image Authors Seonghyeon Nam, Chongyang Ma, Menglei Chai, William Brendel, Ning Xu, Seon Joo Kim 时间流逝视频通常包含视觉上吸引人的内容,但创建起来通常很困难且成本高昂。在本文中,我们提出了一种端到端解决方案,使用深度神经网络从单个室外图像合成时间流逝视频。我们的主要思想是基于时间推移视频和图像序列的现有数据集来训练条件生成对抗网络。我们提出了一种多帧联合条件生成框架,以有效地学习室外场景的照明变化与一天中的时间之间的相关性。我们进一步提出了一个多领域训练方案,用于从具有不同分布和缺失时间戳标签的两个数据集中对我们的生成模型进行稳健训练。与替代时间流逝视频合成算法相比,我们的方法使用时间戳作为控制变量,并且不需要参考视频来指导最终输出的合成。我们进行消融研究以验证我们的算法,并在质量和数量上与现有技术进行比较。 |
| Deep Built-Structure Counting in Satellite Imagery Using Attention Based Re-Weighting Authors Anza Shakeel, Waqas Sultani, Mohsen Ali 在本文中,我们试图解决在卫星图像中计算建筑结构的挑战性问题。与建成区域分割相比,建筑密度可以更准确地估算人口密度,城市面积扩展及其对环境的影响。然而,建立形状差异,重叠边界和变体密度使这成为一项复杂的任务。为了解决这个难题,我们提出了一种基于深度学习的回归技术,用于计算卫星图像中的建筑结构。我们提出的框架使用基于注意力的重新加权技术智能地组合来自卫星图像的不同区域的特征。多个并行卷积网络被设计用于捕获不同颗粒的信息。这些功能与FusionNet相结合,经过培训可以对不同粒度的特征进行不同的称重,使我们能够预测精确的建筑数量。为了训练和评估所提出的方法,我们提出了一个新的大规模和具有挑战性的建筑结构计数数据集。我们的数据集是通过收集来自亚洲,欧洲,北美和非洲的不同地理区域飞机,城市中心,沙漠等的卫星图像而构建的,并捕获了大量建筑结构。详细的实验结果和分析验证了所提出的技术。 FusionNet的平均绝对误差为3.65,测试数据的R平方测量值为88。最后,我们对看不见的地区的274 3 103平方米进行了测试,其中19个建筑物的错误在该地区的656座建筑物之外。 |
| Learning Content-Weighted Deep Image Compression Authors Mu Li, Wangmeng Zuo, Shuhang Gu, Jane You, David Zhang 基于学习的有损图像压缩通常涉及速率失真性能的联合优化。大多数现有方法采用空间不变的比特长度分配并且结合离散熵近似来约束压缩率。尽管如此,信息内容在空间上是变化的,其中具有复杂和显着结构的区域通常对图像压缩更为重要。考虑到图像内容的空间变化,本文提出了一种内容加权编码器解码器模型,它包含一个重要图子网,用于产生局部自适应比特率分配的重要性掩码。因此,重要性掩码的总和因此可以用作压缩率控制的熵估计的替代。此外,学习代码和重要性映射的量化表示仍然是空间相关的,其可以使用算术编码无损压缩。为了有效和高效地压缩代码,我们提出了一个修剪的卷积网络来预测量化代码的条件概率。实验表明,与深度和传统的有损图像压缩方法相比,所提出的方法可以产生视觉上更好的结果,并且表现良好。 |
| Deep Learning for Large-Scale Traffic-Sign Detection and Recognition Authors Domen Tabernik, Danijel Sko aj 交通标志的自动检测和识别在交通标志库存的管理中起着至关重要的作用。它以最少的人力,提供准确,及时的方式来管理交通标志库存。在计算机视觉社区中,交通标志的识别和检测是一个很好的研究问题。绝大多数现有方法在高级驾驶员辅助和自主系统所需的交通标志上表现良好。然而,这代表了几百个类别中约50个类别的所有交通标志中相对较少的数量,并且在剩余的交通标志集上表现,这是消除交通标志库存管理中的手工劳动所必需的,仍然是一个悬而未决的问题。在本文中,我们解决了检测和识别适用于自动化交通标志库存管理的大量交通标志类别的问题。我们采用卷积神经网络CNN方法Mask R CNN,通过自动端到端学习来解决完整的检测和识别流水线。我们提出了几项改进措施,这些改进措施可用于检测交通标志,从而提高整体性能。该方法适用于检测我们的新数据集中表示的200个交通标志类别。结果报告了在以前的工作中尚未考虑的极具挑战性的交通标志类别。我们提供了深度学习方法的综合分析,用于检测具有大的类别外观变化的交通标志,并且使用所提出的方法显示低于3的错误率,这足以部署在交通标志库存管理的实际应用中。 |
| Harvesting Visual Objects from Internet Images via Deep Learning Based Objectness Assessment Authors Kan Wu, Guanbin Li, Haofeng Li, Jianjun Zhang, Yizhou Yu 互联网图像的收集速度惊人地增长。毫无疑问,这些图像包含丰富的视觉信息,可用于许多应用,例如视觉媒体创建和数据驱动图像合成。在本文中,我们关注从一组互联网图像构建可视对象数据库的方法。这样的数据库构建为包含大量高质量的可视对象,可以帮助各种数据驱动的图像应用程序。我们的方法基于密集提议生成和基于对象的重新排序。设计了一种新的深度卷积神经网络,用于推荐提议对象性,提议的概率包含最佳定位的前景对象。在我们的工作中,对象性在完整性和丰满度方面进行了定量测量,反映了最佳提案的两个互补特征,即完整的前景和相对较小的背景。我们的实验表明,根据我们网络的输出重新排列的对象提案通常比其他现有技术方法产生的性能更高。作为具体示例,使用所提出的方法构建了超过120万个可视对象的数据库,并且已经成功地用于各种数据驱动的图像应用。 |
| Single Image Reflection Removal Exploiting Misaligned Training Data and Network Enhancements Authors Kaixuan Wei, Jiaolong Yang, Ying Fu, David Wipf, Hua Huang 从通过玻璃窗捕获的单个图像中去除不期望的反射对于视觉计算系统是实际重要的。尽管在某些情况下,最先进的方法可以获得不错的结果,但在处理更普遍的现实世界案例时,性能会显着下降。这些失败源于单个图像反射去除问题的基本不适应的固有困难,以及在基于学习的神经网络管道中解决这种模糊性所需的密集标记的训练数据的不足。在本文中,我们通过利用有针对性的网络增强和未对齐数据的新颖使用来解决这些问题。对于前者,我们通过嵌入能够利用高级上下文线索的上下文编码模块来增强基线网络架构,以减少包含强反射的区域内的不确定性。对于后者,我们引入了一个对齐不变损失函数,有助于利用更容易收集的未对齐的现实世界训练数据。实验结果共同表明,我们的方法优于对齐数据的现有技术,并且当使用额外的未对齐数据时,可以进行重大改进。 |
| CFSNet: Toward a Controllable Feature Space for Image Restoration Authors Wei Wang, Ruiming Guo, Yapeng Tian, Wenming Yang 深度学习方法见证了图像恢复的巨大进步,具有特定的指标,例如PSNR,SSIM。然而,恢复图像的感知质量是相对主观的,并且用户必须根据个人偏好或图像特征来控制重建结果,这是使用现有确定性网络无法完成的。这促使我们精心设计一个统一的交互式框架,用于一般的图像恢复任务。在该框架下,用户可以控制不同目标的连续转换,例如,图像超分辨率的感知失真折衷,降噪和细节保留之间的折衷。我们通过控制设计网络的潜在功能来实现这一目标。具体而言,我们提出的名为可控特征空间网络CFSNet的框架由两个基于不同目标的分支纠缠在一起。我们的模型可以自适应地学习不同层和通道的耦合系数,从而更好地控制恢复的图像质量。几个典型图像恢复任务的实验充分验证了所提方法的有效益处。 |
| TAN: Temporal Affine Network for Real-Time Left Ventricle Anatomical Structure Analysis Based on 2D Ultrasound Videos Authors Sihong Chen, Kai Ma, Yefeng Zheng 超声心动图具有低成本,便携性和无辐射的优势,是一种广泛用于左心室LV功能量化的成像模式。然而,自动LV分割和运动跟踪仍然是一项具有挑战性的任务。除了模糊边界定义,低对比度和典型超声图像上的丰富伪像之外,LV的形状和大小在心动周期中显着改变。在这项工作中,我们提出了一个时间仿射网络TAN,以在扭曲的图像空间中执行图像分析,其中由于心脏运动以及其他伪像的形状和大小变化在很大程度上得到补偿。此外,我们同时执行三个频繁的超声心动图解释任务标准心脏平面识别,LV标志物检测和LV分割。我们使用多任务网络同时执行三个任务,而不是使用一个专用于每个任务的三个网络。由于三个任务共享相同的编码器,因此紧凑型网络通过更多监督来提高分段准确性。利用光流调整注释进一步微调网络以增强分割结果中的运动相干性。对1,714个二维超声心动图序列的实验表明,所提出的方法以实时效率实现了最先进的分割精度。 |
| Med3D: Transfer Learning for 3D Medical Image Analysis Authors Sihong Chen, Kai Ma, Yefeng Zheng 深度学习的表现受到训练数据量的显着影响。从像ImageNet这样的大量数据集预先训练的模型成为加速训练收敛和提高准确性的有力武器。类似地,基于大数据集的模型对于3D医学图像中的深度学习的发展是重要的。然而,由于3D医学成像中的数据采集和注释的困难,构建足够大的数据集极具挑战性。我们汇总了来自多个医疗挑战的数据集,以构建具有不同模态,目标器官和病理的3DSeg 8数据集。为了提取一般医学三维三维特征,我们设计了一个名为Med3D的异构三维网络来训练多域3DSeg 8,从而制作一系列预训练模型。我们将Med3D预训练模型转移到LIDC数据集中的肺部分割,LIDC数据集中的肺部结节分类和LiTS攻击的肝脏分割。实验表明,与在动力学数据集上预训练的模型相比,Med3D可以将目标3D医疗任务的训练收敛速度提高2倍,与从头开始训练相比提高10倍,并且提高3到20的准确度。将我们的Med3D模型转换为现有技术的DenseASPP分割网络,在单个模型的情况下,我们实现94.6 Dice系数,其接近LiTS挑战的顶级算法的结果。 |
| Video Object Segmentation using Space-Time Memory Networks Authors Seoung Wug Oh, Joon Young Lee, Ning Xu, Seon Joo Kim 我们提出了一种新的半监督视频对象分割解决方案。根据问题的性质,可用提示例如具有对象掩模的视频帧随着中间预测而变得更加丰富。但是,现有方法无法充分利用这种丰富的信息来源。我们通过利用内存网络解决问题,并学习从所有可用来源中读取相关信息。在我们的框架中,具有对象掩码的过去帧形成外部存储器,并且使用存储器中的掩码信息对作为查询的当前帧进行分段。具体地,查询和存储器在特征空间中密集匹配,以前馈方式覆盖所有空时像素位置。与之前的方法相比,大量使用指导信息使我们能够更好地应对外观变化和遮挡等挑战。我们在最新基准测试集上验证了我们的方法,并在Youtube VOS上设置了最先进的性能总分79.4,在DAVIS 2016 2017上设置的J分别为88.7和79.2,而在DAVIS 2016上获得了0.16秒的快速运行时间val set。 |
| Relative Attributing Propagation: Interpreting the Comparative Contributions of Individual Units in Deep Neural Networks Authors Woo Jeoung Nam, Jaesik Choi, Seong Whan Lee 由于深度神经网络DNN已经在许多计算机视觉任务中证明了超人的表现,因此人们越来越关注揭示DNN的复杂内部机制。在本文中,我们提出相对属性传播RAP,它以新的视角分解DNN的输出预测,精确地分离正面和负面的属性。通过识别激活的根本原因和适当的相关性反转,RAP允许为每个神经元分配对输出的实际贡献。此外,我们设计了实用的方法来在归属程序中正确处理偏差和批量归一化的影响。因此,我们的方法可以解释各种非常深的神经网络模型,具有正面和负面归因的清晰和细致的可视化。通过利用区域扰动方法和比较归因分布进行定量评估,我们验证了RAP的正确性,正负归因是否正确地解释了每个含义。 RAP传播的正负归属分别表现出对相应像素失真的脆弱性和鲁棒性特征。我们将RAP应用于DNN模型VGG 16,ResNet 50和Inception V3,与现有归因方法相比,它展示了其更直观和改进的解释。 |
| Learning Combinatorial Embedding Networks for Deep Graph Matching Authors Runzhong Wang, Junchi Yan, Xiaokang Yang 图匹配是指在图之间找到节点对应关系,使得对应的节点和边缘的亲和度可以最大化。除了NP完整性之外,另一个重要的挑战是对图形和结果目标的节点和结构明智的有效建模,以指导匹配过程有效地找到真正的噪声匹配。为此,本文设计了一个端到端的可区分深度网络流水线来学习图匹配的亲和力。它涉及与节点对应关系的监督置换损失,以捕获图匹配的组合性质。同时采用深度图嵌入模型来参数化帧内图和交叉图亲和函数,而不是传统的浅和简单参数形式,例如:高斯核。嵌入还可以有效地捕获超过二阶边缘的更高阶结构。置换损失模型与节点数量无关,并且嵌入模型在节点之间共享,使得网络允许图形中的不同数量的节点用于训练和推断。此外,我们的网络是类不可知的,具有不同类别的一些泛化能力。所有这些功能都受到现实世界的欢迎。实验表明其优于现有技术图匹配学习方法。 |
| ResUNet-a: a deep learning framework for semantic segmentation of remotely sensed data Authors Foivos I. Diakogiannis, Fran ois Waldner, Peter Caccetta, Chen Wu 对高分辨率航拍图像的场景理解对于各种遥感应用中的自动监测任务非常重要。由于类内的较大且感兴趣对象的像素值的类方差较小,这仍然是一项具有挑战性的任务。近年来,深度卷积神经网络已经开始被用于遥感应用并且展示了用于物体的像素级分类的最新性能。在这里,我们提出了一种新颖的深度学习架构ResUNet a,它结合了计算机视觉中用于语义分割任务的各种先进模块的思想。我们分析了几种类型的广义骰子损失对语义分割的表现,并介绍了一种新的变异损失函数,用于对象的语义分割,具有更好的收敛性,即使在高度不平衡的类存在下也表现良好。我们的建模框架的性能在ISPRS 2D Potsdam数据集上进行评估。结果显示了最佳模型的所有类别的平均F1得分为92.1的现有技术表现。 |
| Palmprint image registration using convolutional neural networks and Hough transform Authors Mohsen Ahmadi, Hossein Soleimani 基于Minutia的掌纹识别系统在过去二十年中引起了很多人的兴趣。由于掌纹中的大量细节,大约1000个细节,匹配过程是耗时的,这使得它对于实时应用来说是不实用的。解决此问题的一种方法是将所有掌纹图像与参考图像对齐并将它们带到相同的坐标系。将所有掌纹图像带到相同的坐标系统,可以在细节匹配期间减少计算量。本文利用卷积神经网络CNN和广义Hough变换GHT,提出了一种精确定位掌纹图像的新方法。该方法在掌纹和参考图像之间找到x和y方向上的相应旋转和位移。精确的掌纹注册可以提高匹配过程的速度和准确性。提出的方法能够自动区分左右掌纹,这有助于加速匹配过程。此外,CNN在配准阶段的设计结构,给我们从背景分割的掌纹图像,这是细节提取的预处理步骤。在THUPALMLAB数据库上评估了所提出的注册方法,其后是细节柱面码MCC匹配算法,结果表明我们的算法优于大多数现有算法。 |
| Multi-source weak supervision for saliency detection Authors Yu Zeng, Yunzhi Zhuge, Huchuan Lu, Lihe Zhang, Mingyang Qian, Yizhou Yu 像素级注释的高成本使得它在具有弱监督的情况下训练显着性检测模型具有吸引力。但是,单个弱监督源通常不包含足够的信息来训练表现良好的模型。为此,我们提出了一个统一的框架来训练具有多种弱监督来源的显着性检测模型。在本文中,我们使用类别标签,标题和未标记的数据进行培训,而其他监督来源也可以插入到这个灵活的框架中。我们设计了一个分类网络CNet和一个字幕生成网络PNet,它们分别学习预测对象类别和生成字幕,同时突出显示相应任务的最重要区域。注意力转移损失被设计成在网络之间传输监督信号,使得被设计为用一个监督源训练的网络可以从另一个监督源受益。在未标记数据上定义注意一致性损失,以鼓励网络检测通常显着的区域而不是任务特定区域。我们使用CNet和PNet生成像素级伪标签以训练显着性预测网络SNet。在测试阶段,我们只需要SNet来预测显着性图。实验证明,我们的方法的性能优于无监督和弱监督方法甚至一些监督方法。 |
| Scene Graph Generation with External Knowledge and Image Reconstruction Authors Jiuxiang Gu, Handong Zhao, Zhe Lin, Sheng Li, Jianfei Cai, Mingyang Ling 随着对象检测,属性和关系预测等图像理解任务的进步,场景图生成受到越来越多的关注。然而,现有数据集在对象和关系标签方面存在偏差,或者经常带有噪声和缺失注释,使得开发可靠的场景图预测模型非常具有挑战性。在本文中,我们提出了一种新的场景图生成算法,具有外部知识和图像重建损失,以克服这些数据集问题。特别是,我们从外部知识库中提取常识知识,以改进对象和短语特征,以提高场景图生成的普遍性。为了解决噪声对象注释的偏差,我们引入了辅助图像重建路径来规范场景图生成网络。大量实验表明,我们的框架可以生成更好的场景图,在两个基准数据集视觉关系检测和视觉基因组数据集上实现最先进的性能。 |
| Defogging Kinect: Simultaneous Estimation of Object Region and Depth in Foggy Scenes Authors Yuki Fujimura, Motoharu Sonogashira, Masaaki Iiyama 二维二维图像的三维三维重建和场景深度估计是计算机视觉中的主要任务。然而,使用传统的3D重建技术在参与的媒体中变得具有挑战性,例如模糊的水,雾或烟。我们开发了一种方法,该方法使用飞行时间ToF相机来同时估计参与媒体中的对象区域和深度。散射分量是饱和的,因此它不依赖于场景深度,并且由于参与介质中的光衰减,从远点反射的接收信号可以忽略不计,因此观察这样的点仅包含散射分量。这些现象使我们能够从仅包含散射分量的背景估计对象区域中的散射分量。该问题被公式化为鲁棒估计,其中对象区域被视为异常值,并且它使得能够基于迭代重加权最小二乘IRLS优化方案同时估计对象区域和深度。我们使用来自Kinect v2的捕获图像在真实雾场景中展示了所提出方法的有效性,并评估了合成数据的适用性。 |
| Weakly Supervised Object Detection with Segmentation Collaboration Authors Xiaoyan Li, Meina Kan, Shiguang Shan, Xilin Chen 弱监督对象检测旨在学习精确的对象检测器,给定图像类别标签。在最近的流行作品中,该问题通常被表述为由图像分类损失引导的多实例学习模块。假定对象边界框是对所有提议中的分类贡献最大的对象边界框。然而,贡献最大的区域也可能是对象的关键部分或支持上下文。为了获得更准确的探测器,在这项工作中,我们提出了一种新颖的端到端弱监督检测方法,其中新引入的生成对抗分割模块在协作循环中与传统检测模块交互。协作机制充分利用弱监督本地化任务的互补解释,即检测和分割任务,形成更全面的解决方案。因此,我们的方法获得更精确的对象边界框,而不是部分或不相关的环境。预计,所提出的方法在PASCAL VOC 2007数据集上达到51.0的准确度,优于现有技术并证明其对弱监督物体检测的优越性。 |
| PIRM2018 Challenge on Spectral Image Super-Resolution: Dataset and Study Authors Mehrdad Shoeiby, Antonio Robles Kelly, Ran Wei, Radu Timofte 本文介绍了一种新收集的新型数据集StereoMSI,例如基于单色和彩色引导光谱图像的超分辨率。该数据集首次在PIRM2018光谱图像超分辨率挑战期间发布和推广。据我们所知,该数据集是同类中的第一个,包括350个注册的彩色光谱图像对。数据集已用于挑战的两个轨道,对于每个轨道,我们提供了分为培训,验证和测试的部分。这种布置是挑战结构和阶段的结果,第一轨道聚焦于基于示例的光谱图像超分辨率,第二轨道旨在利用所记录的立体彩色图像来提高光谱图像的分辨率。已经选择每个轨道和分裂在多个图像质量度量上是一致的。该数据集本质上是非常通用的,除了开发光谱图像超分辨率方法之外,还可以用于各种各样的应用。 |
| Perceive Where to Focus: Learning Visibility-aware Part-level Features for Partial Person Re-identification Authors Yifan Sun, Qin Xu, Yali Li, Chi Zhang, Yikang Li, Shengjin Wang, Jian Sun 本文考虑了人体重新识别ID ID任务的现实问题,即部分重新ID。在部分重新ID情景下,图像可以包含对行人的部分观察。如果我们直接将部分行人图像与整体行人图像进行比较,则极端空间错位会显着损害学习表示的辨别能力。我们提出了一个可见性感知的零件模型VPM,它通过自我监督学会了解区域的可见性。可见性识别允许VPM提取区域级别的特征并比较两个图像,并将焦点集中在两个图像上可见的共享区域。对于部分重新ID,VPM可获得两倍的更高准确度。一方面,与学习全局特征相比,VPM学习区域级特征并从细粒度信息中获益。另一方面,利用可见性意识,VPM能够估计两个图像之间的共享区域,从而抑制空间错位。实验结果证实,我们的方法显着改善了学习的表示,并且所达到的准确度与现有技术相当。 |
| Toward Real-World Single Image Super-Resolution: A New Benchmark and A New Model Authors Jianrui Cai, Hui Zeng, Hongwei Yong, Zisheng Cao, Lei Zhang 大多数现有的基于学习的单图像超分辨率SISR方法在模拟数据集上被训练和评估,其中通过对其高分辨率HR对应物应用简单且均匀的降级(即,双三次下采样)来生成低分辨率LR图像。然而,现实世界LR图像中的降级要复杂得多。因此,在应用于实际场景时,对模拟数据进行训练的SISR模型变得不那么有效。在本文中,我们构建了一个真实世界的超级分辨率RealSR数据集,通过调整数码相机的焦距来捕获同一场景上的成对LR HR图像。开发了图像配准算法以逐步地以不同分辨率对齐图像对。考虑到退化核在我们的数据集中自然是不均匀的,我们提出了基于拉普拉斯金字塔的核预测网络LP KPN,其有效地学习每像素核以恢复HR图像。我们的广泛实验表明,在我们的RealSR数据集上训练的SISR模型可以提供更好的视觉质量,在现实世界场景中具有比在模拟数据集上训练的更清晰的边缘和更精细的纹理。虽然我们的RealSR数据集仅使用佳能5D3和尼康D810两款相机构建,但经过训练的型号可以很好地推广到其他相机设备,如索尼a7II和手机。 |
| Single Path One-Shot Neural Architecture Search with Uniform Sampling Authors Zichao Guo, Xiangyu Zhang, Haoyuan Mu, Wen Heng, Zechun Liu, Yichen Wei, Jian Sun 一次性方法是一种功能强大的神经网络搜索NAS框架,但其训练非常简单,很难在像ImageNet这样的大型数据集上获得竞争结果。在这项工作中,我们提出了单路径单击模型,以解决其在培训中的主要挑战。我们的中心思想是构建一个简化的超网,单路径超网,通过统一路径采样方法进行训练。所有底层架构及其权重都得到了充分和平等的培训。一旦我们拥有一个训练有素的超网,我们就应用一种进化算法来有效地搜索性能最佳的架构,而无需进行任何微调。综合实验证明我们的方法灵活有效。它易于训练和快速搜索。它毫不费力地支持复杂的搜索空间,例如,构建块,信道,混合精确量化和不同的搜索约束,例如FLOP,等待时间。因此,方便地用于各种需要。它实现了大型数据集ImageNet的艺术性能的开始。 |
| Self Supervised Occupancy Grid Learning from Sparse Radar for Autonomous Driving Authors Liat Sless, Gilad Cohen, Bat El Shlomo, Shaul Oron 占用网格映射是自主车辆感知的重要组成部分。它封装了可行驶区域,道路障碍物的信息,并实现安全的自动驾驶。为此,雷达因其远距离感测,低成本和对恶劣天气条件的稳健性而变得广泛使用。尽管深度学习技术最近取得了进展,但雷达数据的占用网格映射仍主要使用经典滤波方法完成。在这项工作中,我们提出了一种数据驱动方法,用于学习用于从聚类雷达数据进行占用网格映射的逆传感器模型。由于雷达传感器的数据稀疏性和噪声特性,该任务非常具有挑战性。该问题被公式化为语义分割任务,并且我们展示了如何使用激光雷达数据以自我监督的方式学习它以产生基本事实。我们使用最近发布的NuScenes真实世界驾驶数据,定性和定量地显示我们的学习占用网络大大优于经典方法。 |
| Multi-vision Attention Networks for On-line Red Jujube Grading Authors Xiaoye Sun, Liyan Ma, Gongyan Li 为解决红枣分类问题,本文设计了一种计算量小,分类精度高的卷积神经网络模型。该模型的架构受到有机体和DenseNet的多视觉机制的启发。为了进一步改进我们的模型,我们增加了SE Net的注意机制。我们还构建了一个数据集,其中包含由枣分级系统捕获的23,735个红枣图像。根据枣的外观和分级系统的特点,将数据集分为无效,腐烂,枯萎和正常四类。数值实验表明,该模型的分类精度达到91.89,与DenseNet 121,InceptionV3,InceptionV4和Inception ResNet v2相当。但是,我们的模型具有实时性能。 |
| PyramidBox++: High Performance Detector for Finding Tiny Face Authors Zhihang Li, Xu Tang, Junyu Han, Jingtuo Liu, Ran He 随着深度卷积神经网络的快速发展,人脸检测近年来取得了长足的进步。 WIDER FACE数据集作为主要基准,对该领域做出了巨大贡献。 PyramidBox设计了一种有效的数据增强策略数据锚点采样和基于上下文的人脸检测模块,已经提出了大量的方法。在本报告中,我们对每个部分进行了改进,以进一步提升性能,包括平衡数据锚点采样,Dual PyramidAnchors和Dense Context Module。具体而言,平衡数据锚点采样获得具有不同大小的面部的更均匀采样。 Dual PyramidAnchors通过引入渐进式锚定损失来促进特征学习。具有密集连接的密集上下文模块不仅可以扩大接收域,还可以有效地传递信息。通过集成这些技术,构建了PyramidBox,并在硬集中实现了最先进的性能。 |
| Pedestrian re-identification based on Tree branch network with local and global learning Authors Hui Li, Meng Yang, Zhihui Lai, Weishi Zheng, Zitong Yu 最近文献中基于深度部分的方法揭示了在人员识别任务中学习行人图像的局部部分层次表示的巨大潜力。然而,捕获人体歧视性整体信息的全局特征通常被忽略或未被充分利用。这促使我们调查行人图像的联合学习全局和局部特征。具体来说,在这项工作中,我们提出了一种新的框架,称为树枝网络TBN,用于人员识别。给定一个pedestrain图像,由主干CNN生成的特征映射被递归地划分为若干个部分,每个部分之后是瓶颈结构,该结构为层级树中的每个级别(例如框架)学习更精细的粒度特征。以这种方式,以粗略到精细的方式学习表示并最终组装以产生更具辨别力的图像描述。实验结果证明了全局和局部特征学习方法在提出的TBN框架中的有效性。在市场1501,CUHK 03和DukeMTMC三个公共基准测试中,我们的性能也显着提高。 |
| Fast and Full-Resolution Light Field Deblurring using a Deep Neural Network Authors Jonathan Samuel Lumentut, Tae Hyun Kim, Ravi Ramamoorthi, In Kyu Park 由于基于视差的图像处理的日益普及,从其模糊输入恢复清晰的光场图像变得必不可少。现有技术的盲光场去模糊方法存在若干问题,例如处理缓慢,空间尺寸减小和运动模糊模型有限。在这项工作中,我们通过生成复杂的模糊光场数据集并提出基于学习的去模糊方法来解决这些具有挑战性的问题。特别地,我们模拟完整的6自由度6 DOF光场相机运动,其用于使用利用Lytro Illum相机捕获的真实光场和3D场景的合成光场渲染的组合来创建模糊数据集。此外,我们提出了一个具有大感受野能力的光场去模糊网络。我们还介绍了一种简单的角度采样策略,可以有效地训练大尺度模糊光场。我们通过定量和定性测量来评估我们的方法,并且与现有技术方法相比具有优异的性能,并且执行时间大大加快。我们的方法比Srinivasan等快16K倍。人。 22并且可以在不到2秒的时间内对全分辨率光场进行去模糊。 |
| Fully Learnable Group Convolution for Acceleration of Deep Neural Networks Authors Xijun Wang, Meina Kan, Shiguang Shan, Xilin Chen 受益于其在许多任务上的巨大成功,深度学习越来越多地用于低计算成本的设备,例如,为了降低高计算和内存成本,在这项工作中,我们提出了一个完全可学习的组卷积模块FLGC,它非常有效,可以嵌入任何深度神经网络中进行加速。具体而言,我们提出的方法以完全端到端的方式自动学习训练阶段的组结构,从而导致比现有的预定义,两个步骤或迭代策略更好的结构。此外,我们的方法可以进一步与深度可分离卷积相结合,在单CPU上产生比香草Resnet50加速5倍的加速度。另一个优点是,在我们的FLGC中,组的数量可以设置为任何值,但不一定是大多数现有方法中的2 k,这意味着精度和速度之间的更好权衡。根据我们的实验评估,当使用相同数量的组时,我们的方法比现有的可学习组卷积和标准组卷积实现更好的性能。 |
| An Efficient Approach for Cell Segmentation in Phase Contrast Microscopy Images Authors Lin Zhang 在本文中,我们提出了一种新的模型来分割相位对比显微镜图像中的细胞。从类似场景收集的细胞图像具有相似的背景。受此启发,我们通过将问题表述为低秩和结构化稀疏矩阵分解问题,将细胞与图像中的背景分离。然后,我们提出逆衍射图案滤波方法以进一步分割图像中的各个单元。与其他恢复方法相比,这是一种解卷积过程,其计算复杂度要低得多。实验证明了该模型与最近的工作相比较的有效性。 |
| ImageGCN: Multi-Relational Image Graph Convolutional Networks for Disease Identification with Chest X-rays Authors Chengsheng Mao, Liang Yao, Yuan Luo 图像表示是计算机视觉中的基本任务。然而,大多数现有的图像表示方法忽略了图像之间的关系,并独立地考虑每个输入图像。直观地,图像之间的关系可以帮助理解图像并保持模型在相关图像上的一致性。在本文中,我们考虑建模图像层次关系以生成更多信息图像表示,并提出ImageGCN,一种用于多关系图像建模的端到端图卷积网络框架。我们还将ImageGCN应用于胸部X射线CXR图像,其中丰富的关系信息可用于疾病识别。与以前的图像表示模型不同,ImageGCN使用其原始像素特征和相关图像的特征来学习图像的表示。除了学习图像的信息表示之外,ImageGCN还可以以弱监督的方式用于对象检测。 ChestX ray14数据集的实验结果表明,ImageGCN在疾病识别和定位任务方面可以超越各自的基线,并且可以获得与现有技术方法相当且通常更好的结果。 |
| NM-Net: Mining Reliable Neighbors for Robust Feature Correspondences Authors Chen Zhao, Zhiguo Cao, Chi Li, Xin Li, Jiaqi Yang 特征对应选择对于计算机视觉中的许多基于特征匹配的任务是关键的。搜索空间k最近邻居是在许多先前作品中提取本地信息的常用策略。然而,不能保证对应的空间k最近邻居是一致的,因为错误对应的空间分布通常是不规则的。为解决此问题,我们提出了一种兼容性特定的挖掘方法来搜索一致的邻居。此外,为了从邻居中提取和聚合更可靠的特征,我们提出了一个名为NM Net的分层网络,其中一系列卷积层将生成的图形作为输入,这对应于对应的顺序。我们的实验结果表明,所提出的方法在具有各种入射比和不同数量的特征一致性的四个数据集上实现了现有技术的性能。 |
| Discrete Rotation Equivariance for Point Cloud Recognition Authors Jiaxin Li, Yingcai Bi, Gim Hee Lee 尽管最近对处理具有深度网络的点云进行了积极的研究,但很少关注网络对旋转的敏感性。在本文中,我们提出了一种深度学习架构,它实现了点云识别的离散mathbf SO 2 mathbf SO 3旋转等效性。具体地,输入点云与旋转组的元素的旋转类似于对由我们的方法生成的特征向量进行混洗。通过使用诸如最大值或平均值之类的操作消除置换,可以容易地将等效性简化为不变性。我们的方法可以直接应用于任何现有的基于点云的网络,从而显着改善其旋转输入的性能。我们在mathbf SO 2和mathbf SO 3旋转下使用各种数据集显示分类任务的最新结果。此外,我们进一步分析了将我们的方法应用于基于PointNet的网络的必要条件。源代码在 |
| Two-phase flow regime prediction using LSTM based deep recurrent neural network Authors Zhuoran Dang, Mamoru Ishii 长期短期记忆LSTM和递归神经网络RNN在时间序列预测方面取得了巨大成功。在本文中,提出了一种基于LSTM的深度RNN用于两相流状态预测的方法,这是由以前的构建深度RNN的研究所推动的。该方法具有快速响应和准确性。使用阻抗无效计收集时间序列空隙率数据,对构建的RNN网络进行训练和测试。结果表明,预测精度取决于网络的深度和层单元的数量。但是,越来越大的网络消耗更多的预测时间。 |
| Evaluating CNNs on the Gestalt Principle of Closure Authors Gregor Ehrensperger, Sebastian Stabinger, Antonio Rodr guez S nchez 深度卷积神经网络CNN以其在高维数据上的分类和回归任务中的出色表现而广为人知。这使它们成为工业和学术界广泛应用的流行和强大工具。最近的出版物表明,对于人类来说,看似简单的分类任务对于最先进的CNN来说可能是非常具有挑战性的。格式塔原则给出了描述人类如何感知视觉元素的尝试。在本文中,我们评估AlexNet和GoogLeNet关于它们在众所周知的Kanizsa三角形的正确性方面的表现,这三角形严重依赖于格式的闭合原理。因此,我们创建了包含Kanizsa三角形的有效和无效变体的各种数据集。我们的研究结果表明,利用闭合原理感知对象对于应用的网络架构来说是非常具有挑战性的,但它们似乎适应了闭合的影响。 |
| Can WiFi Estimate Person Pose? Authors Fei Wang, Stanislav Panev, Ziyi Dai, Jinsong Han, Dong Huang WiFi人体感应在室内定位,活动分类等方面取得了很大进展。回顾这些工作的发展,我们有一个自然的问题,WiFi设备可以像视觉应用的相机一样工作在本文中我们试图通过探索能力回答这个问题WiFi估计单人姿势我们使用3天线WiFi发送器和3天线接收器来生成WiFi数据。同时,我们使用同步相机捕获人物视频以获得相应的关键点注释。我们进一步提出了一种完全卷积网络FCN,称为WiSPPN,用于从收集的数据和注释中估计单人姿势。评估超过80k的图像16个站点和8个人回答上述问题并给出肯定答案。代码已公开发布于 |
| Person-in-WiFi: Fine-grained Person Perception using WiFi Authors Fei Wang, Sanping Zhou, Stanislav Panev, Jinsong Han, Dong Huang 已经利用诸如RGB深度相机,雷达(例如RF姿势和LiDAR)的许多2D和3D传感器实现了诸如身体分割和姿势估计的细粒度人物感知。这些传感器捕获具有高空间分辨率的人体的2D像素或3D点云,使得现有的卷积神经网络可以直接应用于感知。在本文中,我们向前迈出了一步,表明即使使用一维传感器WiFi天线也可以实现细粒度的人感知。据我们所知,这是第一个感知具有普及WiFi设备的人的工作,这种设备比雷达和激光雷达更便宜,更节能,对照明不变,与相机相比几乎没有隐私问题。我们使用两组现成的WiFi天线来获取信号,即一个发射机组和一个接收机组。每组包含三个天线,排列为常规家用WiFi路由器。由发射器天线产生的WiFi信号穿透并反射在人体,家具和墙壁上,然后在接收器天线处叠加作为一维信号样本而不是2D像素或3D点云。我们开发了一种深度学习方法,在2D图像上使用注释,将接收到的1D WiFi信号作为输入,并以端到端方式执行身体分割和姿势估计。在16个室内场景下超过100000帧的实验结果表明,WiFi中的人获得了与使用2D图像的方法相当的人的感知。 |
| Classification of Motorcycles using Extracted Images of Traffic Monitoring Videos Authors Adriano Belletti Felicio e Andr Luiz Cunha 由于城市车队中摩托车的大量增长以及对其行为的研究的增长以及该车辆如何影响交通流量变得必要,因此开发不同于传统工具和技术的工具和技术以确定其在交通中的存在流动,并能够提取您的信息。所述文章试图通过生成摩托车图像库并通过组合LBP技术来创建特征向量和用于执行预测的分类技术LinearSVC来开发和校准摩托车分类器,从而有助于对这种类型的车辆的研究。通过这种方式,本研究中开发的摩托车型车辆的分类器可以对两类摩托车和非摩托车之间的监控视频提取的车辆图像进行分类,精度和精度优于0.9。 |
| Person Re-identification with Bias-controlled Adversarial Training Authors Sara Iodice, Krystian Mikolajczyk 受创新对抗网络领域对抗性训练有效性的启发,我们提出了一种新的方法,用于学习人物识别中的特征表示。我们研究通常在重新ID情景中发生的不同类型的偏差,即姿势,身体部位和摄像机视图,并提出解决它们的一般方法。我们引入了一种控制偏倚的对抗策略,命名为偏倚控制对抗框架BCA,具有两个互补分支以减少或增强偏倚相关特征。结果和与不同基准的现有技术的比较表明,我们的框架是一种有效的人员识别策略。性能改进包括人员的全部和部分视图。 |
| OSVNet: Convolutional Siamese Network for Writer Independent Online Signature Verification Authors Chandra Sekhar, Prerana Mukherjee, Devanur S Guru, Viswanath Pulabaigari 在线签名验证OSV是作家识别和数字取证中最具挑战性的任务之一。由于个体内部变异性大,因此需要准确地学习签名的个人内部变化以获得更高的分类准确性。为实现这一目标,本文提出了一种基于深度卷积连体网络DCSN的OSV框架。 DCSN基于基于度量的损失函数自动提取强大的特征描述,这降低了内部写入者的可变性。真正的正版和增加个体间的变异性真实伪造并指导DCSN进行在线签名的有效判别表示学习并将其扩展为一次性学习框架。在三个广泛接受的基准数据集MCYT 100 DB1,MCYT 330 DB2和SVC 2004 Task2上进行的综合实验证明了我们的框架能够区分真实和伪造样本。与许多最近和现有技术的OSV技术相比,实验结果通过实现更低的错误率来确认基于深度卷积的基于Siamese网络的OSV的效率。 |
| MortonNet: Self-Supervised Learning of Local Features in 3D Point Clouds Authors Ali Thabet, Humam Alwassel, Bernard Ghanem 我们在点云上提出了一个自我监督的任务,以便学习在每个点周围编码局部结构的有意义的逐点特征。我们的自监督网络名为MortonNet,直接在非结构化无序点云上运行。使用多层RNN,MortonNet预测由流行且快速的空间填充曲线(Morton顺序曲线)创建的点序列中的下一个点。最终的RNN状态创造了Morton功能,用途广泛,可用于点云上的通用3D任务。实际上,我们展示了在具有挑战性和大规模的S3DIS数据集的点云语义分割任务中,Morton特征如何用于显着提高2个流行语义分割算法的性能3。我们还展示了MortonNet如何在S3DIS上进行培训,以便很好地转移到另一个大规模数据集vKITTI,从而改进了3.8的最新技术水平。最后,我们使用Morton功能来训练一个更简单,更稳定的模型,用于ShapeNet中的零件分割。我们的结果显示了我们的自我监督任务如何产生对3D分割任务有用的特征,并且很好地概括为其他数据集。 |
| USIP: Unsupervised Stable Interest Point Detection from 3D Point Clouds Authors Jiaxin Li, Gim Hee Lee 在本文中,我们提出USIP探测器是一种无监督的稳定兴趣点探测器,可以在任意变换下从三维点云中探测高度可重复且精确定位的关键点,而无需任何地面实况训练数据。我们的USIP探测器由一个特征提议网络组成,该网络从输入的3D点云中学习稳定的关键点,并从随机生成的变换中学习各自的变换对。我们提供USIP检测器的简并分析,并提出预防措施。我们鼓励具有概率倒角损失的关键点的高重复性和精确定位,从而最小化检测到的关键点与训练点云对之间的距离。来自激光雷达,RGB D和CAD模型的几个模拟和真实世界3D点云数据集的重复性测试的广泛实验结果表明,我们的USIP探测器明显优于现有的手工制作和基于深度学习的3D关键点探测器。我们的代码可在项目网站上获得。 |
| RefineLoc: Iterative Refinement for Weakly-Supervised Action Localization Authors Humam Alwassel, Fabian Caba Heilbron, Ali Thabet, Bernard Ghanem 视频动作检测器通常使用具有完全监督的时间注释的视频数据集来训练。构建这样的视频数据集是一项非常昂贵的任务。为了缓解这个问题,最近的算法利用弱标签,其中视频是未修剪的,并且只有视频级标签可用。在本文中,我们提出了RefineLoc,一种弱监督时间动作定位的新方法。 RefineLoc使用迭代细化方法,通过在每次迭代时估计和训练片段级伪地面实况。我们展示了使用这种迭代方法的好处,并对不同的伪地面实例生成器进行了广泛的分析。我们在两个标准动作数据集ActivityNet v1.2和THUMOS14上展示了我们模型的有效性。配备基于段预测的伪地面实况生成器的RefineLoc在具有挑战性和大规模的ActivityNet数据集上的弱监督时间定位中改进了4.2的技术水平,并且在THUMOS14上实现了与现有技术相当的性能。 |
| A HVS-inspired Attention Map to Improve CNN-based Perceptual Losses for Image Restoration Authors Taimoor Tariq, Juan Luis Gonzalez, Munchurl Kim 深度卷积神经网络CNN功能已被证明是有效的感知质量特征。基于预训练的CNN的特征图的感知损失已经证明对于基于CNN的感知图像恢复问题是非常有效的。在这项工作中,从人类视觉系统HVS和我们的视觉感知中获取灵感,我们提出了一种基于依赖人类对比敏感度对空间频率的空间注意机制。我们基于视觉系统可能对失真最敏感的基础空间频率来识别输入图像中的区域。基于此前,我们设计了一个应用于感知损失中的特征映射的注意力图,帮助它识别具有更多感知重要性的区域。结果将证明所提出的技术有助于改善感知损失与人类感知质量的主观评估之间的相关性,并且还导致与基于CNN的图像恢复问题中广泛使用的感知损失相比提供更好的感知失真折衷的损失。 。 |
| Boundary Aware Multi-Focus Image Fusion Using Deep Neural Network Authors Haoyu Ma, Juncheng Zhang, Shaojun Liu, Qingmin Liao 由于通常难以直接捕获3D场景的全焦点图像,因此采用各种多焦点图像融合方法从聚焦在不同深度的若干图像生成它。然而,现有方法的性能几乎不令人满意,并且对于聚焦的散焦边界FDB附近的区域经常会降低。本文提出了一种利用深度神经网络的边界感知方法来克服这一问题。 1为了获得改进的融合图像,提出了一种双通道深度网络,以更好地提取两个源图像的相对散焦信息。 2在分析远离FDB和靠近FDB的补丁的不同情况后,我们分别使用两个网络来处理它们。 3为了更精确地模拟现实,设计了一种新的数据集生成方法。实验表明,所提出的方法在性质和数量上都优于现有技术方法。 |
| Exploiting SIFT Descriptor for Rotation Invariant Convolutional Neural Network Authors Abhay Kumar, Nishant Jain, Chirag Singh, Suraj Tripathi 本文提出了一种利用卷积神经网络中独特不变特征的新方法。所提出的CNN模型使用尺度不变特征变换SIFT描述符而不是最大池化层。最大合并层丢弃了低级特征之间的姿势,即平移和旋转关系,因此无法捕获低级和高级特征之间的空间层次。 SIFT描述符层捕获由卷积层提取的特征的方向和空间关系。因此,所提出的SIFT描述符CNN结合了CNN模型的特征提取能力和SIFT描述符的旋转不变性。 MNIST和fashionMNIST数据集上的实验结果表明,与文献中可用的传统方法相比有了合理的改进。 |
| A Convolution-Free LBP-HOG Descriptor For Mammogram Classification Authors Zainab Alhakeem, Se In Jang 在基于图像的特征描述符设计中,经常采用利用卷积运算的迭代扫描处理来提取图像像素的局部信息。在本文中,我们提出了一种无卷积局部二值模式CF LBP和一种无卷积直方图定向梯度CF HOG描述符矩阵形式的乳房X线照片分类。随后在单个矩阵制剂中构建CF LBP和CF HOG,CF LBP HOG的集成形式。使用公开的乳房X线照片数据库评估所提出的描述符。结果表明,在分类精度和计算效率方面表现良好。 |
| Adaptive Adjustment with Semantic Feature Space for Zero-Shot Recognition Authors Jingcai Guo, Song Guo 近年来,零射击识别ZSR在机器学习和图像处理领域越来越受到关注。它旨在通过从所见类传递的知识来识别看不见的类实例。这通常通过利用预定义的语义特征空间FS(即,语义属性或单词向量)作为在看见和未看到的类之间传递知识的桥梁来实现。然而,由于在训练期间没有看不见的课程,传统的ZSR很容易受到领域转移和枢纽问题的困扰。在本文中,我们提出了一种新颖的ZSR学习框架,通过自适应调整语义FS可以很好地处理这两个问题。据我们所知,我们的工作是第一个考虑ZSR中语义FS的自适应调整。此外,我们的解决方案可以配制成更有效的框架,从而显着提升培训。大量实验表明,与其他现有方法相比,我们的模型性能得到了显着提高。 |
| M2FPA: A Multi-Yaw Multi-Pitch High-Quality Database and Benchmark for Facial Pose Analysis Authors Peipei Li, Xiang Wu, Yibo Hu, Ran He, Zhenan Sun 监视或移动场景中的面部图像通常在俯仰和偏转角方面具有大的视点变化。这些共同发生的角度变化使面部识别具有挑战目前的公共人脸数据库主要考虑偏航变化的情况。本文提出了一种新的大型多偏航多音高质量数据库,用于面部姿势分析M2FPA,包括脸部正面化,面部旋转,面部姿势估计和姿势不变人脸识别。它包含397,544张229个主题的图像,具有偏航,俯仰,属性,照明和配件。 M2FPA是用于面部姿势分析的最全面的多视图面部数据库。此外,我们通过几种最先进的方法,包括DR GAN,TP GAN和CAPG GAN,为M2FPA提供面部正面化和姿势不变人脸识别的有效基准。我们相信新的数据库和基准测试可以显着推动现实世界应用中面部姿势分析的进步。此外,引入了简单但有效的解析引导鉴别器以在GAN优化期间捕获局部一致性。 M2FPA和Multi PIE的广泛定量和定性结果证明了我们的面部正面化方法的优越性。从theart方法的状态进行面部合成和面部识别的基线结果证明了这个新数据库提供的挑战。 |
| Exposing GAN-synthesized Faces Using Landmark Locations Authors Xin Yang, Yuezun Li, Honggang Qi, Siwei Lyu 生成对手网络GAN最近导致高度逼真的图像合成结果。在这项工作中,我们描述了一种使用面部标志点的位置来暴露GAN合成图像的新方法。我们的方法基于观察结果,由于缺乏全局约束,GAN模型生成的面部部件配置与真实面部的面部部件配置不同。我们进行了证明这种现象的实验,并且表明使用面部界标点的位置训练的SVM分类器足以实现GAN合成面部的良好分类性能。 |
| UVA: A Universal Variational Framework for Continuous Age Analysis Authors Peipei Li, Huaibo Huang, Yibo Hu, Xiang Wu, Ran He, Zhenan Sun 用于面部年龄分析的常规方法倾向于以受监督的方式利用准确的年龄标签。然而,现有的年龄数据集处于有限的年龄范围内,导致长尾分布。为了解决这个问题,本文提出了一种通用变异老化UVA框架,以解开的方式制定面部年龄先验。受益于变量证据下限,将面部图像编码并解开成潜在空间中与年龄无关的分布和年龄相关的分布。引入条件内省对抗性学习机制来提高图像质量。通过这种方式,当操纵年龄相关分布时,UVA可以实现任意年龄的年龄翻译。此外,通过从年龄无关分布中采样噪声,我们可以生成具有特定年龄的照片级逼真的面部图像。此外,给定输入面部图像,可以将年龄相关分布的平均值视为年龄估计器。这些表明,即使训练数据集执行长尾分布,UVA也可以通过解开方式有效且准确地估计年龄相关分布。 UVA是在通用框架中首次尝试实现面部年龄分析任务,包括年龄翻译,年龄生成和年龄估计。定性和定量实验证明了UVA在五个流行数据集上的优越性,包括CACD2000,Morph,UTKFace,MegaAge Asian和FG NET。 |
| Chinese Abs From Machine Translation |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号