

【今日CV 计算机视觉论文速览 第97期】Tue, 9 Apr 2019
今日CS.CV 计算机视觉论文速览
Tue, 9 Apr 2019 (showing first 100 of 124 entries)
Totally 100 papers
👉上期速览 ✈更多精彩请移步主页

Interesting:
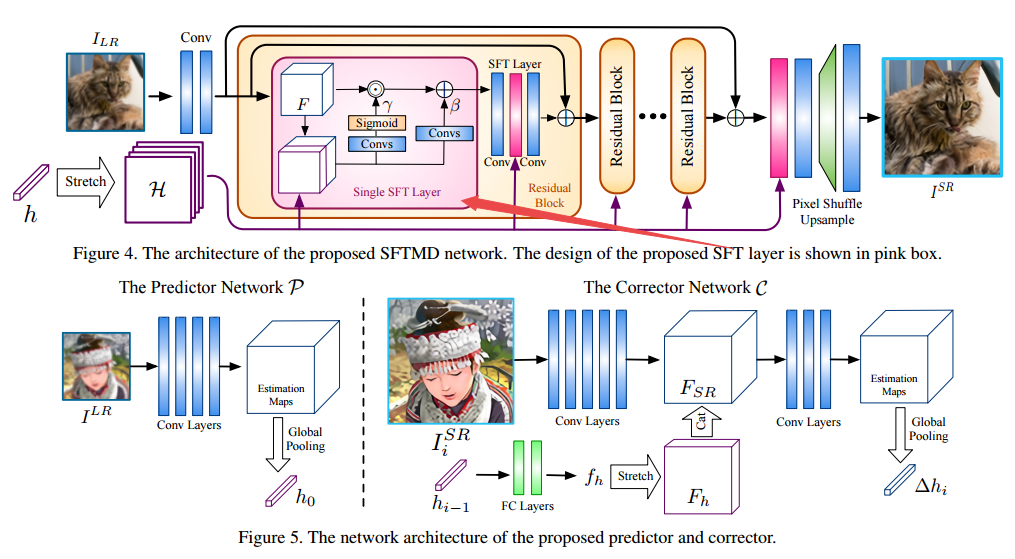
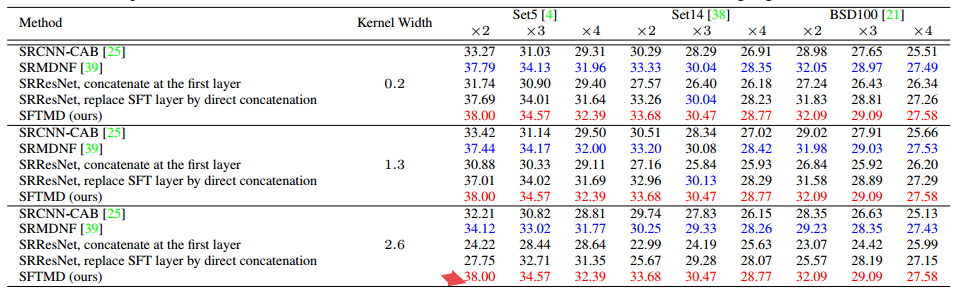
📚基于核纠正迭代的盲超分辨, 提出了一种迭代核纠正的方法来处理退化核未知的盲超分辨过程。效果比直接估计退化核好,并提出了基于空间特征变换层来处理多个模糊核。 (from 香港中文)
与现有个方法的比较:
一些效果:

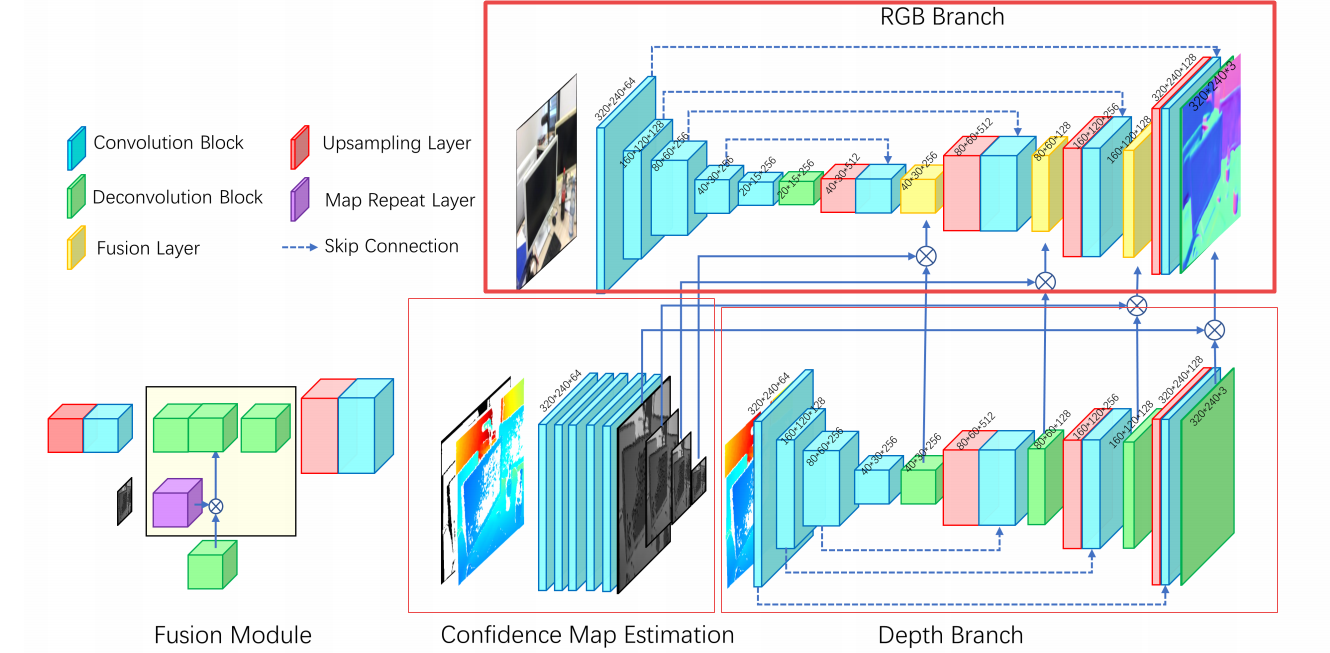
📚CameraSR, 调节内参从相机镜头的角度来平衡分辨率和视角的关系,并构建分辨率和视角的超分辨隐模型,用于逆问题的研究。在单反Digital Single Lens ReflexDSLR和手机相机中进行了实验。利用了高分辨相纸打印并采集了City100数据集。(from 中科大)
基于双三次降采样和分辨率-视角模型的降采样:
dataset:https://github.com/ngchc/CameraSR


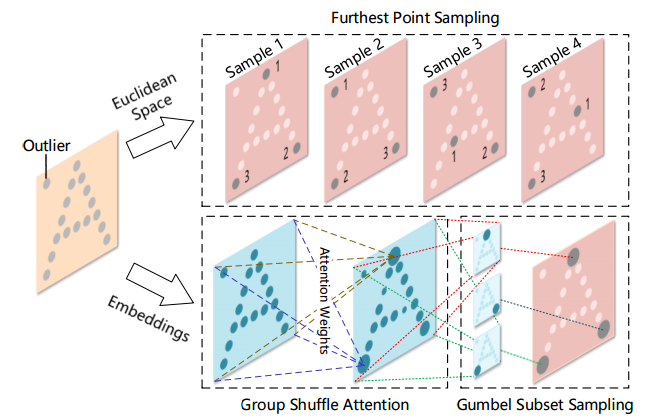
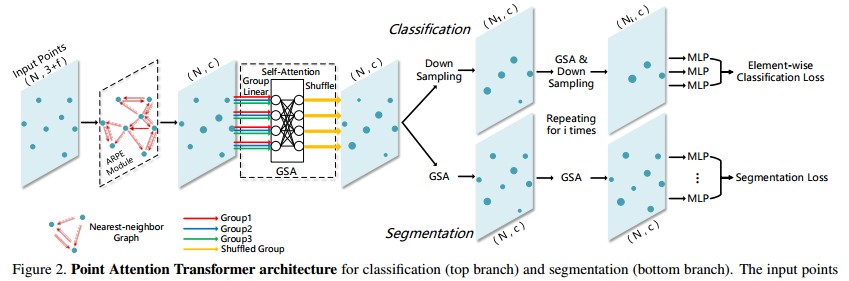
📚Point Attention Transformers,PATs, 可以处理大小变换的输入,并实现了与类别无关的采样方法Gumbel Subset Sampling(GSS),选出点云中最具代表性的点。(from 上海交大 )
应用: DVS128 Gesture Dataset
ref:Gumbel:https://blog.csdn.net/a358463121/article/details/80820878
📚用于处理样本不平衡的加权点云增强系统, (from 伦敦大学学院)
基于点云增强后得到的结果,分别来自于Semantic3D和ScanNet在pointnet++下的结果:

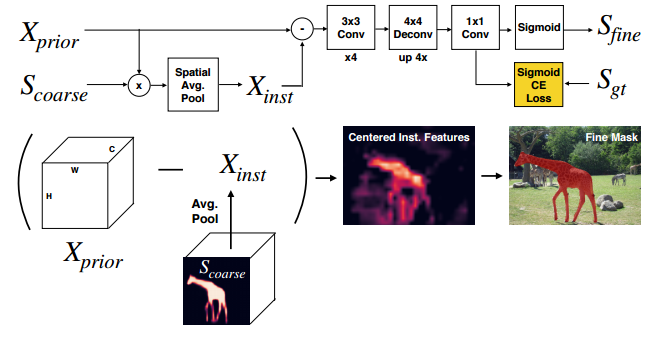
📚ShapeMask, 通过提炼形状先验来实现新颖物体的分割。首先利用bbox来估计目标的形状先验,随后利用目标特征优化得到粗糙的mask,最后特征先验、精炼得到精细的mask分割。(from Google Brain Berkeley)
一些结果:
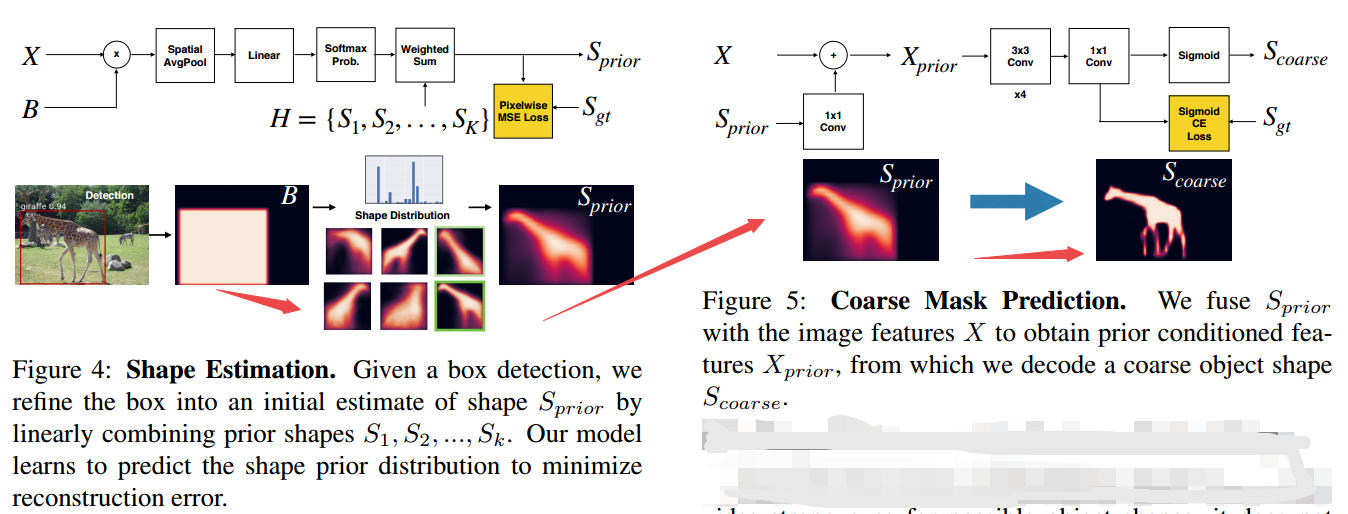

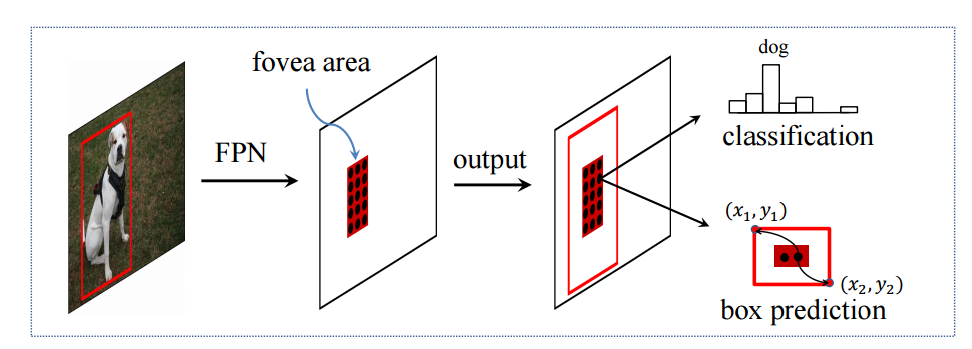
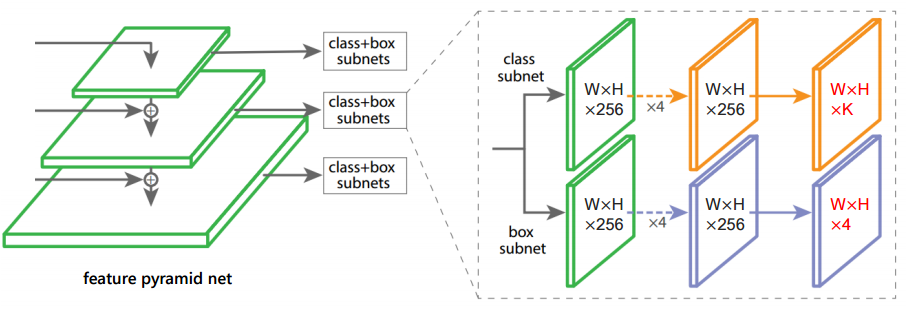
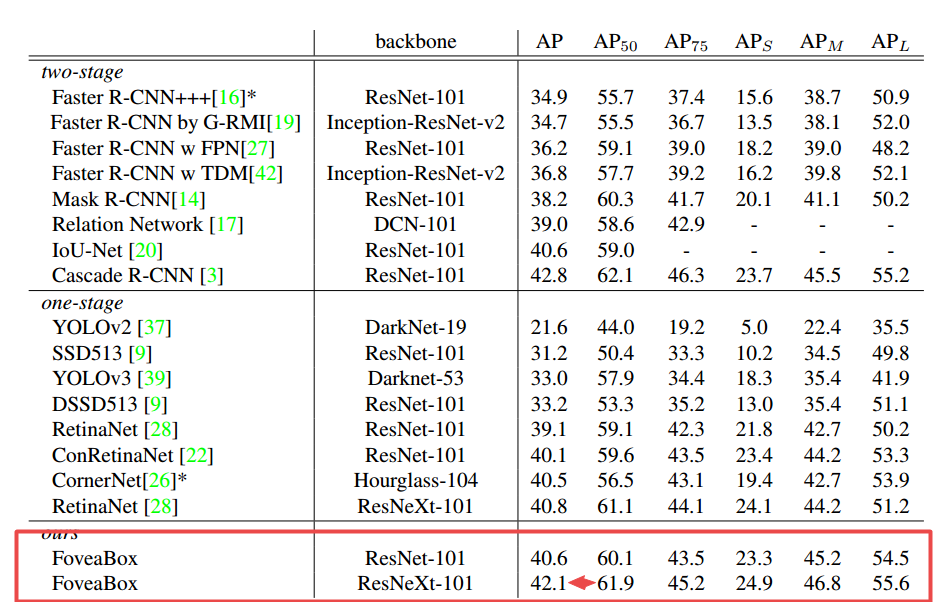
📚FoveaBox一种不基于锚点的目标检测方法, 在不需要锚的情况下直接学习物体存在的可能性和框的位置。主要通过预测类别敏感的目标存在可能性语义图,以及为潜在目标位置生成与类别无关的框。框的尺度与金字塔特征相关。这一方法在COCO上实现了42.1的高mAP。(from 清华)
馈入NMS前得到输出存在可能性图和相应的框。
与各种丰富的比较:

📚Kervolutional Neural Networks, 提出了一种 基于和的卷积(kernel convolution)来研究卷积中操作中的非线性过程,使卷积操作更加通用、提高模型表达能和抽取特征的能力。(from 南洋理工)
基于核函数来实现KNN计算:

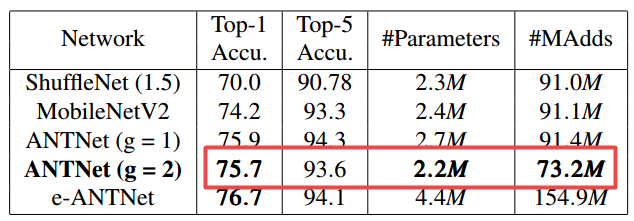
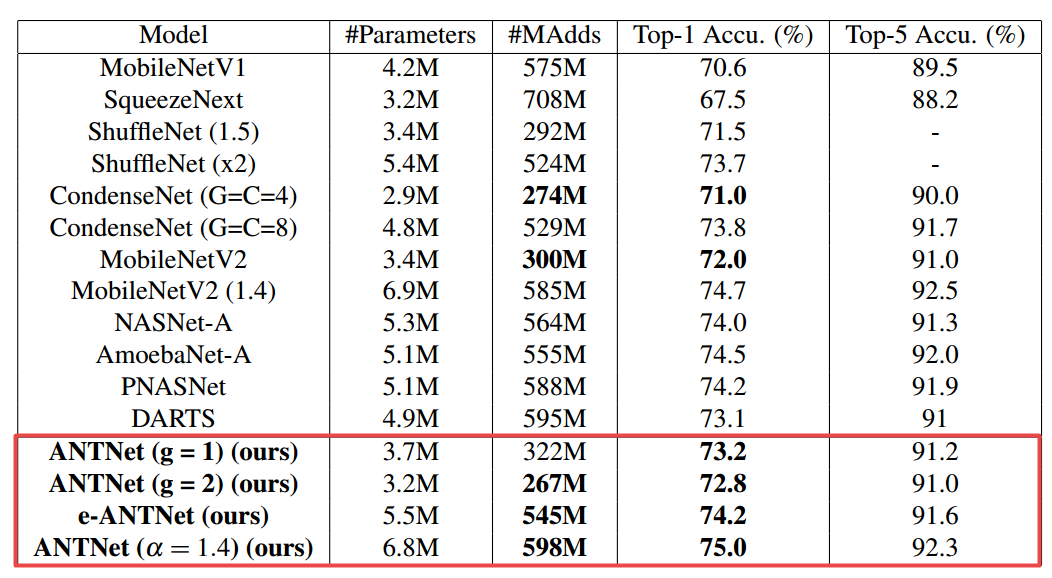
📚ANTNets, 为了解决深度可分离网络表达能力下降的问题,研究人员提出了一种参数和计算量(MAdds)更少的架构模块ANTBlock,Attention NesTed Network,在高维空间中用更少的参数保持模型的表达能力,在CIFAR100上实现了75.7%的top1精度,比MobileV2高75.7%,而参数和计算FLOPS更少、(from 威斯康辛·麦迪逊大学)
实验结果和对比如下:
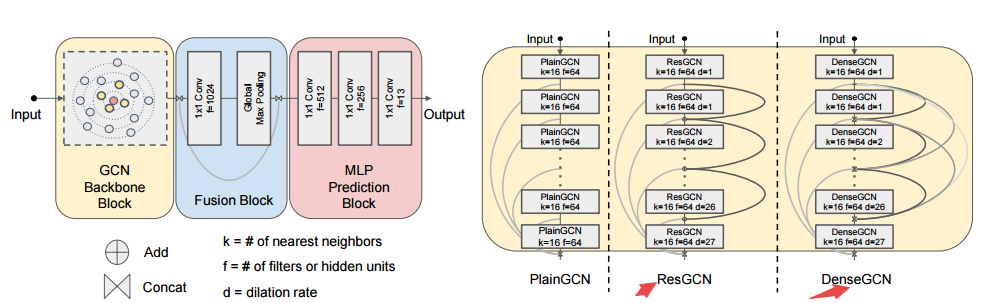
📚深度图卷积网络, 图卷积对于非欧空间数据有着较好的效果,但由于梯度消失问题使网络深度很浅。研究人员利用类似卷积中的残差和稠密连接概念实现了56层的GCN,并在点云分割任务中提升了3.7%的mIOU(from KAUST)
project:https://sites.google.com/view/deep-gcns

📚基于RGBD估计表面法向量, 利用了基于自适应特征赋权方法的分层融合网络实现表面法向量估计。彩色和深度图像在多尺度进行操作保证了图像的连续性和图中物体的显著性,同时深度图和置信图的结合实现重新赋权缓解了人工痕迹。(from 商汤 北理工 )
一些结果和比较:
数据集:Matterport3D and ScanNet dataset

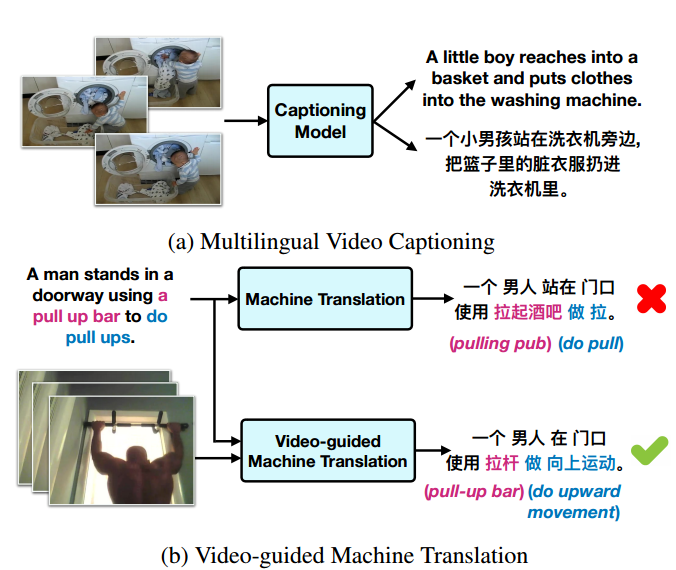
📚VATEX, 大规模高质量多语言视觉语言数据集(from UCSB)
其中包含了多语言视频标注和基于视频的机器翻译任务:
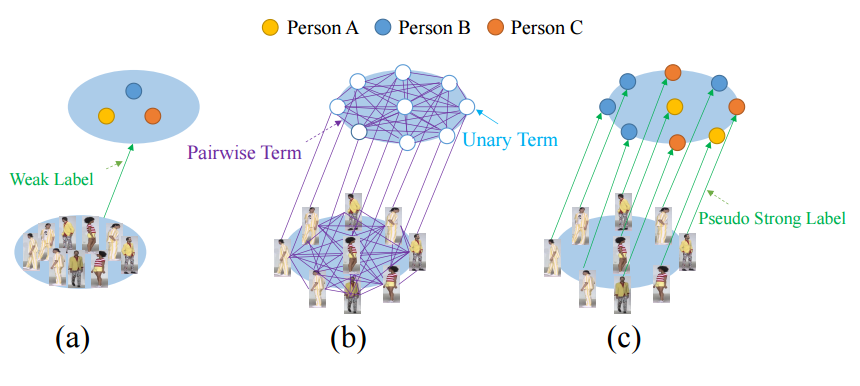
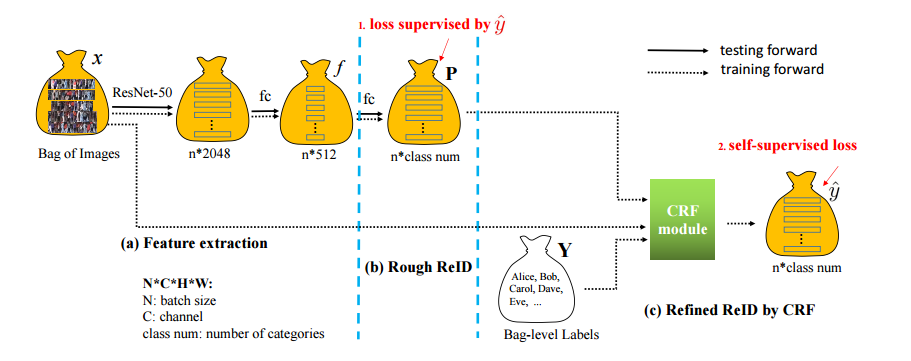
📚 SYSU-30k,弱监督行人重识别的新基准 (from 中山大学)
基于弱监督ReID的重识别方法:
相关数据集:

Daily Computer Vision Papers
| A Closer Look at Few-shot Classification Authors Wei Yu Chen, Yen Cheng Liu, Zsolt Kira, Yu Chiang Frank Wang, Jia Bin Huang 几个镜头分类的目的是学习一个分类器,用有限的标签示例在训练期间识别看不见的课程。虽然已经取得了重大进展,但网络设计,元学习算法的日益复杂以及实施细节的差异使得公平比较变得困难。在本文中,我们提出了几个代表性的几个镜头分类算法的一致比较分析,结果表明,更深的主干显着降低了具有有限域差异的数据集的方法之间的性能差异,2一个改进的基线方法,令人惊讶地实现了竞争性能与miniI和CUB数据集上的现有技术进行了比较,3是用于评估少数镜头分类算法的跨域泛化能力的新实验设置。我们的结果表明,当特征骨干较浅时,减少类内变异是一个重要因素,但在使用更深的骨干时则不那么重要。在真实的跨域评估设置中,我们表明,使用标准微调实践的基线方法与其他现有技术的少数镜头学习算法相比是有利的。 |
| Relational Action Forecasting Authors Chen Sun, Abhinav Shrivastava, Carl Vondrick, Rahul Sukthankar, Kevin Murphy, Cordelia Schmid 本文重点关注视频中的多人动作预测。更确切地说,给定H先前帧的历史,目标是检测演员并预测他们未来对下一个T帧的动作。我们的方法通过构建循环图来联合模拟不同参与者之间的时间和空间相互作用,使用以更快的R CNN获得的行动者提议作为节点。我们的方法学会选择一个判别关系的子集,而不需要明确的监督,从而使我们能够处理具有挑战性的视觉数据。我们将我们的模型称为判别关系循环网络DRRN。对AVA的动作预测的评估证明了我们提出的方法与更简单的基线相比的有效性。此外,我们显着提高了J HMDB早期行动分类任务的性能,从之前的SOTA 48到60。 |
| Least-squares registration of point sets over SE (d) using closed-form projections Authors Sk. Miraj Ahmed, Niladri Ranjan Das, Kunal Narayan Chaudhury 考虑使用旋转和平移在一些d维空间中注册多个点集的问题。假设存在具有共同点的集合,而且对于这样的集合,已知成对对应关系。我们考虑这个问题的最小二乘公式,其中变量是与点集相关联的变换。目前的新颖性是我们将这个非凸问题简化为优于半正半圆的优化,其中目标是线性的,但约束仍然是非凸的。我们建议使用变量分裂和乘法器ADMM的交替方向方法来解决这个问题。由于目标的线性和约束的结构,ADMM子问题由具有闭合形式解的投影给出。特别地,对于m个点集,每次迭代的主要成本是md乘以md矩阵的部分特征分解,以及d乘以d矩阵的m 1奇异值分解。我们根据经验表明,对于适当的参数设置,所提出的求解器具有较大的收敛流域并且在扰动下是稳定的。作为应用程序,我们使用我们的方法进行2D形状匹配和3D多视图注册。在任一应用中,我们将形状扫描建模为点集,并使用ICP确定成对对应关系。特别地,我们的算法在时间和精度方面与用于多视图重建的现有方法相比是有利的。 |
| Log-barrier constrained CNNs Authors Hoel Kervadec, Jose Dolz, Jing Yuan, Christian Desrosiers, Eric Granger, Ismail Ben Ayed 本研究调查了对CNN的输出施加不等式约束以进行弱监督分割。在深度网络的一般环境中,约束通常用惩罚方法处理,因为它们简单,并且尽管它们具有众所周知的限制。拉格朗日优化在惩罚方法方面具有良好的理论和实践优势,但在很大程度上避免了深度CNN,这主要是由于交替随机优化和双重更新引起的计算复杂性和稳定性收敛问题。最近的几项研究表明,在深度CNN的背景下,拉格朗日优化优于简单惩罚的理论优势在实践中并未实现,其表现令人惊讶地更糟。 |
| Pushing the Envelope for RGB-based Dense 3D Hand Pose Estimation via Neural Rendering Authors Seungryul Baek, Kwang In Kim, Tae Kyun Kim 由于固有的2D 3D映射模糊和有限的训练数据,估计来自单个RGB图像的3D手网是具有挑战性的。我们采用紧凑的参数化3D手模型,代表可变形和铰接式手形网格。为了实现适合RGB图像的模型,我们以三种方式进行研究和贡献1神经渲染受到最近人体工作的启发,我们的手网格估计器HME由神经网络和可微分渲染器实现,由2D分割掩模和3D监督骷髅。 HME表现出良好的性能,可用于估计不同的手形并提高姿势估计的准确性。 2迭代测试改进我们的拟合功能是可微分的。我们在迭代模型拟合方法(如ICP)的精神中,使用梯度迭代地细化初始估计。这一想法得到了人体最新研究的支持。 3自我数据增强收集大小的RGB网格或分割掩模骨架三联体用于训练是一个很大的障碍。一旦模型成功地适合输入RGB图像,其网格即形状和关节是逼真的,并且我们在估计的密集手部姿势之上增加视点。使用三个基于RGB的基准测试的实验表明,我们的框架提供了超出3D姿态估计的最先进精度,以及恢复密集的3D手形状。上述每个技术组件都有意义地提高了消融研究的准确性。 |
| Unsupervised learning of action classes with continuous temporal embedding Authors Anna Kukleva, Hilde Kuehne, Fadime Sener, Juergen Gall 最近,人们越来越关注在未修剪的视频中临时检测和分割动作的任务。在这种情况下的一个问题源于需要定义和标记动作边界以创建用于训练的注释,这是非常耗费时间和成本的。为了解决这个问题,我们提出了一种无监督的方法,用于从未修剪的视频序列中学习动作类。为此,我们使用框架特征的连续时间嵌入来受益于活动的顺序性。基于嵌入创建的潜在空间,我们在所有视频中识别对应于语义有意义的动作类的时间片段的集群。该方法在三个具有挑战性的数据集上进行评估,即早餐数据集,YouTube说明和50Salads数据集。虽然之前的作品假设视频包含相同的高级活动,但我们进一步表明,所提出的方法也可以应用于视频内容未知的更一般的设置。 |
| Revisiting EmbodiedQA: A Simple Baseline and Beyond Authors Yu Wu, Lu Jiang, Yi Yang 在Embodied Question Answering EmbodiedQA中,代理与环境交互以收集回答用户问题所需的信息。现有的工作为解决这个有趣的问题奠定了坚实的基础。但目前的表现,尤其是导航表现,表明EmbodiedQA可能对目前的方法来说太具挑战性。在本文中,我们通过实证研究了这个问题并引入了一个简单而有效的基线,可以通过SGD 2进行端到端优化,为EmbodiedQA提供了一个更简单实用的设置,其中代理有机会将训练过的模型适应新环境它实际上回答用户的问题。在新设置中,我们在新环境中随机放置一些对象,并通过蒸馏网络升级代理策略,以保留训练模型的泛化能力。在EmbodiedQA v1基准测试中,在标准设置下,我们的简单基线在新设置中获得了与现有技术水平相当的非常有竞争力的结果,我们发现设置中引入的微小变化会在导航中产生显着的增益。 |
| Robust Alignment for Panoramic Stitching via an Exact Rank Constraint Authors Yuelong Li, Mohammad Tofighi, Vishal Monga 我们研究了全景拼接的图像对齐问题。与大多数基于特征的现有方法不同,我们的算法直接对像素进行处理,并在全局范围内解决整个图像的错误。从技术上讲,我们将对齐问题表示为秩1,并对变换图像进行稀疏矩阵分解,并开发出一种有效的算法来解决这一具有挑战性的非凸优化问题。该算法简化为求解一系列子问题,我们在分析中建立精确的恢复条件,收敛性和最优性,以及收敛速度和复杂度。我们将其概括为同时对齐多个图像并恢复多个单应性,将其应用范围扩展到绝大多数实际场景。实验结果表明,与现有技术相比,所提出的算法能够更精确地对准图像并生成更高质量的拼接图像。 |
| Learning monocular depth estimation infusing traditional stereo knowledge Authors Fabio Tosi, Filippo Aleotti, Matteo Poggi, Stefano Mattoccia 单个图像的深度估计代表了无数应用中令人着迷但具有挑战性的问题。最近的工作证明,这项任务可以在没有直接监督地面真实标签的情况下学习,利用序列或立体对上的图像合成。着眼于第二种情况,在本文中,我们利用立体匹配来改进单眼深度估计。为此,我们提出了monoResMatch,这是一种新颖的深度架构,旨在通过从不同的视角合成特征,与输入图像水平对齐,在单个输入图像中推断深度,在两个线索之间执行立体匹配。与以前分享这一理论基础的作品相比,我们的网络是第一个从头开始结束的训练端。此外,我们展示了如何通过传统的立体算法(例如半全局匹配)获得代理地面实况注释,通过保持自我监督的方法,能够实现更准确的单眼深度估计,从而抵消对昂贵的深度标签的需求。详尽的实验结果证明了所提出的monoResMatch架构和ii代理监督之间的协同作用如何获得自监督单眼深度估计的现有技术。该代码可在以下网站公开获取 |
| Weighted Point Cloud Augmentation for Neural Network Training Data Class-Imblance Authors David Griffiths, Jan Boehm 最近在3D数据深度学习领域的发展已经证明了直接从点云进行端到端学习的巨大潜力。然而,由于在自然界中观察到的自然类im平衡,许多现实世界点云包含大类im平衡。例如,城市环境的3D扫描将主要由道路和立面组成,而其他对象如杆将不足。在本文中,我们通过使用加权扩充来增加包含较少点的类来解决此问题。通过减少数据中存在的类im平衡,我们证明了标准PointNet深度神经网络可以在验证数据的推断上实现更高的性能。这被观察到两个测试基准数据集ScanNet和Semantic3D的F1得分分别增加19和25,其中没有执行类别im余额预处理。我们的网络在高代表性和低代表性类别上表现更好,这表明当损失函数不过度暴露于少数类时,网络正在学习更强大和有意义的特征。 |
| Leveraging the Invariant Side of Generative Zero-Shot Learning Authors Jingjing Li, Mengmeng Jin, Ke Lu, Zhengming Ding, Lei Zhu, Zi Huang 传统的零射击学习ZSL方法通常学习嵌入(例如,视觉语义映射)以通过间接方式处理看不见的视觉样本。在本文中,我们利用生成对抗网络GAN的优势,提出了一种新的方法,称为利用不变边GAN LisGAN,它可以直接生成由语义描述条件限制的随机噪声中看不见的特征。具体来说,我们训练一个条件Wasserstein GAN,其中发生器合成来自噪声的假看不见的特征,鉴别器通过minimax游戏区分假和真实。考虑到一种语义描述可以对应于各种合成的视觉样本,并且语义描述(比喻性地)是生成特征的灵魂,我们将灵魂样本作为生成零射击学习的不变侧进行介绍。灵魂样本是一个类的元表示。它可视化同一类别中每个样本的最具语义意义的方面。我们规定每个生成的样本生成ZSL的变化侧应该接近至少一个灵魂样本,其中不变侧与其具有相同的类标签。在零射击识别阶段,我们建议使用两个分级器,它们以级联方式部署,以实现粗略到精细的结果。对五个流行基准测试的实验证实,我们提出的方法可以在显着改进的情况下优于最先进的方法。 |
| ContextDesc: Local Descriptor Augmentation with Cross-Modality Context Authors Zixin Luo, Tianwei Shen, Lei Zhou, Jiahui Zhang, Yao Yao, Shiwei Li, Tian Fang, Long Quan 大多数关于学习局部特征的研究都集中在基于补丁的个体关键点描述上,而忽略了从关键点位置建立的空间关系。在本文中,我们通过引入上下文感知来扩展本地特征描述符,从而超越了本地细节表示。具体来说,我们提出了一个统一的学习框架,它利用和聚合交叉模态上下文信息,包括来自高级图像表示的i视觉上下文,以及来自2D关键点分布的ii几何上下文。此外,我们提出了一种有效的N对损失,它避开了经验超参数搜索并改善了收敛性。与原始局部特征描述相比,所提出的增强方案是轻量级的,同时在几个具有多样化场景的大规模基准上得到显着改善,这在几何匹配应用中表现出强大的实用性和泛化能力。 |
| Nucleus Neural Network for Super Robust Learning Authors Jia Liu, Maoguo Gong, Haibo He 模拟大脑神经元和连接结构的人工神经网络在许多问题上取得了巨大的成功,特别是那些深层的问题。在本文中,我们提出了一个核神经网络NNN和相应的架构和参数学习方法。在细胞核中,没有规则层,即神经元可以连接到细胞核中的所有神经元。这种架构摆脱了层次限制,可能会带来更强大的学习能力。确定给定众多神经元的连接至关重要。基于更相关的输入和输出神经元对值得更高的连接密度的原理,我们提出了核的架构学习模型。此外,我们提出了一种改进的学习方法,用于学习连接权重和偏差与优化的体系结构。我们发现这种新颖的架构对于测试数据中不相关的组件是健壮的。因此,我们定义了一个超级健壮的学习问题,并测试了所提出的网络,其中一个案例是训练和测试集中的图像背景类型不同。实验表明,所提出的学习者在重建数据集上实现了对传统学习者的显着改进。 |
| Weakly Supervised Semantic Segmentation of Satellite Images Authors Adrien Nivaggioli, Hicham Randrianarivo CEDRIC 当想要训练神经网络来执行语义分割时,为数据库中的每个图像创建像素级注释是一项繁琐的任务。如果他使用通常非常大的航拍或卫星图像,情况会更糟。考虑到这一点,我们研究如何使用图像级注释来执行语义分割。获取图像级注释要比像素级注释便宜得多,但是我们为模型的训练丢失了大量信息。从图像的注释中,模型必须自己找到如何对图像的不同区域进行分类。在这项工作中,我们使用Anh和Kwak 1提出的方法从图像级注释产生像素级注释。我们将生成的数据集的整体质量与原始数据集进行比较。此外,我们提出了AffinityNet的改编版,它允许我们直接执行语义分割。我们的结果表明,生成的标签在几个分割网络的训练中具有相同的性能。此外,AffinityNet和随机漫步直接执行的语义分割的质量接近于最好的全监督方法之一。 |
| Simultaneous Spectral-Spatial Feature Selection and Extraction for Hyperspectral Images Authors Lefei Zhang, Qian Zhang, Bo Du, Xin Huang, Yuan Yan Tang, Dacheng Tao 在高光谱遥感数据挖掘中,重要的是考虑光谱和空间信息,例如光谱特征,纹理特征和形态特性,以改善性能,例如图像分类精度。在特征表示的角度来看,处理这种情况的一种自然方法是将光谱和空间特征连接成单个但高维度的矢量,然后直接在该连接矢量上应用某种降维技术,然后将其输入后续分类器。然而,来自不同领域的多个特征肯定具有不同的物理意义和统计特性,因此这种连接不能有效地探索不同特征之间的互补特性,这将有利于提高特征可辨性。此外,还难以解释级联向量的变换结果。因此,找到具有物理意义的共识低原始多特征的低维特征表示仍然是一项具有挑战性的任务。为了解决这些问题,我们提出了一种新颖的特征学习框架,即同时光谱空间特征选择和提取算法,用于高光谱图像光谱空间特征表示和分类。具体地,所提出的方法通过将光谱空间特征投影到共同特征空间来学习潜在的低维子空间,其中互补信息已被有效地利用,同时,仅变换了最重要的原始特征。在三个公共可用的高光谱遥感数据集上鼓励实验结果证实了我们提出的方法是有效和高效的。 |
| VayuAnukulani: Adaptive Memory Networks for Air Pollution Forecasting Authors Divyam Madaan, Radhika Dua, Prerana Mukherjee, Brejesh Lall 由于各种来源,包括工厂排放,汽车尾气和炉灶,空气污染是全球领先的环境健康危害。作为预防措施,空气污染预测是采取有效污染控制措施的基础,准确的空气污染预测已成为一项重要任务。在本文中,我们根据中央污染控制委员会报告的历史和实时环境空气质量和气象数据,预测德里5个显着位置的细粒度环境空气质量信息。我们提出了VayuAnukulani系统,这是一种新颖的端到端解决方案,通过估算德里的二氧化氮NO 2,颗粒物PM 2.5和PM 10等不同空气污染物的浓度和水平来预测未来24小时的空气质量。在德里获得的关于数据源的大量实验表明,所提出的基于自适应注意的双向LSTM网络优于分类和回归模型的几个基线。所提出的自适应系统的准确性比相同的离线训练模型更好。我们在几个竞争基线上比较了所提出的方法,并表明网络优于传统方法的sim 3 5。 |
| Adaptive Morphological Reconstruction for Seeded Image Segmentation Authors Tao Lei, Xiaohong Jia, Tongliang Liu, Shigang Liu, Hongying Meng, Asoke K. Nandi 形态重建MR通常用于种子图像分割算法,例如分水岭变换和功率分水岭,因为它能够过滤种子区域最小值以减少过度分割。然而,MR可能错误地过滤了生成精确分割所需的有意义的种子,并且它也对比例敏感,因为采用单一比例结构元素。本文提出了一种新的自适应形态重建AMR操作,具有三个优点。首先,AMR可以自适应地过滤无用的种子,同时保留有意义的种子。其次,AMR对结构元素的规模不敏感,因为采用了多尺度结构元素。最后,AMR具有两个有吸引力的属性单调增加和收敛,有助于种子分割算法实现分层分割。实验清楚地表明AMR可用于改进种子图像分割和基于种子的光谱分割的算法。与几种现有技术算法相比,所提出的算法提供了更好的分割结果,需要更少的计算时间。源代码可在以下位置获得 |
| Meta Filter Pruning to Accelerate Deep Convolutional Neural Networks Authors Yang He, Ping Liu, Linchao Zhu, Yi Yang 现有方法通常利用预定义的标准,例如p norm,来修剪不重要的过滤器。这些方法有两个主要限制。首先,过滤器的关系在很大程度上被忽略了。过滤器通常共同工作以协作方式进行准确预测。类似的滤波器将对网络预测产生相同的影响,并且可以进一步修剪冗余滤波器。其次,修剪标准在训练期间保持不变。随着网络在每次迭代时更新,过滤器分布也会不断变化。修剪标准也应该自适应地切换。在本文中,我们提出了Meta Filter Pruning MFP来解决上述问题。首先,作为对现有p范数准则的补充,我们引入了一种新的修剪标准,考虑了滤波器关系的滤波器关系。此外,我们为过滤器修剪构建了一个元修剪框架,以便我们的方法可以在过滤器分布发生变化时自适应地选择最合适的修剪标准。实验验证了我们在两个图像分类基准上的方法。值得注意的是,在ILSVRC 2012上,我们的MFP在ResNet 50上减少了超过50个FLOP,仅有0.44个前5个精度损失。 |
| Kervolutional Neural Networks Authors Chen Wang, Jianfei Yang, Lihua Xie, Junsong Yuan 卷积神经网络CNN在许多计算机视觉任务中实现了最先进的性能。然而,很少有人致力于在非线性空间中建立卷积。现有工作主要利用激活层,激活层只能提供逐点非线性。为了解决这个问题,引入了一种新的操作,即kervolution内核卷积,以利用内核技巧来近似人类感知系统的复杂行为。它概括了卷积,增强了模型容量,并通过补丁核心函数捕获了特征的更高阶交互,但没有引入额外的参数。广泛的实验表明,kervolutional神经网络KNN比基线CNN获得更高的准确性和更快的收敛。 |
| Improving Image Classification Robustness through Selective CNN-Filters Fine-Tuning Authors Alessandro Bianchi, Moreno Raimondo Vendra, Pavlos Protopapas, Marco Brambilla 图像质量在基于CNN的图像分类性能中起着重要作用。对于大型网络,使用失真样本对网络进行微调可能成本太高。为了解决这个问题,我们提出了一种优化的转移学习方法,以便考虑到在CNN的每一层中,某些滤波器比其他滤波器更容易受到图像失真的影响。我们的方法识别最易受影响的滤波器,并仅对在清洁和失真图像之间显示最高激活图距离的滤波器应用重新训练。使用Borda计数选择方法对过滤器进行排名,然后仅对受影响最大的过滤器进行微调。这显着减少了重新训练的参数数量。我们在CIFAR 10和CIFAR 100数据集上评估这种方法,在两种不同的模型和两种不同类型的失真上进行测试。结果表明,由于减少了微调参数的数量,所提出的传递学习技术由于输入数据失真而以相当快的速度恢复了大部分丢失的性能。当为训练提供很少的噪声样本时,我们的滤波器级微调表现得特别好,也优于现有技术的层级传输学习方法。 |
| Variational Uncalibrated Photometric Stereo under General Lighting Authors Bjoern Haefner, Zhenzhang Ye, Maolin Gao, Tao Wu, Yvain Qu au, Daniel Cremers 如今,光度立体PS技术仍然受限于理想的实验室设置,其中照明的建模和校准是合适的。这项工作旨在消除这种限制。为此,我们在一般照明下引入了未校准PS的有效原理变分方法,该方法通过二阶球谐函数展开来近似。形状,反射率和光照的联合恢复被公式化为变分问题,其中形状估计直接根据基础透视深度图执行,从而隐含地确保可积性并且绕过对后续正常积分的需要。我们提供量身定制的数值方案,以有效和稳健地解决由此产生的非凸问题。在各种评估中,与现有技术相比,我们的方法始终将平均角度误差减小了2倍。 |
| Minimal Solvers for Mini-Loop Closures in 3D Multi-Scan Alignment Authors Pedro Miraldo, Surojit Saha, Srikumar Ramalingam 在诸如Kinect和Velodyne之类的3D传感器的背景下,3D扫描配准是经典但非常有用的问题。虽然存在若干现有方法,但是这些技术通常是递增的,其中首先登记相邻扫描以获得初始姿势,然后进行运动平均和束调整细化。在本文中,我们采用了不同的方法,并开发了最小的求解器,用于联合计算小循环(如3,4和5个循环)中摄像机的初始姿态。注意,可以使用最少3点匹配来完成2次扫描的经典配准,以计算6度的相对运动。另一方面,为了共同计算n个周期中的3D配准,我们在前n个连续对之间进行2点匹配,即扫描1扫描2,...,扫描n 1扫描n和1或2个点匹配在扫描1和扫描之间。总的来说,我们使用5,7和10个点匹配3,4和5个循环,并分别恢复12,18和24度的变换变量。使用模拟和真实数据,我们表明使用mini n循环的3D配准在计算上是有效的,并且与标准成对方法相比可以提供替代的和更好的初始姿势。 |
| Sim-Real Joint Reinforcement Transfer for 3D Indoor Navigation Authors Fengda Zhu, Linchao Zhu, Yi Yang 人们对3D室内导航越来越感兴趣,其中环境中的机器人根据指令移动到目标。要在物理世界中部署用于导航的机器人,需要大量的培训数据来学习有效的策略。为训练机器人获得足够的真实环境数据是非常劳动密集的,而合成数据通过渲染更容易构建。虽然有利于利用合成环境来促进现实世界中的导航训练,但真实环境在两个方面与合成环境不同。首先,两种环境的视觉表示具有显着的差异。其次,这两种环境的计划是完全不同的。有两种类型的信息,即。视觉表现和政策行为,需要在强化模型中进行调整。视觉表征和政策行为的学习过程可能是互惠的。我们建议联合调整视觉表现和政策行为,以利用环境和政策的相互影响。具体而言,我们的方法采用对抗特征适应模型进行视觉表示转移,并采用政策模仿策略进行政策行为模仿。实验表明,我们的方法在19.47之前优于基线,没有任何额外的人类注释。 |
| From Patch to Image Segmentation using Fully Convolutional Networks - Application to Retinal Images Authors Taibou Birgui Sekou, Moncef Hidane, Julien Olivier, Hubert Cardot 通常,基于深度学习的模型需要大量样本用于适当的训练,这在医学领域难以满足。通过正确初始化权重,通常可以避免此问题。在一般的医学图像分割任务中,通常采用两种技术来解决深度网络f T的训练。第一个包括重新使用在大规模数据库上预训练的网络的一些权重,例如, ImageNet。这个过程,也称为文本传输学习,恰好会降低新网络设计的灵活性,因为f T被约束为匹配f S的某些部分。第二种常用技术包括处理图像补丁以从大量可用补丁中受益。本文将这两种技术结合起来,并提出培训任意设计的网络,重点是相对较小的数据库,分两阶段补丁预训练和全尺寸图像微调。利用四个公开可用的数据库,对视网膜血管分割和视盘血管分割的任务进行了实验工作。此外,考虑三种类型的网络,从非常轻的网络到密集连接的网络。最终结果显示了所提出的框架的效率以及所有数据库的最新结果。 |
| Referring to Objects in Videos using Spatio-Temporal Identifying Descriptions Authors Peratham Wiriyathammabhum, Abhinav Shrivastava, Vlad I. Morariu, Larry S. Davis 本文提出了一个新的任务,即视频中时空识别描述的基础。以前的工作表明现有数据集存在潜在偏差,并强调需要新的数据创建模式来更好地模拟语言结构。我们引入了一种基于表面实现的语法约束的新数据收集方案,使我们能够研究视频中基于时空识别描述的基础问题。然后,我们提出了一个双流模块化注意网络,该网络基于外观和运动来学习和理论时空识别描述。我们展示了运动模块有助于地面运动相关单词,也有助于学习外观模块,因为模块化神经网络解决了模块之间的任务干扰。最后,我们提出了一个未来的挑战,并需要一个强大的系统,因为用自动视频对象检测器和时间事件定位替换地面真实视觉注释。 |
| Streamlined Dense Video Captioning Authors Jonghwan Mun, Linjie Yang, Zhou Ren, Ning Xu, Bohyung Han 密集视频字幕是一项极具挑战性的任务,因为视频中事件的准确和连贯的描述需要全面了解视频内容以及个别事件的上下文推理。大多数现有方法通过首先从视频中检测事件提议然后对提议的子集进行字幕处理来处理该问题。结果,生成的句子倾向于冗余或不一致,因为它们不能考虑事件之间的时间依赖性。为了应对这一挑战,我们提出了一种新颖的密集视频字幕框架,它可以明确地模拟视频中事件的时间依赖性,并利用先前事件的视觉和语言环境进行连贯的叙事。该目标通过1整合事件序列生成网络以自适应地选择事件提议序列来实现,并且2将事件提议序列馈送到我们的顺序视频字幕网络,该网络通过强化学习在两个事件和两个级别奖励进行训练。剧集级别用于更好的上下文建模。在大多数指标中,所提出的技术在ActivityNet Captions数据集上实现了出色的性能。 |
| Noise-Aware Unsupervised Deep Lidar-Stereo Fusion Authors Xuelian Cheng, Yiran Zhong, Yuchao Dai, Pan Ji, Hongdong Li 在本文中,我们介绍了LidarStereoNet,这是第一个无监督的激光雷达立体融合网络,可以在不需要地面实况深度图的情况下以端到端的方式进行训练。通过引入一种新颖的反馈回路将网络输入与输出连接起来,LidarStereoNet可以解决现有激光雷达立体声融合研究中忽略的噪声激光雷达点和传感器之间的不对准问题。此外,我们建议将分段平面模型结合到网络学习中,以进一步约束深度以符合基础3D几何。对真实和合成数据集进行广泛的定量和定性评估,证明了我们的方法的优越性,该方法优于现有技术的立体匹配,深度完成和激光雷达立体融合方法。 |
| Unsupervised Deep Epipolar Flow for Stationary or Dynamic Scenes Authors Yiran Zhong, Pan Ji, Jianyuan Wang, Yuchao Dai, Hongdong Li 用于光流计算的无监督深度学习已经取得了有希望的结果。大多数现有的基于深度网的方法依赖于图像亮度一致性和局部平滑度约束来训练网络。它们的性能在重复纹理或遮挡发生的区域会降低。在本文中,我们提出了Deep Epipolar Flow,一种无监督的光流方法,它将全局几何约束结合到网络学习中。特别是,我们研究了在流量估算中强制执行极线约束的多种方法。为了减轻在可能存在多个运动的动态场景中遇到的鸡和蛋类型问题,我们提出了低秩约束以及用于训练的子空间约束的并集。各种基准数据集的实验结果表明,与监督方法相比,我们的方法实现了竞争性能,并且优于现有技术的无监督深度学习方法。 |
| Decomposition-Based Transfer Distance Metric Learning for Image Classification Authors Yong Luo, Tongliang Liu, Dacheng Tao, Chao Xu 距离度量学习DML是图像分析和模式识别的关键因素。为了学习目标任务的鲁棒距离度量,我们需要丰富的辅助信息,即标记数据上的相似性不相似成对约束,这在实践中通常由于高标签成本而不可用。本文通过利用来自某些相关但不同的源任务的大量辅助信息来考虑转移学习设置,以帮助仅用少量辅助信息进行目标度量学习。最先进的度量学习算法通常在此设置中失败,因为源任务和目标任务的数据分布通常非常不同。我们通过假设目标距离度量位于由源度量或其他随机生成的基数的特征向量跨越的空间中来解决该问题。目标度量表示为基本度量的组合,其使用源度量的分解的组件或仅仅是我们称为所提出的方法的基于分解的传递DML DTDML的一组随机碱来计算。特别是,DTDML通过强制目标度量接近源度量的集成来学习基本度量的稀疏组合以构建目标度量。与现有的传递度量学习方法相比,所提出的方法的主要优点是我们直接学习基础度量系数而不是目标度量。为此,需要学习的变量要少得多。因此,鉴于有限的辅助信息,我们获得了更可靠的解决方案,并且优化趋于更快。对流行的手写图像数字,字母分类和挑战自然图像注释任务的实验证明了该方法的有效性。 |
| Weakly Supervised Person Re-identification: Cost-effective Learning with A New Benchmark Authors Guangrun Wang, Guangcong Wang, Xujie Zhang, Jianhuang Lai, Liang Lin 人员识别ReID极大地受益于现有数据集的准确注释,例如CUHK03引用li2014deepreid和Market 1501引用zheng2015scalable,这非常昂贵,因为必须为这些数据集中的每个图像分配适当的标签。在这项工作中,我们探索通过用不准确的注释替换准确的注释来简化ReID的注释,即,我们将图像按时间分组为袋子并为每个袋子分配袋子级别标签。这大大减少了注释工作量,并导致创建称为SYSU 30 k的大规模ReID基准测试。新基准包含30k类人员,比CUHK03 1.3k类别和市场1501 1.5k类别大约20倍,ImageNet 1k类别大30倍。它总共达到了29,606,918张图片。使用行级注释学习ReID模型称为弱监督的ReID问题。为了解决这个问题,我们引入条件随机字段CRF来捕获包中所有图像的依赖关系,并为每个人图像生成可靠的伪标签。伪标签还用于监督ReID模型的学习。与完全监督的ReID模型相比,我们的方法在SYSU 30 k和其他数据集上实现了最先进的性能。代码,数据集和预训练模型将在线提供。 |
| Weakly Supervised Person Re-Identification Authors Jingke Meng, Sheng Wu, Wei Shi Zheng 在传统的人物设置中,假设标记图像是每个个体的边界框内的人物图像,这种来自原始视频监视的多个非重叠相机视图上的标记是昂贵且耗时的。为了克服这个困难,我们考虑弱监督的人物重建模型。弱设置是指将目标人物与未修剪的画廊视频匹配,其中我们仅知道身份出现在视频中而不需要在训练过程期间在视频的任何帧中注释身份。因此,对于视频,可能存在多个视频级标签。我们将这个弱受监督的人员重新挑战转变为多实例多标签学习MIML问题。特别地,我们开发了一种Cross View MIML CV MIML方法,该方法能够通过结合袋内对齐和交叉视图袋对齐来探索来自所有相机视图的潜在的类内人物图像。最后,将CV MIML方法嵌入到现有的深度神经网络中,以开发Deep Cross View MIML Deep CV MIML模型。我们已经进行了大量的实验来证明所提出的弱监督设置的可行性,并验证了我们的方法与四个弱标记数据集的相关方法相比的有效性。 |
| Ensemble Teaching for Hybrid Label Propagation Authors Chen Gong, Dacheng Tao, Xiaojun Chang, Jian Yang 标签传播旨在通过相似性图形迭代地将标记信息从标记示例扩散到未标记示例。当前标签传播算法不能始终如一地产生令人满意的性能,原因有两个原因:一种是单一传播方法在处理各种实际数据时的不稳定性,另一种是不适当的传播序列,忽略了不同实例的标记困难。为了弥补上述缺陷,本文提出了一种新的传播算法,即在HyDEnT集成教学下称为混合扩散。具体而言,HyDEnT将多种传播方法作为基础学习者集成,以充分利用其个人智慧,这有助于HyDEnT稳定并获得一致的令人鼓舞的结果。更重要的是,HyDEnT在一群教师的指导下进行传播。也就是说,在每个传播回合中,最简单的课程示例由教学算法明智地指定,使得他们的标签可以由学习者可靠且准确地确定。为了最佳地选择这些最简单的例子,整体中的每位教师都应该从自己的角度全面考虑这些例子的困难,以及所有教师共有的共同知识。这是通过设计的优化问题来实现的,该优化问题可以通过块坐标下降法有效地解决。由于教师的努力,所有未标记的示例在逻辑上从简单传播到困难,导致HyDEnT的传播质量比现有方法更好。 |
| Towards Real-Time Automatic Portrait Matting on Mobile Devices Authors Seokjun Seo, Seungwoo Choi, Martin Kersner, Beomjun Shin, Hyungsuk Yoon, Hyeongmin Byun, Sungjoo Ha 我们解决了移动设备上自动纵向遮罩的问题。所提出的模型旨在实现对移动设备的实时推断,同时模型性能的降低最小。我们的模型MMNet基于具有线性瓶颈块的多分支扩张卷积,优于现有技术模型,并且速度提高了几个数量级。该模型可以加速四次,在小米米5设备上达到30 FPS,梯度误差适度增加。在相同条件下,我们的模型的参数数量减少了一个数量级,并且比Mobile DeepLabv3更快,同时保持了相当的性能。随附的实施可以在网址找到 |
| Visual Localization Using Sparse Semantic 3D Map Authors Tianxin Shi, Shuhan Shen, Xiang Gao, Lingjie Zhu 在各种观察条件变化(包括季节和照明变化以及天气和夜间变化)下,准确而强大的视觉定位是许多计算机视觉和机器人应用的关键组成部分。在这些条件下,大多数传统方法都无法定位相机。在本文中,我们提出了一种视觉定位算法,它将基于结构的方法和基于图像的方法与语义信息相结合。给定关于查询和数据库图像的语义信息,根据3D模型和查询图像的语义一致性对检索到的图像进行评分。然后将语义匹配分数用作RANSAC采样的权重,并通过标准PnP求解器求解姿势。对具有挑战性的长期视觉定位基准数据集的实验表明,与现有技术相比,我们的方法具有显着的改进。 |
| FoveaBox: Beyond Anchor-based Object Detector Authors Tao Kong, Fuchun Sun, Huaping Liu, Yuning Jiang, Jianbo Shi 我们介绍FoveaBox,一个准确,灵活,完全无锚的物体检测框架。虽然几乎所有现有技术的物体检测器都利用预定义的锚点来枚举用于搜索物体的可能的位置,比例和纵横比,但是它们的性能和概括能力也限于锚的设计。相反,FoveaBox直接学习对象现有的可能性和边界框坐标而没有锚引用。这是通过为对象存在的可能性预测类别敏感的语义映射来实现的,并且b为可能包含对象的每个位置生成类别不可知的边界框。目标框的比例自然地与每个输入图像的特征金字塔表示相关联。在没有花里胡哨的情况下,FoveaBox在标准COCO检测基准上实现了42.1 AP的最先进的单一模型性能。特别是对于具有任意宽高比的物体,与基于锚的探测器相比,FoveaBox带来了显着的改进。更令人惊讶的是,当受到拉伸测试图像的挑战时,FoveaBox对于改变的边界框形状分布表现出很强的鲁棒性和泛化能力。该代码将公开发布。 |
| Resource Constrained Neural Network Architecture Search Authors Yunyang Xiong, Ronak Mehta, Vikas Singh 神经网络架构的设计通常基于使用试验误差和经验反馈的人类专业知识,或者通过在不同的离散架构选择上运行的大规模强化学习策略来解决。在后一种情况下,优化任务是不可微分的,也不太适合衍生自由优化方法。目前使用的大多数方法都需要过高的计算资源。如果我们想要额外满足资源限制的网络,则上述挑战会加剧,因为搜索程序现在必须在准确性与资源的某些预算约束之间取得平衡。我们将这个问题表述为集合函数的优化,我们发现这个集合函数的经验行为经常但并不总是满足子模块化思想中的边际增益和单调性原则属性。基于这种观察,我们调整离散优化中众所周知的算法,以获得神经网络架构搜索的启发式方案,对架构有资源限制。这种简单的方案应用于CIFAR 100和ImageNet时,可以识别资源受限的架构,其性能可以比为移动设备设计的当前最先进的模型具有更好的性能。具体来说,我们通过更快的搜索方法找到具有更少参数和计算的高性能体系结构。 |
| ANTNets: Mobile Convolutional Neural Networks for Resource Efficient Image Classification Authors Yunyang Xiong, Hyunwoo J. Kim, Varsha Hedau 深度卷积神经网络在计算机视觉方面取得了显着成功。然而,深度神经网络需要大量计算资源才能实现高性能。尽管深度可分离卷积可以是接近标准卷积的有效模块,但它通常会导致网络的代表能力降低。在本文中,在计算成本MAdds和参数计数等预算约束下,我们提出了一种新的基本架构块ANTBlock。它通过在高维空间中对ANTBlocks中的深度卷积层和投影层之间的通道的相互依赖性进行建模来提高表征能力。我们的实验表明,由一系列ANTBlock构建的ANTNet始终优于跨多个数据集的最先进的低成本移动卷积神经网络。在CIFAR100上,我们的模型实现了75.7的前1精度,比MobileNetV2高1.5,参数减少8.3,计算成本减少19.6。在ImageNet上,我们的模型实现了72.8的前1精度,这是0.8改进,在iPhone 5s上比MobileNetV2快157.7ms 20。 |
| Meta-Learning with Differentiable Convex Optimization Authors Kwonjoon Lee, Subhransu Maji, Avinash Ravichandran, Stefano Soatto 许多用于少数镜头学习的元学习方法依赖于简单的基础学习者,例如最近邻分类器。然而,即使在少数射击机制中,经过有区别训练的线性预测器也可以提供更好的泛化。我们建议使用这些预测器作为基础学习者来学习少数镜头学习的表示,并表明它们在一系列镜头识别基准测试中提供了特征尺寸和性能之间更好的权衡。我们的目标是学习在新的类别的线性分类规则下很好地概括的特征嵌入。为了有效地求解目标,我们利用线性分类器的两个性质隐式区分凸问题的最优性条件和优化问题的双重表达式。这允许我们使用高维嵌入,并且在适度增加计算开销的情况下具有改进的泛化。我们的方法名为MetaOptNet,在miniImageNet,tieredImageNet,CIFAR FS和FC100少数镜头学习基准测试中实现了最先进的性能。 |
| Can GCNs Go as Deep as CNNs? Authors Guohao Li, Matthias M ller, Ali Thabet, Bernard Ghanem 卷积神经网络CNN在各种领域取得了令人瞩目的成果。他们的成功得益于能够训练非常深的CNN模型的巨大推动力。尽管取得了积极的成果,但CNN未能正确解决非欧几里德数据的问题。为了克服这一挑战,图形卷积网络GCN构建图表来表示非欧几里德数据,并从CNN借用概念并应用它们来训练这些模型。 GCN显示出有希望的结果,但由于梯度消失问题,它们仅限于非常浅的模型。因此,大多数现有技术的GCN算法都不会超过3或4层。在这项工作中,我们提出了成功训练非常深的GCN的新方法。我们从CNN借用概念,主要是残余密集连接和扩张卷积,并使它们适应GCN架构。通过大量实验,我们展示了这些深度GCN框架的积极作用。最后,我们使用这些新概念构建了一个非常深的56层GCN,并展示了它在点云语义分割任务中如何显着提升3.7 mIoU的性能。项目网站可在 |
| Measuring Human Perception to Improve Handwritten Document Transcription Authors Samuel Grieggs, Bingyu Shen, Pei Li, Cana Short, Jiaqi Ma, Mihow McKenny, Melody Wauke, Brian Price, Walter Scheirer 视觉科学家通过使用心理物理学来衡量人类感知的微妙之处,是视觉识别内部运作的重要线索。例如,测量的反应时间可以指示视觉刺激是否容易被主体识别,或者是否很难。在本文中,我们考虑如何将视觉感知的心理物理测量结合到被训练用于识别任务的深度神经网络的损失函数中,假设这样的信息可以强制与人类行为的一致性。作为评估这种方法可行性的案例研究,我们研究了手写文档转录的问题。虽然在自动转录现代笔迹方面取得了良好进展,但在抄写历史文件方面仍存在重大挑战。在这里,我们致力于为中世纪手稿提供全面的转录解决方案,将使用我们的新型损失公式训练的网络与自然语言处理元素相结合。在基线评估中,标准IAM和RIMES数据集的可靠性能得到了证明。此外,我们继续展示我们对先前发布的数据集和数字化拉丁文手稿的新数据集的可行性,这些数据集最初是由9世纪中叶的圣加尔修道院的文士制作的。 |
| Planar Geometry and Latest Scene Recovery from a Single Motion Blurred Image Authors Kuldeep Purohit, Subeesh Vasu, M. Purnachandra Rao, A. N. Rajagopalan 关于运动去模糊的现有工作要么忽略深度相关模糊的影响,要么假设多层场景,其中每个层以前平行平面的形式建模。在这项工作中,我们考虑具有分段平面结构的3D场景的情况,即,可以被建模为具有任意取向的多个平面的组合的场景。我们首先提出一种从单个运动模糊观察中估计平面场景的法线的方法。然后,我们开发一种算法,用于自动恢复多个平面,对应于每个平面的参数,以及来自多平面3D场景的单个运动模糊图像的相机运动。最后,我们提出了第一种通过采用基于我们的研究结果的交替最小化框架来恢复场景的平面几何和潜像的方法。对合成和真实数据的实验表明,我们提出的方法达到了最先进的结果。 |
| A Novel Apex-Time Network for Cross-Dataset Micro-Expression Recognition Authors Min Peng, Chongyang Wang, Tao Bi, Tong Chen, XiangDong Zhou, Yu shi 自成功引入深度学习方法以来,微表达的自动识别得到了提升。虽然研究这些主题的研究人员越来越倾向于从微观表达的本质中学习,但使用深度学习技术的实践已经从处理微表达的整个视频剪辑发展到顶点框架上的识别。使用顶点框架能够摆脱冗余信息,但是因此省略了微表达的时间证据。在本文中,我们建议基于来自顶点帧的空间信息以及来自各个相邻帧的时间信息进行识别。因此,提出了一种新颖的Apex时间网络ATNet。通过对三个基准测试的广泛实验,我们通过添加从顶点框架周围的相邻帧学习的时间信息来证明所实现的改进。特别地,具有这种时间信息的模型在交叉数据集验证中更加健壮。 |
| Unsupervised Domain Adaptation for Multispectral Pedestrian Detection Authors Dayan Guan, Xing Luo, Yanpeng Cao, Jiangxin Yang, Yanlong Cao, George Vosselman, Michael Ying Yang 多模态信息(例如,可见和热)可以生成稳健的行人检测以便于全天候计算机视觉应用,例如自动驾驶和视频监视。然而,在没有手动注释的情况下训练可靠的探测器在不同的多光谱行人数据集中工作仍然是一个至关重要的挑战。在本文中,我们提出了一种用于多光谱行人检测的新型无监督域自适应框架,通过迭代生成伪注释并更新我们设计的多目标行人探测器在目标域上的参数。使用在源域上训练的检测器生成伪注释,然后通过固定检测器的参数并最小化交叉熵损失而不反向传播来更新伪注释。通过考虑良好对齐的可见和红外图像对之间的相似性和互补性的特征,使用伪注释生成训练标签。通过使用反向传播最小化我们定义的多检测损失函数,使用生成的标签更新检测器的参数。在迭代更新伪注释和参数之后,可以获得检测器的最佳参数。实验结果表明,我们提出的无监督多模态域自适应方法比没有域自适应的方法具有更高的检测性能,并且与监督的多光谱行人检测器相比具有竞争力。 |
| Robust Building-based Registration of Airborne LiDAR Data and Optical Imagery on Urban Scenes Authors Thanh Huy Nguyen, Sylvie Daniel, Didier Gueriot, Christophe Sintes, Jean Marc Le Caillec 本文的动机是解决在不同时间,不同观点和细节层面登记从不同平台获取的机载激光雷达数据和光学天线或卫星图像的问题。在本文中,我们提出了一种基于建筑区域的稳健配准方法,使用均值移位分割从光学图像中提取,并使用3D点云滤波过程从LiDAR数据中提取。然后使用图形变换匹配GTM执行所提取的建筑物片段的匹配,其允许确定片段中心的相对位置的共同模式。由于这种注册,数据集之间的相对位移显着减少,这使得随后的精确配准和由此产生的高质量数据融合成为可能。 |
| Real-Time Quality Assessment of Pediatric MRI via Semi-Supervised Deep Nonlocal Residual Neural Networks Authors Siyuan Liu, Kim Han Thung, Weili Lin, Pew Thian Yap, DinggangShen 在本文中,我们介绍了儿童T1和T2加权MR图像的图像质量评估IQA方法。首先使用非局部残留神经网络NR Net以切片方式执行IQA,然后通过使用随机森林对切片QA结果进行聚集来逐卷地进行。我们的方法仅需要少量用于训练的高质量注释图像,并且被设计为对由于评估者错误以及图像体积中的好的和坏的切片的不可避免的混合而可能发生的注释噪声具有鲁棒性。使用一小组质量评估图像,我们预先训练NR Net以初始质量等级来注释每个图像切片,即通过,可疑,失败,然后我们通过半监督学习和迭代自我训练来改进。实验结果表明,我们的方法仅使用适度大小的样本进行训练,具有很好的通用性,能够实现每体积大规模IQA的实时毫秒,并具有接近完美的精度。 |
| Learning to Learn Relation for Important People Detection in Still Images Authors Wei Hong Li, Fa Ting Hong, Wei Shi Zheng 人类可以很容易地认识到人们在社交活动图像中的重要性,他们总是关注最重要的个体。然而,学习如何学习图像中人与人之间的关系,并根据这种关系推断出最重要的人,仍未得到发展。在这项工作中,我们提出了一个深刻的关联NeTwork POINT,它结合了关系建模和特征学习。特别地,我们推断两种类型的交互模块:人员交互模块,其学习人与人之间的交互,并且事件人交互模块学习描述人如何参与图像中发生的事件。然后,我们估计来自两个交互的人们之间的重要性关系,并从重要性关系中编码关系特征。通过这种方式,POINT自动并行地学习几种类型的关系特征,并将这些关系特征和人的特征进行聚合,形成重要人物分类的重要性特征。广泛的实验结果表明,我们的方法对于重要人群的检测和验证学习关系的有效性对于重要人群的检测是有效的。 |
| Adaptive NMS: Refining Pedestrian Detection in a Crowd Authors Songtao Liu, Di Huang, Yunhong Wang 人群中的行人检测是一个非常具有挑战性的问题。本文通过一种新颖的非最大抑制NMS算法来解决这个问题,以更好地改进探测器给出的边界框。贡献是三倍1我们提出自适应NMS,它将动态抑制阈值应用于实例,根据目标密度2我们设计了一个有效的子网来学习密度分数,可以方便地嵌入到单级和两级探测器中3我们在CityPersons和CrowdHuman基准测试中取得了最先进的成果。 |
| Learning Metrics from Teachers: Compact Networks for Image Embedding Authors Lu Yu, Vacit Oguz Yazici, Xialei Liu, Joost van de Weijer, Yongmei Cheng, Arnau Ramisa 度量学习网络用于计算图像嵌入,其广泛用于许多应用,例如图像检索和面部识别。在本文中,我们建议使用网络蒸馏来有效地计算小网络的图像嵌入。网络蒸馏已成功应用于改进图像分类,但几乎没有探索过度量学习。为此,我们提出了两种新的损失函数,用于模拟深度教师网络与小型学生网络的通信。我们在几个数据集中评估我们的系统,包括CUB 200 2011,Cars 196,Stanford Online Products,并表明使用小型学生网络计算的嵌入比使用类似大小的标准网络计算的嵌入性要好得多。在可以在移动设备上使用的非常紧凑的网络MobileNet 0.25上的结果表明,所提出的方法可以大大改善Recall 1的结果,从27.5到44.6。此外,我们研究了嵌入蒸馏的各个方面,包括提示和注意层,半监督学习和交叉质量蒸馏。代码可在 |
| A Facial Affect Analysis System for Autism Spectrum Disorder Authors Beibin Li, Sachin Mehta, Deepali Aneja, Claire Foster, Pamela Ventola, Frederick Shic, Linda Shapiro 在本文中,我们介绍了一种基于端到端机器学习的系统,用于使用表情,动作单元,唤醒和效价等面部属性对自闭症谱系障碍ASD进行分类。我们的系统使用来自卷积神经网络的不同面部属性的表示来对ASD进行分类,所述卷积神经网络在野外的图像上训练。我们的实验结果表明,我们系统中使用的不同面部属性具有统计学意义,并且大大提高了ASD分类的敏感性,特异性和F1分数。特别地,添加不同的面部属性将ASD分类的性能提高了约7,从而实现了76得分。 |
| Recovering Faces from Portraits with Auxiliary Facial Attributes Authors Fatemeh Shiri, Xin Yu, Fatih Porikli, Richard Hartley, Piotr Koniusz 从艺术肖像中恢复逼真的面孔是一项具有挑战性的任务,因为关键的面部细节往往在艺术作品中被扭曲或完全丢失。为了应对这种损失,我们提出了一种利用人脸恢复网络FRN和判别网络DN的Portraits AFRP的属性引导人脸恢复。 FRN由具有残余块嵌入式跳过连接的自动编码器组成,并且将面部属性向量合并到自动编码器瓶颈处的输入肖像的特征映射中。 DN具有多个卷积和完全连接的层,其作用是强制FRN生成具有由输入属性向量指示的相应面部属性的真实面部图像。利用空间变换器网络,FRN自动补偿肖像的错位。并生成对齐的脸部图像。为了保护身份,我们将恢复的和真实的面孔强加在一起,以分享类似的视觉特征。具体地,DN确定恢复的图像是否看起来像真实的面部,并检查从恢复的图像中提取的面部属性是否与给定的属性一致。我们的方法可以从未对准的肖像中恢复高质量的照片级真实面部,同时保留面部图像的身份,并且它可以重建具有期望的属性集的照片级真实的面部图像。我们的方法可以从看不见的风格化肖像,艺术绘画和手绘草图中恢复具有所需属性的照片级真实身份保留面。在大规模合成和草图数据集上,我们证明我们的面部恢复方法达到了最先进的结果。 |
| Normalized Diversification Authors Shaohui Liu, Xiao Zhang, Jianqiao Wangni, Jianbo Shi 生成多样但具体的数据是生成对抗性网络GAN的目标,但它遭受模式崩溃的问题。我们引入归一化多样性的概念,迫使模型保持来自潜在参数分布的稀疏样本与它们相应的高维输出之间的归一化成对距离。归一化的多样化旨在展开未知拓扑和非均匀分布的流形,从而导致有效潜在变量之间的安全插值。通过在成对距离上交替最大化并更新总距离归一化器,我们鼓励模型在高维输出空间中主动探索。我们证明,通过结合归一化的多样性损失和对抗性损失,我们可以生成各种数据而不会遭受模式崩溃。实验结果表明,我们的方法在强基线上实现了无监督图像生成,条件图像生成和手姿态估计的一致改进。 |
| Self-supervised Spatio-temporal Representation Learning for Videos by Predicting Motion and Appearance Statistics Authors Jiangliu Wang, Jianbo Jiao, Linchao Bao, Shengfeng He, Yunhui Liu, Wei Liu 我们解决了没有人工注释标签的视频表示学习问题。虽然先前的努力通过使用视频数据设计新颖的自监督任务来解决该问题,但是所学习的特征仅仅是逐帧的,这不适用于空间时间特征占优势的许多视频分析任务。在本文中,我们提出了一种新的自我监督方法来学习视频表示的时空特征。受到视频分类中两种流方法成功的启发,我们建议通过在给定输入视频数据的情况下沿空间和时间维度回归运动和外观统计来学习视觉特征。具体地,我们从空间和时间域中的简单模式中提取统计概念快速运动区域和相应的主导方向,空间时间颜色多样性,主色等。与以前难以解决的谜题不同,所提出的方法与人类固有的视觉习惯一致,因此易于回答。我们使用C3D进行了大量实验,以验证我们提出的方法的有效性。实验表明,当应用于视频分类任务时,我们的方法可以显着提高C3D的性能。代码可在 |
| Modularized Textual Grounding for Counterfactual Resilience Authors Zhiyuan Fang, Shu Kong, Charless Fowlkes, Yezhou Yang 计算机视觉应用通常需要具有精确性,可解释性和对反事实输入查询的弹性的文本接地模块。为了实现高接地精度,当前的文本接地方法严重依赖于大规模训练数据和像素级的手动注释。这样的注释获得起来很昂贵,因此严重缩小了模型的实际应用范围。而且,这些方法中的大多数牺牲了可解释性,普遍性,并且忽视了对反事实输入具有弹性的重要性。为了解决这些问题,我们提出了一种可视化接地系统,该系统可以以弱监督的方式进行端对端训练,仅具有图像级注释,并且由于模块化设计而具有2个反向弹性。具体来说,我们将文本描述分解为三个层次的实体,语义属性,颜色信息,并逐步进行构图基础。我们通过一系列实验验证了我们的模型,并证明了它对现有技术方法的改进。特别是,我们的模型表现不仅超越了其他弱监督方法,甚至接近强监督方法,而且可以解释为决策,并且在反事实类别中表现得比其他所有方法都好得多。 |
| Multi-Label Image Recognition with Graph Convolutional Networks Authors Zhao Min Chen, Xiu Shen Wei, Peng Wang, Yanwen Guo 多标签图像识别的任务是预测图像中存在的一组对象标签。由于对象通常出现在图像中,因此需要对标签依赖性进行建模以提高识别性能。为了捕获和探索这些重要的依赖关系,我们提出了一种基于图形卷积网络GCN的多标签分类模型。该模型在对象标签上构建有向图,其中每个节点标签由标签的单词嵌入表示,并且学习GCN以将该标签图映射到一组依赖于对象的对象分类器。这些分类器应用于由另一个子网提取的图像描述符,使整个网络能够端到端训练。此外,我们提出了一种新的重新加权方案,以创建有效的标签相关矩阵,以指导GCN中节点之间的信息传播。对两个多标签图像识别数据集的实验表明,我们的方法明显优于其他现有技术方法。此外,可视化分析表明,我们的模型学习的分类器保持了有意义的语义拓扑。 |
| Compare More Nuanced:Pairwise Alignment Bilinear Network For Few-shot Fine-grained Learning Authors Huaxi Huang, Junjie Zhang, Jian Zhang, Qiang Wu, Jingsong Xu 人类的识别能力是以渐进的方式发展起来的。通常,儿童学会在有限的监督下区分各种物体,从粗粒到细粒。受此学习过程的启发,我们为少数镜头细粒度FSFG识别提出了一个简单而有效的模型,该模型尝试使用元学习来解决具有挑战性的细粒度识别任务。所提出的方法,名为Pairwise Alignment Bilinear Network PABN,是一种端到端深度神经网络。与用于细粒度分类的传统深双线性网络不同,其采用自双线性池来捕获图像的细微特征,所提出的模型使用新的成对双线性池来比较基本图像和查询图像之间的细微差别以用于学习深度距离度量。为了使基本图像特征与查询图像特征相匹配,我们在提出的成对双线性池化之前设计特征对齐损失。在四个细粒度分类数据集和一个通用的几个镜头数据集上的实验结果表明,所提出的模型优于现有技术的几个镜头细粒度和一般的几个镜头方法。 |
| Adaptively Connected Neural Networks Authors Guangrun Wang, Keze Wang, Liang Lin 本文提出了一种新的自适应连接神经网络ACNet,从两个方面改进了传统的卷积神经网络CNNs。首先,ACNet采用灵活的方式在处理内部特征表示时通过自适应地确定特征节点之间的连接状态来切换全局和局部推断,例如,特征映射的像素脚注在计算机视觉域中,节点指的是像素特征映射,而在图域中,节点表示图节点。 。我们可以证明现有的CNN,经典的多层感知器MLP,以及最近提出的非本地网络NLN引用非本地化17都是ACNet的特例。其次,ACNet还能够处理非欧几里德数据。对各种基准进行广泛的实验分析,即ImageNet 1k分类,COCO 2017检测和分割,CUHK03人员识别,CIFAR分析和Cora文件分类,表明ACNet不仅可以实现最先进的性能,还可以克服限制常规MLP和CNN脚注通讯作者梁林林良ieee.org。该代码可在网址获取 |
| A Dilated Inception Network for Visual Saliency Prediction Authors Sheng Yang, Guosheng Lin, Qiuping Jiang, Weisi Lin 最近,随着深度卷积神经网络DCNN的出现,视觉显着性预测研究的改进令人印象深刻。接近下一个改进的一个可能方向是利用DCNN架构中的计算友好模块来完全表征多尺度显着性影响因素。在这项工作中,我们提出了端到端扩张初始网络DINet用于视觉显着性预测。它使用非常有限的额外参数有效捕获多尺度上下文特征。我们提出的扩张初始模块DIM使用具有不同扩张率的平行扩张卷积,而不是利用具有不同内核尺寸的并行标准卷积作为现有初始模块,这可以显着降低计算量,同时丰富特征图中感受域的多样性。此外,通过使用一组基于线性归一化的概率分布距离度量作为损失函数,我们的显着性模型的性能得到进一步改善。因此,我们可以将显着性预测公式化为全局显着性推断的概率分布预测任务,而不是典型的像素智能回归问题。几个具有挑战性的显着性基准数据集的实验结果表明,我们的具有所提出的损失函数的DINet可以在较短的推理时间内实现最先进的性能。 |
| Image and Video Compression with Neural Networks: A Review Authors Siwei Ma, Xinfeng Zhang, Chuanmin Jia, Zhenghui Zhao, Shiqi Wang, Shanshe Wang 近年来,图像和视频编码技术突飞猛进。然而,由于图像和视频采集设备的普及,图像和视频数据的增长率远远超过压缩比的提高。特别地,已经广泛认识到在传统的混合编码框架内追求进一步的编码性能改进存在越来越多的挑战。深度卷积神经网络CNN近年来使神经网络复苏,并在人工智能和信号处理领域取得了巨大成功,也为图像和视频压缩提供了一种新颖有前途的解决方案。在本文中,我们提供了基于神经网络的图像和视频压缩技术的系统,全面和最新的综述。分别针对图像和视频引入了基于神经网络的压缩方法的演化和发展。更具体地,提出并讨论了通过利用深度学习和HEVC框架的尖端视频编码技术,其基本上促进了现有技术的视频编码性能。此外,还回顾了基于神经网络的端到端图像和视频编码框架,揭示了对下一代图像和视频编码框架标准的有趣探索。突出了使用神经网络对图像和视频编码相关主题进行的最重要的研究工作,并且还设想了未来的趋势。特别是,初步探索了对语义和视觉信息的联合压缩,以制定人类视觉和机器视觉的高效信号表示结构,这是人工智能时代的两个主要信号接受者。 |
| Place-specific Background Modeling Using Recursive Autoencoders Authors Yamaguchi Kousuke, Tanaka Kanji, Sugimoto Takuma, Ide Rino, Takeda Koji 使用车载单眼视觉系统相对于地点特定背景模型检测车辆前方的变化物体的图像变化检测ICD是智能车辆IV中的基本问题。从最近的大规模IV应用的角度来看,在空间时间效率方面为每个可能的地方训练场所特定背景模型是不切实际的。为了解决这些问题,我们引入了一种新的基于自动编码器AE的高效ICD框架,该框架结合了基于AE的异常检测AD和基于AE的图像压缩IC的优点。我们提出了一种方法,该方法使用AE重建误差作为训练最小地点特定AE的单一统一度量并保持检测准确性。我们介绍了一种有效的递增递归AE rAE训练框架,该框架递归地将大量背景图像汇总到AE集中。挑战交叉季节ICD任务的实验结果验证了所提方法的有效性。 |
| Scalable Change Retrieval Using Deep 3D Neural Codes Authors Kojima Yusuke, Tanaka Kanji, Yang Naiming, Hirota Yuji 我们从车载3D图像系统提出了一种新颖的可扩展框架,用于图像变化检测ICD。我们认为现有的ICD系统受到将给定查询图像与单个参考图像坐标对齐所需的时间的约束。我们利用不变坐标系ICS来替换耗时的图像对齐与离线预处理过程。我们的关键贡献是将基于传统图像比较的ICD任务扩展到图像检索IR任务的设置。我们替换3D ICD系统的每个组件,即1个图像建模,2个图像对齐和3个图像差分,具有来自单词BoW IR范例的显着有效的变体。此外,我们使用无监督的Siamese网络以无人监督的方式训练深度3D特征提取器并自动收集训练数据。我们使用公开的数据集对具有挑战性的跨季ICD任务进行了实验,从而验证了所提方法的有效性。 |
| Long-Term Vehicle Localization by Recursive Knowledge Distillation Authors Hiroki Tomoe, Tanaka Kanji 跨季节视觉地点识别CS VPR的大多数现有技术框架专注于域适应DA到单个特定季节。从长期CS VPR的角度来看,这样的框架不能很好地扩展到连续的多个域,例如,春夏秋冬......本研究的目的是开发一种新颖的长期集成学习LEL框架,允许在长期连续多域CS VPR SMD VPR中进行恒定成本再训练,这只需要记忆少量恒定数量的深度卷积神经网络CNN。并且可以以很小的恒定时间空间成本重新训练每个赛季的CNN合奏。我们将我们的任务定位为多教师多学生知识蒸馏MTMS KD,它递归地将所有前一季的知识压缩成当前的CNN集合。我们进一步解决了教师学生分配TSA的问题,以实现良好的泛化专业化权衡。 SMD VPR任务的实验结果验证了所提方法的有效性。 |
| Automatic Target Recognition Using Discrimination Based on Optimal Transport Authors Ali Sadeghian, Deoksu Lim, Johan Karlsson, Jian Li 基于最佳运输的距离的使用最近显示出对功率谱的区分的希望。特别地,基于l1正则化以及基于协方差的方法的谱估计方法可以被示出相对于这样的距离是鲁棒的。这些传输距离提供了几何框架,其中测地线对应于光谱质量的平滑过渡,并且对于跟踪是有用的。在本文中,我们研究了这些距离在自动目标识别中的使用。我们研究了使用Monge Kantorovich距离与标准l2距离进行比较,以便根据SAR图像对民用车辆进行分类。我们使用Monge Kantorovich距离的一个版本也适用于光谱可能具有不同总质量的情况,并且我们将优化问题表示为可以使用有效算法计算的最小流问题。 |
| Dense 3D Face Decoding over 2500FPS: Joint Texture & Shape Convolutional Mesh Decoders Authors Yuxiang Zhou, Jiankang Deng, Irene Kotsia, Stefanos Zafeiriou 3D可变形模型3DMM是使用一组线性基础和更具体的主成分分析PCA来表示面部纹理和形状变化的统计模型。 3DMM被用作统计先验,通过求解非线性最小二乘优化问题从图像重建3D面部。最近,3DMM用作训练非线性映射的生成模型,即通过深度卷积神经网络DCNN从图像到模型参数的回归器。然而,所有上述方法在参数展开的UV空间上使用完全连接的层或2D卷积,导致具有许多参数的大型网络。在本文中,我们通过使用直接网格卷积来学习关节纹理和形状自动编码器,从而获得我们所知的第一个非线性3DMM。我们演示了这些自动编码器如何用于训练非常轻量级的模型,这些模型在野外以超过2500 FPS的速度执行彩色网格解码CMD。 |
| C2S2: Cost-aware Channel Sparse Selection for Progressive Network Pruning Authors Chih Yao Chiu, Hwann Tzong Chen, Tyng Luh Liu 本文描述了一种用于简化深度神经网络的信道选择方法。具体而言,我们提出了一种新的通用网络层,称为修剪层,以无缝地增加给定的预训练模型以进行压缩。每个修剪层包括1倍1深度的核,用双格式表示,一个是实值,另一个是二进制。前者使网络修剪的两阶段优化过程能够与端到端可区分网络一起操作,后者产生用于信道选择的掩码信息。我们的方法逐步逐步执行剪枝任务,并根据稀疏性标准实现频道选择,以有利于修剪更多频道。我们还开发了一种成本感知机制,以防止压缩损害预期的网络性能。我们在图像分类和语义分割上压缩几个基准深度网络的结果与现有技术的结果相当。 |
| DeepSEED: 3D Squeeze-and-Excitation Encoder-Decoder ConvNets for Pulmonary Nodule Detection Authors Yuemeng Li, Hangfan Liu, Yong Fan 肺结节检测在低剂量计算机断层扫描CT扫描肺癌筛查中发挥重要作用。虽然通过基于深度学习的结节检测方法已经实现了有希望的性能,但是由于不平衡的正和负样本,构建具有良好通用性能的结节检测网络仍然是具有挑战性的。为了克服这个问题并进一步改进现有技术的区域提议网络方法,我们开发了一种新的深度3D卷积神经网络,其具有用于肺结节检测的编码器解码器结构。特别地,我们利用动态缩放的交叉熵损失来降低误报率并补偿重要的数据不平衡问题。我们采用挤压和激励结构来学习有效的图像特征并充分利用信道相互依赖性。我们已经基于来自LIDC IDRI数据集的公开可用的CT扫描以及具有更薄切片的其子集LUNA16验证了我们的方法。消融研究和实验结果表明,我们的方法可以大大优于现有的结节检测方法,LUNA16的平均FROC评分为86.2,LIDC IDRI数据集的平均FROC评分仅为37.3(仅限LUNA16) 。 |
| LP-3DCNN: Unveiling Local Phase in 3D Convolutional Neural Networks Authors Sudhakar Kumawat, Shanmuganathan Raman 传统的3D卷积神经网络CNN计算量大,内存密集,容易过度拟合,最重要的是,需要改进其特征学习能力。为了解决这些问题,我们提出了整流局部相位体积ReLPV模块,这是标准3D卷积层的有效替代方案。 ReLPV块提取3D局部邻域中的相位,例如输入映射的每个位置的3×3×3,以获得特征映射。通过在每个位置的3D局部邻域中的多个固定低频点处计算3D短期傅立叶变换STFT来提取相位。然后,在通过激活函数之后,在不同频率点处的这些特征图被线性组合。与标准3D卷积层相比,ReLPV块的显着参数节省至少为3 3至13 3倍,滤波器尺寸分别为3x3x3至13x13x13。我们表明ReLPV块的特征学习能力明显优于标准3D卷积层。此外,它在不同的3D数据表示中产生始终如一的更好结果。我们在体积ModelNet10和ModelNet40数据集上实现了最先进的精度,同时仅使用了当前技术水平的11个参数。当使用现有技术的仅15个参数时,我们还在从头开始训练时将UCF 101分裂1动作识别数据集的现有技术改进5.68。项目网页可在 |
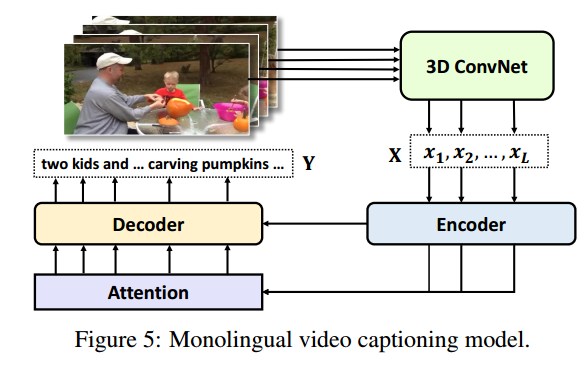
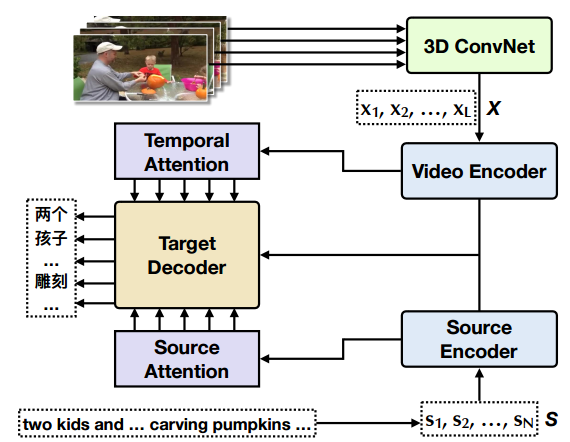
| VATEX: A Large-Scale, High-Quality Multilingual Dataset for Video-and-Language Research Authors Xin Wang, Jiawei Wu, Junkun Chen, Lei Li, Yuan Fang Wang, William Yang Wang 我们提供了一个新的大型多语言视频描述数据集VATEX,其中包含超过41,250个视频和825,000个中英文字幕。在这些字幕中,有超过206,000个英文中文平行翻译对。与广泛使用的MSR VTT数据集相比,VATEX在视频和自然语言描述方面具有多语言,更大,语言复杂,更多样化。我们还介绍了基于VATEX 1多语言视频字幕的视频和语言研究两项任务,旨在通过紧凑的统一字幕模型描述各种语言的视频,以及2视频引导机器翻译,将源语言描述转换为目标语言使用视频信息作为附加的时空背景。对VATEX数据集的大量实验表明,首先,统一的多语言模型不仅可以更有效地生成视频的英文和中文描述,而且还可以提供比单语模型更高的性能。此外,我们证明了时空视频上下文可以有效地用于对齐源语言和目标语言,从而协助机器翻译。最后,我们讨论了使用VATEX进行其他视频和语言研究的潜力。 |
| Self-supervised speaker embeddings Authors Themos Stafylakis, Johan Rohdin, Oldrich Plchot, Petr Mizera, Lukas Burget 与i向量相反,由于训练说话者的分类丢失,诸如x向量之类的说话者嵌入不能利用未标记的话语。在本文中,我们探索了一种替代的培训策略,以便在培训中使用未标记的话语。我们建议通过重建目标语音段的帧来训练说话者嵌入提取器,给定相同话语的另一个语音段的推断嵌入。我们通过将标准扬声器嵌入提取器连接到解码器网络来实现这一点,该解码器网络不仅提供扬声器嵌入,还提供目标帧序列的估计电话序列。重建损失既可以用作单个目标,也可以与标准说话者分类损失结合使用。在后一种情况下,它充当了一个正规化者,鼓励在培训期间看不到的发言者的普遍性。在所有情况下,所提出的架构都是从头开始以端到端的方式进行培训。我们展示了野外VoxCeleb和扬声器的建议方法带来的好处,并且我们报告了基线的显着改进。 |
| When AWGN-based Denoiser Meets Real Noises Authors Yuqian Zhou, Jianbo Jiao, Haibin Huang, Yang Wang, Jue Wang, Honghui Shi, Thomas Huang 基于判别学习的图像降噪器已经在合成噪声(例如加性高斯噪声)上获得了有希望的性能。然而,它们对具有真实噪声的图像的性能通常不令人满意。主要原因是真实噪声主要是空间信道相关和空间信道变量。相比之下,大多数先前工作中采用的合成加性高斯白噪声AWGN与像素无关。在本文中,我们提出了一种提高真实图像去噪器性能的新方法,该方法仅使用合成像素无关噪声数据进行训练。首先,我们训练一个由噪声估计器和具有混合AWGN和随机值脉冲噪声RVIN的降噪器组成的深度模型。然后,我们研究Pixel shuffle Down采样PD策略,以使训练模型适应真实噪声。大量实验证明了所提方法的有效性和泛化能力。值得注意的是,我们的方法在DND基准测试中实现了真实sRGB图像的最新性能。代码可在 |
| SDRSAC: Semidefinite-Based Randomized Approach for Robust Point Cloud Registration without Correspondences Authors Huu Le, Thanh Toan Do, Tuan Hoang, Ngai Man Cheung 本文提出了一种新的随机算法,用于无对应的鲁棒点云登记。大多数现有的注册方法需要通过提取不变描述符而获得的一组推定的对应关系。但是,这些描述符在嘈杂和污染的环境中可能变得不可靠。在这些设置中,直接处理输入点集的方法更可取。然而,没有对应关系,传统的随机技术需要非常大量的样本才能达到令人满意的解决方案。在本文中,我们提出了一种解决这个问题的新方法。特别是,我们的工作使得能够使用随机方法进行点云登记,而无需假定的对应关系。通过将点云对齐视为图匹配的一个特殊实例并采用有效的半定松弛,我们提出了一种新的采样机制,其中采样子集的大小可以大于最小值。我们的紧密弛豫方案可以快速抑制采样集中的异常值,从而产生高质量的假设。我们进行了大量实验,以证明我们的方法优于其他最先进的方法。重要的是,我们提出的方法可以作为通用框架,可以扩展到已知对应问题。 |
| Few-Shot Learning via Saliency-guided Hallucination of Samples Authors Hongguang Zhang, Jing Zhang, Piotr Koniusz 从一些样本中学习新概念是计算机视觉中的标准挑战。提高少数射击训练模型的学习能力的主要方向包括强大的相似性学习和从有限的现有样本中生成或幻觉化附加数据。在本文中,我们遵循后一个方向,并提出一个新的数据幻觉模型。目前,大多数数据点发生器包含专用网络,即GAN,其任务是产生幻觉的新数据点,因此首先需要大量注释数据用于他们的训练。在本文中,我们提出了一种新的低成本幻觉方法,用于少数镜头学习,利用显着性图。为此,我们使用显着性网络来获得可用图像样本的前景和背景,并将得到的地图输入到双流网络中,以便从可行的前景背景组合中直接在特征空间中产生数据点。据我们所知,我们是第一个利用显着性图来完成这项任务的人,我们展示了他们在幻觉中为少数镜头学习产生额外数据点的有用性。我们提出的网络在公开数据集上实现了最新技术水平。 |
| Deep Stacked Hierarchical Multi-patch Network for Image Deblurring Authors Hongguang Zhang, Yuchao Dai, Hongdong Li, Piotr Koniusz 尽管深度端到端的学习方法已经显示出它们在去除非均匀运动模糊方面的优势,但是当前的多尺度和尺度递归模型仍然存在重大挑战.1从粗到细方案中的反卷积上采样操作导致昂贵的运行时间2简单地增加具有更精细尺度水平的模型深度不能提高去模糊的质量。为了解决上述问题,我们提出了一个深层次的多补丁网络,其灵感来自空间金字塔匹配,通过精细到粗糙的层次表示来处理模糊图像。为了处理性能饱和度w.r.t.深度,我们提出了我们的多补丁模型的堆叠版本。我们提出的基本多补丁模型在GoPro数据集上实现了最先进的性能,同时与当前的多尺度方法相比,其运行时间提高了40倍。 30ms处理1280x720分辨率的图像,是30fps的720p图像的第一个实时深度运动去模糊模型。对于堆叠网络,通过增加网络深度,GoPro数据集实现了超过1.2dB的显着改进。此外,通过改变堆叠模型的深度,可以针对不同的应用场景调整相同网络的性能和运行时间。 |
| Embodied Question Answering in Photorealistic Environments with Point Cloud Perception Authors Erik Wijmans, Samyak Datta, Oleksandr Maksymets, Abhishek Das, Georgia Gkioxari, Stefan Lee, Irfan Essa, Devi Parikh, Dhruv Batra 为了帮助弥合互联网视觉风格问题与具体感知愿景目标之间的差距,我们在照片真实环境Matterport 3D中实例化了一个大型导航任务Embodied Question Answering 1。我们彻底研究利用3D点云,RGB图像或它们组合的导航策略。我们对这些模型的分析揭示了几个主要发现。我们发现两个看似天真的导航基线,仅向前和随机,是强大的导航器,并且挑战超越,因为1提供的评估设置的具体选择。我们发现一种新的损失加权方案,我们称之为拐点加权在训练用于行为克隆的导航的复现模型时非常重要,并且能够通过该技术执行基线。我们发现点云提供了比RGB图像更丰富的信号,用于学习避障,激励使用和继续研究用于体现导航的3D深度学习模型。 |
| Doodle to Search: Practical Zero-Shot Sketch-based Image Retrieval Authors Sounak Dey, Pau Riba, Anjan Dutta, Josep Llados, Yi Zhe Song 在本文中,我们研究了基于零镜头草图的图像检索ZS SBIR的问题,其中人类草图被用作查询以从不可见的类别中检索照片。我们通过提出一种新颖的ZS SBIR方案来推进现有技术,这种方案在实际应用中迈出了坚实的一步。新设置独特地认识到实际ZS SBIR的两个重要但经常被忽视的挑战,即业余草图和照片之间的巨大领域差距,以及向大规模检索迈进的必要性。我们首先向社区贡献一个新的ZS SBIR数据集,QuickDraw Extended,包含330,000个草图和204,000张照片,涵盖110个类别。有目的地采用高度抽象的业余人体草图来最大化域间隙,而不是现有数据集中包含的那些通常是半照片级真实的。然后,我们制定了一个ZS SBIR框架,将草图和照片共同建模成一个共同的嵌入空间。挖掘域之间的互信息的新策略是专门设计用于缓解域差距。进一步嵌入外部语义知识以帮助语义转移。我们表明,相当令人惊讶的是,检索性能明显优于现有数据集上的现有数据集,而现有数据集已经可以使用我们模型的简化版本实现。通过与新提出的数据集上的许多备选方案进行比较,我们进一步证明了我们的完整模型的卓越性能。新数据集以及我们模型的所有培训和测试代码将公开发布,以方便未来的研究 |
| Iterative Normalization: Beyond Standardization towards Efficient Whitening Authors Lei Huang, Yi Zhou, Fan Zhu, Li Liu, Ling Shao 批量标准化BN普遍用于加速神经网络训练,并通过在小批量内进行标准化来提高泛化能力。去相关的批量标准化DBN通过增白进一步提高了上述效果。但是,DBN在很大程度上依赖于大批量大小,或者在GPU上效率低下的特征分解。我们提出了迭代归一化IterNorm,它使用牛顿迭代来更有效地增白,同时避免了特征分解。此外,我们开发了一项综合研究,表明IterNorm在优化和泛化之间有更好的权衡,具有理论和实验支持。为此,我们专门引入随机归一化扰动SND,它测量样本在应用于归一化操作时的固有随机不确定性。在SND的支持下,我们从优化的角度为几种现象提供了自然的解释,例如,为什么DBN的组明智增白通常优于完全增白以及为什么BN的精确度随着批量减小而退化。我们通过在BIF和DBN上对CIFAR 10和ImageNet进行了大量实验,证明了IterNorm的持续改进性能。 |
| Unsupervised Embedding Learning via Invariant and Spreading Instance Feature Authors Mang Ye, Xu Zhang, Pong C. Yuen, Shih Fu Chang 本文研究了无监督嵌入学习问题,该问题需要在低维嵌入空间中的样本之间进行有效的相似性测量。由类别智能监督学习观察到的积极集中和负面分离属性的激励,我们建议利用实例监督来近似这些属性,其目的在于学习数据增加不变和实例展开特征。为了实现这一目标,我们提出了一种新的基于实例的softmax嵌入方法,该方法直接优化了softmax函数之上的实例特征。与所有现有方法相比,它实现了更快的学习速度和更高的准确性。所提出的方法对于具有余弦相似性的已见和未见测试类别表现良好。即使没有经过预先训练的网络,也可以获得细粒度样本的竞争性能。 |
| A Novel Unsupervised Camera-aware Domain Adaptation Framework for Person Re-identification Authors Lei Qi, Lei Wang, Jing Huo, Luping Zhou, Yinghuan Shi, Yang Gao 无监督的跨域人员识别Re ID面临两个关键问题。一个是源域和目标域之间的数据分布差异,另一个是目标域中缺少标签信息。本文从表征学习的角度阐述了它们。对于第一个问题,我们强调相机级子域的存在是人Re ID的独特特征,并开发相机感知域适应,以减少源域和目标域之间以及这些子域之间的差异。对于第二个问题,我们利用目标域的每个相机中的时间连续性来创建判别信息。这是通过在每批中动态生成在线三元组来实现的,以便最大限度地利用训练过程中稳定改进的特征表示。总之,上述两种方法为人Re ID产生了一种新颖的无监督深域适应框架。基准数据集的实验和消融研究证明了它的优越性和有趣的特性。 |
| Context-aware Human Motion Prediction Authors Enric Corona, Albert Pumarola, Guillem Aleny , Francesc Moreno 在给定一系列过去观察的情况下预测人体运动的问题是机器人和计算机视觉中许多应用的核心。现有技术将该问题表述为序列任务的序列,其中3D骨架的历史馈送预测未来运动的递归神经网络RNN,通常在1到2秒的量级。然而,到目前为止已经消除的一个方面是人体运动固有地由与环境中的物体和/或其他人的相互作用驱动的事实。 |
| Deep Surface Normal Estimation with Hierarchical RGB-D Fusion Authors Jin Zeng, Yanfeng Tong, Yunmu Huang, Qiong Yan, Wenxiu Sun, Jing Chen, Yongtian Wang 商用RGB D相机的日益增长的可用性促进了场景理解领域的应用。然而,作为基本的场景理解任务,RGB D数据的表面法线估计缺乏彻底的研究。在本文中,提出了一种具有自适应特征重新加权的分层融合网络,用于从单个RGB D图像进行表面法线估计。具体而言,彩色图像和深度的特征在多个尺度上连续集成,以确保全局表面平滑度,同时保留视觉上显着的细节。同时,利用在合并到颜色分支之前从深度估计的置信度图来重新加权深度特征,以避免由输入深度损坏引起的伪像。此外,混合多尺度损失函数被设计用于在给定嘈杂的地面实况数据集的情况下学习准确的正态估计。广泛的实验结果验证了融合策略和损失设计的有效性,优于现有技术的正常估计方案。 |
| Re-Identification Supervised Texture Generation Authors Jian Wang, Yunshan Zhong, Yachun Li, Chi Zhang, Yichen Wei 近年来,已经广泛研究了从单个图像估计3D人体姿势和形状。然而,纹理生成问题尚未得到充分讨论。在本文中,我们提出了一种端到端的学习策略,用于在人格识别的监督下生成人体纹理。我们使用从输入中提取的纹理渲染合成图像,并通过使用re识别网络作为感知度量来最大化渲染图像和输入图像之间的相似性。对行人图像的实验结果表明,我们的模型可以从单个图像生成纹理,并证明我们的纹理质量高于其他可用方法生成的纹理。此外,我们将应用程序范围扩展到其他类别,并探索我们生成的纹理的可能利用率。 |
| Visualization of Convolutional Neural Networks for Monocular Depth Estimation Authors Junjie Hu, Yan Zhang, Takayuki Okatani 最近,卷积神经网络CNN已经在单眼深度估计的任务上取得了巨大的成功。一个基本但尚未回答的问题是CNN如何从单个图像中推断出深度。为了回答这个问题,我们考虑通过识别输入图像的相关像素来进行深度估计来可视化CNN的推断。我们将其制定为识别最小数量的图像像素的优化问题,CNN可以从该图像像素估计深度图,其与来自整个图像的估计具有最小差异。为了应对通过深度CNN进行优化的困难,我们建议使用另一个网络来预测正向计算中的那些相关图像像素。在我们的实验中,我们首先展示了这种方法的有效性,然后将其应用于室内和室外场景数据集的不同深度估计网络。结果提供了一些有助于探索上述问题的发现。 |
| Unsupervised Person Image Generation with Semantic Parsing Transformation Authors Sijie Song, Wei Zhang, Jiaying Liu, Tao Mei 在本文中,我们讨论了无监督的姿势引导人图像生成,其已知由于非刚性变形而具有挑战性。与以前学习人体之间难以直接映射的方法不同,我们提出了一种新的途径,将硬映射分解为两个更易于访问的子任务,即语义解析转换和外观生成。首先,提出了一种语义生成网络,用于在语义解析图之间进行转换,以简化非刚性变形学习。其次,外观生成网络学习合成语义感知纹理。第三,我们证明以端到端方式训练我们的框架进一步细化了语义地图和相应的最终结果。我们的方法可推广到其他语义感知人图像生成任务,例如服装纹理转移和受控图像处理。实验结果证明了我们的方法在DeepFashion和Market 1501数据集上的优越性,特别是在保持服装属性和更好的体形方面。 |
| Camera Lens Super-Resolution Authors Chang Chen, Zhiwei Xiong, Xinmei Tian, Zheng Jun Zha, Feng Wu 用于单图像超分辨率SR的现有方法通常用合成降解模型评估,例如双三次或高斯下采样。在本文中,我们从相机镜头的角度研究SR,命名为CameraSR,旨在减轻真实成像系统中分辨率R和视场V之间的内在折衷。具体而言,我们将R V劣化视为SR过程中的潜在模型,并学习使用逼真的低分辨率和高分辨率图像对来反转它。为了获得配对图像,我们分别为两个代表性成像系统(即DSLR和智能手机相机)提出了两种新颖的数据采集策略。基于获得的City100数据集,我们定量分析了常用合成降解模型的性能,并证明了CameraSR作为提高现有SR方法性能的实用解决方案的优越性。此外,CameraSR可以很容易地推广到不同的内容和设备,在现实的成像系统中用作高级数字变焦工具。代码和数据集可在以下处获得 |
| Blind Super-Resolution With Iterative Kernel Correction Authors Jinjin Gu, Hannan Lu, Wangmeng Zuo, Chao Dong 基于深度学习的方法由于其在有效性和效率方面的显着性能而在超分辨率SR领域占主导地位。这些方法中的大多数假设在下采样期间的模糊内核是预定义的,例如,双三次。然而,实际应用中涉及的模糊内核是复杂且未知的,导致高级SR方法的严重性能下降。在本文中,我们提出了一种迭代核校正IKC方法,用于盲SR问题中的模糊核估计,其中模糊核是未知的。我们得出的结论是,内核不匹配会在锐化或平滑过程中产生规则的伪像,这可以应用于纠正不准确的模糊内核。因此,我们引入了迭代校正方案IKC,其实现了比直接核估计更好的结果。我们进一步提出了一种有效的SR网络架构,其使用空间特征变换SFT层来处理多个模糊内核,名为SFTMD。对合成和真实世界图像的广泛实验表明,所提出的具有SFTMD的IKC方法可以提供视觉上有利的SR结果和盲SR问题中的现有技术性能。 |
| Modeling Point Clouds with Self-Attention and Gumbel Subset Sampling Authors Jiancheng Yang, Qiang Zhang, Bingbing Ni, Linguo Li, Jinxian Liu, Mengdie Zhou, Qi Tian 由于3D传感器的普及,几何深度学习变得越来越重要。受NLP域的最新进展的启发,引入自注意变换器来消耗点云。我们开发了Point Attention Transformers PATs,使用参数高效的Group Shuffle Attention GSA来取代昂贵的Multi Head Attention。我们展示了它处理大小不同输入的能力,并证明了它的置换等价性。此外,先前的工作使用启发式依赖于输入数据,例如,最远点采样,以分层地选择输入点的子集。因此,我们首次提出端到端可学习和任务不可知的采样操作,称为Gumbel子集采样GSS,以选择输入点的代表性子集。配备Gumbel Softmax,它在训练阶段产生一个软连续子集,在测试阶段产生一个硬离散子集。通过以分层方式选择代表性子集,网络以较低的计算成本学习输入集的更强表示。分类和分割基准的实验表明了我们的方法的有效性和效率。此外,我们提出了一种新颖的应用,将事件相机流处理为点云,并在DVS128手势数据集上实现最先进的性能。 |
| Towards Locally Consistent Object Counting with Constrained Multi-stage Convolutional Neural Networks Authors Muming Zhao, Jian Zhang, Chongyang Zhang, Wenjun Zhang 监视场景中的高密度物体计数具有挑战性,主要是由于物体尺度的急剧变化。深度学习的普及在很大程度上提高了几个基准数据集的对象计数准确性。然而,全球计数真的算上武装这个问题,我们深入到预测的密度图,其中整个区域的总和报告全局计数以进行更深入的分析。我们观察到由大多数现有方法生成的对象密度图通常缺乏局部一致性,即,即使全局计数似乎与基础事实很好地匹配,也会意外地存在局部区域中的计数错误。针对这一问题,本文提出了一种约束多阶段卷积神经网络CNN,从两个方面共同寻求局部一致密度图。与主要依赖于普通CNN的多列体系结构的大多数现有方法不同,我们利用普通CNN的堆叠公式。受益于内部多阶段学习过程,可以重复细化特征图,使密度图接近地面真实密度分布。为了进一步细化密度图,我们还提出了网格损失函数。通过更精细的基于局部区域的监督,基础模型被约束为生成局部一致的密度值,以最小化考虑全局和局部计数准确性的训练误差。两个广泛测试的物体计数基准的实验与现有技术方法相比具有总体显着的结果,证明了我们的方法的有效性。 |
| BridgeNet: A Continuity-Aware Probabilistic Network for Age Estimation Authors Wanhua Li, Jiwen Lu, Jianjiang Feng, Chunjing Xu, Jie Zhou, Qi Tian 年龄估计是计算机视觉中一个重要但非常具有挑战性的问题现有的年龄估计方法通常采用分而治之的策略来处理由非固定老化过程引起的异构数据。然而,面部衰老过程也是一个连续的过程,并且没有有效地利用不同组件之间的连续性关系。在本文中,我们提出了BridgeNet用于年龄估计,旨在有效地挖掘年龄标签之间的连续关系。建议的BridgeNet由本地回归器和门控网络组成。本地回归器将数据空间划分为多个重叠子空间以处理异构数据,并且门控网络通过采用所提出的桥接树结构来学习本地回归器的结果的连续性感知权重,所述桥接树结构将桥接连接引入树模型以强制相邻节点之间的相似性。而且,BridgeNet的这两个组件可以以端到端的方式共同学习。我们在MORPH II,FG NET和Chalearn LAP 2015数据集上展示了实验结果,发现BridgeNet优于最先进的方法。 |
| 3D Dilated Multi-Fiber Network for Real-time Brain Tumor Segmentation in MRI Authors Chen Chen, Xiaopeng Liu, Meng Ding, Junfeng Zheng, Jiangyun Li 脑肿瘤分割在医学图像处理中起着关键作用。在这项工作中,我们的目标是分割脑部磁共振成像量。 3D卷积神经网络CNN(例如3D U Net和V Net)采用3D卷积来捕获相邻切片之间的相关性,从而获得了令人印象深刻的分割结果。然而,由于多层3D卷积,这些3D CNN架构具有高计算开销,这可能使这些模型对于实际的大规模应用而言是禁止的。为此,我们提出了一种高效的3D CNN来实现实时密集的体积分割。该网络利用3D多光纤单元,该单元由轻量级3D卷积网络组成,可显着降低计算成本。此外,3D扩张卷积用于构建多尺度特征表示。 BraTS 2018挑战数据集的广泛实验结果表明,所提出的架构大大降低了计算成本,同时保持了脑肿瘤分割的高精度。我们的代码即将发布。 |
| Progressive Pose Attention Transfer for Person Image Generation Authors Zhen Zhu, Tengteng Huang, Baoguang Shi, Miao Yu, Bofei Wang, Xiang Bai 本文提出了一种新的生成对抗网络,用于姿势转移,即将给定人的姿势转移到目标姿势。网络的生成器包括一系列姿势注意转移块,每个姿势转移块转移它所关注的某些区域,逐步生成人物图像。与之前的作品相比,我们生成的人物图像具有更好的外观一致性和与输入图像的形状一致性,因此看起来更加逼真。所提出的网络的功效和效率在市场1501和DeepFashion上进行了定性和定量验证。此外,所提出的架构可以生成用于人员识别的训练图像,从而减轻数据不足。代码和型号可在以下网站获得 |
| Semantic Graph Convolutional Networks for 3D Human Pose Regression Authors Long Zhao, Xi Peng, Yu Tian, Mubbasir Kapadia, Dimitris N. Metaxas 在本文中,我们研究了用于回归的学习图卷积网络GCN的问题。目前的GCN架构仅限于卷积滤波器的小感受域和每个节点的共享变换矩阵。为了解决这些局限性,我们提出了语义图卷积网络SemGCN,这是一种新颖的神经网络体系结构,可以使用图形结构化数据对回归任务进行操作。 SemGCN学习捕获语义信息,例如本地和全局节点关系,这些信息未在图中明确表示。这些语义关系可以通过端到端的训练来学习,而无需额外的监督或手工制作的规则。我们进一步研究将SemGCN应用于3D人体姿势回归。我们的公式直观且充分,因为2D和3D人体姿势都可以表示为编码人体骨骼中关节之间关系的结构化图形。我们进行综合研究以验证我们的方法。结果证明SemGCN在使用90个参数时表现优于现有技术水平。 |
| 360 Panorama Synthesis from a Sparse Set of Images with Unknown FOV Authors Julius Surya Sumantri, In Kyu Park 360图像表示在所有可能的观看方向上捕获的场景。它们使观众能够在场景中自由导航,从而提供身临其境的体验。相反,传统图像表示单个观看方向上的场景。这些图像是通过小视场或有限视野捕获的。结果,仅观察到场景的一些部分,并且丢失了关于周围环境的有价值的信息。我们提出了一种基于学习的方法,可以从传统图像中重建360 x180的场景。该方法首先估计输入图像相对于全景的视野。然后将估计的视野用作合成高分辨率360全景输出的先验。实验结果表明,我们的方法优于替代方法,并且足够稳健,可以合成真实世界的数据,例如:使用智能手机拍摄的场景。 |
| Convolutional Relational Machine for Group Activity Recognition Authors Sina Mokhtarzadeh Azar, Mina Ghadimi Atigh, Ahmad Nickabadi, Alexandre Alahi 我们提出了一种称为卷积关系机器CRM的端到端深度卷积神经网络,用于识别利用图像或视频中个人之间空间关系信息的群体活动。它学习基于个人和团体活动产生中间空间表示活动图。多阶段细化组件负责减少活动图中的错误预测。最后,聚合组件使用细化的信息来识别组活动。实验结果证明了以活动图的形式提取和表示的信息的建设性贡献。 CRM在排球和集体活动数据集上显示出优于现有技术模型的优势。 |
| Revealing Scenes by Inverting Structure from Motion Reconstructions Authors Francesco Pittaluga, Sanjeev J. Koppal, Sing Bing Kang, Sudipta N. Sinha 许多3D视觉系统使用3D点云来定位场景内的相机。这种点云通常使用来自运动SfM的结构来获得,之后丢弃图像以保护隐私。在本文中,我们首次展示了这样的点云保留了足够的信息来揭示场景外观并破坏隐私。我们提出了一种隐私攻击,可以从点云重建场景的彩色图像。我们的方法基于级联U网作为输入,从包含点深度和可选颜色和SIFT描述符的特定视点渲染的点的2D多通道图像,并从该视点输出场景的彩色图像。与以前的特征反演方法不同,我们处理高度稀疏和不规则的2D点分布和输入,其中缺少许多点属性,即关键点方向和比例,描述符图像源和3D点可见性。我们在公共数据集上评估我们的攻击算法并分析点云属性的重要性。最后,我们展示了还可以生成新颖的视图,从而实现底层场景的引人注目的虚拟游览。 |
| In the Wild Human Pose Estimation Using Explicit 2D Features and Intermediate 3D Representations Authors Ikhsanul Habibie, Weipeng Xu, Dushyant Mehta, Gerard Pons Moll, Christian Theobalt 用于单眼3D人体姿势估计的基于卷积神经网络的方法通常需要具有3D姿势注释的大量训练图像。虽然为人类的野生图像中的大型语料库提供2D联合注释是可行的,但是在野外语料库中为此类提供准确的3D注释在实践中几乎不可行。大多数现有的3D标记数据集是合成创建的或工作室图像中的特征。在这样的数据上训练的3D姿势估计算法通常具有有限的推广到现实世界场景分集的能力。因此,我们提出了一种新的基于深度学习的单眼三维人体姿态估计方法,该方法显示出高精度并且在野外场景中更好地推广。它具有网络架构,其包括新的解析的隐藏空间编码的显式2D和3D特征,并且使用来自预测的3D姿势的新学习投影模型的监督。我们的算法可以与具有3D标签的图像数据和仅具有2D标签的图像数据联合训练。它在野外数据中具有挑战性,可实现最先进的精确度。 |
| Weakly Supervised Video Moment Retrieval From Text Queries Authors Niluthpol Chowdhury Mithun, Sujoy Paul, Amit K. Roy Chowdhury 最近在文本中提出了一些使用自然语言查询进行视频时刻检索的方法,但在训练期间需要全面监督。然而,为每个文本描述获取具有时间边界注释的大量训练视频是非常耗时的并且通常不可缩放。为了解决这个问题,在这项工作中,我们介绍了从弱标签学习到文本任务到视频时刻检索的问题。监督的弱性是因为,在训练期间,我们只能访问视频文本对而不是不同文本描述所涉及的视频的时间范围。我们提出了一种基于联合视觉语义嵌入的框架,该框架仅使用视频级句子描述来从视频中学习相关片段的概念。具体来说,我们的主要想法是利用Text Guided Attention TGA利用视频帧之间的潜在对齐和句子描述。然后在测试阶段使用TGA来检索相关时刻。对两个基准数据集的实验表明,我们的方法实现了与现有技术全监督方法相当的性能。 |
| Prediction-Tracking-Segmentation Authors Jianren Wang, Yihui He, Xiaobo Wang, Xinjia Yu, Xia Chen 我们介绍了一种用于视频中视觉跟踪和分割的预测驱动方法。我们建立了一个预测模型,可以指导有效地找到更准确的跟踪区域,而不是仅仅依靠匹配外观线索进行跟踪。利用所提出的预测机制,我们在跟踪期间改善了模型对干扰和遮挡的鲁棒性。我们不仅在视觉跟踪任务VOT 2016和VOT 2018上,而且在视频分段数据集DAVIS 2016和DAVIS 2017上都展示了对现有技术方法的重大改进。 |
| AMASS: Archive of Motion Capture as Surface Shapes Authors Naureen Mahmood Meshcapade GmbH , Nima Ghorbani MPI for Intelligent Systems , Nikolaus F. Troje York University , Gerard Pons Moll MPI for Informatics , Michael J. Black MPI for Intelligent Systems 大型数据集是使用深度学习的计算机视觉近期进步的基石。相比之下,现有的人体运动捕捉mocap数据集很小并且运动受限,妨碍了学习人体运动模型的进展。虽然有许多不同的数据集可用,但它们各自使用不同的主体参数化,因此很难将它们集成到单个元数据集中。为了解决这个问题,我们引入了AMASS,这是一个庞大而多样的人体运动数据库,它通过在一个共同的框架和参数化中表示它们来统一15种不同的基于光学标记的mocap数据集。我们使用一种新方法MoSh来实现这一目标,该方法将mocap数据转换为由装配体模型表示的逼真3D人体网格,我们使用SMPL doi |
| A Variational Auto-Encoder Model for Stochastic Point Processes Authors Nazanin Mehrasa, Akash Abdu Jyothi, Thibaut Durand, Jiawei He, Leonid Sigal, Greg Mori 我们提出了一种新的动作序列概率生成模型。该模型被称为动作点过程VAE APP VAE,变异自动编码器,可以捕获动作序列的时间和类别的分布。对各种可能的动作序列进行建模是一个挑战,我们展示的可以通过APP VAE使用潜在表示和非线性函数来参数化分布在序列中和下一个时间可能发生的事件。我们凭经验验证了APP VAE在MultiTHUMOS和Breakfast数据集上建模动作序列的功效。 |
| Paying More Attention to Motion: Attention Distillation for Learning Video Representations Authors Miao Liu, Xin Chen, Yun Zhang, Yin Li, James M. Rehg 我们使用用于视频识别的深度模型来解决学习运动表示的挑战性问题。为此,我们利用注意力模块,学习突出视频中的区域和聚合功能以进行识别。具体而言,我们建议利用输出关注图作为车辆将学习的表示从运动流网络传输到RGB网络。我们系统地研究了注意模块的设计,并开发了一种新的注意蒸馏方法。我们的方法在主要行动基准上进行了评估,并且始终如一地显着提高了基线RGB网络的性能。此外,我们证明我们的注意力图可以利用学习中的运动提示来识别视频帧中动作的位置。我们相信我们的方法为在深度模型中学习运动感知表示提供了一个步骤。 |
| ShapeMask: Learning to Segment Novel Objects by Refining Shape Priors Authors Weicheng Kuo, Anelia Angelova, Jitendra Malik, Tsung Yi Lin 实例分割旨在检测和分割场景中的各个对象。大多数现有方法依赖于每个类别的精确掩码注释。然而,在新类别中分割对象是困难且昂贵的,因为需要大量掩模注释。我们介绍了ShapeMask,它学习了对象形状的中间概念,以解决实例细分到新类别的泛化问题。 ShapeMask以边界框检测开始,并通过首先通过一组形状先验估计检测到的对象的形状来逐渐细化它。接下来,ShapeMask通过学习实例嵌入将粗糙形状细化为实例级别掩码。形状先验为类似预测的对象提供强大的提示,实例嵌入为实例特定的外观信息建模。在跨类别学习时,ShapeMask显着优于6.4和3.8 AP的技术水平,并在完全监督的环境中获得竞争性能。它对于不准确的检测,降低的模型容量和小的训练数据也很稳健。此外,它以150毫秒的推理时间有效运行,并在11小时内在TPU上进行训练。通过更大的骨干模型,ShapeMask将各种类型的技术与现有技术的差距扩大到9.4和6.2 AP。代码将被释放。 |
| Chinese Abs From Machine Translation |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号