
【今日CV 计算机视觉论文速览 第98期】Wed, 10 Apr 2019
今日CS.CV 计算机视觉论文速览
Wed, 10 Apr 2019
Totally 67 papers
👉上期速览 ✈更多精彩请移步主页

Interesting:
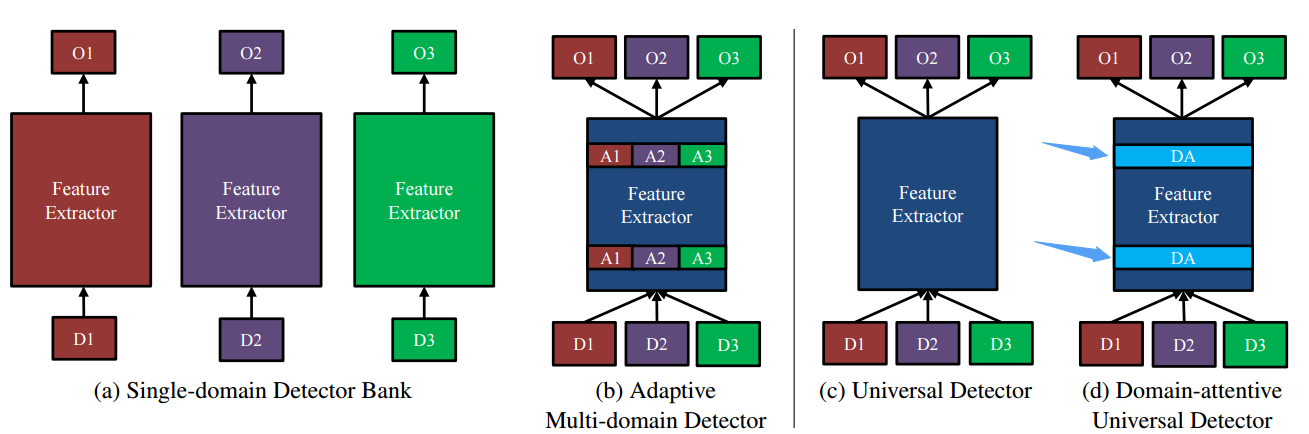
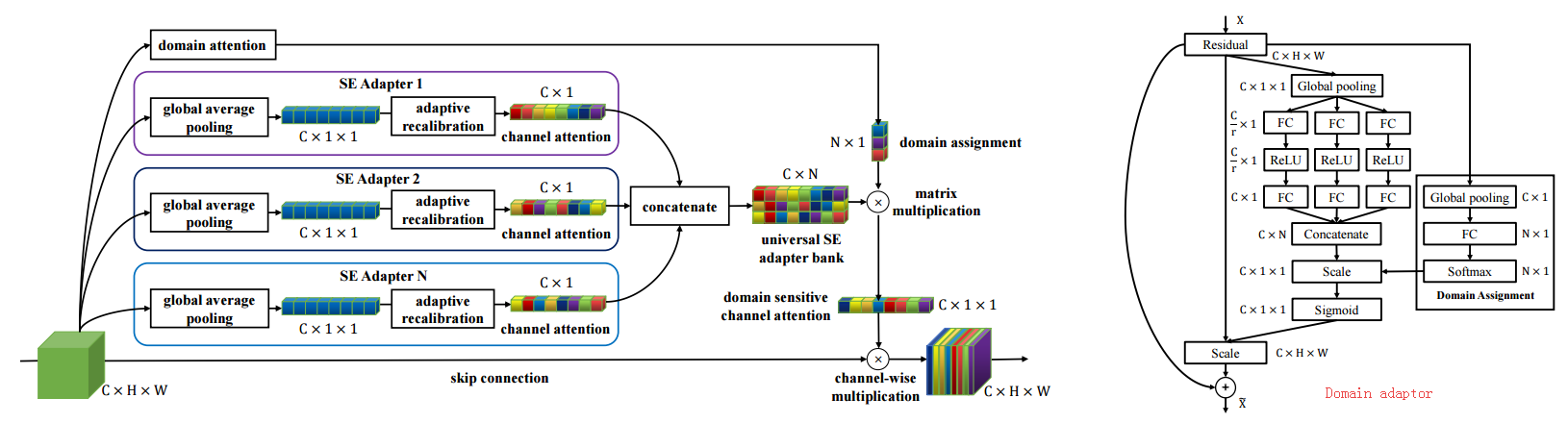
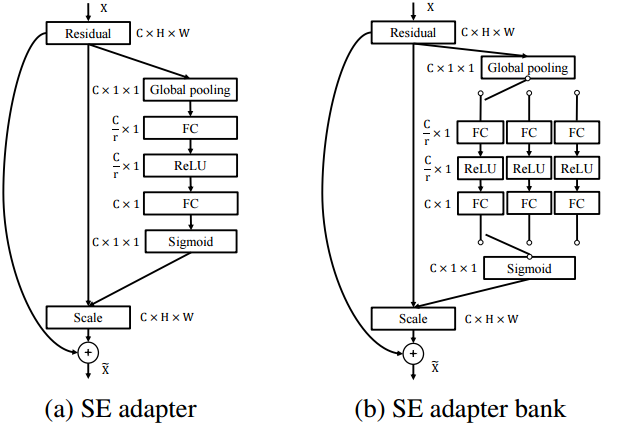
📚通用物体检测框架, 在不需要先验知识的强化下实现了横跨多个域的目标检测,这要通过引入一系列的适应层,基于序列和激活的原理和新域的注意力机制。同时在所有域间共享参数和计算。(from UCSD)
在11个不同数据集上的通用检测:
不同类型的检测器:
网络模型及序列激活单元
code:http://www.svcl.ucsd.edu/projects/universal-detection/

📚基于图割的多模态风格迁移, 通过将风格图像的特征聚类到不同的元素,这些元素则基于图割的方法由局部信息得到。网络将这些特征迁移并渲染到最终的目标图上去。(from 西北大学)
对于风格特征的聚类:
对于风格特征的匹配:



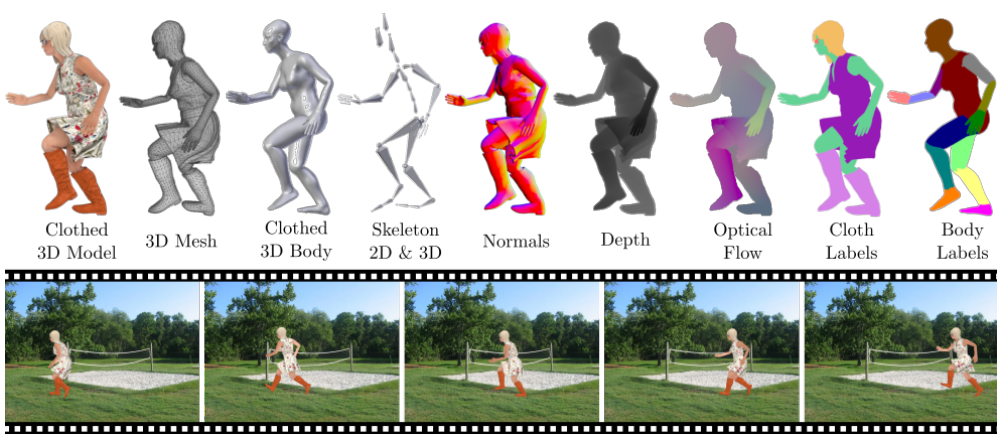
📚3DPeople, 着装情况下的人体几何建模。(from CSIC-UPC 哈佛)
包含了80个主体280段视频序列(四个相机),70个动作的数据集,标注了3D纹理、分割mask、骨架、深度、法向量和光流。
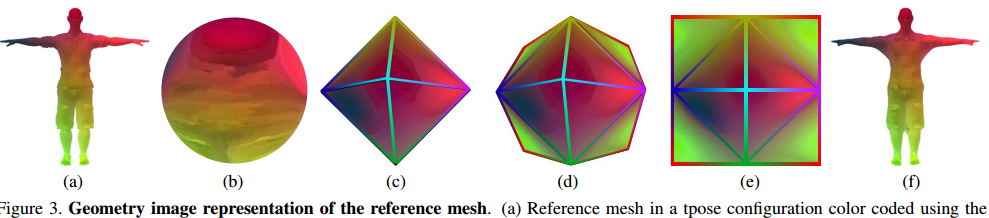
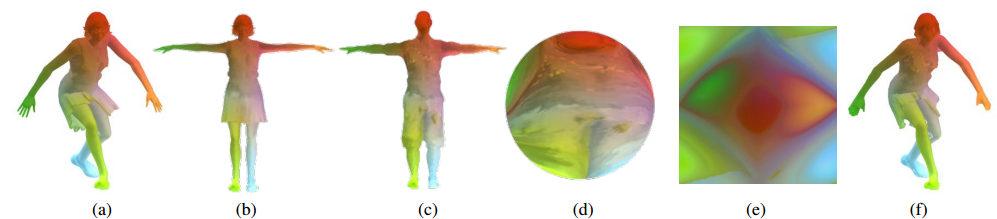
利用二维来表示三维形状,建立了球区域保持参数化算法。以及估计的流程:
最后设计了从着装人体到生成几何图像的网络:
以及一些结果:
数据集:3DPeople Dataset
ref:
https://www.blender.org/
http://www.makehumancommunity.org/
https://www.mixamo.com/#/
matlabICP:https://www.mathworks.com/search/site_search.html?c[]=entire_site&q=ICP
https://www.mathworks.com/matlabcentral/fileexchange/41396-nonrigidicp?s_tid=srchtitle


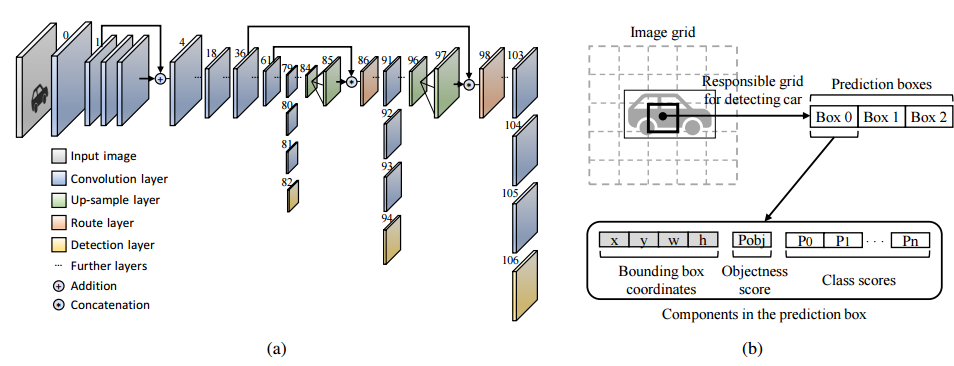
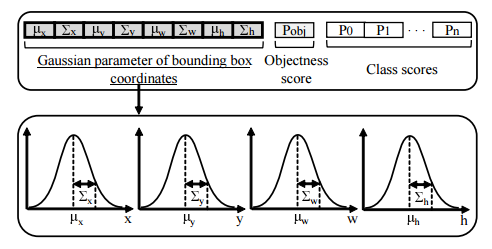
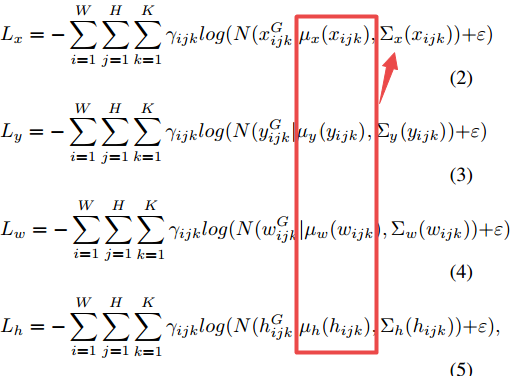
📚Gaussian YOLOv3,利用高斯参数和重新设计的损失来改进yolo v3的精度,通过预测检测过程的不确定度减小了假阳性并提高了TP的概率,最终提高了3.09-3.5的mAP,减小了41.4%-40.62%的FP,增加了4.3%-7.26%的TP,实现了42fps。(from 首尔大学)
将位置xywh的估计变为了四个高斯分布的估计,均值和方差。损失函数最小化均值和方差:
最后是一些结果,下面是加了高速估计的结果:

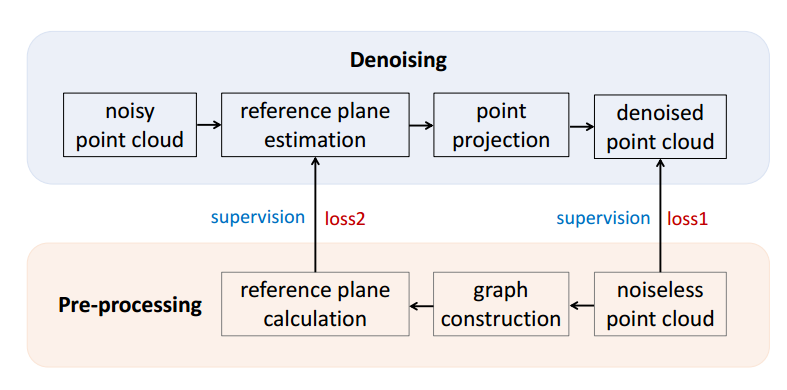
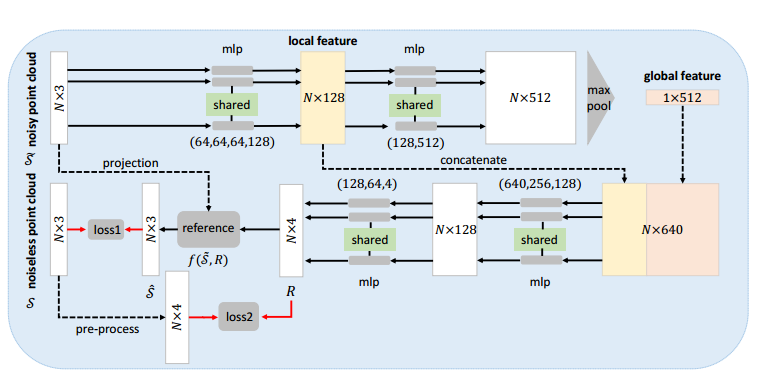
📚NDP三维点云去噪, 基于神经网络估计参考平面,随后将点云投影到参考平面去噪。(from CMU)
流程图和网络架构:
code:https://github.com/chaojingduan/Neural-Projection
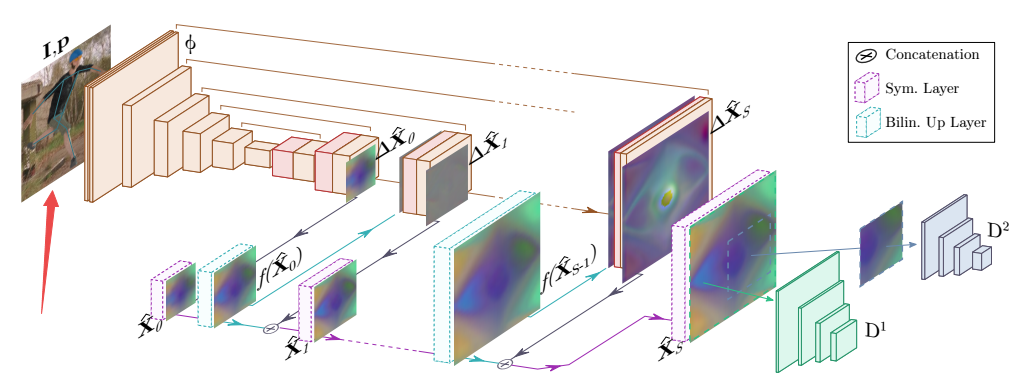
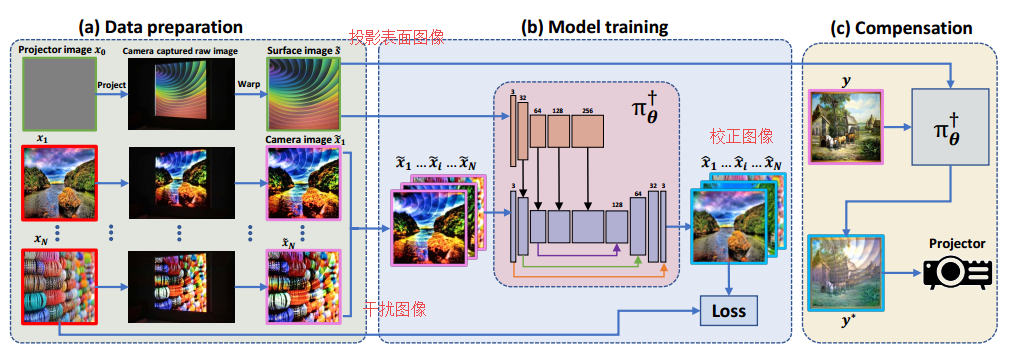
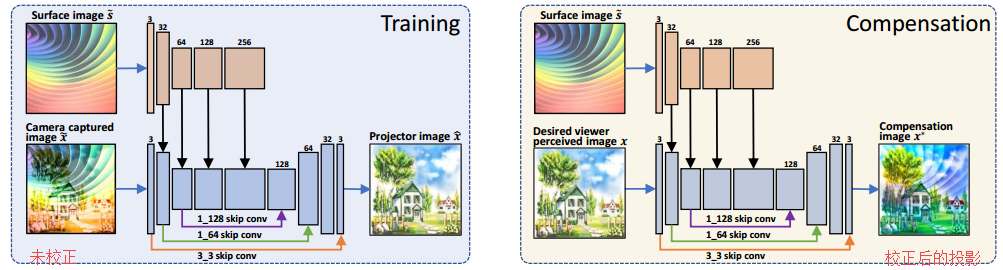
📚CompenNet光度投影补偿方法, (from Meitu HiScene Lab)
训练和补偿的情况,训练重受到平面干扰的图像中个恢复出原图,而补偿则使用网络得到一个补偿后的投影图像,投影后就可以补偿平面的干扰。
不同表面的结果如下:
code:https://github.com/BingyaoHuang/CompenNet

📚UG2+ Track 2 弱视觉条件下的图像理解基准数据集, 包括了雨、雾和弱光条件下的场景。(from http://www.ug2challenge.org/)
ref:
1https://github.com/tzutalin/labelImg
2https://github.com/matterport/Mask RCNN
3https://github.com/fizyr/keras-retinanet
4https://github.com/ayooshkathuria/pytorch-yolo-v3
5https://github.com/DetectionTeamUCAS/FPN Tensorflow
6https://github.com/Boyiliee/AOD-Net
7https://github.com/rwenqi/Multi-scale-CNN-Dehazing
8https://github.com/hezhangsprinter/DCPDN
9https://github.com/TencentYoutuResearch/FaceDetection-DSFD
10https://github.com/EricZgw/PyramidBox
11https://github.com/sfzhang15/SFD
12https://github.com/mahyarnajibi/SSH.git
13https://github.com/playerkk/face-py-faster-rcnn
14https://github.com/baidut/BIMEF
15https://sites.google.com/view/xjguo/lime
16https://github.com/tonghelen/JED-Method
17https://github.com/weichen582/RetinexNet
18http://www.icst.pku.edu.cn/struct/Projects/joint rain removal.html
19https://github.com/XMU-smartdsp/Removing Rain
20https://github.com/TrinhQuocNguyen/Edited Original IDCGAN
21https://github.com/hezhangsprinter/DID-MDN
22https://github.com/rui1996/DeRaindrop



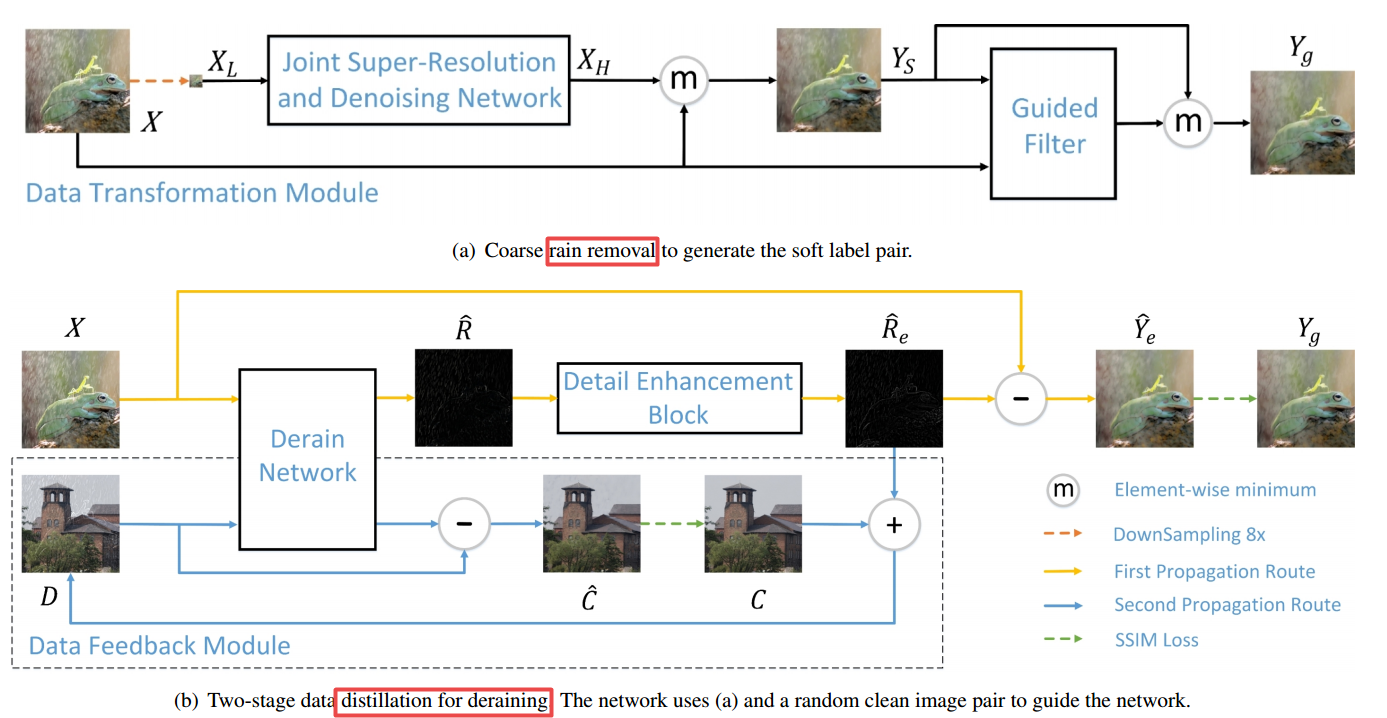
📚Rain O’er Me,合成逼真下雨图片来去雨滴。(from厦门大学)
📚表面缺陷分类及数据集, 将会发布数据集,22000 多种材质的表面缺陷标注图像。(from 德国AI研究中心 )
ref:http://faculty.neu.edu.cn/yunhyan/NEU_surface_defect_database.html

Daily Computer Vision Papers
| Prime Sample Attention in Object Detection Authors Yuhang Cao, Kai Chen, Chen Change Loy, Dahua Lin 对象检测框架中的常见范例是平等地处理所有样本并且目标是平均地最大化性能。在这项工作中,我们通过仔细研究不同样本如何对按mAP衡量的整体绩效做出贡献来重新审视这一范例。我们的研究表明,每个小批次中的样本既不是独立的也不是同等重要的,因此平均更好的分类器并不一定意味着更高的mAP。在本研究的推动下,我们提出了Prime样本的概念,即那些在推动检测性能方面发挥关键作用的样本。我们进一步开发了一种简单而有效的采样和学习策略,称为PrIme Sample Attention PISA,将培训过程的重点转向此类样本。我们的实验表明,在训练探测器时,关注质数样本通常比硬样本更有效。特别是,在MSCOCO数据集上,PISA优于随机抽样基线和硬挖掘方案,例如: OHEM和Focal Loss,在单级和两级探测器上始终保持1个以上,具有强大的主干ResNeXt 101。 |
| Learning from Videos with Deep Convolutional LSTM Networks Authors Logan Courtney, Ramavarapu Sreenivas 本文探讨了使用卷积LSTM同时学习视频中的空间和时间信息。卷积LSTM的深度网络允许模型在数据的所有空间尺度上访问整个时间信息范围。我们描述了涉及用于唇读的卷积LSTM的实验,证明该模型能够选择性地选择哪个时空尺度与特定数据集最相关。所提出的深层体系结构在其他应用中也具有前景,其中时空特征起着至关重要的作用,而不必特别满足网络的设计以满足问题中存在的特定时空特征。对于Wild LRW数据集中的Lip Reading,我们的模型略微优于先前的83.4与83.0相比,并且当模型在Lip Reading Sentences LRS2数据集上预先训练时,将新技术水平设置为85.2。 |
| Unsupervised 3D Pose Estimation with Geometric Self-Supervision Authors Ching Hang Chen, Ambrish Tyagi, Amit Agrawal, Dylan Drover, Rohith MV, Stefan Stojanov, James M. Rehg 我们提出了一种无监督学习方法,用于从单个图像中提取的2D骨骼关节中恢复3D人体姿势。我们的方法不需要任何多视图图像数据,3D骨架,2D 3D点之间的对应关系,或者在训练期间使用先前学习的3D先验。提升网络接受2D地标作为输入并生成相应的3D骨架估计。在训练期间,恢复的3D骨架在随机摄像机视点上重新投影以生成新的合成2D姿势。通过将合成2D姿势提升回3D并在原始相机视图中重新投影它们,我们可以在3D和2D中定义自身一致性损失。因此,通过利用升力重新投影升力过程的几何自洽性,可以自我监督训练。我们表明单独的自我一致性不足以生成逼真的骨架,但是添加2D姿势鉴别器使得升降器能够输出有效的3D姿势。此外,为了从野外的2D姿势中学习,我们训练了一个无监督的2D域适配器网络,以允许扩展2D数据。这改善了结果并且证明了2D姿势数据对于无监督3D提升的有用性。用于3D人体姿势估计的Human3.6M数据集的结果表明我们的方法在先前的无监督方法上改进了30并且优于许多明确使用3D数据的弱监督方法。 |
| CMIR-NET : A Deep Learning Based Model For Cross-Modal Retrieval In Remote Sensing Authors Ushasi Chaudhuri, Biplab Banerjee, Avik Bhattacharya, Mihai Datcu 我们解决了遥感领域中的交叉模态信息检索问题。特别地,我们感兴趣的是两种应用场景,即在全色PAN和多光谱图像之间进行模态检索,以及ii在非常高分辨率的VHR图像和基于语音的标签注释之间的多标签图像检索。请注意,考虑到模态之间分布的固有差异,这些多模态检索场景比传统的单模态检索方法更具挑战性。然而,随着多源遥感数据的日益普及以及足够的语义注释的缺乏,多模态检索的任务最近变得极为重要。在这方面,我们提出了一种新颖的基于深度神经网络的体系结构,其被认为是针对所有输入模态学习辨别共享特征空间,适用于语义相干信息检索。对基准大规模PAN多光谱DSRSID数据集和多标签UC Merced数据集进行了大量实验。与Merced数据集一起,我们生成对应于标签的语音信号语料库。在所有情况下都观察到相对于现有技术的优异性能。 |
| Multi-Agent Tensor Fusion for Contextual Trajectory Prediction Authors Tianyang Zhao, Yifei Xu, Mathew Monfort, Wongun Choi, Chris Baker, Yibiao Zhao, Yizhou Wang, Ying Nian Wu 准确预测其他轨迹对于自动驾驶至关重要。轨迹预测具有挑战性,因为它需要推理代理人过去的动作,不同数量和类型的代理人之间的社会交互,场景背景的约束以及人类行为的随机性。我们的方法在一个新的Multi Agent Tensor Fusion MATF网络中共同模拟这些相互作用和约束。具体地,该模型将多个代理经过轨迹和场景上下文编码到多代理张量中,然后应用卷积融合来捕获多代理交互,同时保留代理的空间结构和场景上下文。该模型反复解码为多个代理未来轨迹,使用对抗性损失来学习随机预测。高速公路驾驶和行人人群数据集的实验表明,该模型实现了最先进的预测精度。 |
| Adversarial Learning of Disentangled and Generalizable Representations for Visual Attributes Authors James Oldfield, Yannis Panagakis, Mihalis A. Nicolaou 最近,用于图像到图像转换的多种方法已经在诸如多域或多属性转移的问题上展示了令人印象深刻的结果。绝大多数此类工作利用对抗性学习的优势与深度卷积自动编码器相结合,通过很好地捕获目标数据分布来实现真实的结果。然而,这类方法中最突出的代表不利于潜在空间中的语义结构,并且通常依赖于域标签来进行测试时间转移。这导致刚性模型无法捕获每个域标签的方差。有鉴于此,我们提出了一种新颖的对抗性学习方法,它通过基于新的成本函数解开变异来源来促进潜在结构,并且鼓励学习可用于诸如不成对的多域图像之类的任务的可推广,连续和可转移的潜在代码。转移和合成,无需标记的测试数据。所得到的表示可以以任意方式组合以生成新颖的混合图像,例如生成身份的混合。我们通过一组关于流行数据库的定性和定量实验证明了所提方法的优点,其中我们的方法明显优于其他最先进的方法。可以在以下位置找到复制我们结果的代码 |
| User-Controllable Multi-Texture Synthesis with Generative Adversarial Networks Authors Aibek Alanov, Max Kochurov, Denis Volkhonskiy, Daniil Yashkov, Evgeny Burnaev, Dmitry Vetrov 我们提出了一种基于具有用户可控机制的生成对抗网络GAN的新型多纹理合成模型。用户控制能力允许明确指定应由模型生成的纹理。该属性遵循使用编码器部分,该编码器部分从数据集学习每个纹理的潜在表示。为了确保数据集覆盖,我们使用对抗性损失函数来惩罚给定纹理的错误复制。在实验中,我们展示了我们的模型可以为大型数据集和原始数据(如高分辨率照片集)学习描述性纹理流形。此外,我们应用我们的方法来生成3D纹理并显示它优于现有基线。 |
| Segmentation of Skeletal Muscle in Thigh Dixon MRI Based on Texture Analysis Authors Rafael Rodrigues, Antonio M. G. Pinheiro 磁共振图像中骨骼肌的分割MRI对肌肉生理学和肌肉病理学诊断的研究至关重要。然而,大型MRI体积的手动分割是一项耗时的任务。关于MRI中肌肉分割的算法的现有技术仍然不是非常广泛并且在某种程度上依赖于数据库。本文提出了一种基于AdaBoost局部纹理特征分类的自动分割方法。纹理描述符包括方向梯度直方图HOG,基于小波的特征,以及从灰度MRI的高斯滤波的原始和拉普拉斯算子计算的一组统计测量。分类器性能表明纹理分析可能是设计通用和自动MRI肌肉分割框架的有用工具。此外,本文还描述了基于图谱的个体肌肉分割方法。通过使用适当的仿射变换在图像对准之后覆盖由放射科医师提供的肌肉分割基础事实来获得图谱。然后,它用于在AdaBoost二进制分割上定义肌肉标签。当获得准确的肌肉组织分割时,开发的图谱方法提供合理的结果。 |
| Cross-Modal Self-Attention Network for Referring Image Segmentation Authors Linwei Ye, Mrigank Rochan, Zhi Liu, Yang Wang 我们考虑引用图像分割的问题。给定输入图像和自然语言表达,目标是分割图像中语言表达引用的对象。此区域中的现有作品将语言表达式和输入图像分别用于表示。它们没有充分捕捉这两种方式之间的长距离相关性。在本文中,我们提出了一种跨模式自我关注CMSA模块,它有效地捕获了语言和视觉特征之间的长期依赖关系。我们的模型可以自适应地关注参考表达中的信息词和输入图像中的重要区域。此外,我们提出了一种门控多级融合模块,以选择性地集成对应于图像中不同级别的自注意交叉模态特征。该模块控制不同级别的功能的信息流。我们在四个评估数据集上验证了所提出的方法。我们提出的方法始终优于现有技术方法。 |
| Learning Across Tasks and Domains Authors Pierluigi Zama Ramirez, Alessio Tonioni, Samuele Salti, Luigi Di Stefano 最近的工作证明,许多相关的视觉任务彼此密切相关。然而,由于缺乏将学习概念转移到不同列车的实用方法,这种联系在实践中很少被部署。在这项工作中,我们引入了一个新的适应框架,可以跨任务和域运行。我们的框架学习如何在完全受监督的域中跨任务传递知识,例如合成数据,并将该知识用于我们仅具有部分监督的不同域,例如真实数据。我们的提议是对现有域适应技术的补充,并将其扩展到跨任务场景,从而提供额外的性能提升。我们证明了我们的框架在两个具有挑战性的任务中的有效性,即单眼深度估计和语义分割以及四个不同的领域Synthia,Carla,Kitti和Cityscapes。 |
| Generative Models for Novelty Detection: Applications in abnormal event and situational change detection from data series Authors Mahdyar Ravanbakhsh 新颖性检测是用于区分在某些方面与训练模型的观察结果不同的观察结果的过程。新颖性检测是良好分类或识别系统的基本要求之一,因为有时测试数据包含在训练时未知的观察结果。换句话说,新颖类通常不会在训练阶段呈现或没有明确定义。 |
| Label Propagation for Deep Semi-supervised Learning Authors Ahmet Iscen, Giorgos Tolias, Yannis Avrithis, Ondrej Chum 半监督学习变得越来越重要,因为它可以将人类仔细标记的数据与丰富的未标记数据相结合,以训练深度神经网络。关于转导学习的半监督学习的经典方法尚未在现代深度学习的归纳框架中得到充分利用。对于类似的例子应该得到相同的预测的多方面假设也是如此。在这项工作中,我们采用转换标签传播方法,该方法基于流形假设对整个数据集进行预测,并使用这些预测为未标记数据生成伪标签并训练深度神经网络。转换方法的核心是我们基于同一网络的嵌入创建的数据集的最近邻图。因此,我们的学习过程在这两个步骤之间进行迭代。我们改进了几个数据集的性能,特别是在少数标签制度中,并表明我们的工作是对当前最新技术的补充。 |
| End-to-End Learning-Based Ultrasound Reconstruction Authors Walter Simson, R diger G bl, Magdalini Paschali, Markus Kr nke, Klemens Scheidhauer, Wolfgang Weber, Nassir Navab 在寻求最高图像质量和临床可用性的必要性之间捕获超声成像。我们的贡献是双倍首先,我们提出了一种用于超声重建的新型完全卷积神经网络。其次,针对模态定制的自定义损失函数用于网络的端到端训练。我们证明,训练网络将时间延迟的原始数据映射到最小的方差基础事实可以提高临床环境中的性能。在这样做的过程中,探索了一条改进临床可行的超声重建的途径。所提出的方法在集成用于实时超声扫描时显示有前途的图像重建质量和获取频率。进行临床评估以验证所提出的方法在临床环境中的诊断有用性。 |
| Fast Accurate CT Metal Artifact Reduction using Data Domain Deep Learning Authors Muhammad Usman Ghani, W. Clem Karl 滤波反投影FBP是X射线计算机断层扫描CT扫描仪中最广泛使用的图像重建方法。场景中存在超高密度材料(例如金属)会强烈衰减X射线,从而在重建中产生严重的条纹伪影。这些金属伪影可以极大地限制随后的物体描绘和从图像中提取信息,从而限制了它们的诊断价值。这个问题在安全领域尤其严重,在安全领域中,可能出现在场景中的对象存在很大的异质性,必须快速做出高度准确的决策。减少CT图像中的金属伪影的标准实用方法是基于简单的非自适应插值的投影数据完成方法或直接图像后处理方法。这些标准方法的成功有限。主要受安全应用的推动,我们提出了一种新的基于深度学习的金属伪影减少MAR方法,该方法解决了投影数据领域中的问题。我们将对应于金属物体的投影数据视为缺失数据,并训练对抗性深层网络以完成投影域中的缺失数据。然后,随后的完整投影数据与FBP一起用于重建旨在没有伪像的图像。这种新方法产生了端到端MAR算法,该算法在计算上非常有效,并且非常适合现有的CT工作流程,可以在现有扫描仪中轻松采用。训练深度网络可能具有挑战性,我们工作的另一个贡献是证明使用精确的X射线模拟生成的训练数据可以用于在与使用有限的真实数据集的转移学习相结合时成功训练深度网络。我们证明了我们的算法在模拟和实际例子中的有效性和潜力。 |
| Action Recognition from Single Timestamp Supervision in Untrimmed Videos Authors Davide Moltisanti, Sanja Fidler, Dima Damen 识别视频中的动作依赖于训练期间的标记监督,通常是每个动作实例的开始和结束时间。这种监督不仅是主观的,而且也很昂贵。弱视频级别监控已成功用于未修剪视频中的识别,但是当培训视频中不同操作的数量增加时,它受到挑战。我们提出了一种方法,该方法由位于每个动作实例周围的单个时间戳监视,在未修剪的视频中。我们用从这些时间戳初始化的采样分布替换昂贵的动作范围。然后,我们使用分类器的响应来迭代地更新采样分布。我们证明这些分布收敛于判别行为部分的位置和范围。我们在三个数据集上评估我们的方法以进行细粒度识别,每个视频的不同操作数量不断增加,并且表明单个时间戳在识别性能和标记工作之间提供了合理的折衷,与完整的时间监督相比。我们的更新方法将前1个测试精度提高了5.4。跨评估的数据集。 |
| Multi-Target Embodied Question Answering Authors Licheng Yu, Xinlei Chen, Georgia Gkioxari, Mohit Bansal, Tamara L. Berg, Dhruv Batra 体验性问题回答EQA是一项相对较新的任务,要求代理人以自我中心的方式回答有关其环境的问题。 EQA做出了一个基本的假设,即每个问题,例如汽车的颜色,都只有一辆目标车被询问。这种假设直接限制了代理人的能力。我们提出了EQA多目标EQA MT EQA的概括。具体来说,我们研究其中有多个目标的问题,例如卧室中的梳妆台是否比厨房中的烤箱大,其中代理必须导航到卧室中的多个位置梳妆台,厨房中的烤箱以及执行比较推理的梳妆台更大而不是烤箱才能回答问题。这些问题需要在代理中开发全新的模块或组件。为了解决这个问题,我们提出了一种模块化架构,它由程序生成器,控制器,导航器和VQA模块组成。程序生成器将给定问题转换为顺序可执行子程序,导航器将代理引导到与导航相关子程序相关的多个位置,并且控制器学习沿其路径选择相关观察。然后将这些观察结果输入VQA模块以预测答案。我们对每个模型组件进行详细分析,并表明我们的联合模型可以大大优于以前的方法和强大的基线。 |
| Domain-Symmetric Networks for Adversarial Domain Adaptation Authors Yabin Zhang, Hui Tang, Kui Jia, Mingkui Tan 无监督域适应的目的是在给定源域上标记样本的训练数据的情况下,学习目标域上未标记样本的分类器模型。最近通过深度网络的域对抗性训练学习不变特征,取得了令人瞩目的进展。尽管最近取得了进展,但领域适应仍然有限,无法在更精细的类别级别实现特征分布的不变性。为此,我们在本文中提出了一种新的域自适应方法,称为域对称网络SymNets。建议的SymNet基于源和目标任务分类器的对称设计,在此基础上我们还构造了一个额外的分类器,与它们共享其层神经元。为了训练SymNet,我们提出了一种新颖的对抗性学习目标,其关键设计基于两级域混淆方案,其中类别级别的混淆损失通过推动中间网络特征的学习在不变的情况下在域级别1上得到改善。两个域的相应类别。域辨别和域混淆都是基于构造的附加分类器实现的。由于目标样本未标记,我们还提出了跨域培训方案,以帮助学习目标分类器。仔细消融研究表明我们提出的方法的功效。特别是,基于常用的基础网络,我们的SymNets在三个基准域自适应数据集上实现了新的技术水平。 |
| Holistic and Comprehensive Annotation of Clinically Significant Findings on Diverse CT Images: Learning from Radiology Reports and Label Ontology Authors Ke Yan, Yifan Peng, Veit Sandfort, Mohammadhadi Bagheri, Zhiyong Lu, Ronald M. Summers 在放射科医师的日常工作中,一个主要任务是读取医学图像,例如CT扫描,发现重大病变,并在放射学报告中描述它们。在本文中,我们研究病变描述或注释问题。鉴于病变图像,我们的目标是预测一组全面的相关标签,例如病变的身体部位,类型和属性,这可能有助于下游细粒度诊断。为了解决这个任务,我们首先设计一个深度学习模块,从与病变图像相关的放射学报告中提取相关的语义标签。利用图像和文本挖掘标签,我们提出了一个基于多标记卷积神经网络CNN的病变注释网络LesaNet,以全面学习所有标签。利用标签之间的分层关系和互斥关系来提高标签预测的准确性。这些关系用于标签扩展策略和关系硬件示例挖掘算法。我们还在LesaNet上附加了一个简单的分数传播层,以增强回忆并探索标签之间的隐式关系。多标签度量学习与分类相结合以实现可解释的预测。我们在公共DeepLesion数据集上评估了LesaNet,该数据集包含超过32K的不同病变图像。实验表明,LesaNet可以使用171个细粒度标签的本体论精确地对病变进行注释,平均AUC为0.9344。 |
| Towards Analyzing Semantic Robustness of Deep Neural Networks Authors Abdullah Hamdi, Bernard Ghanem 尽管深度神经网络DNN在各种视觉任务上的表现令人印象深刻,但它们仍然对语义原语表现出错误的高灵敏度,例如:对象姿势。我们提出了DNN在语义空间中的鲁棒性的理论基础分析。我们通过将DNN全局行为可视化为语义映射并观察某些DNN的有趣行为来定性地分析不同DNN的语义稳健性。由于生成这些语义映射不能很好地与语义空间的维度成比例,因此我们开发了一种自下而上的方法来检测DNN的稳健区域。为了实现这一点,我们将寻找网络的强大语义区域作为整数边界的优化并为区域边界的更新方向开发表达式的问题正式化。我们使用我们开发的公式来定量评估不同着名网络架构的语义稳健性。我们通过大量实验展示了几个网络,虽然在同一数据集上训练并且在享受相当的准确性的同时,但它们在语义鲁棒性方面的表现并不一定。例如,尽管InceptionV3在语义上比ResNet50更健壮,但它更准确。我们希望这个工具将成为理解DNN语义鲁棒性的第一个里程碑。 |
| Gaussian YOLOv3: An Accurate and Fast Object Detector Using Localization Uncertainty for Autonomous Driving Authors Jiwoong Choi, Dayoung Chun, Hyun Kim, Hyuk Jae Lee 物体检测算法的使用在自动车辆中变得越来越重要,并且高精度和快速推理速度的物体检测对于安全自动驾驶是必不可少的。在自动驾驶期间来自错误定位的假阳性FP可导致致命事故并且妨碍安全且有效的驾驶。因此,在自动驾驶应用中需要能够应对误定位的检测算法。本文提出了一种在支持实时操作的同时,通过建模YOLOv3的边界框bbox来提高检测精度的方法,YOLOv3是一阶段检测器中最具代表性的,具有高斯参数并重新设计损失函数。此外,本文提出了一种预测定位不确定性的方法,该方法指出了bbox的可靠性。通过在检测过程中使用预测的定位不确定性,所提出的方案可以显着降低FP并增加真正的TP,从而提高准确度。与传统的YOLOv3相比,所提出的算法Gaussian YOLOv3分别在KITTI和Berkeley深度驱动BDD数据集上将平均精度mAP提高了3.09和3.5。此外,在相同的数据集上,所提出的算法可以将FP降低41.40和40.62,并且将TP分别增加7.26和4.3。然而,所提出的算法能够以比每秒42帧fps更快的速度进行实时检测。 |
| Rain O'er Me: Synthesizing real rain to derain with data distillation Authors Huangxing Lin, Yanlong Li, Xinghao Ding, Weihong Zeng, Yue Huang, John Paisley 我们提出了一种监督技术,用于学习如何在不使用合成雨软件的情该方法基于两阶段数据蒸馏方法1首先使用简单的过滤技术雨来清洁雨季图像与粗略排除的版本。 2然后将干净的图像与雨下的软标记对随机匹配。通过共享的深度神经网络,然后将从第一图像移除的雨添加到清洁图像以产生第二对清洁雨。神经网络同时学习映射两个图像,使得清洁图像中的高分辨率结构可以通知雨天图像的消除。演示表明,这种方法可以解决雨水的视觉特征,这些特征不容易通过软件以通常的方式合成。 |
| 3DPeople: Modeling the Geometry of Dressed Humans Authors Albert Pumarola, Jordi Sanchez, Gary P. T. Choi, Alberto Sanfeliu, Francesc Moreno Noguer 3D人体形状估计的最新进展建立在参数化表示上,其非常好地模拟裸体的形状,但不适合于表示服装几何形状。在本文中,我们提出了一种模拟穿着人类的方法,并从单个图像中预测它们的几何形状。我们在该问题的三个基本方面做出贡献,即新数据集,新颖的形状参数化算法和用于预测形状的端到端深度生成网络。 |
| Deep Virtual Networks for Memory Efficient Inference of Multiple Tasks Authors Eunwoo Kim, Chanho Ahn, Philip H.S. Torr, Songhwai Oh 深度网络本质上消耗大量内存。一个自然的问题是我们可以在保持性能的同时减少内存需求。特别是,在这项工作中,我们解决了针对多个任务的内存有效学习问题。为此,我们提出了一种新颖的网络架构,用于生成不同配置的多个网络,称为深度虚拟网络DVN,用于不同的任务。每个DVN专门用于单个任务并按层次结构进行组织。包含对应于不同数量的参数的多个层次结构的分层结构使得能够对不同的存储器预算进行多个推断。深度虚拟网络的构建块基于网络参数的不相交集合,我们将其称为单元。深层虚拟网络中的最低层次结构是一个单元,更高层次的层次结构包含较低级别的单元和其他附加单元。给定参数数量的预算,可以选择不同级别的深度虚拟网络来执行任务。一个单元可以由不同的DVN共享,允许单个网络中的多个DVN。此外,共享单元通过从其他任务中学到的额外知识为目标任务提供帮助。 DVN的这种协作配置使得以存储器感知方式处理不同任务成为可能。我们的实验表明,所提出的方法优于现有的多任务方法。值得注意的是,我们的效率比其他任务更高,因为它允许对所有任务进行内存感知推理。 |
| Assessing Capsule Networks With Biased Data Authors Bruno Ferrarini 1 , Shoaib Ehsan 1 , Adrien Bartoli 2 , Ale Leonardis 3 , Klaus D. McDonald Maier 1 1 University of Essex, CSEE, Wivenhoe Park, Colchester CO4 3SQ, UK 2 Facult e de M edecine, 28 Place Henri Dunant, 63000 Clermont Ferrand, France 3 University of Birmingham, School of Computer Science, Birmingham B15 2TT, UK 基于机器学习的方法在对象分类和检测方面取得了令人瞩在训练阶段利用视觉世界的代表性数据对于利用这种数据驱动方法实现良好性能至关重要。然而,并不总是可以访问无偏差数据集,因此对偏差数据的鲁棒性是学习系统的理想特性。 Capsule Networks最近已经推出,它们对偏见数据的容忍度很少受到关注。本文旨在填补这一空白,并提出两种实验方案来评估对不平衡训练数据的容忍度,并确定模型的泛化性能,并对图像进行不熟悉的仿射变换。本文评估了基于动态路由和EM路由的胶囊网络,并在两个测试场景中提出了与卷积神经网络的比较。所呈现的结果提供了对胶囊网络行为的新见解。 |
| BoLTVOS: Box-Level Tracking for Video Object Segmentation Authors Paul Voigtlaender, Jonathon Luiten, Bastian Leibe 我们通过将任务分成两个子任务来限制盒级跟踪,然后是边界框分割来接近视频对象分割VOS。在这个范例之后,我们提出了针对VOS的BoLTVOS盒级跟踪,其包括以第一帧边界框为条件的R CNN检测器以检测感兴趣的对象,时间一致性重新绑定算法以及将边界框转换为分割的Box2Seg网络。口罩。 BoLTVOS仅使用没有掩码的第一帧边界框执行VOS。我们评估了我们在DAVIS 2017和YouTube VOS上的方法,并表明它优于所有不执行第一帧微调的方法。我们进一步展示了BoLTVOS ft,它学习在跟踪时使用第一个帧掩码对所讨论的对象进行分段,而不增加运行时间。 BoLTVOS ft优于PReMVOS,这是之前在DAVIS 2016和YouTube VOS上性能最佳的VOS方法,运行速度提高了45倍。我们的边界框跟踪器在边界框级跟踪数据集OTB 2015和LTB35上也优于所有以前的短期和长期跟踪器。 |
| Graphonomy: Universal Human Parsing via Graph Transfer Learning Authors Ke Gong, Yiming Gao, Xiaodan Liang, Xiaohui Shen, Meng Wang, Liang Lin 先前高度调整的人类解析模型倾向于适合特定域中的每个数据集或具有不一致的标签粒度,并且在没有大量重新训练的情况下很难适应其他人类解析任务。在本文中,我们的目标是学习一个通用的人类解析模型,它可以通过统一来自不同域或不同粒度级别的标签注释来解决各种人类解析需求。这带来了许多基本的学习挑战,例如发现不同标签粒度之间的基础语义结构,跨不同图像域执行适当的转移学习,以及识别和利用相关任务中的标签冗余。 |
| Uncertainty Measures and Prediction Quality Rating for the Semantic Segmentation of Nested Multi Resolution Street Scene Images Authors Matthias Rottmann, Marius Schubert 在街景的语义分割中,预测的可靠性以及因此不确定性度量是最受关注的。我们提出了一种方法,该方法为每个输入图像生成图像中心周围的嵌套作物的层次结构,并将这些作物重新缩放到相同的大小,并提供给神经网络以进行语义分割。然后对得到的softmax输出进行后处理,以便我们可以研究所有图像作物的均值和方差,以及从像素方面获得的不确定性热图的均值和方差,如熵,应用于每个作物的softmax输出。在我们的测试中,我们使用在Cityscapes数据集上训练的公开可用的DeepLabv3 MobilenetV2网络,并证明作物的结合提高了预测的质量,并且我们获得了更可靠的不确定性测量。然后将这些聚合在预测的片段上,用于在IoU 0和IoU 0元分类之间进行分类或通过线性回归元回归预测IoU。后者为分段网络产生可靠的性能估计,特别是在没有基础事实的情况下有用。对于元分类的任务,我们获得81.93的分类准确度和89.89的AUROC。对于元回归,我们得到R 2值为84.77。与其他方法相比,这些结果产生显着改善。 |
| High-Resolution Representations for Labeling Pixels and Regions Authors Ke Sun, Yang Zhao, Borui Jiang, Tianheng Cheng, Bin Xiao, Dong Liu, Yadong Mu, Xinggang Wang, Wenyu Liu, Jingdong Wang 高分辨率表示学习在许多视觉问题中起着重要作用,例如姿势估计和语义分割。最近开发用于人体姿态估计的高分辨率网络HRNet引用SunXLW19,通过在并行连接高分辨率和低分辨率卷积的整个过程中保持高分辨率表示,并通过在并行卷积上重复进行融合来产生强大的高分辨率表示。 |
| Convolutional Temporal Attention Model for Video-based Person Re-identification Authors Tanzila Rahman, Mrigank Rochan, Yang Wang 基于视频的人物识别的目标是匹配两个输入视频,以便如果两个视频包含相同的人,则两个视频的距离很小。用于人物识别的常见方法是首先提取视频中所有帧的图像特征,然后聚合所有特征以形成视频级特征。然后可以使用两个视频的视频级别功能来计算两个视频的距离。在本文中,我们提出了一种时间关注方法,用于将帧级特征聚合到视频级特征向量中以进行重新识别。我们的方法的动机是,视频中并非所有帧都具有同等信息。我们提出了一种完全卷积时间注意模型来产生注意力得分。完全卷积网络FCN已广泛用于语义分割以生成2D输出映射。在本文中,我们将基于视频的人重新识别制定为序列标注问题,如语义分割。我们在它们之间建立连接并修改FCN以生成注意力分数以表示每个帧的重要性。对三种不同基准数据集的广泛实验,即iLIDS VID,PRID 2011和SDU VID,表明我们提出的方法优于其他最先进的方法。 |
| UG$^{2+}$ Track 2: A Collective Benchmark Effort for Evaluating and Advancing Image Understanding in Poor Visibility Environments Authors Ye Yuan, Wenhan Yang, Wenqi Ren, Jiaying Liu, Walter J. Scheirer, Zhangyang Wang IEEE CVPR 2019中的UG 2挑战旨在唤起对低水平视觉技术如何在各种情况下有益于高水平自动视觉识别的全面讨论和探索。在第二条轨道中,我们专注于物体或人脸检测,因为恶劣的天气雾霾,雨水和低光照条件导致能见度降低。虽然现有的增强方法在经验上有望用于帮助高级别的最终任务,但实际情况并非总是如此。为了提供更彻底的检查和公平比较,我们分别介绍了在现实世界中模糊的,阴雨天气和低光照条件下收集的三个基准集,其中注释对象面临注释。据我们所知,这是同类中第一个也是目前最大的努力。报告了通过级联现有增强和检测模型的基线结果,表明我们的新数据极具挑战性,以及进一步技术创新的巨大空间。我们期望广泛的研究团体大量参与,共同应对这些挑战。 |
| MVF-Net: Multi-View 3D Face Morphable Model Regression Authors Fanzi Wu, Linchao Bao, Yajing Chen, Yonggen Ling, Yibing Song, Songnan Li, King Ngi Ngan, Wei Liu 我们解决了在多个视图中从一组面部图像恢复人脸的3D几何的问题。虽然最近的研究已经显示出基于3D Morphable Model 3DMM的面部重建的令人印象深刻的进展,但是设置主要限于单个视图。单一视图设置存在固有的缺点,缺乏可靠的3D约束可能导致无法解决的模糊。在本文中,我们在不同的设置中探索基于3DMM的形状恢复,其中给出一组多视图面部图像作为输入。提出了一种新方法,用于从具有端到端可训练卷积神经网络CNN的多视图输入回归3DMM参数。通过利用新颖的自监督视图对准损失在不同视图之间建立密集对应,将多视图几何约束结合到网络中。视图对齐损失的主要成分是可微分密集光流估计器,其可以反向传播输入视图与来自另一输入视图的合成渲染之间的对齐误差,其通过3D形状投影到目标视图以被推断。通过最小化视图对准损失,可以恢复更好的3D形状,使得从一个视图到另一个视图的合成投影可以更好地与观察到的图像对准。大量实验证明了所提方法优于其他3DMM方法的优越性。 |
| Intra-Ensemble in Neural Networks Authors Yuan Gao, Zixiang Cai, Yimin Chen, Wenke Chen, Kan Yang, Chen Sun, Cong Yao 提高模型性能始终是机器学习的关键问题,包括深度学习。然而,当堆叠更多层时,独立的神经网络总是受到边际效应的影响。同时,集合是进一步增强模型性能的有用技术。然而,训练几个独立的独立深度神经网络需要花费多种资源。在这项工作中,我们提出Intra Ensemble,一种端到端策略,具有随机训练操作,可在一个神经网络内同时训练多个子网络。由于大多数参数是相互共享的,因此附加参数大小是边际的。同时,随机训练通过权重共享增加子网络的多样性,这显着增强了内部集合性能。大量实验证明了帧内集合在各种数据集和网络架构中的适用性。我们的模型与CIFAR 10和CIFAR 100上的最新架构实现了可比较的结果。 |
| SPM-Tracker: Series-Parallel Matching for Real-Time Visual Object Tracking Authors Guangting Wang, Chong Luo, Zhiwei Xiong, Wenjun Zeng 视觉对象跟踪面临的最大挑战是对鲁棒性和辨别力的同时要求。在本文中,我们提出了一个基于SiamFC的跟踪器,名为SPM Tracker,以应对这一挑战。基本思想是在两个独立的匹配阶段解决这两个要求。通过广义训练在粗匹配CM阶段中增强鲁棒性,同时通过远程学习网络在精细匹配FM阶段中增强辨别力。当CM阶段的输入提议由CM阶段生成时,这两个阶段串联连接。它们也是并行连接的,因为匹配分数和盒位置细化被融合以产生最终结果。这种创新的串联并联结构充分利用了两个阶段,从而实现了卓越的性能。拟议的SPM跟踪器在GPU上以120fps运行,在OTB 100上达到了0.687的AUC,在VOT 16上达到了0.434的EAO,超过了其他实时跟踪器的显着优势。 |
| Ultrafast Video Attention Prediction with Coupled Knowledge Distillation Authors Kui Fu, Jia Li, Yafei Song, Yu Zhang, Shiming Ge, Yonghong Tian 最近,大型卷积神经网络模型在视频注意力预测方面表现出了令人印象深刻传统上,这些模型具有密集的计算和大的存储器。为了解决这些问题,我们设计了一个超快速的超轻型网络,名为UVA Net。网络基于深度方式的卷积构建,并将低分辨率图像作为输入。但是,这种直接加速方法会显着降低性能。为此,我们提出了一种耦合知识蒸馏策略,以有效地增强和训练网络。通过此策略,模型可以进一步自动发现并强调数据中包含的隐含有用提示。由高分辨率复杂教师网络学习的空间和时间知识也可以被提炼并转移到所提出的低分辨率轻量级时空网络中。实验结果表明,我们的模型的性能可与视频注意力预测中的十种最先进模型相媲美,而其内存占用仅为0.68 MB,GPU上运行约10,106 FPS,CPU上运行404 FPS,比其快206倍。以前的型号。 |
| Semi-Supervised Segmentation of Salt Bodies in Seismic Images using an Ensemble of Convolutional Neural Networks Authors Yauhen Babakhin, Artsiom Sanakoyeu, Hirotoshi Kitamura 地震图像分析在广泛的工业应用中起着至关重要的作用,并且受到了极大的关注。地震成像的一个基本挑战是探测地下盐结构,这对于识别油气藏和钻探路径规划是必不可少的。不幸的是,大型盐沉积物的精确识别是众所周知的困难,专业的地震成像通常需要专业的人体解释盐体。卷积神经网络CNN已经成功应用于许多领域,并且已经在地震成像领域进行了多次尝试。但是地球物理专家手动注释的高成本以及稀缺的公开标记数据集阻碍了现有基于CNN的方法的性能。在这项工作中,我们提出了一种半监督方法,用于地震图像中盐体的划分描绘,利用未标记的数据进行多轮自我训练。为了减少自我训练期间的误差放大,我们提出了一种使用CNN集合的方案。我们证明我们的方法在TGS Salt Identification Challenge数据集上优于现有技术水平,并且在3234种竞争方法中排名第一。 |
| Multimodal Style Transfer via Graph Cuts Authors Yulun Zhang, Chen Fang, Yilin Wang, Zhaowen Wang, Zhe Lin, Yun Fu, Jimei Yang 在最近的神经风格转移方法中广泛使用的假设是图像样式可以通过诸如Gram或协方差矩阵的深度特征的全局静态来描述。替代方法通过将样式分解为局部像素或神经片来表示样式。尽管最近取得了进展,但大多数现有方法均匀地处理样式图像的语义模式,从而在复杂样式上产生令人不愉快的结果。在本文中,我们介绍了一种更灵活和通用的通用风格转移技术多模式转移MST。 MST明确考虑了内容和样式图像中语义模式的匹配。具体而言,样式图像特征被聚类成子样式组件,其在图形切割公式下与本地内容特征匹配。训练重建网络以传输每个子样式并呈现最终的程式化结果。大量实验证明了MST的卓越效果,稳健性和灵活性。 |
| Reliable and Efficient Image Cropping: A Grid Anchor based Approach Authors Hui Zeng, Lida Li, Zisheng Cao, Lei Zhang 图像裁剪旨在通过从图像中去除无关内容来改善图像的构图和美学质量。现有的图像裁剪数据库仅提供一个或几个人注释边界框作为地面实体,这不能反映实际中图像裁剪的非唯一性和灵活性。所采用的评估指标(例如交叉联合)也不能可靠地反映裁剪模型的实际性能。该工作重新审视了图像裁剪的问题,并且通过考虑特殊属性和要求(例如,局部冗余,内容保存,图像裁剪的纵横比)来呈现基于网格锚的公式。我们的配方将候选作物的搜寻空间从数百万减少到不到100。因此,构建基于网格锚点的裁剪基准,其中每个图像的所有裁剪都被注释并且定义了更可靠的评估度量。我们还设计了一个有效且轻量级的网络模块,它同时考虑了感兴趣的区域和丢弃区域,以便更准确地进行图像裁剪。我们的模型可以稳定地输出视觉上令人愉悦的作物,用于不同场景的图像,并以125 FPS的速度运行。代码和数据集可在以下位置获得 |
| Efficient Decision-based Black-box Adversarial Attacks on Face Recognition Authors Yinpeng Dong, Hang Su, Baoyuan Wu, Zhifeng Li, Wei Liu, Tong Zhang, Jun Zhu 近年来,由于深度卷积神经网络CNN的巨大改进,人脸识别取得了显着的进步。然而,深度CNN易受对抗性示例的攻击,这可能会在具有安全敏感性目的的真实世界人脸识别应用中造成致命后果。对抗性攻击被广泛研究,因为它们可以在部署之前识别模型的脆弱性。在本文中,我们评估了基于决策的黑盒攻击设置中最先进的人脸识别模型的稳健性,其中攻击者无法访问模型参数和梯度,但只能通过向查询发送查询来获取硬标签预测。目标模型。这种攻击设置在现实世界的人脸识别系统中更实用。为了提高先前方法的效率,我们提出了一种进化攻击算法,该算法可以对搜索方向的局部几何进行建模并减小搜索空间的维数。大量实验证明了所提出方法的有效性,该方法以较少的查询引起对输入面部图像的最小扰动。我们还应用所提出的方法成功地攻击真实世界的人脸识别系统。 |
| Label Super Resolution with Inter-Instance Loss Authors Maozheng Zhao, Le Hou, Han Le, Dimitris Samaras, Nebojsa Jojic, Danielle Fassler, Tahsin Kurc, Rajarsi Gupta, Kolya Malkin, Shahira Abousamra, Shroyer Kenneth, Joel Saltz 对于语义分割的任务,高分辨率像素级地面实况的收集非常昂贵,尤其是对于诸如千兆像素病理图像的高分辨率图像。另一方面,为这些高分辨率图像收集像素块的低分辨率标签标签更具成本效益。在这些低分辨率标签上训练的常规方法仅能够给出低分辨率预测。鉴于低分辨率和高分辨率标签之间的联合分布,现有技术标签超分辨率LSR方法能够仅使用低分辨率监视来预测高分辨率标签。但是,它没有考虑在理想数学公式中至关重要的实例间方差。在这项工作中,我们提出了一种新的损失函数来模拟实例间方差。我们在多重免疫组织化学IHC图像中的两个实际应用细胞检测中测试我们的方法,并在组织病理学载玻片中渗透乳腺癌区域分割。实验结果表明了该方法的有效性。 |
| 3D Point Cloud Denoising via Deep Neural Network based Local Surface Estimation Authors Chaojing Duan, Siheng Chen, Jelena Kovacevic 我们提出了一种基于神经网络的三维点云去噪架构,称为神经投影去噪NPD。在我们之前的工作中,我们提出了一种两阶段去噪算法,它首先估计参考平面,然后通过将噪声点投影到估计的参考平面来实现。由于估计的参考平面不可避免地有噪声,因此应用多投影来稳定去噪性能。 NPD算法使用神经网络来估计噪声点云中的点的参考平面。通过更精确的参考平面估计,我们只需一次投影即可实现更好的去噪性能。据我们所知,NPD是第一个使用深度学习技术去噪3D点云的工作。为了进行实验,我们从ShapeNet中的3D数据中采集40000点云来训练网络,并从ModelNet10中的3D数据中采样350点云进行测试。实验结果表明,我们的算法可以估计噪声点云中点的法向量。与五种竞争方法相比,所提出的算法实现了更好的去噪性能并且产生了更小的方差。 |
| FPGA/DNN Co-Design: An Efficient Design Methodology for IoT Intelligence on the Edge Authors Cong Hao, Xiaofan Zhang, Yuhong Li, Sitao Huang, Jinjun Xiong, Kyle Rupnow, Wen mei Hwu, Deming Chen 虽然嵌入式FPGA因其低延迟和高能效而成为边缘设备上DNN加速的有吸引力的平台,但边缘规模FPGA器件的资源稀缺也使得它对DNN部署具有挑战性。在本文中,我们提出了一种同时FPGA DNN协同设计方法,包括自下而上和自顶向下方法,自下而上的面向硬件的DNN模型搜索,以实现高精度,以及自上而下的FPGA加速器设计,考虑DNN特定的特性。我们还构建了一个自动协同设计流程,包括一个Auto DNN引擎,用于执行面向硬件的DNN模型搜索,以及一个Auto HLS引擎,用于生成探测DNN的FPGA加速器的可合成C代码。我们使用PYNQ Z1 FPGA演示了对象检测任务的协同设计方法。结果表明,我们提出的DNN模型和加速器在各个方面均优于最先进的FPGA设计,包括Intersoction over Union IoU 6.2更高,每秒帧数FPS高2.48倍,功耗低40,能效高2.5倍。与基于GPU的解决方案相比,我们的设计提供了类似的精度,但消耗的能 |
| Embryo staging with weakly-supervised region selection and dynamically-decoded predictions Authors Tingfung Lau, Nathan Ng, Julian Gingold, Nina Desai, Julian McAuley, Zachary C. Lipton 为了优化临床结果,生育诊所必须战略性地选择转移哪些胚胎。共同选择启发式是根据达到各种发育里程碑所需的持续时间表示的公式,历史上由经验丰富的胚胎学家根据时间流逝的EmbryoScope视频手动注释的数量。我们提出了一种自动胚胎分期的新方法,该方法利用了这个时间推移数据中的几种结构来源。首先,注意到在每个图像中胚胎占据一个小的子区域,我们联合训练区域建议网络与下游分类器以隔离胚胎。值得注意的是,由于我们缺乏地面真实边界框,我们通过强化学习来弱化监督区域建议网络优化其参数,以改善下游分类器的损失。此外,注意到胚胎到达胚泡阶段通过早期阶段单调进展,我们开发了一个基于动态编程的解码器,后处理我们的预测,以选择最可能的单调发育阶段序列。我们的方法优于香草残差网络,并且与现代论文中的最佳数字相媲美,这可以通过每帧精度和转换预测误差来衡量,尽管操作的数据比许多数据要小。 |
| 3D Quantum Cuts for Automatic Segmentation of Porous Media in Tomography Images Authors Junaid Malik, Serkan Kiranyaz, Riyadh Al Raoush, Olivier Monga, Patricia Garnier, Sebti Foufou, Abdelaziz Bouras, Alexandros Iosifidis, Moncef Gabbouj, Philippe C. Baveye 多孔介质体积图像的二元分割是获得对微小尺度生物地球化学过程控制因素的深入理解的关键步骤。当代工作主要围绕基于全局或局部自适应阈值处理的原始技术,这些技术已经在图像分割中具有已知的共同缺点。此外,缺乏统一的基准会禁止定量评估,这进一步影响了现有方法的影响。在这项研究中,我们在两个方面解决了这个问题。首先,通过与自然图像分割的平行,我们提出了一种新颖的自动分割技术,3D Quantum Cuts QCuts 3D基于最先进的光谱聚类技术。其次,我们策划并提供一个公开可用的68个多相体积图像的数据集,其中多孔介质具有不同的固体几何形状,以及每个构成阶段的体素明智的地面实况注释。我们通过各种评估指标提供QCuts 3D与该数据集的当前最新技术水平之间的比较评估。所提出的系统方法实现了AUROC的26增加,同时实现了现有技术竞争者的计算复杂性的显着降低。此外,统计分析表明,所提出的方法对多孔介质的组成变化具有显着的稳健性。 |
| Context-Aware Query Selection for Active Learning in Event Recognition Authors Mahmudul Hasan, Sujoy Paul, Anastasios I. Mourikis, Amit K. Roy Chowdhury 活动识别是许多实际应用中的挑战性问题。除了视觉特征之外,最近的方法已经受益于上下文的使用,例如活动和对象之间的相互关系。然而,这些方法需要标记数据,事先完全可用,并且不能设计为连续更新,这使得它们不适合于监视应用。相比之下,我们提出了一个连续学习框架,用于从未标记的视频中识别上下文感知活动,与现有方法相比,它具有两个明显的优势。首先,它采用了一种新颖的主动学习技术,该技术不仅利用了个人活动的信息性,而且在查询选择期间利用其上下文信息,这导致昂贵的手动注释工作的显着减少。其次,随着更多数据的可用,可以在线调整学习模型。我们制定了一个条件随机场模型,该模型对上下文进行编码,并设计了一种信息理论方法,该方法利用节点的熵和互信息来计算由人类标记的最具信息性的查询集。这些标签与图形推理技术相结合,用于增量更新。我们通过分析解决方案提供主动学习框架的理论表述。对六个具有挑战性的数据集的实验表明,我们的框架实现了卓越的性能,并且手动标记显着减少 |
| Embodied Visual Recognition Authors Jianwei Yang, Zhile Ren, Mingze Xu, Xinlei Chen, David Crandall, Devi Parikh, Dhruv Batra 被动视觉系统通常无法识别amodal设置中被严重遮挡的物体。相反,人类和其他具体代理具有在环境中移动的能力,并且主动控制视角以更好地理解对象形状和语义。在这项工作中,我们介绍了体验视觉识别EVR的任务代理在靠近被遮挡的目标对象的3D环境中实例化,并且可以在环境中自由移动以执行对象分类,amodal对象定位和amodal对象分割。为了解决这个问题,我们开发了一个名为Embodied Mask R CNN的新模型,让代理商学习如何战略性地提升他们的视觉识别能力。我们使用House3D环境进行实验。实验结果表明,1个具有实施例移动的代理实现了比被动2更好的视觉识别性能,以提高视觉识别能力,代理可以学习不同于最短路径的战略移动路径。 |
| Towards Universal Object Detection by Domain Attention Authors Xudong Wang, Zhaowei Cai, Dashan Gao, Nuno Vasconcelos 尽管对视觉识别的通用表示的努力越来越多,但很少有人解决了对象检测问题在本文中,我们开发了一个有效和高效的通用物体检测系统,能够处理各种图像域,从人脸和交通标志到医学CT图像。与多域模型不同,该通用模型不需要对感兴趣的域的先验知识。这是通过引入基于挤压和激发原理的新的适应层族和新的域注意机制来实现的。在所提出的通用检测器中,所有参数和计算在域之间共享,并且单个网络始终处理所有域。在一个新建立的11个不同数据集的通用目标检测基准上的实验表明,所提出的检测器优于单个检测器组,多域检测器和基线通用检测器,在单个域基线检测器上增加了1.3倍的参数。代码和基准可在以下位置获得 |
| Controlling Steering Angle for Cooperative Self-driving Vehicles utilizing CNN and LSTM-based Deep Networks Authors Rodolfo Valiente, Mahdi Zaman, Sedat Ozer, Yaser P. Fallah 自动驾驶车辆的一个基本挑战是在不同的道路条件下调整转向角。解决该挑战的最新技术解决方案包括深度学习技术,因为它们提供端到端解决方案以更高精度直接从原始输入图像预测转向角。大多数这些工作忽略了图像帧之间的时间依赖性。在本文中,我们通过考虑图像帧之间的时间依赖性来解决利用两个自动驾驶车辆之间共享的多组图像来提高控制转向角度的准确性的问题。该问题尚未在文献中广泛研究。我们提出并研究了一种新的深度架构,通过在我们的深层架构中使用长短期记忆LSTM来自动预测转向角。我们的深层架构是利用CNN,LSTM和完全连接的FC层的端到端网络,它使用前方车辆共享的当前和未来图像,通过车辆到车辆V2V通信作为输入来控制转向角。与文献中的其他现有方法相比,我们的模型显示出最低的误差。 |
| Improved Embeddings with Easy Positive Triplet Mining Authors Hong Xuan, Abby Stylianou, Robert Pless 深度量度学习试图定义嵌入,其中语义相似的图像被嵌入到附近的位置,并且语义上不相似的图像被嵌入到远处的位置。大量的工作集中在损失函数和学习这些嵌入的策略,方法是尽可能将来自同一类的图像尽可能地紧密地推在一起。在本文中,我们提出了一种替代的松散嵌入策略,该策略要求嵌入功能仅将每个训练图像映射到同一类中最相似的示例,我们称之为Easy Positive挖掘。我们提供了一系列实验和可视化,突出显示这种Easy Positive挖掘可以使嵌入更灵活,更好地概括为新的看不见的数据。这种简单的挖掘策略产生的回忆性能超过了现有技术方法,包括那些具有复杂损失函数和集合方法的图像检索数据集,包括CUB,Stanford Online Products,In Shop Clothes和Hotels 50K。 |
| A Robust Visual System for Small Target Motion Detection Against Cluttered Moving Backgrounds Authors Hongxin Wang, Jigen Peng, Xuqiang Zheng, Shigang Yue 针对杂乱的移动背景监控小物体是未来机器人视觉系统的巨大挑战。作为灵感的来源,昆虫非常适合寻找配偶和追踪猎物,它们在视野中总是显得微小的斑点。最近发现的昆虫对小目标运动的精确敏感性来自一类称为小目标运动探测器STMD的特定神经元。尽管已经提出了一些基于STMD的模型,但是这些现有模型仅使用运动信息进行小目标检测,并且不能将小目标与小目标区分开,例如称为伪特征的背景特征。针对这一问题,本文提出了一种新的小目标运动检测视觉系统模型STMD,它由四个子系统组成,包括小波,运动路径,对比路径和蘑菇体。与现有的基于STMD的模型相比,附加的对比度路径从亮度信号中提取方向对比度以消除误报背景运动。通过运动路径的方向对比度和提取的运动信息被集成在蘑菇体中以用于小目标辨别。大量实验表明,与现有的基于STMD的假特征模型相比,所提出的视觉系统模型得到了显着和持续的改进。 |
| Heterogeneous Memory Enhanced Multimodal Attention Model for Video Question Answering Authors Chenyou Fan, Xiaofan Zhang, Shu Zhang, Wensheng Wang, Chi Zhang, Heng Huang 在本文中,我们提出了一个新颖的端到端可训练视频问题解答VideoQA框架,其中包含三个主要组件1,一个新的异构存储器,可以从外观和运动特征中有效地学习全局上下文信息2重新设计的问题存储器,有助于理解复杂的语义。问题和重点查询主题和3一个新的多模式融合层,通过参与相关的视觉和文本提示与自我更新的注意执行多步骤推理。我们的VideoQA模型首先通过将当前输入与内存内容进行交互来分别生成全局上下文感知视觉和文本功能。在此之后,它使多模式视觉和文本表示的注意融合推断出正确的答案。可以进行多个推理循环以迭代地改进多模态数据的注意权重并改善QA对的最终表示。实验结果表明,我们的方法在四个VideoQA基准数据集上实现了最先进的性能。 |
| What and How Well You Performed? A Multitask Learning Approach to Action Quality Assessment Authors Paritosh Parmar, Brendan Tran Morris 通过利用对行动及其质量的描述,可以改善行动质量评估AQA任务的绩效当前AQA和技能评估方法建议学习仅用于评估最终得分的一项任务的特征。在本文中,我们建议学习时空特征,解释三个相关任务细粒度动作识别,评论生成和估计AQA分数。一个新的多任务AQA数据集,迄今为止最大,包括1412个潜水样本,用于评估我们的方法 |
| Quantifying the presence of graffiti in urban environments Authors Eric K. Tokuda, Claudio T. Silva, Roberto M. Cesar Jr 涂鸦是城市场景中的常见现象。与城市艺术不同,涂鸦标签是一种故意破坏行为,许多地方政府正在努力打击它。一个地区的涂鸦地图可能是一个非常有用的资源,因为它可能允许人们在高水平涂鸦的地方打击破坏行为,并清理饱和地区以阻止未来的行为。目前没有获得区域的涂鸦地图的自动方式,并且它是通过警察的手动检查或通过民众参与获得的。从这个意义上讲,我们描述了一项正在进行的工作,我们提出了一种获取邻域涂鸦地图的自动方法。它包括系统地收集街景图像,然后在收集的数据集中识别涂鸦标签,最后,计算该位置的拟议涂鸦水平。我们通过评估巴西圣保罗涂鸦浓度高的城市涂鸦的地理分布来验证所提出的方法。 |
| End-to-end Projector Photometric Compensation Authors Bingyao Huang, Haibin Ling 投影仪光度补偿旨在修改投影仪输入图像,使其可以补偿投影表面外观的干扰。在本文中,我们首次将补偿问题表述为端到端学习问题,并提出了一个名为CompenNet的卷积神经网络,以隐含地学习复杂的补偿函数。 CompenNet由一个类似骨干网的UNet和一个自动编码器子网组成。这种架构鼓励相机捕获的投影表面图像和输入图像之间的丰富的多级交互,因此捕获投影表面的光度和环境信息。此外,视觉细节和交互信息沿着多级跳过卷积层被传送到更深层。该架构对于投影仪补偿任务特别重要,在实践中仅允许小的训练数据集。我们做出的另一项贡献是一种新颖的评估基准,它独立于系统设置,因此可以进行定量验证。据我们所知,由于传统评估要求硬件系统实际投影最终结果,因此以前无法获得此类基准。从我们的端到端问题公式出发,我们的主要思想是使用合理的代理来避免这样的投影过程,以便设置独立。我们的方法在基准测试中得到了仔细评估,结果表明我们的端到端学习解决方案在质量和数量上均大大超过了现有技术水平。 |
| Automated Monitoring Cropland Using Remote Sensing Data: Challenges and Opportunities for Machine Learning Authors Xiaowei Jia, Ankush Khandelwal, Vipin Kumar 本文概述了机器学习的最新进展和地球观测卫星数据的可用性如何能够显着提高我们在长期和大区域自动绘制农田的能力。它讨论了作物监测领域的三个应用,其中ML方法开始显示出巨大的希望。对于每个应用程序,它都突出了机器学习挑战,建议的方法和最近的结果。本文最后讨论了在ML方法充分发挥这一具有重大社会意义的问题之前需要解决的主要挑战。 |
| $\mathcal{G}$-softmax: Improving Intra-class Compactness and Inter-class Separability of Features Authors Yan Luo, Yongkang Wong, Mohan Kankanhalli, Qi Zhao 类内紧致性和类间可分性是衡量模型产生判别特征的有效性的关键指标,其中类内紧凑性表示具有相同标签的特征彼此之间的接近程度,并且类间可分性表示特征与特征的距离有多远不同的标签是。在这项工作中,我们研究了卷积网络学习的特征的类内紧致性和类间可分性,并提出了一种基于高斯的softmax mathcal G softmax函数,它可以有效地提高类内紧致性和类间可分性。所提出的功能易于实现并且可以容易地替换softmax功能。我们评估在分类数据集上提出的mathcal G softmax函数,即CIFAR 10,CIFAR 100和Tiny ImageNet以及多标签分类数据集,即MS COCO和NUS WIDE。实验结果表明,所提出的mathcal G softmax函数改进了所有评估数据集的现有模型状态。此外,对类内紧凑性和类间可分性的分析证明了所提出的函数优于softmax函数的优点,这与性能改进一致。更重要的是,我们观察到高内类紧致性和类间可分性与MS COCO和NUS WIDE的平均精度线性相关。这意味着类内紧凑性和类间可分性的改善将导致平均精度的提高。 |
| Learned 3D Shape Representations Using Fused Geometrically Augmented Images: Application to Facial Expression and Action Unit Detection Authors Bilal Taha, Munawar Hayat, Stefano Berretti, Naoufel Werghi 本文提出了一种使用融合纹理和几何数据的新方案来学习通用多模态网格表面表示的方法。我们的方法定义了在网格表面或其下采样版本上计算的不同几何描述符与网格的相应2D纹理图像之间的逆映射,允许构建融合的几何增强图像FGAI。这种新的融合模式使我们能够通过在转移学习模式中简单地采用标准卷积神经网络,以高效的方式从3D数据中学习特征表示。与现有方法相比,所提出的方法在计算和存储器方面都是有效的,通过在数据级别有效地融合形状和纹理信息来保留内在几何信息并学习高度辨别特征表示。我们的方法的功效证明了面部动作单元检测和表达分类的任务。在Bosphorus和BU 4DFE数据集上进行的大量实验表明,与现有技术解决方案相比,我们的方法可以显着提高性能 |
| Neural Rerendering in the Wild Authors Moustafa Meshry, Dan B Goldman, Sameh Khamis, Hugues Hoppe, Rohit Pandey, Noah Snavely, Ricardo Martin Brualla 我们探索全景捕捉录制,建模和重新渲染场景,如季节和时间等不同的外观。从旅游地标的互联网照片开始,我们应用传统的3D重建来注册照片并将场景近似为点云。对于每张照片,我们将场景点渲染为深度帧缓冲,并训练神经网络以学习这些初始渲染到实际照片的映射。该重新渲染网络还将潜在外观向量和语义掩码作为输入,该语义掩码指示诸如行人的瞬态对象的位置。该模型在跨越广泛照明条件的公共可用图像的若干数据集上进行评估。我们创建短视频,展示对图像视点,外观和语义标签的逼真操作。我们还将结果与以前互联网照片的场景重建工作进行了比较。 |
| SCSampler: Sampling Salient Clips from Video for Efficient Action Recognition Authors Bruno Korbar, Du Tran, Lorenzo Torresani 虽然许多动作识别数据集由简短的,修剪过的视频集合组成,每个视频都包含相关动作,但是现实世界中的视频(例如,在YouTube上)显示出非常不同的属性,它们通常是几分钟长,其中简短的相关剪辑通常与扩展的片段交错。持续时间很少变化。密集地将动作识别系统应用于这些视频内的每个时间片段是非常昂贵的。此外,正如我们在实验中所示,这导致了次优的识别准确性,因为来自相关剪辑的信息预测在视频的长信息部分上被无意义的分类输出超过了数量。在本文中,我们介绍了一种轻量级的剪辑采样模型,可以有效地识别长视频中最显着的时间片段。我们证明,通过仅在这些最显着的剪辑上调用识别,可以显着降低未修剪视频上动作识别的计算成本。此外,我们表明,与分析所有剪辑或随机统一选择的剪辑相比,这可以显着提高识别准确度。在Sports1M上,我们的剪辑采样方案将已经最先进的动作分类器的准确度提高了7,并且降低了其计算成本的15倍以上。 |
| 3D Local Features for Direct Pairwise Registration Authors Haowen Deng, Tolga Birdal, Slobodan Ilic 我们提出了一种新颖的数据驱动方法,用于解决两点云扫描的注册问题。我们的方法是直接的,即一对相应的本地补丁已经为全局注册提供了必要的转换提示。为了实现这一目标,我们首先赋予最先进的PPF FoldNet自动编码器AE以及姿势变体兄弟,其中两者之间的差异导致姿势特定描述符。基于此,我们引入了相对姿态估计网络RelativeNet,以便为关键点分配对应的特定方向,从而消除任何局部参考帧计算。最后,我们设计了一个简单而有效的假设和验证算法,以快速使用预测并对齐两个点集。我们广泛的定量和定性实验表明,我们的方法在挑战成对配准的真实数据集方面优于现有技术,并且利用局部姿势信息增加关键点可以实现更好的泛化和显着的加速。 |
| Identity-preserving Face Recovery from Stylized Portraits Authors Fatemeh Shiri, Xin Yu, Fatih Porikli, Richard Hartley, Piotr Koniusz 鉴于艺术肖像,恢复保留主体身份的潜在逼真的面部是具有挑战性的,因为面部细节经常在艺术肖像中被扭曲或完全丢失。我们开发了一种从Portraits IFRP方法开发的身份保护面部恢复,该方法利用了样式移除网络SRN和判别网络DN。我们的SRN由具有残余块嵌入式跳过连接的自动编码器组成,旨在将风格化图像的特征映射传输到相应照片级真实面的特征映射。由于空间变换器网络STN,SRN自动补偿程式化肖像的未对准以输出对齐的逼真面部图像。为了确保身份保护,我们通过距离测量来促进恢复和地面真相面部分享类似的视觉特征,该距离测量比较从训练有素的FaceNet网络提取的恢复和地面真实面部的特征。 DN具有多个卷积和完全连接的层,其作用是强制恢复的面部与真实面部相似。因此,我们可以从未对齐的肖像中恢复高质量的照片级逼真的脸部,同时保留图像中脸部的身份。通过对大规模合成数据集和手绘草图数据集进行广泛评估,我们证明了我们的方法实现了卓越的面部恢复并获得了最先进的结果。此外,我们的方法可以从看不见的风格化肖像,艺术绘画和手绘草图中恢复逼真的面孔。 |
| Surface Defect Classification in Real-Time Using Convolutional Neural Networks Authors Selim Arikan, Kiran Varanasi, Didier Stricker 表面检测系统是计算机视觉的重要应用领域,因为它们用于制造业中的缺陷检测和分类。现有系统使用手工制作的功能,需要广泛的领域知识才能创建。尽管卷积神经网络CNN已经证明在许多大规模挑战中取得了成功,但由于实时处理速度要求和专门的窄域特定数据集(有时尺寸有限)存在两个重大挑战,工业检测系统尚未意识到它们的潜力。在本文中,我们提出了专门设计用于处理表面检测系统的容量和实时速度要求的CNN模型。为了训练和评估我们的网络模型,我们创建了一个表面图像数据集,其中包含22000多个带有多种表面材料的标记图像,并在二进制缺陷分类中实现了98.0的精度。为了解决数据集中的类不平衡问题,我们引入了神经数据增强方法,这些方法也适用于遭受同样问题的类似域。我们的研究结果表明,基于深度学习的方法可用于表面检测系统,并且在准确度和推理时间方面优于传统方法。 |
| Automated Search for Configurations of Deep Neural Network Architectures Authors Salah Ghamizi, Maxime Cordy, Mike Papadakis, Yves Le Traon 深度神经网络DNN被广泛用于解决各种复杂问题。虽然功能强大,但此类系统需要手动配置和调整。为此,我们将DNN视为可配置系统,并提出端到端框架,允许对DNN架构进行配置,评估和自动搜索。因此,我们的贡献是三倍的。首先,我们使用特征模型FM对DNN体系结构的可变性进行建模,该模型可以概括现有体系结构。 FM的每个有效配置对应于可以构建和训练的有效DNN模型。其次,我们在Tensorflow之上实施了一个自动化程序,用于部署,训练和评估已配置模型的性能。第三,我们提出了一种搜索配置的方法,并证明它可以产生良好的DNN模型。我们通过将其应用于图像分类任务MNIST,CIFAR 10来评估我们的方法,并且表明,通过有限的计算和训练,我们的方法可以高精度地识别高性能架构。我们还证明我们的表现优于ML研究人员手工制作的现有最先进的架构。我们的FM和框架已经发布并可公开发布,以支持复制和未来的研究。 |
| PUNCH: Positive UNlabelled Classification based information retrieval in Hyperspectral images Authors Anirban Santara, Jayeeta Datta, Sourav Sarkar, Ankur Garg, Kirti Padia, Pabitra Mitra 由机载或卫星安装的传感器捕获的土地覆盖的高光谱图像提供了关于给定位置中存在的材料的化学组成的丰富信息源。这使得高光谱成像成为地球科学,土地覆盖研究以及军事和战略应用的重要工具。然而,标记训练样本的稀缺性和光谱特征的空间变异性是高光谱图像分类面临的两大挑战。为了解决这些问题,我们的目标是开发一个基于正无标记PU分类的高光谱图像中材料不可知信息检索的框架。给定高光谱场景,用户标记他正在寻找的材料的一些正样本,并且我们的目标是检索场景中查询材料的所有剩余实例。此外,我们要求系统同样适用于任何场景中的任何材料,而无需用户披露查询材料的身份。框架的这种材料不可知性使其具有出色的泛化能力。我们探索了两种在该框架内解决高光谱图像分类问题的替代方法。第一种方法是针对高光谱数据的基于非负风险评估的PU学习的改编。第二种方法基于一对所有正负分类,其中使用新颖的光谱空间检索模型近似地对负分类进行采样。我们提出两个注释器模型uniform和blob,它们代表人类注释器的标记模式。我们比较了每个注释器模型的算法在三个基准高光谱图像数据集Indian Pines,Pavia University和Salinas上的性能。 |
| Regression Concept Vectors for Bidirectional Explanations in Histopathology Authors Mara Graziani, Vincent Andrearczyk, Henning M ller 根据域相关概念对深度神经网络预测的解释在医学应用中可能是有价值的,其中理由对于决策的可信度是重要的。在这项工作中,我们提出了一种方法,可以在层的激活空间中利用连续概念测量作为回归概念向量RCV。沿着RCV的决策函数的方向导数表示网络对给定概念测量值的增加值的敏感性。当应用于乳腺癌分级时,核质地作为乳腺淋巴结样品中肿瘤组织检测的相关概念出现。我们通过统计分析评估得分稳健性和一致性。 |
| Relational Reasoning Network (RRN) for Anatomical Landmarking Authors Neslisah Torosdagli, Mary McIntosh, Denise K. Liberton, Payal Verma, Murat Sincan, Wade W. Han, Janice S. Lee, Ulas Bagci 准确识别解剖标志是颅颌面CMF骨骼变形分析和手术计划的关键步骤。可用的方法需要分割感兴趣的对象以进行精确的标记。与那些不同,我们在这项研究中的目的是使用CMF骨骼的固有关系来执行解剖标记,而无需明确地对它们进行分割。我们提出了一种新的深度网络架构,称为关系推理网络RRN,以准确地了解地标的本地和全球关系。具体来说,我们有兴趣学习CMF区域下颌骨,上颌骨和鼻骨的地标。所提出的RRN以端到端的方式工作,利用基于密集块单元的地标的学习关系而不需要分段。对于给定的几个界标作为输入,所提出的系统准确且有效地将剩余的界标定位在上述骨骼上。为了全面评估RRN,我们使用了250名患者的锥形束计算机断层扫描CBCT扫描。即使在骨骼中存在严重的病变或变形时,所提出的系统也非常准确地识别界标位置。建议的RRN还揭示了地标之间的独特关系,这有助于我们推断出关于具有里程碑意义的点的信息量的几个推理。 RRN对于地标的顺序是不变的,并且它允许我们发现在感兴趣的对象下颌骨或附近的对象上颌骨和鼻腔内定位的地标的最佳配置数量和位置。据我们所知,这是第一种使用深度学习找到物体解剖关系的算法。 |
| L2AE-D: Learning to Aggregate Embeddings for Few-shot Learning with Meta-level Dropout Authors Heda Song, Mercedes Torres Torres, Ender zcan, Isaac Triguero 很少有镜头学习侧重于学习一个新的视觉概念,标签示例非常有限。解决该问题的成功方法是比较基于卷积神经网络的学习度量空间中的示例之间的相似性。然而,由于训练任务的数量有限,现有方法通常遭受元级过度拟合,并且通常不考虑同一信道内不同示例的卷积特征的重要性。为了解决这些局限性,我们做了以下两个贡献:我们提出了一种新颖的元学习方法,用于聚合有用的卷积特征,并基于渠道明智的注意机制来抑制噪声,以改进类表示。所提出的模型不需要微调,并且可以以端对端的方式进行训练。主要的新颖之处在于结合了共享权重生成模块,该模块学习为同一信道内的不同示例的特征映射分配不同的权重。 b我们还介绍了一种简单的元级别丢失技术,该技术可以减少几种镜头学习方法中的元级别过度拟合。在我们的实验中,我们发现这种简单的技术显着提高了所提出方法的性能以及各种最先进的元学习算法。将我们的方法应用于使用Omniglot和miniImageNet数据集的少量镜头图像识别,表明它能够提供最先进的分类性能。 |
| SoDeep: a Sorting Deep net to learn ranking loss surrogates Authors Martin Engilberge, Louis Chevallier, Patrick P rez, Matthieu Cord 机器学习中的几个任务使用不可微的度量来评估,例如平均精度或Spearman相关性。然而,它们的非差异性阻碍了它们在学习框架中作为目标函数使用。存在替代和放松方法,但倾向于特定于给定度量。 |
| Chinese Abs From Machine Translation |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号