
【今日CV 计算机视觉论文速览 第100期】Mon, 15 Apr 2019
今日CS.CV 计算机视觉论文速览
Mon, 15 Apr 2019
Totally 37 papers
👉上期速览 ✈更多精彩请移步主页

Interesting:
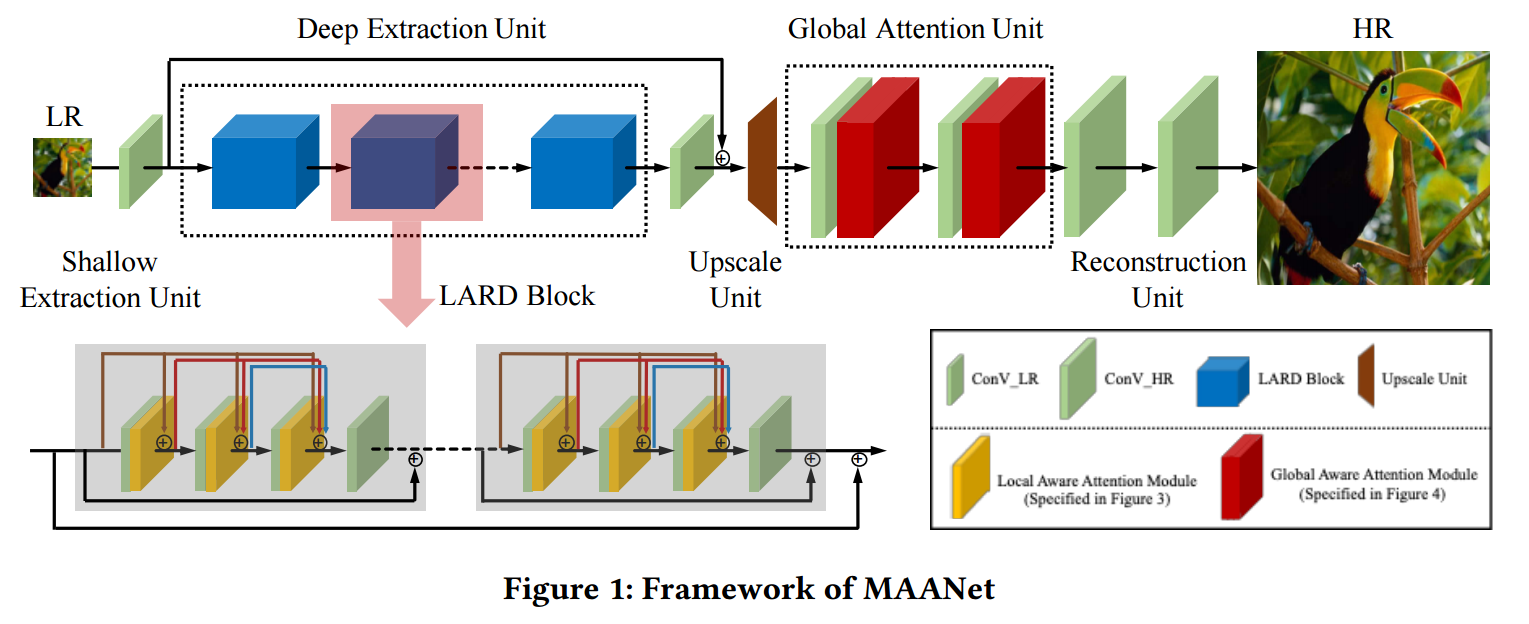
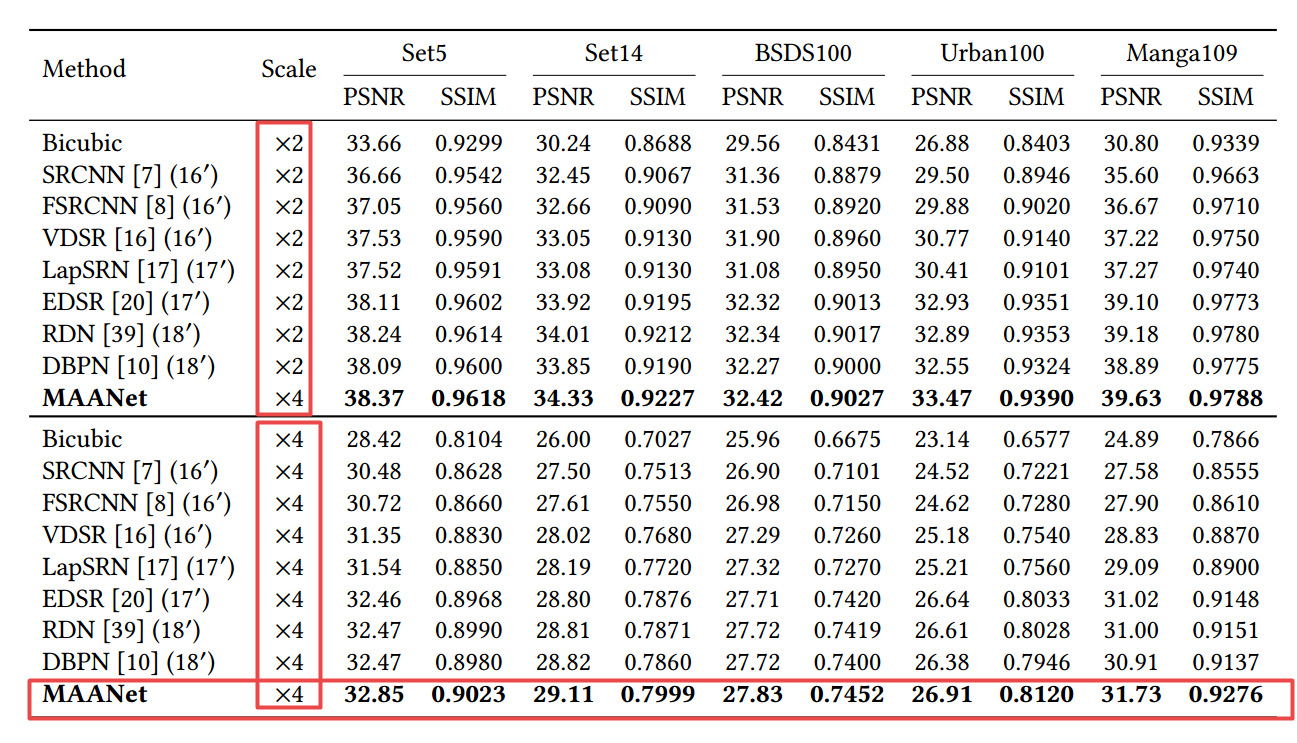
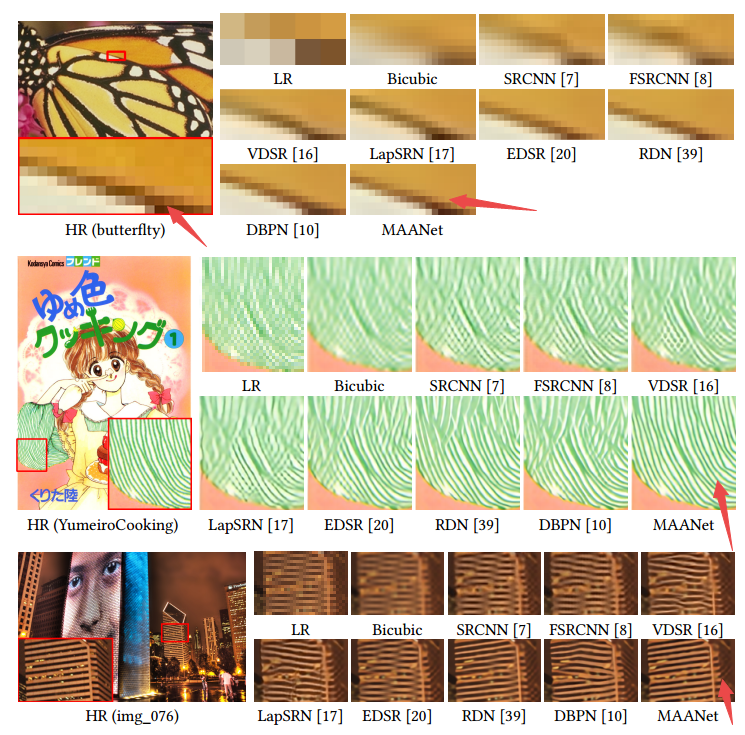
📚MAANet多视角图像超分辨,通过局域注意力和全局注意力机制解决图像超分辨中高频信息缺失的问题,从局域和全局视角来分辨特征,并提出了基于注意力残差单元来便于深度网络的训练。(from 香港理工 上海交大)
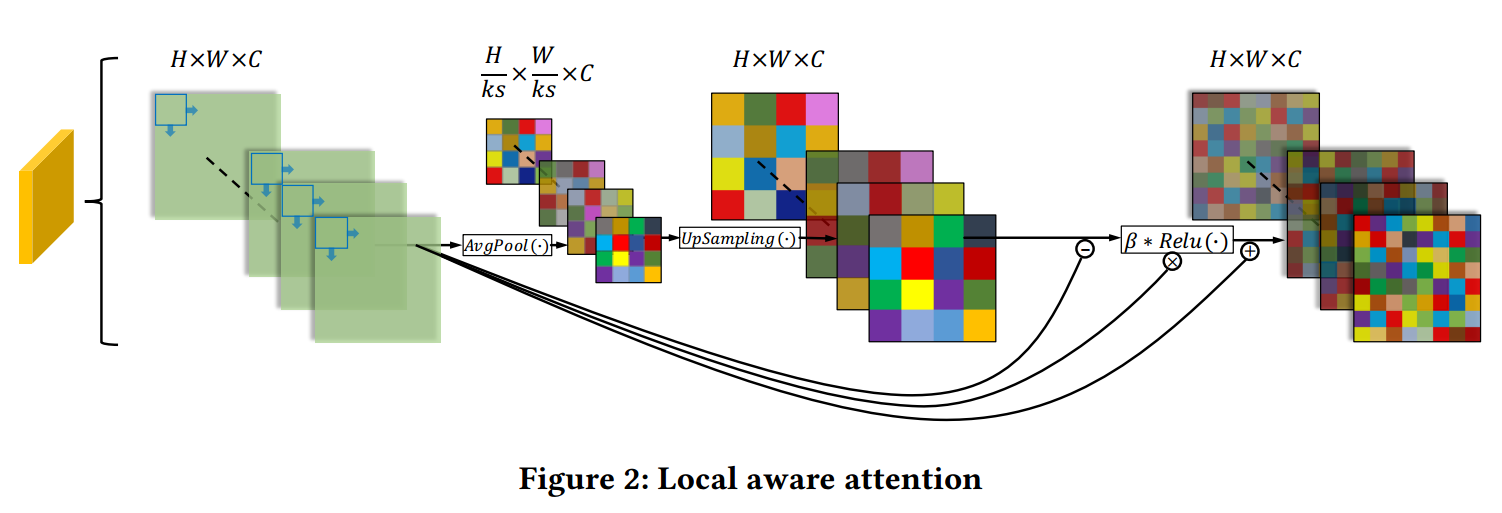
局域注意力机制:
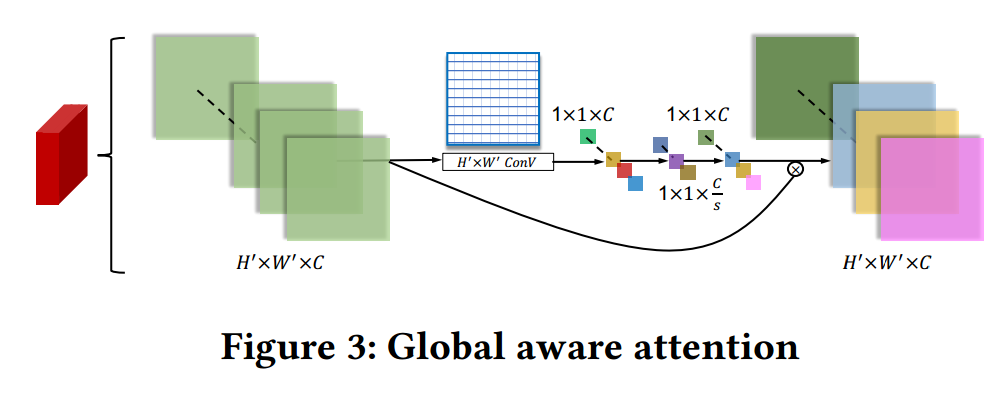
全局注意力机制:
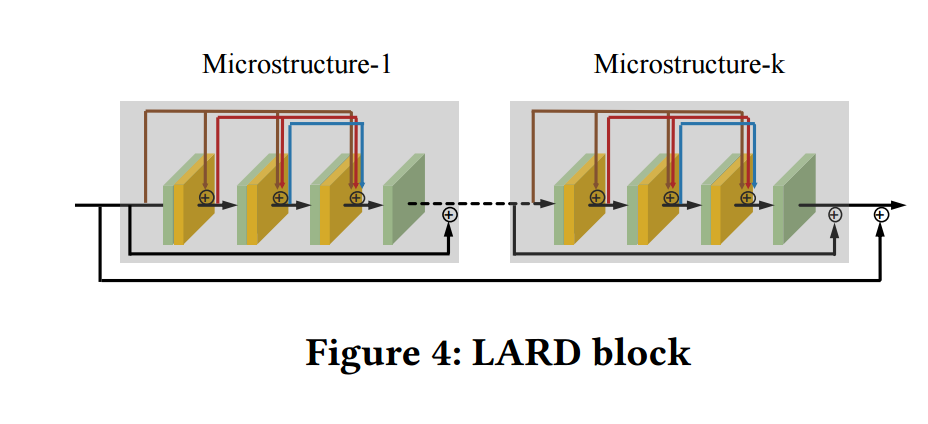
局域注意力残差块:
一些结果的恢复过程:
dataset:n DIV2K dataset [28], Set5 [5], Set14 [37], BSDS100 [1], Urban100 [14], and Manga109 [22].
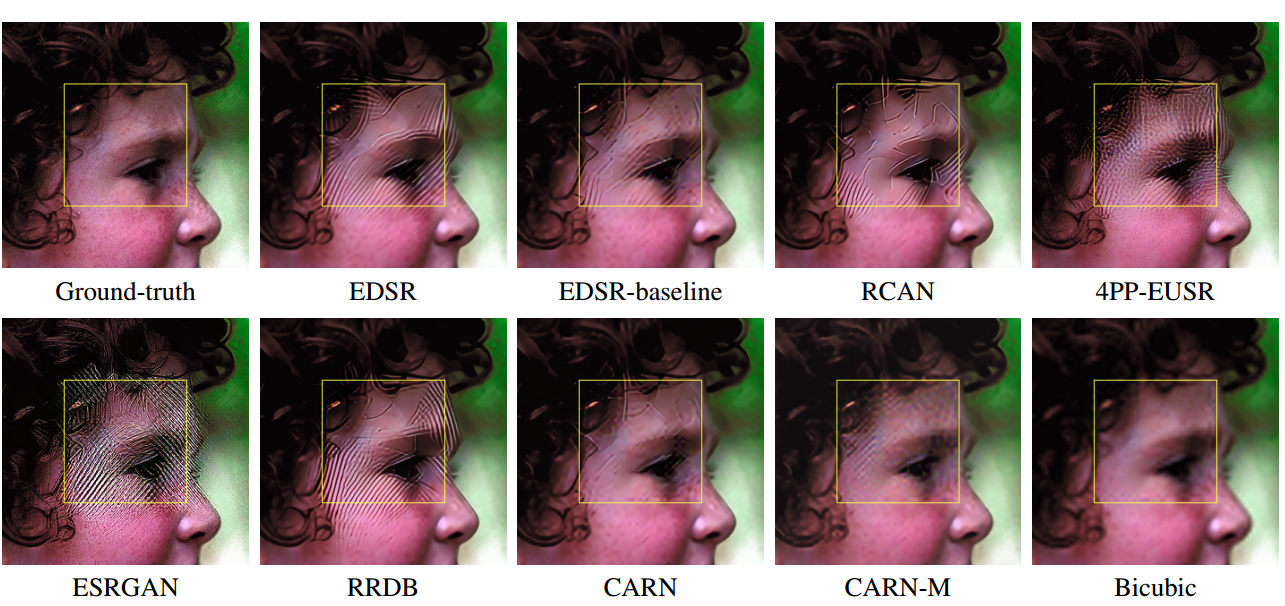
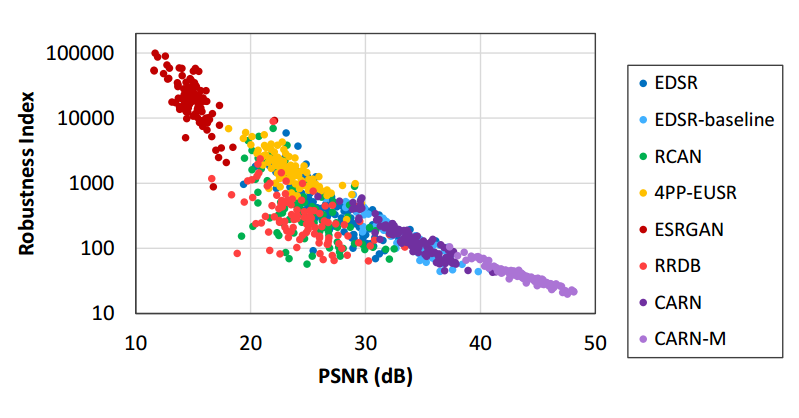
📚通过对抗样本分析并提高超分辨模型的鲁棒性, (from 延世大学 UCLA)
低分辨率图像中注入了很少的扰动,但对结果造成很大影响。基于I-FGSM [11]对抗攻击下超分辨的结果呈现出各式各样的畸变:
各种模型的鲁棒性:

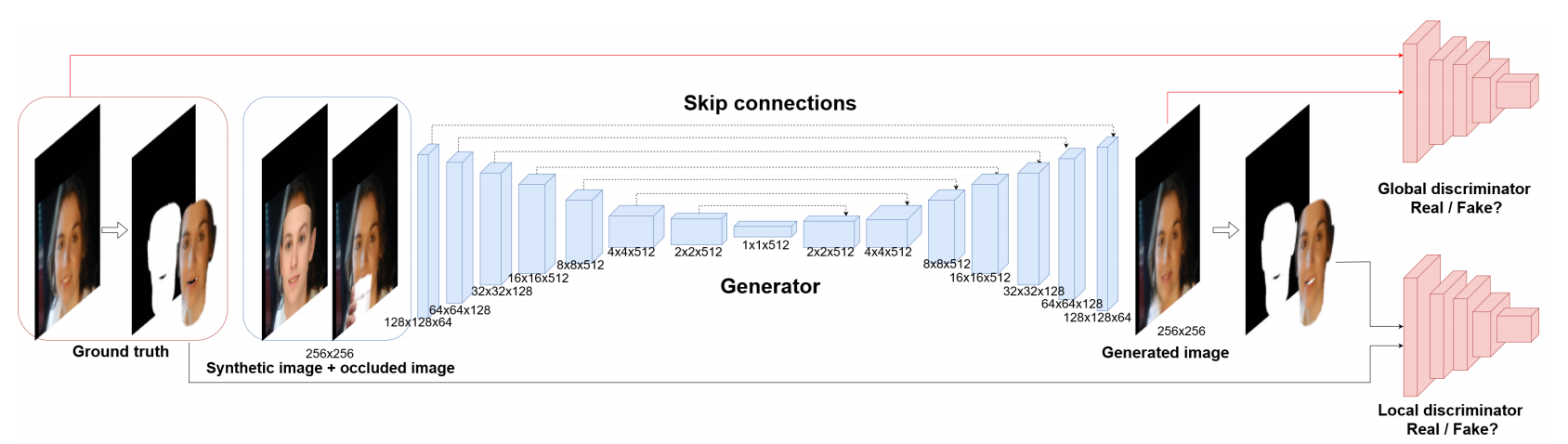
📚基于3D可变形模型和GAN的人脸去遮挡, 3DMM不仅作为几何先验,同时为局域判别器提供了人脸区域。利用全局和局域对抗网络实现了3D人脸的去遮挡,(from Inha University)
网络架构,包含了局域和全局的判别器,以及人脸部分的掩膜作为GT:
合成与真实数据结果:
dataset:300W-3D,AFLW2000-3D CelebA [16]


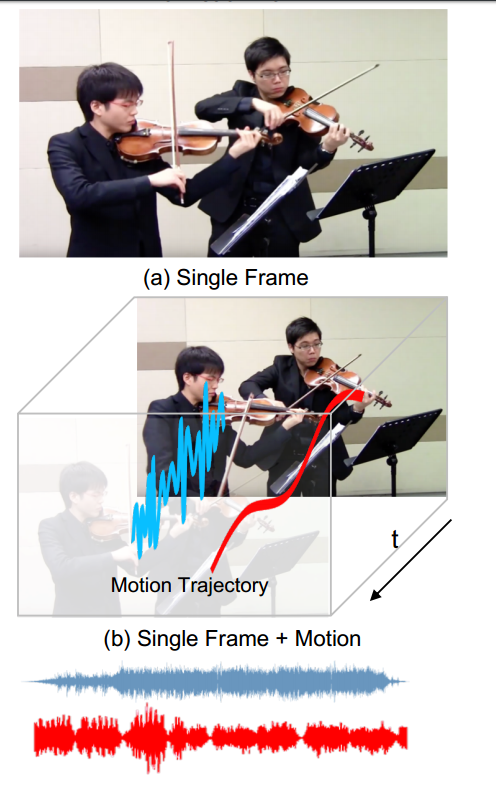
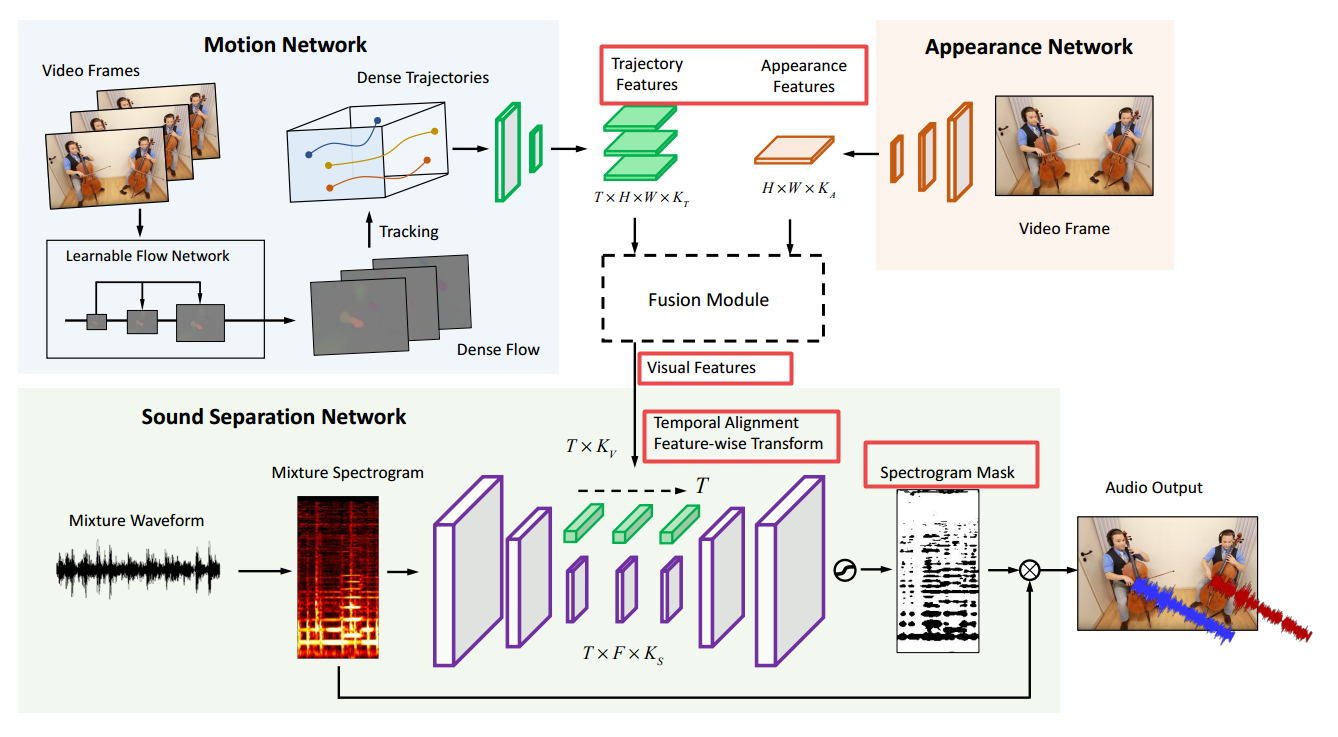
📚Deep Dense Trajectory (DDT), The Sound of Motions, 从运动中分辨出声音的音源(from MIT)
从运动中分辨出两个个演奏者的音乐
网络包含了运动轨迹特征抽取、外部特征、视觉特征融合(作为声音分离的条件)、声音分离网络等四部分构成。
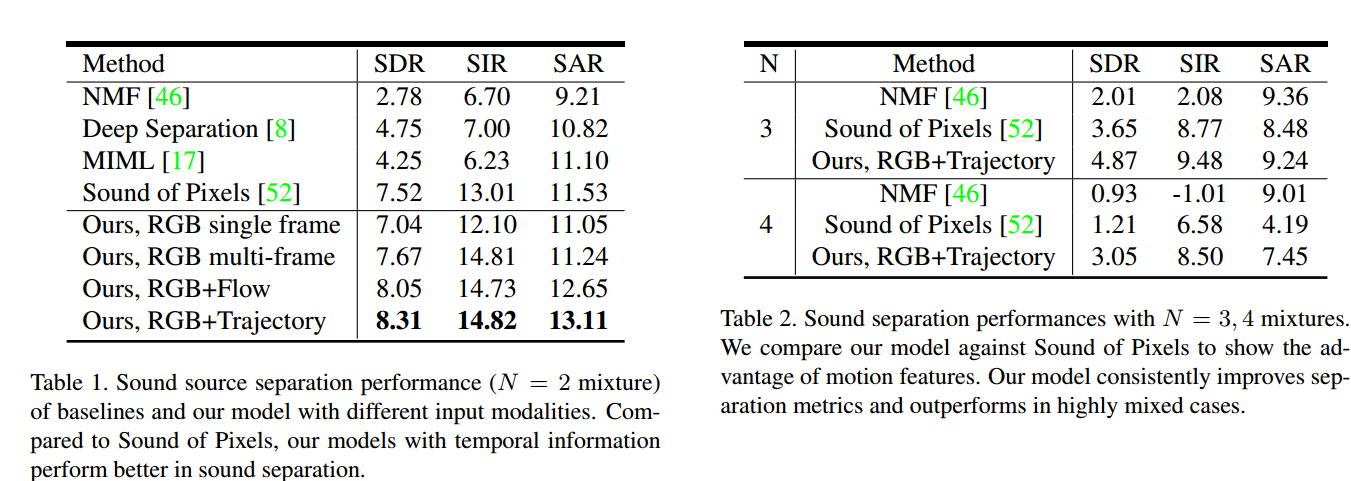
实验结果和相关方法比较:
从混合声音重分离出两个独立的声源:
数据集:MUSIC [52] and URMP [28].
video:https://www.youtube.com/watch?v=XDuKWUYfA_U

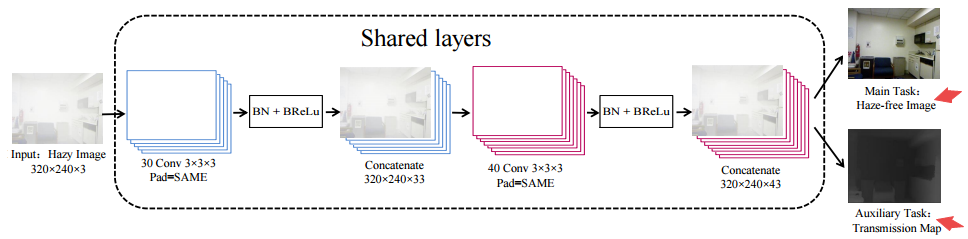
📚LDTNet图像去雾,在图像去雾的同时估计了场景的投射图 (from 哈工程)
网络架构:
效果比较:
相关指标:airlight robustness evaluation (ARE), coefficient robustness evaluation (CRE), scale robustness evaluation (SRE) and noise robustness evaluation (NRE).
相关方法:DCP [17] CAP [34] MSCNN [24] DehazeNet [23] AOD-Net [25]

📚暗光增强, (from 阿联酋人工智能感知研究院)
相关方法和数据集的比较:
dataset: See-in-the-Dark (SID)dataset [3]

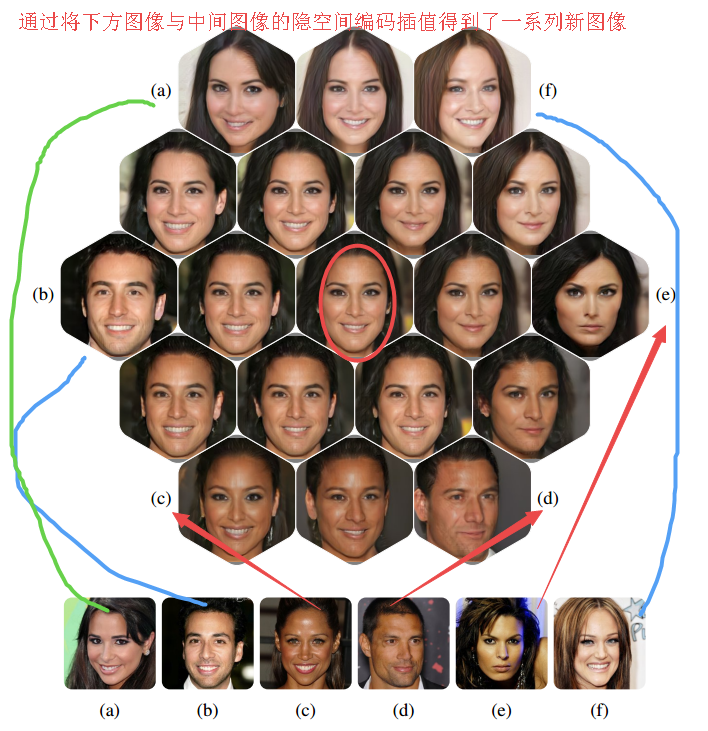
📚基于单个自编码器实现照片的编码重建,并通过隐空间编码生成新的高清图像, (from 芬兰阿尔托大学 GenMind)
一些结果:
相关方法:PIONEER networks,IntroVAE
相关数据集:CELEBA-HQ LSUN Bedrooms dataset
code:https://aaltovision.github.io/balanced-pioneer


📚基于合成数据识别珍稀物种, 通过不同位姿、光照、模型和模拟法探究了合成数据提升野外识别效果。(小样本学习)合成数据可有效降低错误率,提升精度。(from 加州理工 微软研究院)
四种合成方法与真实数据的比较:

📚iWildCam数据集, 野外自动观察相机数据集,为了实现自动标注的挑战,包含了美国西南部143个地点的292732张图像(from 加州理工)
相关数据集:Caltech Camera Traps (CCT) dataset[19]
参考文献中有一堆合成方法和动物研究。

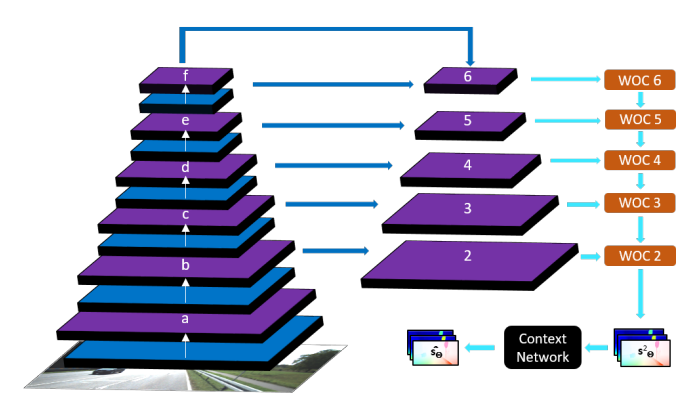
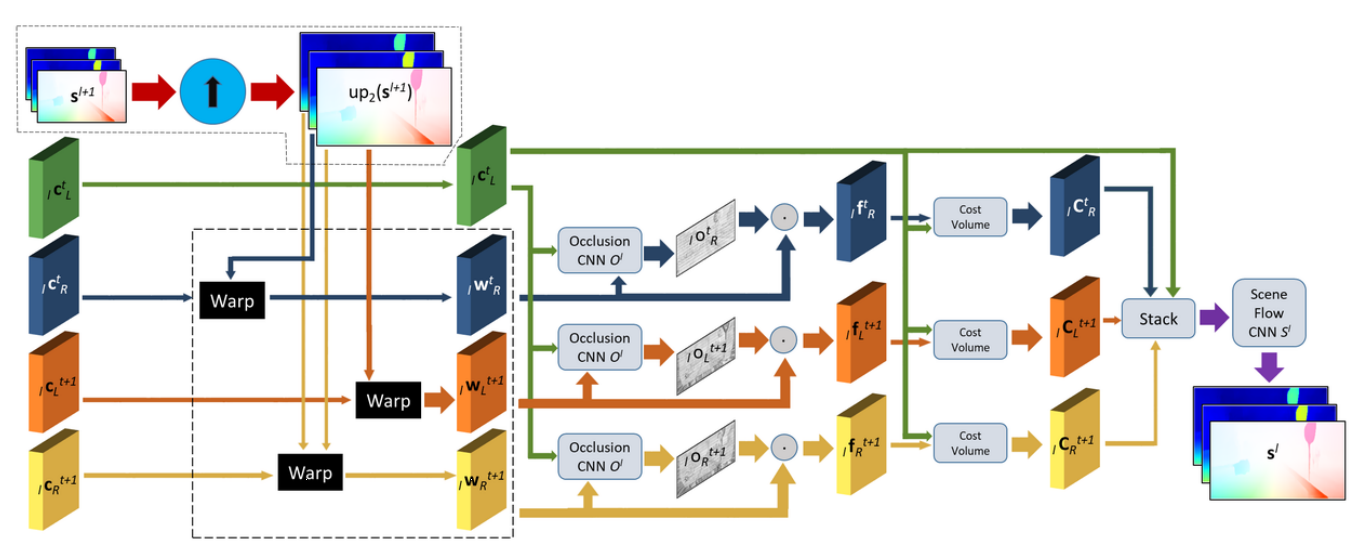
📚PWOC-3D场景流估计方法, 从立体视觉图像序列中高效的预测出场景流(光流和立体匹配)、并学会如何处理遮挡场景。(from 德国AI研究中心DFKI)
金字塔层中的结构:
最终预测结果:

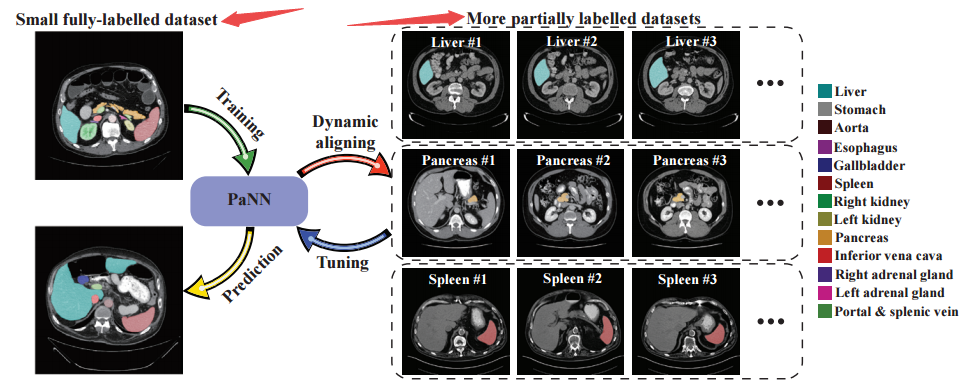
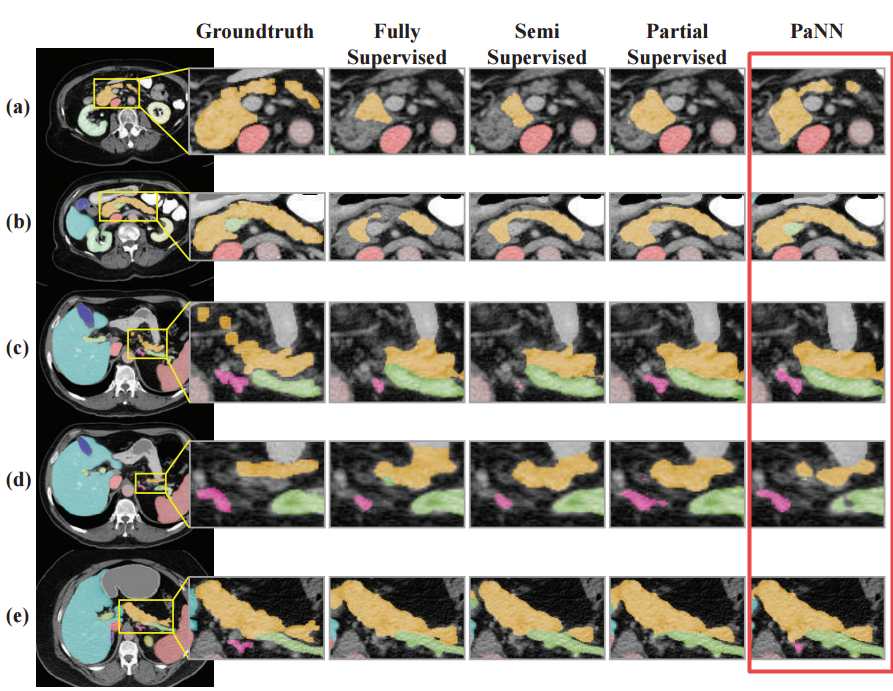
📚 Prior-aware Neural Network(PaNN)医学影像多器官分割网络, 通过器官大小的分布的先验知识,来训练网络获取领域知识,完成多器官分割。(from 约翰霍普金斯)
少部分完全分割图像和大部分部分只包含单个器官的分割图像:
得到了边缘较为清晰的分割结果:
相关数据集:
spleen segmentation dataset1 Available at http://medicaldecathlon.com
pancreas segmentation dataset2 Available at https://wiki.cancerimagingarchive.net/
display/Public/Pancreas-CT
3https://github.com/tensorflow/models/tree/
master/research/deeplab
4https://github.com/DLTK/DLTK
Daily Computer Vision Papers
| Big but Imperceptible Adversarial Perturbations via Semantic Manipulation Authors Anand Bhattad, Min Jin Chong, Kaizhao Liang, Bo Li, David A. Forsyth 机器学习,尤其是深度学习,广泛应用于计算机视觉,机器人和自然语言处理等一系列应用。然而,已经表明,机器学习模型容易受到对抗性的例子,精心设计的样本欺骗学习模型。深入研究对抗性示例可以帮助更好地了解潜在的漏洞,从而提高模型的稳健性。最近的作品引入了各种产生对抗性例子的方法。然而,所有这些都要求扰动具有小幅度的数学L p范数,使得人类难以察觉,这在实践中难以部署。在本文中,我们提出了两种新方法,tAdv和cAdv,它们利用纹理转移和着色来产生具有大数学L p范数的自然扰动。我们进行了大量实验,表明所提出的方法足以攻击ImageNet和MSCOCO数据集上的图像分类和图像字幕任务。此外,我们在各种条件下进行全面的用户研究,以表明即使扰动很大,我们生成的对抗性例子对人类也是不可察觉的。我们还评估了针对几种最先进防御的拟议攻击的可转移性和稳健性。 |
| Prior-aware Neural Network for Partially-Supervised Multi-Organ Segmentation Authors Yuyin Zhou, Zhe Li, Song Bai, Chong Wang, Xinlei Chen, Mei Han, Elliot Fishman, Alan Yuille 准确的多器官腹部CT分割对于许多临床应用是必不可少的,例如计算机辅助干预。由于数据注释需要来自经验丰富的放射科医师的大量人力,因此通常训练数据被部分标记,例如,胰腺数据集仅标记胰腺而将其余部分标记为背景。然而,这些背景标签在多器官分割中可能会产生误导,因为背景通常包含一些其他感兴趣的器官。为了解决这些部分标记的数据集中的背景模糊性,我们通过明确地将腹部器官大小的解剖学先验结合起来,提出先验感知神经网络PaNN,用领域特定知识指导训练过程。更具体地说,PaNN假设腹部的平均器官大小分布应该接近它们的经验分布,这是从完全标记的数据集获得的先前统计数据。由于我们的训练目标难以使用随机梯度下降20直接优化,我们建议以最小最大形式重新形成它并通过随机原始双梯度算法对其进行优化。 PaNN在MICCAI2015挑战Multi Atlas Labeling Beyond the Cranial Vault上实现了最先进的性能,这是一项关于腹部器官分割的竞赛。我们报告的平均骰子得分为84.97,超过现有技术的3.27。 |
| Incremental multi-domain learning with network latent tensor factorization Authors Adrian Bulat, Jean Kossaifi, Georgios Tzimiropoulos, Maja Pantic 深度学习的突出性,大量注释数据和越来越强大的硬件使得有可能在监督分类任务中达到显着的性能,在许多情况下使训练集饱和。然而,将学习的分类调整到新域仍然是一个难题,因为至少有三个原因1域和任务可能完全不同2新域上的注释数据量可能非常有限,而新域的3个完整培训由于深度网络参数的剪切数,每个新任务的模型在内存方面是禁止的。相反,新任务应该逐步学习,建立在已经学过的任务的先验知识的基础上,没有灾难性遗忘,即不损害先前任务的表现。据我们所知,本文提出了第一种多域任务学习方法,无需使用完全张量化的体系结构进行灾难性遗忘。我们的主要贡献是用于多域学习的方法,其将CNN内的相同结构化的块的组建模为高阶张量。我们证明了这种联合建模自然地利用了不同层之间的相关性,并且导致每个新任务域的表达比以前的方法更紧凑,这些方法侧重于分别调整每个层。我们将所提出的方法应用于视觉十项全能挑战赛的10个数据集,并表明我们的方法在分类准确度和迪卡侬评分方面平均提供约7.5倍的参数数量和优异的性能。特别是,我们的方法优于Visual Decathlon Challenge的所有先前工作。 |
| GeoCapsNet: Aerial to Ground view Image Geo-localization using Capsule Network Authors Bin Sun, Chen Chen, Yingying Zhu, Jianmin Jiang 交叉视图图像地理定位的任务旨在通过将查询地面视图图像与参考数据集中的GPS标记的航空卫星图像进行匹配来确定查询地面视图图像的地理位置GPS坐标。由于视点的剧烈变化,匹配交叉视图图像具有挑战性。在本文中,我们提出了基于胶囊网络的GeoCapsNet,用于地面到航空图像的地理定位。网络首先通过标准卷积层从地面视图和航空图像中提取特征,并且胶囊层进一步对特征进行编码以对空间特征层级进行建模并增强表示能力。此外,我们通过在线批量硬样本挖掘引入了一种简单有效的加权软边缘三元组损失,可以大大提高图像检索的准确性。实验结果表明,我们的GeoCapsNet明显优于两个基准数据集的最新技术方法。 |
| ACE: Adapting to Changing Environments for Semantic Segmentation Authors Zuxuan Wu, Xin Wang, Joseph E. Gonzalez, Tom Goldstein, Larry S. Davis 当深度神经网络在相同的数据分布上进行训练和测试时,它们表现出非凡的准确性。然而,当面对随时间发生的输入分布中的域移位变化时,神经分类器通常非常脆弱。我们提出了ACE,这是一种语义分段框架,可以随时动态适应不断变化的环境。通过将来自原始源域的标记训练数据的分布与移位域中的输入数据的分布对齐,ACE在其看到的环境中合成标记的训练数据。然后,使用此风格化数据更新分段模型,以使其在新环境中表现良好。为了避免忘记过去环境中的知识,我们引入了一个存储器来存储以前看到的域中的特征统计信息。这些统计数据可用于重放任何先前观察到的域中的图像,从而防止灾难性遗忘。除了使用随机梯度体面SGD的标准批量训练之外,我们还尝试了基于自适应元学习的快速自适应方法。对来自SYNTHIA的两个数据集进行了大量实验,结果证明了该方法在适应许多任务时的有效性。 |
| MAANet: Multi-view Aware Attention Networks for Image Super-Resolution Authors Jingcai Guo, Shiheng Ma, Song Guo 近年来,基于深度卷积神经网络DCNN的图像超分辨率SR在多媒体和计算机视觉社区中受到越来越多的关注,重点在于从低分辨率LR图像恢复高分辨率HR图像。然而,基于DCNN的方法的一个不可忽视的缺陷是它们中的大多数不能从具有低频信息冗余的低分辨率图像恢复包含足够高频信息的高分辨率图像。更糟糕的是,随着DCNN的深度增加,训练容易遇到梯度消失的问题,这使得训练更加困难。这些问题阻碍了DCNN在图像SR任务中的有效性。为了解决这些问题,我们提出了用于图像SR任务的多视图感知注意网络MAANet。具体而言,我们建议本地知晓的LA和全球意识的GA注意以不相等的方式处理LR特征,其可以突出高频分量并且分别在局部视图和全局视图中区分LR图像中的每个特征。此外,我们提出了局部注意力残留密集LARD模块,它将LA注意力与多个残余和密集连接相结合,以适应更深入,更易于训练的体系结构。实验结果表明,与其他最先进的方法相比,我们提出的方法可以获得显着的性能。 |
| Generative Hybrid Representations for Activity Forecasting with No-Regret Learning Authors Jiaqi Guan, Ye Yuan, Kris M. Kitani, Nicholas Rhinehart 关于未来人类行为的自动推理是辅助系统的重要实际应用的难题。部分困难源于学习系统无法表现各种行为。一些行为,例如运动,最好用连续表示来描述,而其他行为,例如拿起杯子,最好用离散表示来描述。此外,人的行为一般不固定,人们可以改变他们的习惯和惯例。这表明这些系统必须能够不断学习和适应。在这项工作中,我们开发了一种有效的深度生成模型,以共同预测一个人未来的离散动作和连续动作。在大规模的自我中心数据集EPIC KITCHENS中,我们观察到我们的方法生成高质量和多样化的样本,同时展示出比相关生成模型更好的泛化。最后,我们提出了一种变体,从流数据中不断学习我们的模型,观察其实际效果,并在理论上证明其学习效率。 |
| Multimodal Machine Learning-based Knee Osteoarthritis Progression Prediction from Plain Radiographs and Clinical Data Authors Aleksei Tiulpin, Stefan Klein, Sita M.A. Bierma Zeinstra, J r me Thevenot, Esa Rahtu, Joyce van Meurs, Edwin H.G. Oei, Simo Saarakkala 膝关节骨性关节炎OA是最常见的无法治愈的肌肉骨骼疾病,目前的治疗方案仅限于缓解症状。 OA进展的预测是一个非常具有挑战性和及时的问题,如果得到解决,它可以加速疾病调节药物的开发,并最终有助于防止每年进行数百万次全关节置换手术。在这里,我们提出了一种基于多模态机器学习的OA进展预测模型,该模型利用原始射线照相数据,临床检查结果和患者的既往病史。我们在来自2,129名受试者的3,918张膝关节图像的独立测试集上验证了这种方法。我们的方法在ROC曲线AUC为0.79 0.78 0.81,平均精度AP为0.68 0.66 0.70时产生面积。相比之下,基于逻辑回归的参考方法产生的AUC为0.75 0.74 0.77,AP为0.62 0.60 0.64。该方法可以显着改善OA药物开发试验的受试者选择过程,并有助于个性化治疗计划的发展。 |
| Generalized Presentation Attack Detection: a face anti-spoofing evaluation proposal Authors Artur Costa Pazo, David Jimenez Cabello, Esteban Vazquez Fernandez, Jose L. Alba Castro, Roberto J. L pez Sastre 在过去几年中,Presentation Attack Detection PAD已经成为面部识别系统的基本组成部分。尽管在反欺骗研究方面投入了大量精力,但在真实场景中的推广仍然是一项挑战。在本文中,我们提出了一个新的开源评估框架来研究面部PAD方法的泛化能力,在这里被创造为面向GPAD。该框架有助于创建侧重于泛化问题的新协议,建立公平的评估程序和PAD解决方案之间的比较。我们还引入了一个大型聚合和分类数据集,以解决公开数据集之间不兼容的问题。最后,我们提出了一个基准,增加了两个新的评估协议,一个用于测量面部分辨率变化引入的影响,另一个用于评估对抗性操作条件的影响。 |
| Topological signature for periodic motion recognition Authors Javier Lamar Leon, Rocio Gonzalez Diaz, Edel Garcia Reyes 在本文中,我们提出了一种算法,用于计算给定周期运动序列的拓扑签名。这种特征由通过持久同源性获得的矢量组成,该矢量捕获模拟运动的对象的拓扑和几何变化。简单地通过相应矢量之间的角度比较两个拓扑签名。关于步态识别,我们仅使用身体轮廓的最低四分之一测试了我们的方法。通过这种方式,在实际场景中非常频繁的身体上部变化的影响显着降低。我们还使用其他周期性运动(例如跑步或跳跃)测试了我们的方法。最后,我们正式证明了我们的方法对输入数据中的小扰动是鲁棒的,并且不依赖于周期运动序列中包含的周期数。 |
| An Empirical Evaluation Study on the Training of SDC Features for Dense Pixel Matching Authors Ren Schuster, Oliver Wasenm ller, Christian Unger, Didier Stricker 训练深度神经网络是一项非常重要的任务。不仅可以调整超参数,还可以收集和选择训练数据,设计损失函数以及构建训练计划对于充分利用模型非常重要。在这项研究中,我们进行了一系列与这些问题相关的实验。研究不同训练策略的模型是最近呈现的SDC描述符网络堆叠扩张卷积。它用于描述像素级别的图像,用于密集匹配任务。我们的工作更详细地分析了SDC,验证了深度神经网络训练的一些最佳实践,并提供了对多域数据训练的见解。 |
| PWOC-3D: Deep Occlusion-Aware End-to-End Scene Flow Estimation Authors Rohan Saxena, Ren Schuster, Oliver Wasenm ller, Didier Stricker 在过去几年中,卷积神经网络CNN已经证明在学习许多计算机视觉任务方面取得了越来越大的成功,包括密集估计问题,如光流和立体匹配。然而,这些任务的联合预测,称为场景流,传统上使用基于原始假设的慢经典方法来解决,这些方法未能概括。本文介绍的工作通过提出PWOC 3D克服了速度和准确性方面的这些缺点,PWOC 3D是一种紧凑的CNN架构,用于预测端到端监督设置中立体图像序列的场景流。此外,大的运动和遮挡是场景流估计中众所周知的问题。 PWOC 3D采用专门的设计决策来明确地模拟这些挑战。在这方面,我们提出了一种新颖的自我监督策略来预测从没有任何标记的遮挡数据的图像中的遮挡。利用多种此类构造,我们的网络在KITTI基准测试和具有挑战性的FlyingThings3D数据集上实现了竞争结果。特别是在KITTI上,PWOC 3D在端到端深度学习方法中排名第二,参数比最佳表现方法少48倍。 |
| Face De-occlusion using 3D Morphable Model and Generative Adversarial Network Authors Xiaowei Yuan, In Kyu Park 近几十年来,3D可变形模型3DMM已经普遍用于基于图像的照片级真实感3D面部重建。然而,面部图像经常被包括眼镜,面具和手的非面部物体严重遮挡而破坏。这些对象阻止正确捕获地标和阴影信息。因此,重建的3D人脸模型难以重复使用。本文提出了一种基于3DMM反向使用和生成对抗网络恢复被遮挡人脸图像的新方法。我们在提出的对抗网络之前使用3DMM,并结合全局和局部对抗卷积神经网络来学习面部遮挡模型。 3DMM不仅用作几何先验,还为局部鉴别器提出面部区域。实验结果证实了所提出的算法在去除具有各种头部姿势和照明的具有挑战性的遮挡类型方面的有效性和鲁棒性。此外,所提出的方法利用去遮挡纹理重建正确的3D面部模型。 |
| Evaluating Robustness of Deep Image Super-Resolution against Adversarial Attacks Authors Jun Ho Choi, Huan Zhang, Jun Hyuk Kim, Cho Jui Hsieh, Jong Seok Lee 单图像超分辨率旨在生成低分辨率图像的高分辨率版本,其在许多计算机视觉应用中充当必要组件。本文研究了基于深度学习的超分辨率方法对抗对抗性攻击的鲁棒性,这可以显着恶化超分辨率图像,而在受到攻击的低分辨率图像中没有明显的失真。已经证明,现有技术的深度超分辨率方法极易受到对抗性攻击。从理论上和实验上分析了不同方法的不同水平的鲁棒性。我们还分析了攻击的可转移性,以及针对性攻击和普遍攻击的可行性。 |
| Digging Deeper into Egocentric Gaze Prediction Authors Hamed R. Tavakoli, Esa Rahtu, Juho Kannala, Ali Borji 本文深入研究了影响自我中心凝视的因素。我们建议在日常工作中检查有助于注视引导的因素,而不是盲目地为此目的训练深层模型。与强空间先验基线相比,评估自下而上的显着性和光流。任务特定提示(例如消失点,操纵点和手区域)被分析为自上而下信息的代表。我们还通过研究自我中心凝视预测的简单递归神经模型来研究这些因素的贡献。首先,为所有输入视频帧提取深度特征。然后,使用门控递归单元随时间整合信息并预测下一次固定。我们还提出了一个集成模型,它将循环模型与几个自上而下和自下而上的线索相结合。在多个数据集上进行的大量实验表明,自我中心视频中有1个空间偏差很强,2个自下而上显着模型在预测凝视和表现空间偏差方面表现不佳,3个深度特征与传统特征相比表现更好,4与手部区域相比,操纵点是凝视预测的一个强有力的影响因素,5将提出的复发模型与自下而上的线索,消失点相结合,特别是操纵点导致对自我中心视频的最佳凝视预测准确性,6知识转移最适用于任务或序列是相似的,7任务和活动识别可以受益于凝视预测。我们的研究结果表明,1应该更多地强调手对象的相互作用,2自我中心视觉社区应该考虑更大的数据集,包括不同的刺激和更多的主题。 |
| Multi-View Region Adaptive Multi-temporal DMM and RGB Action Recognition Authors Mahmoud Al Faris, John P. Chiverton, Yanyan Yang, David L. Ndzi 人类行为识别仍然是一项重要而又具有挑战性这项工作提出了一种新颖的行动识别系统它使用新颖的多视图区域自适应多分辨率时间深度运动图MV RAMDMM公式结合外观信息。多流3D卷积神经网络CNN在区域自适应深度运动图的不同视图和时间分辨率上进行训练。合成多个视图以增强视图不变性。基于局部运动的区域自适应权重,强调和区分具有更快运动的动作的部分。还包括用于多时间分辨率外观信息RGB的专用3D CNN流。这些有助于识别和区分小对象交互。这里使用预先训练的3D CNN,对每个流进行微调,以及多类支持向量机SVM。平均分数融合用于输出。所开发的方法能够识别人类行为和人类对象的相互作用。三个公共领域数据集(包括MSR 3D Action,西北UCLA多视图操作和MSR 3D日常活动)用于评估建议的解决方案。实验结果证明了该方法与现有算法相比的鲁棒性。 |
| Unifying Heterogeneous Classifiers with Distillation Authors Jayakorn Vongkulbhisal, Phongtharin Vinayavekhin, Marco Visentini Scarzanella 在本文中,我们研究了将一组具有不同体系结构和目标类的分类器中的知识统一到单个分类器中的问题,只给出了一组通用的未标记数据。我们将此问题称为统一异构分类器UHC。该问题的动机是从多个源收集数据的情况,但是例如由于隐私问题,源不能共享其数据,并且只能共享经过私人训练的模型。此外,由于每个源的数据可用性,每个源可能无法收集数据以训练所有类,并且由于不同的计算资源,可能无法训练相同的分类模型。为了解决这个问题,我们提出了将知识蒸馏概括为合并HC的概括。我们推导出HC的输出与所有类别的概率之间的概率关系。基于这种关系,我们提出了两类基于交叉熵最小化和矩阵因子分解的方法,它们允许我们从未标记的样本中估计所有类的软标签,并使用它们代替地面实况标签来训练统一的分类器。我们在ImageNet,LSUN和Places365数据集上的广泛实验表明,我们的方法明显优于蒸馏的天然延伸,并且可以实现与以集中,监督方式训练的分类器几乎相同的精度。 |
| Unsupervised Method to Localize Masses in Mammograms Authors Bilal Ahmed Lodhi 乳腺癌是最常见和最普遍的癌症类型之一,主要影响女性人群。早期诊断有效治疗的机会增加。乳房X线照相术被认为是早期诊断乳腺癌的有效且经过验证的技术之一。肿块周围的组织看起来相同,这使得自动检测过程成为一项非常具有挑战性的任务。它们与周围的薄壁组织无法区分。在本文中,我们提出了一种有效的自动化方法来分割乳房X线照片中的肿块。所提出的方法使用分层聚类来隔离显着区域,然后提取特征以拒绝错误检测。我们将我们的方法应用于两个流行的公开数据集mini MIAS和DDSM。随机选择来自迷你mias数据库的56个图像和来自DDSM的76个图像。根据ROC接收器操作特性曲线解释结果并与其他技术进行比较。实验结果证明了该系统在乳房X线照片中自动质量识别的效率和优势。 |
| Adaptive Weighting Multi-Field-of-View CNN for Semantic Segmentation in Pathology Authors Hiroki Tokunaga, Yuki Teramoto, Akihiko Yoshizawa, Ryoma Bise 自动数字组织病理学图像分割是帮助病理学家诊断肿瘤和癌症亚型的重要任务。对于癌症亚型的病理诊断,病理学家通常改变整个载玻片图像WSI观察者的放大率。一个关键假设是放大倍数的重要性取决于输入图像的特征,例如癌症亚型。在本文中,我们提出了一种新的语义分割方法,称为自适应加权多视场CNN AWMF CNN,可以自适应地使用来自不同放大率的图像的图像特征来分割输入图像中的多个癌症亚型区域。所提出的方法通过根据输入图像自适应地改变每个专家的权重来聚合几个专家CNN用于不同放大率的图像。它利用可能对识别子类型有用的不同放大率的图像中的信息。它在实验中胜过其他最先进的方法。 |
| EvalNorm: Estimating Batch Normalization Statistics for Evaluation Authors Saurabh Singh, Abhinav Shrivastava 批量标准化BN对于深度学习非常有效并且被广泛使用。然而,当使用小型微型培训时,使用BN的模型表现出性能的显着降低。在本文中,我们研究了BN的这种特殊行为,以便更好地理解问题,并根据统计洞察确定潜在原因。我们建议EvalNorm通过估计在评估期间用于BN的校正归一化统计来解决该问题。 EvalNorm支持在训练模型时在线估计校正后的统计数据,并且不会影响模型的训练方案。因此,EvalNorm的一个附加优势是它可以与现有的预训练模型一起使用,从而使它们能够从我们的方法中受益。 EvalNorm为使用较小批次训练的模型带来了巨大的收益。我们的实验表明,对于ImageNet验证集上的2个批量大小,EvalNorm执行6.18绝对优于vanilla BN,并且在各种设置中,COCO对象检测基准上的绝对增益为1.5到7.0个点。 |
| Cycle-Consistent Adversarial GAN: the integration of adversarial attack and defense Authors Lingyun Jiang, Kai Qiao, Ruoxi Qin, Linyuan Wang, Jian Chen, Haibing Bu, Bin Yan 在深度学习的图像分类中,用于增加小幅度扰动的输入的对抗性示例可能误导深度神经网络DNN到不正确的结果,这意味着DNN易受它们的攻击。为了更好地研究深度学习的机制,已经提出了不同的攻防策略。然而,这些网络中的研究仅仅针对一个方面,无论是攻击还是防御,不考虑攻击和防御应该相互依赖和相互加强,就像长矛和盾牌之间的关系一样。在本文中,我们提出循环一致性对抗性GAN CycleAdvGAN来生成对抗性示例,其可以学习和近似原始实例和对抗性示例的分布。对于CycleAdvGAN,一旦生成并且经过训练,就可以有效地为任何实例生成对抗性扰动,从而使DNN预测错误,并恢复对抗性实例来清理实例,从而使DNN预测正确。我们在两个公共数据集MNIST和CIFAR10上的半白盒和黑盒设置下应用CycleAdvGAN。通过广泛的实验,我们证明了我们的方法已经达到了最先进的对抗攻击方法,并且有效地提高了防御能力,使得对抗攻击和防御的整合成为现实。此外,它还改进了攻击效果,仅对任何类型的对抗性攻击所产生的对抗性数据集进行训练。 |
| A Light Dual-Task Neural Network for Haze Removal Authors Yu Zhang, Xinchao Wang, Xiaojun Bi, Dacheng Tao 单一图像去雾是一个具有挑战性的问题,因为它具有不良的性质。现有方法依赖于次优的两步法,其中估计诸如深度图的中间产品,基于该中间产品随后使用人工先验公式生成无雾图像。在本文中,我们提出了一种称为LDTNet的轻型双任务神经网络,可以一次性恢复无雾图像。我们使用传输图估计作为辅助任务来辅助主要任务,雾霾去除,特征提取以及增强网络的泛化。在LDTNet中,同时产生无雾度图像和透射图。结果,人工先验减少到最小程度。大量实验表明,我们的算法在合成和真实世界图像上都能够针对最先进的方法实现卓越的性能。 |
| Real-Time Dense Stereo Embedded in A UAV for Road Inspection Authors Rui Fan, Jianhao Jiao, Jie Pan, Huaiyang Huang, Shaojie Shen, Ming Liu 路面状况评估对于确保其可维护性至关重要,同时仍能提供最大的道路交通安全。本文介绍了一种嵌入无人机无人机的鲁棒立体视觉系统。首先将目标图像的透视图变换为参考视图,这不仅提高了视差精度,而且降低了算法的计算复杂度。然后使用双边滤波器对立体匹配产生的成本量进行滤波。后者已被证明是完全连通马尔可夫随机场模型中功能最小化问题的可行解。最后,通过相对于侧倾角和视差投影模型最小化能量函数来变换视差图。这使受损的道路区域更加与路面区分开来。所提出的系统在具有CUDA的NVIDIA Jetson TX2 GPU上实现,用于实时目的。通过实验证明,可以容易地将受损的道路区域与变换的视差图区分开。 |
| A New Loss Function for CNN Classifier Based on Pre-defined Evenly-Distributed Class Centroids Authors Qiuyu Zhu, Pengju Zhang, Xin Ye 随着近年来卷积神经网络CNN的发展,网络结构变得越来越复杂多变,在模式识别,图像分类,目标检测和跟踪方面取得了很好的效果。对于用于图像分类的CNN,除了网络结构外,现在越来越多的研究关注于损失函数的改进,从而扩大类间特征差异,并尽快减少类内特征变化。 。除了传统的Softmax之外,典型的损耗函数包括L Softmax,AM Softmax,ArcFace和Center loss等。基于CSAE网络中预定义均匀分布的类质心PEDCC的概念,本文提出了一种基于PEDCC的损失函数,称为PEDCC Loss,这可以使隐藏的特征空间中的类间距离最大和类内距离足够小。多个图像分类和人脸识别实验证明,该方法具有最佳的识别精度,网络训练稳定,易于收敛。 |
| An Introduction to Person Re-identification with Generative Adversarial Networks Authors Hamed Alqahtani, Manolya Kavakli Thorne, Charles Z. Liu 人格识别是计算机视觉领域的基础课程。传统方法在解决复杂背景下的遮挡,姿势变化和特征变化等人物照明问题上存在一些局限性。幸运的是,深度学习范式开辟了人物识别研究的新途径,成为该领域的热点。生成性对抗网在过去几年中,GAN在解决这些问题时引起了很多关注。本文回顾了基于GAN的人员识别方法,重点关注不同基于GAN的框架的相关论文,并讨论了它们的优缺点。最后,提出了未来研究的方向,特别是基于GAN的人员识别方法的前景。 |
| The iWildCam 2018 Challenge Dataset Authors Sara Beery, Grant van Horn, Oisin MacAodha, Pietro Perona 相机陷阱是研究生物多样性的有用工具,但使用这些数据的研究受到人类注释速度的限制。由于现有大量数据,我们必须开发自动解决方案来注释相机陷阱数据,以便进行此项研究。一种有前景的方法是基于对人类注释图像进行训练的深度网络。我们提供了一个挑战数据集,以探索这些解决方案是否可以推广到新的位置,因为经过一次训练并可能部署在新位置自动运行的系统将是最有用的。 |
| Cramnet: Layer-wise Deep Neural Network Compression with Knowledge Transfer from a Teacher Network Authors Jon Hoffman 神经网络完成了惊人的事情,但它们受到限制其使用的计算和内存瓶颈的影响。没有比在移动领域更好地看到这一点,在移动领域,正在创建专门的硬件以满足对神经网络的需求。以前的研究表明,神经网络的连接数量远远超过实际工作所需的连接数。本文开发了一种方法,可以将网络压缩到小于10的内存和小于25的计算能力,而不会损失准确性,并且不会创建需要特殊代码运行的稀疏网络。 |
| The Sound of Motions Authors Hang Zhao, Chuang Gan, Wei Chiu Ma, Antonio Torralba 声音源于物体运动和周围空气的振动。受到人类能够从物体如何在视觉上移动来解释声源这一事实的启发,我们提出了一种新颖的系统,该系统明确地捕获了声音定位和分离任务的运动提示。我们的系统由一个名为Deep Dense Trajectory DDT的端到端可学习模型和一个课程学习方案组成。它利用了来自大量未标记视频的视听信号的固有连贯性。定量和定性评估表明,与先前依赖视觉外观线索的模型相比,我们的基于动作的系统提高了分离乐器声音的性能。此外,它将声音组件与同类仪器的二重奏分开,这是一个以前没有解决过的具有挑战性的问题。 |
| TAFE-Net: Task-Aware Feature Embeddings for Low Shot Learning Authors Xin Wang, Fisher Yu, Ruth Wang, Trevor Darrell, Joseph E. Gonzalez 学习图像的良好特征嵌入通常需要大量的训练数据。因此,在训练数据受限的设置中,例如,少量镜头和零镜头学习,我们通常被迫使用嵌入各种任务的通用特征。理想情况下,我们希望构建针对给定任务进行调整的要素嵌入。在这项工作中,我们建议任务感知特征嵌入网络TAFE网络学习如何以元学习方式使图像表示适应新任务。我们的网络由元学习器和预测网络组成。基于任务输入,元学习器生成预测网络中的特征层的参数,使得可以针对该任务精确地调整特征嵌入。我们证明TAFE Net在推广新任务或概念方面非常有效,并且在零射击和少射击学习的一系列基准测试中评估TAFE网络。我们的模型在所有任务上都达到或超过了最新技术水平。特别地,我们的方法在具有挑战性的视觉属性对象组合任务上将未看见的属性对象对的预测准确度提高了4到15个点。 |
| Automatic Pulmonary Nodule Detection in CT Scans Using Convolutional Neural Networks Based on Maximum Intensity Projection Authors Sunyi Zheng, Jiapan Guo, Xiaonan Cui, Raymond N. J. Veldhuis, Matthijs Oudkerk, Peter M.A.van Ooijen 计算机断层扫描中准确的肺结节检测是肺癌筛查中的关键步骤。计算机辅助检测CAD系统不是常规用于临床实践中肺结节检测的放射科医师,尽管它们具有潜在的益处。最大强度投影MIP图像通过计算机断层扫描CT扫描改善了放射学评估中肺结节的检测。在这项工作中,我们旨在探索利用MIP图像提高卷积神经网络CNNs自动检测肺结节的有效性的可行性。我们提出了一种基于CNN的方法,该方法将不同厚度的5mm,10mm,15mm和1mm平板多平面重建MPR图像的MIP图像作为输入。这种方法利用更具代表性的空间信息来增强2D D CT图像,这有助于通过其形态从血管中区分出结节。我们使用从七个学术中心收集的公共LUNA16集来训练和测试我们的方法。我们提出的方法在该数据集中实现了91.13的灵敏度,每次扫描具有1个假阳性,灵敏度为94.13,每次扫描有4个假阳性用于肺结节检测。使用厚MIP图像有助于检测3mm 10mm的小肺结节并获得较少的假阳性。实验结果表明,应用MIP图像可以提高灵敏度,降低假阳性数,证明了基于CNN框架的CT扫描自动肺结节检测的有效性和重要性。索引术语计算机辅助检测CAD,卷积神经网络CNNs,计算机断层扫描,最大强度投影MIP,肺结节检测 |
| Absolute Human Pose Estimation with Depth Prediction Network Authors M rton V ges, Andr s L rincz 3D人体姿势估计的常见方法是预测相对于臀部的身体关节坐标。这适用于单个人,但在多个交互人员的情况下是不够的。预测绝对坐标的方法首先估计根相对姿势,然后通过辅助优化任务计算转换。我们提出了一种神经网络,它可以预测相机中心坐标系中的关节,而不是相对于根的坐标系。与以前的方法不同,我们的网络只需一步即可完成,无需任何后期处理。我们的网络优于MuPoTS 3D数据集的先前方法,并实现最先进的结果。 |
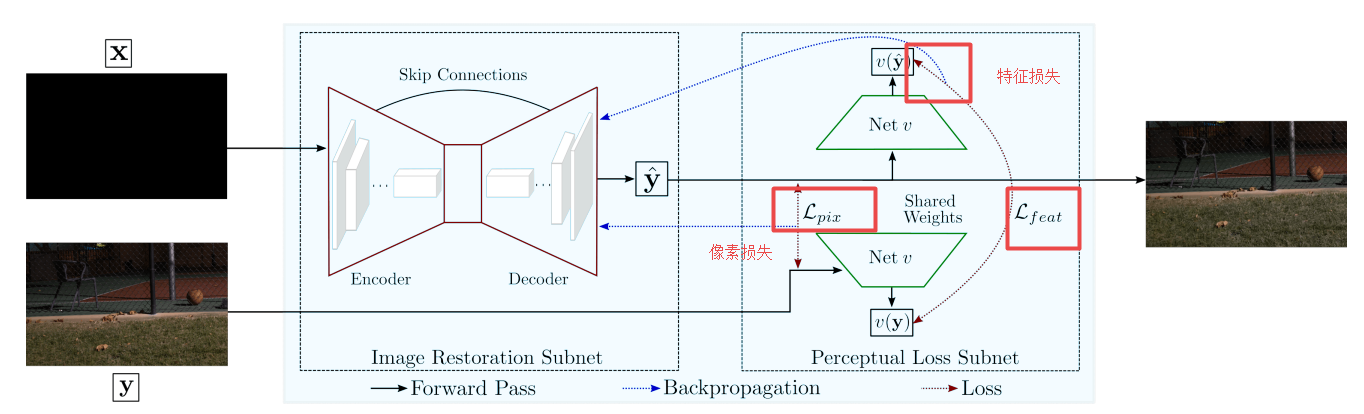
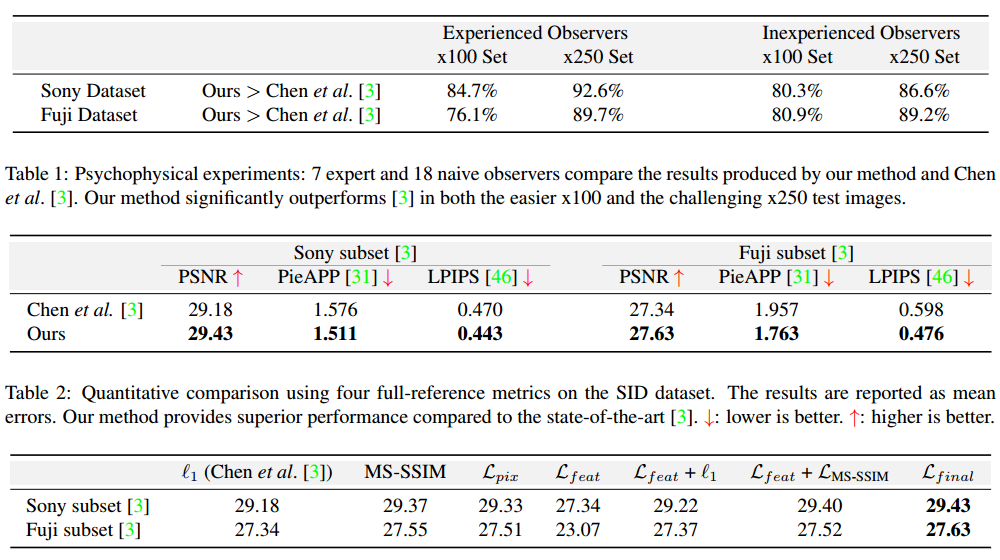
| Learning Digital Camera Pipeline for Extreme Low-Light Imaging Authors Syed Waqas Zamir, Aditya Arora, Salman Khan, Fahad Shahbaz Khan, Ling Shao 在低光条件下,传统的相机成像管道产生亚最佳图像,由于低光子计数和低信噪比SNR,这些图像通常是暗的和有噪声的。我们提出了一种数据驱动方法,该方法可以学习曝光良好的图像所需的属性,并将它们反映在极低环境光环境中捕获的图像中,从而显着改善这些低光图像的视觉质量。我们提出了一种新的损失函数,它利用像素和感知指标的特征,使我们的深度神经网络能够学习相机处理流程,将短曝光,低光RAW传感器数据转换为曝光良好的sRGB图像。结果表明,根据心理物理测试以及像素标准度量和最近基于学习的感知图像质量测量,我们的方法优于现有技术。 |
| Synthetic Examples Improve Generalization for Rare Classes Authors Sara Beery, Yang Liu, Dan Morris, Jim Piavis, Ashish Kapoor, Markus Meister, Pietro Perona 检测和分类图像中罕见事件的能力具有重要的应用,例如,在研究生物多样性时计算稀有和濒危物种,或检测对自驾车造成危险的不常见的交通场景。很少有镜头学习是一个开放的问题,当前的计算机视觉系统很难对他们在训练期间很少看到的物体进行分类,并且收集足够数量的罕见事件的训练样本通常具有挑战性且昂贵,有时甚至是不可能的。我们深入探讨了这个问题的方法,用特殊的模拟数据补充了少数可用的训练图像。 |
| Boundary-Preserved Deep Denoising of the Stochastic Resonance Enhanced Multiphoton Images Authors Sheng Yong Niu, Lun Zhang Guo, Yue Li, Tzung Dau Wang, Yu Tsao, Tzu Ming Liu 随着生物医学研究中高速和深部组织成像的快速发展,迫切需要找到一种稳健有效的去噪方法来保留形态特征,以进行进一步的纹理分析和分割。传统的去噪滤波器和模型可以很容易地抑制高对比度图像中的微扰噪声。然而,对于低光子预算的多光子图像,高检测器增益不仅会增强信号,还会带来巨大的背景噪声。在这种成像的随机共振方案中,可以借助噪声检测亚阈值信号。因此,非常需要能够巧妙地去除噪声而不牺牲诸如单元边界的重要细胞特征的去噪滤波器。在本文中,我们提出了一种基于卷积神经网络的自动编码器方法,即全卷积深度去噪自动编码器DDAE,以提高三光子荧光3PF和三次谐波产生THG显微图像的质量。获取的给定位置的200个图像的平均值用作DDAE训练的低噪声答案。与其他广泛使用的去噪方法相比,我们的DDAE模型对3PF和THG分别表现出更好的信噪比26.6和29.9,3PF和THG的结构相似性分别为0.86和0.87,以及核或细胞边界的保留。 |
| Compressing deep neural networks by matrix product operators Authors Ze Feng Gao, Song Cheng, Rong Qiang He, Z. Y. Xie, Hui Hai Zhao, Zhong Yi Lu, Tao Xiang 深度神经网络是根据许多交替排列的线性和非线性变换的信号的多层映射的参数化。线性变换通常用于完全连接和卷积层,包含训练和存储的大多数变分参数。压缩深度神经网络以减少变分参数的数量而不是其预测能力是建立优化方案以有效地训练这些参数和降低过度拟合风险的重要但具有挑战性的问题。在这里,我们表明通过用矩阵乘积算子MPO表示线性变换可以有效地解决这个问题。我们在五个主要的神经网络中测试了这种方法,包括FC2,LeNet 5,VGG,ResNet和DenseNet两个广泛使用的数据集,即MNIST和CIFAR 10,并发现这个MPO表示确实建立了忠实和有效的映射输入和输出信号,可以显着减少参数数量,从而保持甚至提高预测精度。 |
| Towards Photographic Image Manipulation with Balanced Growing of Generative Autoencoders Authors Ari Heljakka, Arno Solin, Juho Kannala 我们建立在逐步增长的生成自动编码器模型的最新进展的基础上。这些模型可以编码和重建现有图像,并以与生成对抗网络GAN相当的分辨率生成新的图像,同时仅由单个编码器和解码器网络组成。重建和任意修改现有样本(如图像)的能力将自动编码器模型与GAN分开,但图像自动编码器的输出质量仍然较差。最近提出的PIONEER自动编码器可以在256次256 CelebAHQ数据集中重建面部,但是像最近的另一种方法IntroVAE一样,它常常会失去过程中人的身份。我们提出了PIONEER的改进和简化版本,并在视觉和数量上显示了CelebAHQ中面部身份的显着改善的质量和保存。我们还通过定量和通过逼真的图像特征操作来显示模型潜在空间的现有技术解开的证据。在LSUN Bedrooms数据集上,我们的模型还改进了原始PIONEER的结果。总的来说,我们的结果表明,PIONEER网络提供了一种照片般逼真的面部操作方法。 |
| Evaluating the Representational Hub of Language and Vision Models Authors Ravi Shekhar, Ece Takmaz, Raquel Fern ndez, Raffaella Bernardi 在计算语言学和计算机视觉交叉领域的新兴领域中使用的多模式模型实现了认知科学中提出的Hub和Spoke架构的自下而上的处理,以表示大脑如何处理和组合多个感官输入。特别地,Hub被实现为神经网络编码器。我们研究了文献视觉问题回答,视觉参考分辨率和视觉基础对话中提出的各种视觉和语言任务对该编码器的影响。为了测量编码器学习的表示的质量,我们使用两种分析。首先,我们评估在不同视觉和语言任务上预先训练的编码器,用于评估多模态语义理解的现有诊断任务。其次,我们进行了一系列分析,旨在研究编码器如何合并和利用这两种模式。 |
| Chinese Abs From Machine Translation |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号