
【今日CV 计算机视觉论文速览 第102期】Fri, 19 Apr 2019
今日CS.CV 计算机视觉论文速览
Fri, 19 Apr 2019
Totally 80 papers
👉上期速览✈更多精彩请移步主页

Interesting:
📚Deep Network Resizing (DNR)基于深度特征重建来实现图像的缩放, (from 特拉维夫大学)
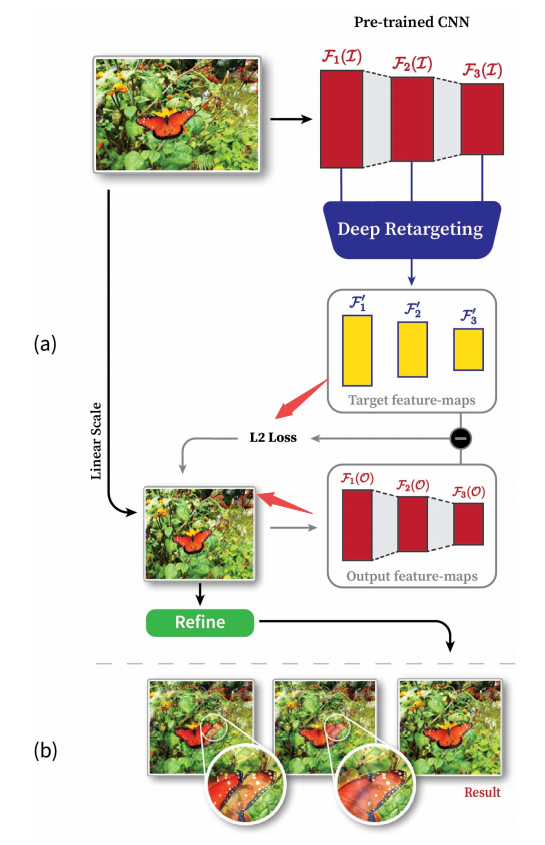

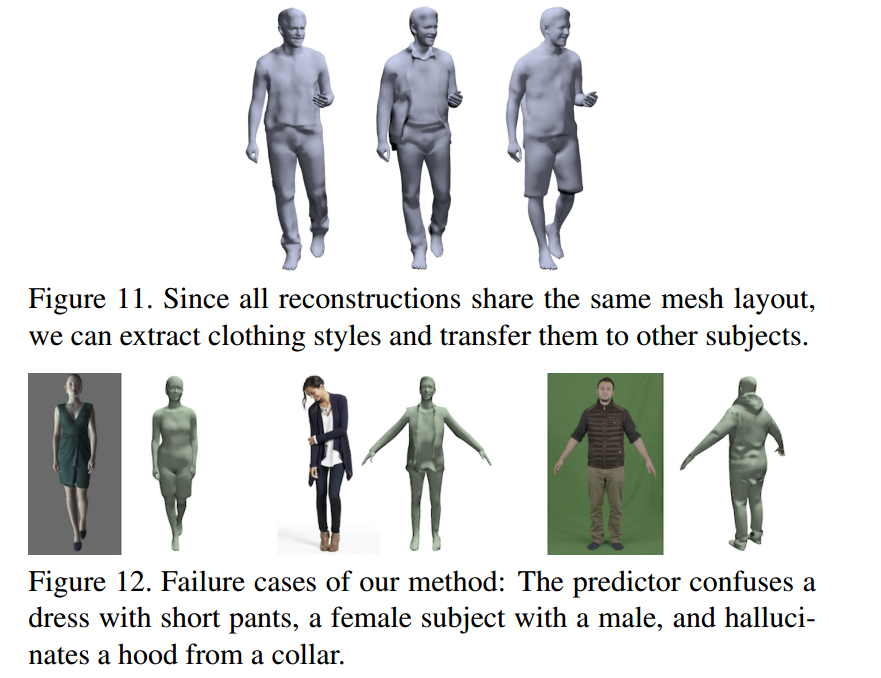
📚Tex2Shape, 基于单张图像生成人体几何外形(from 布伦瑞克工业大学 德国TU9 马普研究所)
先将图像转换到UV空间的材质图,而后利用自编码器处理并保留高频特征,利用PatchGAN判别器来判别,并将生成的表面法向量和位移结合起来利用SMPL(A skinned multi-person linear model)模型进行渲染。(The UV-mapping unfolds the body surface onto a 2D image such that every pixel corresponds to a 3D point on the body surface.)

主要工作是将UV图(partial texture map)生成对应法向量与偏移的SMPL(detailed normal and vector displacement maps),将图像生成3D外形转换为了图像到图像的迁移任务:

仿真中训练并在真实中得到了较好的结果:
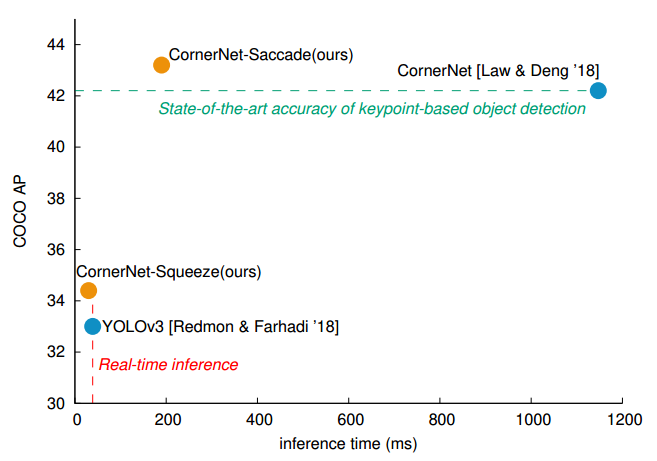
📚CornerNet-Lite, 基于关键点的目标检测,利用了CornerNet的两大高效优势,包括Saccade注意力机制用于减小不必要像素的计算、Squeeze引入了更为紧致的后端网络。不仅提高了六倍速度并得到了AP0.1的特征。(from 普林斯顿 Vision & Learning Lab
)
先预测一系列可能有物体的区域,并裁剪原图用于检测目标:
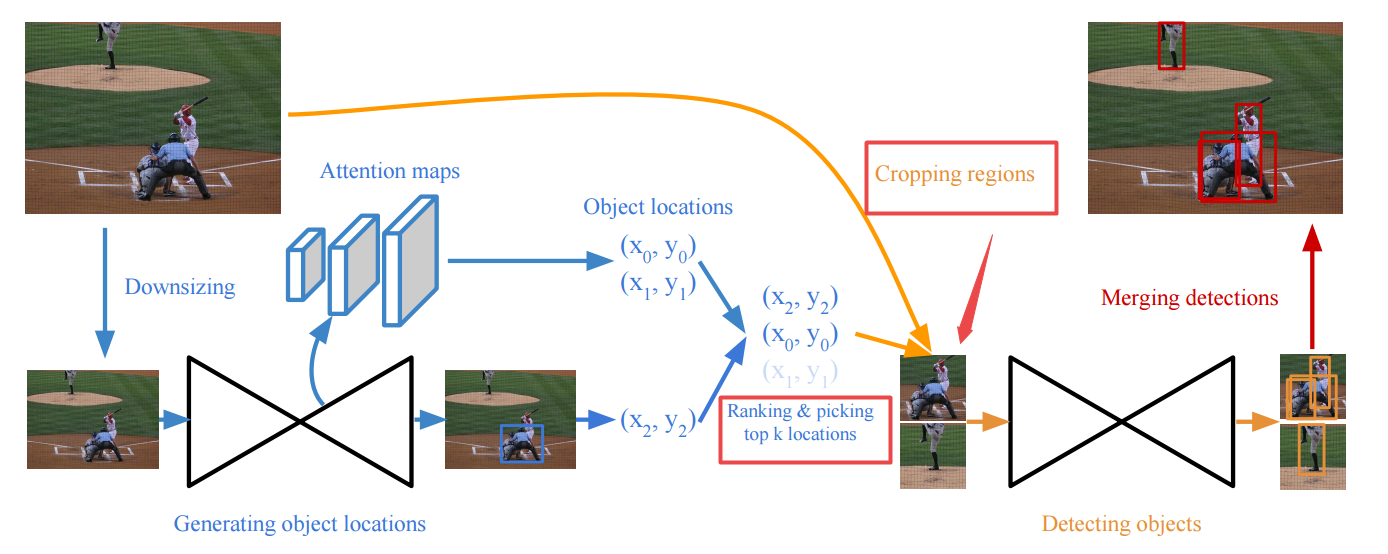
一些检测结果:

code:https://github.com/princeton-vl/CornerNet-Lite
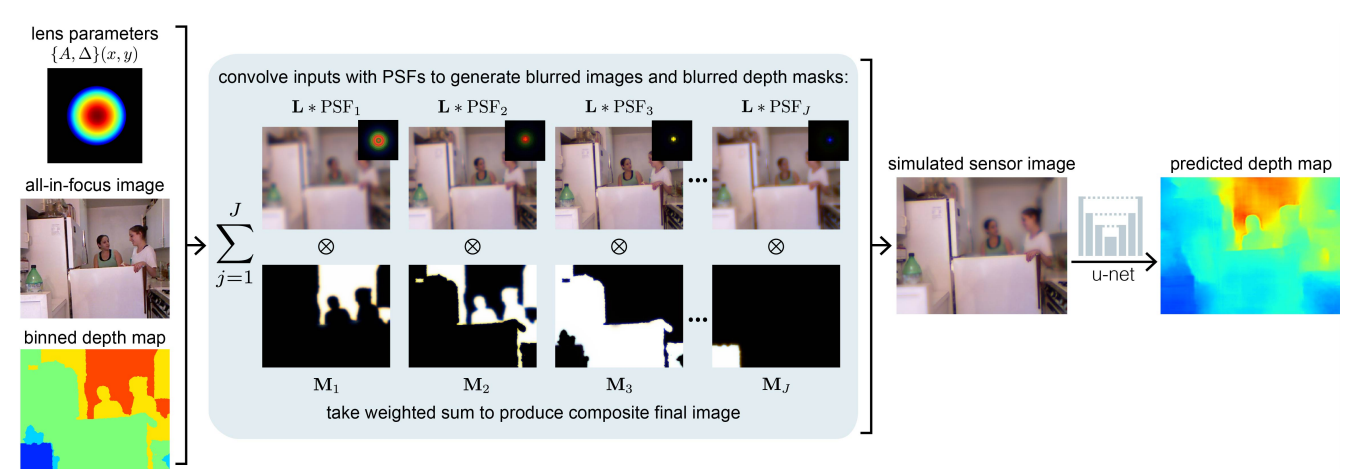
📚基于光学方法的深度估计帮助估计绝对深度, 端到端的结合了光学和图像处理过程用于单目深度估计问题,并利用编码的离焦模糊来作为辅助深度信息用于深度估计。研究发现优化的自由曲面设计得到结果较好,而色差也会带来相同的效果。研究建立了物理原型并验证了色差促进深度估计的效果。(from 斯坦福 )
点扩散函数的建模:
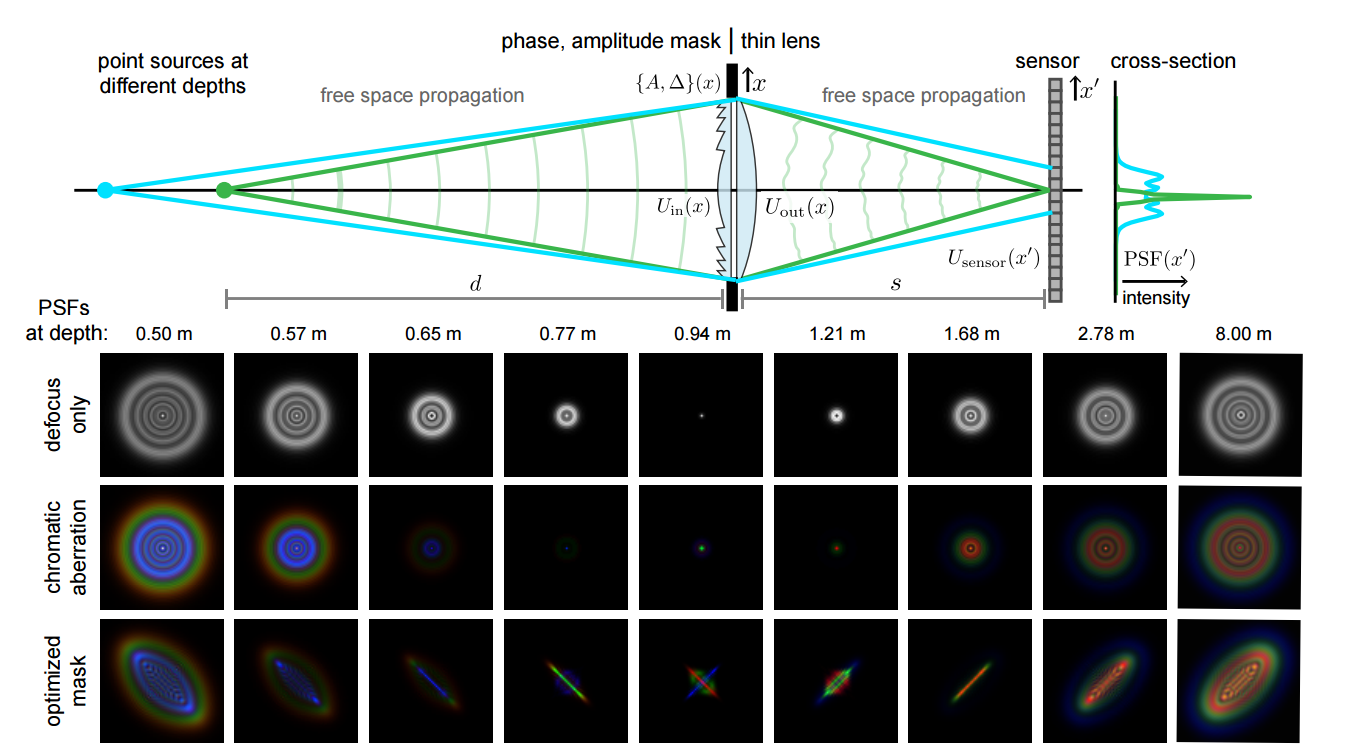
dataset:NYU Depth v2 and KITTI,计算成像
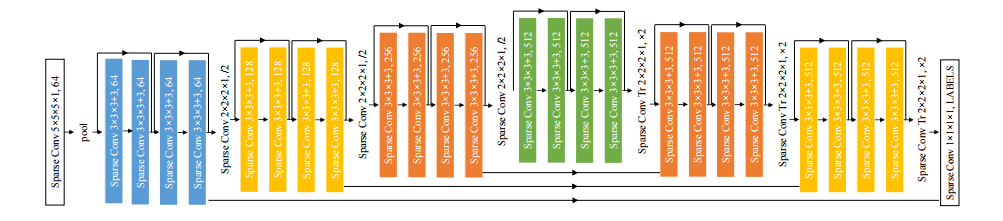
📚闵可夫斯基卷积神经网络处理4D空时卷积, 利用稀疏张量来进行卷积,并给出了一个处理稀疏张量自动差分的库。(from 斯坦福)
不同的空时核
code:https://github.com/StanfordVL/MinkowskiEngine
📚MLB半球比赛运动受伤预测检测, (from 印第安纳大学)

📚人脸去模糊, 通过一系列预训练的正交点扩散函数来表示点扩散函数,同时用一系列预训练的正交人脸组合来表示清晰的人脸。(from )

点扩散函数及线性组合:
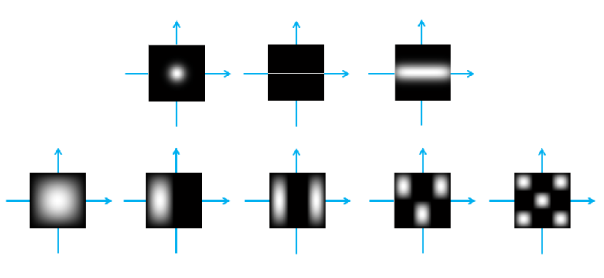
模糊图像与对应的模糊核:

dataset:
Facial Recognition Technology (FERET) Database1http://www.itl.nist.gov/iad/humanid/feret/feret_master.html
Yale Face Database B2http://vision.ucsd.edu/∼leekc/ExtYaleDatabase/ExtYaleB.html
CMU Pose, Illumination, and Expression (PIE) database3https://www.ri.cmu.edu/research project detail.html?project_id=418&
menu_id=261
Face Recognition Grand Challenge (FRGC) Database version 2.04http://www.nist.gov/itl/iad/ig/frgc.cfm
📚提高中心编码用于细胞检测, 将原始的点label编码成更容易学习的形式,便捷性和鲁棒性,为了分辨出相邻区域,提出了五种编码机制和四种细胞在两种网络上实验。(from 弗吉尼亚大学)
模型的编码,并与高斯和矩形编码作对比:

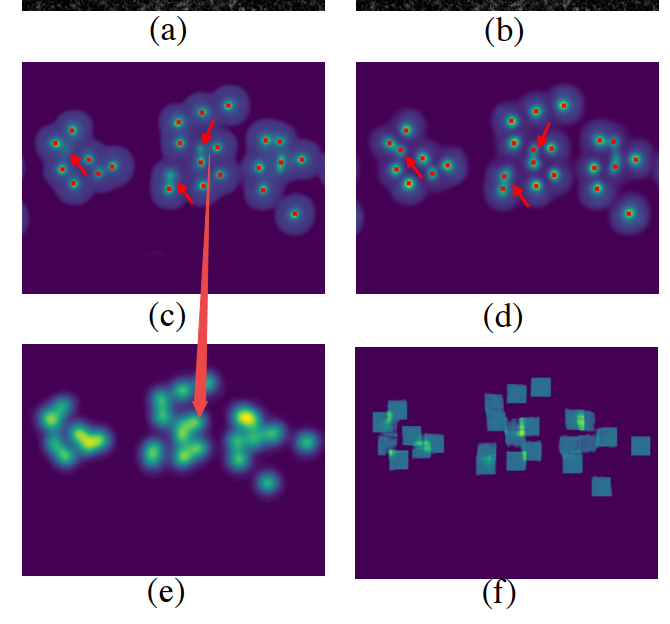

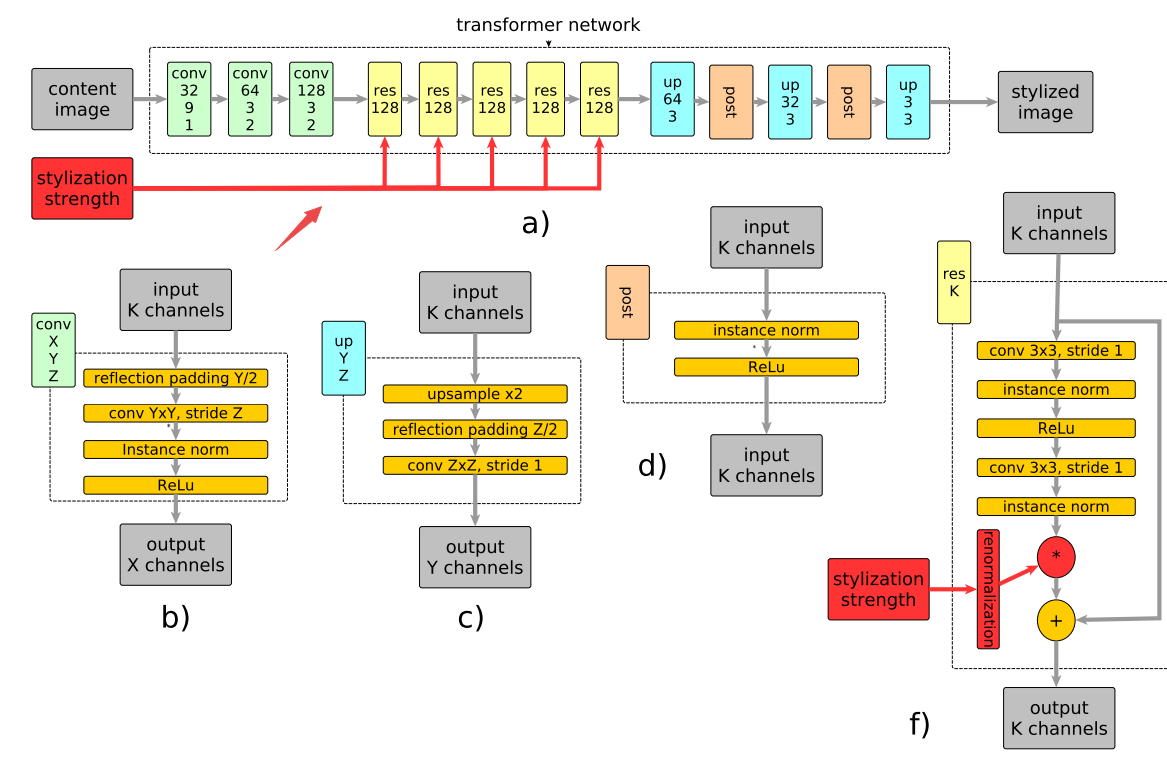
📚基于强度控制的实时风格迁移, 提出了可以直接连续控制风格化强度的模型。(from 莫斯科罗蒙索夫大学 )

在残差输出位置加入了强度控制单元:
控制风格强度的结果:
📚基于注意力机制的多任务单任务学习, 通过依赖于任务的特征适应,是网络可以充分利用任务相关特征,并突出任务相关的梯度。(from ethz)
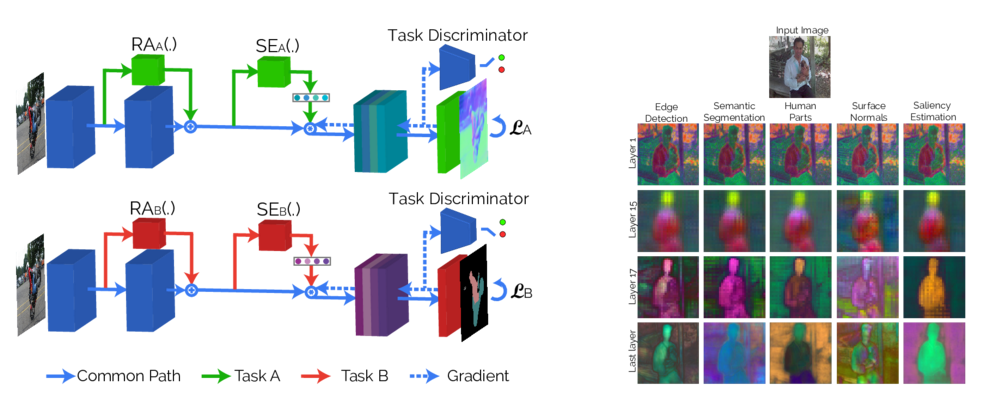
实现了边缘检测、分割、法向量估计和深度估计等。

code:http://www.vision.ee.ethz.ch/~kmaninis/astmt/
📚少儿不宜卡通片的识别, (from RECOD Lab., Institute of Computing, University of Campinas)
Elsagate卡通和架构图

评测方法:GoogLeNet [19], SqueezeNet [20], MobileNetV2 [21], and NASNet [22]
Elsagate dataset: https://github.com/akariueda/DLAforElsagate
📚基于近红外相机的天然气泄漏检测, (from 斯坦福)


📚由照片估计相机参数和拍摄相机, (from University of Campinas)
不同相机抹胸识别问题建模:
dataset:http://www.recod.ic.unicamp.br/~filipe/dataset/
Classifiers:http://www.ic.unicamp.br/~ra142698/oscmi-results.html
📚路面开裂检测, 基于神经网络实现了99.92%的准确率。首先分类是否存在缺陷,随后利用双边滤波去噪,最后利用自适应阈值分割(from 香港科技)
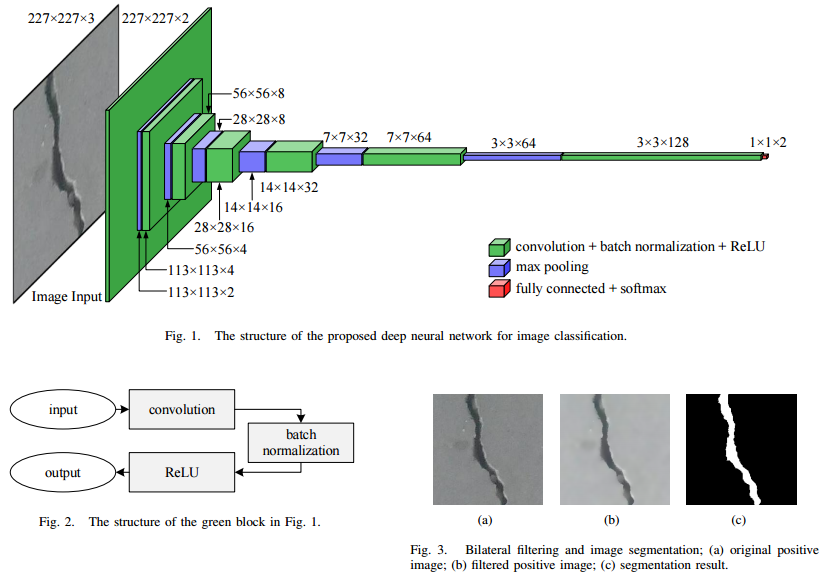
code:https://github.com/ruirangerfan/road_crack_detection_net
dataset:http://dx.doi.org/10.17632/5y9wdsg2zt.1
📚COncrete DEfect BRidge IMage dataset (CODEBRIM)混泥土缺陷检测数据集, 多目标分类任务。基于”efficient neural architecture search” 和MetaQNN来搜索神经网络实现了任务。(ENAS) (from Goethe University )

📚皮肤癌数据集的bias, (from Institute of Computing)
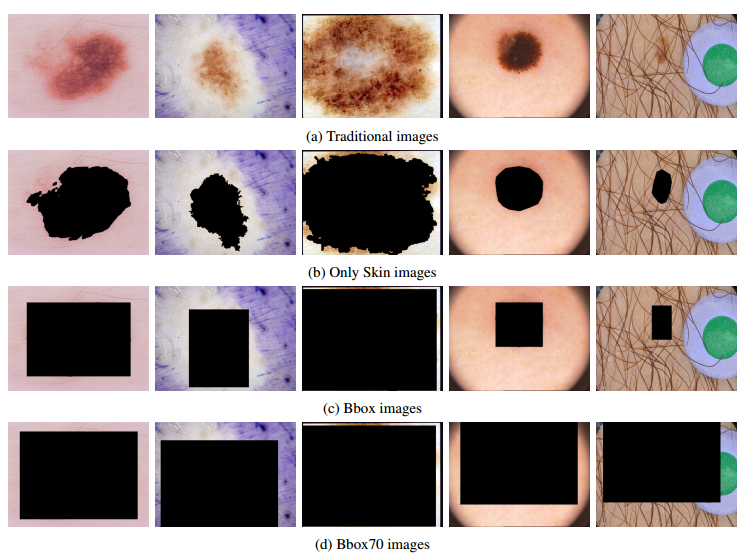
检测结果:
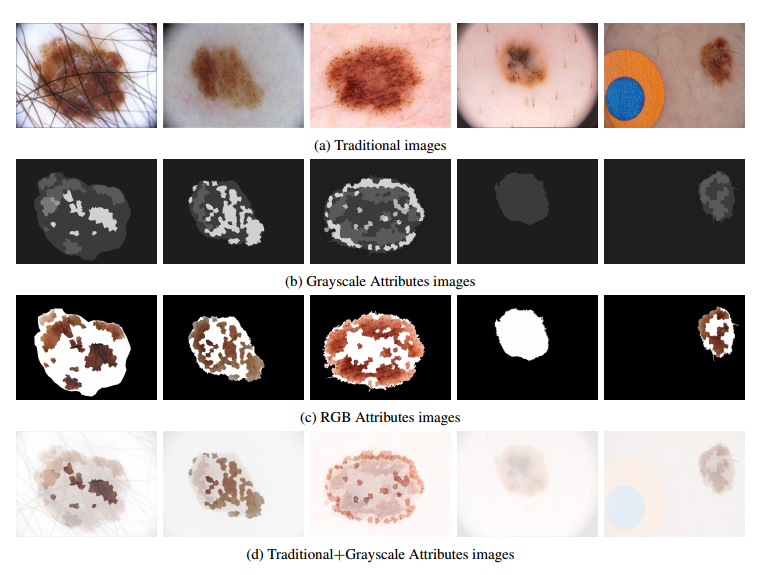
src:https://www.cancer.net/cancer-types/melanoma/statistics
code:https://github.com/alceubissoto/deconstructing-bias-skin-lesion
dataset:http://derm.cs.sfu.ca/Welcome.html
Daily Computer Vision Papers
| Attentive Single-Tasking of Multiple Tasks Authors Kevis Kokitsi Maninis, Ilija Radosavovic, Iasonas Kokkinos 在这项工作中,我们通过考虑网络是在多个任务上进行训练,但是一次执行一项任务来解决通用网络中的任务干扰,我们将这种方法称为单任务多任务。因此,网络通过任务相关的特征适配或任务关注来修改其行为。这使网络能够强调适应任务的功能,同时避开不相关的功能。我们通过强制通过对抗性训练在统计上无法区分任务梯度来进一步减少任务干扰,确保服务于所有任务的公共骨干架构不受任何特定任务梯度的支配。三个多任务密集标记问题的结果一致表明,在保持甚至提高性能的同时,参数数量大大减少,并且在计算和多任务准确性之间平滑折衷。我们提供系统代码和预先训练的模型 |
| Early Detection of Injuries in MLB Pitchers from Video Authors AJ Piergiovanni, Michael S. Ryoo 受伤是运动中的主要成本。球队每年花费数百万美元用于受伤和无法比赛的球员,导致比赛输球,球迷兴趣减少以及替补球员的额外工资。现代卷积神经网络已成功应用于许多视频识别任务。在本文中,我们介绍了MLB投手中伤害检测预测的问题,并通过实验评估这种卷积模型仅从视频数据中检测和预测球场伤害的能力。我们对2017年季节受伤的20名不同投手的电视转播MLB视频的大型数据集进行了实验。我们通过实验评估模型在每个投手上的表现,它对新投手的概括性,它对各种伤害的表现如何,以及它如何及早预测或发现伤害。 |
| Combating the Elsagate phenomenon: Deep learning architectures for disturbing cartoons Authors Akari Ishikawa, Edson Bollis, Sandra Avila 观看漫画对儿童的智力,社交和情感发展非常有用。然而,今天最流行的视频分享平台提供了许多带有Elsagate内容的视频。 Elsagate是一种在令人不安的环境中描绘童年人物的现象,例如血腥,厕所幽默,饮酒,偷窃。即使这种威胁很容易为儿童所用,文献中也没有解决问题的工作。作为第一个探讨漫画中令人不安的内容的人,我们从最新的色情检测文献开始,应用深度卷积神经网络结合视频的静态和运动信息。我们的解决方案与移动平台兼容,达到92.6的准确性。我们的目标不仅是引入第一个解决方案,还要围绕Elsagate进行讨论。 |
| CornerNet-Lite: Efficient Keypoint Based Object Detection Authors Hei Law, Yun Teng, Olga Russakovsky, Jia Deng 基于关键点的方法是对象检测中相对较新的范例,消除了对锚箱的需求并提供了简化的检测框架。基于Keypoint的CornerNet在单级探测器中实现了最先进的精度。然而,这种准确性来自高处理成本。在这项工作中,我们解决了基于关键点的高效对象检测问题,并引入了CornerNet Lite。 CornerNet Lite是CornerNet CornerNet Saccade的两种有效变体的组合,它使用注意机制消除了对图像的所有像素进行彻底处理的需要,以及引入新的紧凑骨干架构的CornerNet Squeeze。这两个变体共同解决了有效物体检测中的两个关键用例,在不牺牲精度的情况下提高了效率,并提高了实时效率的准确性。 CornerNet Saccade适用于离线处理,在COCO上将CornerNet的效率提高6.0倍,AP的效率提高1.0。 CornerNet Squeeze适用于实时检测,提高了CornerNet Squeeze的流行实时检测器YOLOv3 34.4 AP的效率和准确度,相比于COCO上YOLOv3的39.0 AP,33.0 AP。这些贡献首次共同揭示了基于关键点的检测对于需要处理效率的应用的潜力。 |
| No-Reference Quality Assessment of Contrast-Distorted Images using Contrast Enhancement Authors Jia Yan, Jie Li, Xin Fu 没有参考图像质量评估NR IQA旨在测量没有参考图像的图像质量。然而,NR IQA的当前研究忽略了对比度失真。在本文中,我们提出了一个非常简单但有效的度量标准,用于根据高对比度图像通常与其对比度增强图像更相似的事实来预测对比度变化图像的质量。具体来说,我们首先通过直方图均衡生成增强图像。然后,我们通过使用结构相似性指数SSIM作为第一特征来计算原始图像和增强图像的相似性。此外,我们分别计算原始图像和增强图像之间的基于直方图的熵和交叉熵,以获得4个特征的总和。最后,我们学习了一个回归模块来融合上述5个特征,以推断质量得分。四个公开数据库的实验验证了所提出技术的优越性和效率。 |
| Salient Object Detection: A Distinctive Feature Integration Model Authors Abdullah J. Alzahrani, Hina Afridi 我们提出了一种在不同图像中进行显着物体检测的新方法。我们的方法集成了空间特征,以实现高效和稳健的表示,以捕获有关显着对象的有意义信息。然后,我们使用集成特征训练条件随机场CRF。然后使用训练的CRF模型在在线测试阶段检测显着对象。我们对两个标准数据集进行实验,并将我们的方法的性能与不同的参考方法进行比较。我们的实验表明,我们的方法在精度,召回和F测量方面优于比较方法。 |
| Enhanced Center Coding for Cell Detection with Convolutional Neural Networks Authors Haoyi Liang, Aijaz Naik, Cedric L. Williams, Jaideep Kapur, Daniel S. Weller 细胞成像和分析是生物医学研究的基础,因为细胞是生命的基本功能单元。在不同的细胞相关分析中,细胞计数和检测被广泛使用。在本文中,我们关注一个基于学习的细胞计数方法的常见步骤,将原始点标签编码为更适合学习的地图。讨论了原始点标签编码的两个标准,并提出了一种新的编码方案。这两个标准衡量了使用编码方案训练模型是多么容易,以及在预测时恢复的原始点标签的稳健性。所提出的编码方案的最引人注目的优点是能够区分拥挤区域中的相邻小区。对四种类型的细胞和两种网络结构的五种编码方案进行细胞计数和检测实验。与广泛使用的高斯和矩形内核(最多12个)相比,所提出的编码方案提高了计数精度,并且与常见的接近编码相比,提高了检测精度。 |
| Generating Training Data for Denoising Real RGB Images via Camera Pipeline Simulation Authors Ronnachai Jaroensri, Camille Biscarrat, Miika Aittala, Fr do Durand 诸如去噪的图像重建技术通常需要应用于相机和手机的RGB输出。不幸的是,常用的加性白噪声AWGN模型不能准确地再现这些输入上的噪声和降级。这对于基于学习的技术尤其重要,因为训练和现实世界数据之间的不匹配将损害它们的泛化。本文旨在准确模拟摄像机管道的退化和噪声转换。这使我们能够在RGB图像中生成真实的降级,可用于训练机器学习模型。我们使用我们的模拟来研究噪声建模对基于学习的去噪的重要性。我们的研究表明,学习去噪真实的JPEG图像需要一个逼真的噪声模型。受现实噪声训练的神经网络优于使用AWGN训练的神经网络3 dB。对我们的管道的消融研究表明,模拟去噪和去马赛克对于这种改进很重要,并且需要很少考虑的现实的去马赛克算法。我们相信这种模拟对其他图像重建任务也很有用,我们将公开发布我们的代码。 |
| (De)Constructing Bias on Skin Lesion Datasets Authors Alceu Bissoto, Michel Fornaciali, Eduardo Valle, Sandra Avila 黑色素瘤是最致命的皮肤癌。自动皮肤病变分析在早期检测中起着重要作用。如今,ISIC档案和皮肤镜检查数据集是最常用的基于深度学习的工具的皮肤病变来源。但是,由于获取和注释它们的方式,所有数据集都包含偏差,通常是无意的。这些偏差扭曲了机器学习模型的性能,产生了模型可能不公平地利用的虚假相关性,或者相反地破坏了模型可以学习的有说服力的相关性。在本文中,我们提出了一组实验,揭示现有皮肤病变数据集中的两种偏差类型,即正面和负面。我们的研究结果表明,模型能够正确地对皮肤病变图像进行分类而不会产生临床上有意义的信息,机器学习模型在图像上学习,其中没有关于病变的信息仍然存在,提供了高于AI基准的精确度,该基准由皮肤科医生表现。这强烈暗示了指导模型的虚假相关性。我们给模型提供了额外的临床有意义的信息,这些信息甚至未能略微改善结果,这表明了有力的相关性的破坏。我们的主要发现提高了对在我们评估的小数据集中训练和评估的模型的局限性的认识,并且可能建议用于现实世界部署的模型的未来指南。 |
| DDNet: Cartesian-polar Dual-domain Network for the Joint Optic Disc and Cup Segmentation Authors Qing Liu, Xiaopeng Hong, Wei Ke, Zailiang Chen, Beiji Zou 现有的联合视盘和杯分割方法是在笛卡尔坐标系或极坐标系中开发的。然而,由于微妙的光学杯,即使通过主流CNN从单个域利用的上下文信息仍然不足。在本文中,我们提出了一种新的分割方法,即笛卡尔极化双域网络DDNet,它首次考虑了笛卡尔域和极域的互补性。我们提出了一个域特征编码器的两个分支,并从笛卡尔域学习直线网格上的平移等变表示,并且从极域并行地在极坐标网格上旋转等变表示。为了融合两个不同网格上的特征,我们提出了一个双域融合模块。该模块通过可微分极化变换层建立两个网格之间的对应关系,并在元素方面学习两个领域的特征重要性,以增强表达能力。最后,解码器将融合特征从低级聚合到高级并进行密集预测。我们在公共数据集ORIGA上验证DDNet的最新分割性能。根据分割掩模,我们估计了常用的青光眼临床措施,即垂直杯与椎间盘的比率。较低的杯盘比率估计误差表明了在青光眼筛查中的潜在应用。 |
| Uncovering convolutional neural network decisions for diagnosing multiple sclerosis on conventional MRI using layer-wise relevance propagation Authors Fabian Eitel, Emily Soehler, Judith Bellmann Strobl, Alexander U. Brandt, Klemens Ruprecht, Ren M. Giess, Joseph Kuchling, Susanna Asseyer, Martin Weygandt, John Dylan Haynes, Michael Scheel, Friedemann Paul, Kerstin Ritter 基于机器学习的成像诊断最近达到甚至取代了几个临床领域的临床专家水平。然而,受过训练的机器学习系统的分类决策通常是不透明的,是临床集成,错误跟踪或知识发现的主要障碍。在这项研究中,我们提出了一个透明的深度学习框架,依靠卷积神经网络CNNs和层次相关传播LRP来诊断多发性硬化症MS。 MS通常利用临床表现和常规磁共振成像MRI的组合来诊断,特别是T2加权图像中白质病变的发生和呈现。我们假设在幼稚预测模型中使用LRP将使我们能够发现训练有素的CNN用于决策的相关图像特征。由于MS中的成像标记已经很好地建立,这将使我们能够验证相应的CNN模型。首先,我们预先对来自阿尔茨海默氏病神经影像学倡议n 921的MRI数据进行CNN训练,之后专门研究CNN以区分MS患者和健康对照[147]。然后,使用LRP,我们为保持集中的每个主题生成热图,描绘了针对特定分类决策的体素明智相关性。得到的CNN模型在接收器工作特性曲线中产生87.04的平衡精度和96.08的曲线下面积。随后的LRP可视化显示CNN模型确实关注于个体病变,但还包括其他信息,例如病变位置,非病变白质或丘脑等灰质区域,这些是MS中建立的常规和高级MRI标记。我们得出结论,LRP和提议的框架有能力做出......的诊断决策。 |
| Cursive Multilingual Characters Recognition Based on Hard Geometric Features Authors Amjad Rehman, Majid Harouni, Tanzila Saba 阿拉伯语,波斯语,乌尔都语语言的多语言字符分割和识别的草书性质吸引了学术界和工业界的研究人员。然而,尽管经过几十年的研究,仍然多语言字符的分类准确性达不到标准。本文介绍了一种多语言字符分割和识别的自动化方法。所提出的方法基于其几何特征来探索角色。然而,由于不确定性和没有字典支持,很少有字符过分。为了扩展所提出的方法的生产率,BPN准备了草书多语言角色的无数分工重点。准备好的BPN分离基本分区表示有效的快速升级字符确认精度。为了合理检查,仅使用基准数据集。 |
| 4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks Authors Christopher Choy, JunYoung Gwak, Silvio Savarese 在许多机器人和VR AR应用中,3D视频是随时可用的输入源,连续的深度图像序列或LIDAR扫描。然而,这些3D视频通过2D convnets或3D感知算法逐帧处理。在这项工作中,我们提出了用于时空感知的4维卷积神经网络,可以使用高维卷积直接处理这样的3D视频。为此,我们采用稀疏张量并提出包含所有离散卷积的广义稀疏卷积。为了实现广义稀疏卷积,我们为稀疏张量创建了一个开源自动微分库,为高维卷积神经网络提供了广泛的功能。我们使用该库创建了4D空间时间卷积神经网络,并在各种3D语义分割基准上验证它们,并提出了用于3D视频感知的4D数据集。为了克服4D空间中的挑战,我们提出了混合核,广义稀疏卷积的特殊情况,以及在7D时空色度空间中强制时空一致性的三边静止条件随机场。实验上,我们证明了仅具有广义3D稀疏卷积的卷积神经网络可以大大超过2D或2D 3D混合方法。此外,我们表明,在3D视频上,4D空间时间卷积神经网络对噪声具有鲁棒性,优于3D卷积神经网络,并且在某些情况下比3D对应物更快。 |
| Targetless Rotational Auto-Calibration of Radar and Camera for Intelligent Transportation Systems Authors Christoph Sch ller, Maximilian Schnettler, Annkathrin Kr mmer, Gereon Hinz, Maida Bakovic, M ge G zet, Alois Knoll 大多数智能交通系统使用雷达传感器和摄像头的组合来实现稳健的车辆感知。由于不同的物理测量原理和交通雷达的高稀疏性,在系统操作期间以自动方式校准这些异构传感器类型是具有挑战性的。我们尽最大努力提出第一种用于自动旋转雷达相机校准的数据驱动方法,无需专用校准目标。我们的方法基于粗略和精细卷积神经网络。我们采用了一种提升灵感的训练算法,我们在粗网络的剩余误差上训练精细网络。由于没有结合雷达和相机测量的公共数据集,我们记录了我们自己的真实世界数据。我们证明了我们的方法能够实现精确和稳健的传感器配准,并展示其对不同传感器对准和视角的泛化能力。 |
| Cascaded Partial Decoder for Fast and Accurate Salient Object Detection Authors Zhe Wu, Li Su, Qingming Huang 现有技术的显着对象检测网络依赖于聚合预训练的卷积神经网络CNN的多级特征。与高级功能相比,低级功能对性能的贡献较小,但由于其较大的空间分辨率而需要更多的计算。在本文中,我们提出了一种新颖的级联部分解码器CPD框架,用于快速准确的显着对象检测。一方面,该框架构造了部分解码器,其丢弃较浅层的较大分辨率特征以用于加速。另一方面,我们观察到更深层的特征积分获得相对精确的显着图。因此,我们直接利用生成的显着图来细化骨干网的特性。该策略有效地抑制了特征中的干扰因素,并显着提高了它们的表示能力。在五个基准数据集上进行的实验表明,所提出的模型不仅实现了最先进的性能,而且比现有模型运行得更快。此外,所提出的框架进一步应用于改进现有的多级特征聚合模型,并显着提高其效率和准确性。 |
| A Theoretically Sound Upper Bound on the Triplet Loss for Improving the Efficiency of Deep Distance Metric Learning Authors Thanh Toan Do, Toan Tran, Ian Reid, Vijay Kumar, Tuan Hoang, Gustavo Carneiro 我们提出了一种基于三重态损失函数的优化来显着提高深度距离度量学习效率的方法。基于三元组丢失函数的朴素优化的这种训练过程的一个时期具有运行时复杂度O N 3,其中N是训练样本的数量。这种优化的扩展性很差,并且提出的解决这一高复杂性问题的最常见方法是基于对训练过程所需的三元组集进行子采样。在该领域中探索的另一种方法依赖于引入类质心的三重态损失的N的临时线性化,必须使用每个小批量的整个训练集来优化这种方法,这意味着这种方法的天真实现具有运行时间复杂性ON 2。这种复杂性问题通常通过差的但计算上便宜的近似质心优化方法来减轻。在本文中,我们首先提出了一个关于使用类质心线性化三重态损失的可靠理论,其中主要结论是我们的新线性损失代表了三重态损失的紧密上限。此外,基于上述理论,我们提出了一种不再需要质心优化步骤的训练算法,这意味着我们的方法是具有保证线性运行时复杂度的领域中的第一个。我们表明,使用所提出的上限的深度度量度量学习方法的训练比基于三胞胎的方法快得多,同时在基准数据集CUB 200 2011和CAR196上产生竞争性检索准确度结果。 |
| Out-of-Distribution Detection for Generalized Zero-Shot Action Recognition Authors Devraj Mandal, Sanath Narayan, Saikumar Dwivedi, Vikram Gupta, Shuaib Ahmed, Fahad Shahbaz Khan, Ling Shao 广义零射击动作识别是一个具有挑战性的问题,其任务是识别在训练阶段期间不可用的新动作类别,以及所看到的动作类别。现有方法受到学习分类器对所见行动类别的固有偏差的影响。因此,未见的类别样本被错误地归类为属于所见行动类别之一。在本文中,我们通过争论对广义零射击动作识别中的已知和看不见的动作类别进行单独处理来着手解决这个问题。我们引入了一个分布式检测器,用于确定视频功能是属于看见或看不见的动作类别。为了训练我们的分布检测器,使用在看到的动作类别特征上训练的生成对抗网络来合成用于看不见的动作类别的视频特征。据我们所知,我们是第一个提出基于GZSL框架的分布式检测器,用于视频中的动作识别。在三个动作识别数据集Olympic Sports,HMDB51和UCF101上进行实验。对于广义零射击动作识别,我们提出的方法优于基线f CLSWGAN,在这些数据集上分别具有7.0,3.4和4.9的分类精度的绝对增益。 |
| Examining the Capability of GANs to Replace Real Biomedical Images in Classification Models Training Authors Vassili Kovalev, Siarhei Kazlouski 在本文中,我们探索了生成人工生物医学图像的可能性,这些图像可以用作应用机器学习任务中真实图像数据集的替代品。我们专注于使用包括DCGAN和PGGAN在内的两个最新GAN架构生成逼真的胸部X射线图像以及淋巴结组织学图像。通过使用传统和深度学习方法解决的基准分类任务来检查使用人工图像而不是真实图像来训练机器学习模型的可能性。具体地,通过在模型训练阶段用合成图像替换真实图像并将预测结果与在实际图像数据上训练时获得的预测结果进行比较来进行比较。结果发现,对于深度学习模型,由这种训练数据替换引起的分类准确度的下降在2.2和3.5之间,对于诸如LBP随机森林的传统方法,在5.5和13.25之间。 |
| Global Hashing System for Fast Image Search Authors Dayong Tian, Dacheng Tao 哈希方法已被广泛研究用于大数据集中的快速近似最近邻搜索。大多数现有方法在较低维空间中使用二进制向量来表示通常是较高维度的实际向量的数据点。我们将散列过程分为两个步骤。首先将数据点嵌入低维空间,然后引入全局定位系统方法,但修改为二进制嵌入。我们设计了数据依赖和数据相关的方法,以便在适当的位置分配卫星。我们的方法基于在这两个步骤中找到信息损失之间的权衡。实验表明,我们的数据相关方法在100k到10M的不同大小的数据集中优于其他方法。通过结合代码矩阵的正交性,我们的数据独立和数据相关方法在较长位的实验中特别令人印象深刻。 |
| Coupled Learning for Facial Deblur Authors Dayong Tian, Dacheng Tao 面部图像中的模糊显着阻碍了识别方法的效率。然而,大多数现有的盲去卷积方法由于它们依赖于强边缘而不能产生令人满意的结果,强边缘在自然图像中是足够的而在面部图像中不是。在本文中,我们通过一组预定义的正交PSF的线性组合来表示点扩散函数PSF,并且类似地,估计的固有EI锐利面部图像由一组预定义的正交面部图像的线性组合来表示。在这样做时,PSF和EI估计被简化为发现两组线性组合系数,其由我们提出的耦合学习算法同时找到。为了使我们的方法对不同类型的模糊人脸图像具有鲁棒性,我们为测试图像生成若干候选PSF和EI,然后采用非盲去卷积方法通过那些候选PSF生成更多EI。最后,我们部署盲图像质量评估指标以自动选择最佳EI。对面部识别技术数据库,扩展的耶鲁人脸数据库B,CMU姿势,光照和表达PIE数据库以及人脸识别大挑战数据库2.0版进行了深入的实验,证明了所提出的方法有效地恢复了内在的锐利人脸图像,从而改善了表情识别的表现。 |
| An Efficient Approximate kNN Graph Method for Diffusion on Image Retrieval Authors Federico Magliani, Kevin McGuinness, Eva Mohedano, Andrea Prati 扩散在许多计算机视觉和人工智能项目中的应用已被证明可以提供出色的性能改进。该技术的主要瓶颈之一是由于图中节点之间的大量新连接导致kNN图大小的二次增长,导致计算时间长。已经提出了几种策略来解决这个问题,但没有一种策略是有效和有效的。基于LSH投影的我们的新技术获得了与扩散后的精确kNN图相同的性能,但是在十万个图像的数据集中,在更短的时间内大约快18倍。所提出的方法在几个公共图像数据集上得到验证并与其他现有技术进行了比较,包括Oxford5k,Paris6k和Oxford105k。 |
| Fully Automatic Segmentation of 3D Brain Ultrasound: Learning from Coarse Annotations Authors Julia Rackerseder, R diger G bl, Nassir Navab, Christoph Hennersperger 术中超声是神经外科中越来越重要的成像方式。然而,在过程期间与成像数据的手动交互(例如,选择地标或执行分割)是困难的并且可能是耗时的。然而,由于在大多数情况下需要注册其他成像模式,因此需要一些注释。我们提出了一种基于DeepVNet的分割方法,专门评估预训练与模拟超声扫描的集成,以改善自动分割并实现注册的全自动初始化。在这个视图中,我们表明,尽管有关粗糙和不完全半自动注释的训练,我们的方法能够捕获所需的表面结构,如纹状脑沟,纹理小脑幕和纹理镰刀脑。我们对公开的RESECT数据集执行五次交叉验证。仅在数据集上进行训练,我们分别报告0.49 pm 0.09和0.30 pm 0.07的Dice和Jaccard系数,以及0.78 pm 0.36 mm的平均距离。通过建议的预训练,我们计算出0.47 pm 0.10和0.31 pm 0.08的Dice和Jaccard系数,以及0.71 pm 0.38 mm的平均距离。定性评估表明,通过预训练,网络可以学习更好地概括,并提供与作为输入提供的不完整注释相比更精细和更完整的分段。 |
| Fooling automated surveillance cameras: adversarial patches to attack person detection Authors Simen Thys, Wiebe Van Ranst, Toon Goedem 在过去几年中,对机器学习模型的对抗性攻击越来越受到关注。通过仅对卷积神经网络的输入进行微妙的改变,可以使网络的输出摇摆以输出完全不同的结果。第一次攻击是通过稍微改变输入图像的像素值来欺骗分类器输出错误的类来实现的。其他方法已经尝试学习可以应用于对象以愚弄检测器和分类器的补丁。这些方法中的一些还表明这些攻击在现实世界中是可行的,即通过修改对象并用摄像机拍摄它。然而,所有这些方法都以几乎没有内部类别的类为目标。停止迹象。然后使用对象的已知结构在其上生成对抗性补丁。 |
| Tex2Shape: Detailed Full Human Body Geometry from a Single Image Authors Thiemo Alldieck, Gerard Pons Moll, Christian Theobalt, Marcus Magnor 我们提出了一种简单而有效的方法,仅从一张照片中推断出详细的完整人体形状。我们的模型可以以交互式帧速率推断包括面部,头发和衣服在内的全身形状,包括皱纹。即使在输入图像中遮挡的部分,结果也会显示细节。我们的主要想法是将形状回归转换为对齐图像到图像转换问题。我们方法的输入是从现成方法获得的可见区域的部分纹理图。从部分纹理,我们估计详细的法线和矢量位移图,可以应用于低分辨率光滑的身体模型,以添加细节和衣服。尽管纯粹使用合成数据进行训练,但我们的模型很好地概括了真实世界的照片。大量结果证明了我们方法的多功能性和稳健性。 |
| Real-Time Style Transfer With Strength Control Authors Victor Kitov 样式转移是以另一样式图像的样式呈现内容图像的问题。风格转移应用中一个自然而常见的实际任务是调整风格化的强度。 Gatys等人的算法。 2016通过改变内容和风格损失的加权因子来提供这种能力,但计算效率低下。 Johnson等人介绍的实时风格转移。 2016通过经过预先培训的变压器网络,可以实现任何图像的快速风格化。虽然速度很快,但这种架构无法持续调整风格强度。我们建议扩展实时样式传输,允许在推理时直接控制样式强度,仍然只需要一个变压器网络。我们进行定性和定量实验,证明所提出的方法能够进行平滑的样式强度控制,并消除原始实时样式转移方法中出现的某些样式伪影。与能够调整样式强度的替代实时样式传输算法进行比较,表明我们的方法使用更多细节再现样式。 |
| DDLSTM: Dual-Domain LSTM for Cross-Dataset Action Recognition Authors Toby Perrett, Dima Damen 卷积网络中的域对齐旨在了解有利于源和目标数据集的联合学习的层特定特征对齐的程度。虽然在卷积网络中越来越流行,但以前没有尝试在循环网络中实现域对齐。与空间特征类似,源域和目标域都可能表现出可以联合学习和对齐的时间依赖性。 |
| Learning a No-Reference Quality Assessment Model of Enhanced Images With Big Data Authors Ke Gu, Dacheng Tao, Junfei Qiao, Weisi Lin 在本文中,我们通过机器学习研究图像质量评估IQA和增强的问题。这个问题长期以来一直引起计算智能和图像处理领域的广泛关注,因为对于许多实际应用,例如,物体检测和识别,通常需要适当增强原始图像以提高视觉质量,例如能见度和对比度。实际上,适当的增强可以显着改善输入图像的质量,甚至比通常被认为具有最佳质量的原始捕获图像更好。在这项工作中,我们提出了两个最重要的贡献。第一个贡献是开发一个新的无参考NR IQA模型。给定一个图像,我们的质量测量首先通过分析对比度,清晰度,亮度等来提取17个特征,然后使用回归模块产生一定程度的视觉质量,该模块使用比大小更大的大数据训练样本学习相关图像数据集。九个数据集的实验结果验证了盲目标度的优越性和效率,与典型的现有技术完全,减少和无参考IQA方法相比。第二个贡献是基于质量优化建立稳健的图像增强框架。对于输入图像,通过所提出的NR IQA测量的指导,我们进行直方图修改以连续地将图像亮度和对比度校正到适当的水平。彻底的测试表明,我们的框架可以很好地增强自然图像,低对比度图像,低光图像和去噪图像。源代码将在发布时发布 |
| Unsupervised Open Domain Recognition by Semantic Discrepancy Minimization Authors Junbao Zhuo, Shuhui Wang, Shuhao Cui, Qingming Huang 我们解决了无监督的开放域识别UODR问题,其中标记的源域S中的类别仅是未标记的目标域T中的类别。任务是正确地对包括已知和未知类别的T中的所有样本进行分类。 UODR由于域差异而具有挑战性,当T中存在大量未知类别时,其变得更难以桥接。此外,由图CNN GCN传播的分类规则可能被未知类别分散并且缺乏泛化能力。为了测量S和T之间非对称标签空间的域差异,我们提出了语义引导匹配差异SGMD,它首先采用S和T之间的实例匹配,然后通过匹配实例之间的加权特征距离来测量差异。我们进一步设计了有限的平衡约束,以在已知和未知类别上实现更平衡的分类输出。我们开发了无监督开放域转移网络UODTN,它通过减少SGMD来共同学习骨干分类网络和GCN,实施有限平衡约束并最小化S. UODTN上的分类丢失,更好地保留语义结构并强化学习之间的一致性。域不变的视觉特征和语义嵌入。实验结果表明我们的方法在识别已知和未知类别的图像方面具有优势。 |
| Discriminative Online Learning for Fast Video Object Segmentation Authors Andreas Robinson, Felix J remo Lawin, Martin Danelljan, Fahad Shahbaz Khan, Michael Felsberg 我们解决了视频对象分割的极具挑战性的问题。仅给出初始掩码,任务是在后续帧中对目标进行分段。为了有效地处理外观变化和类似的背景对象,需要稳健的目标表示。先前的方法或者依赖于在第一帧上微调分割网络,或者采用生成外观模型。虽然部分成功,但这些方法经常遭受不切实际的低帧速率或不令人满意的鲁棒性。 |
| Client/Server Based Online Environment for Manual Segmentation of Medical Images Authors Daniel Wild, Maximilian Weber, Jan Egger 分割是分析和处理医学图像的关键步骤。由于医学成像中的低容错性,手动分割仍然是该领域中事实上的标准。此外,自动化分段过程的努力通常依赖于大量手动标记的数据。虽然支持手动分割的现有软件具有丰富的功能并提供准确的结果,但是设置它并使用它的必要时间可能会成为收集大型数据集的障碍。这项工作介绍了一个基于客户端服务器的在线环境,称为Studierfenster |
| Learning to Collocate Neural Modules for Image Captioning Authors Xu Yang, Hanwang Zhang, Jianfei Cai 我们不是从头开始逐字逐句地说我们的大脑很快就会在某个地方快速构建像文本一样的模式,然后填写详细的描述。为了使现有的编码器解码器图像捕获器像人类一样推理,我们提出了一种新的框架学习来配置神经模块CNM,以生成连接可视编码器和语言解码器的内部模式。与视觉Q A中广泛使用的神经模块网络不同,其中语言即问题是完全可观察的,用于字幕的CNM在生成语言时更具挑战性,因此是部分可观察的。为此,我们为CNM培训做了以下技术贡献1紧凑模块设计一个用于功能词,三个用于视觉内容词,例如名词,形容词和动词,2软模块融合和多步模块执行,证明视觉推理在部分观察中,3模块控制器的语言损失忠实于词性搭配,例如,形容词在名词之前。针对具有挑战性的MS COCO图像字幕基准的大量实验验证了CNM图像字幕的有效性。特别是,CNM在官方服务器上实现了最新技术127.9 CIDEr D的Karpathy分割和单一型号126.0 c40。 CNM对于少数训练样本也很稳健,例如,通过仅训练每个图像一个句子,与强基线相比,CNM可以将性能损失减半。 |
| Progressive Attention Memory Network for Movie Story Question Answering Authors Junyeong Kim, Minuk Ma, Kyungsu Kim, Sungjin Kim, Chang D. Yoo 本文提出了用于电影故事问答QA的渐进式注意记忆网络PAMN。电影故事QA与VQA在两个方面相比具有挑战性1确定与回答问题相关的时间部分是困难的,因为电影通常超过一小时,2它有视频和副标题,其中不同的问题需要不同的模态来推断答案。为了克服这些挑战,PAMN涉及三个主要特征1渐进式注意机制,它利用来自问题和答案的线索逐步删除记忆中不相关的时间部分,2动态模态融合,自适应地确定每种模态对回答当前问题的贡献,和3个信念校正答案方案,连续校正每个候选答案的预测分数。公开可用的基准数据集,MovieQA和TVQA的实验证明,每个功能都有助于我们的电影故事QA架构,PAMN,并提高性能,以实现最先进的结果。还提供了通过可视化PAMN的推理机制进行定性分析。 |
| Deep Optics for Monocular Depth Estimation and 3D Object Detection Authors Julie Chang, Gordon Wetzstein 深度估计和3D对象检测对于场景理解是至关重要的,但由于在图像捕获期间3D信息的丢失而对单个图像执行仍然具有挑战性。最近使用深度神经网络的模型已经改善了单眼深度估计性能,但是仍然难以预测绝对深度并且在标准数据集之外进行推广。在这里,我们将深度光学的范例,即光学和图像处理的端到端设计,引入单眼深度估计问题,使用编码的散焦模糊作为由神经网络解码的附加深度线索。我们评估了几种光学编码策略以及用于三个数据集的深度估计的端到端优化方案,包括NYU Depth v2和KITTI。我们发现优化的自由形状透镜设计可以产生最佳效果,但单透镜的色差也可以显着提高性能。我们构建了一个物理原型并验证色差可以改善现实世界结果的深度估计。此外,我们在KITTI数据集上训练物体检测网络,并显示针对深度估计优化的镜头也导致改善的3D物体检测性能。 |
| Road Crack Detection Using Deep Convolutional Neural Network and Adaptive Thresholding Authors Rui Fan, Mohammud Junaid Bocus, Yilong Zhu, Jianhao Jiao, Li Wang, Fulong Ma, Shanshan Cheng, Ming Liu 裂缝是最常见的道路窘迫之一,可能会造成道路安全隐患。通常,裂缝检测由经过认证的检查员或结构工程师执行。然而,这项任务耗时,主观且劳动强度大。在本文中,我们提出了一种基于深度学习和自适应图像分割的新型道路裂缝检测算法。首先,训练深度卷积神经网络以确定图像是否包含裂缝。然后使用双边滤波对包含裂缝的图像进行平滑处理,这极大地减少了噪声像素的数量。最后,我们利用自适应阈值法从路面提取裂缝。实验结果表明,我们的网络可以对图像进行99.92的精度分类,利用我们提出的阈值算法可以从图像中成功提取裂缝。 |
| Generative Model for Zero-Shot Sketch-Based Image Retrieval Authors Vinay Kumar Verma, Aakansha Mishra, Ashish Mishra, Piyush Rai 我们提出了基于草图的图像检索SBIR的概率模型,其中,在检索时,我们给出了在训练时不存在的新类的草图。现有的SBIR方法,大多数依赖于草图和图像之间的学习类明智对应,通常仅适用于先前看到的草图类,并且导致新类的检索性能差。为了解决这个问题,我们提出了一种生成模型,它可以学习生成图像,并以给定的新类草图为条件。这使我们能够将SBIR问题减少到标准图像到图像搜索问题。我们的模型基于基于逆自回归流的变分自动编码器,具有反馈机制以确保稳健的图像生成。我们在两个非常具有挑战性的数据集Sketchy和TU Berlin上评估我们的模型,并进行了新的列车测试分割。所提出的方法明显优于两个数据集上的各种基线。 |
| Material Segmentation of Multi-View Satellite Imagery Authors Matthew Purri, Jia Xue, Kristin Dana, Matthew Leotta, Dan Lipsa, Zhixin Li, Bo Xu, Jie Shan 材料识别方法使用图像上下文和局部线索进行像素分类。在许多情况下,只有一个图像可用于进行材料预测。在诸如mutliview立体声之类的应用中常规获取的图像序列可以提供显示像素级材料属性的下层反射率函数的采样。我们使用从SpaceNet Challenge卫星图像数据集生成的用于建筑材料分割和场景材料分割的两个数据集来研究多视图材料分割。在本文中,我们通过引入纹理反射残差编码来探索多角度反射信息的影响,该编码捕获我们的数据集中存在的多角度和多光谱信息。通过用预定义的密集采样反射函数的字典对稀疏采样反射函数进行差分来计算残差。我们提出的反射率残差特征在集成到像素和语义分割体系结构中时可以提高材料分割性能。在测试时,来自各个分段的预测通过softmax融合进行组合,并通过建立分段投票进行细化。我们使用所提出的材料分割管道展示了稳健且精确的像素分割结果。 |
| Do Lateral Views Help Automated Chest X-ray Predictions? Authors Hadrien Bertrand, Mohammad Hashir, Joseph Paul Cohen 胸部放射学中的大多数卷积神经网络仅使用额外的前后PA视图来进行预测。然而,已知侧视图有助于诊断某些疾病和病症。最近发布的PadChest数据集包含成对的PA和侧视图,允许我们在提供横向x射线视图而不是前额后PA视图时,研究神经网络的性能改善的疾病和状况。使用简单的DenseNet模型,我们发现使用横向视图可以增加数据中56个标签中8个的AUC,并且可以获得与21个标签的PA视图相同的性能。我们发现共同使用PA和侧面观点并不能简单地导致性能提高,但建议进一步调查。 |
| Graph based Dynamic Segmentation of Generic Objects in 3D Authors Xiao Lin, Josep R. Casas, Montse Pard s 我们提出了一种新的RBGD流数据3D分割方法,用于处理频繁对象交互的通用场景中的3D对象分割任务。它主要有两个方面,一般是通用的,不需要初始化,提出了场景点云的新颖树形结构表示。然后,连接组件拆分和合并的动态管理机制利用树结构表示。 |
| Adaptive Hierarchical Down-Sampling for Point Cloud Classification Authors Ehsan Nezhadarya, Ehsan Taghavi, Bingbing Liu, Jun Luo 虽然最近提出了几个类似于卷积运算符的运算符用于从点云中提取特征,但是在深度神经网络中对无序点云进行下采样尚未得到严格研究。现有方法对点进行下采样,无论它们对输出的重要性如何。因此,可以去除点云中的一些重要点,而可以将较少有价值的点传递到下一层。相比之下,自适应下采样方法通过考虑每个点的重要性来对点进行采样,这些点根据应用,任务和训练数据而变化。在本文中,我们提出了一种基于置换不变学习的自适应下采样层,称为临界点层CPL,它可以减少无序点云中的点数,同时保留重要点。与使用k NN搜索算法找到相邻点的大多数基于图的点云下采样方法不同,CPL是一种全局下采样方法,使其在计算上非常有效。所提出的层可以与任何基于图的点云卷积层一起使用以形成卷积神经网络,在本文中称为CP Net。我们引入了用于3D对象分类的CP Net,它在基于点云的方法中实现了ModelNet 40数据集的最佳精度,从而验证了CPL的有效性。 |
| Dynamic Gesture Recognition by Using CNNs and Star RGB: a Temporal Information Condensation Authors Clebeson Canuto dos Santos, Jorge Leonid Aching Samatelo, Raquel Frizera Vassallo 随着技术的进步,机器越来越多地存在于人们的日常生活中。因此,越来越多的努力来开发提供直观交互方式的界面,例如动态手势。目前,最常见的趋势是使用多模态数据作为深度和骨架信息来尝试识别动态手势。然而,一旦在几乎每个公共场所都可以找到RGB相机,只使用颜色信息会更有趣,并且可以用于手势识别而无需安装其他设备。这种方法的主要问题是难以仅使用颜色来表示时空信息。考虑到这一点,我们提出了一种名为Star RGB的技术,能够将包含动态手势的视频片段描述为RGB图像。然后将该图像传递给由两个Resnet CNN(一个软注意集合)和多层感知器形成的分类器,该多层感知器返回预测的类标签,该标签指示输入视频属于哪种类型的手势。使用Montalbano和GRIT数据集进行实验。在Montalbano数据集上,所提出的方法达到了94.58的准确度,该结果使用该数据集达到了现有技术水平,仅考虑颜色信息。在GRIT数据集上,我们的提案实现了超过98的准确度,召回率,精确度和F1分数,超过了6个以上的参考方法。 |
| Exploring Uncertainty Measures for Image-Caption Embedding-and-Retrieval Task Authors Kenta Hama, Takashi Matsubara, Kuniaki Uehara, Jianfei Cai 随着黑盒机器学习算法,特别是深度神经网络DNN的广泛发展,对可靠性评估的实际需求正在迅速增加。基于贝叶斯深度学习知道它不知道的概念,DNN输出的不确定性已经被研究作为分类和回归任务的可靠性度量。然而,在图像标题检索任务中,众所周知的样本并不总是容易检索样本。本研究调查了图像标题嵌入和检索系统的两个方面。一方面,我们通过将图像标题嵌入视为回归任务来量化特征不确定性,并将其用于模型平均,这可以提高检索性能。另一方面,我们通过将检索视为分类任务来进一步量化后验不确定性,并将其用作可靠性度量,通过拒绝不确定查询可以极大地提高检索性能。使用不同的数据集MS COCO和Flickr30k,不同的深度学习架构丢失和批量归一化以及不同的相似性函数观察到两种不确定性度量的一致性能。 |
| QANet - Quality Assurance Network for Microscopy Cell Segmentation Authors Assaf Arbelle, Eliav Elul, Tammy Riklin Raviv 用于自动图像分割的工具和方法正在快速发展,每种工具和方法都有其自身的优点和缺点。虽然这些方法设计得尽可能通用,但无法保证它们在新数据上的性能。方法之间的选择通常基于基准性能,而基准测试中的数据可能与用户的数据明显不同。 |
| Few-Shot Learning with Localization in Realistic Settings Authors Davis Wertheimer, Bharath Hariharan 传统的识别方法通常需要大型的,人工平衡的训练课程,而很少有射击学习方法在人工小型训练课程中进行测试。与两种极端情况相反,现实世界识别问题表现出严重的尾类分布,杂乱的场景以及粗粒度和细粒度级别区别的混合。我们表明,基于新的meta iNat基准测试,针对少数镜头学习而设计的先前方法在这些具有挑战性的条件下无法开箱即用。我们引入了三个参数自由改进,一个更好的训练程序,基于适应交叉验证到元学习,b新颖的架构,使用有限的边界框注释在分类之前定位对象,以及c基于双线性池的特征空间的简单参数自由扩展。总之,这些改进使meta iNat上的最新模型的准确性翻倍,同时推广到先前的基准,复杂的神经架构和具有实质域移位的设置。 |
| New method for shape recognition based on dynamic programming Authors Noreddine Gherabi, Mohamed Bahaj 在本文中,我们提出了一种基于动态规划的形状识别新方法。首先,每个形状轮廓由一组点表示。在两个形状之间的对齐和匹配之后,形状的轮廓根据N个角度和M个径向扇区被分成部分,每个扇区包含轮廓的一部分,该部分在拐点处被分成凸部和凹部,并且提取关于部分的信息以便为轮廓形状提供语义内容,然后将该信息编码并转换成符号串。最后,我们找到两个完整字符串的最佳对齐并计算最佳相似成本。该算法已在大量形状数据库和真实图像MPEG 7,自然轮廓数据库上进行了测试。 |
| Machine Vision for Natural Gas Methane Emissions Detection Using an Infrared Camera Authors Jingfan Wang, Lyne P. Tchapmi, Arvind P. Ravikumara, Mike McGuire, Clay S. Bell, Daniel Zimmerle, Silvio Savarese, Adam R. Brandt 减少天然气甲烷排放至关重要,这可能会抵消用煤气取代煤炭的气候效益。光学气体成像OGI是一种广泛使用的检测甲烷泄漏的方法,但是劳动强度大,无法在没有操作员判断的情况下提供泄漏检测结果。在本文中,我们开发了一种基于OGI的泄漏检测的计算机视觉方法,使用卷积神经网络CNN训练甲烷泄漏图像以实现自动检测。首先,我们从不同的泄漏设备收集1M M标记视频的甲烷泄漏,用于构建CNN模型,覆盖范围广泛的泄漏尺寸5.3 2051.6 gCH4 h,成像距离4.6 15.6 m。其次,我们研究了不同的背景扣除方法,以提取前景中的甲烷羽流。第三,我们然后测试三个CNN模型变体,统称为GasNet,以检测在其他泄漏设备上拍摄的视频中的羽流。我们通过将GasNet与使用基于光流的变化检测算法的基线方法进行比较来评估GasNet执行泄漏检测的能力。我们探索结果对CNN结构的敏感性,其中中等复杂度变体在距离上表现最佳。我们发现检测精度可高达99,对于所有泄漏尺寸和成像距离的情况,整体检测精度可超过95。对于大型泄漏,二元检测精度超过97,710 gCH4 h紧密成像5 7 m。在距离为5 10 m的较近成像距离处,基于CNN的模型在所有泄漏尺寸上具有大于94的精度。在13 16 m的最远距离处,性能迅速下降,但它可以达到95以上的准确度,以检测950 gCH4 h的大泄漏。基于GasNet的计算机视觉方法可以部署在OGI调查中,以便在现实世界中以高检测精度自动警惕甲烷泄漏检测。 |
| Co-regularized Multi-view Sparse Reconstruction Embedding for Dimension Reduction Authors Huibing Wang, Jinjia Peng, Xianping Fu 随着信息技术的发展,我们目睹了一个数据爆炸的时代,它产生了大量充满冗余信息的数据。由于降维是将高维数据嵌入低维子空间以避免冗余信息的重要工具,因此它吸引了全世界研究人员的兴趣。然而,面对来自多个视图的特征,大多数降维方法难以完全理解多视图特征并且集成来自这些特征的兼容和补充信息以直接构造低维子空间。此外,大多数多视图降维方法不能处理具有高维度的非线性空间的特征。因此,如何构建能够处理来自高维非线性空间的多视图特征的多视图降维方法是至关重要的,但具有挑战性。为了解决这个问题,本文提出了一种新的方法,即Co正则化多视图稀疏重构嵌入CMSRE。通过利用多视图稀疏重建的相关性,CMSRE能够从多个视图中学习非线性流形的局部稀疏结构,并为它们构造有意义的低维表示。由于提出的协规化方案,CMSRE尽可能保留来自多个视图的稀疏重建的相关性。此外,稀疏表示在每个单个视图的特征之间产生更有意义的相关性,这有助于CMSRE获得更好的性能。基于文档分类,人脸识别和图像检索的应用的各种评估可以证明所提出的方法在多视图维度减少方面的有效性。 |
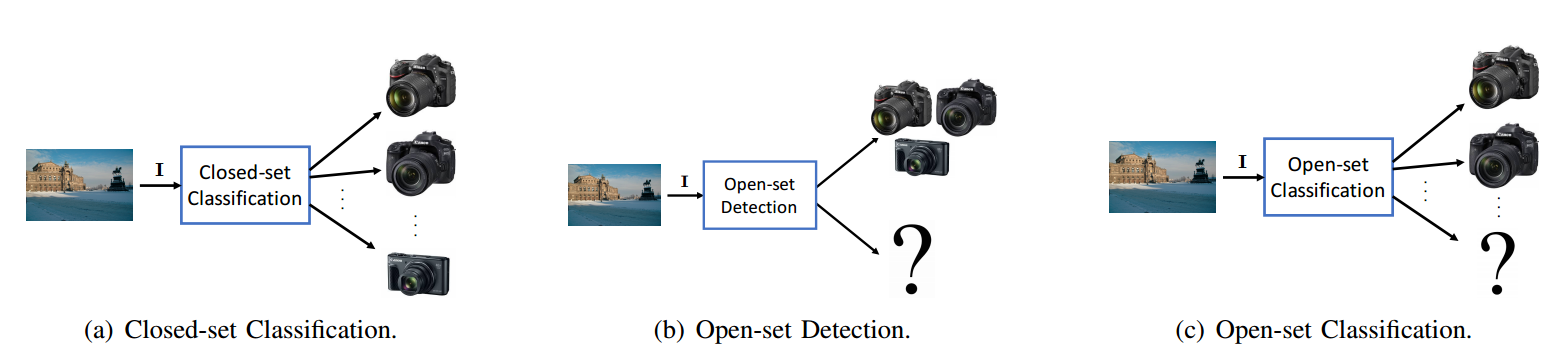
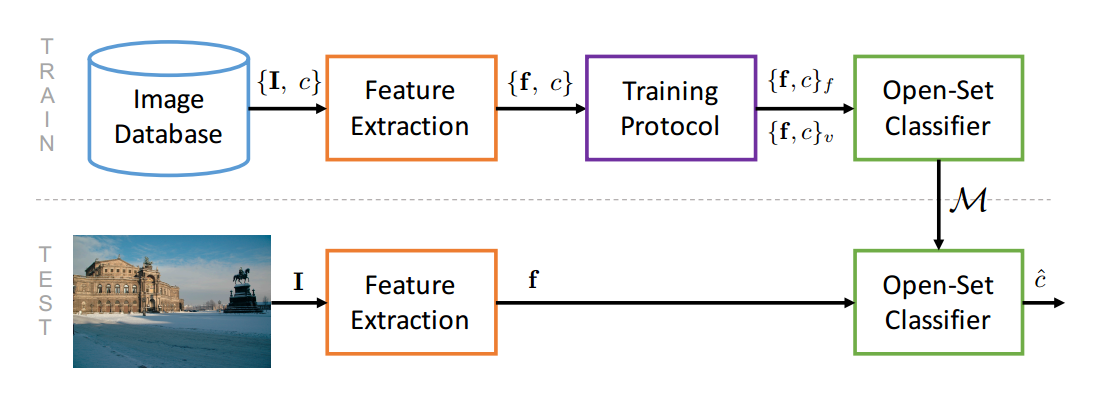
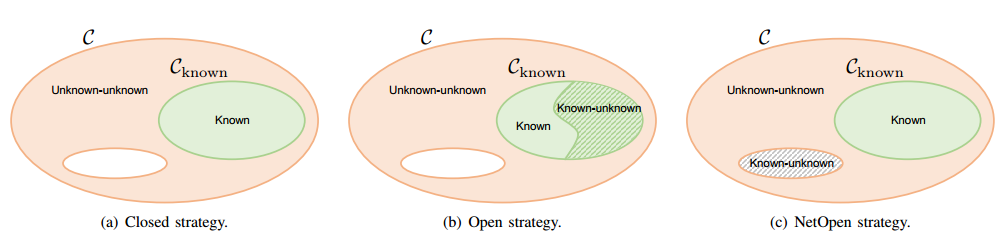
| An In-Depth Study on Open-Set Camera Model Identification Authors Pedro Ribeiro Mendes J nior, Luca Bondi, Paolo Bestagini, Stefano Tubaro, Anderson Rocha 相机型号识别是指将图片链接到用于拍摄它的相机型号的问题。由于这可能是不同法医应用中的一个促成因素,以挑出可能的嫌疑人,例如,检测虐待儿童或恐怖主义宣传材料的作者,在文献中已经开发了许多精确的相机模型归属方法。然而,它们的主要缺点之一是问题的典型闭集假设。这意味着调查的照片总是被分配给在调查期间存在的一组已知的照相机模型中,即训练时间,并且在实际测试期间图像可以来自完全不相关的照相机模型的事实通常被忽略。在现实条件下,不可能假设所分析的每张图片都属于可用的相机型号之一。为了解决这个问题,在本文中,我们首次深入研究了在开集方案中解决相机模型识别问题的可能性。鉴于照片,我们的目标是检测它是来自一个已知的相关模型或来自未知设备。我们比较了不同的特征提取算法和分类器,专门针对开放集识别。我们还评估了可以与任何开集分类器一起应用的可能的开放式训练协议。更具体地说,我们评估一种针对具有深层特征的开放式分类器的训练协议。我们观察到这些训练协议的更简单版本与需要额外数据的结果类似的结果起作用,这在许多采用深度特征的应用中是有用的。对独立数据集进行彻底测试表明,有可能利用最近提出的卷积神经网络作为特征提取器与经过适当训练的开集分类器配对... |
| Tensor Sparse PCA and Face Recognition: A Novel Approach Authors Loc Hoang Tran, Linh Hoang Tran 人脸识别是机器学习和模式识别研究领域的重要领域。它在军事,金融,公共安全方面有很多应用,仅举几例。在本文中,将提出张量稀疏PCA与最近邻法和核岭回归方法的组合,并将其应用于人脸数据集。实验结果表明,张量稀疏PCA与任何分类系统的结合并不总能达到最佳的精度性能指标。然而,稀疏PCA方法和一个特定分类系统的组合的准确性总是优于PCA方法和一个特定分类系统的组合的准确性,并且总是优于分类系统本身的准确性。 |
| Learning 2D to 3D Lifting for Object Detection in 3D for Autonomous Vehicles Authors Siddharth Srivastava, Frederic Jurie, Gaurav Sharma 我们在自动驾驶场景中解决了2D单眼图像的3D物体检测问题。我们建议使用学习的神经网络将2D图像提升为3D表示,并利用直接在3D上工作的现有网络来执行3D对象检测和定位。我们表明,通过精心设计的训练机制和自动选择最小噪声数据,这种方法不仅可行,而且比从物理传感器获取的实际3D输入的许多方法提供更高的结果。在具有挑战性的KITTI基准测试中,我们展示了我们的2D到3D提升方法优于许多最近竞争的3D网络,同时显着优于先前的单眼图像3D检测技术。我们还表明,在生成的3D图像上训练的网络输出与在真实3D图像上训练的网络输出的后期融合提高了性能。我们发现结果非常有趣,并认为这种方法可以作为高昂可靠的备份,以防昂贵的3D传感器出现故障,如果不是潜在地使它们变得多余,至少在低人身伤害风险的情况下自主导航场景如仓库自动化。 |
| Performance Evalution of 3D Keypoint Detectors and Descriptors for Plants Health Classification Authors Shiva Azimi, Brejesh lall, Tapan K. Gandhi 基于成像技术的植物表型组学可用于监测植物和作物的健康和疾病。将3D数据用于植物表型组学是最近的现象。然而,由于3D点云包含的信息多于植物图像,因此在本文中,我们比较了植物生长阶段的不同关键点检测器和局部特征描述符组合的性能,以及基于植物3D点云的生长条件分类。我们还实现了一种修改形式的3D SIFT描述符,它对旋转不变,并且在计算上不如现有文献中报道的大多数3D SIFT描述符强烈。根据分类准确度评估性能,结果以准确度表表示。我们发现ISS SHOT和SIFT SIFT组合始终表现更好,而Fisher Vector FV是一种比线性聚合VLAD矢量更好的编码器。它可以作为一种更好的方式。 |
| MultiNet++: Multi-Stream Feature Aggregation and Geometric Loss Strategy for Multi-Task Learning Authors Sumanth Chennupati, Ganesh Sistu, Senthil Yogamani, Samir A Rawashdeh 多任务学习通常用于自动驾驶以解决各种视觉感知任务。它在性能和计算复杂性方面提供了显着的优势。当前关于多任务学习网络的工作集中于处理单个输入图像,并且没有已知的处理图像序列的多任务学习的实现。在这项工作中,我们提出了一个多流多任务网络,以利用视频序列中前面帧的特征表示来进行分割,深度和运动的联合学习。共享当前和先前编码器的权重,以便可以利用在前一帧中计算的特征而无需额外的计算。此外,我们建议使用任务损失的几何平均值作为任务损失加权平均值的更好替代方案。所提出的损失函数有助于更好地处理不同任务的收敛速度的差异。 KITTI,Cityscapes和SYNTHIA数据集的实验结果表明,所提出的策略优于各种现有的多任务学习解决方案。 |
| Semantic Adversarial Attacks: Parametric Transformations That Fool Deep Classifiers Authors Ameya Joshi, Amitangshu Mukherjee, Soumik Sarkar, Chinmay Hegde 已经证明,深度神经网络对于具有不可察觉的扰动而破坏的对抗性输入图像表现出有趣的脆弱性。然而,大多数对抗性攻击都假设对图像像素空间进行全局细粒度控制。在本文中,我们考虑一个不同的设置,如果对手只能改变输入图像的特定属性会发生什么。这会产生可能明显不同的输入,但仍然看起来很自然,足以欺骗分类器。我们提出了一种新方法,通过优化参数条件生成模型的范围空间上的特定对抗性损失来生成这种语义对抗性示例。我们演示了对在面部图像上训练的二元分类器的攻击的实现,并且表明存在这种自然的语义对抗性示例。我们评估攻击对合成和真实数据的有效性,并提供与现有攻击方法的详细比较。我们用理论界限补充我们的实证结果,证明存在这种参数对抗性的例子。 |
| Machine Vision Guided 3D Medical Image Compression for Efficient Transmission and Accurate Segmentation in the Clouds Authors Zihao Liu, Xiaowei Xu, Tao Liu, Qi Liu, Yanzhi Wang, Yiyu Shi, Wujie Wen, Meiping Huang, Haiyun Yuan, Jian Zhuang 基于云的医学图像分析最近变得流行,这是由于基于各种深度神经网络DNN的框架的高计算复杂性以及需要处理的越来越大量的医学图像。已经证明,对于医学图像,从局部到云的传输比云本身的计算要昂贵得多。为此,3D图像压缩技术已被广泛应用于减少数据流量。然而,大多数现有的图像压缩技术是围绕人类视觉开发的,即,它们被设计成最小化人眼可以感知的失真。在本文中,我们将使用基于深度学习的医学图像分割作为载体,并有趣地证明,机器和人类对压缩质量的看法不同。压缩的医学图像质量好w.r.t.人类视觉可能导致较差的分割准确性。然后,我们设计了一个面向机器视觉的3D图像压缩框架,专门用于使用DNN进行分割。我们的方法自动提取并保留对分割最重要的图像特征。利用HVSMR 2016挑战数据集对广泛采用的分割框架进行的综合实验表明,与现有的JPEG 2000方法相比,我们的方法可以在相同的分割精度下实现更高的分割精度,或者在相同的分割精度下获得更好的压缩率。据作者所知,这是第一个用于云中分割的机器视觉引导医学图像压缩框架。 |
| Meta-learning Convolutional Neural Architectures for Multi-target Concrete Defect Classification with the COncrete DEfect BRidge IMage Dataset Authors Martin Mundt, Sagnik Majumder, Sreenivas Murali, Panagiotis Panetsos, Visvanathan Ramesh 识别混凝土基础设施中的缺陷,尤其是桥梁中的缺陷,是评估结构完整性的关键的第一步,这是一项代价高昂且耗时的工作。混凝土材料外观的巨大变化,不断变化的照明和天气条件,各种可能的表面标记以及不同类型的缺陷重叠的可能性使其成为具有挑战性的现实世界任务。在这项工作中,我们介绍了新的COncrete DEfect BRidge IMage数据集CODEBRIM,用于五种常见混凝土缺陷的多目标分类。我们研究和比较两种基于强化学习的元学习方法,MetaQNN和有效的神经结构搜索,以找到适合这种具有挑战性的多类多目标任务的卷积神经网络架构。我们表明,与我们的应用背景下评估的文献中的流行神经架构相比,学习架构除了产生更好的多目标精度之外还具有更少的总体参数。 |
| Bilinear Faster RCNN with ELA for Image Tampering Detection Authors Robin Elizabeth Yancey 随着技术进步导致图像篡改机制的增加,我们的欺诈检测方法必须继续升级以适应其复杂程度。当前方法的一个问题是它们需要伪造方法的先验知识,以便确定从图像中提取哪些特征以定位感兴趣区域。当机器学习算法用于学习从大量各种图像类型中篡改的不同类型时,通过足够大的数据库,我们可以通过对每个图像的整个图像特征映射进行训练来轻松地对哪些图像进行篡改进行分类,但我们仍然是留下了要训练哪些特征以及如何定位操纵的问题。为了解决这个问题,最近已经将诸如RPN区域提议网络与CNN组合的更快RCNN的对象检测网络适用于欺诈检测,其利用它们为感兴趣对象提出边界框以定位篡改工件的能力。在这项工作中,开发的现有双线性Faster RCNN模型将使用具有ELA错误级别分析JPEG压缩级别掩码输入的第二个流进行修改。 |
| Is deep learning a good choice for image segmentation? Authors Zhenzhou Wang 深度学习作为一种离散的非线性映射函数,作为一种强大的分类工具取得了巨大的成功。但是,它在很多领域都被夸大了。此评论将图像分割作为典型的文件来证明这一观点。首先,深度学习并非无所不能。它仅生成预测图并依赖于其他分割方法来完成分割任务。其次,深度学习的表现与输出的数量成反比。因此,除非图像的分辨率非常小,否则深度学习不是图像分割的良好选择。 |
| Variational Prototyping-Encoder: One-Shot Learning with Prototypical Images Authors Junsik Kim, Tae Hyun Oh, Seokju Lee, Fei Pan, In So Kweon 在日常生活中,由于其超越语言边界的直观表达,图形符号(例如交通标志和品牌标识)在我们周围无处不在。我们通过一次性分类处理开放式图形符号识别问题,其中原型图像作为每个小说类的单个训练示例。我们采用一种方法来学习用于新任务的通用嵌入空间。我们提出了一种称为变分原型编码器VPE的新方法,该方法将现实世界输入图像中的图像转换任务学习为相应的原型图像作为元任务。因此,VPE学习图像相似性以及原型概念,这与广泛使用的基于度量学习的方法不同。我们对不同数据集的实验表明,所提出的VPE对于基于单击方法的竞争度量学习表现良好。此外,我们的定性分析表明,我们的元任务会产生适合于看不见的数据表示的有效嵌入空间。 |
| LCC: Learning to Customize and Combine Neural Networks for Few-Shot Learning Authors Yaoyao Liu, Qianru Sun, An An Liu, Yuting Su, Bernt Schiele, Tat Seng Chua 元学习已被证明是少数镜头学习的有效策略。关键的想法是利用大量类似的少数镜头任务,以便学习如何最好地启动单个基础学习者进行新颖的少数镜头任务。虽然元学习如何初始化基础学习器已经显示出有希望的结果,但众所周知,诸如学习速率和正则化项的权重之类的超参数设置对于实现最佳性能是重要的。因此,我们建议也学习这些超参数,并实际上学习时间和层次变化方案,以便在新任务上学习基础学习者。此外,我们建议不仅要学习单个基础学习者,还要学习几个基础学习者的集合,以获得更强大的结果。虽然学习者的合奏已经证明可以提高各种环境中的表现,但由于训练样本的数量有限,这对于少数镜头学习任务来说是具有挑战性的。因此,我们的方法还旨在学习如何有效地结合几个基础学习者。我们在两个具有挑战性的基准测试miniImageNet和Fewshot CIFAR100 FC100上进行了大量的实验并报告了五类少数镜头识别任务的最佳性能。 |
| Image Resizing by Reconstruction from Deep Features Authors Moab Arar, Dov Danon, Daniel Cohen Or, Ariel Shamir 传统的图像大小调整方法通常在像素空间中工作并使用各种显着性度量。挑战是在尝试保留重要内容的同时调整图像形状。在本文中,我们在特征空间中执行图像大小调整,其中神经网络的深层包含丰富的重要语义信息。我们直接调整从预训练的分类网络中提取的图像特征图,并使用基于神经网络的优化来重建调整大小的图像。这种新颖的方法利用网络的分层编码,特别是其更深层的高级辨别力,识别语义对象和区域并允许维持其纵横比。我们使用深度特征重建减少了图像空间大小调整操作符引入的伪像。我们在基准测试中评估我们的方法,与替代方法进行比较,并展示其在挑战图像上的强度。 |
| DeepAtlas: Joint Semi-Supervised Learning of Image Registration and Segmentation Authors Zhenlin Xu, Marc Niethammer 深度卷积神经网络CNN是用于语义图像分割的现有技术,但通常需要许多标记的训练样本。获得用于监督训练的医学图像的3D分割是困难且劳动密集的。由于经典的联合分割和登记方法的推动,我们提出了一个深度学习框架,共同学习网络进行图像配准和图像分割。与先前关于深度无监督图像配准的工作相比,其显示了通过图像分割的弱监督的益处,我们的方法可以在可用时使用现有分割并且通过分割网络计算它们,从而提供相同的配准益处。相反,细分网络培训受益于注册,这实质上提供了一种实际形式的数据增强。膝盖和脑部3D磁共振MR图像的实验表明,我们的方法在独立训练的网络上实现了分割和配准精度的大幅度同步改进,并且允许训练具有非常有限的训练数据的高质量模型。具体而言,在仅具有一个手动标记图像的一次性场景中,我们的方法分别在膝盖和脑图像上将无人监督登记网络上的Dice分数增加2.7和1.8。 |
| Online Adaptation through Meta-Learning for Stereo Depth Estimation Authors Zhenyu Zhang, St phane Lathuili re, Andrea Pilzer, Nicu Sebe, Elisa Ricci, Jian Yang 在这项工作中,我们解决了立体深度估计的在线自适应问题,其中包括不断地使深度网络适应在不同于源训练集的环境中记录的目标视频。为了解决这个问题,我们提出了一个新的在线元学习模型与适应OMLA。我们的提案基于两个主要贡献。首先,为了减少源和目标特征分布之间的域移位,我们引入了从批量标准化得到的在线特征对齐程序。其次,我们设计了一种元学习方法,利用特征对齐在在线学习环境中实现更快的收敛。此外,我们提出了一种元预训练算法,以便在源数据集上获得初始网络权重,从而有助于对未来数据流进行适应。在实验上,我们展示了OMLA和meta预训练helpthe模型能够更快地适应新环境。我们的建议是在完善的KITTI数据集上进行评估的,我们在这里展示了我们的在线方法与批量设置中训练的艺术算法的竞争力。 |
| A large-scale field test on word-image classification in large historical document collections using a traditional and two deep-learning methods Authors Lambert Schomaker 本技术报告描述了对300多种不同手写历史手稿的大量集合中的单词图像分类的实际现场测试,其中160万个独特的标记图像和超过1100万个图像用于测试。结果表明,几项深度学习测试完全失败,平均准确度为83。在用于分类的一个热编码中具有超过1000个输出单位词汇词的测试中,性能急剧下降到几乎为零的准确度,即使具有适当大小的前决赛,即倒数第二层150单位。传统的特征方法BOVW在类的数量上显示一致的性能,训练样本的数量意味着准确度87。对于每本书,在Inception V3网络的最后一层输出上使用最近均值的附加测试,仅产生平庸的结果意味着准确度49,但对大量类别不敏感。值得注意的是,这个实验只能在基于传统方法收获的标签的基础上进行,该方法已经从每个类别的单个标记图像开始工作。预计失败的深度学习测试的性能可以修复,但仅基于人工手工制作的网络架构和超参数。当考虑到失败的有问题的书籍时,端到端的CNN训练产生大约95准确度。这个平均值由大量汉字主导,其他剧本风格的表现较低。 |
| 2D Car Detection in Radar Data with PointNets Authors Andreas Danzer, Thomas Griebel, Martin Bach, Klaus Dietmayer 对于许多自动驾驶功能,高度准确的车辆环境感知是至关重要的先决条件。现代高分辨率雷达传感器为每个物体生成多个雷达目标,这使得这些传感器特别适合于2D物体检测任务。这项工作提出了一种仅使用PointNets根据稀疏雷达数据检测对象假设的方法。在文献中,到目前为止仅呈现了方法,其执行对象的对象分类或边界框估计。相反,该方法使用单个雷达传感器便于分类以及对象的边界框估计。为此,PointNets针对使用分割执行2D对象分类的雷达数据和2D边界框回归进行调整,以便估计amodal边界框。使用由各种逼真的驾驶操纵组成的自动创建的数据集来评估算法。结果表明使用PointNets在高分辨率雷达数据中物体检测的巨大潜力。 |
| SCE: A manifold regularized set-covering method for data partitioning Authors Xuelong Li, Quanmao Lu, Yongsheng Dong, Dacheng Tao 聚类分析在数据分析中起着非常重要的作用。近年来,作为聚类分析工具的聚类集合因其稳健性,稳定性和准确性而备受关注。已经做了许多努力来将不同的初始聚类结果组合到具有更好性能的单个聚类解决方案中。但是,他们在执行集群集合时忽略了原始数据的结构信息。在本文中,我们提出了一种用于数据划分的结构聚类集合SCE算法,该算法被公式化为集合覆盖问题。特别地,我们构造拉普拉斯正则化目标函数以捕获聚类之间的结构信息。此外,考虑到初始聚类结果中潜在的判别信息的重要性,我们在我们提出的目标函数中添加了一个判别约束。最后,我们验证了SCE算法在合成和真实数据集上的性能。实验结果表明了我们提出的方法SCE算法的有效性。 |
| Neural Painters: A learned differentiable constraint for generating brushstroke paintings Authors Reiichiro Nakano 我们探索神经画家,这是一种从真正的非微分和非确定性绘画程序中学习的笔触的生成模型。我们表明,当训练一个代理人使用笔触绘制图像时,使用可区分的神经画家会导致更快的收敛。我们提出了一种方法,用于在重建数字时鼓励该代理遵循类似人的笔画。我们还探讨了使用神经画家作为可区分的图像参数化。通过直接优化笔触以激活预先训练的卷积网络中的神经元,我们可以直接可视化ImageNet类别并生成每个类的理想绘画。最后,我们提出了一种称为内在风格转移的新概念。通过最小化来自神经风格转移的内容损失,我们允许艺术媒介(在这种情况下是笔触)自然地决定所产生的风格。 |
| Fast object detection in compressed JPEG Images Authors Benjamin Deguerre, Cl ment Chatelain, Gilles Gasso 静止图像中的物体检测在过去几年中引起了很多关注,随着深度学习的出现,许多工业应用已经实现了令人印象深刻的性能。大多数这些深度学习模型依靠RGB图像来定位和识别图像中的对象。然而,在某些应用场景中,图像被压缩以节省存储空间或快速传输。因此,为了应用上述深度模型,必须进行耗时的图像解压缩步骤。为了缓解这一缺点,我们提出了一种快速深度体系结构,用于JPEG图像中的对象检测,这是最普遍的压缩格式之一。我们训练神经网络以基于从JPEG压缩算法发出的块状DCT离散余弦变换系数来检测对象。我们通过用一个专用于处理DCT输入的卷积层替换其第一层来修改众所周知的Single Shot multibox Detector SSD。对包含道路交通监控图像的PASCAL VOC和工业数据集的实验评估表明,该模型比普通SSD快2倍,具有很好的检测性能。据我们所知,本文是第一个解决压缩JPEG图像检测问题的论文。 |
| Deep Parametric Shape Predictions using Distance Fields Authors Dmitriy Smirnov, Matthew Fisher, Vladimir G. Kim, Richard Zhang, Justin Solomon 图形和视觉中的许多任务需要用于将形状转换为具有稀疏参数集的表示的机器,这些表示便于渲染,编辑和存储。然而,当源数据有噪声或模糊时,艺术家和工程师经常手动构建这样的表示,这是一个繁琐且可能耗时的过程。虽然深度学习的进步已成功应用于噪声几何数据,但迄今为止生成参数形状的任务对于这些方法来说是困难的。因此,我们提出了一种使用深度学习来预测参数形状基元的新框架。我们使用距离场在控制点之类的形状参数和栅格网格上的输入数据之间进行转换。我们展示了对2D和3D任务的功效,包括字体矢量化和表面抽象。 |
| Towards VQA Models that can Read Authors Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, Marcus Rohrbach 研究表明,视障用户对周围环境图像提出的主要问题包括阅读图像中的文字。但今天的VQA模型无法阅读我们的论文迈出了解决这一问题的第一步。首先,我们引入一个新的TextVQA数据集,以促进这一重要问题的进展。现有数据集或者具有关于文本的一小部分问题,例如VQA数据集,或者太小,例如VizWiz数据集。 TextVQA在28,408张图片中包含45,336个问题,需要推理文本才能回答。其次,我们介绍了一种新颖的模型体系结构,它可以读取图像中的文本,在图像和问题的上下文中对其进行推理,并预测答案可能是基于文本和图像的推论或由找到的字符串组成的在图像中。因此,我们将我们的方法称为Look,Read,Reason Answer LoRRA。我们证明LoRRA在TextVQA数据集上优于现有的VQA模型。我们发现TextVQA上的人类性能和机器性能之间的差距明显大于VQA 2.0,这表明TextVQA非常适合沿着与VQA 2.0互补的方向进行基准测试。 |
| On The Classification-Distortion-Perception Tradeoff Authors Dong Liu, Haochen Zhang, Zhiwei Xiong 信号衰减无处不在,并且已经研究了降级信号的计算恢复多年。最近,据报道,信号恢复的能力基本上受到感知失真折衷的限制,即,恢复信号和理想原始信号之间的失真和感知差异不能同时最小化。失真对应于信号保真度,感知差异对应于感知自然度,这两者都是实践中的重要指标。此外,还有另一个值得考虑的维度,即恢复信号的语义质量或用于识别目的的效用。在本文中,我们将先前的感知失真权衡扩展到分类失真感知CDP权衡的情况,其中我们引入了恢复信号的分类错误率以及失真和感知差异。考虑CDP权衡的两个版本,一个使用预定义的分类器,另一个处理恢复信号的最佳分类器。对于这两个版本,我们可以严格证明CDP权衡的存在,即失真,感知差异和分类错误率不能同时全部最小化。我们的研究结果尤其适用于计算机视觉研究,其中一些低级视觉任务信号恢复用于高级视觉任务视觉理解。 |
| Learning a Controller Fusion Network by Online Trajectory Filtering for Vision-based UAV Racing Authors Matthias M ller, Guohao Li, Vincent Casser, Neil Smith, Dominik L. Michels, Bernard Ghanem 自主无人机比赛最近成为一个有趣的研究问题。梦想是在这项新的快节奏运动中击败人类。一种常见的方法是学习端到端策略,通过模仿专家直接预测来自原始图像的控制。然而,这样的政策受到模仿的专家的限制,并且扩展到其他环境并且车辆动力学很难。克服端到端策略的缺点的一种方法是仅在感知任务上训练网络并使用PID或MPC控制器处理控制。但是,必须对单个控制器进行广泛调整,并且通常不能覆盖整个状态空间。在本文中,我们建议使用融合多个控制器的DNN来学习优化控制器。网络学习具有在线轨迹滤波的鲁棒控制器,其抑制单个控制器的噪声轨迹和缺陷。结果是一个网络能够学习来自不同控制器的过滤轨迹的良好融合,从而显着改善整体性能。我们将经过训练的网络与它所学到的控制器,端到端基线和人类飞行员进行了实际模拟比较,我们的网络在广泛的实验中击败了所有基线并接近了专业人员飞行员的表现。总结这项工作的视频可在以下网址获得 |
| Artificial Intelligence for Pediatric Ophthalmology Authors Julia E. Reid, Eric Eaton 回顾的目的尽管最近人工智能AI应用于普通眼科的结果令人印象深刻,但在使用类似技术解决儿科眼科问题方面取得的进展相对较少。本文讨论了儿科眼科患者的独特需求以及AI技术如何应对这些挑战,调查AI近期应用于儿科眼科,并讨论了该领域的未来发展方向。 |
| Deep Learning Fundus Image Analysis for Diabetic Retinopathy and Macular Edema Grading Authors Jaakko Sahlsten, Joel Jaskari, Jyri Kivinen, Lauri Turunen, Esa Jaanio, Kustaa Hietala, Kimmo Kaski 糖尿病是一种全球流行的疾病,其可引起可见的微血管并发症,例如人眼视网膜中的糖尿病性视网膜病和黄斑水肿,其图像目前用于手动疾病筛查。使用深度学习技术的自动检测可以极大地利用这项劳动密集型任务。在这里,我们提出了一个深度学习系统,可以比以前的研究中提供的相比或更好地识别可引起的糖尿病视网膜病变,尽管我们在训练中仅使用了一小部分图像,但辅助了更高的图像分辨率。我们还为糖尿病视网膜病变和黄斑水肿分类的五种不同筛查和临床分级系统提供了新的结果,包括根据临床五级糖尿病视网膜病变和四级糖尿病性黄斑水肿量表准确分类图像的结果。这些结果表明,深度学习系统可以提高筛查的成本效益,同时达到高于推荐的性能,并且该系统可以应用于需要更精细分级的临床检查。 |
| Knowledge-rich Image Gist Understanding Beyond Literal Meaning Authors Lydia Weiland, Ioana Hulpus, Simone Paolo Ponzetto, Wolfgang Effelsberg, Laura Dietz 我们调查了解图像及其字幕所传达的消息要点的问题,例如,在网站或新闻文章中找到的问题。为此,我们提出了一种方法,可以在大量机器可读知识的基础上捕获图像标题对的含义,这些知识以前被证明对文本理解非常有效。我们的方法识别超出其表示的对象的内涵,其中大多数图像理解方法关注于对象的表示,即它们的字面意义,我们的工作解决了内涵的识别,即对象的标志性意义,以理解图像的信息。 。我们将图像理解视为基于诸如维基百科提供的概念的广泛覆盖词汇表示图像字幕对的任务,以及将图像字幕对作为查询的施法要点检测作为概念排序问题。为了彻底调查对要点理解的问题,我们制作了一个超过300个图像标题对的金标准和超过8,000个gist注释,涵盖了不同抽象层次的各种主题。我们使用此数据集来实验性地对来自异构源(即图像和文本)的信号的贡献进行基准测试。平均精度MAP为0.69的最佳结果表明,通过组合两个维度,我们能够比单独使用语言或视觉信息更好地理解图像标题对的含义。我们在接收自动生成的输入时测试我们的要点检测方法的稳健性,即使用自动生成的图像标签或生成的标题,并证明端到端自动化过程的可行性。 |
| Disentangled Representation Learning with Information Maximizing Autoencoder Authors Kazi Nazmul Haque, Siddique Latif, Rajib Rana 从任何未标记的数据中学习解开的表示是一个非常重要的问题。在本文中,我们提出信息最大化自动编码器InfoAE,其中编码器通过以无人监督的方式最大化表示和给定信息之间的互信息来学习强大的解开的表示。我们已经在MNIST数据集上评估了我们的模型,并且在使用完全无监督训练的同时达到了98.9 pm .1的测试精度。 |
| ZK-GanDef: A GAN based Zero Knowledge Adversarial Training Defense for Neural Networks Authors Guanxiong Liu, Issa Khalil, Abdallah Khreishah 神经网络分类器已成功用于广泛的应用。然而,他们的无攻击环境的基本假设已被对抗性的例子所抵制。然而,研究人员试图开发防御措施,但现有方法仍远未为这一不断发展的问题提供有效的解决方案。在本文中,我们设计了一种基于零知识对抗训练防御的生成对抗性网络GAN,称为ZK GanDef,它在训练期间不消耗对抗性的例子。因此,ZK GanDef不仅在训练方面有效,而且适用于新的对抗性例子。与全知识方法相比,这种优势的代价是测试精度的小幅下降。我们的实验表明,与零知识方法相比,ZK GanDef将对抗实例的测试准确度提高了49.17。更重要的是,它的测试精度接近于现有技术的全部知识接近最大降级8.46,同时减少了训练时间。 |
| Defensive Quantization: When Efficiency Meets Robustness Authors Ji Lin, Chuang Gan, Song Han 神经网络量化正成为在硬件平台(如CPU,GPU,TPU和FPGA)上高效部署深度学习模型的行业标准。但是,我们观察到传统的量化方法容易受到对抗性攻击。本文旨在提高人们对量化模型安全性的认识,并设计了一种新的量化方法,共同优化深度学习模型的效率和鲁棒性。我们首先进行一项实证研究,以证明香草量化更多地受到对抗性攻击。我们观察到较差的鲁棒性来自误差放大效应,其中量化操作进一步扩大了由放大的噪声引起的距离。然后,我们通过在量化期间控制网络的Lipschitz常数来提出新颖的防御量化DQ方法,使得在推理期间对抗性噪声的幅度保持非扩展。对CIFAR 10和SVHN数据集的大量实验表明,我们的新量化方法可以防御神经网络对抗对抗性示例,甚至可以实现比全精度对应物更强的鲁棒性,同时保持与vanilla量化方法相同的硬件效率。作为副产品,DQ还可以提高量化模型的准确性,而不会产生对抗性攻击。 |
| Tightly Coupled 3D Lidar Inertial Odometry and Mapping Authors Haoyang Ye, Yuying Chen, Ming Liu 自我运动估计是大多数移动机器人应用的基本要求。通过传感器融合,我们可以弥补独立传感器的不足,并提供更可靠的估算。我们在本文中介绍了一种紧耦合的激光雷达IMU融合方法。通过联合最小化激光雷达和IMU测量得出的成本,激光雷达IMU测距仪LIO在长期实验后可以在可接受的漂移下表现良好,即使在激光雷达测量可能降低的具有挑战性的情况下也是如此。此外,为了获得更可靠的激光雷达姿势估计,提出了旋转约束细化算法LIO映射以进一步将激光雷达姿势与全局图对齐。实验结果表明,即使在快速运动条件下或功能不足的情况下,所提出的方法也能够以高精度估计IMU更新速率下传感器对的姿态。 |
| Chinese Abs From Machine Translation |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号