
【今日CV 计算机视觉论文速览 第104期】Wed, 24 Apr 2019
今日CS.CV 计算机视觉论文速览
Wed, 24 Apr 2019
Totally 43 papers
👉上期速览✈更多精彩请移步主页

Interesting:
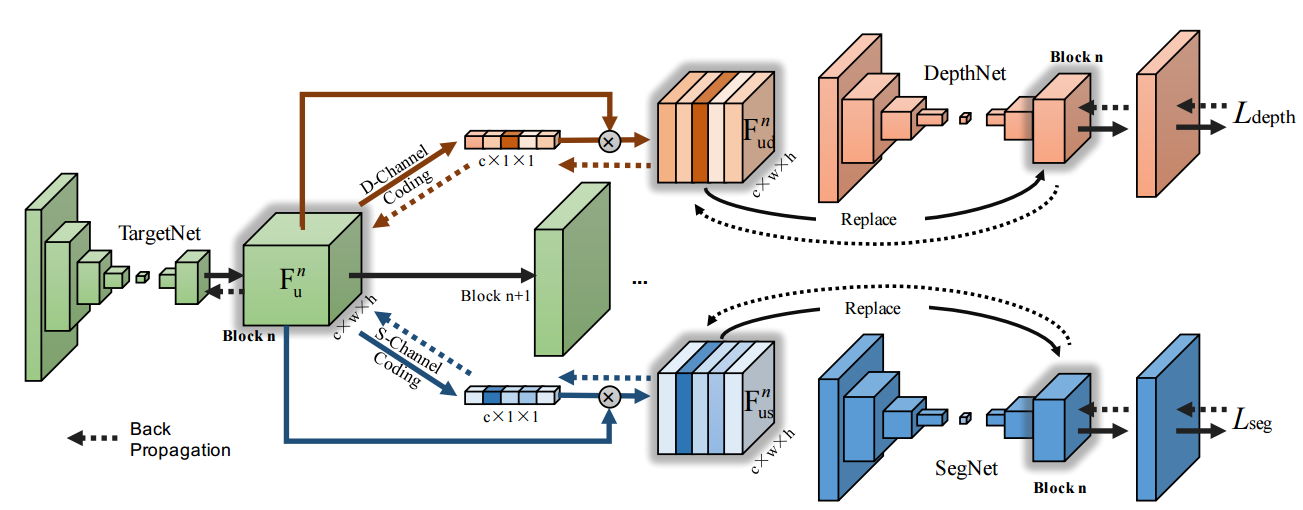
📚从学习到大师的知识融合, 联合场景解析、深度估计的新方法。创造一个可以无需人类标注,从两个预训练模型中自主学习的方法。通过将预训练模型的特征映射到学生模型,实现了可以同时训练学习多个任务的方法。首先初始化与教师网络相同的目标网络,随后训练目标网络的每一个block,并决定分支网络的位置,最后将教师网络的分支拿过来使用,并移除初始网络。精调最终的目标网络。可以理解为训练了一个满足两个任务的嵌入隐变量(通用编码器),并基于这个隐变量利用原始网络的解码器实现功能。(from 浙大)
可以结合两种网络模型功能,获取新功能的模型,实现知识融合:
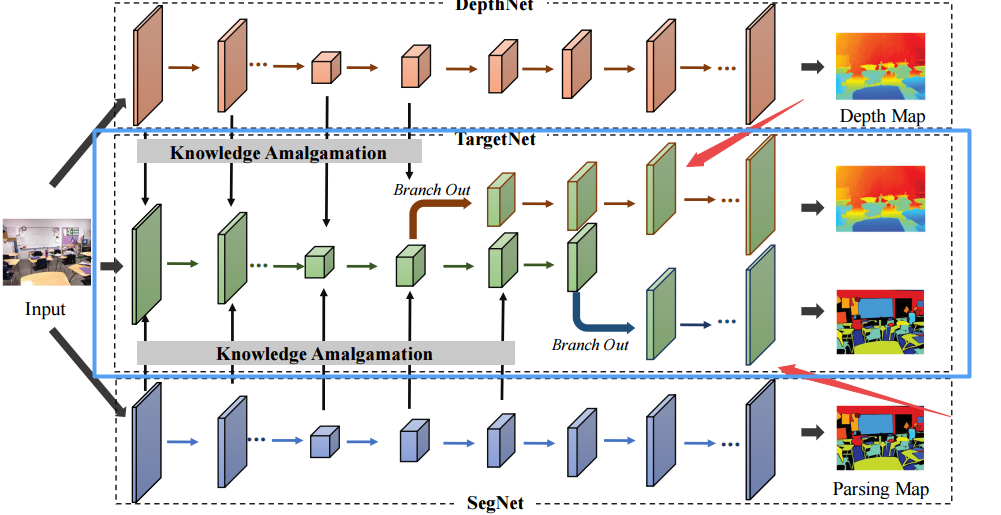
知识融合模块:
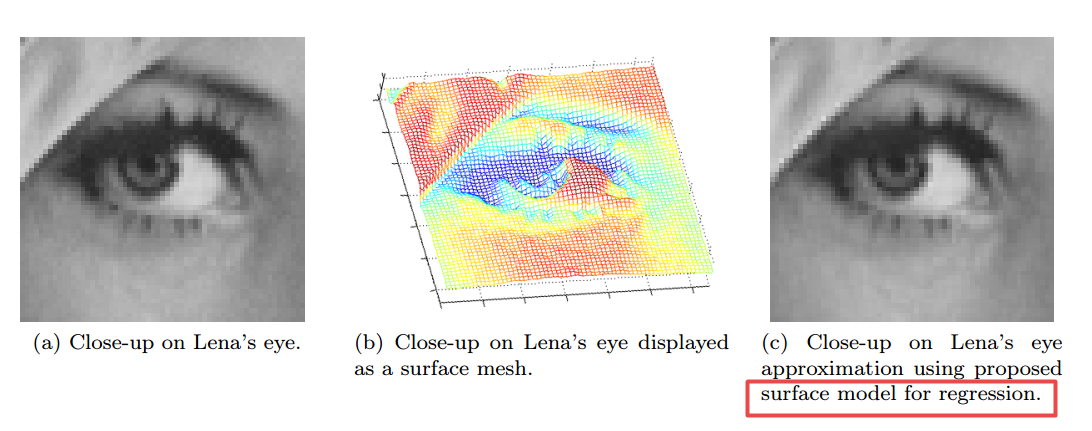
📚RSD:Regression Surface Descriptor回归表面描述子,一种基于边缘检测的参数化表面模型。首先将图像看做是参数化表面,随后利用局域参数化模型来表示图像内容,最后利用对表面不连续敏感的参数模型来实现有效的边缘检测,具有对模糊的鲁棒性和定制化的灵活性。 (from Troyes University of Technology)
提出参数化模型:
不同配置下的结果:

此方法的鲁棒性:


📚Water-Filling, 用于文件拍摄时表面阴影的去除,解决了拍摄文件时灯光造成的阴影。首先利用像素值形态学的方法估计了阴影部分,随后利用浸入过程找出阴影区域,利用新的扩散方程的迭代来实现模拟。最后基于朗伯表面模型来重建了文件表面。(from KAIST )
估计阴影区域:
漫水扩散方法找到阴影区域:

重建结果:、


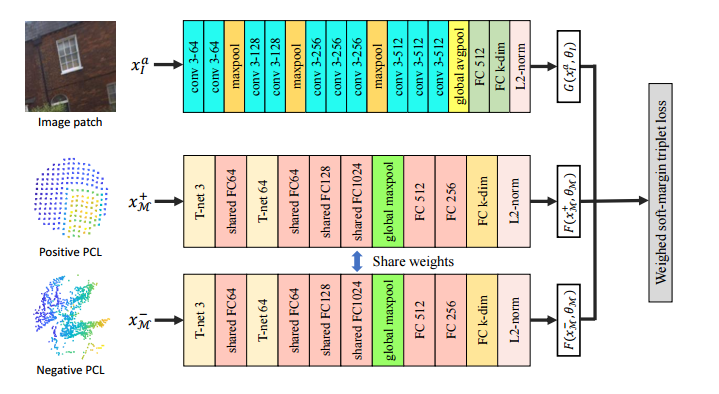
📚2D3D-MatchNet, 二维图像和三维点云的关键点匹配。(from 新加坡国立)
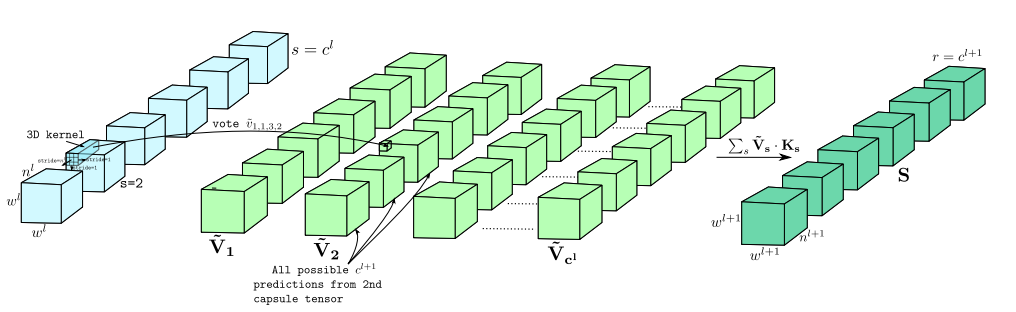
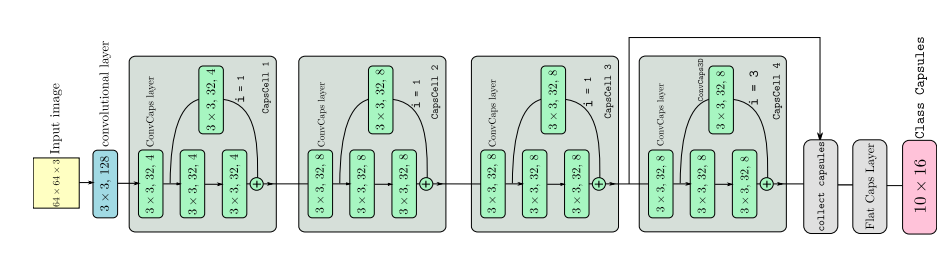
📚DeepCaps, 基于三维卷积的动力学路由算法。(from University of Moratuwa)
三维卷积的动态路由:
基于DeepCap模块的卷积网络:
project:https://github.com/brjathu/deepcaps
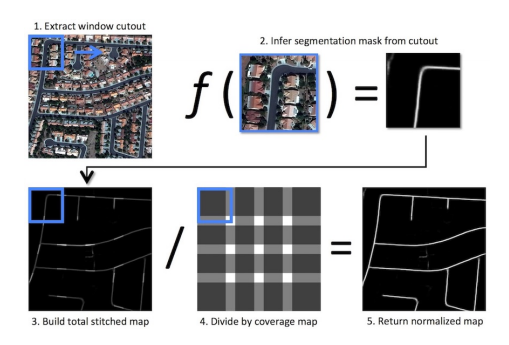
📚CRESI, 直接从卫星影响中抽取道路。(from )
标注和图像处理过程:

道路抽取的过程:

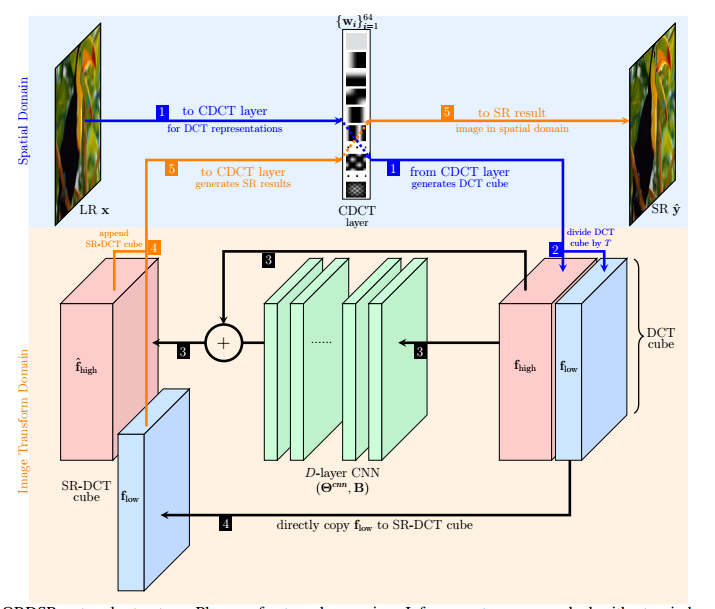
📚ORDSR, 通过正交正则化深度网络实现的自适应域迁移的图像超分辨(from 宾夕法尼亚大学)
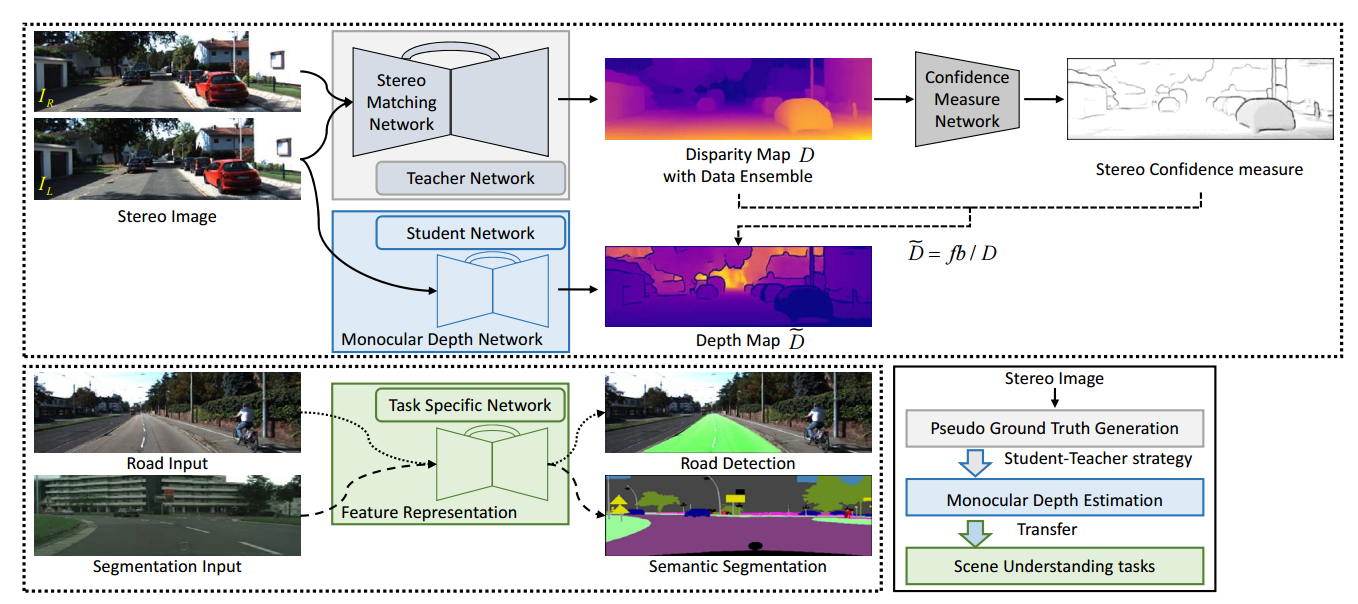
📚大规模半监督单目深度估计的RGB-D数据集, 基于学生-老师的半监督训练机制在大规模的非标注数据上取得了很好的效果。(from 延世大学)

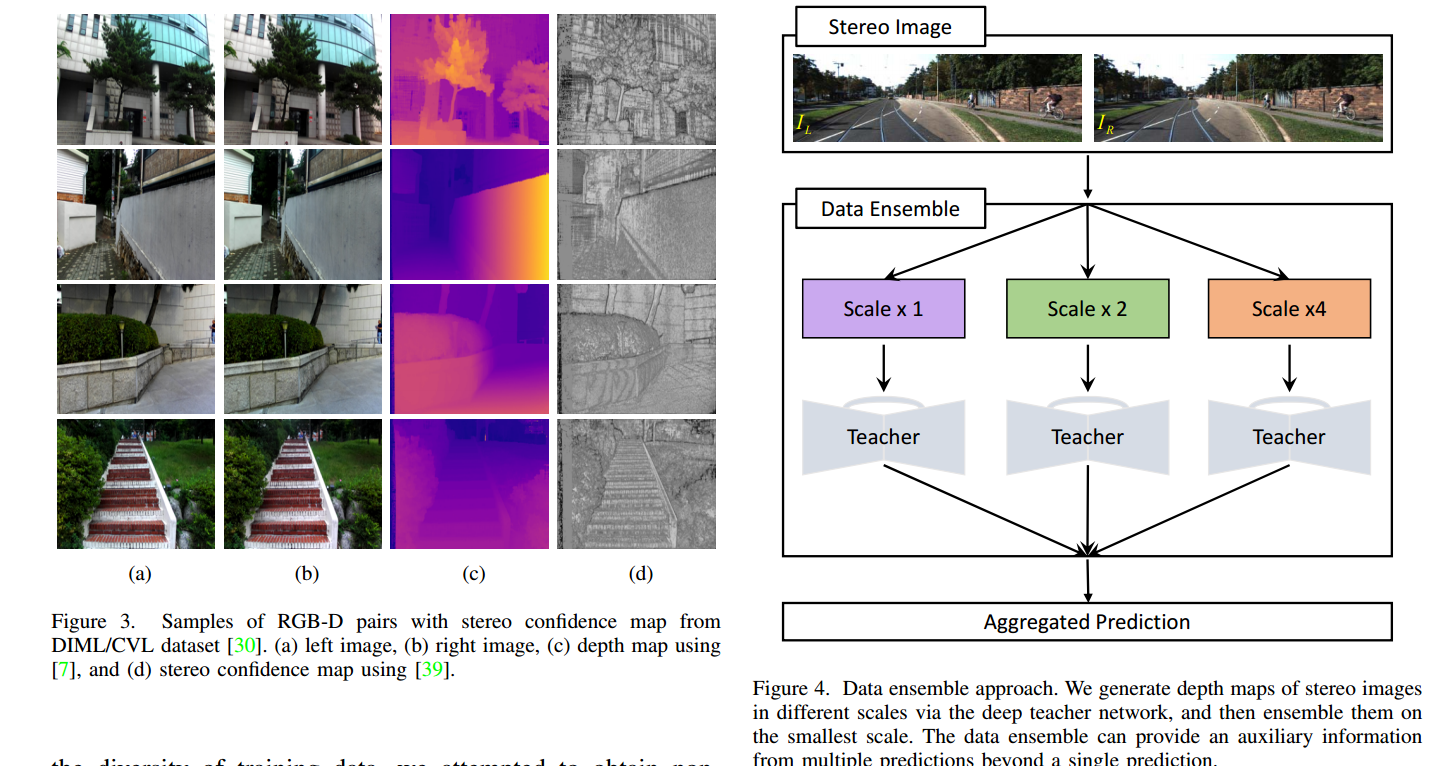
数据集和一些结果:
project:https://dimlrgbd.github.io
📚RERERE, 真实室内的远程嵌入推理表达,视觉语言导航。(from 阿德莱德大学)

ref:Vision-and-language navigation: Interpreting visuallygrounded navigation instructions in real environments CVPR2018
📚芬兰二战摄影师照片分析, (from 芬兰坦佩雷大学)

二战照片数据集:http://www.loc.gov/pictures/collection/fsa/
Daily Computer Vision Papers
| DenseNet Models for Tiny ImageNet Classification Authors Zoheb Abai, Nishad Rajmalwar 在本文中,我们在Tiny ImageNet数据集上提出了两种图像分类模型。我们基于密集连接卷积网络的思想,从头开始构建了两个截然不同的网络。网络的体系结构基于该特定数据集的图像分辨率并通过计算卷积层的感知域来设计。我们还使用了一些与图像增强和循环学习率相关的非传统技术来提高模型的准确性。网络在高约束和低计算资源下训练。我们的目标是实现结果的前1个验证准确度,并且还提供了错误分析。 |
| Interpretable and Generalizable Deep Image Matching with Adaptive Convolutions Authors Shengcai Liao, Ling Shao 对于图像匹配任务,如人脸识别和人物识别,现有的深度网络通常关注表示学习。然而,在没有域适应或转移学习的情况下,学习模型是固定的,其不适于处理各种看不见的场景。在本文中,除了表示学习之外,我们还考虑如何在深度特征映射中直接形成图像匹配。我们将图像匹配视为在特征映射中寻找局部对应关系,并在运行中构建自适应卷积核以实现局部匹配。通过这种方式,匹配过程和结果是可解释的,并且这种显式匹配比表示特征更加普遍,以便看不见的场景,例如未知的未对准,姿势或视点变化。为了促进这种图像匹配架构的端到端训练,我们进一步构建了一个类存储器模块,用于缓存每个类的最新样本的特征映射,以便计算用于度量学习的图像匹配损失。该方法初步验证了人员识别任务。通过直接交叉数据集评估而无需进一步的转移学习,它实现了比许多转移学习方法更好的结果。此外,提出了一种基于模型自由时间共生的得分加权方法,该方法进一步提高了性能,从而在交叉数据集评估中得到了最新的结果。 |
| BIT: Biologically Inspired Tracker Authors Bolun Cai, Xiangmin Xu, Xiaofen Xing, Kui Jia, Jie Miao, Dacheng Tao 由于各种因素(例如物体变形,尺度变化,光照变化和遮挡)引起的图像变化,视觉跟踪具有挑战性。鉴于人类视觉系统HVS的卓越跟踪性能,理想的生物启发模型设计有望改善计算机视觉跟踪。然而,由于对HVS中神经元工作机制的不完全理解,这是一项艰巨的任务。本文旨在通过分析视觉皮层腹侧视觉认知机制来解决这一挑战,模拟浅层神经元S1单元和C1单元,为目标外观提取低水平的生物启发特征,并模仿先进的学习机制S2单位和C2单位将目标位置的生成和判别模型结合起来。此外,该框架中采用快速Gabor近似FGA和快速傅里叶变换FFT进行实时学习和检测。对大规模基准数据集的大量实验表明,所提出的生物启发式跟踪器在效率,准确性和稳健性方面对现有技术方法表现出优异的效果。加速技术特别确保BIT保持大约每秒45帧的速度。 |
| Minimizing Perceived Image Quality Loss Through Adversarial Attack Scoping Authors Kostiantyn Khabarlak, Larysa Koriashkina 现在,神经网络正在积极地用于安全关键领域的计算机视觉任务,例如机器人,人脸识别,自动驾驶车辆,但在发现对抗性攻击后,他们的安全性受到质疑。在本文中,我们开发了基于范围思想的简化对抗攻击算法,该算法能够执行快速对抗攻击,最大限度地降低结构图像质量SSIM丢失,允许执行具有低目标推理网络呼叫计数的有效传输攻击,并使用笔只用于MNIST手写数字数据集的纸上绘图。所提出的对抗性攻击分析和攻击范围的思想可以很容易地扩展到不同的数据集,从而使得论文的结果适用于广泛的实际任务。 |
| Path-Restore: Learning Network Path Selection for Image Restoration Authors Ke Yu, Xintao Wang, Chao Dong, Xiaoou Tang, Chen Change Loy 非常深的卷积神经网络CNN大大提高了各种图像恢复任务的性能。然而,这是以增加计算负担为代价的,这限制了它们的实际用途。我们相信一些损坏的图像区域本身比其他区域更容易恢复,因为图像内的失真和内容是变化的。为此,我们提出路径恢复,一种带有路径查找器的多路径CNN,可以为每个图像区域动态选择合适的路径。我们使用强化学习训练探路者,并且难以调节奖励,这与恢复区域的性能,复杂性和难度有关。我们进行了去噪和混合修复任务的实验。结果表明,我们的方法可以实现与现有方法相当或更优的性能,并且计算成本更低。特别地,我们的方法对于真实世界去噪是有效的,其中噪声分布在单个图像的不同区域上变化。我们超越了现有技术的CBDNet 0.94 dB,在现实的达姆施塔特噪声数据集上运行速度更快29。模型和代码将被发布。 |
| Privacy Preserving Group Membership Verification and Identification Authors Marzieh Gheisari, Teddy Furon, Laurent Amsaleg 在召集隐私时,群组成员身份验证会检查生物特征是否与群组中的一个成员相对应,而不会显示该成员的身份。类似地,群组成员身份识别指出个人所属的群组,而不知道他的身份。最近的贡献通过联合使用将生物特征模板量化为离散嵌入并将若干模板聚合成一个组表示的两种机制来为组成员协议提供隐私和安全性。本文显着改善了这一贡献,因为它共同学习如何嵌入和聚合,而不是强加固定和硬编码规则。这通过暴露学习阶段的数学基础来证明,然后通过针对人脸识别的大量实验展示改进。总的来说,实验表明,学习在安全隐私和验证识别性能之间产生了极好的折衷。 |
| VITAMIN-E: VIsual Tracking And MappINg with Extremely Dense Feature Points Authors Masashi Yokozuka, Shuji Oishi, Thompson Simon, Atsuhiko Banno 在本文中,我们提出了一种名为VITAMIN E的新型间接单眼SLAM算法,该算法由于跟踪极其密集的特征点而具有高度的精确性和鲁棒性。典型的间接方法难以重建密集几何体,因为它们精确匹配的特征点选择。与传统方法不同,所提出的方法通过跟踪由主流估计所通知的局部曲率极值来处理大量特征点。因为这可能导致束调整期间的高计算成本,我们提出了一种新颖的优化技术,子空间Gauss Newton方法,通过部分更新变量显着提高了束调整的计算效率。我们同时从重建点生成网格并将它们合并为整个3D模型。 SLAM基准数据集EuRoC的实验结果表明,所提出的方法在轨迹估计的准确性和鲁棒性方面均优于现有的SLAM方法,如DSO,ORB SLAM和LSD SLAM。所提出的方法仅使用CPU同时从密集特征点同时生成显着详细的3D几何结构。 |
| Transferable Semi-supervised 3D Object Detection from RGB-D Data Authors Yew Siang Tang, Gim Hee Lee 我们研究了仅从这些新类的2D边界框标签训练新对象类的3D对象检测器的方向,同时从现有类的3D边界框标签传输信息。为此,我们提出了一种可转移的半监督3D物体检测模型,该模型从训练数据中学习3D物体探测器网络,其中两组不相交的物体类是一组具有2D和3D箱标签的强类,另一组是弱类。只有2D盒子标签。特别是,我们建议放松的重投注损失,盒子先前丢失和Box to Point Cloud Fit网络,这使我们能够在训练期间有效地将有用的3D信息从强类转移到弱类,从而使网络能够检测到3D推理期间弱类中的对象。实验结果表明,与SUN RGBD和KITTI数据集上的完全监督方法相比,我们提出的算法优于基线方法并取得了有希望的结果。此外,我们表明我们的Box to Point Cloud Fit网络改善了两个数据集上完全监督方法的性能。 |
| Attention-guided Network for Ghost-free High Dynamic Range Imaging Authors Qingsen Yan, Dong Gong, Qinfeng Shi, Anton van den Hengel, Chunhua Shen, Ian Reid, Yanning Zhang 由移动物体或未对准引起的重影伪影是动态场景的高动态范围HDR成像中的关键挑战。先前的方法首先在合并它们之前使用光流注册输入的低动态范围LDR图像,这些图像容易出错并且导致结果中的重影。最近的一项工作试图通过具有跳过连接的深度网络绕过光流,但是仍然存在严重移动的重影伪像。为了避免来源的重影,我们提出了一种新颖的注意力引导端到端深度神经网络AHDRNet,以产生高质量的无鬼HDR图像。与先前直接堆叠LDR图像或用于合并的特征的方法不同,我们使用注意模块来引导根据参考图像的合并。注意模块自动抑制由未对准和饱和引起的不期望的分量,并增强非参考图像中所需的精细细节。除了注意模型之外,我们还使用扩张的残余密集块DRDB来充分利用分层特征,并增加感知域以消除丢失的细节。所提出的AHDRNet是一种基于非流的方法,其还可以避免由光流估计误差产生的伪像。对不同数据集的实验表明,所提出的AHDRNet可以实现最先进的定量和定性结果。 |
| Free-form Video Inpainting with 3D Gated Convolution and Temporal PatchGAN Authors Ya Liang Chang, Zhe Yu Liu, Winston Hsu 自由形式视频修复是一项非常具有挑战性的任务,可广泛用于视频编辑,如文本删除。现有的基于补丁的方法无法处理非重复结构(如人脸),而直接将基于图像的修复模型应用于视频会导致时间不一致 |
| A Large RGB-D Dataset for Semi-supervised Monocular Depth Estimation Authors Jaehoon Cho, Dongbo Min, Youngjung Kim, Kwanghoon Sohn 单眼深度估计的最新进展主要基于深度嵌套的卷积网络,并结合监督训练。然而,收集大规模地面实况深度或视差图以监督网络仍然是艰巨的。本文提出了一种简单而有效的半监督单眼深度估计方法。受人类视觉系统的启发,我们提出了一种学生教师策略,其中使用从更深入和准确的教师网络获得的辅助信息来训练浅层学生网络。具体来说,我们首先充分利用三维几何的双目感知训练立体教师网络,然后使用教师网络的深度预测来监督学生网络进行单眼深度推理。这使我们能够利用相对容易获得的大量未标记立体对的所有可用深度数据。我们进一步介绍了一种数据集合策略,该策略融合了教师网络的多个深度预测,以改进学生网络的训练样本。另外,提供立体置信度图以避免在监督学生网络时使用不准确的深度估计。我们的新训练数据包括使用手持立体摄像机拍摄的100万个室外立体图像,在项目网页上进行。最后,我们证明了单眼深度估计网络提供了适用于某些高级视觉任务(如语义分割和道路检测)的特征表示。大量实验证明了所提方法在各种户外场景中的有效性和灵活性。 |
| High-frequency crowd insights for public safety and congestion control Authors Karthik Nandakumar, Sebastien Blandin, Laura Wynter 我们提供了几个项目的结果,旨在实现人群及其在建筑环境中的行为的实时理解。我们利用在整个发达国家和发展中国家无处不在的闭路电视摄像机,因此能够发挥可靠的传感机制的作用。我们概述了为我们的人群洞察引擎开发的新方法,并举例说明了它在城市景观的不同背景下的使用。该技术的应用范围从维护公共场所的安全性到量化公共交通服务水平的充分性。 |
| Student Becoming the Master: Knowledge Amalgamation for Joint Scene Parsing, Depth Estimation, and More Authors Jingwen Ye, Yixin Ji, Xinchao Wang, Kairi Ou, Dapeng Tao, Mingli Song 在本文中,我们研究了一种新的深度模型重用任务。我们的目标是培养一个轻量级和多功能的学生模型,没有人类标注注释,合并知识并掌握两个训练有素的问题的预训练教师模型的专业知识,一个是场景解析,另一个是深度估计。为此,我们提出了一种创新的培训策略,通过将学生合并的特征投射到每个教师的领域并计算损失来实现与教师交织在一起的学生参数。我们还介绍了两种选项来概括所提出的培训策略,以同时处理三个或更多任务。拟议的计划产生非常令人鼓舞的结果正如在几个基准测试中所证明的那样,受过训练的学生模型取得的成果甚至优于他们自己的专业领域中的教师,并且与依赖于人类标记注释的现有技术完全监督模型相当。 |
| A Novel Multi-layer Framework for Tiny Obstacle Discovery Authors Feng Xue, Anlong Ming, Menghan Zhou, Yu Zhou 对于单眼图像中的微小障碍物发现,边缘是一个基本的视觉元素。然而,由于各种原因,例如噪声和具有背景的类似颜色分布,仍然难以在长距离处检测微小障碍物的边缘。在本文中,我们提出了一种障碍感知发现方法来恢复这些障碍物的缺失轮廓,这有助于尽可能地获得障碍物建议。首先,通过在单眼图像中使用视觉提示,精心推断几个多层区域以显示与相机的距离。其次,构建了几个新颖的障碍物识别遮挡边缘图,以便很好地捕捉微小障碍物的轮廓,这些障碍物结合了每层的线索。第三,为了确保微小障碍物提议的存在,来自所有层的地图用于提议提取。最后,基于包含微小障碍的这些提议,提出了一种新颖的障碍感知回归器,以高可信度生成障碍物占用概率图。通过与Lost and Found数据集进行比较的令人信服的实验结果证明了我们的方法的有效性,实现了比FPHT和PHT大约9.5的精度改进,甚至可以获得与MergeNet相当的性能。此外,我们的方法优于现有技术的算法,并显着提高了远距离微小障碍物的发现能力。 |
| RERERE: Remote Embodied Referring Expressions in Real indoor Environments Authors Yuankai Qi, Qi Wu, Peter Anderson, Marco Liu, Chunhua Shen, Anton van den Hengel 机器人技术的长期挑战之一是使人类能够与机器人沟通世界。如果他们要合作是至关重要的。人类是视觉动物,我们主要通过语言进行交流,因此人类机器人交流不可避免地至少部分是视觉和语言问题。这促进了引用表达数据集以及视觉和语言导航数据集。这些将问题划分为识别感兴趣对象或导航到另一个位置的问题。然而,许多最吸引人的机器人用途需要与远程对象进行通信,因此不能反映数据集中的二分法。因此,我们提出了第一个远程实体参考表达数据集,其自然语言参考实际图像中的远程对象。成功需要在先前看不见的环境中导航以选择通过一般自然语言识别的对象。这代表了一个复杂的挑战,但它恰好反映了机器人技术中的一个核心视觉问题。还提出了一种导航器指针模型,该模型为任务提供了强大的基线。 |
| Siamese Attentional Keypoint Network for High Performance Visual Tracking Authors Peng Gao, Yipeng Ma, Ruyue Yuan, Liyi Xiao, Fei Wang 在本文中,我们研究了视觉跟踪的三个主要方面,即骨干网络,注意机制和检测组件的影响,并提出了一个名为SATIN的连体注意关键点网络,以实现有效的跟踪和准确的本地化。首先,新的Siamese轻质沙漏网络专为视觉跟踪而设计。它利用重复自下而上和自上而下推断的优势,在多个尺度上捕获更多的全局和局部上下文信息。其次,利用新颖的交叉注意模块来利用频道明智和空间中间注意信息,这增强了特征地图的辨别能力和定位能力。第三,发明了一种关键点检测方法,通过检测其边界框的左上角点,质心点和右下角点来跟踪任何目标对象。据我们所知,我们是第一个提出这种方法的人。因此,我们的SATIN跟踪器不仅具有很强的学习更有效的对象表示能力,而且还具有计算和内存存储效率,无论是在培训阶段还是测试阶段。没有花里胡哨,实验结果表明我们的方法在几个最近的基准数据集上达到了最先进的性能,速度远远超过了帧速率要求。 |
| Lung Nodule Classification using Deep Local-Global Networks Authors Mundher Al Shabi, Boon Leong Lan, Wai Yee Chan, Kwan Hoong Ng, Maxine Tan 目的肺结节具有非常多样的形状和大小,这使得它们被分类为良性恶性是一个具有挑战性的问题。在本文中,我们提出了一种预测结节恶性的新方法,该方法能够使用全局特征提取器分析结节的形状和大小,以及使用局部特征提取器来分析结节的密度和结构。方法我们建议使用具有3x3内核大小的残差块用于局部特征提取,并使用非局部块来提取全局特征。非局部块能够在不使用大量参数的情况下提取全局特征。非局部块背后的关键思想是在相同特征图上的特征之间应用矩阵乘法。结果我们在LIDC IDRI数据集上训练和验证了所提出的方法,该数据集包含1,018个计算机断层扫描CT扫描。我们遵循严格的实验设置程序,即10倍交叉验证,忽略了由少于3名放射科医师注释的结节。所提出的方法利用AUC 95.62实现了现有技术水平,同时显着优于其他基线方法。结论我们提出的Deep Local Global网络能够准确地提取本地和全局特征。我们的新方法优于传统学习,包括Densenet和Resnet在内的最先进的架构。 |
| Learning Actor Relation Graphs for Group Activity Recognition Authors Jianchao Wu, Limin Wang, Li Wang, Jie Guo, Gangshan Wu 演员之间的关系建模对于识别多人场景中的团体活动很重要。本文旨在利用深层模型有效地学习参与者之间的判别关系。为此,我们建议构建一个灵活高效的Actor Relation Graph ARG,以同时捕获actor之间的外观和位置关系。由于图形卷积网络,ARG中的连接可以以端到端的方式从组活动视频中自动学习,并且可以使用标准矩阵操作有效地执行对ARG的推断。此外,在实践中,我们提出了两种变体来稀疏化ARG,以便在视频空间局部化ARG和时间随机化ARG中进行更有效的建模。我们对两个标准组活动识别数据集 - 排球数据集和集体活动数据集 - 进行了大量实验,在这两个数据集中实现了最先进的性能。我们还可以将学习的演员图和关系特征可视化,这表明所提出的ARG能够捕获用于组活动识别的判别关系信息。 |
| DirectShape: Photometric Alignment of Shape Priors for Visual Vehicle Pose and Shape Estimation Authors Rui Wang, Nan Yang, Joerg Stueckler, Daniel Cremers 从图像中理解3D场景是机器人技术,增强现实和自动驾驶场景中遇到的具有挑战性的问题。在本文中,我们提出了一种新的方法,从道路场景的立体图像联合推断车辆的3D刚体姿态和形状。与先前依赖于具有密集立体重建的形状的几何对齐的工作不同,我们的方法直接在图像上工作并且通过3D形状先验与立体图像的组合光度和轮廓对准来有效地推断形状和姿势。我们使用先前的形状来表示体积符号距离函数的低维线性嵌入中的汽车。为了有效地测量两个对齐项的一致性,我们提出了一种自适应稀疏点选择方案。在实验中,我们展示了我们的方法在姿态估计和形状重建方面的优越性能,这种方法采用了使用密集立体重建的几何对齐的现有技术方法。我们的方法还可以提高基于深度学习的3D对象检测方法的性能,作为一种改进方法。我们证明了我们的方法显着提高了几种近期检测方法的准确性。 |
| Tertiary Eye Movement Classification by a Hybrid Algorithm Authors Samuel Hunter Berndt, Douglas Kirkpatrick, Timothy Taviano, Oleg Komogortsev 主要眼动,眼跳,固定和平滑追踪的正确分类对于利用眼动追踪数据仍然是必不可少的。将顺利追求与其他行为类型分开是困难的,尤其是从注视中。为此,我们提出了一种新的离线算法,I VDT HMM,用于眼动的三级分类。该算法结合了两种基本算法的简单性,I VT和I DT,如在I VDT中实现的,具有维特比算法的统计预测能力。我们使用提出的定量和定性行为评分,从以前的研究中收集的八个采样率评估八个眼球运动记录的数据集的适应度,并与现有技术水平进行比较。所提出的算法在干净的高采样频率数据中实现了有希望的结果,并且稍微修改可以在较低质量数据下显示类似的结果。但是,算法的统计方面是以分类时间为代价的。 |
| Adaptive Transform Domain Image Super-resolution Via Orthogonally Regularized Deep Networks Authors Tiantong Guo, Hojjat S. Mousavi, Vishal Monga 深度学习方法,特别是训练有素的卷积神经网络CNN最近已被证明可以为单图像超分辨率SR产生引人注目的结果。总是,CNN被学习将低分辨率LR图像映射到空间域中的相应高分辨率HR版本。我们提出了一种新颖的网络结构,用于学习图像变换域中的SR映射函数,特别是离散余弦变换DCT。作为第一个贡献,我们表明DCT可以作为卷积DCT CDCT层集成到网络结构中。通过CDCT层,我们构建了DCT Deep SR DCT DSR网络。我们进一步扩展DCT DSR以允许CDCT层变得可训练,即可优化。因为该层表示图像变换,所以我们在各个基函数滤波器上强制成对正交性约束和新制定的复杂性顺序约束。这种正交正则化深度SR网络ORDSR通过利用图像变换域简化SR任务,同时使变换基础的设计适应训练图像集。实验结果表明,与大多数深度CNN方法相比,ORDSR以更少的参数实现了最先进的SR图像质量。 ORDSR的一个特别成功是克服双三次插值引入的伪像。深度SR的一个关键负担已被确定为慷慨训练的要求LR和HR图像对ORSDR表现出更优雅的退化,因为训练规模减少,并且在有限训练制度中具有显着益处。对内存和计算要求的分析证实,ORDSR可以实现更快速推理的更高效网络。 |
| Using Videos to Evaluate Image Model Robustness Authors Keren Gu, Brandon Yang, Jiquan Ngiam, Quoc Le, Jonathan Shlens 人类视觉系统对于对人工网络具有挑战性的各种图像变换是鲁棒的。我们首先研究了图像模型对视频帧中发现的微小变换的鲁棒性,我们称之为自然鲁棒性。与先前关于对抗性实例和合成扭曲的研究相比,自然稳健性捕获了在自然环境中发生的更多样化的常见图像变换。我们对十几个模型体系结构的研究表明,更准确的模型对自然变换更具鲁棒性,并且对合成颜色失真的鲁棒性是自然鲁棒性的良好代表。在检查视频中的脆弱性时,我们发现视频中发现的大多数脆弱性都不在对抗性示例99.9的典型定义之外。最后,我们研究了降低脆性的训练技术,发现没有一种技术可以系统地改善12种测试架构的自然鲁棒性。 |
| Learning Feature-to-Feature Translator by Alternating Back-Propagation for Zero-Shot Learning Authors Yizhe Zhu, Jianwen Xie, Bingchen Liu, Ahmed Elgammal 我们通过交替反向传播来研究特征转换器网络的学习特征,作为零射击学习ZSL问题的通用解决方案。我们的方法可以归类为基于ZSL的生成模型。与需要辅助网络来辅助训练的GAN或VAE相比,我们的模型由单个条件生成器组成,该生成器将类特征映射和潜在向量计算输出中的随机性到图像特征,并通过最大似然训练估计。训练过程是一个简单而有效的EM类过程,它迭代以下两个步骤:推理反向传播以推断每个观测数据的潜在噪声向量,以及ii学习反向传播以更新模型的参数。通过对我们模型的略微修改,我们还提供了从ZSL的不完整视觉特征中学习的解决方案。我们在五个基准测试中对现有的生成ZSL方法进行了广泛的比较,证明了我们的方法不仅在性能上而且在收敛速度和计算成本方面都具有优势。具体来说,我们的模型分别在ZSL和广义ZSL设置中以高达3.1和4.0的显着余量优于现有技术方法。 |
| UDFNet: Unsupervised Disparity Fusion with Adversarial Networks Authors Can Pu, Robert B. Fisher 现有的基于深度学习的差异融合方法实现了最先进的性能,但它们需要地面实况差异数据进行训练。据我所知,这是第一次提出不使用地面实况差异数据的无监督差异融合。本文提出了一种差异融合的数学模型,用于指导对抗网络在没有地面实况差异数据的情况下进行有效训练。初始视差图从左视图连同辅助信息梯度,左右强度图像一起输入到精炼机中,并且精炼机被训练以输出在左视图上登记的精制视差图。精细的左视差图和左强度图用于重建假的右强度图像。最后,来自右立体视觉相机的伪造和真实权利强度图像被馈送到鉴别器中。在该模型中,精炼器被训练以输出接近用于全局初始化的视差输入的加权和的精细视差值。然后,采用三个细化原则来进一步细化结果。 1伪造和真实右强度图像之间的重建强度误差被最小化。 2最大化了不同感受野中伪造图像和真实图像之间的相似性。 3基于相应的强度图像平滑细化的视差图。对抗性网络架构对于融合任务是有效的。使用所提出的网络的融合时间很小。当输入分辨率为1242 375宽度高度而没有下采样和裁剪时,网络可以使用Kitti2015数据集上的Nvidia Geforce GTX 1080Ti实现90 fps。这项工作的准确性等于或优于现有技术的监督方法。 |
| LBS Autoencoder: Self-supervised Fitting of Articulated Meshes to Point Clouds Authors Chun Liang Li, Tomas Simon, Jason Saragih, Barnab s P czos, Yaser Sheikh 我们提出了LBS AE一种自我监督的自动编码算法,用于将关节网格模型拟合到点云。作为输入,我们采用要注册的一系列点云以及艺术家装配的网格,即配备有由骨架层级参数化的线性混合蒙皮LBS变形空间的模板网格。作为输出,我们学习了一个基于LBS的自动编码器,它从输入点云产生注册的网格物体。为了弥合艺术家定义的几何体和捕获的点云之间的差距,我们的自动编码器模型构成了与模板几何体的相关偏差。在训练期间,我们的方法不是使用明确的对应关系,例如关键点或姿势监督,而是利用LBS变形来引导学习过程。为了避免错误的点到点对应的局部最小值,我们利用基于部分分割的结构化倒角距离,这是使用自我监督同时学习的。我们在真实捕获的手上展示了定性结果,并报告了针对身体登记的FAUST基准的定量评估。我们的方法实现了优于其他无监督方法的性能,并且与使用监督示例的方法相当。 |
| Orientation Aware Object Detection with Application to Firearms Authors Javed Iqbal, Muhammad Akhtar Munir, Arif Mahmood, Afsheen Rafaqat Ali, Mohsen Ali 枪械的自动检测对于提高人员的安全性和安全性非常重要,然而,由于枪械的形状,大小和外观的广泛变化,这是一项具有挑战性的任务。为了应对这些挑战,我们提出了一种定向感知对象检测器OAOD,它已经实现了改进的枪械检测和定位性能。提出的探测器有两个阶段。在阶段1中,它预测用于旋转对象提议的对象的方向。从旋转的对象提议中裁剪出最大区域矩形,这些对象再次被分类并定位在算法的阶段2中。定向对象提议被映射回原始坐标,从而产生定向边界框,这些边界框比轴对齐边界框更好地定位武器。作为方向感知,我们的非最大抑制能够避免对同一对象的多次检测,并且它可以更好地解决彼此非常接近的对象。这个两阶段系统利用OAOD来预测面向对象的边界框,同时仅在地面实况中的轴对齐框上进行训练。为了训练用于火器探测的物体探测器,从互联网收集由大约一万一千个火器图像组成的数据集并手动注释。拟议的国际电联枪支ITUF数据集包含各种枪支和步枪。在ITUF数据集上评估OAOD算法,并与现有技术的目标检测器进行比较。我们的实验证明了所提出的探测器在枪械探测任务中的出色性能。 |
| Linked Dynamic Graph CNN: Learning on Point Cloud via Linking Hierarchical Features Authors Kuangen Zhang, Ming Hao, Jing Wang, Clarence W. de Silva, Chenglong Fu 由于点云是一种常见的几何数据类型,因此可以帮助机器人稳健地理解环境,因此急需对点云进行学习。然而,点云是稀疏的,非结构化的和无序的,这是传统的卷积神经网络CNN和递归神经网络RNN无法准确识别的。幸运的是,图形卷积神经网络Graph CNN可以处理稀疏和无序数据。因此,本文提出了一种链接动态图CNN LDGCNN来直接对点云进行分类和分割。我们删除转换网络,从动态图链接分层特征,冻结特征提取器,并重新训练分类器以提高LDGCNN的性能。我们使用理论分析和可视化解释我们的网络。通过实验,我们证明了所提出的LDGCNN在两个标准数据集ModelNet40和ShapeNet上实现了最先进的性能。 |
| Three dimensional blind image deconvolution for fluorescence microscopy using generative adversarial networks Authors Soonam Lee, Shuo Han, Paul Salama, Kenneth W. Dunn, Edward J. Delp 由于图像模糊,图像去卷积通常用于研究荧光显微镜中的生物结构。荧光显微镜图像体积固有地受到强度不均匀性,模糊的影响,并且被各种类型的噪声破坏,这加剧了更深组织深度处的图像质量。因此,深层组织中荧光显微镜的定量分析仍然是一个挑战。本文提出了一种利用3路空间约束循环一致对抗网络的荧光显微镜三维盲图像反褶积方法。所提出的反卷积方法的恢复体积和其他众所周知的反卷积方法,去噪方法和不均匀性校正方法在视觉上和数字上进行评估。实验结果表明,该方法可以在视觉和数量上恢复和改善模糊和噪声深度深度显微图像的质量。 |
| Multi-modal 3D Shape Reconstruction Under Calibration Uncertainty using Parametric Level Set Methods Authors Moshe Eliasof, Andrei Sharf, Eran Treister 考虑到不确定的校准参数,我们考虑了多模态数据的三维形状重建问题。通常,3D数据模态可以是各种形式,例如稀疏点集,体积切片,2D照片等。为了共同处理这些数据模态,我们利用了一个利用椭圆体径向基函数的参数水平集方法。这种方法不仅允许我们分析和紧凑地表示物体,它还使我们能够克服源自不准确的采集参数的校准相关噪声。这种基本上隐含的正则化导致了高度稳健和可扩展的重建,超越了其他传统方法。在我们的结果中,我们首先展示了该方法紧凑地表示复杂对象的能力。然后,我们表明我们的重建方法对于少量测量和采集参数中的噪声都是稳健的。最后,我们通过各种模态展示了我们的重建能力,例如从类似于CTscans和XRays的液体位移获得的体积切片,以及从形状轮廓获得的视觉测量。 |
| HAUAR: Home Automation Using Action Recognition Authors Shashank Kotyan, Nishant Kumar, Pankaj Kumar Sahu, Venkanna Udutalapally 如今,部署的许多家庭自动化系统大多由人类控制。人的这种控制在一定程度上限制了家用电器的自动化。此外,大多数部署的家庭自动化系统使用物联网技术来控制设备。在本文中,我们提出了一个使用动作识别开发的系统,以使家用电器完全自动化。我们认识到一个人坐着,站立和躺着的三个动作以及对空房间的认可。在现实生活测试实验中,系统的准确度为90。通过该系统,我们消除了家庭自动化系统中用于控制家用电器的人为干预,同时我们通过有效和最佳地使用家用电器来确保数据隐私并降低能耗。 |
| Drishtikon: An advanced navigational aid system for visually impaired people Authors Shashank Kotyan, Nishant Kumar, Pankaj Kumar Sahu, Venkanna Udutalapally 今天,为视障人士部署的许多援助系统大多是为一个目的而制造的。无论是导航,物体检测还是距离感知。此外,大多数部署的辅助系统使用室内导航,这需要事先了解环境。在陌生的情况下,这些援助系统往往无法帮助视障人士。在本文中,我们提出了一种使用物体检测和深度感知开发的辅助系统来导航一个人而不会闯入一个物体。开发的原型检测90种不同类型的物体并计算它们与用户的距离。我们还实施了导航功能,以获取用户关于目标目的地的输入,从而使用Google Directions API将受损人员导航到其目的地。通过该系统,我们构建了一个多功能,高精度的导航辅助系统,可以在野外部署,通过毫不费力地将他们导航到他们想要的目的地,帮助视障人士在日常生活中。 |
| Monte-Carlo Tree Search for Efficient Visually Guided Rearrangement Planning Authors Sergey Zagoruyko, Yann Labb , Igor Kalevatykh, Ivan Laptev, Justin Carpentier, Mathieu Aubry, Josef Sivic 在本文中,我们解决了具有许多可移动物体的视觉引导重新布置规划的问题,即,找到一系列动作以将一组物体从初始布置移动到期望的布置,同时直接依赖来自相机的视觉输入。我们引入了一种有效且可扩展的重排规划方法,解决了大多数现有方法的基本限制,这些方法不能很好地适应对象的数量。这种提高的效率使我们能够在闭环中使用可视工作空间分析来构建强大的重排框架,从而可以从错误和外部扰动中恢复。这项工作的贡献有三个方面。首先,我们开发了一种类似AlphaGo的重排规划策略,使用从重新排列规划示例中训练的策略来提高蒙特卡罗树搜索MCTS的效率。我们凭经验证明,所提出的方法可以很好地适应对象的数量。其次,为了展示规划器在真实机器人上的效率,我们采用了最先进的校准自由视觉识别系统,该系统输出单个物体的位置并对其进行扩展以估计包含多个物体的工作空间的状态。第三,我们通过在真实的UR 5机器人手臂上进行多次实验来验证整个管道,解决了多个可移动物体的重排规划问题,并且只需要几秒钟的计算来计算计划。我们还凭经验证明机器人可以成功地从工作空间中的错误和扰动中恢复。我们的工作的源代码和预训练模型可在以下位置获得 |
| Improving benchmarks for autonomous vehicles testing using synthetically generated images Authors Aleksander Lukashou 如今,自主技术是一个经过深度探索的领域,特别是计算机视觉作为车辆感知的主要组成部分。基于神经网络的整个视觉系统的质量依赖于它所训练的数据集。从世界上大多数县找到交通标志数据集是极其困难的。意味着来自美国的自动驾驶车辆将无法驾驶,但立陶宛在途中识别出所有道路标志。在本文中,我们提出了一个解决方案,如何使用来自国家车辆的小型数据集来更新模型。重要的是要提到的不是灵丹妙药,而是小型升级,可以在数据有限的国家推动自动驾驶汽车的发展访问。我们实现了约10%的质量提升,并期望在未来的实验中获得更好的结果。 |
| End-to-end Sleep Staging with Raw Single Channel EEG using Deep Residual ConvNets Authors Ahmed Imtiaz Humayun, Asif Shahriyar Sushmit, Taufiq Hasan, Mohammed Imamul Hassan Bhuiyan 人类大约三分之一的时间都在睡觉,这使得监控睡眠成为健康的一个组成部分。在本文中,提出了一种用于端到端睡眠分期的34层深度残余ConvNet架构。网络将原始单通道脑电图Fpz Cz信号作为输入,并将每个30s段的睡眠图注释作为输出。在扩展的PhysioNet睡眠EDF数据集上对两个不同的评分标准5和6阶段分类进行实验,其包含来自医院和家庭多导睡眠图设置的多源数据。将所提出的网络的性能与患者独立验证任务中的现有技术的性能进行比较。实验结果表明,与现有的最佳方法相比,所提出的网络具有优越性,分别为家庭数据和多源数据提供了6.8和6.3的时期平均准确度的相对改善。代码在Github上公开发布。 |
| A new Edge Detector Based on Parametric Surface Model: Regression Surface Descriptor Authors R mi Cogranne, R mi Slysz, Laurence Moreau, Houman Borouchaki 在本文中,我们提出了一种新的数字图像边缘检测方法。所提出方法的第一个原创性是将图像内容视为参数表面。然后,提出了表示图像内容的该表面的原始参数局部模型。所提出的模型中涉及的少数参数被示出对表面中的不连续性非常敏感,其对应于图像内容中的边缘。这自然导致了有效边缘检测器的设计。此外,对所提出的模型的全面分析还允许我们解释如何使用这些参数来获得边缘描述符,例如方向和曲率。 |
| Non-convex Penalty for Tensor Completion and Robust PCA Authors Tao Li, Jinwen Ma 在本文中,我们提出了一种新的非凸张量等级代理函数和一个新的张量非凸稀疏度量。基本思想是通过引入凹陷来回避ell 1范数的偏差。此外,我们在张量恢复问题中采用所提出的非凸罚分,例如张量完成和张量鲁棒主成分分析,其具有各种实际应用,例如图像修复和去噪。由于凹度,模型很难解决。为了解决这个问题,我们设计了主要化最小化算法,它们优化了每次迭代中原始函数的上界,并且每个子问题都通过交替方向乘法器方法来解决。最后,自然图像和高光谱图像的实验结果证明了所提方法的有效性和有效性。 |
| Spatio-temporal crop classification of low-resolution satellite imagery with capsule layers and distributed attention Authors John Brandt 低分辨率空间图像的土地利用分类是遥感领域研究最广泛的领域之一。尽管卫星技术取得了重大进展,但高分辨率图像缺乏全球覆盖,并且在长时间内采购可能会非常昂贵。在没有高分辨率图像的情况下准确分类土地利用变化,有可能监测全球发展议程的重要方面,包括气候智能农业,抗旱作物和可持续土地管理。利用胶囊层和长短期记忆层的组合以及分布式注意力,本文利用Sentinel 2图像以30x30m分辨率实现了时间作物类型分类的现有技术精确度。 |
| Multiview Hessian Regularization for Image Annotation Authors Weifeng Liu, Dacheng Tao 计算机硬件和互联网技术的快速发展使得大规模数据依赖模型在计算上易于处理,并且通过创新的机器学习算法为注释图像开辟了一条明亮的途径。因此,半监督学习SSL近年来受到了广泛的关注,并且已经成功地部署在图像标注中。 SSL中的一个代表性工作是拉普拉斯正则化LR,其平滑条件分布沿着拉普拉斯图中编码的流形进行分类,然而,已经观察到LR将分类函数偏向于恒定函数,这可能导致不良的泛化。此外,LR被开发用于处理均匀分布的数据或单个视图数据,尽管实例或对象(例如图像和视频)通常由多视图特征(例如颜色,形状和纹理)表示。在本文中,我们提出了多视图Hessian正则化mHR来解决基于LR的图像标注中的上述两个问题。特别地,mHR最佳地组合多个Hessian正则化,每个Hessian正则化从特定的实例视图获得,并且控制沿着数据流形线性变化的分类函数。我们将mHR应用于核最小二乘和支持向量机作为图像注释的两个示例。 PASCAL VOC 07数据集的大量实验通过将其与基线算法(包括LR和HR)进行比较来验证mHR的有效性。 |
| Bold Hearts Team Description for RoboCup 2019 (Humanoid Kid Size League) Authors Marcus M. Scheunemann, Sander G. van Dijk, Rebecca Miko, Daniel Barry, George M. Evans, Alessandra Rossi, Daniel Polani 我们参加了蒙特利尔的RoboCup 2018年比赛,我们新开发的BoldBot基于Darwin OP,主要是自行打印的定制部件。本文是关于从竞争中获得的经验教训以及RoboCup 2019竞赛的进一步发展。首先,我们简要介绍团队以及过去成就的概述。然后,我们提出了一个简单的独立2D模拟器,用于简化新成员的入口,使基本的RoboCup概念可以快速访问。我们描述了我们在2018年竞赛中使用的视觉的语义分割方法,该方法取代了我们之前使用的查找表LUT实现。我们还讨论了我们计划添加到BoldBot打印部分的额外结构支持以及我们向ROS 2过渡作为我们的新中间件。最后,我们将介绍我们团队的一系列开源贡献。 |
| The Profiling Potential of Computer Vision and the Challenge of Computational Empiricism Authors Jake Goldenfein 计算机视觉和其他生物识别数据科学应用程序已经开始了一个新的人物剖析项目。这些系统不是使用交易生成的信息,而是衡量现实世界,并在这种情况下对世界状态进行评估,评估某些个体特征。他们不再使用代理或分数来评估人,而是越来越多地使用逻辑来揭示关于现实及其中的人的真相。虽然这些剖析知识主张有时是暂时性的,但它们越来越多地表明,只有通过计算才能捕捉和理解这些过度的现实。本文探讨了计算机视觉中部署的测量,表示和分类系统中这些主张的基础。它询问这种类型的知识主张是否有新的东西,勾勒出一种新的计算经验主义形式的运作,并质疑这些技术系统和实践正在构建什么样的人类主体。最后,本文探讨了将计算经验主义的出现作为理解世界及其中人的主导知识平台的法律机制。 |
| A Fast, Semi-Automatic Brain Structure Segmentation Algorithm for Magnetic Resonance Imaging Authors Kevin Karsch, Qing He, Ye Duan 医学图像分割已成为临床和研究应用中的基本技术。由于手动分割方法繁琐,全自动分割缺乏人为干预或矫正的灵活性,半自动方法已成为医学图像分割的首选方式。我们提出了一种3D混合半自动分割方法,它集成了基于区域和基于边界的过程。我们的方法与以前的混合方法的不同之处在于我们分别执行基于区域和基于边界的方法,这允许更有效的分割。基于区域的技术用于生成初始种子轮廓,其粗略地表示目标脑结构的边界,从而减轻后续模型变形阶段中的局部最小问题。轮廓在独立于图像边缘的独特力方程下变形。 MRI数据的实验表明,该方法主要由于独特的种子初始化技术,可以实现高精度和高效率。 |
| Web Based Brain Volume Calculation for Magnetic Resonance Images Authors Kevin Karsch, Brian Grinstead, Qing He, Ye Duan 脑容量计算在现代医学研究中是至关重要的,特别是在神经发育障碍的研究中。在本文中,我们提出了一种计算脑容量,总脑容量TBV和颅内容积ICV两种分类的算法。我们的算法将MRI数据作为输入,执行多个预处理和中间步骤,然后返回两个计算量中的每一个。为了简化此过程并使我们的算法可供任何人公开访问,我们创建了一个基于Web的界面,允许用户上传自己的MRI数据并计算给定数据的TBV和ICV。该界面为计算这两种脑容量分类提供了一种简单有效的方法,同时也消除了用户下载或安装任何应用程序的需要。 |
| Joint Domain Alignment and Discriminative Feature Learning for Unsupervised Deep Domain Adaptation Authors Chao Chen, Zhihong Chen, Boyuan Jiang, Xinyu Jin 最近,相当大的努力致力于计算机视觉和机器学习社区中的深度域适应。但是,大多数现有工作仅通过最小化不同域之间的分布差异来集中于学习共享特征表示。由于所有域对齐方法都只能减少,但不能消除域移位。分布在簇的边缘附近或远离其对应的类中心的目标域样本很容易被从源域学习的超平面错误分类。为了缓解这个问题,我们建议联合域对齐和判别特征学习,这有利于域对齐和最终分类。具体地,提出了基于实例的判别特征学习方法和基于中心的判别特征学习方法,两者都保证了域不变特征具有更好的类内紧致性和类间可分性。大量实验表明,学习共享特征空间中的判别特征可以显着提高深域自适应方法的性能。 |
| Chinese Abs From Machine Translation |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}