
【今日CV 计算机视觉论文速览 第105期】Thu, 25 Apr 2019
今日CS.CV 计算机视觉论文速览
Thu, 25 Apr 2019
Totally 31 papers
👉上期速览✈更多精彩请移步主页

Interesting:
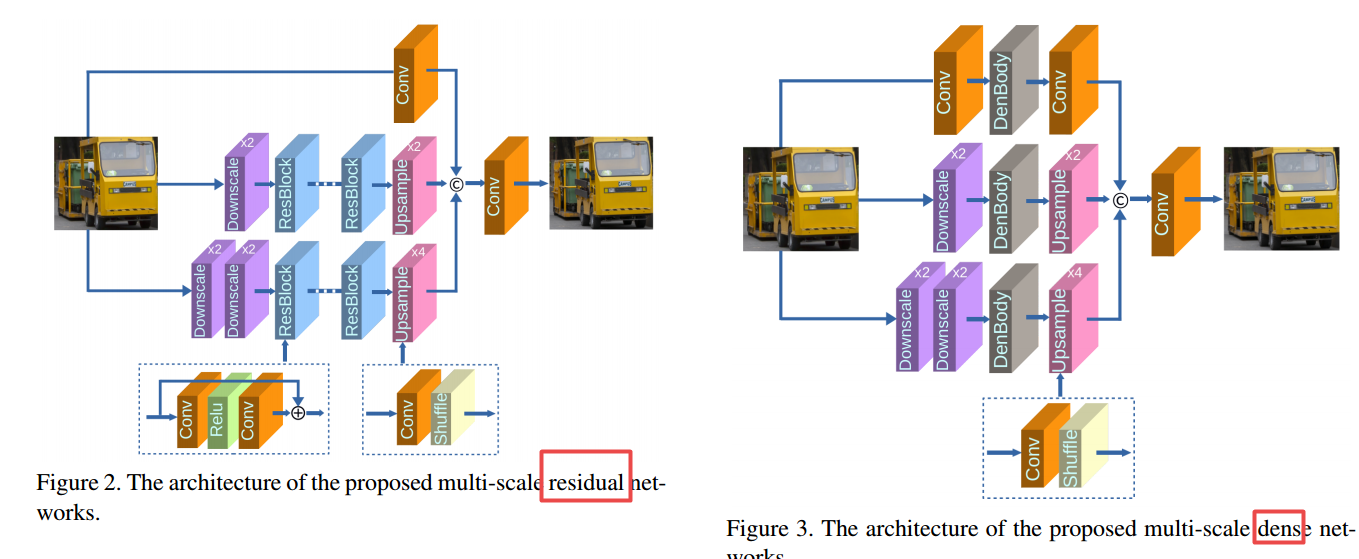
📚MsDNN多尺度图像超分辨, 两个降采样的低分辨空间中首先处理以减小计算量,随后利用多尺度残差块来处理图像,并比较了多尺度稠密连接块的性能。(from 复旦)
提出的两种多尺度模型:
code:https://github.com/shangqigao/gsq-image-SR
ref:NTIRE 超分辨挑战赛:https://competitions.codalab.org/competitions/21439
ntire:http://www.vision.ee.ethz.ch/ntire19/
📚基于图像方法检测恶意软件, 通过将恶意软件的二进制文件作为图像处理,减小了特征工程的难度,并利用大规模图像分类的方法来实现有效的恶意软件检测。作者从有效性、可靠性和恢复性等方面阐述了这一新的研究视角。(from 英特尔)
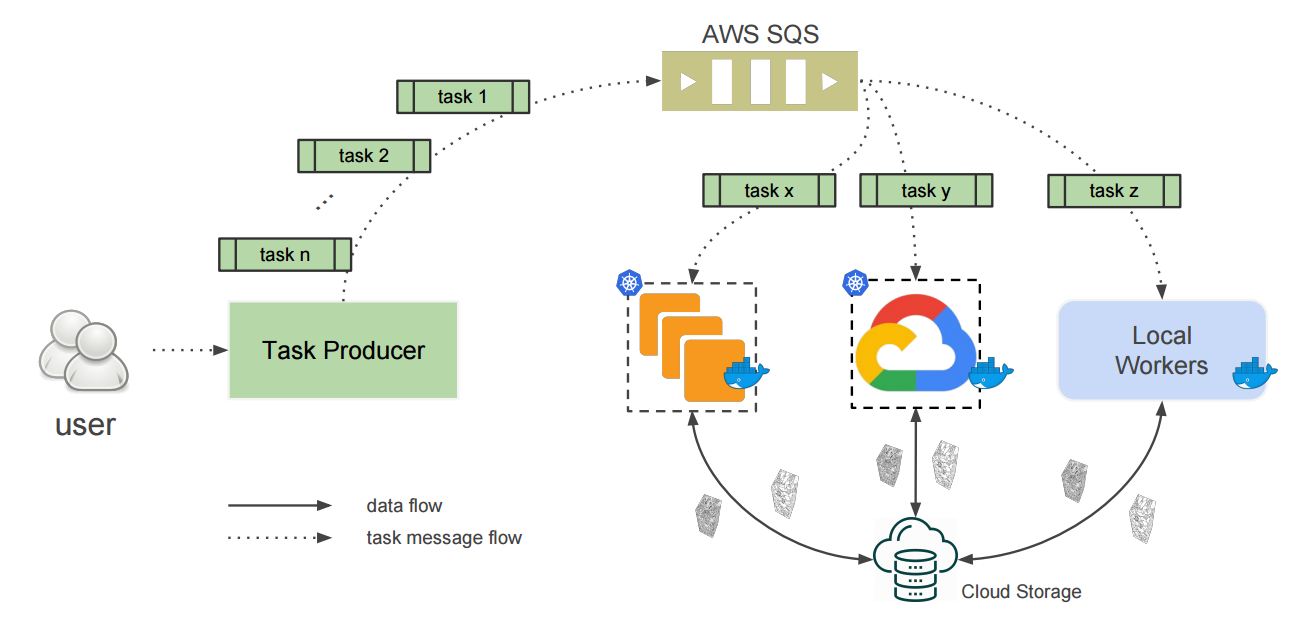
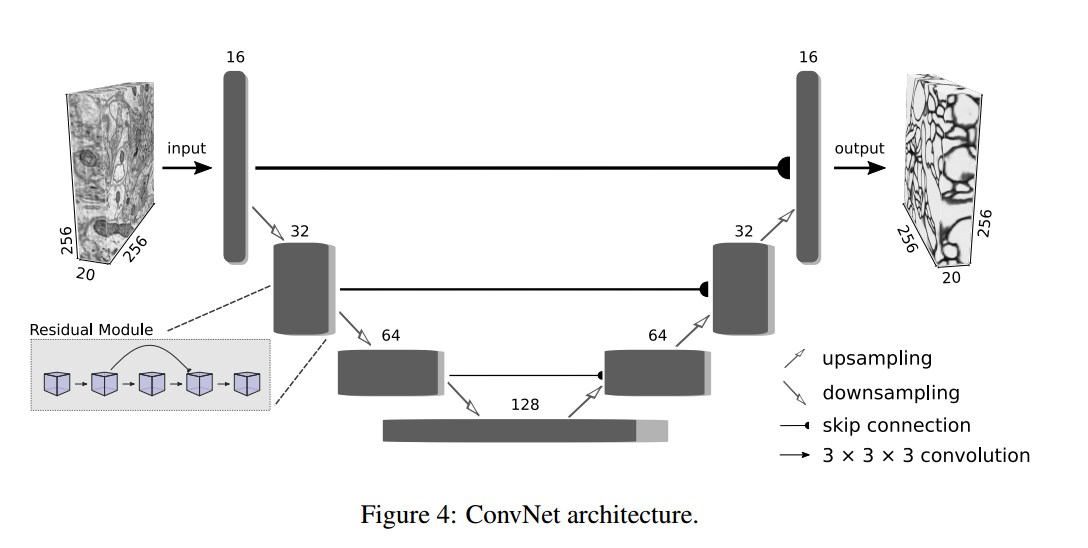
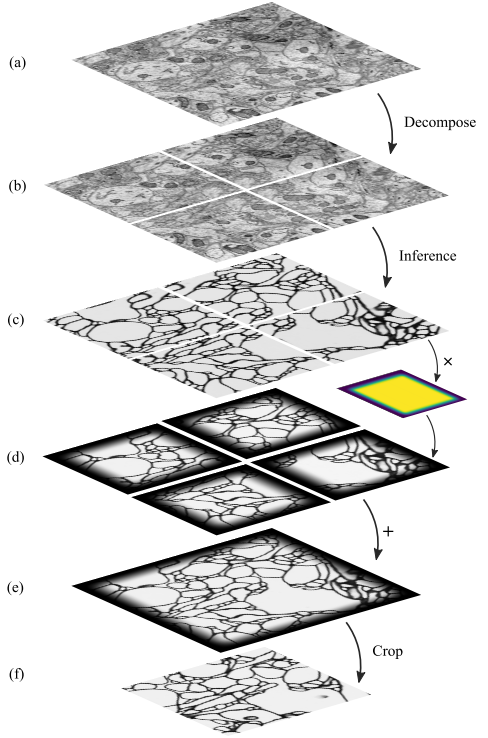
📚CHUNKFLOW, 大规模混合云处理大型3D图像卷积,用于处理医疗图像中T,P级数据。通过将图像体分为有重叠的chunk,并利用分布式卷积进行处理而后融合得到最终结果,实现了大规模数据的高性能处理。(from 普林斯顿)
系统架构图:
一个实际的例子和数据处理流程:
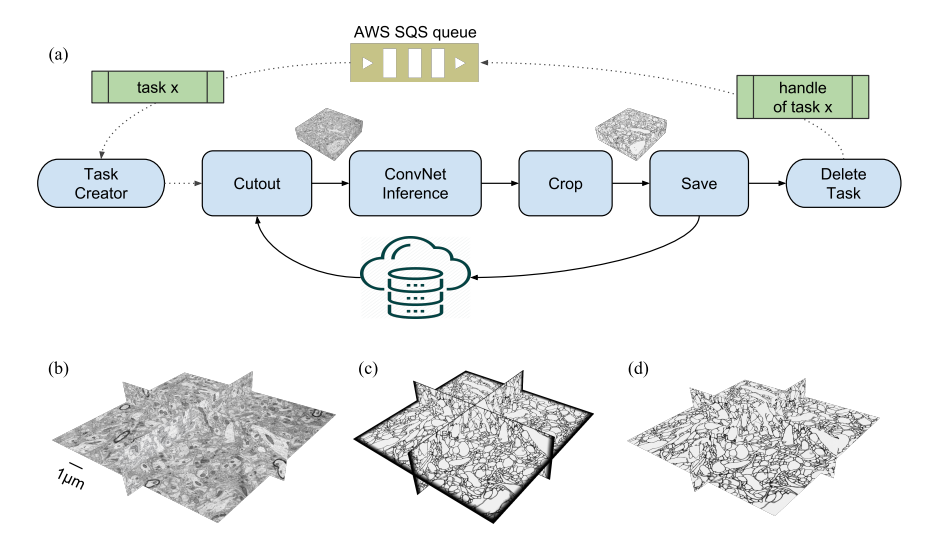
典型的处理架构和图像分片处理流程:
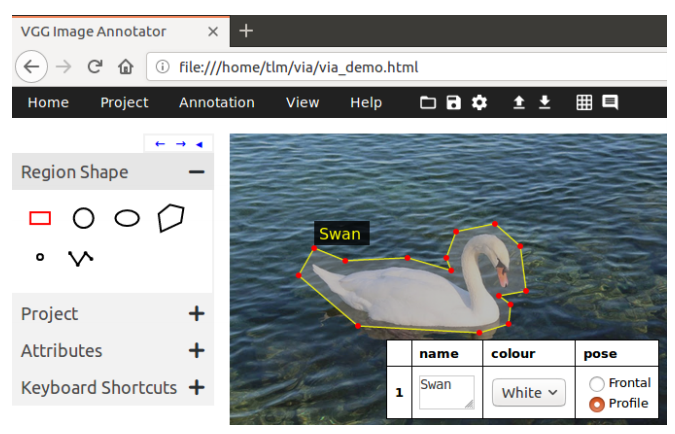
📚VIA,VGG Image Annotator, 来自牛津VGG组推出的标注工具,一个轻量化的基于web的标注工具,在学术界和工业界得到了广泛应用。(from 牛津大学)
简单的界面:
不同的标注类型:

多样化设置:
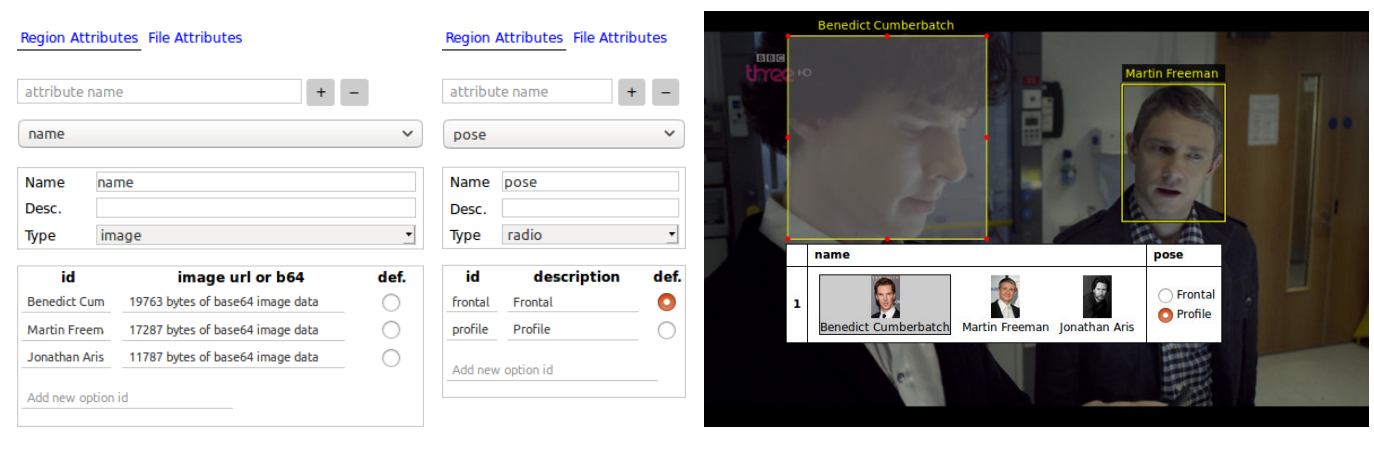
还可以从url导入数据集,带有自动人脸捕捉和纠错功能。可用于视频等多种形态数据,广泛可用的插件。
code:http://www.robots.ox.ac.uk/~vgg/software/via/via_wikimedia_demo.html
2http://www.robots.ox.ac.uk/~vgg/software/via/via-0.0.1.html (add “.txt” suffix to view source code)
3https://gitlab.com/vgg/via/blob/master/CodeDoc.md
4https://gitlab.com/vgg/via
类似的工具MIT labelMe:http://labelme.csail.mit.edu/Release3.0/
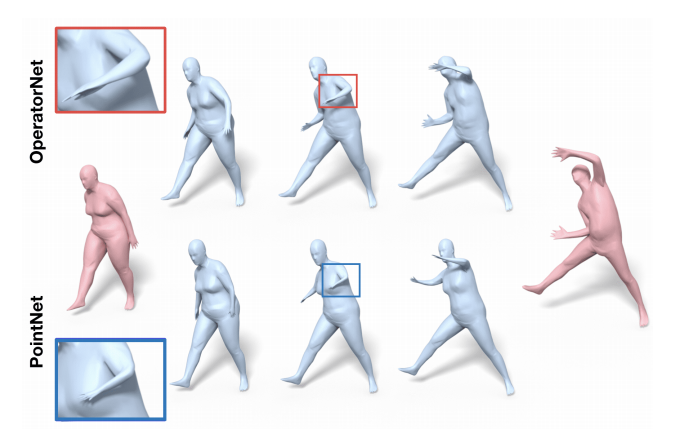
📚OperatorNet:基于不同操作子恢复三维形貌, (from 巴黎综合理工大学)
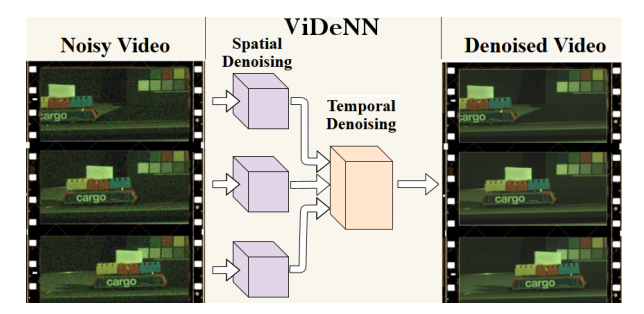
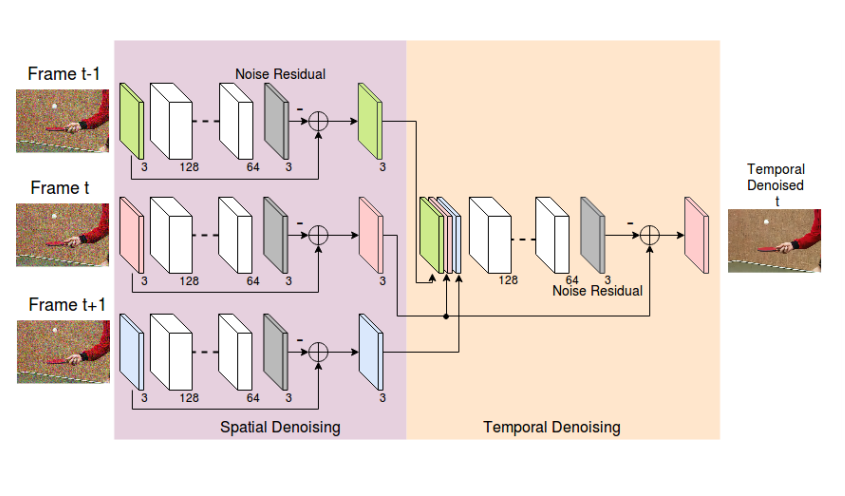
📚ViDeNN视觉盲去噪, 分别在每一帧上进行空间去噪,在三个连续帧上进行时间去噪。两个过程都是基于残差的方法进行处理(from 代尔夫特理工)
去噪的结果,表面残差去噪很有效:

code:http://jvgemert.github.io/
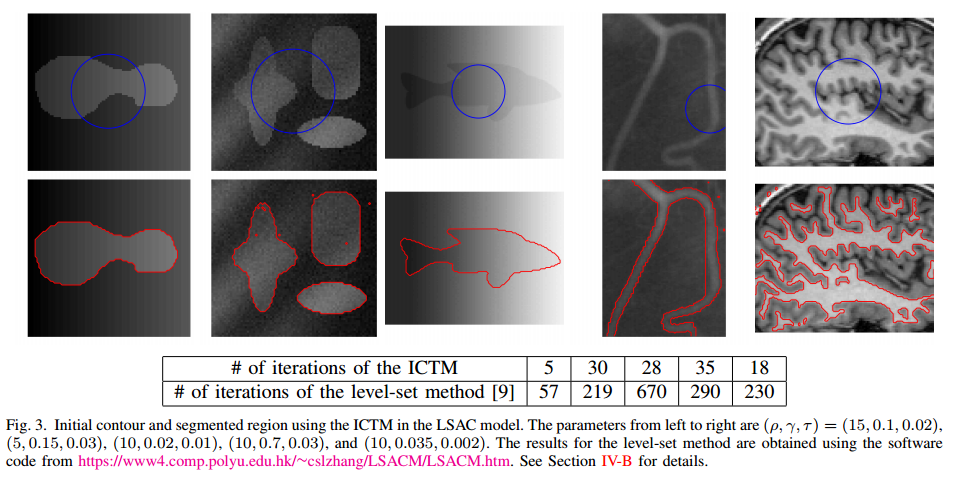
📚ICTM,迭代卷积阈值法用于图像分割, 一种包含了保真项和正则项的能量最小化函数。在ICTM中两个物体的边界隐式的表示为他们的特征方程。保真项由特征方程的线性组合构成,而正则项则由热核卷积构成。(from 犹他州立大学)

初始化和迭代后的分割:
code:https://www.math.utah.edu/~dwang/ICTM_CV.zip
http://www.imagecomputing.org/~cmli/code/
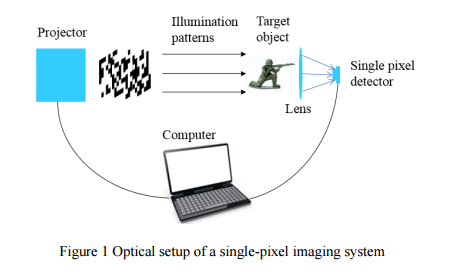
📚基于单像素和相干光的光学机器学习, (from 深圳大学)
通过多次不同模式下对物体的照明,单像素相机可以收集重建出物体的图像,并实现识别。
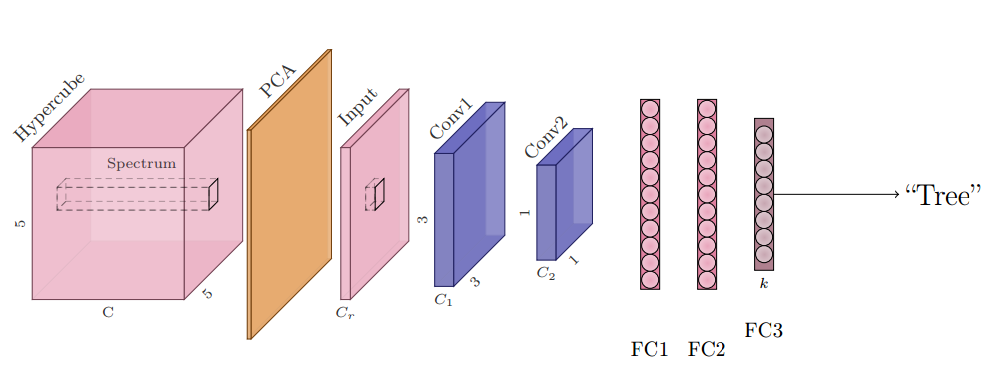
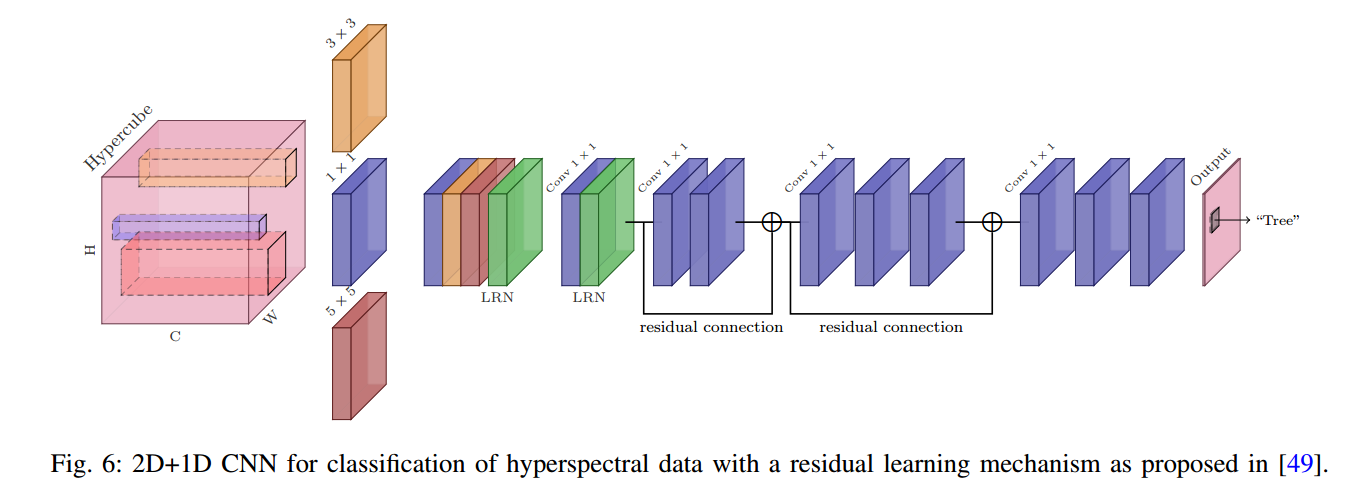
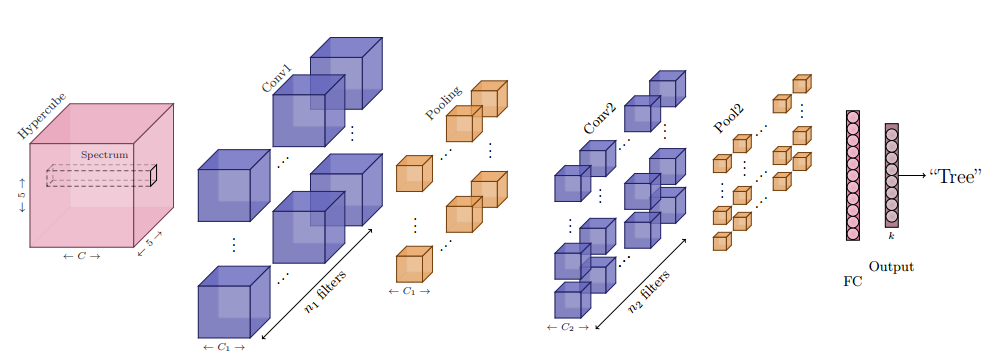
📚**超光谱数据分类问题综述, (from University Paris Saclay)
典型的超光谱图像:

二维模型,二加一维模型,
不同方法及其结果:

code:https://github.com/nshaud/DeepHyperX
📚HMD方法单幅图像恢复人体形貌, (from 南京大学)
模型架构包含了关节、锚点和顶点三部分:
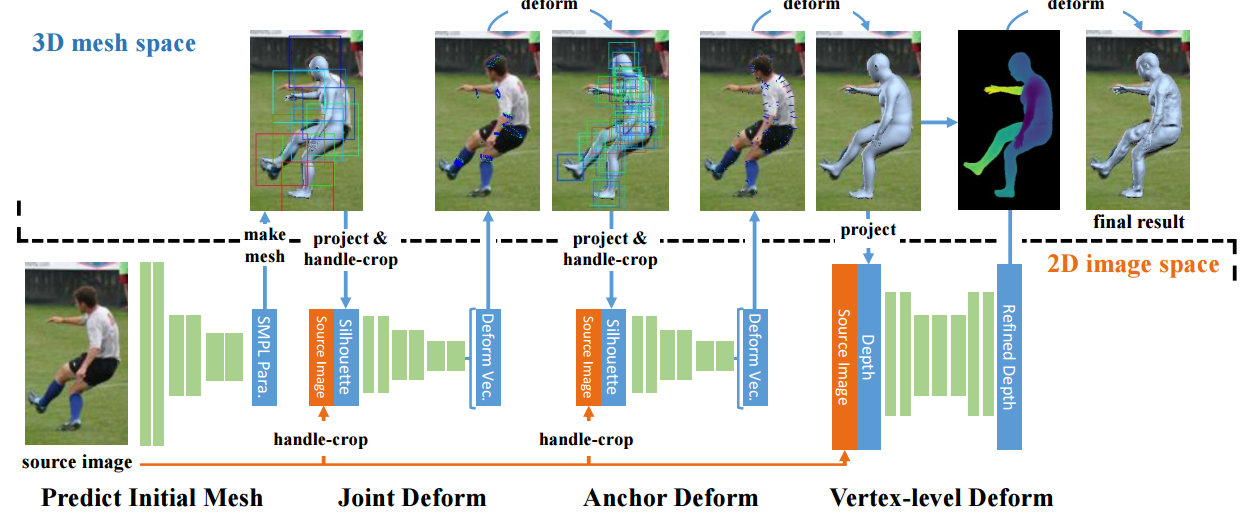
code:n https://github.com/zhuhao-nju/hmd.git.
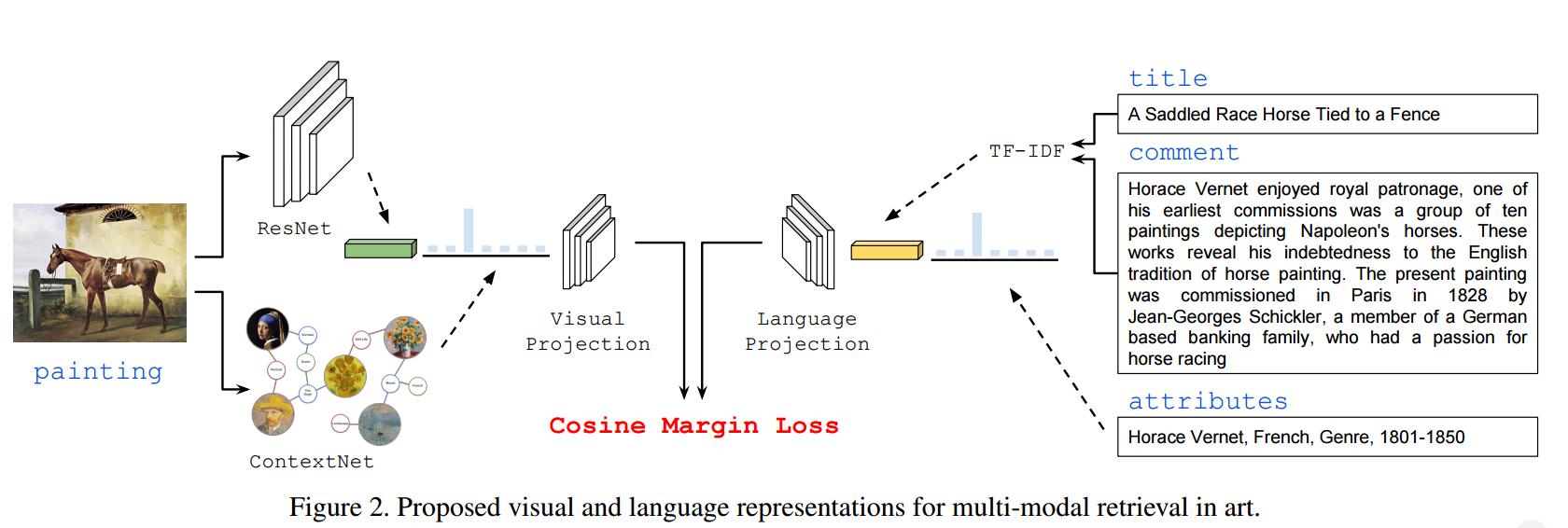
📚利用多模态检索理解艺术, 同时分析了视觉美学和语义信息。(from 大阪大学)
用于多模态检索的视觉语言表示:
dataset:SemArt http://noagarciad.com/SemArt/
from web Gallery of art: https://www.wga.hu/
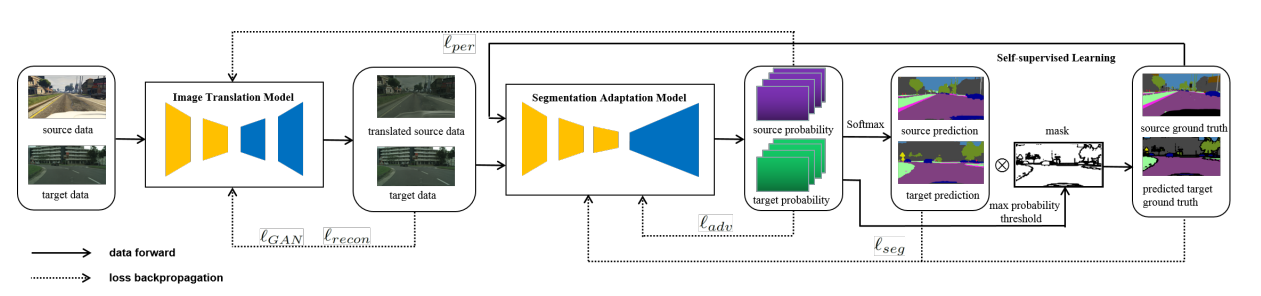
📚基于双向学习的域自适应语义分割, 联合图像迁移模型和分割适应模型实现。(from ucsd)
与相关方法的对比:
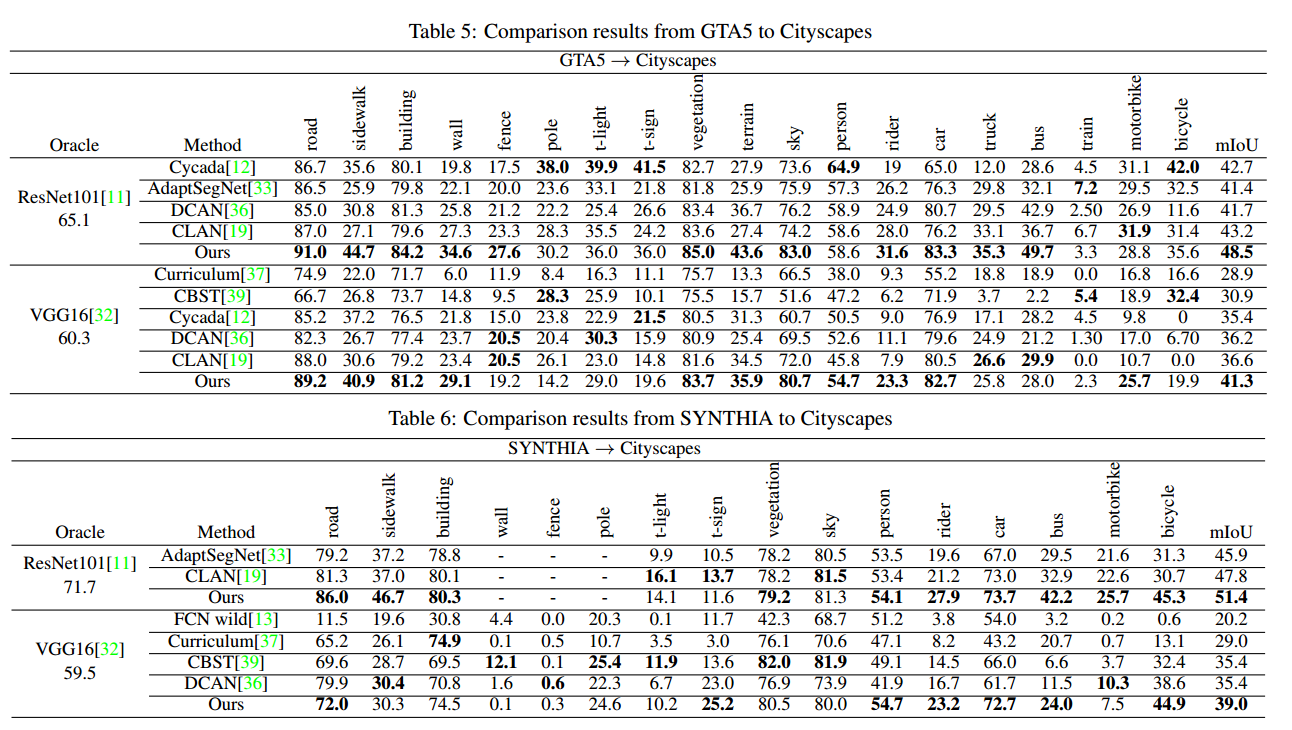
code: https://github.com/liyunsheng13/BDL.
dataset:GTA5 [27] and SYHTHIA [28] CITYSCAPE [5], CamVid [1]).
📚Light and Fast Face Detector,LFFD, 一个高效的边缘设备人脸检测架构实现,在TX2上实现136.99pfs,树莓派3 b+上以9M的模型实现了8.44fps(from 北京工业大学)
在不同尺度上检测,分为四个部分八个loss分支:
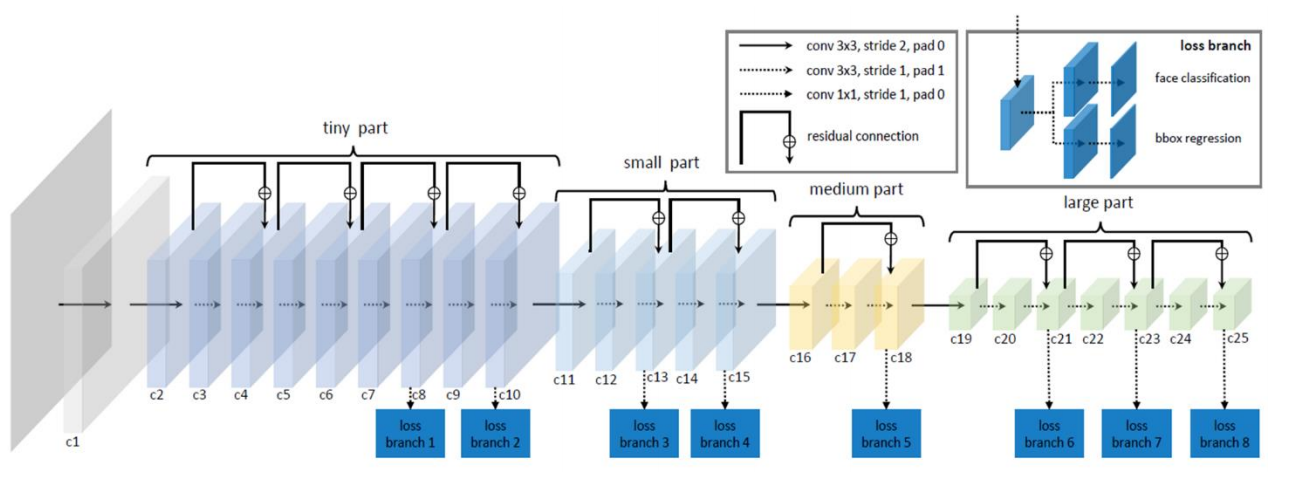
dataset: WIDER FACE and FDDB
一些移动端优化库:
——————————
https://developer.nvidia.com/cudnn
https://github.com/Tencent/ncnn
https://github.com/XiaoMi/mace
https://github.com/PaddlePaddle/paddle-mobile
📚Segmenting the Future视频序列预测未来语义分割, (from 斯坦福)
利用可训练的学生和预训练的教师网络的模式进行学习:
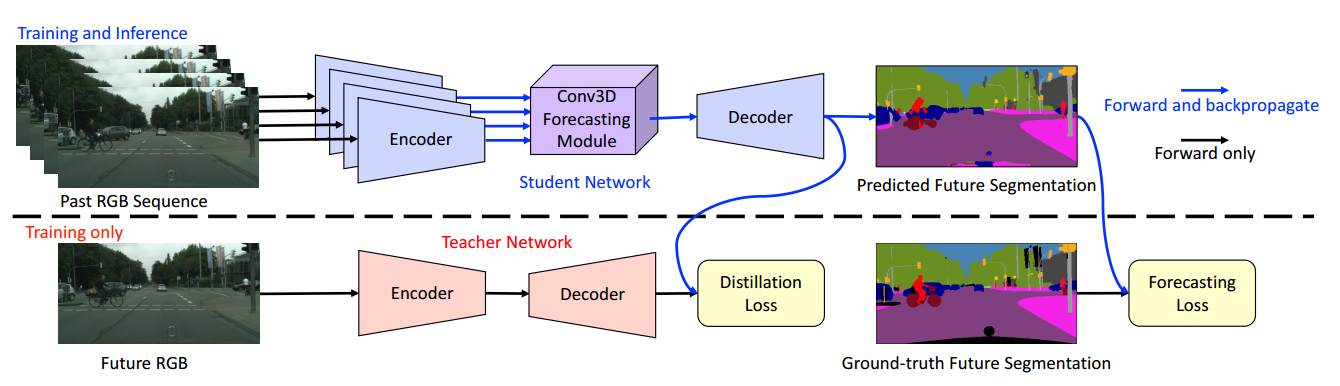
code: https://github.com/eddyhkchiu/segmenting_the_future/.
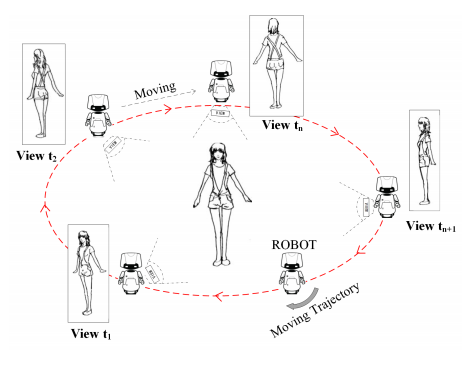
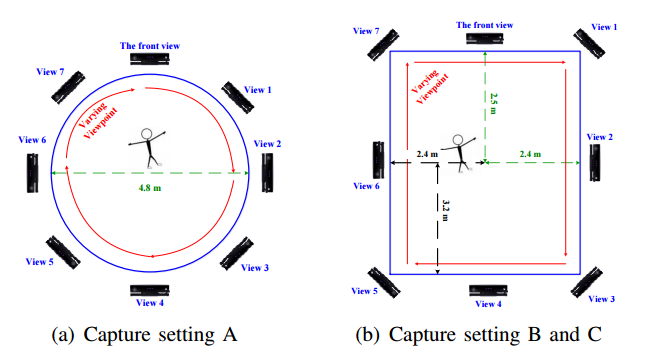
📚大规模多视角的人体行为识别RGBD数据集, 包含了8个固定视角和360度的移动序列,供118个人40个动作25600个视频。并提出了测评基准View-guided Skeleton-CNN (VSCNN)。(from 成电)
八个不同视点:
VS-CNN网络架构:
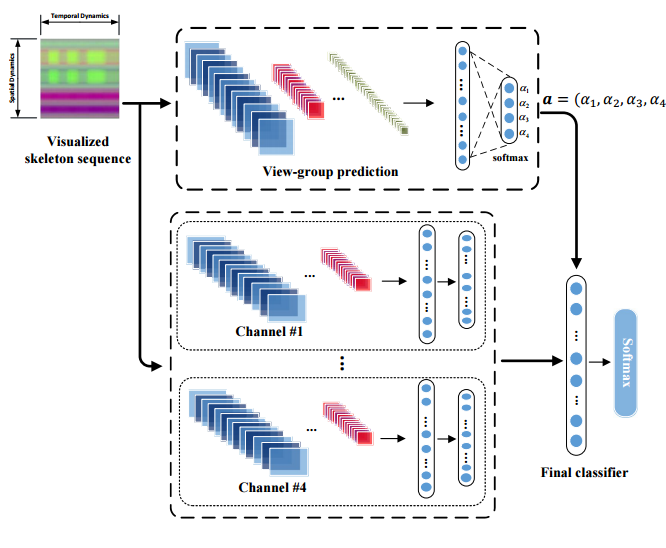
dataset:https://github.com/HRI-UESTC/CFMHRI-RGB-D-action-database
ref:Act4:http://mocap.cs.cmu.edu
SK-CNN,View-guided Skeleton-CNN (VSCNN)
📚基于RNN-CNN多标签天气预测, 利用多标签分类任务来实现单图像天气识别。(from OPTIMAL)
不同天气情况照片和判断天气的重要部分:


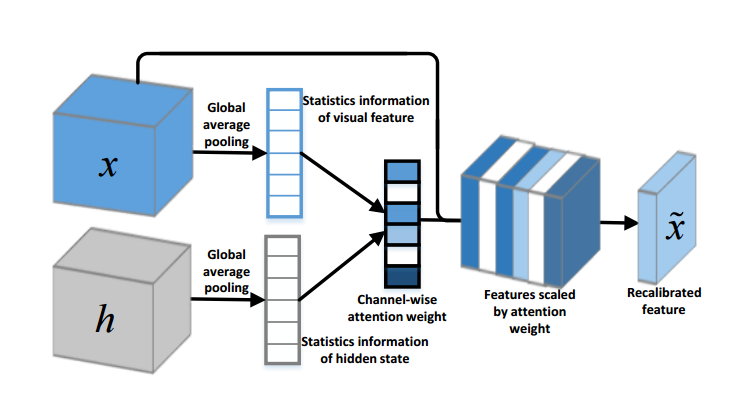
CNN-RNN网络架构和通道注意力:
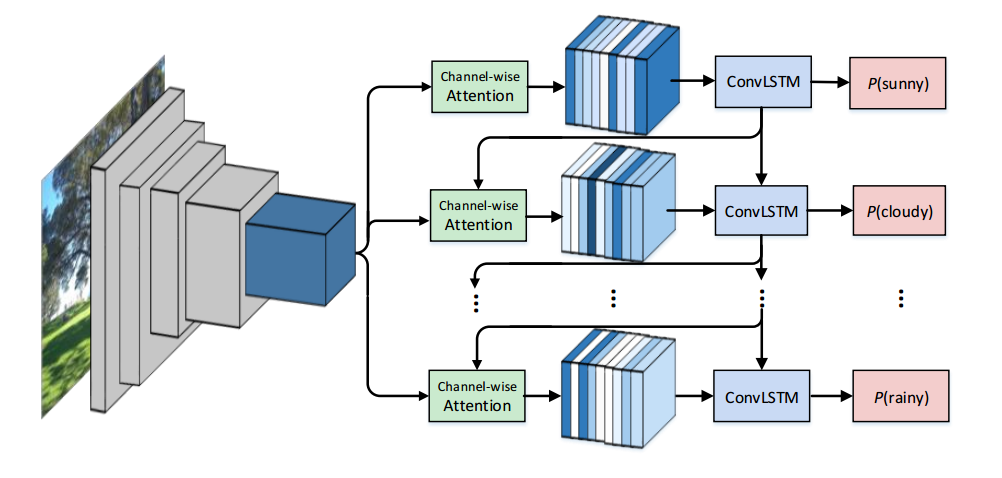
code: https://github.com/wzgwzg/Multi-Label-Weather-Recognition.
dataset:Transient attributes for highlevel understanding and editing of outdoor scenes
📚CED彩色事件相机数据集, 包含了50mins的彩色事件相机记录,包含室内室外场景。并提出了事件相机模拟器ESIM(from 澳大利亚国立)


dataset:http://rpg.ifi.uzh.ch/CED
ref:
ColorDAVIS346,驱动 https://github.com/uzh-rpg/rpg_dvs_ros
ESIM:“ESIM: an openevent camera simulator,”
模拟器:https://github.com/uzh-rpg/rpg_esim
重建方法:https://github.com/VLOGroup/dvs-reconstruction
https://github.com/cedric-scheerlinck/dvs_image_reconstruction
Daily Computer Vision Papers
| The iterative convolution-thresholding method (ICTM) for image segmentation Authors Dong Wang, Xiao Ping Wang 在本文中,我们提出了一种新的迭代卷积阈值方法ICTM,适用于一系列用于图像分割的变分模型。变分模型通常最小化由保真度项和正则化项组成的能量函数。在ICTM中,两个不同的分段域之间的接口由它们的特征函数隐含地表示。然后,保真度项通常被写为特征函数的线性函数,并且正则化项通过热核卷积方面的特征函数的函数来近似。这允许我们设计迭代卷积阈值方法以最小化近似能量。该方法简单,高效,具有能量衰减性能。数值实验表明,该方法易于实现,鲁棒性强,适用于各种图像分割模型。 |
| ViDeNN: Deep Blind Video Denoising Authors Michele Claus, Jan van Gemert 我们建议ViDeNN使用CNN进行视频去噪,而无需事先了解噪声分布盲去噪。 CNN架构使用空间和时间滤波的组合,学习首先对帧进行空间去噪,同时如何组合它们的时间信息,处理对象运动,亮度变化,低光条件和时间不一致。我们证明了用于CNN培训的数据的重要性,为此目的创建了一个针对弱光条件的特定数据集。我们在常用基准测试和自我收集的数据上测试ViDeNN,获得与现有技术相当的良好结果。 |
| Optical machine learning with incoherent light and a single-pixel detector Authors Shuming Jiao, Xiang Li, Zibang Zhang, Yang Gao, Ting Lei, Zhenwei Xie, Xiaocong Yuan 最近提出了光学衍射神经网络DNN的概念,其通过级联相位掩模架构实现。与光学计算机一样,该系统可以以全光学方式执行诸如数字识别之类的机器学习任务。但是,该系统只能在相干光照下工作,实际实验中的精度要求很高。本文提出了一种基于单像素成像MLSPI的光学机器学习框架。 MLSPI系统可以执行与DNN相同的线性模式识别任务。此外,它可以在非相干光照条件下工作,具有较低的实验复杂性并且易于编程。 |
| Automatic cephalometric landmarks detection on frontal faces: an approach based on supervised learning techniques Authors Lucas Faria Porto, Laise Nascimento Correia Lima, Marta Flores, Andrea Valsecchi, Oscar Ibanez, Carlos Eduardo Machado Palhares, Flavio de Barros Vidal 面部标志被用于许多研究领域,如面部识别,颅面识别,年龄和性别评估等最重要的。在法医领域,重点是分析一组特定的面部标志,定义为头部测量标志。以前的工作表明,这些解剖学参考文献对间接应用照片人体测量学描述的描述性充分性提高了这些点的标记精度,有助于提高这些分析的可靠性。但是,大多数都是手动执行的,所有这些都是专家审查员固有的主观性。从这个意义上讲,这项工作的目的是开发和验证自动技术,以从法医领域的正面数字图像中检测头部测量标志。所提出的方法在监督学习过程中使用计算机视觉和图像处理技术的组合。所提出的方法获得与一组人类手动头部测量参考标记相似的精确度,并且结果对于其他现有技术的面部标志检测框架更加准确。它实现了像素误差的归一化平均距离0.014,类似于平均专家间离差0.009,并且明显优于其他自动方法,也分析了这项工作0.026和0.101。 |
| Simultaneous regression and feature learning for facial landmarking Authors Janez Kri aj, Peter Peer, Vitomir truc, Simon Dobri ek 面部对齐或面部标记是许多面部相关应用中的重要任务,从注册,跟踪和动画到更高级别的分类问题,例如面部,表情或属性识别。虽然到目前为止已经在文献中提出了用于该任务的若干解决方案,但是在各种各样的位置上可靠地定位显着的面部特征仍然是具有挑战性的。为了解决这个问题,我们在本文中提出了一种用于3D面部数据中自动面部标志定位的新方法,该3D面部数据专门用于解决由显着的姿势变化引起的外观变化。我们的方法建立在最近基于级联回归的面部标记方法的基础上,并使用门控机制将多个线性级联回归模型结合到一个能够处理任意构成输入数据的强大的标记模型中,每个线性级联回归模型都针对有限范围的姿势进行训练。我们针对所提出的选通机制开发了两种不同的方法,第一种方法是使用门控多脊下降GRID机制,结合已建立的手工制作HOG特征进行面部对齐,并在各种面部姿势中实现最先进的地标性能,ii第二个同时学习多个下降方向以及最适合对齐任务的二元特征SMUF,除了竞争性的标志性结果外,还确保了极快的处理速度。我们在几个流行的3D人脸图像数据集的严格实验中评估两种方法,即来自圣母大学的FRGCv2和Bosphorus 3D Face数据集以及图像集合F和G.我们的评估结果表明,与现有技术相比,这两种方法都具有竞争力,同时对姿势变化表现出相当大的稳健性。 |
| Informative sample generation using class aware generative adversarial networks for classification of chest Xrays Authors Behzad Bozorgtabar, Dwarikanath Mahapatra 由于覆盖不同疾病类型和严重程度的有限图像,培训用于医学图像的疾病检测的强大深度学习DL系统是具有挑战性问题尤其严重,严重的阶级不平衡。我们提出了一个主动学习AL框架来选择大多数信息样本,以便使用贝叶斯神经网络训练我们的模型。然后在新颖的类感知生成对抗网络CAGAN中使用信息性样本,通过将特征从一个类标签转移到另一个类标签来生成用于数据增强的真实胸部X射线图像。实验表明,我们提出的AL框架能够通过使用大约35个完整数据集来实现最先进的性能,从而比传统方法节省了大量的时间和精力。 |
| CED: Color Event Camera Dataset Authors Cedric Scheerlinck, Henri Rebecq, Timo Stoffregen, Nick Barnes, Robert Mahony, Davide Scaramuzza 事件相机是新颖的生物灵感视觉传感器,其像素在局部强度变化时输出异步和独立的时间戳尖峰,称为事件。在延迟,高动态范围HDR和时间分辨率方面,事件相机提供优于传统基于帧的相机的优势。直到最近,事件相机一直限于在强度通道中输出事件,然而,最近的进步导致彩色事件相机的开发,例如Color DAVIS346。在这项工作中,我们展示并发布了第一个彩色事件相机数据集CED,其中包含50分钟的彩色帧和事件镜头。 CED具有各种室内和室外场景,我们希望这将有助于推动基于事件的视觉研究。我们还提供了事件相机模拟器ESIM的扩展,可以模拟颜色事件。最后,我们提出了三种最先进的图像重建方法的评估,可用于将Color DAVIS346转换为连续时间,HDR,彩色视频摄像机以可视化事件流,并用于下游视觉应用。 |
| A CNN-RNN Architecture for Multi-Label Weather Recognition Authors Bin Zhao, Xuelong Li, Xiaoqiang Lu, Zhigang Wang 天气识别在我们的日常生活和许多计算机视觉应用中发挥着重要作用。然而,从单个图像中识别天气条件仍然具有挑战性,并且尚未彻底研究。通常,大多数先前的作品将天气识别视为单个标签分类任务,即,确定图像是否属于特定的天气等级。这种处理并不总是合适的,因为在单个图像中可能同时出现多个天气条件。为了解决这个问题,我们首次尝试将天气识别视为多标签分类任务,即根据所显示的天气条件为多个标签分配图像。具体而言,本文提出了一种基于CNN RNN的多标签分类方法。卷积神经网络CNN通过渠道智能关注模型进行扩展,以提取最相关的视觉特征。递归神经网络RNN进一步处理特征并挖掘天气类之间的依赖关系。最后,一步一步地预测天气标签。此外,我们为天气识别任务构建了两个数据集,并探索了不同天气条件之间的关系。实验结果证明了该方法的优越性和有效性。新构建的数据集将在 |
| The VGG Image Annotator (VIA) Authors Abhishek Dutta, Andrew Zisserman 手动图像注释,例如定义和标记感兴趣的区域,是许多研究项目和工业应用的基本处理阶段。在本文中,我们介绍了一个简单而独立的手动图像注释工具VGG Image Annotator href |
| Multi-scale deep neural networks for real image super-resolution Authors Shangqi Gao, Xiahai Zhuang 如果图像对的放大因子是未知的并且彼此不同,则单图像超分辨率SR是非常困难的,这在实像SR中是常见的。为了解决这个难题,我们在这项工作中开发了两个多尺度深度神经网络MsDNN。首先,由于高分辨率空间中的高计算复杂度,我们主要在两个不同的缩小空间处理输入图像,这可以大大降低GPU存储器的使用。然后,为了重建图像的细节,我们基于残余块在缩小空间中设计多尺度残留网络MsRN。此外,我们提出了一个基于密集块的多尺度密集网络,以与MsRN进行比较。最后,我们的经验实验表明,当放大系数未知时,MsDNN对图像SR的鲁棒性。根据NTIRE 2019图像SR挑战的初步结果,我们的ZXHresearch团队在所有参与者中排名第21位。 MsDNN的实施已经发布 |
| A Large-scale Varying-view RGB-D Action Dataset for Arbitrary-view Human Action Recognition Authors Yanli Ji, Feixiang Xu, Yang Yang, Fumin Shen, Heng Tao Shen, Wei Shi Zheng 目前对动作识别的研究主要集中在单视图和多视图识别上,难以满足人机交互HRI应用识别任意视图动作的要求。缺乏数据集也会设置障碍。为了提供任意视图动作识别的数据,我们新收集了用于任意视图动作分析的大规模RGB D动作数据集,包括RGB视频,深度和骨架序列。数据集包括在8个固定视点中捕获的动作样本以及覆盖整个360度视角的变化视图序列。共有118人被邀请行动40个行动类别,并收集了25,600个视频样本。我们的数据集涉及更多参与者,更多观点和大量样本。更重要的是,它是第一个包含整个360度变化视图序列的数据集。数据集为多视图,交叉视图和任意视图动作分析提供了足够的数据。此外,我们提出了一个View Guidance Skeleton CNN VS CNN来解决任意视图动作识别的问题。实验结果表明,VS CNN具有优越的性能。 |
| A General Framework for Edited Video and Raw Video Summarization Authors Xuelong Li, Bin Zhao, Xiaoqiang Lu 在本文中,我们为编辑的视频和原始视频摘要构建了一个通用的摘要框架。总的来说,我们的工作可分为三个部分1四个模型旨在捕捉视频摘要的属性,即包含重要的人物和对象的重要性,代表视频内容的代表性,没有类似的关键镜头多样性和故事情节的平滑性。具体而言,这些模型适用于编辑过的视频和原始视频。 2使用上述四种模型的加权组合构建综合评分函数。注意,得分函数中的四个模型的权重,表示为属性权重,以监督的方式学习。此外,分别为编辑过的视频和原始视频学习属性权重。 3训练集由编辑过的视频和原始视频构成,以弥补训练数据的不足。特别地,每个训练视频配备有一对混合系数,其可以减少由粗糙混合引起的训练集中的结构混乱。我们在三个数据集上测试我们的框架,包括编辑过的视频,简短的原始视频和长视频。实验结果验证了所提框架的有效性。 |
| Segmenting the Future Authors Hsu kuang Chiu, Ehsan Adeli, Juan Carlos Niebles 预测未来是机器人或自动驾驶系统决策的一个重要方面,它严重依赖于视觉场景理解。虽然先前的工作试图预测未来的视频像素,预测活动或预测未来的场景语义片段来自前一帧的分割,但是不存在仅从前一帧中预测未来语义分段的方法在单端到可训练模型中的RGB数据。在本文中,我们提出了一种时间编码器解码器网络架构,该架构对过去的RGB帧进行编码并对未来的语义分段进行解码。该网络与专门用于预测任务的新知识蒸馏培训框架相结合。我们的方法,仅查看前面的视频帧,隐式地模拟场景片段,同时考虑对象动态以推断未来的场景语义片段。我们对Cityscapes的结果优于基线和当前最先进的方法。代码可在 |
| Super-resolution based generative adversarial network using visual perceptual loss function Authors Xuan Zhu, Yue Cheng, Rongzhi Wang 近年来,感知质量驱动的超分辨率方法显示出令人满意的结果。然而,超分辨率图像具有不确定的纹理细节和令人不快的伪像。我们建立了一种新的感知损失函数,由形态成分的对抗性损失和颜色对抗性损失以及显着的内容丢失组成,以改善这些问题。对抗性损失用于约束超分辨图像的颜色和形态成分分布,突出内容损失突出了特征丰富区域的感知相似性。实验表明,与现有技术相比,所提出的方法在感知指数和视觉质量方面取得了显着的改进。 |
| Improving Few-Shot User-Specific Gaze Adaptation via Gaze Redirection Synthesis Authors Yu Yu, Gang Liu, Jean Marc Odobez 作为人类注意力的指标,凝视是一种微妙的行为线索,可以在许多应用中被利用。然而,即使对于深度神经网络,推断3D注视方向也是具有挑战性的,因为缺乏大量数据,地面控制凝视是昂贵的并且现有数据集使用不同的设置和由于人特定差异而存在的凝视偏差的固有存在。在这项工作中,我们仅从少数参考训练样本中解决了人特定凝视模型适应的问题。主要和新颖的想法是通过合成来自现有参考样本的凝视重定向眼睛图像来生成额外的训练样本来改善凝视适应。在这样做的过程中,我们的贡献是三倍我从合成数据设计我们的凝视重定向框架,允许我们从对齐的训练样本对中受益,以预测准确的逆映射场。我们提出了一种自我监督的域自适应方法,我们利用凝视重定向改善人特定凝视估计的表现。对两个公共数据集的广泛实验证明了我们的凝视重定目标和凝视估计框架的有效性。 |
| LFFD: A Light and Fast Face Detector for Edge Devices Authors Yonghao He, Dezhong Xu, Lifang Wu, Meng Jian, Shiming Xiang, Chunhong Pan 面部检测作为各种应用的基础技术,始终部署在边缘设备上。因此,面部检测器应该具有有限的模型尺寸和快速的推理速度。本文介绍了一种用于边缘设备的轻型快速人脸检测器LFFD。我们在面部检测的背景下重新考虑感受野RF,并发现RF可以用作固有锚,而不是手动构建。结合射频锚和适当的步幅,所提出的方法可以覆盖大范围的连续面部鳞片,具有接近100的命中率,而不是离散的鳞片。对有效感受野ERF和面部尺度之间关系的深刻理解激发了一阶段检测的有效支柱。骨干的特征在于八个检测分支和共同的构建块,从而实现高效的计算。对流行基准WIDER FACE和FDDB进行了全面而广泛的实验。为实际应用提出了一种新的评估方案。在新的模式下,所提出的方法可以实现更高的精度WIDER FACE Val Test Easy 0.910 0.896,Medium 0.880 0.865,Hard 0.780 0.770 FDDB不连续0.965,连续0.719。引入多个硬件平台来评估运行效率。所提出的方法可以获得快速推断速度NVIDIA TITAN Xp 131.45 FPS,640480 NVIDIA TX2 136.99 FPS,160120 Raspberry Pi 3 Model B 8.44 FPS,160120,型号尺寸9 MB。 |
| Computer-aided diagnosis in histopathological images of the endometrium using a convolutional neural network and attention mechanisms Authors Hao Sun, Xianxu Zeng, Tao Xu, Gang Peng, Yutao Ma 子宫癌也称为子宫内膜癌,可严重影响女性生殖器官,组织病理学图像分析是诊断子宫内膜癌的金标准。然而,由于对组织病理学图像与其解释之间的复杂关系建模的能力有限,这些基于传统机器学习算法的计算机辅助诊断CADx方法通常未能获得令人满意的结果。在这项研究中,我们使用卷积神经网络CNN和称为HIENet的注意机制开发了一种CADx方法。由于HIENet使用注意机制和特征图可视化技术,它可以通过突出局部像素水平图像特征与子宫内膜组织形态特征的组织病理学相关性,为病理学家提供更好的诊断可解释性。在十倍交叉验证过程中,CADx方法HIENet达到了76.91 pm 1.17平均pm s。 d。四类子宫内膜组织的分类准确性,即正常子宫内膜,子宫内膜息肉,子宫内膜增生和子宫内膜腺癌。此外,HIENet在检测子宫内膜样腺癌恶性肿瘤的二元分类任务中实现了曲线AUC为0.9579pm 0.0103,灵敏度为81.04 pm,灵敏度为94.78 pm 0.87的特异性区域。此外,在外部验证过程中,HIENet在四级分类任务中达到了84.50的准确度,其实现了AUC为0.9829,具有77.97 95 CI,65.27 87.71灵敏度和100 95 CI,97.42 100.00特异性。总之,拟议的CADx方法HIENet在这个由3,500个苏木精和曙红H E图像组成的小型数据集上的表现优于三个人类专家和四个端到端CNN的分类器,这些数据集关于整体分类性能。 |
| Bidirectional Learning for Domain Adaptation of Semantic Segmentation Authors Yunsheng Li, Lu Yuan, Nuno Vasconcelos 用于语义图像分割的域自适应是非常必要的,因为用像素级标签手动标记大数据集是昂贵且耗时的。现有的域适应技术要么在有限的数据集上工作,要么与监督学习相比产生不那么好的性能。在本文中,我们提出了一种新的双向学习框架,用于领域适应分割。使用双向学习,可以交替地学习图像翻译模型和分割适应模型并相互促进。此外,我们提出了一种自我监督学习算法来学习更好的分割自适应模型,并反过来改进图像转换模型。实验表明,我们的方法在分割领域适应性方面优于现有技术方法。源代码可在以下位置获得 |
| A Novel Re-weighting Method for Connectionist Temporal Classification Authors Hongzhu Li, Weiqiang Wang 连接主义时间分类CTC通过最大化在训练期间正确识别序列的概率来实现端到端序列学习。通过额外的空白类,CTC隐含地将识别序列转换为对序列中的每个时间步进行分类。但CTC损失对于这样的分类任务并不直观,因此由于压倒性的空白时间步长导致的每个序列内的类不平衡是一个棘手的问题。在本文中,我们将一个分段函数定义为伪基础事实,将基于序列的CTC损失重新解释为基于时间步长的交叉熵损失。交叉熵形式使得重新加权CTC损失变得容易。文本识别实验表明,加权CTC损失解决了类不平衡问题,有利于收敛,一般导致比CTC损失更好的结果。除此之外,作为一种全新的视角,对CTC的重新解释在某些其他情况下可能是有用的。 |
| Understanding Art through Multi-Modal Retrieval in Paintings Authors Noa Garcia, Benjamin Renoust, Yuta Nakashima 在计算机视觉中,视觉艺术通常从纯粹的美学角度进行研究,主要是通过分析艺术再现的视觉外观来推断其风格,作者或其代表性特征。然而,在这项工作中,我们从视觉和语言的角度探索艺术。我们的目标是通过联合分析艺术品的美学和语义来弥合艺术品的视觉外观与其潜在意义之间的差距。我们通过收集具有美术绘画和评论的多模态数据集,以及在艺术图像中探索强大的视觉和文本表示,介绍了在自动艺术分析领域中多模态技术的使用。 |
| Unfocused images removal of z-axis overlapping Mie scattering particles by using three-dimensional nonlinear diffusion based on digital holography Authors Wei Na Li, Zhengyun Zhang, Jianshe Ma, Xiaohao Wang, Ping Su 我们提出了一种三维非线性扩散方法,以去除沿z轴重叠的某些尺寸的Mie散射粒子的未聚焦图像。它同时应用于在每次反向传播之后从捕获的全息图生成的所有重建切片。对于某些小尺寸粒子,当沿z轴的重建范围足够长并且在应用所提出的方案后重建深度间隔足够精细时,每个重建切片的最大梯度幅度的最大值出现在地面实况z位置,因此,在地面实况z位置处的重建图像仍然存在,然而,未聚焦的图像被扩散出去。结果表明,尽管几个Mie散射粒子沿z轴完全重叠,当直径为15um时距离为800um并且全息像素,所提出的方案可以扩散出离地面实况z位置20um的未聚焦图像。音高是2um。它还表明,当粒子足够小时,当重建深度间距大于20um时,地面实况z切片的稀疏性不会受到相应未聚焦图像稀疏性的影响。 |
| Neural Collaborative Subspace Clustering Authors Tong Zhang, Pan Ji, Mehrtash Harandi, Wenbing Huang, Hongdong Li 我们介绍了神经协同子空间聚类,这是一种神经模型,可以发现从低维子空间的并集中提取的数据点集群。与之前的尝试相反,我们的模型在没有光谱聚类的帮助下运行。这使我们的算法成为可以优雅地扩展到大型数据集的类型之一。从本质上讲,我们的神经模型受益于分类器,该分类器确定一对点是否位于同一子空间中。对我们的模型至关重要的是构建两个亲和矩阵,一个来自分类器,另一个来自子空间自我表达的概念,以监督协作方案中的训练。我们彻底评估和对比我们的模型与各种最先进的聚类算法(包括基于深子空间的算法)的性能。 |
| Detailed Human Shape Estimation from a Single Image by Hierarchical Mesh Deformation Authors Hao Zhu, Xinxin Zuo, Sen Wang, Xun Cao, Ruigang Yang 本文提出了一个新的框架,从单个图像恢复详细的人体形状。由于诸如人体形状,身体姿势和观点的变化等因素,这是一项具有挑战性的任务。现有方法通常尝试使用缺少表面细节的基于参数的模板来恢复人体形状。因此,所得到的身体形状似乎没有衣服。在本文中,我们提出了一种新的基于学习的框架,它结合了参数模型的鲁棒性和自由形式3D变形的灵活性。我们使用深度神经网络在层次网格变形HMD框架中利用来自身体关节,轮廓和每像素着色信息的约束来细化3D形状。我们能够恢复除皮肤模型之外的详细人体形状。实验证明,我们的方法优于先前的现有技术方法,在2D IoU数和3D度量距离方面实现了更好的准确性。代码可用 |
| $S^{2}$-LBI: Stochastic Split Linearized Bregman Iterations for Parsimonious Deep Learning Authors Yanwei Fu, Donghao Li, Xinwei Sun, Shun Zhang, Yizhou Wang, Yuan Yao 本文提出了一种新的随机分裂线性化Bregman迭代S 2 LBI算法来有效地训练深度网络。 S 2 LBI引入了具有结构稀疏性的迭代正则化路径。我们的S 2 LBI结合了LBI的计算效率和模型选择一致性来学习结构稀疏性。计算出的解决方案路径本质上使我们能够扩大或简化网络,理论上,该网络受益于我们的S2 LBI算法的动态特性。实验结果验证了我们在MNIST和CIFAR 10数据集上的S 2 LBI。例如,在MNIST中,我们可以用仅1.5K参数的1个卷积层和1个FC层来增强网络,达到98.40识别精度或者我们在LeNet 5网络中简化82.5个参数,并且仍然可以实现98.47识别准确性。此外,我们还在ImageNet上有学习成果,将在下一版本的报告中添加。 |
| Unsupervised Assignment Flow: Label Learning on Feature Manifolds by Spatially Regularized Geometric Assignment Authors Artjom Zern, Matthias Zisler, Stefania Petra, Christoph Schn rr 本文介绍了无监督分配流程,它将监督图像标记的分配流与黎曼梯度流耦合,用于特征流形上的标记进化。该方法的后一部分包括对多种有价值数据的现有技术聚类方法的扩展。将标签进化与空间正则化的分配流耦合引起稀疏效应,使得能够以无监督的方式学习紧凑标签词典。我们的方法减少了对监督标签的要求,以便有适当的标签,因为初始标签集可以在分配给给定数据的同时发展并适应更好的值。特征和分配流形之间的分离使得灵活的应用能够在具有多种重要特征的三种情景中得到证明。实验证明了在两个方向上的有益效果标签的自适应性改善了图像标记,并且通过空间正则化分配的转向标签进化导致适当的标签,因为用于监督标记的分配流程被精确地使用而没有任何标签学习的近似。 |
| Graph-based Inpainting for 3D Dynamic Point Clouds Authors Zeqing Fu, Wei Hu, Zongming Guo 随着深度传感器和3D激光扫描技术的发展,3D动态点云作为运动中三维物体表现的一种格式引起了越来越多的关注,应用于各种领域,如3D沉浸式远程呈现,导航,动画,游戏和虚拟现实。然而,动态点云通常表现出缺失数据的漏洞,主要是由于快速运动,采集技术的限制和复杂的结构。此外,点云在不规则非欧几里德域上定义,这对于使用常规数据的传统方法来说是难以解决的。因此,利用图形信号处理工具,我们提出了一种有效的动态点云修复方法,利用三维动态点云中的帧间相干性和帧内自相似性。具体而言,对于点云序列中的每个帧,我们首先将其拆分为固定大小的立方体作为处理单元,并将具有孔的立方体视为目标立方体。其次,我们利用目标帧中的帧内自相似性,通过全局搜索与每个目标立方体最相似的立方体作为内部源立方体。第三,我们利用每三个连续帧之间的帧间相干性,通过在每个目标立方体的前一帧和后一帧中搜索相应的立方体作为源间立方体,其包含相对位置中目标立方体的最近邻居。最后,我们将基于帧内和源间立方体的动态点云修补法制定为优化问题,并通过图形信号平滑度先验进行正则化。实验结果表明,该方法在客观和主观质量上均优于三种竞争方法。 |
| OperatorNet: Recovering 3D Shapes From Difference Operators Authors Ruqi Huang, Marie Julie Rakotosaona, Panos Achlioptas, Leonidas Guibas, Maks Ovsjanikov 本文提出了一种基于学习的框架,用于从函数运算符重建三维形状,紧凑编码为小尺寸矩阵。为此,我们引入了一种名为OperatorNet的新型神经结构,它将一组表示形状的线性运算符作为输入,并生成其3D嵌入。我们证明了这种方法在同一问题上明显优于以前的纯几何方法。此外,我们引入了一种新颖的函数运算符,它对外在或姿势依赖的形状信息进行编码,从而补充了纯粹的内在姿势遗忘运算符,例如经典的拉普拉斯算子。与这种新颖的算子相结合,我们的重建网络实现了非常高的重建精度,即使在存在关于形状的不完整信息的情况下,给定以减少的基础表示的软或功能图。最后,我们证明了这些算子所享有的乘法函数代数可用于在形状插值和形状类比应用的背景下合成全新的看不见的形状。 |
| Deep Learning for Classification of Hyperspectral Data: A Comparative Review Authors Nicolas Audebert OBELIX , Bertrand Saux, S bastien Lef vre OBELIX 近年来,深度学习技术彻底改变了遥感数据的处理方式。高光谱数据的分类也不例外,但具有内在的特性,这使得深度学习的应用不如其他光学数据那么直接。本文介绍了先前机器学习方法的最新技术,回顾了目前针对高光谱分类提出的各种深度学习方法,并确定了为此任务实现深度神经网络所出现的问题和困难。特别地,解决了空间和光谱分辨率,数据量以及从多媒体图像到高光谱数据的模型转移的问题。另外,提供了各种网络体系结构的比较研究,并且公开发布了软件工具箱以允许试验这些方法。 1本文适用于对高光谱数据感兴趣的数据科学家和渴望将深度学习技术应用于他们自己的数据集的遥感专家。 |
| Understanding the efficacy, reliability and resiliency of computer vision techniques for malware detection and future research directions Authors Li Chen 我的研究在于安全和机器学习的交叉。本概述总结了我的研究的一个组成部分,将计算机视觉与恶意软件漏洞检测相结合,以增强安全性解决方我将介绍有效性,可靠性和弹性的观点,将威胁检测制定为计算机视觉问题,并开发基于图像的恶意软件分类。将恶意软件二进制文件表示为图像可提供数据样本的直接可视化,减少特征提取的工作量,并消耗整个二进制文件以进行整体结构分析。与传统的机器学习算法相比,采用对大规模图像分类有效的深度神经网络的转移学习与恶意软件分类相比,表现出更高的分类效率。为了增强这些基于视觉的恶意软件检测器的可靠性,可以在恶意软件可视化表示上构建解释框架,并且可用于提取忠实的解释,以便安全从业者在部署之前对模型有信心。在网络安全应用程序中,我们应该始终假设恶意软件编写者不断修改代码以绕过检测。解决恶意软件检测器的弹性对于功效和可靠性来说同样重要。通过了解用于恶意软件检测的机器学习模型的攻击面,我们可以极大地提高算法的鲁棒性,以对抗野外的恶意软件攻击者。最后,我将讨论本研究界值得追求的未来研究方向。 |
| Comparing Samples from the $\mathcal{G}^0$ Distribution using a Geodesic Distance Authors Alejandro C. Frery, Juliana Gambini mathcal G 0分布广泛用于单极化SAR图像建模,因为它可以准确地表征具有不同纹理程度的区域。它由三个参数索引,可以估计整个图像的外观数量,比例参数和纹理参数。本文提出了一种新的方案,用于使用测地距离GD比较来自mathcal G 0分布的样本,作为模型之间不相似性的度量。目标是使用本地参数标度和mathcal G 0分布的纹理来量化来自SAR数据的样本对之间的差异。我们提出了三个基于GD的测试,它们结合了GeodesicDistanceGI0JSTARS中提供的测试,我们使用置换方法估计它们的概率分布。 |
| Chunkflow: Distributed Hybrid Cloud Processing of Large 3D Images by Convolutional Nets Authors Jingpeng Wu 1 , William M. Silversmith 1 , H. Sebastian Seung 1 and 2 1 Princeton Neuroscience Institute, Princeton University, 2 Department of Computer Science, Princeton University 现在通常使用3D卷积网络ConvNets处理体积生物医学图像。对于今天通过光学或电子显微镜获得的teravoxel甚至petavoxel图像,这可能是具有挑战性的。在这里,我们介绍chunkflow,一个用于在本地和云GPU和CPU上分发ConvNet处理的软件框架。图像体积被分成重叠的块,每个块由ConvNet处理,并且结果被混合在一起以产生输出图像。前端将ConvNet任务提交到云队列。任务由本地和云GPU和CPU执行。由于Chunkflow的容错架构,通过利用廉价的不稳定云实例可以大大降低成本。 Chunkflow目前支持GPU的PyTorch和CPU的PZnet。为了说明其用法,来自串行截面电子显微镜的大型3D脑图像由具有U Net样式架构的3D ConvNet处理。 Chunkflow为一般用途提供了一些块操作,并且可以在命令行界面中灵活地组合操作。 |
| Chinese Abs From Machine Translation |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号