
【今日CV 计算机视觉论文速览 第109期】Wed, 1 May 2019
今日CS.CV 计算机视觉论文速览
Wed, 1 May 2019
Totally 40 papers
👉上期速览✈更多精彩请移步主页

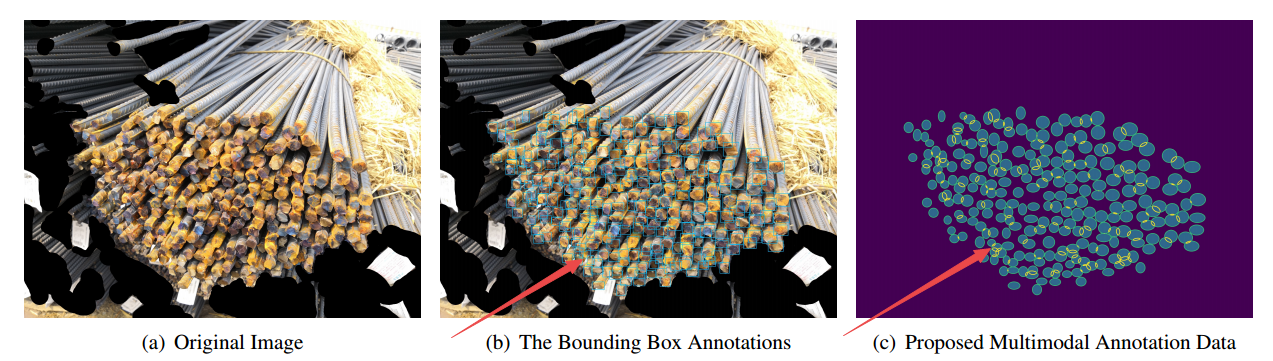
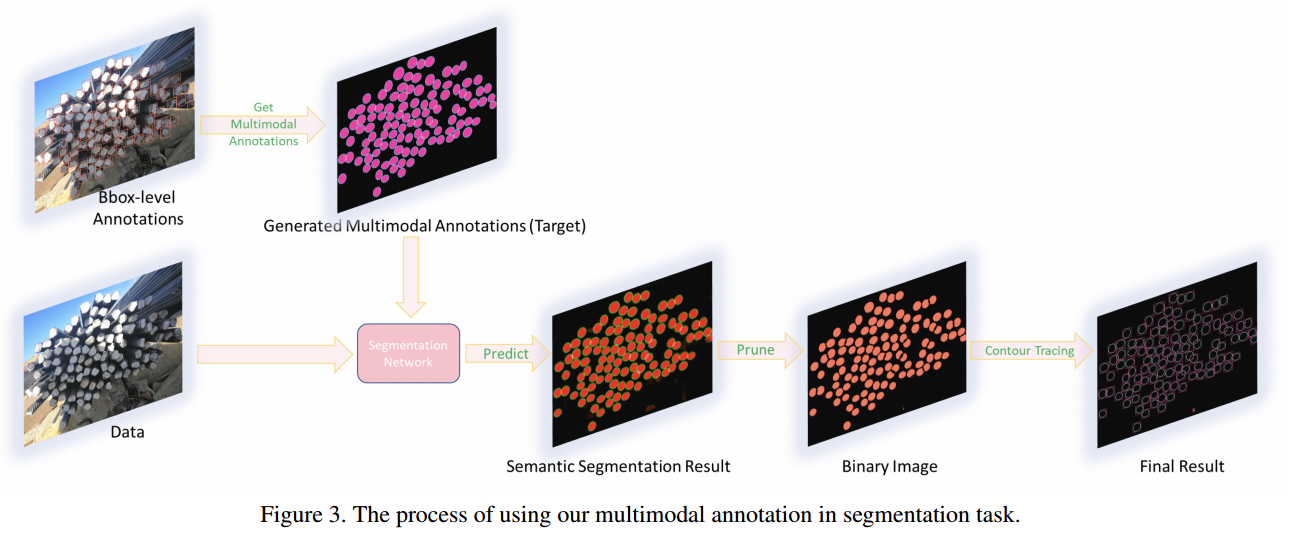
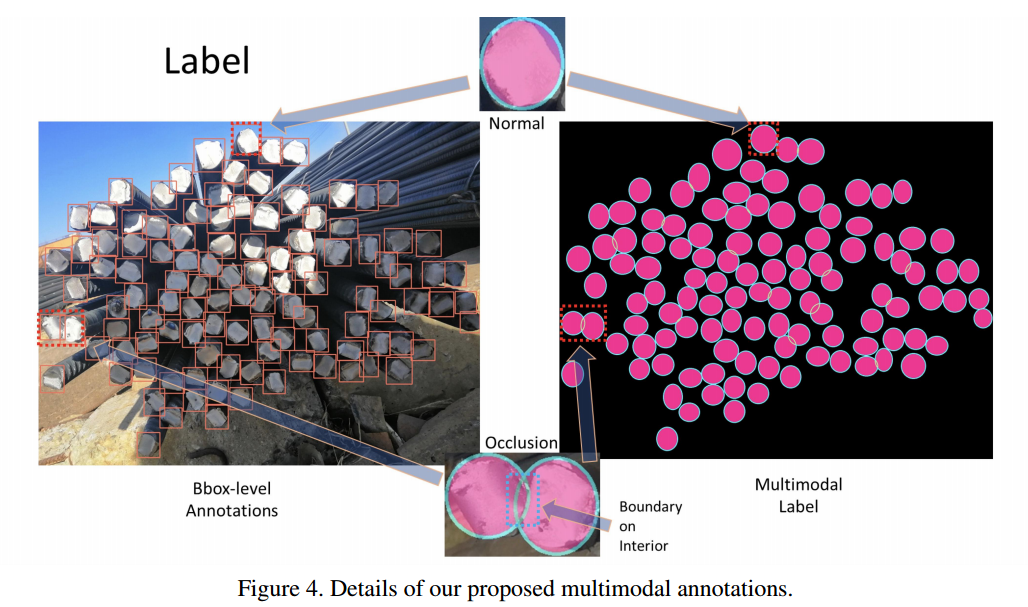
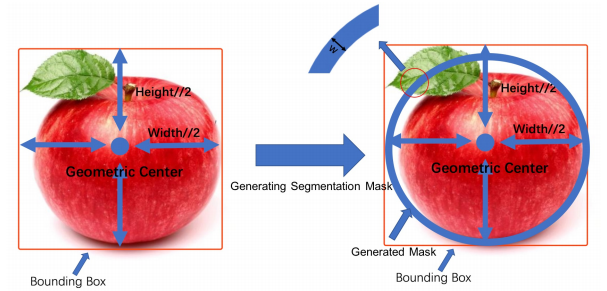
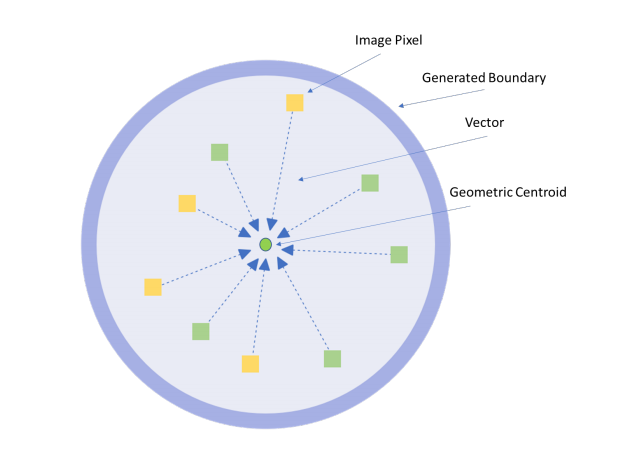
📚Segmentations is All You Need,提出了一种无须锚点和非极大值抑制的目标检测方法,主要解决了复杂遮挡情况下召回率低的问题。研究人员提出了一种基于弱监督分割的多模态标记方法来实现更高的鲁棒性。利用bbox作为弱标记来得到鲁棒的检测表现,避免了超参数相关的锚框和非极大值抑制。(from 牛津)
分割标记的成本是bbox成本的15倍以上,研究人员提出了基于bbox使用分割的方法来实现多模态标记,只需要一个模型即可处理多种情况。
多模态数据:
可以检测小到5050,1515像素的小物体(矢量场的帮助下)。
多模态标记方法的细节以及向量场:
dataset:
野外人脸WIDER Face
钢筋检测数据集, github
pytorch faster rcnn
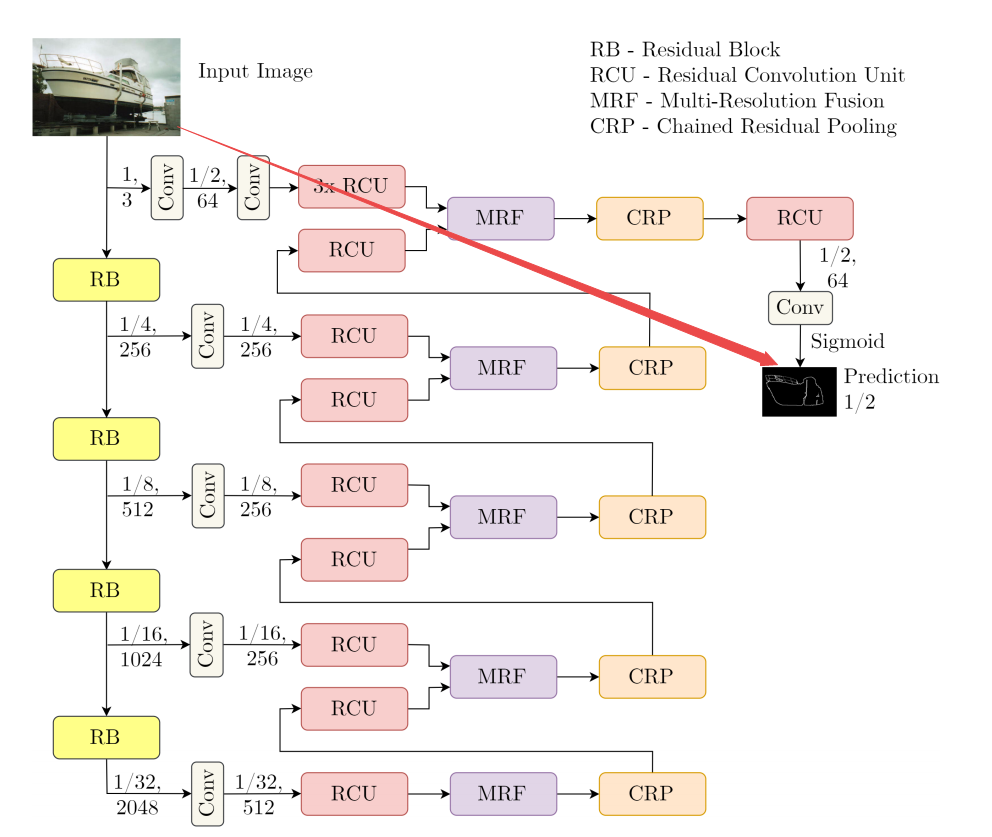
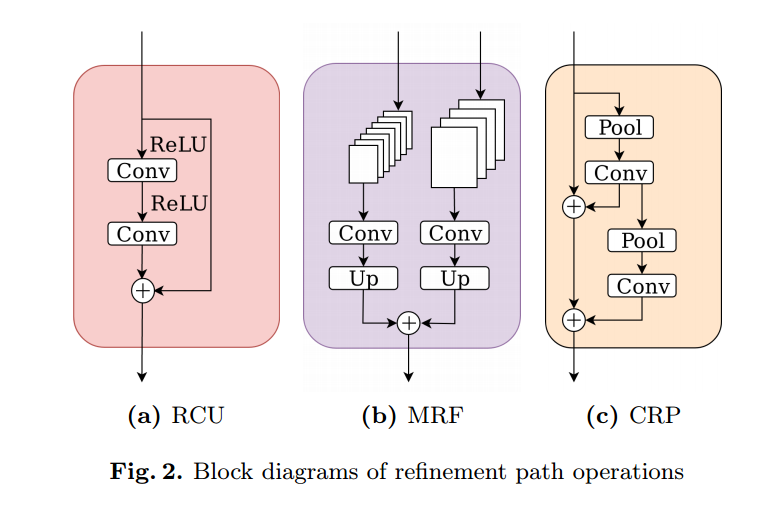
📚RefineContourNet进行目标轮廓及边缘检测, 利用了Resnet抽取高层次特征并用于边缘检测,并融合了高、中、低特征,通过一定的方式层层融合。(from Helmut Schmidt University)
边缘检测的过程:
残差卷积单元、多分辨率融合、链式残差池化单元的结构:
一些得到的结果:
dataset:BSDS500,PASCAL VOC 2012 dataset

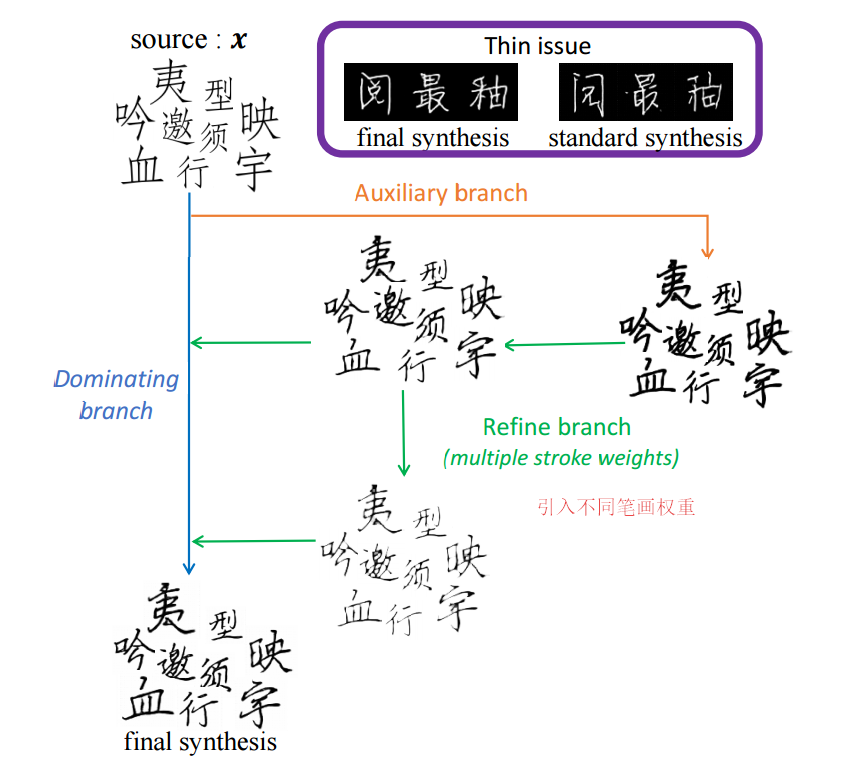
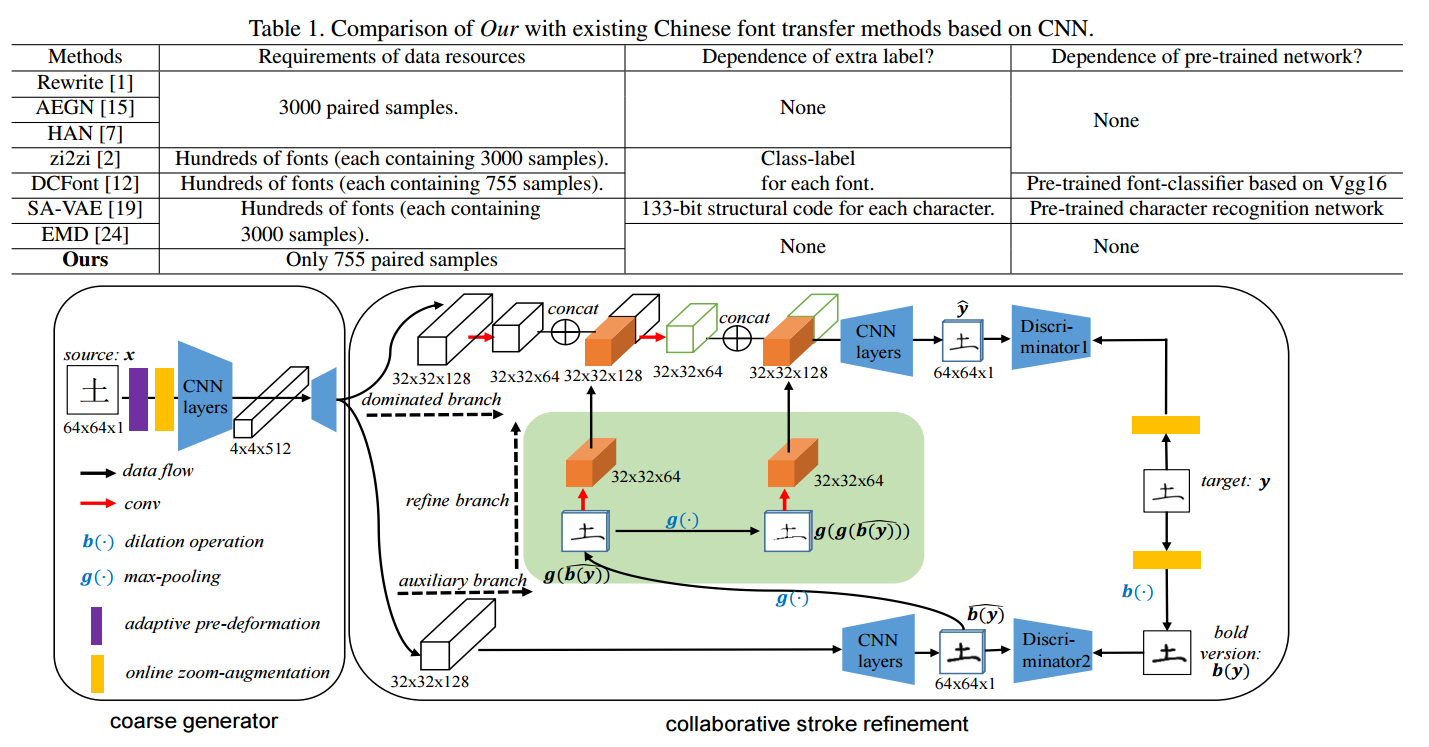
📚自动字形生成, 提出了基于cnn模型的字形生成架构,首先利用协作策略训练合作笔画精炼技术来恢复缺失笔画部分;同时利用在线缩放增强技术来充分复用内容以减小训练集大小;并使得字形产生自适应的预变形、标准化和配准,只利用了750对字符进行训练。(from 上海交大)
网络具体架构以及比较方法需要数据集大小如下:
一些生成的记结果:

📚SurfelWarp高效的单视角非刚体动态三维重建, 提出了一种基于深度图流的非刚体实时重建方法,而无需维持体素数据结构,不需要模板和先验模型,同时避免了较大内存和计算量的使用。同时使用曲面元素表示的集合可以高效的跟踪形态学变换并实现基于深度观测的实时重建。(from MIT)
系统流程图:

一些动态重建结果:

web:https://sites.google.com/view/surfelwarp/home
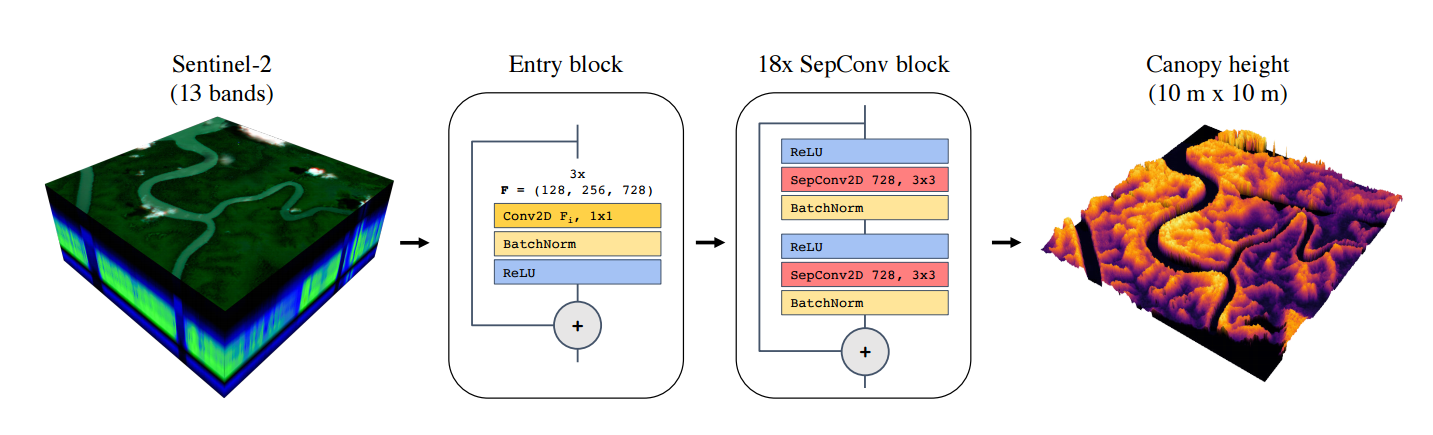
📚基于深度学习利用Sentinel-2多光谱卫星图像估计森林覆盖植被的高度, 其中基准数据来自于激光雷达或者林木高度模型。(from ETHz)
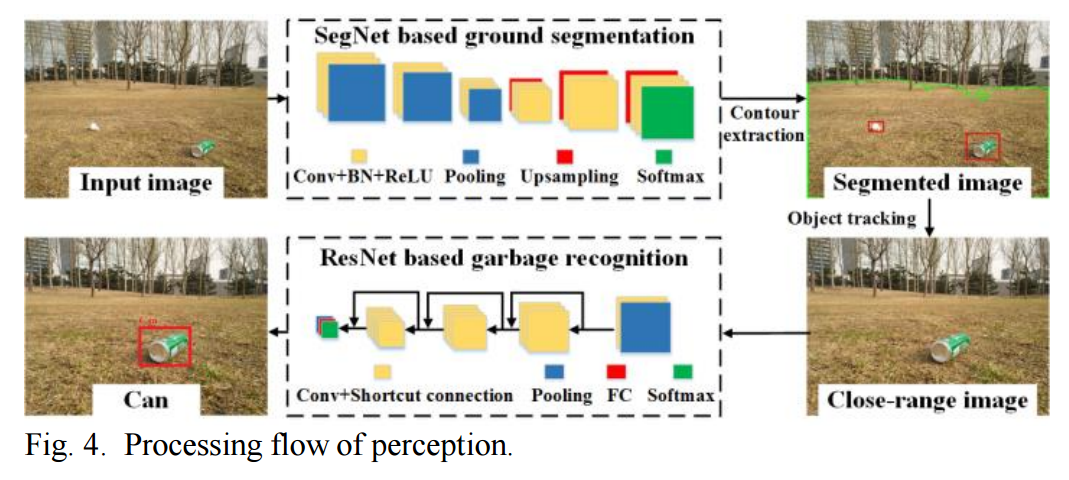
📚公园里自动捡垃圾的机器人, (from 北航)
Daily Computer Vision Papers
| Comparative evaluation of 2D feature correspondence selection algorithms Authors Chen Zhao, Jiaqi Yang, Yang Xiao, Zhiguo Cao 旨在从原始特征匹配中寻找正确的特征对应关系的对应选择对于许多基于特征匹配的任务是关键的。已经呈现了各种2D图像对应选择算法,其具有数十年的进步。遗憾的是,由于缺乏深入评估,开发人员很难在给定特定应用的情况下选择合适的算法。本文通过评估八种二维对应选择算法(从经典方法到四种标准数据集中的最新方法)来填补这一空白。实验数据集的多样性带来各种麻烦,包括缩放,旋转,模糊,视点变化,JPEG压缩,光变化,不同的渲染风格和多结构,以进行全面测试。为了进一步创建初始匹配的不同分布,还考虑了一组检测器和描述符的组合。我们从四个方面测量对应选择算法的质量,即精度,召回,F测量和效率。根据评估结果,汇总了所有考虑的算法的当前优点和局限性,可以将其视为以下开发人员的用户指南。 |
| The Level Weighted Structural Similarity Loss: A Step Away from the MSE Authors Yingjing Lu 均方误差MSE在应用于深度生成模型(如自动编码器)模型重建损失时已显示出其强度。然而,特别是在图像领域,MSE的局限性很明显,它假定像素独立并忽略样本的空间关系。这与使用卷积层提取空间相关特征的自动编码器的大多数架构相矛盾。我们基于结构相似性度量SSIM,并为卷积自动编码器提出新的级别加权结构相似性LWSSIM损失。对各种自动编码器变体的常见数据集的实验表明,我们的损失能够超越MSE损失和香草SSIM损失。我们还提供了在标准SSIM丢失失败的情况下我们的模型能够成功的原因。 |
| Structured Prediction using cGANs with Fusion Discriminator Authors Faisal Mahmood, Wenhao Xu, Nicholas J. Durr, Jeremiah W. Johnson, Alan Yuille 我们提出了融合鉴别器,一种统一的框架,用于将条件信息合并到生成对抗网络GAN中,用于各种不同的结构化预测任务,包括图像合成,语义分割和深度估计。与常用的卷积神经网络条件马尔可夫随机场CNN CRF模型非常相似,所提出的方法能够在模型中实施更高阶的一致性,但不限于非常特定的一类电势。该方法在概念上简单而灵活,我们的实验结果证明了对几种不同的结构化预测任务的改进。 |
| Object Contour and Edge Detection with RefineContourNet Authors Andre Peter Kelm, Vijesh Soorya Rao, Udo Zolzer 基于ResNet的多路径细化CNN用于对象轮廓检测。对于此任务,我们优先考虑ResNet的高级抽象功能的有效利用,这导致边缘检测的最新结果。牢记我们的关注点,我们将特定顺序的高,中,低级功能融合在一起,这与许多其他方法不同。它使用具有最高级别特征的张量作为起点,逐层将其与较低抽象级别的特征组合,直到达到最低级别。我们在改进的PASCAL VOC 2012数据集上训练该网络以进行物体轮廓检测,并在精细的PASCAL val数据集上进行评估,达到卓越的性能和0.752的最佳数据集规模ODS。此外,通过对BSDS500数据集的精细培训,我们达到了最先进的边缘检测结果,ODS为0.824。 |
| PYRO-NN: Python Reconstruction Operators in Neural Networks Authors Christopher Syben, Markus Michen, Bernhard Stimpel, Stephan Seitz, Stefan Ploner, Andreas K. Maier 目的最近,进行了多次尝试以将深度学习转移到医学图像重建。越来越多的出版物遵循将CT重建作为已知算子嵌入神经网络的概念。然而,所提出的大多数方法缺乏完全整合到深度学习环境中的有效CT重建框架。结果,许多方法被迫使用变通方法来解决数学上明确无法解决的问题。方法PYRO NN是一个通用的框架,用于将已知运算符嵌入到流行的深度学习框架Tensorflow中。目前的状态包括现有的并行,扇形和锥形光束投影仪以及使用CUDA作为Tensorflow层加速的后投影仪。最重要的是,该框架提供了一个高级Python API,可以使用来自真实CT系统的数据进行FBP和迭代重建实验。结果该框架提供了所有必要的算法和工具,用于集成CT重建算法设计端到端神经网络管道。高级Python API允许简单地使用Tensorflow中已知的层。为了演示层的功能,该框架附带三个基线实验,显示锥形束短扫描FDK重建,CT重建滤波器学习设置和TV正则化迭代重建。所有算法和工具都参考科学出版物,并与现有的非深度学习重建框架进行比较。该框架可在url作为开源软件使用 |
| Segmentation is All You Need Authors Yuxiang Wu, Zehua Cheng, Zhenghua Xu, Weiyang Wang 我们提出了一种新的检测任务范例,即锚箱免费和NMS免费。尽管目前基于区域提出方法的现有技术模型已经得到了很好的认可,但是作为RPN的基础,NMS无法解决复杂遮挡情况下的低召回率问题。当面对复杂的遮挡时,这种情况尤其重要。我们提出使用弱监督分段多模态注释来实现没有NMS的高度鲁棒的对象检测性能。在这种情况下,我们利用差的带注释的边界框注释来在困难的环境中执行稳健的对象检测性能。我们已经避免了与锚框和NMS相关的所有超参数。我们提出的模型优于先前基于锚的单级和多级探测器,具有更简单的优点。我们在准确率和召回率方面都达到了最先进的表现。 |
| Detecting Reflections by Combining Semantic and Instance Segmentation Authors David Owen, Ping Lin Chang 自然图像中的反射通常会导致自动检测系统出现误报。这些误报可能导致检测,计数和分割任务的准确性严重受损。在这里,受最近全景分割方法的启发,我们展示了融合实例和语义分割如何能够自动识别反射误报,而无需明确地需要标记反射区域。我们详细探讨了现有技术的两级探测器如何遭受更广泛的背景特征的损失,因此无法学会忽略这些反射。然后,我们提出了一种融合该应用的实例和语义分割的方法,并随后展示了如何减少具有大量反射表面的真实世界监视数据中的误报检测。这表明尽管处于起步阶段,但全景分割和相关工作在现实世界的计算机视觉问题中已经非常有用。 |
| Non-Rigid Structure-From-Motion by Rank-One Basis Shapes Authors Sami S. Brandt, Hanno Ackermann 在本文中,我们表明,运动问题的仿射,非刚性结构可以通过一级解决,从而退化,基础形状。这是Bregler等人对经典低等级方法的自然重构,其中假设可变形3D结构由刚性基础形状的线性组合产生。非刚性形状将被分解为平均形状和简并形状,由低秩分解的右奇异向量构成。正确的奇异向量被仿射地反投影到3D空间中,并且仿射背投影也将作为因子分解的一部分被解决。通过构造,对低秩分解的右奇异向量的直接解释也将随后被视为主要成分,因此,我们方法的第一变体被称为秩1 PCA。被称为秩1 ICA的第二变体另外估计正交变换,其将变形模式映射到尽可能统计独立的模式。它具有精确定位与例如人脸上的嘴唇运动相关的统计依赖子空间的优点。而且,与先前的工作相反,没有强加子空间的预定义维度。对几个数据集的实验表明,该方法比现有技术获得了更好的结果,可以更快地计算,并且为变形模式提供了直观的解释。 |
| Handwritten Chinese Font Generation with Collaborative Stroke Refinement Authors Chuan Wen, Jie Chang, Ya Zhang 自动字符生成是新字体设计的有吸引力的解决方案,特别是对于包括超过3700个最常用字符的中文字体。这个任务有两个主要的难点我手写字符通常与很少信息和复杂结构的细笔画相关联,这些笔画在变形过程中容易出错。基于一些手工设计的字符,需要数千个具有各种形状的字符来合成。为了解决这些问题,我们提出了一种新的基于卷积神经网络的模型,采用三种主要技术协同笔划细化,利用协同训练策略恢复在线缩放增加的丢失或中断,利用内容重用现象来减小大小。训练集和自适应预变形,标准化和对齐字符。所提出的模型仅需要750个配对的训练样本,没有预先训练的网络,需要额外的数据集资源或标签。实验结果表明,该方法在手写字体合成的实际限制下明显优于现有技术方法。 |
| A new algorithm for shape matching and pattern recognition using dynamic programming Authors Noreddine Gherabi, Bahaj Mohamed 我们提出了一种基于动态规划的形状识别和检索的新方法。我们的方法使用动态编程算法来计算最佳分数并找到两个字符串之间的最佳对齐。首先,每个形状轮廓由一组点表示。在两个形状之间对齐和匹配之后,轮廓被转换为一串符号和数字。最后,我们找到两个完整字符串的最佳对齐并计算最佳相似成本。通常,动态编程具有前向阶段和后向阶段两个阶段。在前进阶段,我们计算每个子问题的最优成本。在后退阶段,我们重建了提供最优成本的解决方案。我们的算法在包含各种形状(如MPEG 7)的数据库中进行测试。 |
| GaborNet: Gabor filters with learnable parameters in deep convolutional neural networks Authors Andrey Alekseev, Anatoly Bobe 本文描述了一种使用深度卷积神经网络进行图像识别的系统。提出了改进的网络架构,侧重于改善收敛性并降低训练复杂性。网络的第一层中的过滤器被约束以适合Gabor功能。 Gabor函数的参数是可学习的,并通过标准反向传播技术进行更新。该系统是在Python上实现的,在几个数据集上进行了测试,并且优于常见的卷积网络。 |
| Using cameras for precise measurement of two-dimensional plant features Authors Amy Tabb, Germ n A Holgu n, Rachel Naegele 图像经常用于植物表型分析以捕获测量值。本章提供了一种可重复的方法,使用各种相机类型的手机,数码单反相机,在现场或实验室环境中捕获植物部件的二维测量值,并添加了印刷校准图案。该方法基于使用来自图像的EXIF标签的可用信息校准相机,以及来自图案的视觉信息。提供代码以实现该方法,以及用于测试的数据集。我们包括通过对工件进行成像来验证协议正确性的步骤。将该协议用于二维植物表型分析将允许从不同的相机和环境捕获数据,并在相同的物理尺度上进行比较。 |
| Facial Expressions Analysis Under Occlusions Based on Specificities of Facial Motion Propagation Authors Delphine Poux, Benjamin Allaert, Jose Mennesson, Nacim Ihaddadene, Ioan Marius Bilasco, Chaabane Djeraba 尽管在面部表情分析领域已经取得了很大进展,但面部遮挡仍然具有挑战性。这一贡献带来的主要创新在于利用面部运动传播的特殊性来识别存在重要遮挡的表情。由表达引起的运动延伸到运动震中之外。因此,在遮挡区域中发生的移动朝向相邻的可见区域传播。在存在遮挡,每个表达的情况下,我们计算每个未被遮挡的面部区域的重要性,并且我们构建适应的面部框架,其提高每个表达式二元分类器的性能。然后聚合每个依赖于表达式的二元分类器的输出并将其馈送到融合过程,该融合过程旨在构建每个遮挡的识别所考虑的所有面部表情的唯一模型。评估强调了这种方法在存在明显面部遮挡的情况下的稳健性。 |
| PR Product: A Substitute for Inner Product in Neural Networks Authors Zhennan Wang, Wenbin Zou, Chen Xu 本文从矢量正交分解的角度分析了神经网络中权向量和输入向量的内积,证明了权向量的局部方向梯度随着它们之间的角度接近0或pi而减小。我们提出了PR产品,它是内积的替代品,它使重量矢量的局部方向梯度与角度无关,并且始终大于传统内积中的那个,同时保持前向传播相同。作为神经网络的基本操作,PR产品可以应用于许多现有的深度学习模块,因此我们开发了完全连接层,卷积层和LSTM层的PR产品版本。在静态图像分类中,对CIFAR10和CIFAR100数据集的实验表明,PR产品可以有力地增强各种现有技术分类网络的能力。关于图像字幕的任务,即使没有任何花哨,我们的PR产品版本的字幕模型可以在MS COCO数据集上竞争或优于最先进的模型。 |
| Surprising Effectiveness of Few-Image Unsupervised Feature Learning Authors Yuki M. Asano, Christian Rupprecht, Andrea Vedaldi 用于无监督表示学习的现有技术方法可以很好地训练标准卷积神经网络的前几层,但是它们不如针对更深层的监督学习那么好。这可能是由于浅层的一般性和相对简单的性质,然而,这些方法被应用于数百万个图像,可扩展性被宣传为它们的主要优点,因为未标记的数据收集起来便宜。在本文中,我们质疑这种做法,并询问是否实际需要这么多图像来学习无监督学习效果最好的图层。我们的主要结果是,一些甚至单个图像以及强大的数据增强足以使性能几乎达到饱和。具体来说,我们提供了三种不同的自监督特征学习方法BiGAN,RotNet,DeepCluster与训练图像数量1,10,1000的分析,并表明我们可以使用一个单一的常见网络的前两个卷积层的精度未标记的训练图像并获得其他层的竞争结果。我们进一步研究和可视化学习的表示,作为单个图像用于训练的函数。我们的结果也暗示了深层网络中浅层可以捕获哪种类型的信息。 |
| Deep Learning-based Face Pose Recovery Authors Zhaoxiang Liu, Zezhou Chen, Jinqiang Bai, Shaohua Li, Shiguo Lian 面部姿势估计在许多实际应用中获得了很多关注,例如人体机器人交互,注视估计和驾驶员监控。同时,基于端到端深度学习的面部姿势估计正变得越来越流行。然而,面部姿势估计受到关键挑战的困扰,即许多姿势缺乏足够的训练数据,尤其是对于大姿势。受近视姿势下面部相似的观察启发,我们将面部姿势估计重新表述为标签分布学习问题,将每个面部图像作为与高斯标签分布而非单个标签相关联的示例,并构造卷积神经在AFLW数据集和300WLP数据集上训练具有多重损失功能的网络,直接从彩色图像预测面部姿势。在几个流行的基准测试中进行了大量实验,包括AFLW2000,BIWI,AFLW和AFW,其中我们的方法显示出优于其他最先进方法的显着优势。 |
| Early Action Prediction with Generative Adversarial Networks Authors Dong Wang, Yuan Yuan, Qi Wang 动作预测旨在尽早确定视频中正在发生的动作,这对于许多在线应用程序至关重要,例如在事故发生之前预测交通事故并检测监控系统中的恶意行为。在这项工作中,我们通过开发端到端架构来解决这个问题,该架构通过将部分观察到的视频的特征同化为完整视频中的特征来提高其可辨别性。为此目的,引入生成对抗网络来解决动作预测问题,虽然缩小了部分观察视频与完整视频的特征差异,但提高了部分观察视频的识别精度。具体来说,它的发生器包括两个网络,一个用于特征提取的CNN和一个用于估计部分观察到的视频和完整视频的特征之间的残差的LSTM,然后CNN的特征增加了来自LSTM的残差,这被认为是增强的。愚弄竞争鉴别者的功能。同时,使用额外的感知目标训练发生器,这迫使部分观察的视频的增强特征对于动作预测具有足够的辨别力。在UCF101,BIT和UT交互数据集上的广泛实验结果表明,我们的方法优于现有技术方法,特别是对于观察到少于50个帧的视频。 |
| Memory-Augmented Temporal Dynamic Learning for Action Recognition Authors Yuan Yuan, Dong Wang, Qi Wang 在视频序列中捕获的人类动作包含用于动作识别的两个关键因素,即视觉外观和运动动态。为了模拟这两个方面,卷积和回归神经网络CNN和RNN被用于大多数现有的识别动作的成功方法中。然而,基于CNN的方法在建模长期运动动力学方面受到限制。 RNN能够学习时间运动动力学,但缺乏有效的方法来解决长时间运动中的不稳定动态。在这项工作中,我们提出了一个内存增强时态动态学习网络,它学会将最明显的信息写入外部存储器模块并忽略不相关的信息。特别地,我们提出了一种差分存储器控制器,以便对是否应该用当前特征更新外部存储器模块做出离散决定。离散存储器控制器将存储器历史,上下文嵌入和当前特征作为输入并控制信息流入外部存储器模块。此外,我们使用直通估算器训练这个分立的内存控制器。我们在人类行动识别的基准数据集UCF101和HMDB51上评估这个端到端系统。实验结果表明,与以前的工作和我们的基线相比,这两个数据集都有一致的改进。 |
| Anomaly Detection in Traffic Scenes via Spatial-aware Motion Reconstruction Authors Yuan Yuan, Dong Wang, Qi Wang 从驾驶员的角度来看,驾驶时的异常检测对于自动驾驶车辆来说是重要的。作为高级驾驶员辅助系统ADAS的一部分,它可以及时提醒驾驶员有关危险的信息。与大学校园和市场监控视频等传统研究场景相比,由于摄像机摆动,持续移动背景,车速急剧变化等原因,很难从驾驶员的角度检测异常事件。为解决这些具体问题,本文提出了一种用于交通场景异常检测的空间局部约束稀疏编码方法,首先分别测量运动方向和幅度的异常,然后融合这两个方面,得到一个鲁棒的检测结果。主要贡献是三重1这项工作分别以一种新的方式描述了物体的运动方向和大小,这被证明比传统的运动描述符更好。 2物体的空间定位考虑了稀疏重建框架,该框架利用场景的结构信息,优于传统的稀疏编码方法。 3运动方向和幅度的结果通过贝叶斯模型进行自适应加权和融合,使得该方法更加鲁棒,可以处理更多种类的异常事件。通过对我们自己捕获的九个困难视频序列进行测试,验证了所提方法的效率和有效性。从实验结果观察,所提出的方法比流行的竞争对手更有效和高效,并且产生更高的性能。 |
| Interpretation of Feature Space using Multi-Channel Attentional Sub-Networks Authors Masanari Kimura, Masayuki Tanaka 卷积神经网络在各种任务中取得了令人瞩目的成果,但解释内部机制是一个具有挑战性的问题。为了解决这个问题,我们在特征空间中利用了多通道注意机制。我们的网络架构允许我们为每个特征获得注意掩模,而现有的CNN可视化方法仅为所有特征提供共同的注意掩模。我们将提出的多通道关注机制应用于多属性识别任务。我们可以为每个特征和每个属性获得不同的注意掩码。这些分析使我们更深入地了解CNN的特征空间。基准数据集的实验结果表明,所提出的方法在准确掌握数据属性的同时,为人类提供了高度的可解释性。 |
| SurfelWarp: Efficient Non-Volumetric Single View Dynamic Reconstruction Authors Wei Gao, Russ Tedrake 我们提供密集的SLAM系统,将深度图像的实时流作为输入,并实时重建非刚性变形场景,无需模板或先前模型。与现有方法相比,我们不维护任何体积数据结构,例如截断的带符号距离函数TSDF字段或变形字段,这些都是性能和内存密集型的。我们的系统采用基于平点表面的几何表示,可以直接从商品深度传感器获取。标准图形管线和通用GPU GPGPU计算用于所有中心操作,即最近邻维护,非刚性变形场估计和深度测量的融合。我们的管道固有地避免了昂贵的体积操作,例如行进立方体,体积融合和密集变形场更新,从而显着提高了性能。此外,基于显式和灵活的基于表面的几何表示能够有效地处理拓扑变化和跟踪失败,这使得我们的重建与更新的深度观察一致。我们的系统允许机器人使用非刚性变形的对象维护场景描述,这可能使得能够与动态工作环境进行交互。 |
| Cross-Modal Message Passing for Two-stream Fusion Authors Dong Wang, Yuan Yuan, Qi Wang 在多模态之间处理和融合信息是在许多计算机视觉问题中实现高性能的非常有用的技术。为了更有效地处理多模态信息,我们引入了一种新的多模态融合框架Cross Modeal Message Passing CMMP。具体地,我们提出了一种交叉模态消息传递机制来融合两个流网络以进行动作识别,其由外观模态网络RGB图像和运动模态光流图像网络组成。该框架中各个网络的目标是标准分类目标和竞争目标的两倍。分类对象确保每个模态网络预测真实的行动类别,而竞争目标鼓励每个模态网络优于另一个模态网络。我们定量地表明,所提出的CMMP更有效地融合了传统的双流网络,并且优于UCF 101和HMDB 51数据集上现有的两种流融合方法。 |
| Wearable Travel Aid for Environment Perception and Navigation of Visually Impaired People Authors Jinqiang Bai, Zhaoxiang Liu, Yimin Lin, Ye Li, Shiguo Lian, Dijun Liu 本文介绍了一种可穿戴式辅助设备,它具有一副眼镜的形状,允许视障人士在陌生的环境中安全快速地导航,以及感知复杂的环境,自动决定移动的方向。该设备使用消费者红色,绿色,蓝色和深度RGB D相机和惯性测量单元IMU来检测障碍物。由于该装置利用相邻图像帧之间的地面高度连续性,因此能够准确且快速地从障碍物中分割地面。基于检测到的地面,计算最佳可行走方向,然后通过转换的蜂鸣声通知用户。此外,通过利用深度学习技术,设备可以在语义上对检测到的障碍物进行分类,以改善用户对周围环境的感知。它将部署在智能手机上的卷积神经网络CNN与基于深度图像的对象检测相结合,以确定对象类型是什么以及对象位于何处,然后通过语音通知用户此类信息。我们通过不同的实验评估了设备的性能,其中20名视障人士被要求佩戴设备并在办公室中移动,并且发现他们能够避免障碍物碰撞并在复杂的情况下找到方法。 |
| Deep Learning Based Robot for Automatically Picking up Garbage on the Grass Authors Jinqiang Bai, Shiguo Lian, Zhaoxiang Liu, Kai Wang, Dijun Liu 本文介绍了一种在草地上作业的新型垃圾拾取机器人。通过使用深度神经网络进行垃圾识别,机器人能够准确,自动地检测垃圾。此外,利用深度神经网络进行地面分割,提出了一种新的导航策略来引导机器人四处移动。通过垃圾识别和自动导航功能,机器人可以高效,自主地清理公园或学校等地面上的垃圾。实验结果表明,垃圾识别精度可高达95,即使没有路径规划,导航策略也可以达到与传统方法几乎相同的清洁效率。因此,所提出的机器人可以作为一个很好的帮助,以减轻垃圾清洁任务中的尘土工人的体力劳动。 |
| Virtual-Blind-Road Following Based Wearable Navigation Device for Blind People Authors Jinqiang Bai, Shiguo Lian, Zhaoxiang Liu, Kai Wang, Dijun Liu 为了帮助盲人在室内环境中高效安全地到达目的地,本文提出了一种新型的可穿戴导航设备。定位,寻路,路线跟踪和避障模块是导航系统中必不可少的组件,而在路线跟踪期间考虑避障是一项具有挑战性的任务,因为室内环境复杂,多变且可能与动态物体相关。为了解决这个问题,我们提出了一种新方案,该方案利用动态子目标选择策略来引导用户到达目的地并帮助他们同时绕过障碍物。该方案是部署在一对可穿戴式光学透镜上的完整导航系统的关键部件,以便于盲人日常行走。所提出的导航设备已经在一组个人身上进行了测试,并证明对室内导航任务有效。嵌入式传感器成本低,体积小,易于集成,使得眼镜可以广泛用作可穿戴的消费设备。 |
| Curvature: A signature for Action Recognition in Video Sequences Authors He Chen, Gregory S. Chirikjian 在本文中,介绍了人类动作识别的新颖签名,即视频序列的曲率。以这种方式,建模顺序数据的分布,这使得几乎没有镜头学习。我们的算法不是依赖于识别图像中的特征,而是将动作视为整个图像序列中通用时间尺度上的序列。视频序列(在像素空间中被视为曲线)通过使用像素空间中的曲线的arclength进行重新参数化来对齐。一旦获得这样的曲率,就提取统计指数并将其馈送到基于学习的分类器中。总的来说,我们的方法简单但功能强大。初步实验结果表明,该方法是有效的,在基于视频的人体动作识别中达到了最先进的性能。此外,我们看到将这一想法转移到其他基于序列的识别应用程序(如语音识别,机器翻译和文本生成)的潜在能力。 |
| A Study on Action Detection in the Wild Authors Yubo Zhang, Pavel Tokmakov, Martial Hebert, Cordelia Schmid 最近推出的动作检测AVA数据集引起了人们对这一问题的兴趣。最近提出了几种改进性能的方法。然而,他们都忽略了AVA数据集的主要困难,即其实际分布的训练和测试实例。该数据集是通过在未经准确的视频中对人类行为的详尽注释来收集的。因此,最常见的类别,例如stand或sit,包含成千上万的例子,其中罕见的例子只有几十个。在这项工作中,我们研究了高度不平衡的数据集中的动作检测问题。与以前处理长尾类别分布的工作不同,我们首先分析测试集中的不平衡。我们证明了标准AP度量标准对于尾部的类别没有提供信息,并提出了另一个样本AP。有了这个新措施,我们研究了将表示从数据丰富的头部转移到稀有尾部类别的问题,并提出了一种简单但有效的方法。 |
| A neural network based on SPD manifold learning for skeleton-based hand gesture recognition Authors Xuan Son Nguyen, Luc Brun, Olivier L zoray, S bastien Bougleux 本文提出了一种基于SPD流形学习的神经网络,用于基于骨架的手势识别。鉴于手的关节位置流,我们的方法分别在空间和时间域上组合了两个聚合过程。我们的网络架构的管道包括三个主要阶段。第一阶段基于卷积层,以增加学习特征的判别力。第二阶段依赖于关节特征的空间和时间高斯聚合的不同架构。第三阶段从骨架数据中学习最终的SPD矩阵。基于Stiefel流形上随机梯度下降的变量,提出了第三阶段的新型层。所提出的网络在两个具有挑战性的数据集上得到验证,并显示了两个数据集的最新精度。 |
| Convolutional nets for reconstructing neural circuits from brain images acquired by serial section electron microscopy Authors Kisuk Lee, Nicholas Turner, Thomas Macrina, Jingpeng Wu, Ran Lu, H. Sebastian Seung 可以通过连续切片电子显微镜获得的脑图像重建神经回路。半个世纪以来,人工劳动一直在进行图像分析,自动化的努力几乎可以追溯到目前为止。十几年前卷积网首次应用于神经元边界检测,现在已经在清晰图像上获得了令人印象深刻的准确度。对图像缺陷的稳健处理是一项重大的突出挑战。卷积网也被用于神经回路重建的其他任务,寻找突触并识别突触伙伴,扩展或修剪神经元重建,以及对齐连续切片图像以创建3D图像堆栈。计算系统正在设计用于处理立方毫米脑容积的petavoxel图像。 |
| Learning Raw Image Denoising with Bayer Pattern Unification and Bayer Preserving Augmentation Authors Jiaming Liu, Chi Hao Wu, Yuzhi Wang, Qin Xu, Yuqian Zhou, Haibin Huang, Chuan Wang, Shaofan Cai, Yifan Ding, Haoqiang Fan, Jue Wang 在本文中,我们提出了基于DNN的原始图像去噪的新数据预处理和增强技术。与传统的RGB图像去噪相比,在直接相机传感器读数上执行此任务带来了新的挑战,例如如何有效地处理来自不同数据源的各种Bayer模式,以及随后如何使用原始图像执行有效的数据增强。为了解决第一个问题,我们提出了Bayer模式统一BayerUnify方法来统一不同的拜耳模式。这使我们能够充分利用异构数据集来训练单个去噪模型,而不是为每个模式训练一个模型。此外,虽然增加数据集以改进模型泛化和性能是必不可少的,但我们发现通过调整为RGB图像设计的增强方法来修改原始图像是容易出错的。为此,我们提出了一种Bayer保留增强BayerAug方法作为原始图像增强的有效方法。将这些数据处理技术与改进的U Net相结合,我们的方法在NTIRE 2019 Real Image Deoising Challenge中实现了52.11的PSNR和0.9969的SSIM,展示了最先进的性能。 |
| Learning to Find Common Objects Across Image Collections Authors Amirreza Shaban, Amir Rahimi, Stephen Gould, Byron Boots, Richard Hartley 我们解决了从图像提议集合中查找包含共同但未知的对象类别的一组图像的问题。我们的配方假设我们收到了一系列行李,其中每个行李都是一套图像提案。我们的目标是从每个包中选择一个图像,使得所选图像具有相同的对象类别。我们将选择模型化为具有一元和成对势函数的能量最小化问题。受最近几种镜头学习算法的启发,我们提出了一种直接从数据中学习潜在功能的方法。此外,我们提出了一种快速简单的贪婪推理算法,用于能量最小化。我们评估了我们针对少数镜头常见对象识别和对象共定位任务的方法。我们的实验表明,学习成对和一元术语大大提高了模型的性能,而不是几种众所周知的方法来完成这些任务。所提出的贪婪优化算法实现了与现有技术的结构化推理算法相当的性能,同时快了10倍。该代码可公开获取 |
| DiamondGAN: Unified Multi-Modal Generative Adversarial Networks for MRI Sequences Synthesis Authors Hongwei Li, Johannes C. Paetzold, Anjany Sekuboyina, Florian Kofler, Jianguo Zhang, Jan S. Kirschke, Benedikt Wiestler, Bjoern Menze 最近关于医学图像合成的研究报告了使用生成对抗网络的有希望的结果,主要集中于一对一的交叉模态综合。当然,这个想法产生了目标模态将受益于多模态输入。合成MR成像序列对于临床实践是非常有吸引力的,因为通常单个序列缺失或质量差,例如由于运动。然而,现有方法无法扩展到具有大量模态和大量非对齐体积的图像体积,面临复杂多模态成像序列的共同缺点。为了解决这些局限性,我们提出了一种新颖的,可扩展的多模式方法,称为DiamondGAN。当给定多个模态或任意任意子集时,我们的模型能够执行灵活的非对齐交叉模态合成和数据填充。它以端对端方式使用非对齐输入模式学习结构化信息。我们合成了两个具有临床相关性的MRI序列,即双反转恢复DIR和对比增强T1 T1c,它们是从三个常见的MRI序列重建的。此外,我们进行多评估者视觉评估实验,发现训练有素的放射科医师无法将我们的合成DIR图像与真实的DIR图像区分开来。 |
| Survey of Computer Vision and Machine Learning in Gastrointestinal Endoscopy Authors Anant S. Vemuri 本文试图为读者提供一个开始研究计算机视觉和机器学习在胃肠道胃肠镜检查中应用的场所。它们被分为18类。读者应该注意,这是一个深度学习时代的评论。本文没有涉及许多基于深度学习的应用程序。 |
| CT-To-MR Conditional Generative Adversarial Networks for Ischemic Stroke Lesion Segmentation Authors Jonathan Rubin, S. Mazdak Abulnaga 由急性中风引起的梗塞脑组织很容易在扩散加权磁共振成像DWI中显示为高信号区域。还提出,计算机断层扫描灌注CTP可替代地用于对中风患者进行分类,其中考虑到速度和可用性的改进以及降低的成本。然而,与MR相比,CTP具有较低的信噪比。在这项工作中,我们研究是否可以通过生成性对抗网络学习条件映射,以将CTP输入映射到生成的MR DWI,更清楚地描绘由缺血性中风引起的高信号区域。我们详细介绍了发生器和鉴别器的结构,并描述了用于执行从多模态CT灌注图到扩散加权MR输出的图像到图像转换的训练过程。我们通过视觉比较生成的MR与地面实况来定性地评估结果,并且通过训练完全卷积神经网络定量地评估结果,所述卷积神经网络利用生成的MR数据输入来执行缺血性中风病变分割。与仅使用CT灌注输入的网络相比,使用生成的CT到MR输入训练的分割网络导致用于评估的所有度量的至少一些改善。 |
| Country-wide high-resolution vegetation height mapping with Sentinel-2 Authors Nico Lang, Konrad Schindler, Jan Dirk Wegner 在几个月的时间内收集的Sentinel 2多光谱图像用于估算加蓬(瑞士)的植被高度。训练深度卷积网络以从反射图像中提取合适的光谱和纹理特征并回归每像素植被高度。在加蓬,训练和验证的参考高度来自机载LiDAR测量。在瑞士,参考高度取自现有的通过摄影测量表面重建得到的冠层高度模型。得到的地图在瑞士的平均绝对误差MAE为1.7m,加蓬的平均绝对误差为4.3m,并且正确地再现了高达50m的植被高度。它们还与现有植被高度图显示出良好的定性一致性。我们的工作表明,给定适量的参考数据,可以从Sentinel 2图像中在国家范围内推导出具有10米地面采样距离GSD的密集植被高度图。 |
| Signal2Image Modules in Deep Neural Networks for EEG Classification Authors Paschalis Bizopoulos, Dimitrios Koutsouris 深度学习利用大数据的增加可用性和图形处理单元等并行计算单元的强大功能,彻底改变了计算机视觉。绝大多数深度学习研究是使用图像作为训练数据进行的,然而生物医学领域富含生理信号,用于诊断和预测问题。如何最好地利用信号来训练深度神经网络仍然是一个开放的研究问题。 |
| Semantic Referee: A Neural-Symbolic Framework for Enhancing Geospatial Semantic Segmentation Authors Marjan Alirezaie, Martin L ngkvist, Michael Sioutis, Amy Loutfi 理解机器学习算法可能失败的原因通常是人类专家的任务,它使用领域知识和上下文信息来发现数据或算法中的系统缺陷。在本文中,我们提出了一种语义裁判,它能够提取深度机器学习框架中出现的错误的定性特征并提出修正建议。语义裁判依赖于关于空间知识的本体论推理,以便根据它们与环境的空间关系来表征错误。使用语义,推理器作为主管与学习算法交互。在本文中,提出的神经网络分类器和语义裁判之间的交互方法显示了如何提高卫星图像数据的语义分割性能。 |
| Deep Spectral Clustering using Dual Autoencoder Network Authors Xu Yang, Cheng Deng, Feng Zheng, Junchi Yan, Wei Liu 聚类方法最近吸收了更多的学习和视觉注意力。深度聚类将嵌入和聚类结合在一起以获得用于聚类的最佳嵌入子空间,与传统的聚类方法相比,这可以更有效。在本文中,我们提出了一个用于判别嵌入和谱聚类的联合学习框架。我们首先设计了一个双自动编码器网络,它对潜在表示及其噪声版本强制执行重建约束,将输入嵌入潜在空间进行聚类。因此,所学习的潜在表示对于噪声可以更稳健。然后利用互信息估计从输入提供更多的判别信息。此外,应用深谱聚类方法将潜在表示嵌入到本征空间中并随后将它们聚类,这可以充分利用输入之间的关系以实现最佳聚类结果。基准数据集的实验结果表明,我们的方法可以明显优于最先进的聚类方法。 |
| Learning Image Information for eCommerce Queries Authors Utkarsh Porwal 计算查询和文档之间的相似性是任何信息检索系统的基础。在搜索引擎中,计算查询文档相似性是检索和排序阶段中必不可少的步骤。在eBay搜索中,文档是项目,并且可以通过比较查询项目对的不同方面来计算查询项目相似性。查询文本可以与项目标题的文本进行比较。同样,可以将对查询应用的类别约束与项目的列表类别进行比较。但是,图像是一个通常存在于项目中但在查询中不存在的信号。图像是用户用来确定给定查询的项目的相关性的最直观信号之一。在估计查询项对之间的相似性中包括该信号可能会提高搜索引擎的相关性。我们提出了一种为查询导出图像信息的新方法。我们尝试从项目图像中学习查询的图像信息,而不是生成显式图像特征或查询图像。我们使用典型相关分析CCA来学习新的子空间,其中投影原始数据将为我们提供新的查询和项目表示。我们假设这个新的查询表示还将具有关于查询的图像信息。我们使用向量空间模型估计查询项目相似性,并在eBay的搜索数据上报告所提出方法的性能。我们使用接收器操作特性曲线AUROC下的面积作为评估指标,显示了相对于基线的11.89相关性改进。我们还在精确回忆曲线AUPRC下显示了相对于基线的3.1相关性改进。 |
| Learning to Index for Nearest Neighbor Search Authors Chih Yi Chiu, Amorntip Prayoonwong, Yin Chih Liao 在这项研究中,我们提出了一种基于嵌入在索引空间中的学习邻域关系的新颖排名模型。给定查询点,传统的近似最近邻搜索在基于距离从近到远对群集进行排序之前计算到群集质心的距离。检索在排名最高的集群中索引的数据并将其视为查询的最近邻居候选者。然而,数据和聚类质心之间的量化损失将不可避免地损害搜索精度。为了解决这个问题,所提出的模型基于它们的最近邻概率而不是查询质心距离对聚类进行排序。通过使用神经网络来表征邻域关系(即,关于查询的最近邻居的密度函数)来估计最近邻概率。所提出的基于概率的排名可以替换用于查找候选聚类的传统的基于距离的排名,并且预测的概率可以用于确定要从候选聚类中检索的数据量。我们的实验结果表明,所提出的排名模型可以在十亿比例的数据集中有效地提高搜索性能。 |
| Chinese Abs From Machine Translation |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}