
【今日CV 计算机视觉论文速览 第113期】Wed, 8 May 2019
今日CS.CV 计算机视觉论文速览
Wed, 8 May 2019
Totally 44 papers
👉上期速览✈更多精彩请移步主页

Interesting:
📚***MobileNetV3新一代高效的移动端神经网络, 结合互补搜索技术和新型架构谷歌提出了新一代的mobilenet。研究人员利用网络搜索和NetAdapt算法那进行调试,随后利用了新型架构进行了改进。这篇文章主要讲解了如何利用自动化的搜索算法和网络设计改进模型表现。研究人员创造了MobileNetV3-Large和MobileNet-Small模型,并在目标检测和语意分割上进行了应用。在语义分割中提出了了Lite Reduced Atrous Spatial Pyramid Pooling (LR-ASPP) 方法实现了3.2%提升,比v2版本减小了15%。在分割和检测任务中表现更快更好了。(from 谷歌)
新型的V3模块架构:

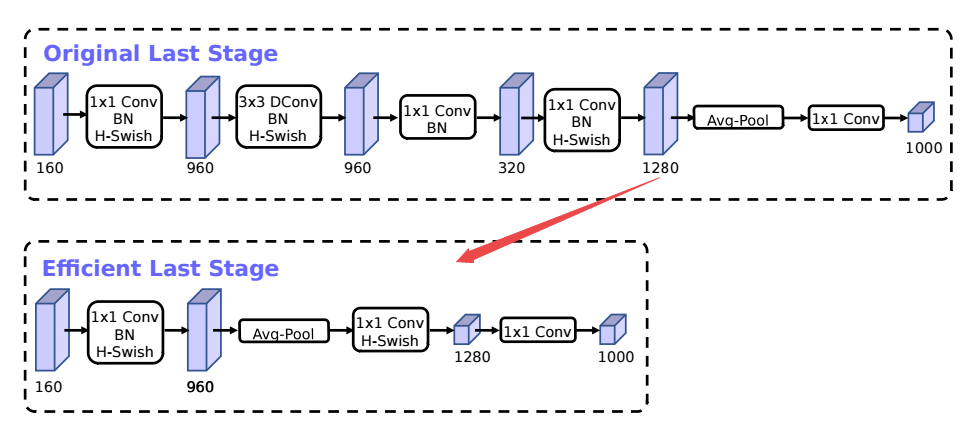
高效的最后级:
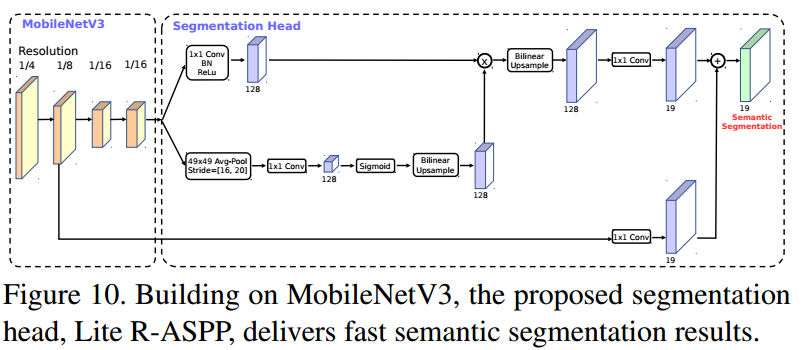
新提出的分割方法头:
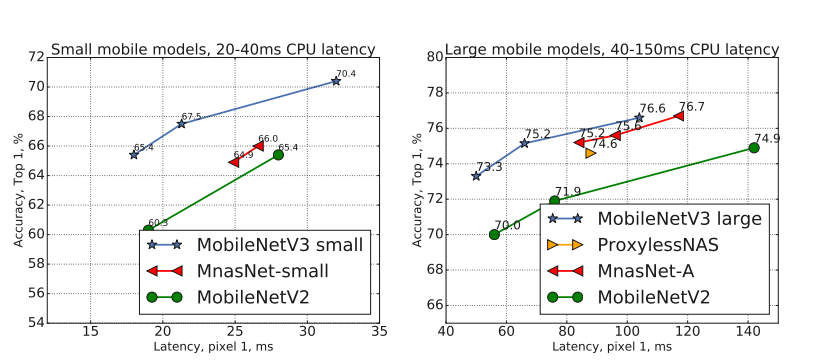
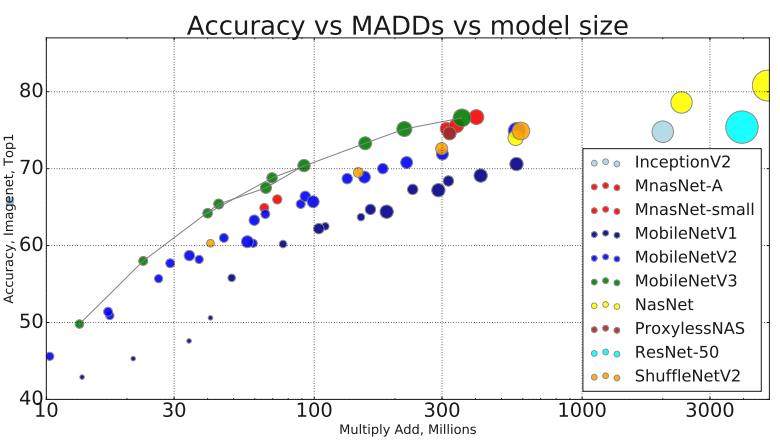
模型的精度与速度,模型*小与精度:
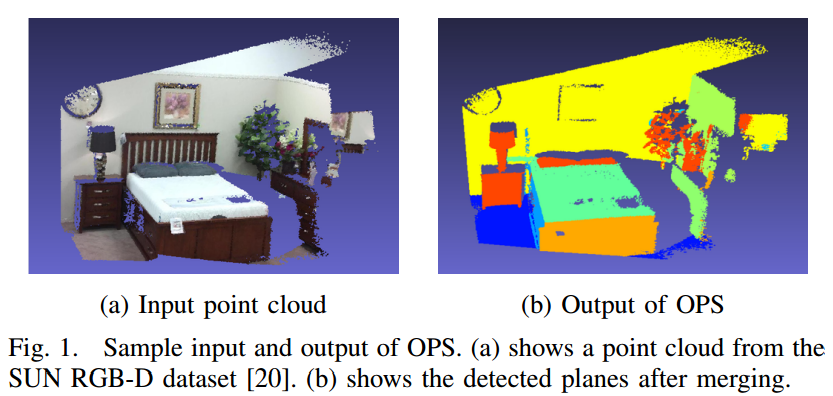
📚Oriented Point Sampling,OPS 方向点云采样用于无序点云中的平面检测, 基于稀疏采样并估计法向量,随后生成假设平面,在所有点上最后验证平面。(from Stevens Institute of Technology 斯蒂文斯理工学院)
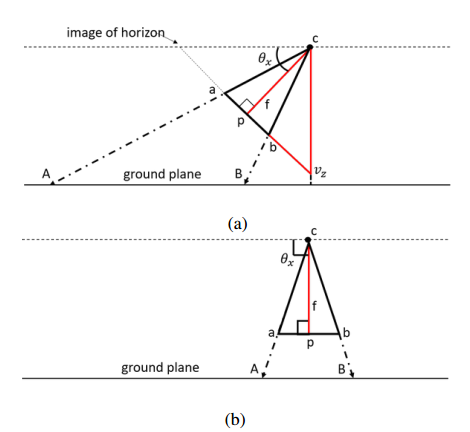
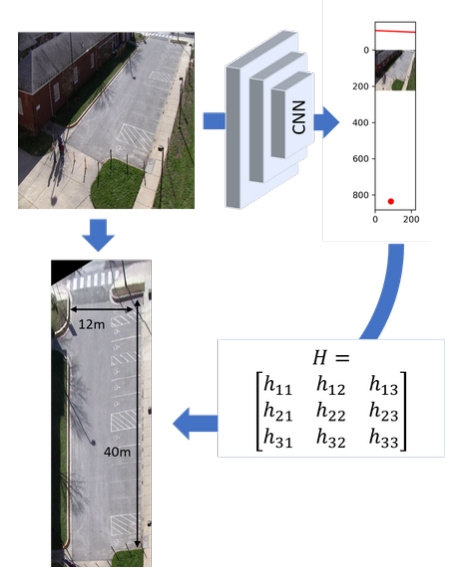
📚基于几何方法得到鸟瞰图, 通过计算单应性矩阵从而将任意单目视图转化为鸟瞰图。首先利用CNN 来表示点线的几何结构(水平线和消失点四个参数),随后利用合成数据集来进行训练,并在真实数据集撒和功能取得了74.52的AUC。(from VGG 牛津)
鸟瞰图的相机视角:
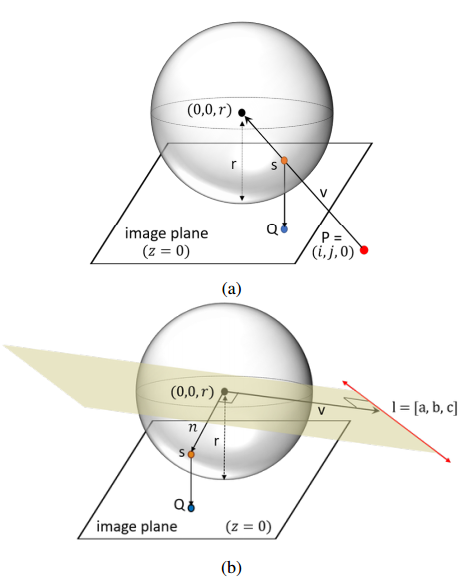
流程方法和一些结果:

dataset:Horizon Lines in the Wild dataset CARLA-VP Dataset CARLA [13]
https://drive.google.com/drive/folders/1o9ydKCnh0oyIMFAw7oNxQohFa0XM4V-g
📚基于卫星图像预测乡村人口密度, 精确的人口密度对于政府治理十分重要,但人口普查无法精确覆盖所有的人口。本文基于卫星图像和普查基数提供了一种基于卫星图像的人口密度估计方法。(from 斯坦福 )
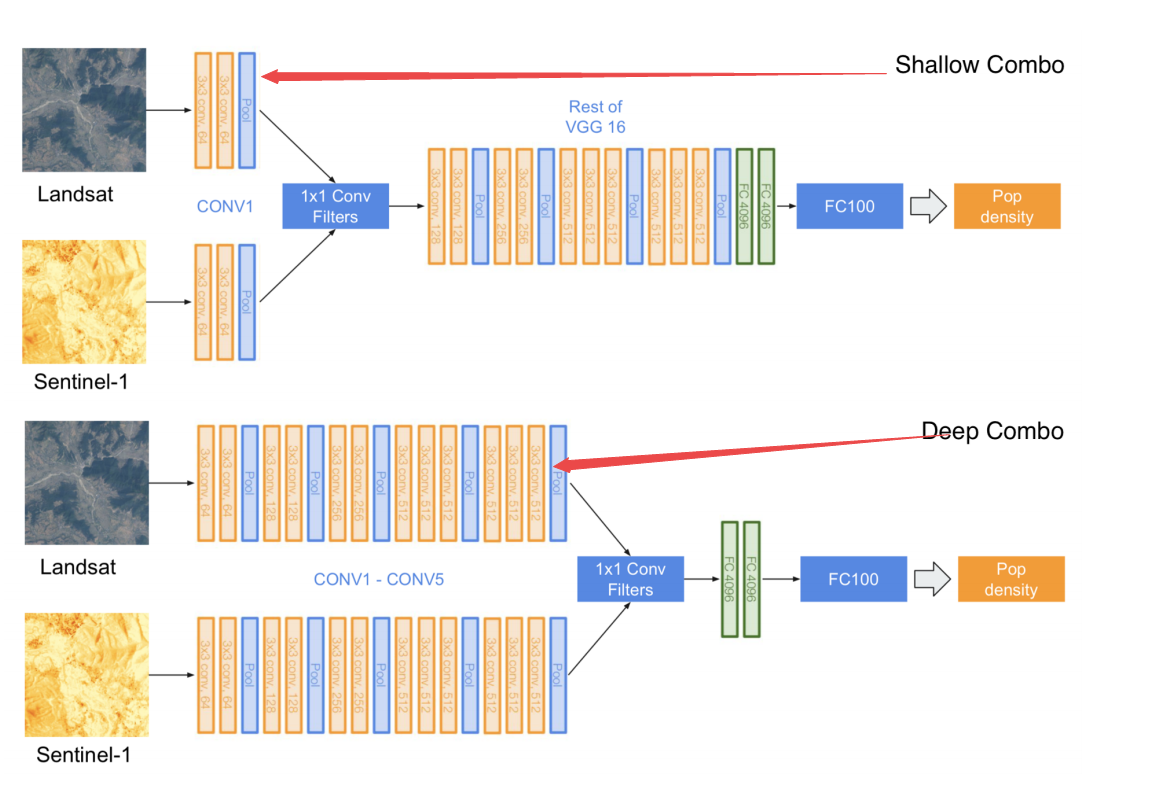
印度真实人口密度结果和预测误差:
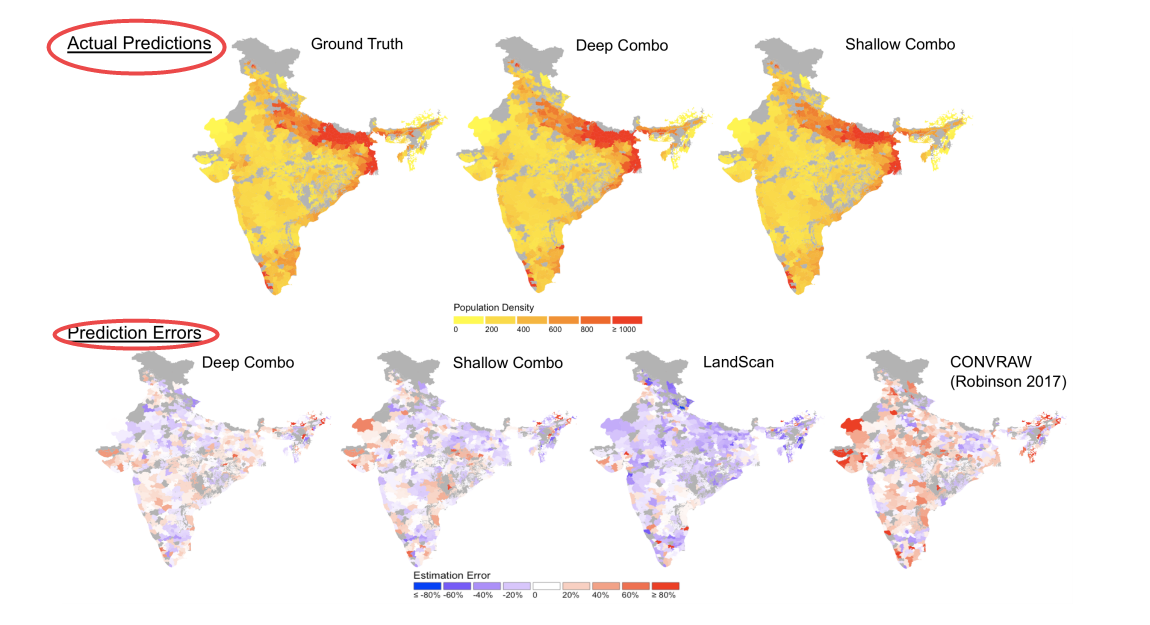
数据集:Landsat-8 Sentinel-1
ref: LandScan
📚CRF Simulator条件随机场模拟器, 文章提出了一种基于CNN标准架构模拟条件随机场正则化的模拟方法,可以生成数据来训练CRF模拟器,并可集成到CNN架构中,将CRF与CNN的能力进行了结合。(from University of Western Ontario)
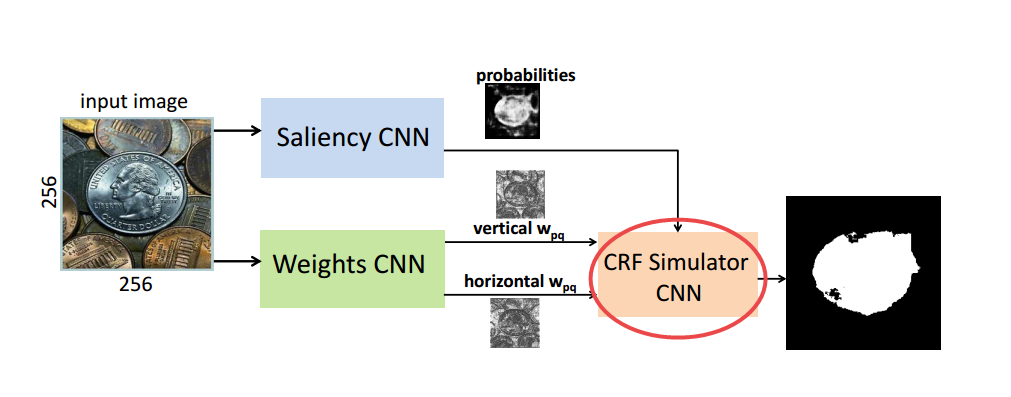
author:http://www.csd.uwo.ca/~olga/
http://www.csd.uwo.ca/~ygorelic/
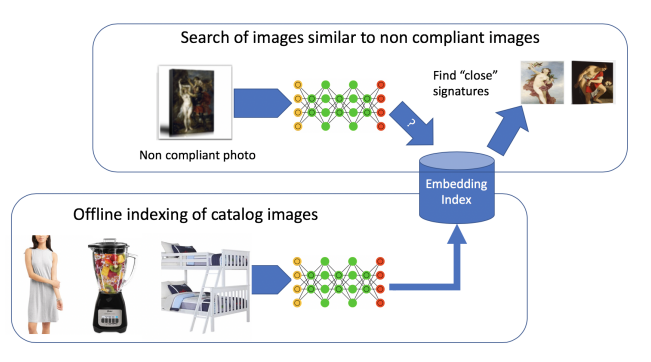
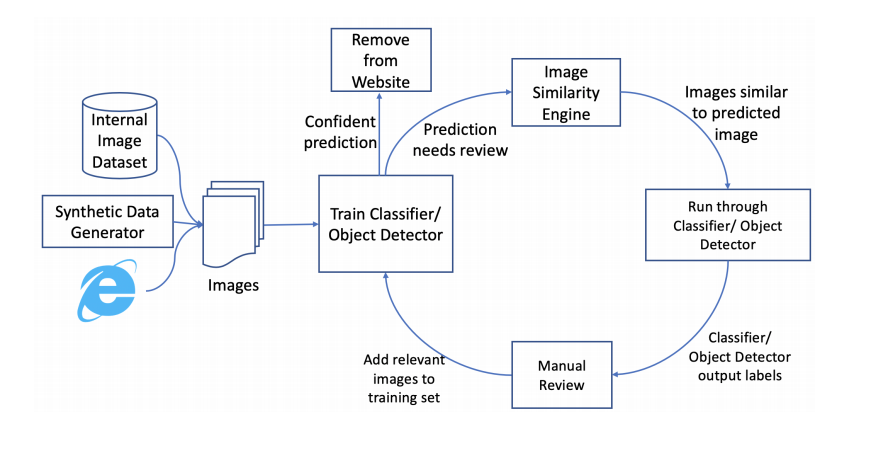
📚Image Matters检测不适宜内容, 提出了一种检测电子商务网站上具有冒犯性或者不宜内容的方法。主要基于网络数据和合成数据将暴力、性暗示和不合时宜的商标logo图像检测出来进行处理。(from 沃尔玛实验室)
数据收集方法视觉检索,以及训练框架:
Daily Computer Vision Papers
| EDVR: Video Restoration with Enhanced Deformable Convolutional Networks Authors Xintao Wang, Kelvin C.K. Chan, Ke Yu, Chao Dong, Chen Change Loy 视频恢复任务,包括超分辨率,去模糊等,正在计算机视觉界引起越来越多的关注。在NTIRE19挑战赛中发布了名为REDS的具有挑战性的基准。这个新基准从两个方面挑战现有方法1如何在给定*运动的情况下对齐多个帧,以及2如何有效地融合具有不同运动和模糊的不同帧。在这项工作中,我们提出了一种新的视频恢复框架,其具有增强的可变形网络,称为EDVR,以应对这些挑战。首先,为了处理*型运动,我们设计了金字塔,级联和可变形PCD对准模块,其中使用可变形卷积以粗略到精细的方式在特征级别进行帧对齐。其次,我们提出了一种时空空间注意TSA融合模块,其中在时间和空间上都应用注意力,以强调后续恢复的重要特征。得益于这些模块,我们的EDVR赢得了冠军,并且在NTIRE19视频恢复和增强挑战的所有四个轨道中都*幅超越了第二名。 EDVR还展示了对视频超分辨率和去模糊的最新发布方法的卓越性能。代码可在 |
| Context-Aware Automatic Occlusion Removal Authors Kumara Kahatapitiya, Dumindu Tissera, Ranga Rodrigo 遮挡移除是图像增强的一个有趣应用,为此,现有工作建议手动注释或特定于域的遮挡移除。没有工作尝试将自动遮挡检测和移除作为上下文感知的一般问题来解决。在本文中,我们提出了一种新方法,用于识别与图像上下文无关的对象作为遮挡并将其移除,重建相干占据的空间。所提出的系统通过考虑表示为矢量嵌入的前景和背景对象类之间的关系来检测遮挡,并通过修复来移除它们。我们在COCO Stuff数据集上测试我们的系统并进行用户研究以在上下文感知自动遮挡移除中建立基线。 |
| Learning Unsupervised Multi-View Stereopsis via Robust Photometric Consistency Authors Tejas Khot, Shubham Agrawal, Shubham Tulsiani, Christoph Mertz, Simon Lucey, Martial Hebert 我们提出了一种基于学习的多视图立体视觉MVS方法。虽然目前深度MVS方法取得了令人瞩目的成果,但它们至关重要地依赖于地面实况3D训练数据,并且获取这种精确的3D几何形状以进行监督是一个主要障碍。我们的框架反而利用多个视图之间的光度一致性作为用于在宽基线MVS设置中学习深度预测的监督信号。然而,由于跨视图的遮挡和光照变化,天真地应用照片一致性约束是不期望的。为了克服这个问题,我们提出了一个强*的损失公式,它强制执行一阶一致性,每个点执行b,有选择地强制与某些视图保持一致,从而隐式处理遮挡。我们展示了使用真实数据集在没有3D监督的情况下学习MVS的能力,并表明我们提出的强*损失的每个组成部分都会带来显着的改进。我们定性地观察到我们的重建通常比获得的基本事实更完整,进一步显示了这种方法的优点。最后,我们的学习模型推广到新颖的设置,我们的方法允许通过无监督的微调,将现有CNN适应数据集,而无需地面实况3D。项目网页 |
| PackNet-SfM: 3D Packing for Self-Supervised Monocular Depth Estimation Authors Vitor Guizilini, Rares Ambrus, Sudeep Pillai, Adrien Gaidon 从单个图像密集地估计场景的深度是一个不适当的逆问题,其通过来自强几何线索的自我监督看到令人兴奋的进展,特别是来自使用立体图像的训练。在这项工作中,我们研究了运动SfM设置中更具挑战性的结构,纯粹从单眼视频学习。我们建议PackNet采用一种新颖的深层架构,利用新的3D打包和解包块来有效捕获单眼深度图预测中的精细细节。此外,我们提出了一种新颖的速度监控损耗,它允许我们的模型预测精确的精确深度,从而减少了测试时间地面实例缩放的需要。我们展示了我们提出的尺度感知架构在KITTI基准测试中实现了最先进的结果,显着改进了对单眼视频训练的任何方法,甚至实现了立体训练方法的竞争性能。 |
| Feature-Fused Context-Encoding Network for Neuroanatomy Segmentation Authors Yuemeng Li, Hangfan Liu, Hongming Li, Yong Fan 细粒度脑结构的自动分割仍然是一项具有挑战性的任务。目前的分割方法主要利用2D和3D深度神经网络。 2D网络将图像切片作为输入以在较少的处理时间内产生粗分割,而3D网络使整个图像体积生成具有更多计算负担的精细细分。为了有效地获得准确的细粒度分割,本文提出了一种端到端的特征融合上下文编码网络,用于MR磁共振图像的脑结构分割。我们的模型基于2D卷积骨干实现,其集成了2D编码模块以获取平面图像特征,并且空间编码模块用于提取空间背景信息。进一步引入全局上下文编码模块以从融合的2D编码和空间特征捕获全局上下文语义。所提出的网络旨在充分利用从上下文语义学习的全局解剖学先验知识,其由结构感知注意因子表示以重新校准网络的输出。以这种方式,保证网络知道依赖于类的特征图以便于分割。我们在2012 Brain Multi Atlas Labeling Challenge数据集上评估我们的模型,用于134细粒度结构分割。此外,我们在27个粗结构分段任务上验证我们的网络。实验结果表明,与现有技术方法相比,我们的模型可以实现更好的性能。 |
| Attention-based Fusion for Multi-source Human Image Generation Authors St phane Lathuili re, Enver Sangineto, Aliaksandr Siarohin, Nicu Sebe 我们提出了人物图像生成任务的概括,其中以目标姿势和源外观图像的集合X为条件生成人类图像。通过这种方式,我们可以利用同一人的多个,可能是互补的图像,这些图像通常在训练和测试时可用。我们提出的解决方案主要基于本地注意机制,该机制从不同的源图像区域中选择相关信息,避免为X的每个特定基数构建特定生成器的必要性。我们的方法的实证评估显示了解决该人的实际利益。多源设置中的图像生成问题。 |
| High Frequency Residual Learning for Multi-Scale Image Classification Authors Bowen Cheng, Rong Xiao, Jianfeng Wang, Thomas Huang, Lei Zhang 我们提出了一种新颖的高频残差学习框架,它为移动和嵌入式视觉问题提供了一个高效的多尺度网络MSNet架构。该架构利用两个网络,低分辨率网络有效地近似低频分量和高分辨率网络,通过重用上采样的低分辨率特征来学习高频残差。通过分类器校准模块,MSNet可以在推理期间动态分配计算资源,以实现更好的速度和准确性权衡。我们在具有挑战性的ImageNet 1k数据集上评估我们的方法,并观察不同基础网络的一致改进。在具有alpha 1.0的ResNet 18和MobileNet上,MSNet在两种体系结构上都获得1.5准确度,而不会增加计算量。在具有alpha 0.25的更高效的MobileNet上,我们的方法在相同的计算量下获得3.8精度。 |
| Efficient Neural Architecture Search on Low-Dimensional Data for OCT Image Segmentation Authors Nils Gessert, Alexander Schlaefer 通常,深度学习架构是针对各自的学习问题手工制作的。作为替代方案,已经提出了神经架构搜索NAS,其中在另外的优化步骤中学习架构的结构。对于医学成像领域,这种方法非常有前途,因为存在需要架构设计的各种问题和成像模式。然而,NAS非常耗时并且医学学习问题通常涉及具有高计算要求的高维数据。我们通过在低维数据上搜索架构,然后将其转移到高维数据,在医学,基于图像的深度学习问题的背景下提出了一种有效的NAS方法。对于基于OCT的图层分割,我们证明了对一维数据的搜索与搜索二维数据相比,搜索时间减少了87.5,而最终的二维模型实现了类似的性能。 |
| Oriented Point Sampling for Plane Detection in Unorganized Point Clouds Authors Bo Sun, Philippos Mordohai 3D点云中的平面检测是点云分割,语义映射和SLAM等应用的关键预处理步骤。与最近仅适用于有组织点云的许多平面检测方法相比,我们的工作针对的是无法进行2D参数化的无组织点云。我们比较了三种有效检测点云平面的方法。一种是本文提出的一种新方法,它通过从具有估计法线的一组点中采样来生成平面假设。我们将这种方法命名为Oriented Point Sampling OPS,以与需要对三个无定向点进行采样以产生平面假设的更传统技术进行对比。我们还实现了一种基于三个无定向点的局部采样的有效平面检测方法,并将其与OPS和基于八叉树的3D KHT算法进行比较,以检测来自SUN RGB D数据集的10,000个点云的平面。 |
| Learning Spatio-Temporal Features with Two-Stream Deep 3D CNNs for Lipreading Authors Xinshuo Weng, Kris Kitani 我们专注于单词级视觉唇读,这需要识别所说的单词,仅给出视频但不给出音频。现有技术方法探索端到端神经网络的使用,包括浅层三层3D卷积神经网络CNN,深2D CNN网络,例如, ,ResNet作为提取视觉特征的前端,以及一个循环的神经网络。 ,双向LSTM作为后端进行分类。在这项工作中,我们建议用最近成功的深3D CNN两个流,即灰度视频和光流流I3D替换浅3D CNN深2D CNN前端。我们使用LRW数据集上的灰度视频和光流输入评估前端和后端模块的不同组合。实验表明,与浅3D CNN深2D CNN前端相比,深3D CNN前端在*规模图像和视频数据集上进行预训练。 ,ImageNet和Kinetics可以提高分类准确性。另一方面,我们证明单独使用光流输入可以实现与使用灰度视频作为输入相当的性能。此外,使用灰度视频和光流输入的两个流网络可以进一步改善性能。总的来说,我们的双流I3D前端带有Bi LSTM后端,与现有技术相比,其绝对性能提高了5.3。 |
| Trinity of Pixel Enhancement: a Joint Solution for Demosaicking, Denoising and Super-Resolution Authors Guocheng Qian, Jinjin Gu, Jimmy S. Ren, Chao Dong, Furong Zhao, Juan Lin 去马赛克,去噪和超分辨率SR在数字图像处理中具有实际重要性,并且在过去的几十年中已经独立研究。尽管最近基于学习的图像处理方法在图像质量方面得到了改进,但在去马赛克,去噪和SR的混合问题的实际设置下,缺乏足够的分析它们的相互作用和特征。在现有解决方案中,简单地组合这些任务以从低分辨率原始马赛克图像获得高分辨率图像,导致最终图像质量的性能下降。在本文中,我们首先从整体的角度重新思考混合问题,然后提出三位一体增强网络TENet,一种专门设计的混合问题学习方法,采用新颖的图像处理流水线顺序和联合学习策略。为了获得正确的训练颜色采样,我们还提供了一个新的数据集,即PixelShift200,它使用先进的像素移位技术,由高质量的全色采样现实世界图像组成。实验表明,我们的TENet在定量和定性方面都优于现有解决方案。我们的实验还表明了PixelShift200数据集的必要性。 |
| Contrastive Learning for Lifted Networks Authors Christopher Zach, Virginia Estellers 在这项工作中,我们通过提升网络配方解决有监督的学习问题。提升网络很有意思,因为它们允许在*规模并行硬件上进行训练,并将能量模型分配给有区别训练的神经网络。我们证明文献中提出的提升网络的训练方法具有显着的局限性,因此我们建议使用对比损失来训练提升的网络。我们证明了这种对比训练在理论上和实践中近似于反向传播,并且它优于提升网络的常规训练目标。 |
| Learning to Interpret Satellite Images in Global Scale Using Wikipedia Authors Burak Uzkent, Evan Sheehan, Chenlin Meng, Zhongyi Tang, Marshall Burke, David Lobell, Stefano Ermon 尽管最近在计算机视觉方面取得了进展,但由于缺乏标记的训练数据,卫星图像的细粒度解释仍然具有挑战性。为了克服这个限制,我们通过将地理参考维基百科文章与其相应位置的卫星图像配对,构建了一个名为WikiSatNet的新数据集。然后,我们提出两种策略来通过从图像中预测相应物品的属性来学习卫星图像的表示。利用这种新的多模态数据集,我们可以*幅减少人类注释标签的数量和下游任务所需的时间。在最近发布的fMoW数据集中,我们的预训练策略可以将在ImageNet上预训练的模型的性能提高多达4分(F1分数)。 |
| Locality and Structure Regularized Low Rank Representation for Hyperspectral Image Classification Authors Qi Wang, Xiange He, Xuelong Li 高光谱图像HSI分类旨在为高光谱像素分配准确的标签,近年来引起了极*的兴趣。虽然低秩表示LRR已被用于对HSI进行分类,但其从整个HSI数据中分割每个类的能力尚未被完全利用。 LRR具有捕获原始数据中嵌入的底层低维子空间的良好能力。但是,LRR仍有两个缺点。首先,LRR不考虑数据内的局部几何结构,这使得相邻数据之间的局部相关性容易被忽略。其次,通过求解LRR获得的表示不足以区分不同的数据。本文提出了一种新的局部性和结构正则化低秩表示LSLRR模型用于HSI分类。为克服上述局限性,我们提出局部约束准则LCC和结构保持策略SPS来改进经典LRR。具体来说,我们引入了一种新的距离度量,它结合了空间和光谱特征,以探索像素的局部相似性。因此,可以充分利用HSI数据的全局和局部结构。此外,我们提出了一种结构约束,使表示具有近块对角线结构。这有助于直接确定最终的分类标签。已经对三种流行的HSI数据集进行了广泛的实验。实验结果表明,所提出的LSLRR优于其他最先进的方法。 |
| P2SGrad: Refined Gradients for Optimizing Deep Face Models Authors Xiao Zhang, Rui Zhao, Junjie Yan, Mengya Gao, Yu Qiao, Xiaogang Wang, Hongsheng Li 基于余弦的softmax损失显着改善了深度识别网络的性能。然而,这些损失总是包括敏感的超参数,这可能使训练过程不稳定,并且为特定数据集设置合适的超参数是非常棘手的。本文通过直接设计自适应训练深度神经网络的梯度来解决这一挑战。我们首先通过分析它们的梯度来研究和统一以前的余弦softmax损失。这种统一的观点激发我们提出一种新的梯度,称为P2SGrad概率相似梯度,利用余弦相似性而不是分类概率来直接更新测试指标以更新神经网络参数。 P2SGrad具有自适应性和超参数,这使得训练过程更加高效和快速。我们在三个面部识别基准,LFW,MegaFace和IJB C上评估我们的P2SGrad。结果表明P2SGrad在训练中是稳定的,对噪声具有鲁棒性,并且在所有三个基准测试中都达到了最先进的性能。 |
| Ensemble of Convolutional Neural Networks Trained with Different Activation Functions Authors Gianluca Maguolo, Loris Nanni, Stefano Ghidoni 激活函数在卷积神经网络的训练中起着至关重要的作用。因此,开发高效和执行功能是深度学习社区中的一个关键问题。这些方法的关键是允许可靠的参数学习,避免消失的梯度问题。这项工作的目标是提出一个使用几种不同激活函数训练的卷积神经网络集合。此外,这里首次提出了一种新颖的激活功能。我们的目标是在中小型生物医学数据集中提高卷积神经网络的性能。我们的结果清楚地表明,所提出的集合优于使用标准ReLU训练的卷积神经网络作为激活函数。所提出的集合优于p值0.01每个测试的独立激活函数以进行可靠的性能比较我们使用两个众所周知的卷积神经网络Vgg16和ResNet50在10个以上的数据集中测试了我们的方法。此处使用的MATLAB代码将在 |
| Adapting Image Super-Resolution State-of-the-arts and Learning Multi-model Ensemble for Video Super-Resolution Authors Chao Li, Dongliang He, Xiao Liu, Yukang Ding, Shilei Wen 最近,图像超分辨率已被广泛研究,并通过利用深度卷积神经网络的力量取得了重*进展。然而,由于视频中的复杂时间模式,视频超分辨率VSR的进步有限。在本文中,我们研究如何适应视频超分辨率的图像超分辨率的最新方法。所提出的适应方法很简单。连续帧之间的信息被很好地利用,而原始图像超分辨率方法的开销可以忽略不计。此外,我们提出了一种基于学习的方法来集成来自多个超分辨率模型的输出。我们的方法在NTIRE2019视频超分辨率挑战赛1中表现出色,并排名第二。 |
| Interactive Video Retrieval with Dialog Authors Sho Maeoki, Kohei Uehara, Tatsuya Harada 现在每个人都可以轻松录制视频,其数量不断增加,对改进视频检索方法的研究在当代世界中非常重要。在要由个人收集的*型集合中识别目标视频的情况下,必须获得适当的信息以在目标数据库中的*量类似项目内检索正确的视频。本研究的目的是通过在系统和用户之间引入交互或对话来检索此类情况下的目标视频。我们提出了一种系统,通过询问有关视频内容的问题并利用用户对问题的回答来检索视频。此外,我们使用名为AVSD的数据集通过实验确认了所提议系统的实用性,该数据集包括有关视频的视频和对话框。 |
| LEDNet: A Lightweight Encoder-Decoder Network for Real-Time Semantic Segmentation Authors Yu Wang, Quan Zhou, Jia Liu, Jian Xiong, Guangwei Gao, Xiaofu Wu, Longin Jan Latecki 广泛的计算负担限制了移动设备中CNN在密集估计任务中的使用。在本文中,我们提出了一个轻量级网络来解决这个问题,即LEDNet,它采用非对称编码器解码器架构来进行实时语义分段。更具体地说,编码器采用ResNet作为骨干网络,其中两个新的操作,在每个残余块中利用信道分离和混*,以**降低计算成本,同时保持更高的分割精度。另一方面,在解码器中采用注意金字塔网络APN以进一步减轻整个网络的复杂性。我们的模型参数不到1M,并且能够在单个GTX 1080Ti GPU中以超过71 FPS的速度运行。综合实验表明,我们的方法在CityScapes数据集的速度和准确性权衡方面实现了最先进的结果。 |
| Recovering remote Photoplethysmograph Signal from Facial videos Using Spatio-Temporal Convolutional Networks Authors Zitong Yu, Xiaobai Li, Guoying Zhao 最近,基于非接触式远程光电容积描记术rPPG,可以从人脸视频相对准确地测量平均心率HR。然而,在许多医疗保健应用中,仅知道平均HR是不够的,并且测量的血容量脉冲信号及其心率变异性HRV特征也是重要的。我们提出了第一个端到端rPPG信号恢复系统PhysNet,使用深度时空卷积网络来测量HR和HRV特征。 PhysNet从原始面部序列同时提取空间和时间隐藏特征,同时直接输出相应的rPPG信号。时间上下文信息有助于网络以较小的波动学习更强*的特征。我们的方法在两个数据集上进行了测试,与现有技术方法相比,实现了HR和HRV特性的卓越性能。 |
| Accurate Tissue Interface Segmentation via Adversarial Pre-Segmentation of Anterior Segment OCT Images Authors Jiahong Ouyang, Tejas Sudharshan Mathai, Kira Lathrop, John Galeotti 光学相干断层扫描OCT是一种成像模式,已广泛用于以微米分辨率可视化角膜,视网膜和角膜缘组织结构。它可用于诊断眼睛的病理状况,并用于制定术前手术计划。与后视网膜相比,对前组织结构(例如角膜缘和角膜)进行成像,导致B扫描显示出增加的斑点噪声模式和成像伪影。这些伪像(例如阴影和镜面反射)在获取的体积分析期间提出了挑战,因为它们基本上模糊了组织界面的位置。为了处理伪影和斑点噪声模式并精确分割最浅的组织界面,我们提出了一种级联神经网络框架,其包括条件生成性对抗网络cGAN和组织界面分割网络TISN。 cGAN预分段OCT B通过在最浅组织界面上方移除不期望的镜面伪影和散斑噪声图案来扫描,并且TISN将原始OCT图像与预分割组合以分割最浅界面。我们展示了级联框架对角膜数据集的适用性,证明它精确地分割了最浅的角膜界面,并且还显示了其对角膜缘数据集的泛化能力。我们还提出了一种混合框架,其中将cGAN预分割传递给基于传统图像分析的分割算法,并描述改进的分割性能。据我们所知,这是在影响前段OCT数据集解释的最浅界面之前去除严重镜面伪影和散斑噪声模式的第一种方法,从而导致最浅组织界面的准确分割。 |
| Variational Representation Learning for Vehicle Re-Identification Authors Saghir Ahmed Saghir Alfasly, Yongjian Hu, Tiancai Liang, Xiaofeng Jin, Qingli Zhao, Beibei Liu 近年来,车辆识别识别越来越受到关注。最具挑战性的问题之一是从其多视点图像中学习车辆的有效表示。现有方法倾向于导出尺寸范围从数千到数万的特征。在这项工作中,我们提出了一个基于深度学习的框架,可以导致车辆的有效表示。虽然学习特征的维度可以低至256,但是对不同数据集的实验表明,前1和前5的检索精度超过了多种最先进的方法。我们框架的关键是双重的。首先,采用变分特征学习来生成更具区别性的变分特征。其次,长期短期记忆LSTM用于学习车辆的不同视点之间的关系。 LSTM还可以作为编码器来缩小功能。 |
| Semantic Adversarial Network for Zero-Shot Sketch-Based Image Retrieval Authors Xinxun Xu, Hao Wang, Leida Li, Cheng Deng 基于零镜头草图的图像检索ZS SBIR是一种特定的交叉模态检索任务,用于在零拍摄场景下用自由手绘草图检索自然图像。以前的工作主要集中在建模图像和草图之间的对应关系或使用草图特征合成图像特征。但是,它们都忽略了草图的*的类内方差,从而导致检索性能不令人满意。在本文中,我们为ZS SBIR提出了一种新颖的端到端语义对抗方法。具体来说,我们设计了一个语义对抗模块,以最*化学习的语义特征和类别级别的单词向量之间的一致性。此外,为了保持每个训练类别内的合成特征的可辨别性,生成模块采用三元组损失。此外,所提出的模型在端到端策略中进行训练,以利用适用于ZS SBIR的更好的语义特征。在两个*规模流行数据集上进行的*量实验表明,我们提出的方法在Sketchy数据集上的表现优于现有技术的12个以上,在检索中的TU Berlin数据集上超过3个。 |
| Spatially Constrained Generative Adversarial Networks for Conditional Image Generation Authors Songyao Jiang, Hongfu Liu, Yue Wu, Yun Fu 图像生成在学术和工业领域引起了极*的关注,特别是对于有条件和面向目标的图像生成,例如犯罪肖像和时装设计。虽然目前的研究已经沿着这个方向取得了初步成果,但他们总是把重点放在类标签上,作为从潜在载体随机产生空间内容的条件。边缘细节通常是模糊的,因为难以保留空间信息。鉴于此,我们提出了一种新颖的空间约束生成对抗网络SCGAN,它将空间约束与潜在向量分离,并使这些约束成为可选的附加可控信号。为了增强空间可控性,生成器网络被专门设计为逐步采用语义分段,潜在向量和属性级别标签作为输入。此外,构造分段网络以对发生器施加空间约束。在实验上,我们在CelebA和DeepFashion数据集上提供视觉和定量结果,并证明所提出的SCGAN在控制空间内容以及生成高质量图像方面非常有效。 |
| Automatic 4D Facial Expression Recognition via Collaborative Cross-domain Dynamic Image Network Authors Muzammil Behzad, Nhat Vo, Xiaobai Li, Guoying Zhao 本文提出了一种新的4D面部表情识别FER方法,该方法采用协同交叉域动态图像网络CCDN。给定面部扫描的4D数据,我们首先计算其几何图像,然后在提出的跨域图像表示中组合它们的相关信息。然后,所获取的集合用于通过等级池生成跨域动态图像CDI,该等级池化根据单个图像封装面部变形随时间的变化。对于训练阶段,这些CDI被馈入端到端深度学习模型,并且结果预测在多个视图上协作以获得表达分类中的性能增益。此外,我们提出了一种4D增强方案,不仅扩展了训练数据量表,还引入了重要的面部肌肉运动模式,以提高FER性能。在广泛采用的设置下对常用BU 4DFE数据集进行*量实验的结果表明,我们提出的方法优于现有技术的4D FER方法,达到96.5的准确度,表明其有效性。 |
| Frame-wise Motion and Appearance for Real-time Multiple Object Tracking Authors Jimuyang Zhang, Sanping Zhou, Jinjun Wang, Dong Huang 多目标跟踪MOT的主要挑战是在视频帧之间关联不定数量的对象的效率。用于跟踪的标准运动估计器(例如,长短期存储器LSTM)仅处理单个对象,而基于Re IDentification Re ID的方法穷举地比较对象外观。当它们被缩放到*量对象时,这两种方法在计算上都是昂贵的,这使得实时MOT非常困难。为了解决这些问题,我们提出了一种高效的深度神经网络DNN,它可以同时模拟不确定数量的对象之间的关联。 DNN的推理计算不会随着对象的数量而增加。我们的方法,帧式运动和外观FMA,计算两帧之间的帧式运动场FMF,这导致在*量对象边界框之间的非常快速和可靠的匹配。由于辅助信息用于修复不确定匹配,因此与FMF并行地学习帧明显外观特征FAF。对MOT17基准测试的广泛实验表明,我们的方法实现了具有竞争力结果的实时MOT,这是最先进的技术。 |
| Simultaneous Object Detection and Semantic Segmentation Authors Niels Ole Salscheider 相机图像中的物体检测和语义分割都是自动车辆的重要任务。对象检测是必要的,以便规划和行为模块可以推断其他道路使用者。语义分段提供例如自由空间信息和关于环境的静态和动态部分的信息。使用卷积神经网络解决这两项任务已经有很多研究。这些方法给出了良好的结果,但计算要求很高。实际上,必须在检测性能,检测质量和任务数量之间找到折衷方案。否则,不可能满足自动车辆的实时要求。在这项工作中,我们提出了一种神经网络架构来同时解决这两个任务。该架构设计为在当前硬件上以1 MP图像运行*约10 Hz。我们的方法在具有挑战性的Cityscapes基准测试中实现了语义分段任务的平均IoU为61.2。它还实现了汽车的平均精度为69.3,而KITTI基准的中等难度等级为67.7。 |
| Source Generator Attribution via Inversion Authors Michael Albright, Scott McCloskey 随着生成对抗网络GAN的发展,导致合成图像和视频的显着改进,对将传统取证扩展到这一新图像类别的算法的需求增加。尽管已经证明GAN在许多计算机视觉应用中是有用的,但是还存在其他有问题的用途,例如需要这种取证的深假货。使用各种提示的源相机属性算法已经满足了对相机捕获的图像的需求,但合成图像的选项较少。我们通过反转生成过程来解决将合成图像归因于白盒设置中的特定生成器的问题。这使我们能够同时确定发生器是否产生图像并恢复产生与合成图像紧密匹配的输入。 |
| Searching for MobileNetV3 Authors Andrew Howard, Mark Sandler, Grace Chu, Liang Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, Hartwig Adam 我们基于互补搜索技术的组合以及新颖的架构设计呈现下一代MobileNets。 MobileNetV3通过结合使用硬件感知网络架构搜索NAS和NetAdapt算法进行调整,然后通过新颖的架构改进进行改进,从而调整到移动电话CPU。本文开始探索自动搜索算法和网络设计如何协同工作,以利用互补的方法来改善整体的现状。通过这个过程,我们创建了两个新的MobileNet模型,用于发布MobileNetV3 Large和MobileNetV3 Small,它们针对高资源和低资源使用情况。然后,这些模型被适应并应用于对象检测和语义分割的任务。对于语义分割或任何密集像素预测的任务,我们提出了一种新的有效分割解码器Lite Reduced Atrous Spatial Pyramid Pooling LR ASPP。我们实现了移动分类,检测和分割的最新技术成果。与MobileNetV2相比,MobileNetV3 Large在ImageNet分类上的准确度为3.2,同时将延迟降低了15。与MobileNetV2相比,MobileNetV2 Small的准确度为4.6,同时将延迟降低了5。 MobileNetV3*检测速度提高了25倍,与COCO检测时的MobileNetV2*致相同。 MobileNetV3*型LR ASPP比MobileNetV2 R ASPP快30倍,城市景观细分的准确度相近。 |
| Image Matters: Detecting Offensive and Non-Compliant Content / Logo in Product Images Authors Shreyansh Gandhi, Samrat Kokkula, Abon Chaudhuri, Alessandro Magnani, Theban Stanley, Behzad Ahmadi, Venkatesh Kandaswamy, Omer Ovenc, Shie Mannor 在电子商务中,产品内容,尤其是产品图像对客户从产品发现到评估以及最终购买决策的过程具有重*影响。由于许多电子商务零售商除了他们自己之外还销售来自其他第三方市场卖家的商品,因此需要尽可能地监控和丰富内部和外部内容创建者发布的内容。尽管有指导和警告,但包含攻击性和不合规图像的产品列表仍会继续进入目录。攻击性和不符合要求的内容可以包括各种各样的对象,徽标和横幅,传达暴力,色情,种族主义或促销信息。此类图像可能严重损害客户体验,导致法律问题,并侵蚀公司品牌。 |
| A Geometric Approach to Obtain a Bird's Eye View from an Image Authors Ammar Abbas, Andrew Zisserman 本文的目的是通过计算单应矩阵来纠正任何单目图像,该单应矩阵将其转换为鸟瞰俯视图。 |
| Sparse data interpolation using the geodesic distance affinity space Authors Mikhail G. Mozerov, Fei Yang, Joost van de Weijer 在本文中,我们使基于测地距离的递归滤波器适应稀疏数据插值问题。所提出的技术是通用的,并且可以容易地应用于任何类型的稀疏数据。我们证明了在三个实验中用于定性和定量评估的优于其他插值技术。 |
| Transferring Multiscale Map Styles Using Generative Adversarial Networks Authors Yuhao Kang, Song Gao, Robert E. Roth 人工智能AI技术的进步使得从现有地图或其他视觉艺术中学习风格设计标准成为可能,并转移这些风格以制作新的数字地图。在本文中,我们提出了一种新的框架,使用AI进行地图样式转换,适用于多个地图尺度。具体来说,我们通过两个生成的对抗性网络GAN模型识别并将文本元素从包括谷歌地图,OpenStreetMap和艺术绘画在内的一组目标视觉元素转移到未经校正的GIS矢量数据。然后,我们基于深度卷积神经网络训练二元分类器,以评估传递样式的地图图像是否保留原始地图设计特征。我们的实验结果表明,GAN具有很*的多尺度地图样式转移潜力,但仍有许多挑战需要进一步研究。 |
| Mapping Missing Population in Rural India: A Deep Learning Approach with Satellite Imagery Authors Wenjie Hu, Jay Harshadbhai Patel, Zoe Alanah Robert, Paul Novosad, Samuel Asher, Zhongyi Tang, Marshall Burke, David Lobell, Stefano Ermon 全世界有数百万人缺席他们国家的人口普查。准确,最新和精细的人口指标对于改善政府资源配置,衡量疾病控制,应对自然灾害以及研究这些社区的人类生活方面至关重要。卫星图像可以提供足够的信息来建立人口地图,而无需政府人口普查的成本和时间。我们提出了两种卷积神经网络CNN架构,它可以有效地组合来自多个源的卫星图像输入,以准确地预测一个区域的人口密度。在本文中,我们使用来自印度农村的卫星图像和2011年SECC人口普查中的人口标签。我们的最佳模型实现了比以前的论文以及LandScan更好的性能,LandScan是全球人口分布的社区标准。 |
| Towards Evaluating and Understanding Robust Optimisation under Transfer Authors Todor Davchev, Timos Kores, Stathi Fotiadis, Nick Antonopoulos, Subramanian Ramamoorthy 这项工作评估了从CIFAR 100转移到CIFAR 10的对抗稳健性的有效性。这使我们能够识别成功保留对抗性防御的转移学习策略,此外还可以揭示潜在的漏洞。我们研究了快速梯度符号方法FGSM制作的特征及其迭代替代PGD在三种不同的转移学习策略下可以保护其抵御黑白盒攻击的防御属性的程度。我们发现在训练期间使用PGD示例会导致更一般的鲁棒性,更容易传递。此外,在成功转移的情况下,它对白盒PGD攻击的准确度比所考虑的基线高出5.2倍。在本文中,我们研究了在源网络和目标网络中使用稳健优化的效果。我们的实证评估揭示了这种机制如何在与非转移防御取得可比结果的同时进行推广。 |
| Learning Optimal Data Augmentation Policies via Bayesian Optimization for Image Classification Tasks Authors Chunxu Zhang, Jiaxu Cui, Bo Yang 近年来,深度学习在计算机视觉,自然语言处理,语音识别等多个领域取得了显着成绩。充足的培训数据是确保深层模型有效性的关键。但是,获取有效数据需要*量的时间和人力资源。数据增强DA是一种有效的替代方法,可以使用标签保留转换基于现有数据生成新的标记数据。尽管我们可以从DA中受益匪浅,但设计合适的DA策略需要*量的专家经验和时间消耗,并且搜索最优策略的评估成本很高。因此,我们在本文中提出了一个如何以尽可能低的成本实现自动数据增强的新问题。我们提出了一种名为BO Aug的方法,通过使用贝叶斯优化方法找到最优的DA策略来自动化该过程。我们的方法可以以相对较低的搜索成本找到最优策略,并且基于特定数据集的搜索策略可以跨不同的神经网络架构甚至不同的数据集传输。我们在三个广泛使用的图像分类数据集上验证了BO Aug,包括CIFAR 10,CIFAR 100和SVHN。实验结果表明,该方法可以达到现有技术水平或接近先进的分类精度。可以在以下位置获得重现我们实验的代码 |
| DLIMD: Dictionary Learning based Image-domain Material Decomposition for spectral CT Authors Weiwen Wu, Haijun Yu, Peijun Chen, Fulin Luo, Fenglin Liu, Qian Wang, Yining Zhu, Yanbo Zhang, Jian Feng, Hengyong Yu 光谱计算机断层扫描CT的潜在巨*优势是它能够提供准确的材料识别和定量组织信息。这可以使临床应用受益,例如脑血管造影,早期肿瘤识别等。为了获得具有更高材料图像质量的更准确的材料成分,我们开发了基于字典学习的图像域材料分解DLIMD用于光谱CT。首先,我们从投影重建光谱CT图像,并通过从图像重建结果中选择基础材料的均匀区域来计算材料系数矩阵。其次,我们采用直接反演DI方法获得初始材料分解结果,并从标准化材料图像张量的模式1展开中提取一组图像块,以通过K SVD技术训练联合字典。第三,通过构建DLIMD模型,使用训练的字典来探索来自分解的材料图像的相似性。第四,更多约束,即体积守恒和材料图内每个像素的边界进一步集成到模型中,以提高材料分解的准确性。最后,采用物理体模和临床前实验来评估所提出的DLIMD在材料分解精度,材料图像边缘保持和特征恢复方面的性能。 |
| Ocular Diseases Diagnosis in Fundus Images using a Deep Learning: Approaches, tools and Performance evaluation Authors Yaroub Elloumi LIGM , Mohamed Akil LIGM , Henda Boudegga 眼底图像的眼部病理检测对医疗保健提出了重要挑战。事实上,每种病理都有不同的严重程度,可以通过验证特定病变的存在来推断。每个病变的特征在于形态学特征。此外,不同病理的几种病变具有相似的特征。我们注意到患者可能同时受到多种病症的影响。因此,眼病理检测呈现具有复杂分辨率原理的多类分类。已经提出了几种来自眼底图像的眼病变的检测方法。基于深度学习的方法由于其相对于检测目标配置网络的能力而通过更高性能检测来区分。这项工作提出了一种基于深度学习的眼病理检测方法的调查。首先,我们研究现有的方法,用于病变分割或病理分类。然后,我们提取处理的主要步骤,并分析所提出的神经网络结构。随后,我们确定了采用深度学习架构所需的硬件和软件环境。此后,我们调查了评估方法所涉及的实验原则以及用于培训和测试阶段的数据库。还报告和讨论了检测性能比和执行时间。 |
| Generating Realistic Unrestricted Adversarial Inputs using Dual-Objective GAN Training Authors Isaac Dunn, Tom Melham, Daniel Kroening 众所周知,深度神经网络的正确性易受其输入的小的,对抗性扰动的影响。虽然研究这些攻击很有价值,但它们并不一定符合任何现实世界的威胁模型。这引起了人们对无限制对抗性输入的产生和稳健性的兴趣,这些对抗性输入并不构成对正确分类的地面实况输入的小扰动。我们引入了一种新算法来生成逼真的无限制对抗输入,因为它们无法通过人类可靠地与训练数据集区分开来。这是通过修改生成性对抗网络来实现的,生成器神经网络被训练以构建欺骗固定目标网络的示例,因此它们是对抗性的,同时也欺骗通常的共同训练鉴别器网络,因此它们是现实的。我们的方法通过为训练有素的图像分类器生成无限制的对抗输入来证明,该分类器对基于扰动的攻击是鲁棒的。我们发现人类法官无法确定我们的方法在*约50%的时间内生成了十分之一的图像,并提供了证据证明它们是中等现实的。 |
| Representation of White- and Black-Box Adversarial Examples in Deep Neural Networks and Humans: A Functional Magnetic Resonance Imaging Study Authors Chihye Han, Wonjun Yoon, Gihyun Kwon, Seungkyu Nam, Daeshik Kim 最近*脑的成功激发了深度神经网络DNN在解决复杂,高水平的视觉任务方面的成功,导致人们对它们与人类视觉系统相匹配的潜力的期望越来越高。然而,DNN表现出的特质表明它们的视觉表现和处理可能与人类视觉有很*不同。 DNN的一个限制是它们易受对抗性示例的影响,输入图像上添加了细微的,精心设计的噪声以欺骗机器分类器。人类视觉系统对抗对抗性示例的稳健性可能具有重要意义,因为它可以揭示机器视觉尚未融入的关键机制特征。在这项研究中,我们通过利用功能磁共振成像fMRI比较DNN和人类中白盒和黑盒对抗性实例的视觉表示。我们发现人类和DNN的不同即白色与黑盒类型的对抗性示例的表示模式之间存在微小但显着的差异。然而,与DNN不同,无论类型如何,人类对分类判断的表现都不会因噪声而降低。这些结果表明,对抗性的例子可能在人类视觉系统中有差异地表现,但不能影响感知体验。 |
| Are Graph Neural Networks Miscalibrated? Authors Leonardo Teixeira, Brian Jalaian, Bruno Ribeiro 图形神经网络GNN已经证明在许多分类任务中是成功的,在准确性方面优于先前的最新技术方法。然而,仅靠准确性对于高风险决策来说还不够。决策者想知道特定GNN预测是否正确的可能性。为此,获得校准模型至关重要。在这项工作中,我们分析了多个数据集上最先进的GNN的校准。我们的实验表明,GNN可以在某些数据集中进行校准,但在其他数据集中也会严重错误校准,并且最先进的校准方法很有帮助,但不能解决问题。 |
| Caveats in Generating Medical Imaging Labels from Radiology Reports Authors Tobi Olatunji, Li Yao, Ben Covington, Alexander Rhodes, Anthony Upton 在医学成像中获得高质量的注释通常是昂贵的过程。使用自然语言处理自动标签提取NLP已成为绕过专家注释需求的有前途的解决方案。尽管方便,但是没有仔细检查这种近似的限制并且不能很好地理解。通过一系列具有挑战性的1000次胸部X线研究及其相应的放射学报告,我们发现放射科医师在视觉上感知的与临床报告的内容之间存在着惊人的巨*差异。此外,由于具有固有缺陷的报告作为基本事实,最先进的医疗NLP无法产生高保真标签。 |
| MixMatch: A Holistic Approach to Semi-Supervised Learning Authors David Berthelot, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, Colin Raffel 事实证明,半监督学习是利用未标记数据来减轻对*型标记数据集的依赖的有力范例。在这项工作中,我们统一了当前用于半监督学习的主要方法来生成新算法MixMatch,该算法通过猜测数据增强的未标记示例的低熵标签并使用MixUp混合标记和未标记数据来工作。我们展示了MixMatch在许多数据集和标记数据量上获得了*量优势。例如,在具有250个标签的CIFAR 10上,我们将错误率从38降低到4,在STL 10上降低了2倍。我们还演示了MixMatch如何帮助实现显着更好的精度隐私折衷差异隐私。最后,我们进行了一项消融研究,以分析MixMatch的哪些成分对其成功最重要。 |
| Back to the Future: Predicting Traffic Shockwave Formation and Propagation Using a Convolutional Encoder-Decoder Network Authors Mohammadreza Khajeh Hosseini, Alireza Talebpour 本研究提出了一种深度学习方法来预测交通冲击波的传播。深度神经网络的输入是研究段的时间空间图,网络的输出是以时间空间图的形式预测冲击波在研究段上的未来传播。所提出的方法的主要特征是能够提取嵌入在时间空间图中的特征以预测交通冲击波的传播。 |
| Chinese Abs From Machine Translation |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}