
【今日CV 计算机视觉论文速览 第114期】Thu, 9 May 2019
今日CS.CV 计算机视觉论文速览
Thu, 9 May 2019
Totally 37 papers
👉上期速览✈更多精彩请移步主页

Interesting:
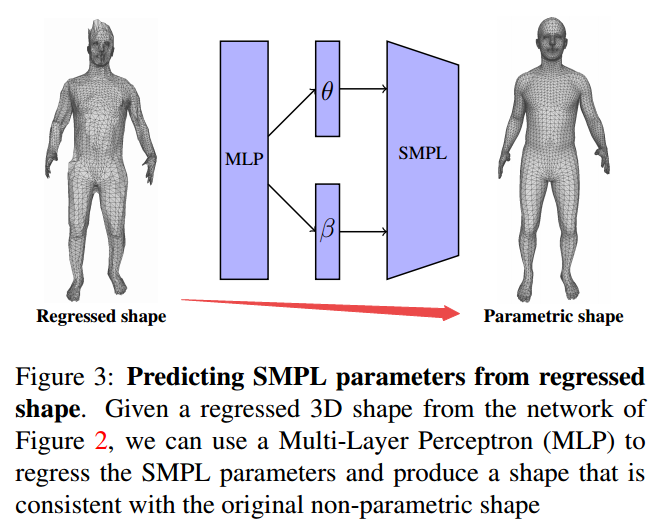
📚用于单图像人体形状重建的卷积网格回归方法,基于图卷积的方法直接回归出网格点的三维坐标。基于图像的特征被附着在mesh节点上,并利用GCNN处理成mesh结构,并回归到三维位置。(from 宾夕法尼亚大学)
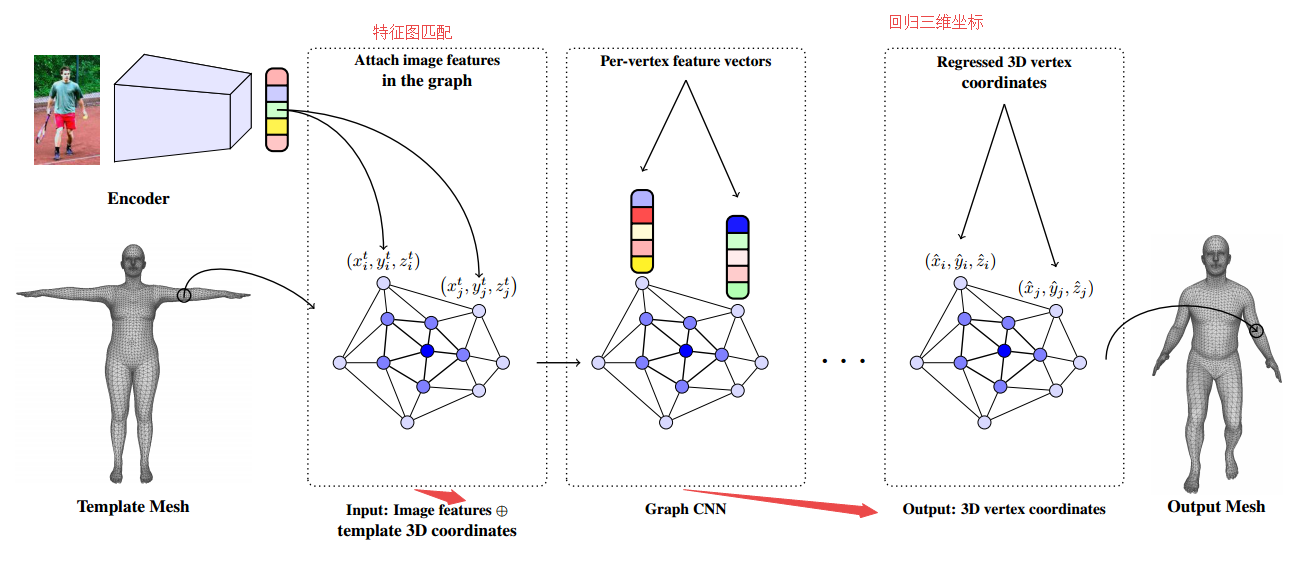
回归网格到参数化外形的预测和一些结果:

code: seas.upenn.edu/˜nkolot/projects/cmr
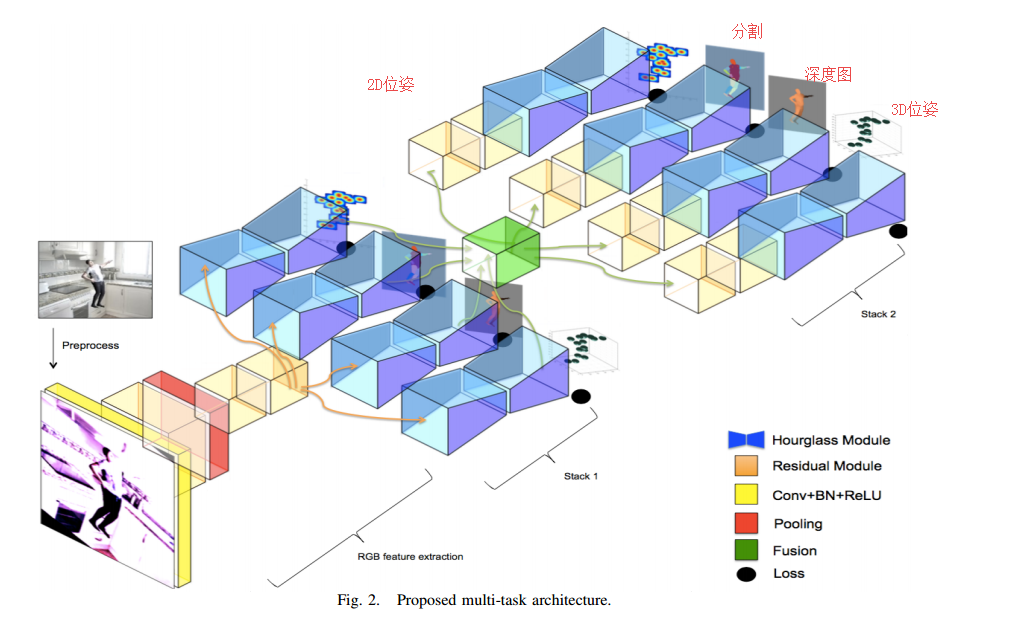
📚***基于静态图的多任务人体分析, 单图像实现2D/3D位姿、深度图和多部分分割任务的实现。基于可共享信息的堆叠沙漏模块来构建多任务模型,各个任务间将会相互提升和促进。研究发现2D位姿估计得到的提升最大,2D分割将会受益于2D位姿估计。(from Universitat Oberta de Catalunya spain)
文章提出的多任务架构:
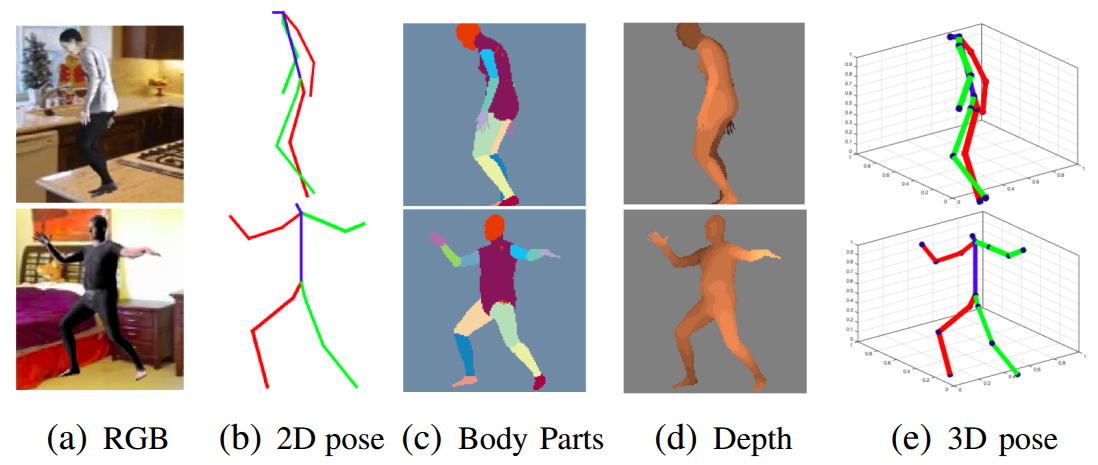
dataset:SURREAL DATASET [1]Learning from synthetic humans
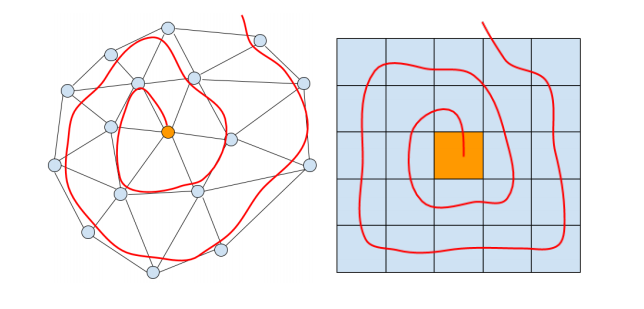
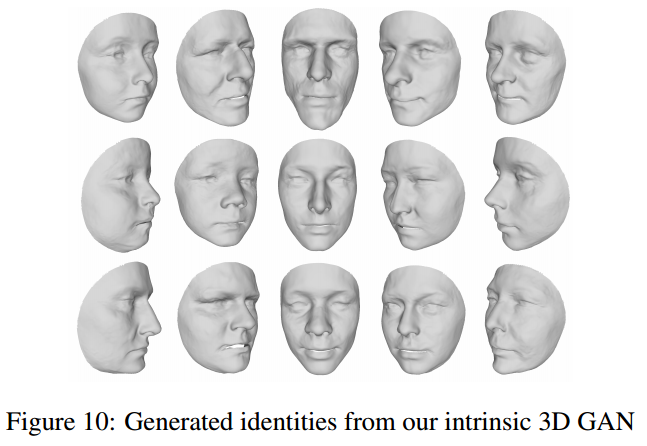
📚****Neural 3D Morphable Models, 利用螺旋卷积网络实现3D形状表示学习和生成。虽然可变形模型能对人脸这样的形状得到紧致的表示,简单有效但表达能力受到了线性方程的限制。研究人员提出了一种螺旋卷积操作来实现非线性操作,随后基于螺旋卷积构建GANs用于处理网格和几何结构。这种方法在三维形状表达上取得了良好的表现。(from 帝国理工)
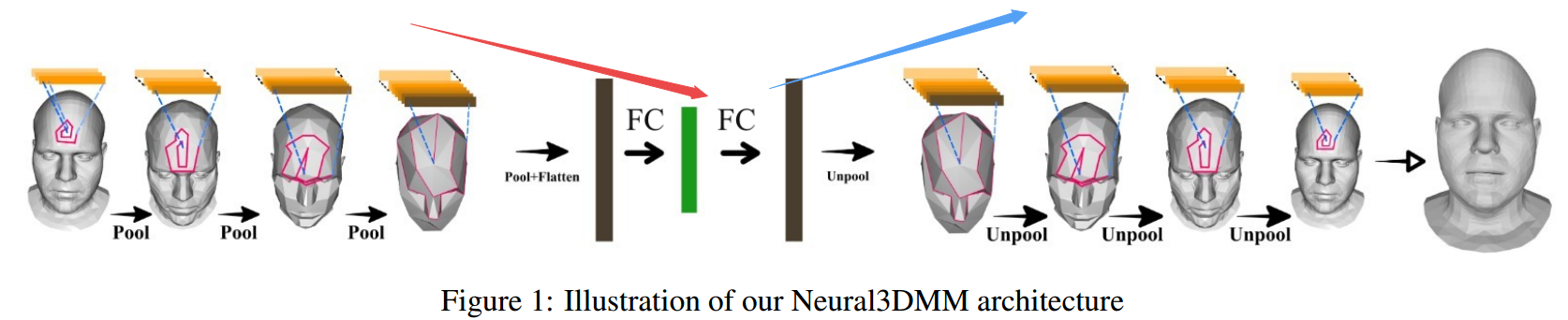
网格点和图像片上的螺旋卷积:
一些结果:
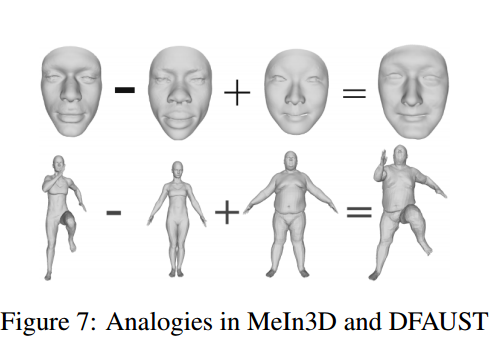
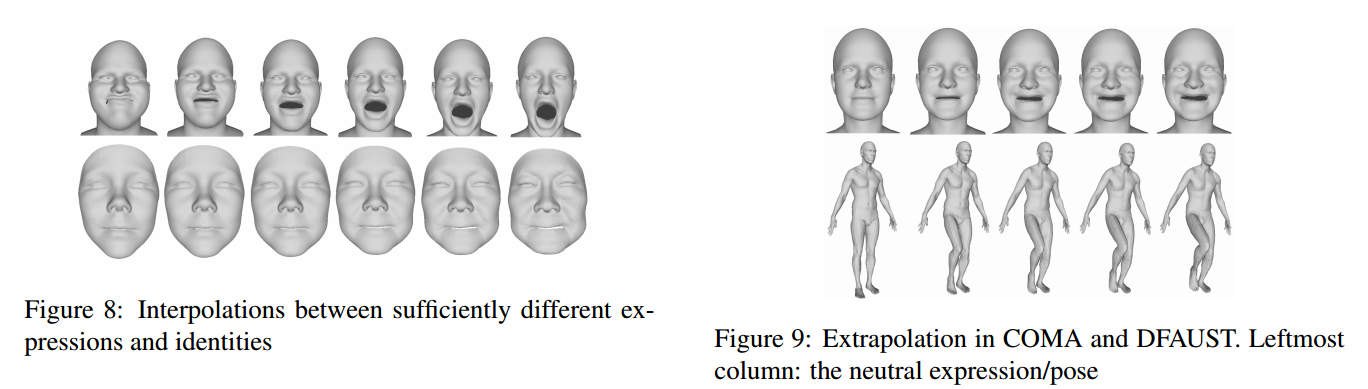
ref:linear Morphable Model, COMA model
PCA: 3D Morphable Model [3]
COMA: ChebNet-based Convolutional Mesh Autoencoder [35]. For the high resolutional meshes
of the MeIn3D dataset, we modified the architecture with an additional convolutional and downsampling/upsampling layer.
dataset:COMA DFAUST. MeIn3D.
📚**L-CNN 用于室内场景解析的三维线框模型, 与先前方法需要预测热力图作为中介并通过启发式算法抽取直线不同,这篇文章提出的方法直接使用了端到端的方法来直接输出矢量化的线框图,并包含了有几何和语义意义的显著性节点。同时还提出了新的度量惩罚重叠的线和不正确的连接,提高了输出线框图的精度。(from 伯克利)

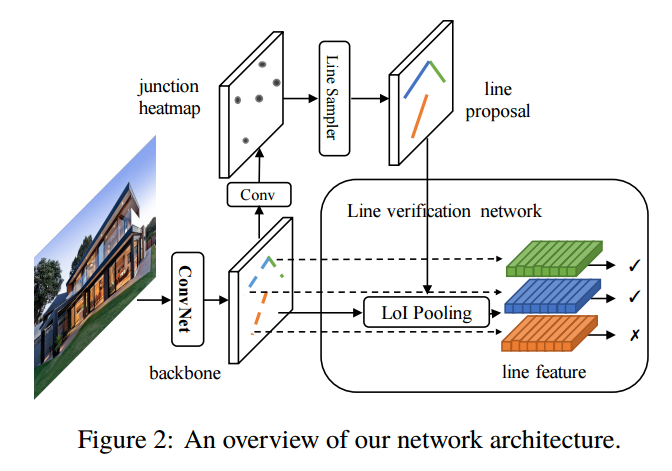
一些结果,可以看到线框预测十分准确:

dataset:[13] K. Huang, Y. Wang, Z. Zhou, T. Ding, S. Gao, and Y. Ma.Learning to parse wireframes in images of man-made environments.In CVPR, 2018
author:https://github.com/zhou13/lcnn
code:https://github.com/zhou13/lcnn
p.s:马毅老师的组:http://people.eecs.berkeley.edu/~yima/Students.html
📚模式识别中的特征选择与抽取综述, 回顾了不同特征选择和抽取方法背后的动机和通用方法,以及他们的应用,并介绍了一些相关的数值计算方法。(from 滑铁卢大学 ca)
(参考文献有用~~)
📚**ShapeGlot一种描述几何形状不同的语言模型,探索了自然语言在描述通常物体形状上的应用,训练了听和说的模型,从3D/2D几何形状中抽取抽象描述。 (from 斯坦福)
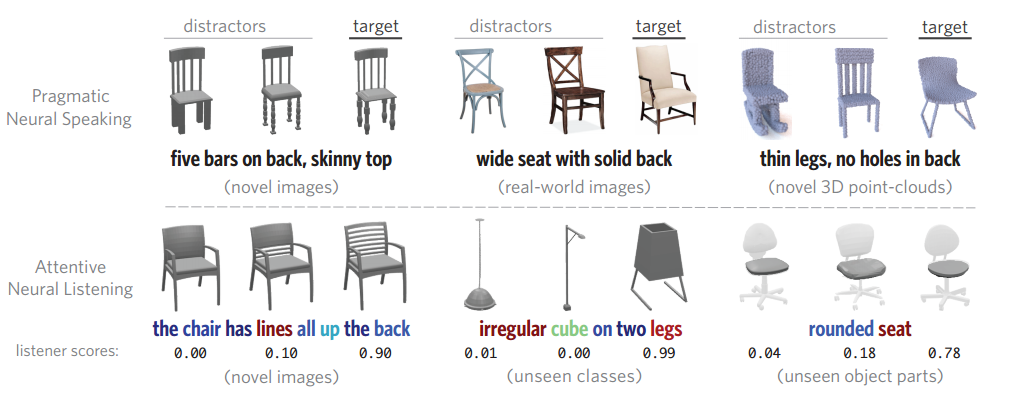
项目地址:https://www.bit.ly/shapeglot
http://videolectures.net/aaai2013_mooney_language_learning/
dataset:CiC (Chairs in Context)
📚*黑白视频彩色化, 基于三维卷积将明度L通道序列输出来生成色度ab通道图像。损失包含了生成彩色化的可信度和与色度GT的误差。(from University of Ioannina, Greece)
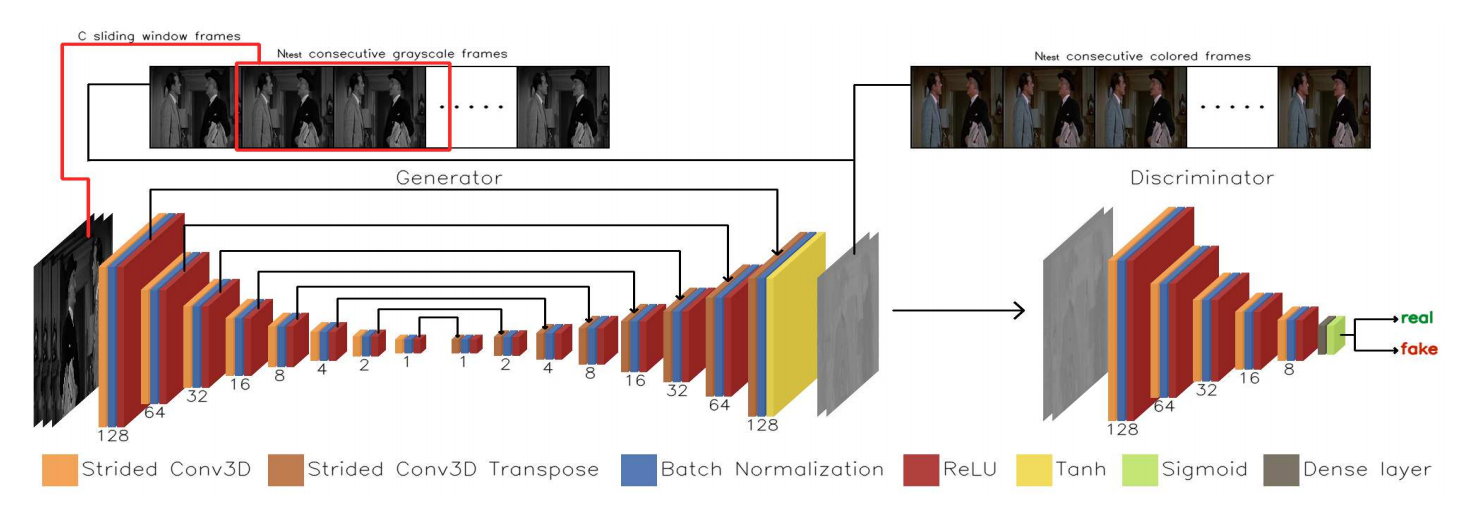
项目地址:http://www.cs.uoi.gr/~sfikas/video_colorization
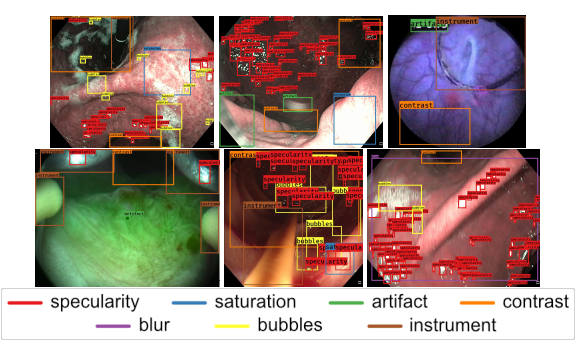
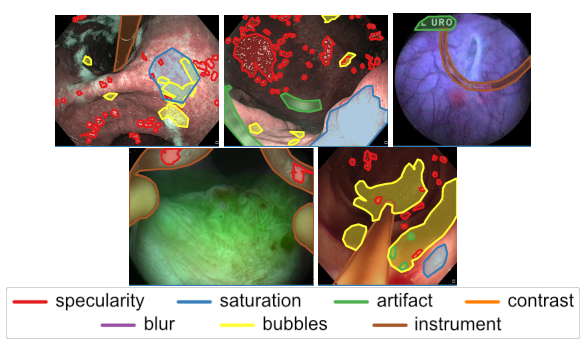
📚内窥镜数据集Endoscopy artifact detection (EAD 2019), (from 牛津)
分割和检测数据样本:
dataset:https://ead2019.grand-challenge.org/
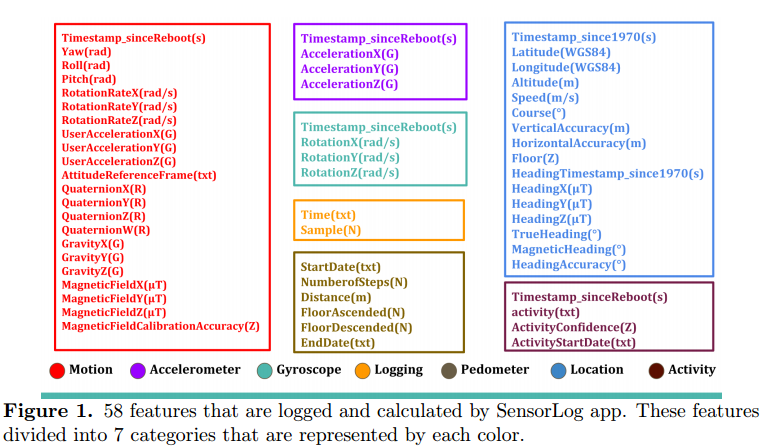
📚人体步态数据集,基于智能手机加速度计手机。 (from University of Massachusetts Boston)
手机收集的步态数据和步态模型:
数据集:
https://drive.google.com/file/d/1XdPRA6LsfsSA2zXzdw7u_EkhVx96erw9/view
https://drive.google.com/file/d/1XdPRA6LsfsSA2zXzdw7u_EkhVx96erw9/view
Daily Computer Vision Papers
| End-to-End Wireframe Parsing Authors Yichao Zhou, Haozhi Qi, Yi Ma 我们提出了一种概念上简单而有效的算法来检测给定图像中的线框。与先前预测中间热图然后用启发式算法提取直线的方法相比,我们的方法是端到端可训练的,并且可以直接输出包含语义上有意义且几何上显着的连接点和线的矢量化线框。为了更好地理解输出的质量,我们提出了一种新的线框评估指标,它可以惩罚重叠的线段和不正确的线路连接。我们进行了大量实验,并表明我们的方法明显优于先前的线框和线提取算法。我们希望我们的简单方法可以作为未来线框解析研究的基准。代码已公开发布于 |
| Convolutional Mesh Regression for Single-Image Human Shape Reconstruction Authors Nikos Kolotouros, Georgios Pavlakos, Kostas Daniilidis 本文从单个图像中解决了3D人体姿态和形状估计的问题。以前的方法考虑人体的参数模型,SMPL,并尝试回归模型参数,从而产生与图像证据一致的网格。该参数回归是一项非常具有挑战性的任务,基于模型的方法在姿态估计方面与非参数解决方案相比表现不佳。在我们的工作中,我们建议放松对模型参数空间的严重依赖。我们仍保留SMPL模板网格的拓扑结构,但不是预测模型参数,而是直接回归网格顶点的3D位置。对于典型的网络来说,这是一项繁重的任务,但我们的主要观点是使用Graph CNN可以显着简化回归。这种架构允许我们在网络中明确编码模板网格结构,并利用网格提供的空间局部性。基于图像的特征附加到网格顶点,图形CNN负责在网格结构上处理它们,而每个顶点的回归目标是其3D位置。恢复了网格的完整3D几何体后,如果我们仍然需要特定的模型参数化,则可以从顶点位置可靠地回归。我们通过在网格顶点上附加不同类型的特征来证明我们提出的基于图形的网格回归的灵活性和有效性。在所有情况下,我们都依赖于模型参数回归的可比基线,同时我们也在基于模型的姿态估计方法中实现了最先进的结果。 |
| Endoscopy artifact detection (EAD 2019) challenge dataset Authors Sharib Ali, Felix Zhou, Christian Daul, Barbara Braden, Adam Bailey, Stefano Realdon, James East, Georges Wagni res, Victor Loschenov, Enrico Grisan, Walter Blondel, Jens Rittscher 内窥镜伪影是促进中空器官疾病的诊断和治疗的核心挑战。精确检测像素饱和度,运动模糊,镜面反射,气泡和碎片等特定伪像对于高质量的帧恢复至关重要,对于实现可靠的计算机辅助工具以改善患者护理至关重要。目前,由于视频帧中存在大量多类伪像,因此目前尚未分析内窥镜检查中的大多数视频。通过内窥镜伪影检测EAD 2019挑战,我们通过解决内窥镜帧伪影的准确识别和定位来解决这一关键瓶颈问题,从而能够对不可用的视频帧进行进一步的关键定量分析,例如镶嵌和3D重建,这对于提供改善的患者护理至关重要。本文总结了挑战任务,并描述了在EAD 2019挑战中建立的数据集和评估标准。 |
| Unsupervised Domain Adaptation using Generative Adversarial Networks for Semantic Segmentation of Aerial Images Authors Bilel Benjdira, Yakoub Bazi, Anis Koubaa, Kais Ouni 划分航拍图像在城市地区的监视和场景理解方面具有巨大潜力。它为自动报告在居住区域发生的不同事件提供了一种方法。这极大地促进了公共安全和交通管理应用。在广泛采用卷积神经网络方法之后,如果提供健壮的数据集,语义分割算法的准确性可以轻松超过80。尽管取得了这样的成功,但是部署训练有素的分割模型来调查未包含在训练集中的新城市会显着降低准确性。这是由于训练模型的源数据集与新城市图像的新目标域之间的域移位。在本文中,我们解决了这个问题,并考虑了域适应在航空图像语义分割中的挑战。我们设计了一种算法,使用生成对抗网络GAN减少域移位影响。在实验中,我们测试了国际摄影测量和遥感学会ISPRS语义分割数据集的方法,并发现我们的方法从被认为是源域的波茨坦域到被视为目标的Vaihingen域时,总体准确度从35提高到52。域名。另外,该方法允许由于传感器变化而有效地恢复反转类别。特别是,由于传感器从14变化到61,它提高了反转类别的平均分割精度。 |
| Thinking Outside the Box: Generation of Unconstrained 3D Room Layouts Authors Henry Howard Jenkins, Shuda Li, Victor Prisacariu 我们提出了一种房间布局估计方法,该方法不依赖于典型的盒子近似或曼哈顿世界假设。相反,我们将几何推理问题重新设计为实例检测任务,我们通过使用R CNN直接回归3D平面来解决这个问题。然后,我们使用概率聚类的变体将在视频序列中的每个帧处回归的3D平面与它们各自的相机姿势组合成单个全局3D房间布局估计。最后,我们展示了对垂直对齐没有任何假设的结果,因此可以有效地处理任何对齐的墙壁。 |
| Capture, Learning, and Synthesis of 3D Speaking Styles Authors Daniel Cudeiro, Timo Bolkart, Cassidy Laidlaw, Anurag Ranjan, Michael J. Black 音频驱动的3D面部动画已被广泛探索,但实现逼真的,类似人类的表现仍未得到解决。这是由于缺乏可用的3D数据集,模型和标准评估指标。为了解决这个问题,我们推出了一个独特的4D人脸数据集,其中包括以60 fps捕获的约29分钟4D扫描和12个扬声器的同步音频。然后,我们在我们的数据集上训练神经网络,该网络从面部运动中识别身份。学习型模型,VOCA语音操作角色动画将任何语音信号作为输入甚至是除英语之外的语言的语音,并且逼真地动画化各种各样的成人面部。在训练期间对主题标签进行调节允许模型学习各种逼真的说话风格。 VOCA还提供动画控件以改变演讲风格,依赖身份的面部形状,以及在动画期间的姿势,即头部,下颌和眼球旋转。据我们所知,VOCA是唯一逼真的3D面部动画模型,它可以很容易地应用于看不见的对象而无需重新定位。这使得VOCA适用于诸如游戏视频,虚拟现实化身之类的任务,或者预先不知道说话者,语音或语言的任何场景。我们将数据集和模型用于研究目的 |
| Training a Fast Object Detector for LiDAR Range Images Using Labeled Data from Sensors with Higher Resolution Authors Manuel Herzog, Klaus Dietmayer 本文提出了一种从自动驾驶汽车中的LiDAR传感器进行物体检测的有效模型,以及使用来自不同类型的LiDAR传感器的数据训练模型的策略。目前,用于LiDAR测量的物体检测的最高性能算法基于神经网络。使用监督学习训练这些网络需要大量带注释的数据集。这导致了这样的情况:大多数使用神经网络从LiDAR点云进行物体检测的研究是在极少数公开可用的数据集和极少数的传感器类型上完成的。本文使用现有的带注释数据集来训练可与LiDAR传感器一起使用的神经网络,该传感器的分辨率低于用于记录注释数据集的分辨率。这是通过基于较高分辨率数据集模拟来自较低分辨率LiDAR传感器的数据来完成的。此外,还介绍了使用LiDAR系列图像进行物体检测的模型的改进。结果在模拟传感器数据和来自安装到研究车辆的实际较低分辨率传感器的数据上得到验证。结果表明,该模型可以实时预测360度范围图像中的物体。 |
| Automatic Video Colorization using 3D Conditional Generative Adversarial Networks Authors Panagiotis Kouzouglidis, Giorgos Sfikas, Christophoros Nikou 在这项工作中,我们提出了一种自动着色灰度视频的方法。该方法的核心是生成对抗网络,其以滑动窗口方式在帧序列上训练和测试。网络卷积和反卷积层是三维的,框架高度,宽度和时间作为考虑的尺寸。每帧的多个色度估计被聚合并与可用的亮度信息组合以重建彩色序列。在旧的黑白电影的数据集上成功运行着色试验。我们的方法的有用性也通过数值结果进行验证,数值结果使用新提出的度量来计算,该度量法测量帧序列上的着色一致性。 |
| A Genetic Algorithm Enabled Similarity-Based Attack on Cancellable Biometrics Authors Xingbo Dong, Zhe Jin, Andrew Teoh Beng Jin 可取消的生物特征识别CB作为生物特征模板保护方法的手段是指对原始模板的不可逆但相似的保留变换。利用相似性保留属性,可以在变换域中执行模板和查询实例之间的匹配,而不会危及准确性性能。不幸的是,这种特性引发了一类攻击,即基于相似性的攻击SA。 SA生成一个preimage,一个转换模板的逆,可用于模拟和交叉匹配。在本文中,我们提出了一种基于遗传算法的基于相似性的攻击框架GASAF,以证明具有相似性保持特性的CB方案极易受到基于相似性的攻击。除此之外,还设计了一组新指标来衡量基于相似性的攻击的有效性。我们在两个代表性的CB方案上进行实验,即BioHashing和Bloom过滤器。实验结果证明了这种攻击下的脆弱性。 |
| Algorithms for Grey-Weighted Distance Computations Authors Magnus Gedda 随着数据集的大小增加以及对交互式应用程序的实时响应的需求,改进具有过多计算要求的算法的运行时变得越来越重要。已经提出了许多将有效优先级队列与各种辅助结构相结合的不同算法来计算灰度加权距离变换。在这里,我们比较了不同场景中流行竞争算法的性能,以形成易于采用的实用指南。算法的标签设置类别显示为所有方案的最佳选择。具有用于跟踪堆上节点的指针数组的分层堆被显示为优先级队列的最佳选择。但是,如果内存是一个关键问题,那么最好的选择是整数值成本的拨号优先级队列和实值成本的不整齐优先级队列。 |
| Multi-task human analysis in still images: 2D/3D pose, depth map, and multi-part segmentation Authors Daniel S nchez, Marc Oliu, Meysam Madadi, Xavier Bar , Sergio Escalera 虽然人类分析领域的许多个人任务最近都得到了深度学习方法的准确性提升,但由于缺乏数据,多任务学习大多被忽略。正在发布新的合成数据集,用合成生成的数据填补这一空白。在这项工作中,我们通过利用这些数据集分析多任务场景中静止图像中的四个相关人体分析任务。具体来说,我们研究了2D 3D姿态估计,身体部位分割和全身深度估计的相关性。通过众所周知的Stacked Hourglass模块学习这些任务,使得每个任务特定流与其他流共享信息。主要目标是分析如何将这四个相关任务一起训练可以使每个单独的任务受益,以实现更好的概括。新发布的SURREAL数据集的结果显示,所有四个任务都受益于多任务方法,但是使用不同的任务组合,同时组合所有四个任务可以最大程度地改进2D姿势估计,2D姿势既不会改善3D姿势也不会改善全身深度估计。另一方面,2D零件分割可以受益于2D姿势,但不受益于3D姿势。在所有情况下,如所预期的那样,在那些在空间分布,外观和形状方面表现出更多可变性的人体部分上实现了最大的改进。手腕和脚踝。 |
| Multimodal Semantic Attention Network for Video Captioning Authors Liang Sun, Bing Li, Chunfeng Yuan, Zhengjun Zha, Weiming Hu 受视频中不同模态携带补充信息这一事实的启发,我们提出了一种多模态语义注意网络MSAN,它是一种新的编码器解码器框架,其中包含用于视频字幕的多模态语义属性。在编码阶段,我们通过将其设计为多标签分类问题来检测和生成多模态语义属性。此外,我们在模型中添加了辅助分类损失,可以获得更有效的视觉特征和高水平的多模态语义属性分布,从而实现足够的视频编码。在解码阶段,我们将传统LSTM的每个权重矩阵扩展到属性依赖权重矩阵的集合,并且在字幕处理的每个时间使用注意机制来关注不同的属性。我们在两个流行的公共基准MSVD和MSR VTT上评估算法,在六个评估指标中以当前最先进的水平获得竞争结果。 |
| Deep Blind Video Decaptioning by Temporal Aggregation and Recurrence Authors Dahun Kim, Sanghyun Woo, Joon Young Lee, In So Kweon 盲视频去除是一个自动删除文本覆盖并在没有任何输入掩码的情况下修复视频中被遮挡部分的问题。虽然最近基于深度学习的修复方法处理单个图像并且大多数假设已知损坏像素的位置,但我们的目标是在没有掩模信息的视频序列中自动删除文本。在本文中,我们提出了一个简单而有效的快速盲视频截断框架。我们构造了一个编码器解码器模型,其中编码器采用多个源帧,可以提供从场景动态显示的可见像素。这些提示被聚合并馈送到解码器中。我们将输入帧的残余连接应用于解码器输出,以强制我们的网络仅关注损坏的区域。我们提出的模型在ECCV Chalearn 2018 LAP Inpainting Competition Track2视频断开中排名第一。此外,我们通过应用反复反馈进一步改进这一强大的模型。循环反馈不仅可以强制实现时间一致性,还可以提供有关损坏像素位置的强有力线索。定性和定量实验都表明,我们的完整模型可以实时产生50 fps的精确和时间一致的视频结果。 |
| Photometric Transformer Networks and Label Adjustment for Breast Density Prediction Authors Jaehwan Lee, Donggeon Yoo, Jung Yin Huh, Hyo Eun Kim 分级乳房密度对数字乳房X线照片的标准化设置高度敏感,因为密度与像素强度的分布紧密相关。此外,由于评分标准不确定,评分因读者而异。这些问题是数字乳腺摄影密度评估中固有的。当设计用于乳房密度的计算机辅助预测模型时它们是有问题的,并且如果数据来自多个站点则变得更糟。在本文中,我们提出了两种新的用于乳房密度预测的深度学习技术1光度变换,其自适应地标准化输入乳房X线照片,以及2标签蒸馏,其通过使用其输出预测来调整标签。光度变换器网络预测了与主要预测网络联合学习的动态光度变换的最佳参数。标签蒸馏是一种伪标签技术,旨在减轻分级变化。我们通过实验证明,所提出的方法在乳房密度预测方面是有益的,与以前的各种方法相比,导致显着的性能改善。 |
| Deep Flow-Guided Video Inpainting Authors Rui Xu, Xiaoxiao Li, Bolei Zhou, Chen Change Loy 由于难以保持视频内容的精确空间和时间相干性,旨在填充视频的缺失区域的视频修补仍然具有挑战性。在这项工作中,我们提出了一种新颖的流导视频修复方法。我们不是直接填充每个帧的RGB像素,而是将视频修复视为像素传播问题。我们首先使用新设计的Deep Flow Completion网络在视频帧上合成空间和时间上相干的光流场。然后,合成的流场用于引导像素的传播以填充视频中的缺失区域。具体而言,深流完井网络遵循粗略到精细的细化来完成流场,同时通过硬流示例挖掘进一步改善其质量。在完成流程的指导之后,可以精确地填充缺失的视频区域。我们的方法在DAVIS和YouTube VOS数据集上进行了定性和定量评估,在质量和速度方面达到了最先进的性能。 |
| Frame-Recurrent Video Inpainting by Robust Optical Flow Inference Authors Yifan Ding, Chuan Wang, Haibin Huang, Jiaming Liu, Jue Wang, Liqiang Wang 在本文中,我们提出了一个新的修复框架,用于恢复视频帧的缺失区域。与图像修复相比,在视频上执行此任务会带来新的挑战,例如如何保持时间一致性和空间细节,以及如何快速有效地处理任意输入视频大小和长度。为此,我们提出了一种新颖的深度学习架构,它结合了ConvLSTM和光流,用于对视频中的空间时间一致性进行建模。它还节省了大量的计算资源,使得我们的方法可以实时处理具有较大帧大小和任意长度的视频。此外,为了从损坏的帧产生精确的光流,我们提出了一个强大的流量生成模块,其中馈送两个流源并且训练流混合网络以融合它们。我们进行了大量实验,以定性和定量的方式评估我们在各种情景和不同数据集中的方法。实验结果表明,与现有技术的修复方法相比,我们的方法更优越。 |
| Neural 3D Morphable Models: Spiral Convolutional Networks for 3D Shape Representation Learning and Generation Authors Giorgos Bouritsas, Sergiy Bokhnyak, Michael Bronstein, Stefanos Zafeiriou 3D几何数据的生成模型出现在3D计算机视觉和图形的许多重要应用中。在本文中,我们关注具有共同拓扑结构的3D可变形状,例如人脸和人体。 Morphable Models是首次尝试为这种形状创建紧凑表示尽管它们有效且简单,但由于它们的线性公式,这些模型具有有限的表示能力。最近,已经提出了非线性可学习方法,尽管它们中的大多数采用中间表示,例如体素的3D网格或2D视图。在本文中,我们引入了卷积网格自动编码器和基于螺旋卷积算子的GAN架构,直接作用于网格并利用其基础几何结构。我们提供了对卷积算子的分析,并与线性可变模型和最近提出的COMA模型相比,展示了3D形状数据集的最新结果。 |
| Learning Cascaded Siamese Networks for High Performance Visual Tracking Authors Peng Gao, Yipeng Ma, Ruyue Yuan, Liyi Xiao, Fei Wang 视觉跟踪是最具挑战性的计算机视觉问题之一。为了在各种负面情景中实现高性能视觉跟踪,基于两个不同的深度学习网络,匹配子网和分类子网,提出并开发了一种新颖的级联连体网络。匹配的子网是一个完全卷积的Siamese网络。根据样本图像和候选图像之间的相似性得分,其目的在于搜索可能的对象位置和裁剪缩放的候选块。分类子网旨在进一步评估裁剪的候选补丁,并根据分类得分确定最佳跟踪结果。匹配的子网络离线训练并在线固定,而分类子网络在线执行随机梯度下降以了解更多目标特定信息。为了进一步提高跟踪性能,利用基于相似度和分类得分的有效分类子网更新方法来更新分类子网。大量实验结果表明,我们提出的方法在最近的基准测试中实现了最先进的性能。 |
| Goal-oriented Object Importance Estimation in On-road Driving Videos Authors Mingfei Gao, Ashish Tawari, Sujitha Martin 我们在道路驾驶视频中制定了作为对象重要性估计OIE的新问题,如果道路使用者对自我车辆驾驶员的控制决策有影响,则将其视为重要对象。道路使用者的重要性取决于其视觉动态,例如驾驶场景中的外观,运动和位置,以及例如自我车辆的计划路径的驾驶目标。我们提出了一个新的框架,结合了视觉模型和目标表示来进行OIE。为了评估我们的框架,我们在现实世界的交通路口收集道路驾驶数据集,并对重要物体进行人工标记的注释。实验结果表明,我们的目标导向方法优于基线,左转和右转方案有更多改进。此外,我们探索了使用对象重要性来驱动控制预测的可能性,并证明了可以利用对象重要性的信息来改进二元制动预测。 |
| FANTrack: 3D Multi-Object Tracking with Feature Association Network Authors Erkan Baser, Venkateshwaran Balasubramanian, Prarthana Bhattacharyya, Krzysztof Czarnecki 我们提出了一种在线多目标跟踪MOT的数据驱动方法,该方法使用卷积神经网络CNN在检测框架的跟踪中进行数据关联。多目标跟踪的问题旨在将噪声检测分配给跨越帧序列的先验未知和随时间变化数量的跟踪对象。大多数现有解决方案都侧重于繁琐地设计成本函数或将数据关联任务制定为可以有效解决的复杂优化问题。相反,我们利用深度学习的力量将数据关联问题表述为CNN中的推理。为此,我们建议学习一种相似性函数,该函数结合了来自对象的图像和空间特征的线索。我们的解决方案学会完全从数据中执行3D全局分配,处理嘈杂的检测和不同数量的目标,并且易于训练。我们在具有挑战性的KITTI数据集上评估我们的方法并显示出有竞争力的结果我们的代码可在 |
| LightTrack: A Generic Framework for Online Top-Down Human Pose Tracking Authors Guanghan Ning, Heng Huang 在本文中,我们提出了一种新的有效轻量级框架,称为LightTrack,用于在线人体姿势跟踪。建议的框架被设计为自上而下的姿势跟踪通用,并且比现有的在线和离线方法更快。单人姿势跟踪SPT和视觉对象跟踪VOT被合并到一个统一的功能实体中,可由可替换的单人姿势估计模块轻松实现。我们的框架将单人姿势跟踪与多人身份关联统一起来,并首先阐明了利用对象跟踪桥接关键点跟踪。我们还提出了一种用于人体姿势匹配的Siamese Graph Convolution Network SGCN作为我们的姿势跟踪系统中的Re ID模块。与其他Re ID模块相反,我们使用人体关节的图形表示进行匹配。基于骨架的表示有效地捕获人类姿势相似性并且在计算上是便宜的。突然的相机移位很强大,引入了人类漂移。据我们所知,这是第一篇以自上而下的方式提出在线人体姿势跟踪框架的论文。所提出的框架足够通用以适合其他姿势估计器和候选匹配机制。我们的方法优于其他在线方法,同时保持更高的帧速率,并且与我们的离线技术水平相比具有很强的竞争力。我们公开提供代码 |
| Skin Lesion Classification Using CNNs with Patch-Based Attention and Diagnosis-Guided Loss Weighting Authors Nils Gessert, Thilo Sentker, Frederic Madesta, R diger Schmitz, Helge Kniep, Ivo Baltruschat, Ren Werner 目的这项工作解决了皮肤病变分类的两个关键问题。第一个问题是有效地使用具有预训练标准体系结构的高分辨率图像用于图像分类。第二个问题是现实世界多类数据集中遇到的高级不平衡。方法为了使用高分辨率图像,我们提出了一种新的基于补丁的注意力架构,它提供小型高分辨率补丁之间的全局上下文我们修改了三个预训练架构并研究了基于补丁的注意力的表现。为了解决类不平衡问题,我们比较过采样,平衡批量采样和类特定损失加权。此外,我们提出了一种新颖的诊断引导损失加权方法,该方法将地面实况注释的方法考虑在内。结果我们基于补丁的注意机制优于以前的方法,平均灵敏度提高7。类平衡显着提高了平均灵敏度,我们证明我们的诊断引导损失加权方法比正常损失平衡提高了平均灵敏度3。结论基于补丁的新型注意机制可以集成到预训练架构中,并提供本地补丁之间的全局上下文,同时优于其他基于补丁的方法。因此,预训练的体系结构可以容易地与高分辨率图像一起使用而无需下采样。新的诊断引导损失加权方法优于其他方法,并允许在面对类不平衡时进行有效的训练。意义所提出的方法改善了自动皮肤病变分类。它们可以扩展到其他临床应用,其中高分辨率图像数据和类不平衡是相关的。 |
| Robust Dense Mapping for Large-Scale Dynamic Environments Authors Ioan Andrei B rsan, Peidong Liu, Marc Pollefeys, Andreas Geiger 我们提出了一种基于立体的密集映射算法,用于大规模动态城市环境与其他现有方法相比,我们同时分别重建静态背景,移动物体和可能移动但当前静止的物体,这对于高级移动机器人任务(例如拥挤环境中的路径规划)是期望的。我们使用实例感知语义分割和稀疏场景流来将对象分类为背景,移动或潜在移动,从而确保系统能够模拟具有从静态转变为动态的对象的模型,例如停放的汽车。给定从视觉里程计算估计的相机姿势,通过融合从立体声输入计算的深度图,分别重建背景和可能移动的物体。除了视觉测距之外,稀疏场景流还用于估计检测到的移动物体的3D运动,以便精确地重建它们。进一步开发了地图修剪技术以提高重建精度并减少存储器消耗,从而提高可扩展性。我们在众所周知的KITTI数据集上彻底评估我们的系统。我们的系统能够在大约2.5Hz的PC上运行,主要瓶颈是实例感知语义分段,这是我们希望在未来工作中解决的限制。源代码可从项目网站获得 |
| Generalization ability of region proposal networks for multispectral person detection Authors Kevin Fritz, Daniel K nig, Ulrich Klauck, Michael Teutsch 多光谱人检测旨在自动将人类定位在由多个光谱带组成的图像中。通常,视觉光学VIS和热红外IR光谱被组合以实现更高的人体检测稳健性,尤其是在照明不充分的场景中。本文着重分析现有检测方法的泛化能力。泛化是基于机器学习的检测算法的关键特征,该算法应该在不同的数据集中表现良好。受近期有关VIS谱中人体检测的文献的启发,我们进行了交叉验证研究,以经验确定最有前途的数据集来训练井推广探测器。因此,我们选择一个参考深度卷积神经网络DCNN架构和三个不同的多光谱数据集。最初为流行的Faster R CNN中的对象检测引入的区域提议网络RPN被选择作为参考DCNN。原因在于,独立的RPN能够作为人员检测等两类问题的竞争检测器。此外,现有技术方法最初应用RPN,然后是单独的分类器。三个考虑的数据集是KAIST多光谱行人基准,包括最近发布的用于训练和测试的改进注释,东京多光谱语义分割数据集,以及OSU Color Thermal数据集,包括最近发布的注释。实验结果表明,与其他两个多光谱数据集相比,KAIST多光谱行人基准及其改进的注释为训练具有良好泛化能力的DCNN提供了最佳基础。平均而言,该检测模型在三个数据集的合理测试子集上评估的对数平均Miss Miss MR为29.74。 |
| Uncertainty Modeling of Contextual-Connection between Tracklets for Unconstrained Video-based Face Recognition Authors Jingxiao Zheng, Ruichi Yu, Jun Cheng Chen, Boyu Lu, Carlos D. Castillo, Rama Chellappa 基于无约束视频的面部识别是一个具有挑战性的问题,因为由于姿势,遮挡和模糊导致的视频变化很大。为了解决这个问题,一个有效的想法是通过基于诸如身体外观的上下文构建的上下文连接将身份从高质量的面部传播到低质量的面部。然而,由于缺乏对噪声上下文连接的不确定性建模,先前的方法经常传播错误信息。在本文中,我们提出了不确定性门控图UGG,它在轨迹之间进行基于图的身份传播,这些轨迹由图中的节点表示。 UGG通过在推理期间根据节点的身份分布自适应地更新边缘门的权重来明确地模拟上下文连接的不确定性。 UGG是一种通用的图形模型,只能在推理时或端到端训练中应用。我们在最近发布的具有挑战性的Cast Cast in Movies和IARPA Janus Surveillance Video Benchmark数据集中展示了UGG与最新成果的有效性。 |
| DeepSWIR: A Deep Learning Based Approach for the Synthesis of Short-Wave InfraRed Band using Multi-Sensor Concurrent Datasets Authors Litu Rout, Yatharath Bhateja, Ankur Garg, Indranil Mishra, S Manthira Moorthi, Debjyoti Dhar 卷积神经网络CNN在各种计算机视觉任务中取得了显着进步。在过去几年中,遥感社区观察到深度神经网络DNN最终在几个具有挑战性的领域起飞。在本研究中,我们提出DNN使用并发低分辨率LR波段和现有HR波段的集合生成预定义的高分辨率HR合成波谱带。特别令人感兴趣的是,所提出的网络,即DeepSWIR,在24m和5m GSD以及24m GSD的SWIR频带处使用绿色G,红色R和近红外NIR频带在5m地面采样距离GSD处合成短波红外SWIR频带。据我们所知,商业可交付SWIR波段的最高空间分辨率为7.5米GSD。此外,我们提出了一种基于高斯羽化的图像拼接方法,以处理大型卫星图像。为了通过实验验证合成的HR SWIR波段,我们使用最先进的评估指标严格分析了DeepSWIR产生的定性和定量结果。此外,我们将合成的DN值转换为Top Of Atmosphere TOA反射率,并与Sentinel 2B的相应波段进行比较。最后,我们展示了合成波段的一个真实世界应用,用它来绘制我们感兴趣的区域上的湿地资源。 |
| Inverse Rendering for Complex Indoor Scenes: Shape, Spatially-Varying Lighting and SVBRDF from a Single Image Authors Zhengqin Li, Mohammad Shafiei, Ravi Ramamoorthi, Kalyan Sunkavalli, Manmohan Chandraker 我们为室内场景提出了深度逆渲染框架。从任意室内场景的单个RGB图像,我们创建完整的场景重建,估计形状,空间变化的光照,以及空间变化的非朗伯表面反射。为了训练这个网络,我们使用真实世界的材料增加SUNCG室内场景数据集,并使用快速,高质量,基于物理的GPU渲染器渲染它们,以创建大规模,逼真的室内数据集。我们的逆渲染网络结合了物理洞察力,包括空间变化的球形高斯光照表示,用于模拟场景外观的可微分渲染层,用于迭代细化预测的级联结构和用于细化的双边求解器,允许我们共同推理形状,光照和反射率。实验表明,我们的框架优于以前用于估计单个场景组件的方法,这也使得能够实现增强现实的各种新颖应用,例如照片级真实对象插入和材料编辑。代码和数据将公开发布。 |
| Interpretation of Feature Space using Multi-Channel Attentional Sub-Networks Authors Masanari Kimura, Masayuki Tanaka 卷积神经网络在各种任务中取得了令人瞩目的成果,但解释内部机制是一个具有挑战性的问题。为了解决这个问题,我们在特征空间中利用了多通道注意机制。我们的网络架构允许我们为每个特征获得注意掩模,而现有的CNN可视化方法仅为所有特征提供共同的注意掩模。我们将提出的多通道关注机制应用于多属性识别任务。我们可以为每个特征和每个属性获得不同的注意掩码。这些分析使我们更深入地了解CNN的特征空间。基准数据集的实验结果表明,所提出的方法在准确掌握数据属性的同时,为人类提供了高度的可解释性。 |
| Image-based reconstruction for strong-nonlinear transient problems by using an enhanced ReConNN Authors Yu Lia, Hu Wanga, Wenquan Shuai 随着深度神经网络DNN的模式识别和特征提取的改进,越来越多的问题试图从图像的角度来解决。最近,提出了重建神经网络ReConNN以从基于分析的模型获得基于图像的模型,其可以帮助我们解决许多难以采样的高频问题,例如,声波和冲击力。然而,由于研究过程中问题变化最小,因此卷积神经网络CNN的精度低,生成性对抗网络GAN的多样性差,使得重建过程精度低,效率低,计算成本高,人力资源高。在这项研究中,提出了一种改进的ReConNN模型来解决上述缺点。通过实验,比较和分析,改进后的测试表现出在准确性,效率和成本方面表现优异。 |
| Evaluating the Stability of Recurrent Neural Models during Training with Eigenvalue Spectra Analysis Authors Priyadarshini Panda, Efstathia Soufleri, Kaushik Roy 我们通过评估储层动力学的特征值谱来分析循环网络的稳定性,特别是训练期间的储层计算模型。为了避免在用反馈检查闭环油藏系统时出现的不稳定性,我们建议打破闭环系统。基本上,我们在一段时间内展开油藏动力学,同时结合保留系统整体时间完整性的反馈效应。我们分别用最小二乘回归和FORCE训练评估我们的定点和时变目标方法。我们的分析建立了特征值谱,即随着训练的进行,谱圈收缩,作为衡量训练收敛性以及水库混沌活动向稳定状态收敛的有效和有效度量。 |
| Human Gait Database for Normal Walk Collected by Smart Phone Accelerometer Authors Amir Vajdi, Mohammad Reza Zaghian, Saman Farahmand, Elham Rastegar, Kian Maroofi, Shaohua Jia, Marc Pomplun, Nurit Haspel, Akram Bayat 这项研究的目的是引入一个综合步态数据库,包括93名人类受试者,他们在两个不同的会话期间走在两个终点之间,并使用两个智能手机记录他们的步态数据,一个连接到右大腿,另一个连接在腰部左侧。收集该数据的目的是通过需要足够时间点的基于深度学习的方法来利用。记录包括年龄,性别,吸烟,每日运动时间,身高和体重的元数据。该数据集是公开的。 |
| Unsupervised Learning through Temporal Smoothing and Entropy Maximization Authors Per Rutquist 本文提出了一种以时间序列形式从未标记数据中学习机器的方法。所学习的映射用于提取对控制应用有用的缓慢演变信息,同时有效滤除不需要的高频噪声。 |
| PiNet: A Permutation Invariant Graph Neural Network for Graph Classification Authors Peter Meltzer, Marcelo Daniel Gutierrez Mallea, Peter J. Bentley 我们提出了一种用于图分类和表示学习的端到端深度学习学习模型,该模型对于输入图的节点的排列是不变的。我们通过可区分的节点注意池机制解决了为不同维度的图形学习固定大小图表示的挑战。除了对置换不变性的理论证明之外,我们还提供了经验证据,证明在面对同构图分类任务时,只有少量训练样例,在准确性方面具有统计上显着的增益。我们分析了四个不同矩阵的效果,以促进执行图形卷积的局部消息传递机制与由能够在前者之间平滑过渡的学习参数对进行参数化的矩阵。最后,我们表明我们的模型使用现有技术在一组分子数据集上实现了竞争分类性能。 |
| 3d-SMRnet: Achieving a new quality of MPI system matrix recovery by deep learning Authors Ivo Matteo Baltruschat, Patryk Szwargulski, Florian Griese, Mirco Grosser, Ren Werner, Tobias Knopp 磁性粒子成像MPI数据通常使用在耗时的校准测量中获取的系统矩阵来重建。校准方法与基于模型的重建相比具有重要的优势,它将复杂的粒子物理学和系统缺陷考虑在内。这种益处来自于每当扫描参数,粒子类型或甚至粒子环境例如需要重新校准系统矩阵的成本。粘度或温度变化。用于减少校准时间的一种途径是在预期视场的空间位置的子集处对系统矩阵进行采样并采用系统矩阵恢复。最近的方法使用压缩感知CS并且实现了高达28的子采样因子,其仍然允许重建足够质量的MPI图像。在这项工作中,我们提出了一个带有3d系统矩阵恢复网络的新型框架,并演示它在不到一分钟内恢复一个子采样因子为64的3d系统矩阵,并在系统矩阵质量,重建图像质量方面优于CS和处理时间。通过重建开放访问MPI数据集来证明我们方法的优点。该模型进一步显示能够推断出不同粒子类型的系统矩阵。 |
| ShapeGlot: Learning Language for Shape Differentiation Authors Panos Achlioptas, Judy Fan, Robert X.D. Hawkins, Noah D. Goodman, Leonidas J. Guibas 在这项工作中,我们探讨了常见对象形状之间的细粒度差异是如何用语言表达的,基于图像和对象的3D模型。我们首先构建一个大规模,精心控制的人类话语数据集,每个数据集都指的是3D CAD模型的2D渲染,以便将其与一组形状相似的替代品区分开来。使用这个数据集,我们开发了神经语言理解听力和生产说话模型,这些模型通过点云与渲染的2D图像在接地纯3D形式上有所不同,例如捕获的语用推理程度。关于听众与否的原因,以及神经结构,例如有没有注意。我们发现模型可以与合成伙伴和人类合作伙伴一起表现良好,并且可以保持话语和对象。我们还发现这些模型适用于零射击转移学习到新的对象类,例如从椅子培训转到灯具测试,以及从家具目录中抽取的真实世界图像。病变研究表明,神经聆听者在很大程度上依赖于与部分相关的词语,并将这些词语与对象的视觉部分正确关联,而无需对象部分进行任何明确的网络训练,并且当已知部分词语可用时,转移到新类别是最成功的。这项工作说明了语言基础的实用方法,并提供了对象形态和语言结构之间关系的案例研究。 |
| Feature Selection and Feature Extraction in Pattern Analysis: A Literature Review Authors Benyamin Ghojogh, Maria N. Samad, Sayema Asif Mashhadi, Tania Kapoor, Wahab Ali, Fakhri Karray, Mark Crowley 模式分析通常需要预处理阶段来提取或选择特征,以帮助分类,预测或聚类阶段以更好的方式区分或表示数据。这种要求的原因是原始数据很复杂并且难以在不事先提取或选择适当特征的情况下处理。本文回顾了不同常用的特征选择和提取方法的理论和动机,并介绍了它们的一些应用。还针对这些方法示出了一些数值实现。最后,比较了特征选择和提取中的方法。 |
| LiStereo: Generate Dense Depth Maps from LIDAR and Stereo Imagery Authors Junming Zhang, Manikandasriram Srinivasan Ramanagopalg, Ram Vasudevan, Matthew Johnson Roberson 准确的环境深度图对于自主机器人和车辆的安全操作至关重要。目前,光检测和测距LIDAR或立体匹配算法用于获取这样的深度信息。然而,高分辨率激光雷达是昂贵的并且在大范围产生稀疏深度图立体匹配算法能够生成更密集的深度图,但是通常在远距离上不如LIDAR精确。本文将这些方法结合在一起,生成高质量的密集深度图。与先前使用地面实况标签训练的方法不同,所提出的模型采用自我监督的训练过程。实验表明,所提出的方法能够生成高质量的密集深度图,并且即使在低分辨率输入下也能够稳健地执行。这显示了通过在保持高分辨率的同时使用具有较低分辨率的LIDAR与立体声系统一起降低成本的潜力。 |
| Chinese Abs From Machine Translation |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}