
【今日CV 计算机视觉论文速览 第115期】Fri, 10 May 2019
今日CS.CV 计算机视觉论文速览
Fri, 10 May 2019
Totally 57 papers
👉上期速览✈更多精彩请移步主页

Interesting:
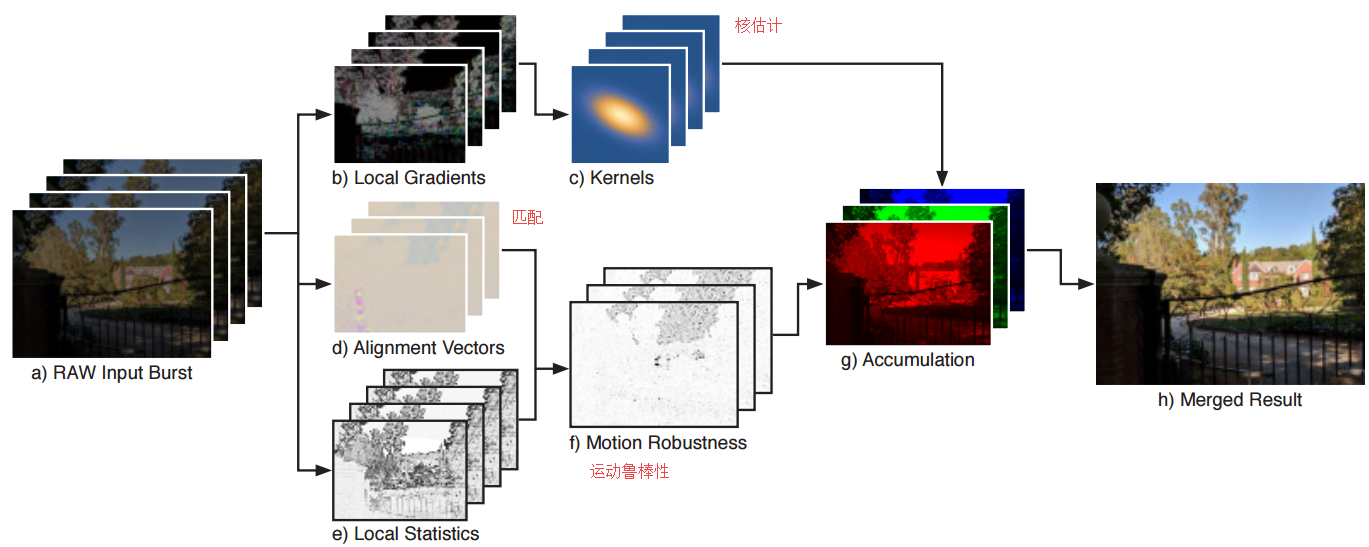
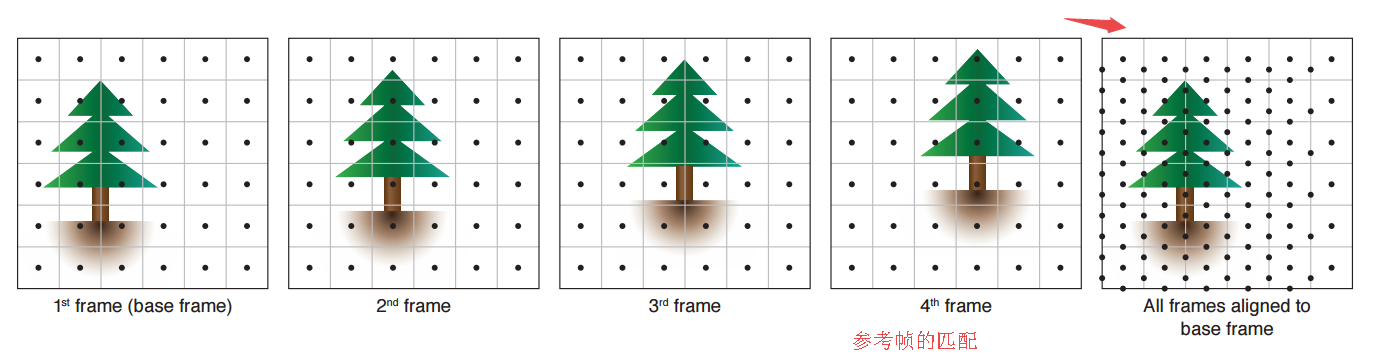
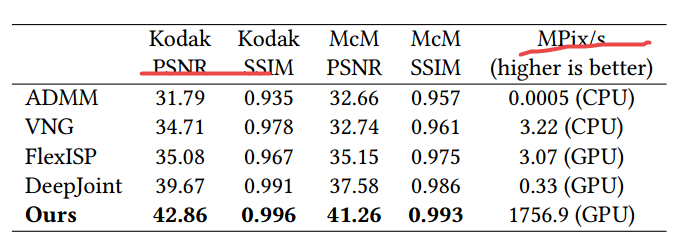
📚****手持设备多帧超分辨, 手机上的相机与单反相比传感器小、孔径小像素少使得成像质量不如单反、信噪比也比较低。这篇文章中研究人员提出直接从彩色滤光阵列(color filter arrays,CFAs)中的原始图像序列得到完整的RGB图像,并有效处理了手的震颤,并在移动、遮挡、场景变化的情况下取得了很好的效果,同时在移动端处理12M照片只需要100ms。(from google research)
速度和精度分析:
一些惊艳的结果:

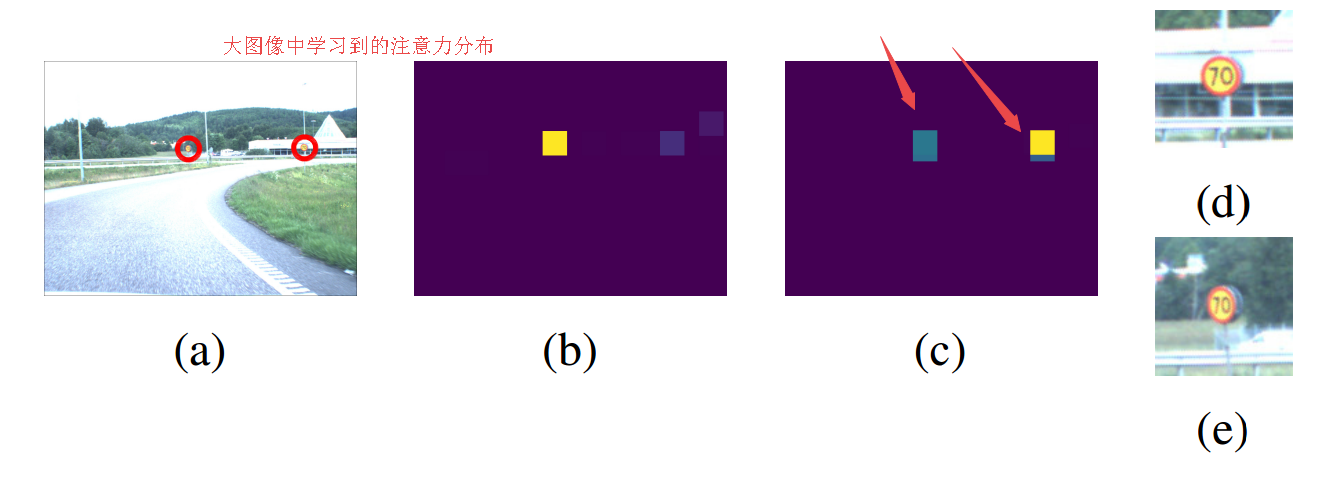
📚基于深度注意力采样模型处理宏像素,通过注意力机制模块采样需要处理的位置,代替先前处理大图像的下采样方法,使用图像片作为输入。使得大图像的原分辨率处理成为可能。基于此研究人员推导出了无偏估计器和可以用SGD训练的模型。 (from 洛桑理工)

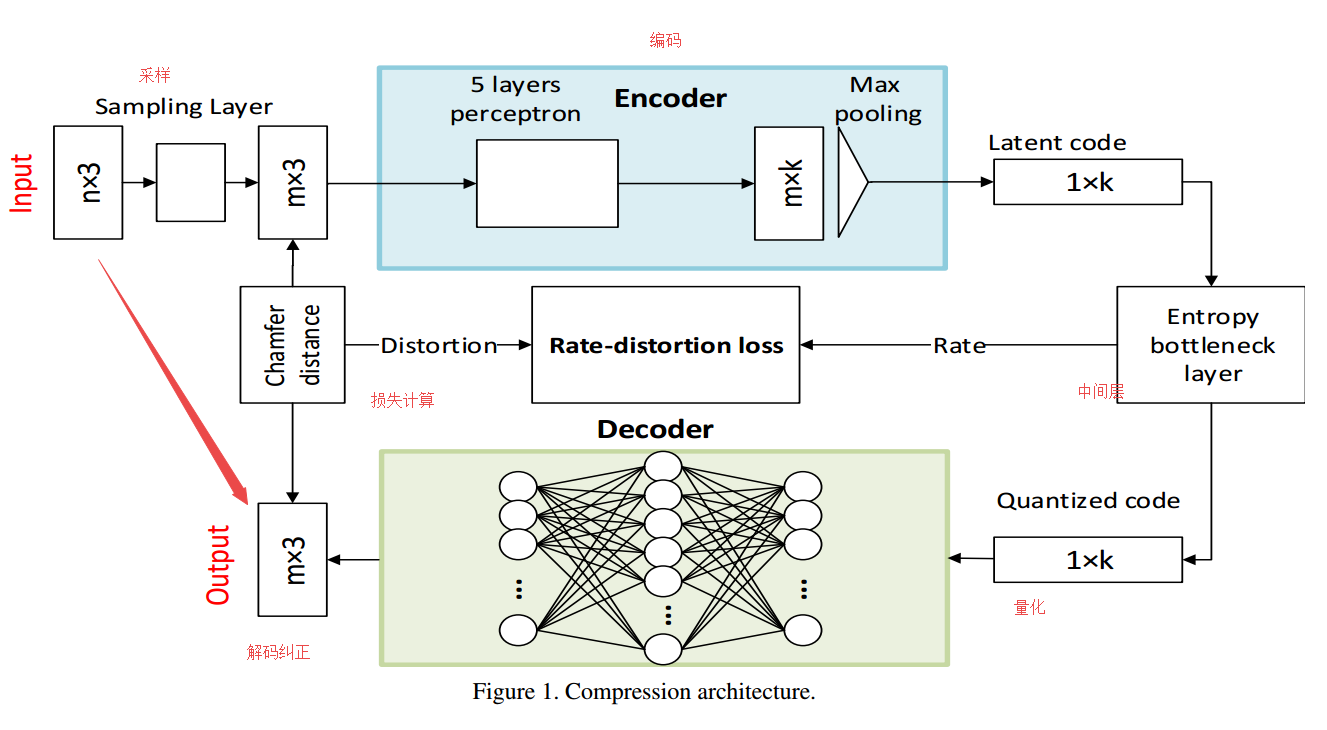
📚**基于自编码器点云有损压缩算法, 第一个直接处理点云数据的压缩模型。基于自编码器实现。(from 北大)
点云压缩架构,从n个点压缩到m个点:
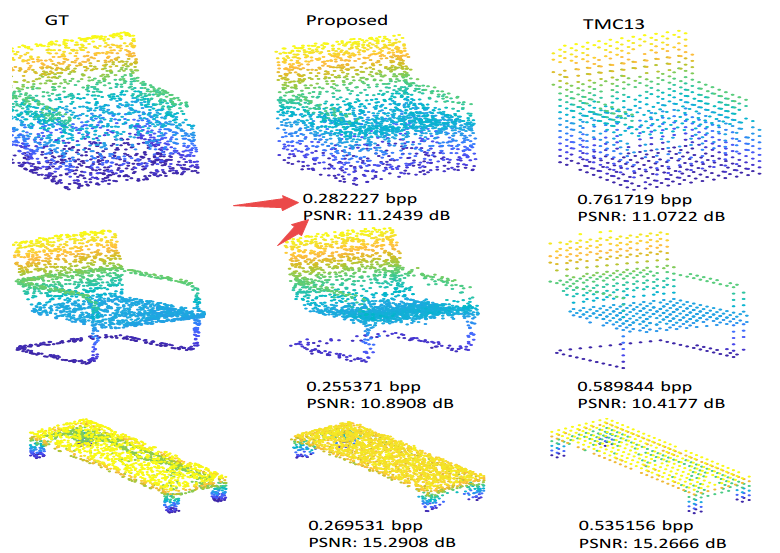
提出的压缩方法码率更低峰值信噪比更高:
entropy_bottleneck:https://tensorflow.github.io/compression/docs/entropy_bottleneck.html
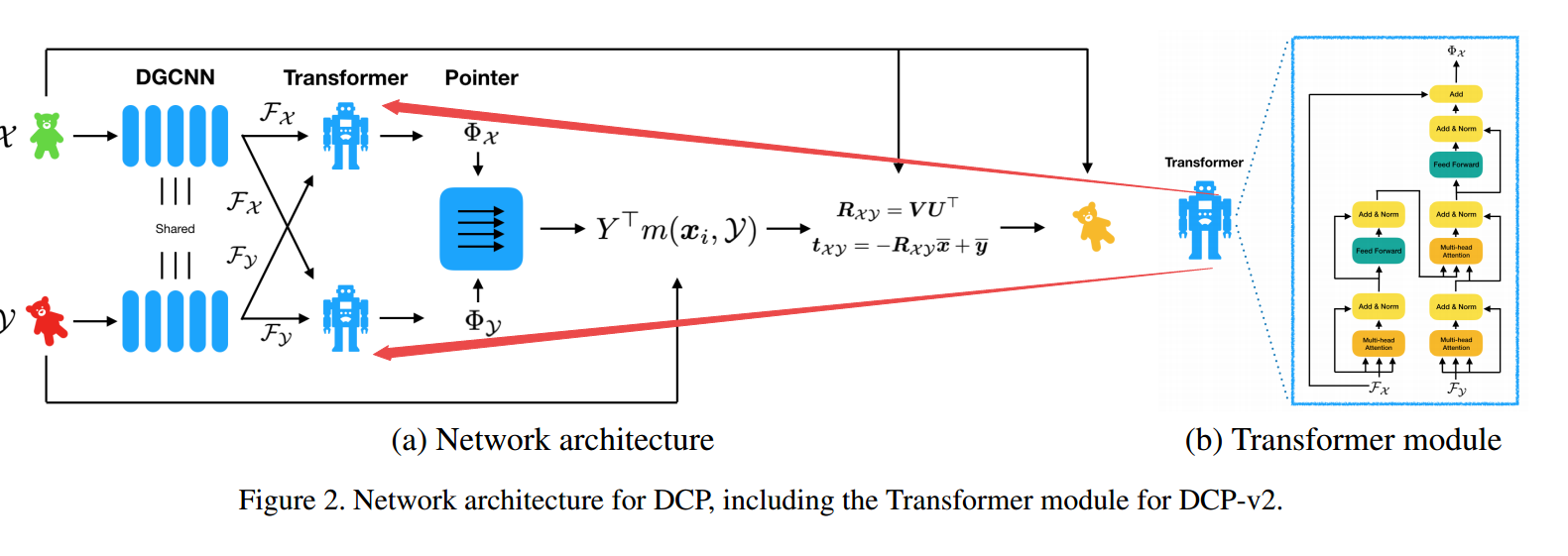
📚***Deep Closest Point学习点云注册配准的表示, 为了学习出两个点云间的刚体选择方程,克服ICP陷入局域最小值的局限,研究人员提出了利用深度网络实现点云配准的方法DCP。模型包含点云嵌入网络和注意里模块结合的点云生成阶段实现粗配准,随后利用可差分的奇异值分解层抽取最后的刚体变化。并在ModelNet40上进行训练.具有泛化性,全局特征抽取性能好(from MIT)
模型架构包含了转换器结构:
一些点云配准的效果:
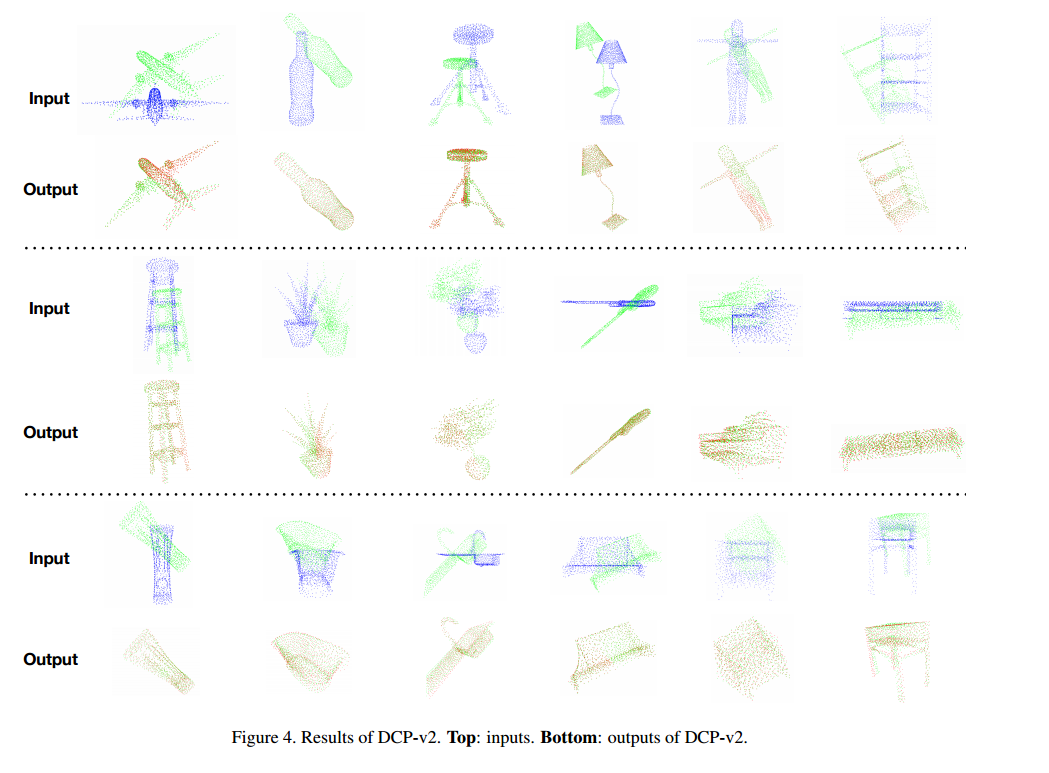
ref:ICPs和PointNetLK Transformer
code:https://github.com/WangYueFt/dcp
author:https://people.csail.mit.edu/yuewang/
Geometric Data Processing group:https://groups.csail.mit.edu/gdpgroup/
prof solomon:https://people.csail.mit.edu/jsolomon/
📚提出识别和检索方法对于单视角三维重建, 研究人员发现现有的网络模型都是基于编码器来从单图像恢复三维结构的,但利用图像分类(聚类)和检索来替换了发现得到的重建结果更好。统计上图像分类和自编码器不可区分,意味着自编码器在做分类而不是重建。研究人员对此进行了深入研究并提出了改进的方向。(from 弗莱堡大学 intel)
We show that encoder-decoder methods are statistically indistinguishable from these baselines, thus indicating that the current state of the art in single-view object reconstruction does not actually perform reconstruction but image classification. We identify aspects of popular experimental procedures that elicit this behavior and discuss ways to improve the current state of research.

不同方法不确定度与IoU与训练样本间的关系:
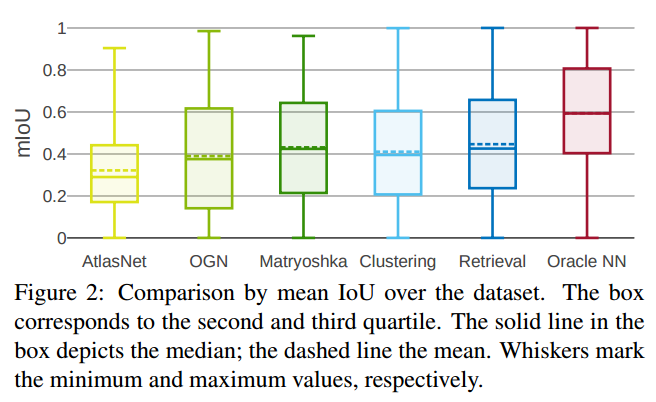
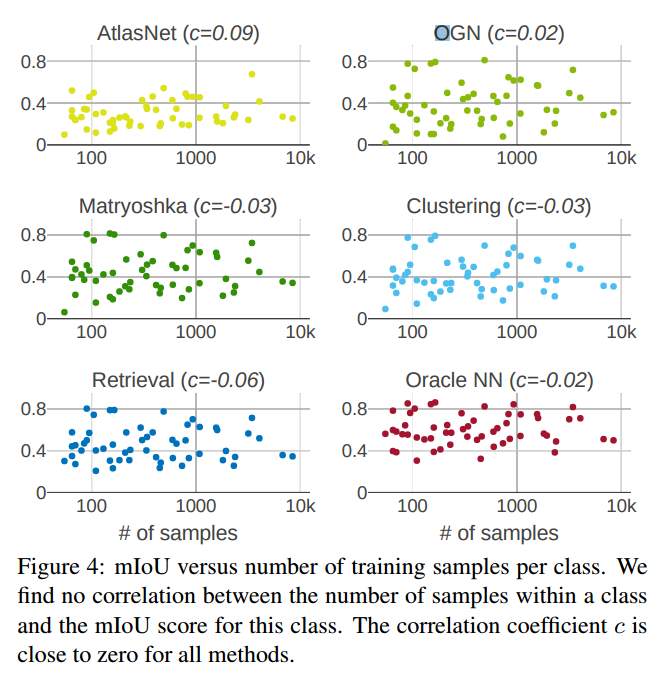
dataset:ShapeNet,[ShapeNet Core55.](Li Yi, Lin Shao, Manolis Savva, et al. Large-scale 3D shape reconstruction and segmentation from ShapeNet Core55.CoRR, abs/1710.06104, 2017. 3)
ref:***Open3D:Qian-Yi Zhou, Jaesik Park, and Vladlen Koltun. Open3D: Amodern library for 3D data processing.
Open3D, doc
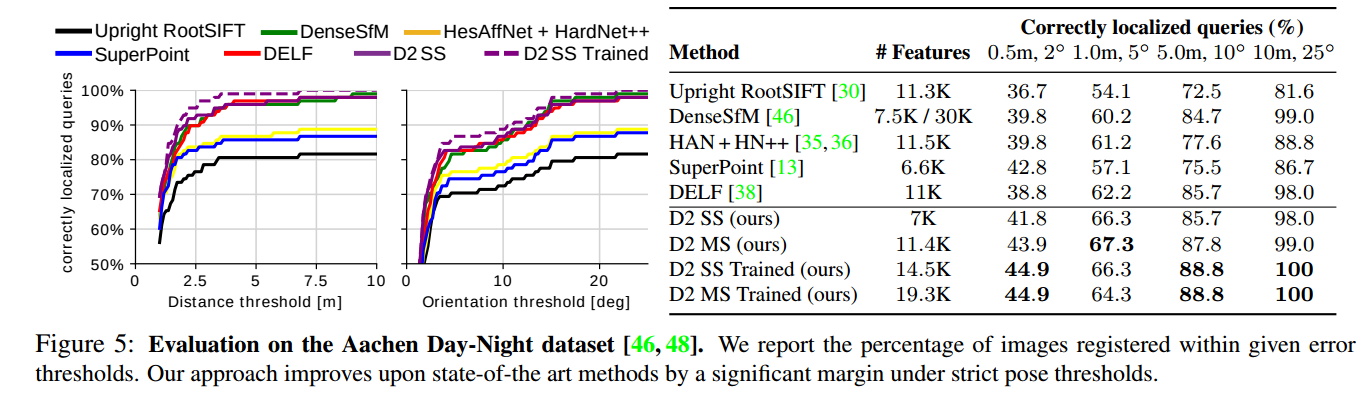
📚D2-Net局域特征的联合描述与检测网络, 提出了一种在极差的图像情况下找到像素级的特征描述子,利用卷积网络同时实现了稠密特征描述和特征检测。通过后处理得到的关键点比传统方法具有更鲁棒的特征。这种方法可以有效用于SFM等重建任务。(from DI, ENS Inria ETH Zurich )
一些很难匹配的结果依然效果很好:
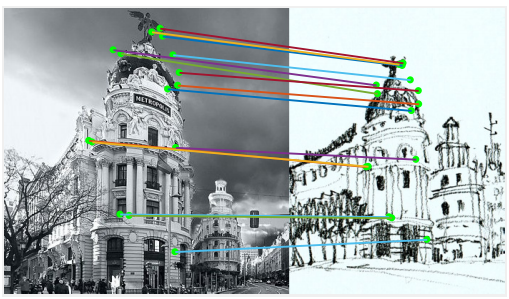


文章提出的方法,第二种:
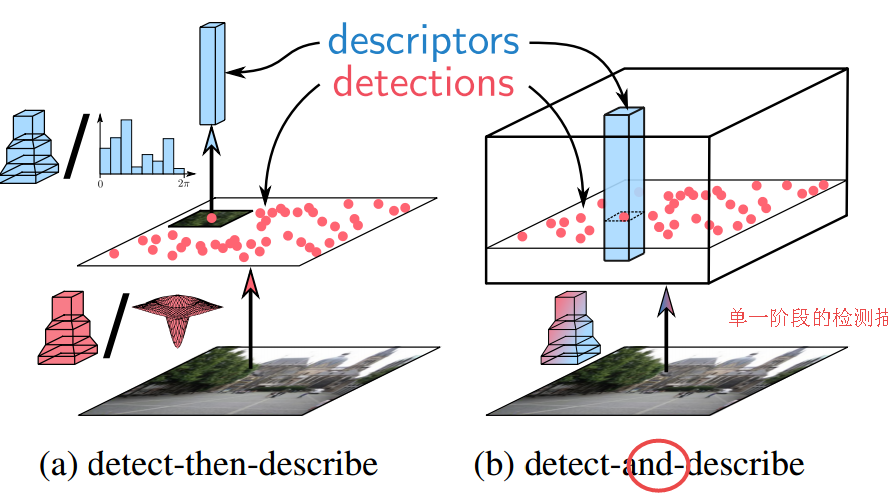
检测和描述网络的结构:
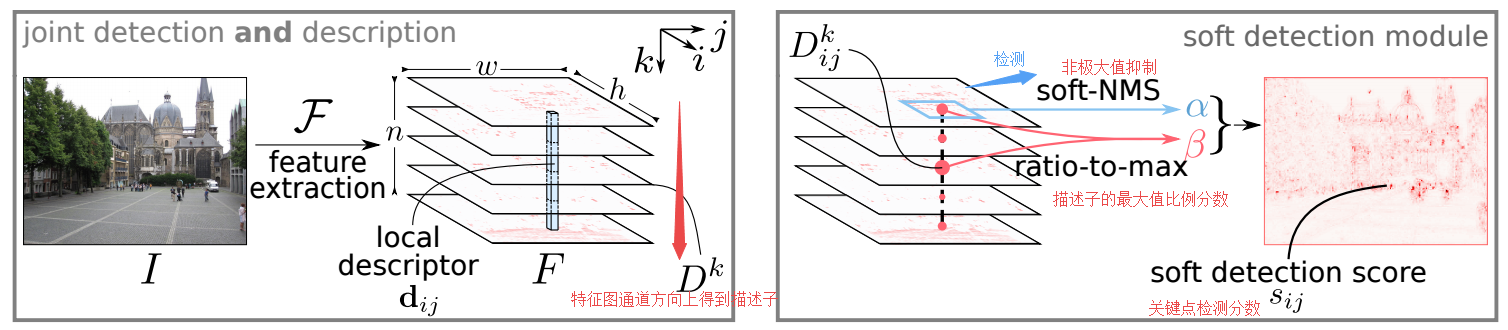
与相关方法的比较:
code:https://github.com/mihaidusmanu/d2-net
dataset: Aachen Day-Night localization dataset InLoc indoor localization benchmark
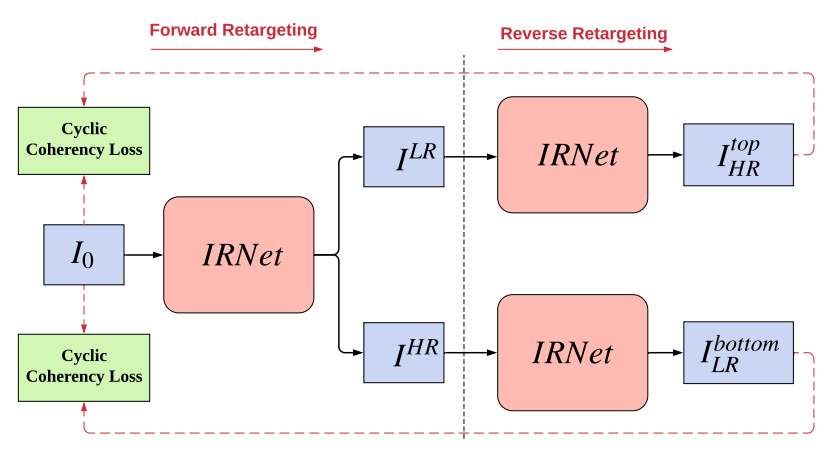
📚Cycle-IR图像重定向,针对图像重定向(缩略图)重新调整大小的任务(图像缩略图技术,在不引入大畸变情况下改变尺寸来适应各种尺寸平面),研究人员提出了基于深度学习的方法,其想法来自于如果一个拉伸变形后的图像可以恢复出原始图像,那么意味着它是有效的retarget。同时通过感知连续损失保持图像前传的连续性。并提出了retarget网络IRNet,加入了空间和通道注意力模块,可以识别出视觉重要性区域。(from 复旦)
模型思想和架构图:
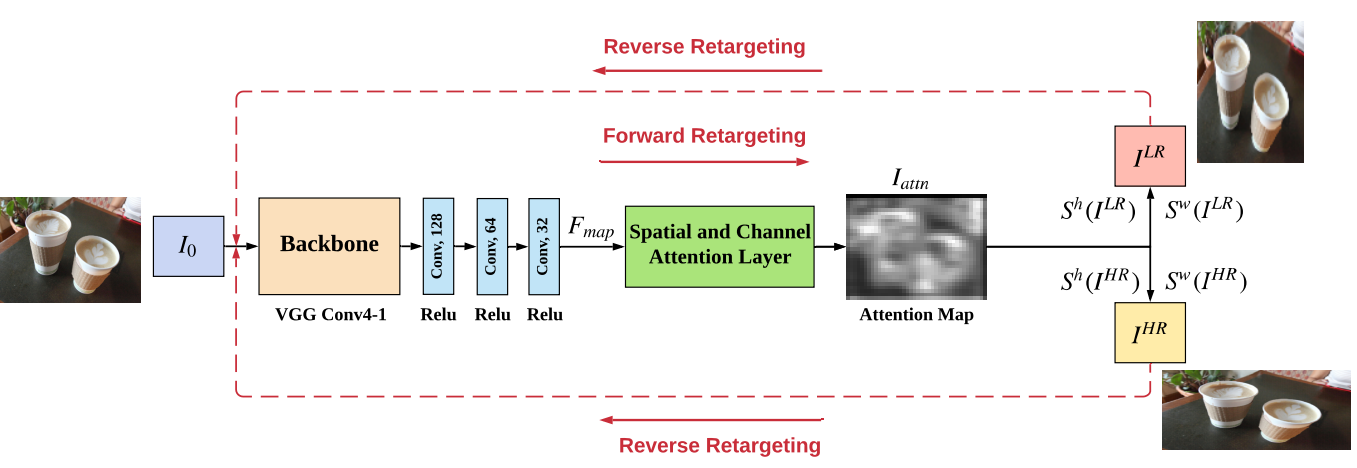
空间注意力模块和通道注意力模块:
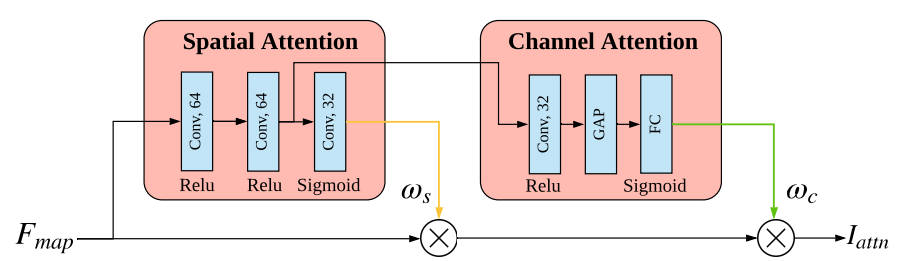
一些结果显示本方法的有效性,可以消除畸变并保持比例结构:

相关方法比较:

code:https://github.com/mintanwei/Cycle-IR
RetargetMe dataset:http://people.csail.mit.edu/mrub/retargetme/
ref:https://blog.csdn.net/piaomiaoju/article/details/9165583
A Comparative Study of Image Retargeting:http://people.csail.mit.edu/mrub/papers/retBenchmark.pdf
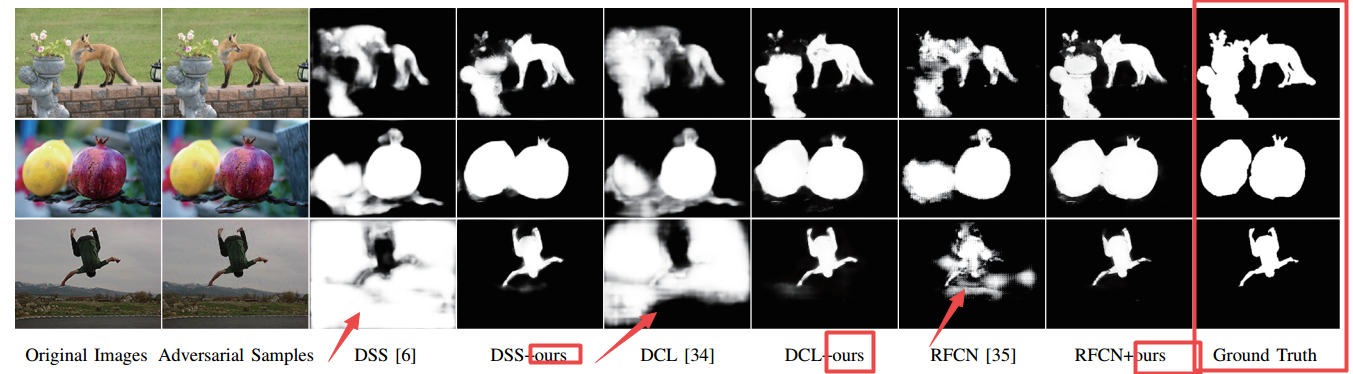
📚ROSA对抗样本鲁棒的显著性目标检测, 通过噪声的引入来摧毁对抗扰动,并在这一噪声的基础上进行有效的显著性预测,框架中还包含了部分分割来保持边缘摧毁对抗扰动和报纸内容。(from 香港大学)
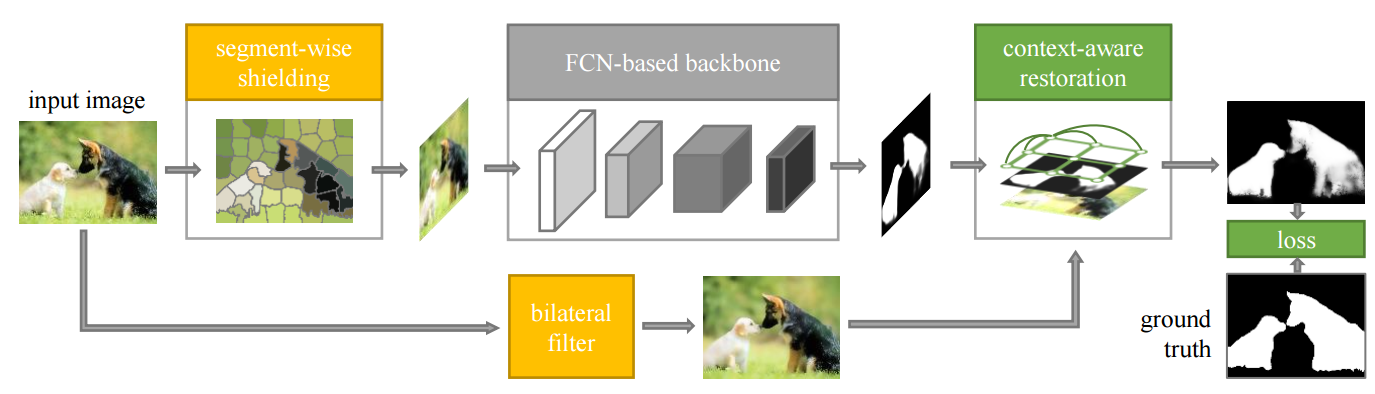
加入本方法后对于对抗样本处理的稳定性:
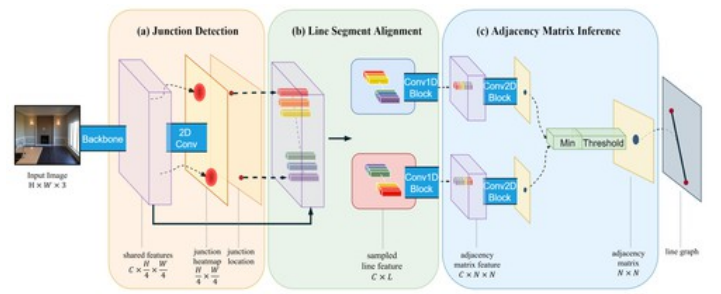
📚PPGNet, 提出了一种检测线元素的网络,通过图来描述线的交点、线和关系,并利用PPGNet来抽取了图像周的线元素。(from 上海科技大学)
在图表示中,交点和连线可以更为容易有效的表示出来。

模型的架构图
dataset:g York Urban and Wireframe
CVPR2019 code:https://github.com/svip-lab/PPGNet
📚***移动端视觉模型的加速技术综述, 综述了适用于移动环境的架构、操作算法,基于强化学习和递归网络改进模型精度速度的方法,最后回顾了软硬件架构和芯片级移动端hpc的发展现状。(from 华为)
一些常用的移动端深度学习计算框架:
📚Learning to Evolve, 将进化算法引入深度强化学习来得到比随机方法更好的策略,充分利用了进化中的变异和组合方式来实现。(from TUM)
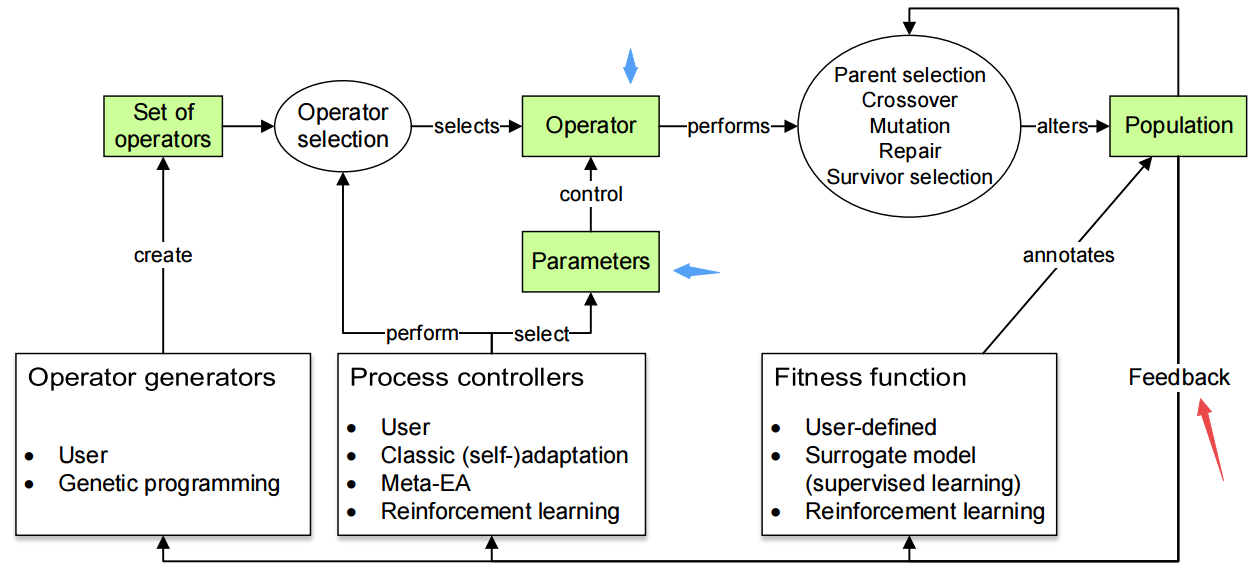
📚JD landmark, 106个人脸关键点定位数据集,包含约16000张人脸数据(from 京东AI 百度VIS,中科大 美图 科大讯飞Iflytekco)
数据样本和106个人脸关键点:

架构和评测方法(3.2部分包含了比赛参赛者的一些模型数据):
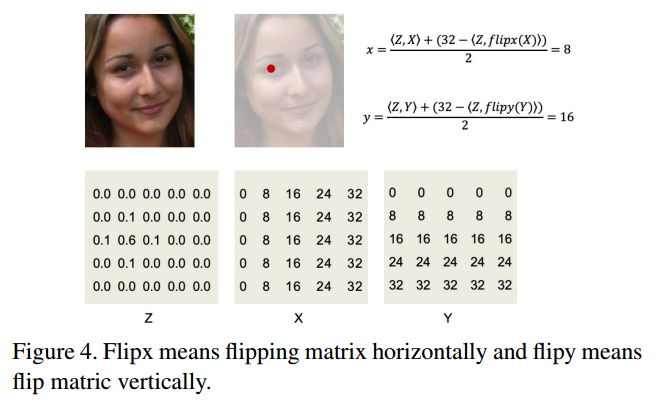
project:https://facial-landmarks-localization-challenge.github.io/
68关键点:300-W, 300-VW and Menpo challenges
300W [11, 10, 16], composed of LFPW [1],AFW [9], HELEN [7] and IBUG [12],
https://ibug.doc.ic.ac.uk/
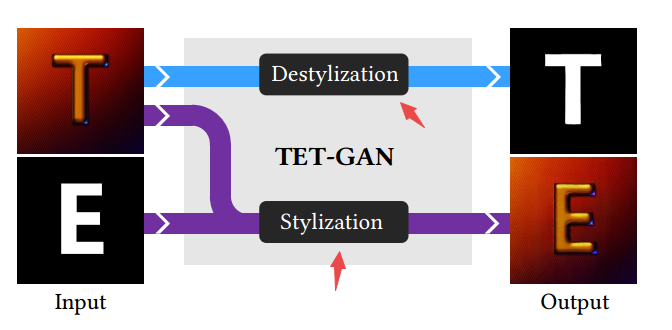
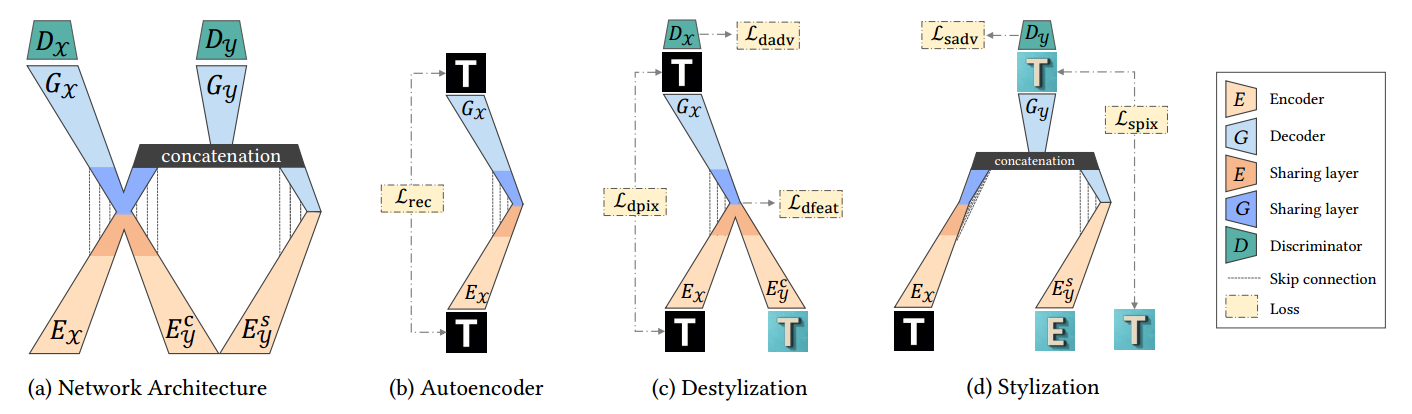
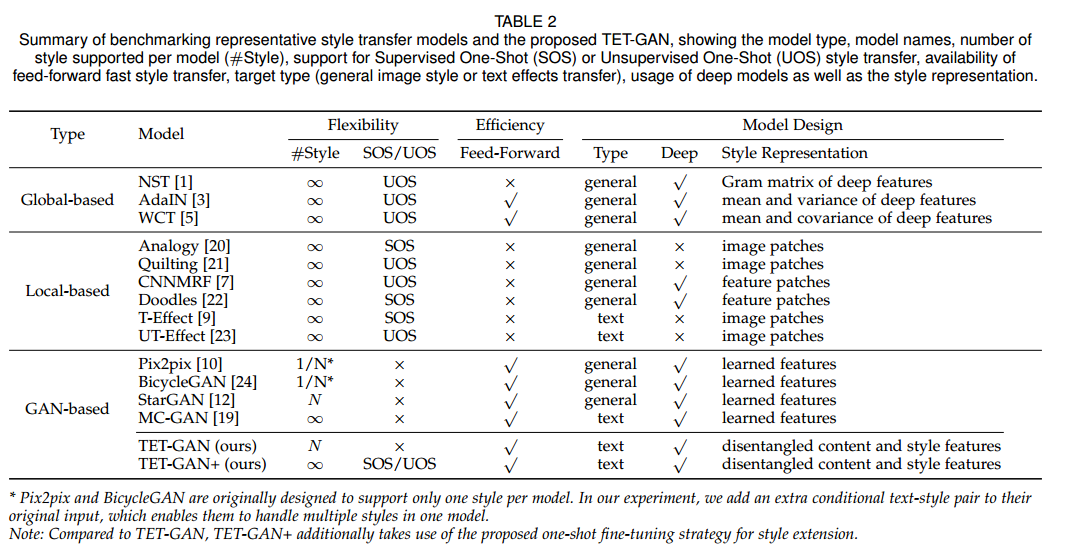
📚TE141K and TETGANs, 艺术字体迁移数据集和基准,包含了141081对艺术字体变形配对数据,共152中设计效果。最后比较了14中风格迁移模型,提出了自己的TET-GAN。(from 北大)

TETGAN的架构图:
14种相关方法的对比:
project:https://daooshee.github.io/TE141K/ could find emails
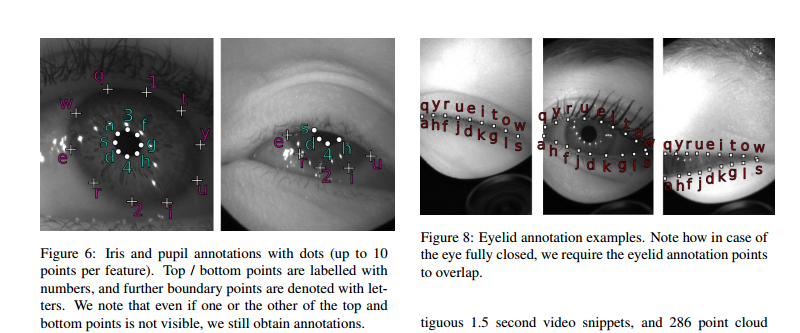
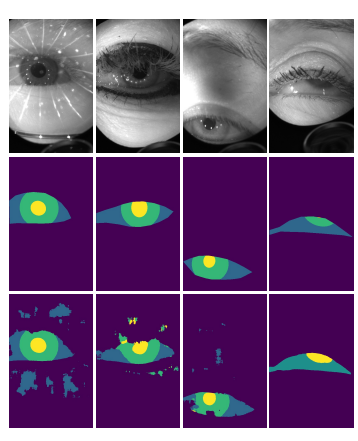
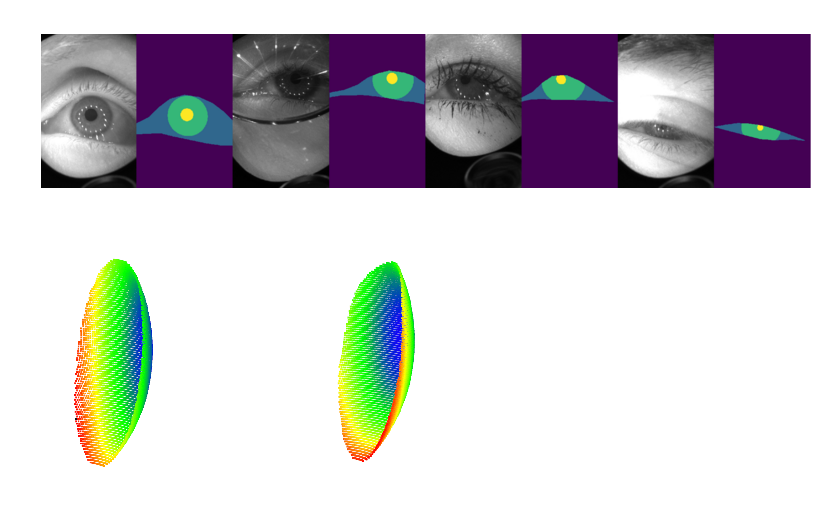
📚OpenEDS, 通过虚拟显示头盔收集的眼部数据集,包含了152个对象,12759张全标记图像和252690张无标记图像。还包括了91200帧序列,143对左右眼点云数据。too那个是提供了对于瞳孔、视网膜、巩膜和背景的语义分割基准。 (from 伦敦大学学院)
瞳孔标注:
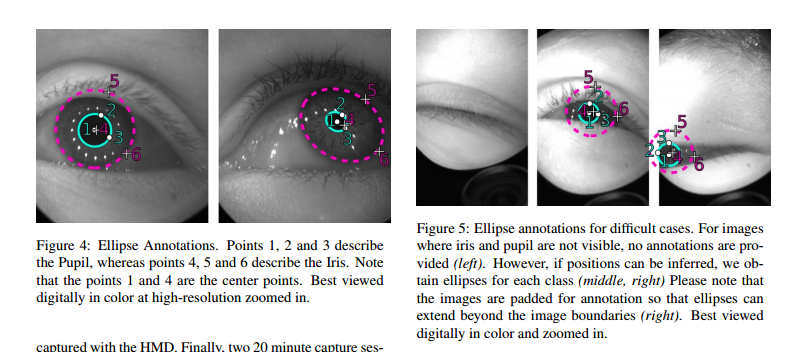
眼部标注信息:
一些实验的分割结果:
project:https://research.fb.com/programs/openeds-challenge
Daily Computer Vision Papers
| Learning Interpretable Features via Adversarially Robust Optimization Authors Ashkan Khakzar, Shadi Albarqouni, Nassir Navab 事实证明,神经网络在医学应用中的分类和诊断方面非常成功。然而,决策过程中的模糊性和学习特征的可解释性是一个值得关注的问题。在这项工作中,我们提出了一种改进神经网络分类器的特征可解释性的方法。最初,我们提出了一种基线卷积神经网络,其在准确性和弱监督定位方面具有最先进的性能。随后,修改损失以将对抗性示例的稳健性整合到训练过程中。在这项工作中,通过使用地面实况边界框评估弱监督定位来量化特征可解释性。还可以使用类激活图和显着性图来直观地评估可解释性。该方法适用于NIH ChestX ray14,这是目前最大的胸部x射线数据集。我们证明了对抗性强大的优化范例在数量上和视觉上都提高了特征可解释性。 |
| Interactive Image Generation Using Scene Graphs Authors Gaurav Mittal, Shubham Agrawal, Anuva Agarwal, Sushant Mehta, Tanya Marwah 近年来,在基于场景的文本描述中生成图像的领域中已经见证了一些令人兴奋的发展。这些方法主要集中在从静态文本描述生成图像,并且仅限于一次性生成图像。他们无法基于增量添加的文本描述以交互方式生成图像,这些描述更直观且类似于我们描述图像的方式。我们提出了一种基于场景描述场景图的一系列图形来递增地生成图像的方法。我们提出了一种循环网络架构,其保留在先前步骤中生成的图像内容,并根据新提供的场景信息修改累积图像。我们的模型利用Graph Convolutional Networks GCN来满足可变大小的场景图以及Generative Adversarial图像转换网络,以生成逼真的多目标图像,而无需在训练期间进行任何中间监督。我们使用Coco Stuff数据集进行实验,该数据集具有多个对象图像以及描述视觉场景的注释,并且表明我们的模型明显优于同一数据集上的其他方法,从而为增量增长的场景图生成视觉上一致的图像。 |
| Show, Price and Negotiate: A Hierarchical Attention Recurrent Visual Negotiator Authors Amin Parvaneh, Ehsan Abbasnejad, Qi Wu, Javen Shi 作为卖方或买方的谈判是在线购物的基本和复杂方面。对于智能代理来说是具有挑战性的,因为它需要提取和利用来自多个源的信息,例如照片,文本和数字,2预测产品的合适价格以达到最佳协议,3表达意图以自然语言的价格和4个一致的定价为条件。传统的对话系统不能很好地解决这些问题。例如,我们认为价格应该是谈判的驱动因素,并且可以由代理商理解。但是传统上,价格被简单地视为单词标记,即作为句子的一部分并且与其他单词共享相同的单词嵌入空间。为此,我们提出了我们的Visual Negotiator,它包含一个端到端的深度学习模型,可以预测初始协议价格并在生成引人注目的支持对话框时对其进行更新。对于1,我们的视觉谈判者利用注意机制从图像和文本描述中提取相关信息,并将价格和后来提炼的价格作为系统的几个阶段的单独重要输入,而不是简单地成为句子的一部分2,我们使用注意力来学习价格嵌入来估计初始值。随后,我们以编码器解码器的方式生成支持对话框,利用价格嵌入。此外,我们使用分层递归模型,该模型学习在一个级别上细化价格,同时在另一个级别生成支持对话框。对于这种分层模型,该层次模型提供一致的定价。根据经验,我们证明我们的模型在协议价格,价格一致性和语言质量方面显着改善了CraigslistBargain数据集的协商。 |
| Fully Parallel Architecture for Semi-global Stereo Matching with Refined Rank Method Authors Yiwu Yao, Yuhua Cheng 提出了具有精细秩方法的高效半全局匹配SGM的视差级完全并行架构。改进的SGM算法采用非参数统一秩模型实现,该模型是秩滤波器AD和秩SAD的组合。通过将局部图像结构的约束引入秩方法,秩SAD是一种新颖的定义。因此,具有Rank SAD的统一秩模型可以弥补Rank过滤器AD的缺陷。实验结果表明,精细SGM算法具有良好的主观质量和客观性能。 SGM硬件实现的完全并行结构采用合理的差异化策略。数据流的并行性允许具有可接受的最大频率的特定应用的适当吞吐量。 RTL仿真和综合的结果确保了所提出的并行架构适用于VLSI实现。 |
| Tuned Inception V3 for Recognizing States of Cooking Ingredients Authors Kin Ng 烹饪是一项必须每天进行的任务,因此这是许多人认为理所当然的活动。对于准备膳食的人来说很自然,但对于机器人来说,即使准备一个简单的三明治也会导致极其艰巨的任务。在机器人技术中,设计厨房机器人很复杂,因为烹饪依赖于各种物理相互作用,这些相互作用取决于不同的条件,例如环境的变化,顺序指令的正确执行,以及运动,以及检测烹饪成分的不同状态可以为他们正确的把握和操纵。在本文中,我们关注状态识别的挑战,并提出一个精细调整的卷积神经网络,通过重用Inception V3预训练模型来利用转移学习。该模型在由11个状态组成的烹饪数据集上训练和验证,例如去皮,切丁,整个等。本文提出的工作可以为找到解决问题的潜在解决方案提供见解。 |
| Processing Megapixel Images with Deep Attention-Sampling Models Authors Angelos Katharopoulos, Fran ois Fleuret 由于计算和存储器限制,现有的深层架构不能在诸如百万像素图像的非常大的信号上操作。为了解决这一局限,我们提出了一种完全可区分的端到端可训练模型,该模型仅对全分辨率输入图像的一小部分进行采样和处理。 |
| Bilinear discriminant feature line analysis for image feature extraction Authors Lijun Yan, Jun Bao Li, Xiaorui Zhu, Jeng Shyang Pan, Linlin Tang 提出了一种新的双线性判别特征线分析BDFLA用于图像特征提取。最近的特征线NFL是强大的分类器。最近引入了一些基于NFL的子空间算法。在大多数基于NFL的经典子空间学习方法中,输入样本是向量。对于图像分类任务,应首先将图像样本转换为矢量。该过程引起高计算复杂性并且还可能导致样品的几何特征的损失。提出的BDFLA是基于矩阵的算法。它旨在最小化类内散射,并基于二维2D NFL最大化类散射。两个图像数据库的实验结果证实了有效性。 |
| Visualizing the Consequences of Climate Change Using Cycle-Consistent Adversarial Networks Authors Victor Schmidt, Alexandra Luccioni, S. Karthik Mukkavilli, Narmada Balasooriya, Kris Sankaran, Jennifer Chayes, Yoshua Bengio 我们提出了一个项目,旨在使用Cycle Consistent Adversarial Networks CycleGAN生成描绘气候变化准确,生动和个性化结果的图像。通过在极端天气事件之前和之后的房屋的街景图像上训练我们的CycleGAN模型,例如洪水,森林火灾等,我们学习了一个映射,然后可以应用于尚未经历这些事件的位置的图像。这种视觉转换与气候模型预测相结合,以评估长期50年气候相关事件的可能性和类型,以便在观众心目中更接近未来。我们项目的最终目标是通过利用气候模型预测,在保持科学可信度的同时,通过更加深刻地了解气候变化的影响,使个人能够对气候未来做出更明智的选择。 |
| Machine Vision in the Context of Robotics: A Systematic Literature Review Authors Javad Ghofrani, Robert Kirschne, Daniel Rossburg, Dirk Reichelt, Tom Dimter 机器视觉对机器人技术至关重要,因为它依赖于视觉传感器(如自动移动机器人和智能生产系统)的输入。为了创建明天的智能家居和系统,对系统研究领域当前挑战的概述将用于确定以系统和可重复的方式创建的更多可能方向。在这项工作中,进行了系统的文献回顾,涵盖了过去10年的研究。我们从四个数据库中筛选了172篇论文,并选择了52篇相关论文。虽然稳健性和计算时间大大提高,但遮挡和光照变化仍然是最大的问题。根据最近出版物的数量,我们得出结论,观察到的领域与研究界具有相关性和关注性。该领域的许多领域出现了进一步的挑战。 |
| Human Activity Recognition Using Visual Object Detection Authors Schalk Wilhelm Pienaar, Reza Malekian 视觉人类活动识别HAR和与其他传感器的数据融合可以帮助我们跟踪地下矿工的行为和活动,几乎没有阻碍。现有模型,例如Single Shot Detector SSD,在上下文COCO数据集中的公共对象上训练,用于检测矿工的当前状态,例如受伤矿工与非受伤矿工。 Tensorflow用于实现机器学习算法的抽象层,虽然它使用Python来处理节点和张量,但实际算法在C库上运行,在性能和开发速度之间提供了良好的平衡。本文进一步讨论了用于确定机器学习准确性的评估方法,以及通过数据融合提高采矿环境中人们检测到的活动状态的准确性的方法。 |
| Accurate Visual Localization for Automotive Applications Authors Eli Brosh, Matan Friedmann, Ilan Kadar, Lev Yitzhak Lavy, Elad Levi, Shmuel Rippa, Yair Lempert, Bruno Fernandez Ruiz, Roei Herzig, Trevor Darrell 准确的车辆定位是建立有效的车辆到车辆网络和汽车应用的关键一步。然而,诸如移动电话提供的标准等级GPS数据通常是嘈杂的并且在许多城市区域中表现出显着的定位误差。从图像精确定位的方法通常依赖于基于结构的技术,因此在规模上受到限制并且计算成本高。在本文中,我们提出了一种可扩展的可视化本地化方法,旨在实现实时性能。我们提出了一种混合粗到精的方法,利用视觉和GPS定位线索。我们的解决方案使用自我监督的方法来学习紧凑的道路图像表示。该表示使得能够进行有效的视觉检索并提供粗略的定位提示,其与车辆自我运动融合以获得高精度的位置估计。作为评估我们视觉定位方法性能的基准,我们引入了一个新的大型驾驶数据集,该数据集基于从大规模连接的仪表板凸轮网络获得的视频和GPS数据。我们的实验证实,我们的方法在挑战城市环境方面非常有效,将定位误差降低了一个数量级。 |
| A note on 'A fully parallel 3D thinning algorithm and its applications' Authors Tao Wang, Anup Basu 3D细化算法逐层侵蚀3D二值图像以提取骨架。本文对Ma和Sonka的细化算法,一种完全并行的3D细化算法及其应用进行了修正,无法保持三维物体的连通性。我们从Ma和Sonka的算法开始,并检查其连通性保护的验证。我们的分析导致一组不同的删除模板,可以保持3D对象的连接。 |
| Agnostic Lane Detection Authors Yuenan Hou 车道检测是自动驾驶中的一项重要但具有挑战性的任务,其受许多因素的影响,例如,光照条件,由其他车辆引起的遮挡,道路上的无关标记以及车道固有的长而薄的特性。传统方法通常将车道检测视为语义分段任务,其将类标签分配给图像的每个像素。这种表述很大程度上取决于车道数量是预定义和固定的假设,并且没有发生车道变换,这并不总是成立。为了使车道检测模型适用于任意数量的车道和车道变换场景,我们采用实例分割方法,首先区分车道和背景,然后将每个车道像素分类到每个车道实例中。此外,利用多任务学习范例来更好地利用结构信息,并且使用特征金字塔结构来检测极薄的通道。三种流行的通道检测基准,即TuSimple,CULane和BDD100K,用于验证我们提出的算法的有效性。 |
| Learning fashion compatibility across apparel categories for outfit recommendation Authors Luisa F. Polania, Satyajit Gupte 本文解决了在用户对特定服装项目感兴趣的情况下生成完成服装的建议的问题。所提出的方法基于用于特征提取的暹罗网络,随后是用于学习时尚兼容性度量的完全连接的网络。由暹罗网络生成的嵌入增强了颜色直方图特征,这是由颜色在确定时尚兼容性中起重要作用所激发的。网络的训练被公式化为最大后验MAP问题,其中假设拉普拉斯分布用于暹罗网络的滤波器以促进稀疏性,并且假设矩阵变量正态分布用于度量网络的权重以有效地利用输入之间的相关性。每个完全连接层的单元。 |
| OpenEDS: Open Eye Dataset Authors Stephan J. Garbin, Yiru Shen, Immo Schuetz, Robert Cavin, Gregory Hughes, Sachin S. Talathi 我们提供了一个大规模的数据集,OpenEDS Open Eye Dataset,使用虚拟现实VR头戴式显示器拍摄的眼睛图像,该显示器安装有两个同步的眼镜摄像头,在受控照明下以200Hz的帧速率。该数据集是从从152个个体参与者收集的眼睛区域的视频捕获中编辑的,并且被分成4个子集,12,759个图像,其具有用于关键眼睛区域虹膜,瞳孔和巩膜的像素级注释ii 252,690个未标记的眼睛图像,iii 91,200个来自随机选择的帧持续时间为1.5秒的视频序列和静态143对左右点云数据,这些数据来自从子集中收集的眼部区域的角膜地形图,152个中的143个参与者。已经在OpenEDS上评估了基线实验,用于瞳孔,虹膜,巩膜和背景的语义分割任务,平均交叉联合mIoU为98.3。我们预计OpenEDS将为眼动追踪社区和更广泛的机器学习和计算机视觉社区的研究人员创造机会,以推进VR应用程序的眼动追踪状态。数据集可根据要求下载 |
| Unsupervised automatic classification of Scanning Electron Microscopy (SEM) images of CD4+ cells with varying extent of HIV virion infection Authors John M. Wandeto, Birgitta Dresp Langley 在数字图书馆中存档大量医学或细胞图像可能需要根据特定标准对随机分散的图像数据集进行排序,例如特定局部颜色的空间范围或显示生理结构,组织的不同有意义状态的对比内容,或以特定顺序的细胞,指示病理学的进展或衰退,或细胞结构对治疗的进行性反应。在这里,我们使用了我们早期工作中描述的基于自组织地图SOM,全自动和无监督的分类程序,并将其应用于CD4 T淋巴细胞的最小处理灰度和/或颜色处理的扫描电子显微镜SEM图像,所谓的辅助细胞具有不同HIV病毒粒子感染的程度。结果表明,训练后SOM输出中的量化误差允许在一系列图像中缩放空间大小和变化方向或局部像素对比度或颜色,其可靠性超过任何人类专家的可靠性。该过程易于实施且快速,并且代表了朝向低成本自动数字图像存档的有希望的步骤,其中人类操作员的干预最小。 |
| Alignment-Free Cross-Sensor Fingerprint Matching based on the Co-Occurrence of Ridge Orientations and Gabor-HoG Descriptor Authors Helala AlShehri, Muhammad Hussain, Hatim AboAlSamh, Qazi Emad ul Haq, Aqil M. Azmi 现有的自动指纹验证方法被设计为在假设安装相同的传感器用于登记和认证常规匹配的情况下工作。当使用一种基于接触的传感器进行登记而另一种基于接触的传感器用于认证交叉匹配或指纹传感器互操作性问题时,效率显着降低。指纹中的脊取向图案对于传感器类型是不变的。基于这一观察,我们提出了一种强健的指纹描述符,称为脊线方向Co Ror的共同出现,它对脊线方向的空间分布进行编码。利用该描述符,我们引入了一种有效的交叉匹配问题自动指纹验证方法。此外,为了增强该方法的鲁棒性,我们通过Gabor HoG描述符合并基于尺度的脊定向信息。将两个描述符与典型相关分析CCA融合,并使用城市街区距离计算两个指纹之间的匹配分数。所提出的方法是无对齐的并且可以处理匹配过程而无需注册步骤。两个基准数据库FingerPass和MOLF的强化实验显示了该方法的有效性,并揭示了其对现有技术方法的显着增强,如VeriFinger商业SDK,细节柱面代码MCC,带刻度的MCC和薄板样条TPS模型。拟议的研究将帮助安全机构,服务提供商和执法部门克服不同技术和交互类型的接触传感器的互操作性问题。 |
| Inferring the Importance of Product Appearance: A Step Towards the Screenless Revolution Authors Yongshun Gong, Jinfeng Yi, Dongdong Chen, Jian Zhang, Jiayu Zhou, Zhihua Zhou 如今,几乎所有的在线订单都是通过手机,平板电脑和电脑等屏蔽设备进行的。随着物联网物联网和智能家电的快速发展,越来越多的无屏智能设备,例如智能扬声器和智能冰箱,出现在我们的日常生活中。他们开辟了新的互动方式,可以为接触新客户和增加销售提供绝佳机会。然而,并非所有项目都适合无屏幕购物,因为一些项目外观在消费者决策中起着重要作用。典型的例子包括衣服,娃娃,包和鞋子。在本文中,我们的目的是推断每个项目在消费者决策中的重要性,并确定适合无屏购物的项目组。具体而言,我们将问题表述为分类任务,预测项目的外观是否对人们的购买行为产生重大影响。为了解决这个问题,我们从三个不同的视图中提取特征,即项目内在属性,项目图像和用户评论,并通过众包收集一组必要的标签。然后,我们提出了一个迭代半监督学习框架,其中包含三个精心设计的损失函数。我们对从在线零售巨头收集的真实世界交易数据集进行了大量实验 |
| On Applying Machine Learning/Object Detection Models for Analysing Digitally Captured Physical Prototypes from Engineering Design Projects Authors Jorgen F. Erichsen, Sampsa Kohtala, Martin Steinert, Torgeir Welo 虽然计算机视觉在过去十年中越来越受到计算机科学的关注,但很少有人将其用于工程设计研究。现有的数据集和技术使研究人员能够捕获和访问更多的观测和视频文件,因此分析正在成为一个限制因素。因此,本文正在研究机器学习的应用,即物体检测方法,以帮助分析物理定型。通过从早期开发项目访问来自850个原型的5950个图像的大型数字捕获物理原型数据集,作者研究了可用于分析该数据集的应用程序。作者使用物理原型图像的自定义图像集,从两个已知的框架(TensorFlow对象检测API和Darknet)中重新训练了两个经过预先训练的对象检测模型。结果,提出了四种训练模型的概念证明,其中两种模型用于检测基于木材的片材样品,两种模型用于检测包含微控制器的样品。所有模型都使用标准度量对象检测模型性能进行评估,并讨论了在工程设计研究中使用对象检测模型的适用性。结果表明,模型可以分别成功地分类材料的类型和预制组件的类型。但是,需要做更多的工作才能将对象检测模型完全集成到工程设计分析工作流程中。作者还推断,使用物体检测分析物理原型图像将大大减少在工程设计研究中分析大型数据集所需的工作量。 |
| HAWQ: Hessian AWare Quantization of Neural Networks with Mixed-Precision Authors Zhen Dong, Zhewei Yao, Amir Gholami, Michael Mahoney, Kurt Keutzer 模型大小和推理速度功率已经成为许多应用中神经网络部署的主要挑战。解决这些问题的有希望的方法是量化。然而,将模型均匀量化到超低精度会导致显着的精度降低。对此的新颖解决方案是使用混合精确量化,因为与其他层相比,网络的某些部分可能允许更低的精度。但是,没有系统的方法来确定不同层的精度。对于深度网络而言,强力方法是不可行的,因为混合精度的搜索空间是层数的指数。另一个挑战是在将模型量化为目标精度时用于确定逐块微调顺序的类似因子复杂度。在这里,我们介绍了Hessian AWare量化HAWQ,一种新颖的二阶量化方法来解决这些问题。 HAWQ允许基于层的Hessian谱自动选择每层的相对量化精度。此外,HAWQ基于二阶信息为量化层提供确定性微调顺序。我们使用ResNet20在Cifar 10上显示我们的方法的结果,使用Inception V3,ResNet50和SqueezeNext模型在ImageNet上显示我们的方法的结果。将HAWQ与现有技术进行比较表明,与DNAS引用wu2018混合相比,我们可以在ResNet20上实现8倍激活压缩比的类似更高精度,在ResNet50和Inception V3上使用多达14个较小型号可获得高达1倍的精度最近提出的RVQuant引用方法2018值和HAQ引用wang2018haq。此外,我们展示了我们可以将SqueezeNext量化为仅1MB的模型尺寸,同时在ImageNet上实现68以上的top1精度。 |
| Measuring similarity between geo-tagged videos using largest common view Authors Wei Ding, KwangSoo Yang, Kwang Woo Nam 本文提出了一种基于视频数据视场FoV发现相似轨迹的新问题。这个问题对于许多社会应用非常重要,例如对移动物体进行分组,对地理图像进行分类以及识别有趣的轨迹模式。先前的工作仅考虑空间位置或两个线段之间的空间关系。然而,这些方法显示了找到具有共同视图的类似移动对象的限制。在本文中,我们提出了一种新的算法,可以将空间位置和视点分组,以识别类似的轨迹。我们还提出了降低所提议工作的计算成本的新方法。使用真实世界数据集的实验结果表明,所提出的方法优于先前的工作并降低了计算成本。 |
| Supervised Online Hashing via Hadamard Codebook Learning Authors Mingbao Lin, Rongrong Ji, Hong Liu, Yongjian Liu 近年来,二进制代码学习,即a.k.a散列,在大规模多媒体检索中受到广泛关注。它旨在将高维数据点编码为二进制代码,因此可以通过汉明空间有效地近似原始高维度量空间。但是,大多数现有的散列方法采用离线批量学习,不适合处理带有流数据或新实例的增量数据集。相比之下,现有在线哈希的鲁棒性仍然是一个开放性问题,而有监督语义信息的嵌入几乎不会提高在线哈希的性能,这主要是由于监督学习中未知类别数的缺陷。在本文中,我们提出了一种在线哈希方案,称为Hadamard Codebook,基于在线哈希HCOH,旨在解决上述问题,以实现健壮和有监督的在线哈希。特别地,我们首先为每个类标签分配适当的高维二进制代码,该标签由Hadamard代码随机生成到每个类标签,该标签由Hadamard代码随机生成。随后,采用LSH根据哈希比特减少这种Hadamard码的长度,这可以在线调整预定义的二进制码,并在理论上保证语义相似性。最后,我们考虑随机数据采集的设置,这有利于我们的方法通过随机梯度下降SGD在线有效地学习相应的哈希函数。值得注意的是,所提出的HCOH可以嵌入有监督标签,并且不限于预定义的类别编号。对三种广泛使用的基准测试的广泛实验证明了所提出的方案优于现有技术方法的优点。 |
| Improving Image-Based Localization with Deep Learning: The Impact of the Loss Function Authors Isaac Ronald Ward, M. A. Asim K. Jalwana, Mohammed Bennamoun 这项工作制定了一个新的损失项,可以附加到仅RGB图像定位网络的损失函数,以改善其性能。当从图像回归相机的姿势时使用的常用技术是使用调谐的超参数作为系数将损失表示为位置和旋转误差的线性组合。在这项工作中,我们观察到旋转和位置的变化会相互影响捕获的图像,并且为了提高性能,网络丢失函数应包括一个结合位置和旋转误差的术语。为此,我们设计了一个几何损失项,它使用位置和旋转来考虑预测和地面真实姿势之间的相似性,并用它来增强现有的图像定位网络PoseNet。丢失项简单地附加到已经存在的图像定位网络的损失函数。与类似的管道相比,我们实现了室内场景网络定位精度的提高,中位数和旋转误差降低了9.64和2.99。 |
| Deep AutoEncoder-based Lossy Geometry Compression for Point Clouds Authors Wei Yan, Yiting shao, Shan Liu, Thomas H Li, Zhu Li, Ge Li 点云是一种基本的3D表示,广泛用于现实世界的应用,如自动驾驶。作为一种以复杂性和不规则性为特征的新开发的媒体格式,点云产生了对压缩算法的需求,该压缩算法比现有的编解码器更灵活。最近,自动编码器AE已经在许多视觉分析任务以及图像压缩中显示出它们的有效性,这激励我们在点云压缩中使用它。在本文中,我们提出了一种基于通用自动编码器的架构,用于有损几何点云压缩。据我们所知,它是第一个基于自动编码器的几何压缩编解码器,它直接将点云作为输入而不是体素网格或图像集合。与手工编解码器相比,这种方法可以更快地适应以前看不见的媒体内容和媒体格式,同时实现竞争性能。我们的架构包括基于点网的编码器,统一量化器,熵估计块和非线性合成变换模块。在点云的有损几何压缩中,结果表明,所提出的方法优于MPEG 3DG组在第125次会议上发布的第1类和第3类TMC13的测试模型,并且平均实现了73.15 BD速率增益。 |
| Forecasting Pedestrian Trajectory with Machine-Annotated Training Data Authors Olly Styles, Arun Ross, Victor Sanchez 行人轨迹的可靠预期对于自动驾驶车辆的操作是必不可少的,并且可以显着增强高级驾驶员辅助系统的功能。虽然在行人检测领域取得了重大进展,但由于行人的不可预测性和潜在有用特征的巨大空间,预测行人轨迹仍然是一个具有挑战性的问题。在这项工作中,我们提出了一种深度学习方法,用于使用单个车载摄像头进行行人轨迹预测。已经彻底改变计算机视觉其他领域的深度学习模型在轨迹预测方面的应用有限,部分原因是由于缺乏丰富的注释训练数据。我们通过引入可扩展的机器注释方案来解决缺少训练数据的问题,该方案使我们的模型能够使用大型数据集进行训练而无需人工注释。此外,我们提出动态轨迹预测器DTP,这是一种预测未来一秒钟的行人轨迹的模型。 DTP使用人工和机器注释数据进行训练,并预测线性模型未捕获的动态运动。实验评估证实了所提出模型的好处。 |
| What Do Single-view 3D Reconstruction Networks Learn? Authors Maxim Tatarchenko, Stephan R. Richter, Ren Ranftl, Zhuwen Li, Vladlen Koltun, Thomas Brox 用于单视图对象重建的卷积网络已经显示出令人印象深刻的性能并且已经成为研究的热门主题。所有现有技术通过具有编码器解码器网络的想法而联合,该编码器解码器网络执行关于输出空间的3D结构的非平凡推理。在这项工作中,我们设置了两种分别执行图像分类和检索的替代方法。这些简单的基线在质量和数量上都比现有技术方法产生更好的结果。我们示出编码器解码器方法在统计上与这些基线无法区分,因此指示单视图对象重建中的现有技术实际上不执行重建而是图像分类。我们确定了引发这种行为的流行实验程序的各个方面,并讨论了改善当前研究状态的方法。 |
| Learning Loss for Active Learning Authors Donggeun Yoo, In So Kweon 随着更多注释数据,深度神经网络的性能得到改善。问题是注释的预算是有限的。对此的一个解决方案是主动学习,其中模型要求人们注释其认为不确定的数据。已经提出了各种最近的方法来将主动学习应用于深度网络,但是大多数方法要么针对其目标任务而设计,要么对于大型网络而言计算效率低。在本文中,我们提出了一种新颖的主动学习方法,该方法简单但与任务无关,并且可以与深度网络一起高效地工作。我们将一个名为损耗预测模块的小参数模块附加到目标网络,并学习它以预测未标记输入的目标损失。然后,该模块可以建议目标模型可能产生错误预测的数据。这种方法与任务无关,因为无论目标任务如何,都可以从单一损失中学习网络。我们通过最近的网络架构,通过图像分类,对象检测和人体姿态估计来严格验证我们的方法。结果表明,我们的方法在任务上始终优于以前的方法。 |
| Seesaw-Net: Convolution Neural Network With Uneven Group Convolution Authors Jintao Zhang 在本文中,我们感兴趣的是提高利用倒置残差结构的卷积神经网络的表示能力。基于倒置残余结构Sandler等人的成功。 2018年和Interleaved Low Rank Group Convolutions Sun et al。 2018年,我们重新思考这两种神经网络结构模式,而不是NAS神经网络搜索方法Zoph和Le 2017 Pham等。 2018年刘等人。 2018b,我们引入了不均匀的点群组卷积,它为设计基本块提供了新的搜索空间,以在表示能力和计算成本之间获得更好的折衷。同时,我们提出了两种新颖的信息流模式,它们可以实现多组卷积层的跨组信息流,有或没有任何信道置换混洗操作。图像分类任务的密集实验表明,我们提出的模型,名为Seesaw Net,以有限的计算和内存成本实现了最先进的SOTA性能。我们的代码将是开源的,并与预先训练的模型一起提供。 |
| S$^\mathbf{4}$L: Self-Supervised Semi-Supervised Learning Authors Xiaohua Zhai, Avital Oliver, Alexander Kolesnikov, Lucas Beyer 这项工作解决了图像分类器的半监督学习问题。我们的主要观点是半监督学习领域可以从快速发展的自我监督视觉表征学习领域中受益。统一这两种方法,我们提出了自监督半监督学习S 4L的框架,并用它来推导出两种新颖的半监督图像分类方法。我们证明了这些方法与仔细调整的基线和现有的半监督学习方法相比的有效性。然后,我们表明S 4L和现有的半监督方法可以联合训练,在半监督的ILSVRC 2012上产生了一种新的最先进的结果,其中有10个标签。 |
| TE141K: Artistic Text Benchmark for Text Effects Transfer Authors Shuai Yang, Wenjing Wang, Jiaying Liu 文本效果是视觉元素的组合,例如轮廓,颜色和文本纹理,可以显着改善其艺术性。尽管文本效果在设计行业中被广泛使用,但它们通常由人类专家创建,因为它们极其复杂,这对于普通用户来说是费力且不实用的。近年来,已经对自动文本效果转移进行了一些努力,然而,缺乏数据限制了转移模型的能力。为了解决这个问题,我们引入了一个新的文本效果数据集TE141K,总共有141,081个文本效果字形对。我们的数据集由152个专业设计的文本效果组成,在包括英文字母,汉字,阿拉伯数字等字形上呈现。据我们所知,这是迄今为止最大的文本效果传输数据集。基于此数据集,我们提出了一种名为Text Effects Transfer GAN TET GAN的基线方法,该方法支持在一个模型中传输所有152种样式,并可以有效地扩展到新样式。最后,我们进行了全面的比较,其中14种风格转移模型进行了基准测试。实验结果证明了TET GAN在质量和数量上的优越性,并表明我们的数据集是有效和具有挑战性的。 |
| Liver Lesion Segmentation with slice-wise 2D Tiramisu and Tversky loss function Authors Karsten Roth, Tomasz Konopczy ski, J rgen Hesser 目前,病变分割仍由医学专家手动或半自动进行。为了促进这一过程,我们提供了一个全自动的病变分割管道。这项工作提出了一种方法,作为针对ISBI 17和MICCAI 17的LiTS肝肿瘤分割挑战竞赛的一部分,比较CT扫描中肝脏病变的自动化评估方法。通过利用级联,密集连接的2D U网和基于Tversky系数的损耗函数,我们的框架实现了非常好的形状提取,具有高检测灵敏度,在发布时具有竞争性分数。此外,在我们的Tversky丢失中调整超参数可以将网络调整为更高的灵敏度或稳健性。 |
| Intra-frame Object Tracking by Deblatting Authors Jan Kotera, Denys Rozumnyi, Filip roubek, Ji Matas 沿着复杂轨迹高速移动的物体经常出现在视频中,尤其是体育视频。这些物体在单个帧的曝光时间期间经过不可忽略的距离,因此它们在帧中的位置没有很好地限定。由于运动模糊,它们显示为半透明条纹,并且无法通过标准跟踪器可靠地跟踪。我们基于观察到运动模糊与物体的帧内轨迹直接相关,提出了一种称为Deblatting跟踪的新方法。通过解决两个相互交织的反问题,盲目去模糊和图像消光来估计模糊,我们称之为解卷。然后通过拟合分段二次曲线来估计轨迹,该曲线模拟物理上合理的轨迹。结果,跟踪对象被精确定位,具有比传统跟踪器更高的时间分辨率。所提出的TbD跟踪器是在新创建的视频数据集上进行评估的,该视频具有地面实况,由高速摄像机使用新的轨迹IoU度量获得,该度量推广了传统的联盟交叉点并测量帧内轨迹的准确性。所提出的方法在回忆和轨迹准确性方面都优于基线。 |
| Fast and Efficient Zero-Learning Image Fusion Authors Fayez Lahoud, Sabine S sstrunk 我们提出了一种使用预训练神经网络的实时图像融合方法。我们的方法生成包含来自多个源的特征的单个图像。我们首先将图像分解为表示大规模强度变化的基础层,以及包含小规模变化的细节层。我们使用视觉显着性融合基础层,并从预先训练的神经网络中提取深度特征图以融合细节层。我们进行消融研究以分析我们的方法参数,例如分解滤波器,重量构建方法,网络深度和架构。然后,我们验证其在热,医疗和多焦点融合方面的有效性和速度。我们还将其应用于多个图像输入,例如多重曝光序列。实验结果表明,我们的技术在视觉质量,客观评估和运行时效率方面达到了最先进的性能。 |
| Learning Representations for Predicting Future Activities Authors Mohammadreza Zolfaghari, zg n i ek, Syed Mohsin Ali, Farzaneh Mahdisoltani, Can Zhang, Thomas Brox 预见未来是智力的关键因素之一。它涉及对过去和当前环境的理解以及对其可能动态的体面经验。在这项工作中,我们在抽象的活动层面上讨论未来的预测。我们提出了一个网络模块,用于以自我监督的方式学习环境动态的嵌入。为了将未来活动中的含糊不清和高度差异考虑在内,我们使用可以代表多个未来的多假设方案。我们通过对Epic Kitchens and Breakfast数据集的未来活动进行分类来演示该方法。此外,我们生成描述未来活动的字幕 |
| Feature Extraction and Classification Based on Spatial-Spectral ConvLSTM Neural Network for Hyperspectral Images Authors Wen Shuai Hu, Heng Chao Li, Lei Pan, Wei Li, Ran Tao, Qian Du 近年来,深度学习在高光谱图像HSI分类方面取得了很大进展。特别地,长短期记忆LSTM作为一种特殊的深度学习结构,在视频时间维度或HSI频谱维度的长期依赖性建模方面表现出很强的能力。然而,空间信息的丢失使得获得更好的性能变得非常困难。为了解决这个问题,提出了两种新的深度模型,通过首次利用卷积LSTM ConvLSTM来提取更具辨别力的空间光谱特征。通过将局部滑动窗口中的数据块作为每个存储器单元带的输入,LSTM的2D扩展架构被考虑用于构建空间谱ConvLSTM 2 D神经网络SSCL2DNN以模拟谱域中的长程依赖性。 。为了更有效地利用空间和光谱信息来提取更具辨别力的空间光谱特征表示,通过将LSTM扩展到3D版本,进一步提出了空间光谱ConvLSTM 3D神经网络SSCL3DNN。在三个常用的HSI数据集上进行的实验表明,所提出的深度模型具有一定的竞争优势,并且可以提供比其他现有技术方法更好的分类性能。 |
| D2-Net: A Trainable CNN for Joint Detection and Description of Local Features Authors Mihai Dusmanu, Ignacio Rocco, Tomas Pajdla, Marc Pollefeys, Josef Sivic, Akihiko Torii, Torsten Sattler 在这项工作中,我们解决了在困难的成像条件下找到可靠的像素级对应的问题。我们提出了一种方法,其中单个卷积神经网络起双重作用。它同时是一个密集的特征描述符和一个特征检测器。通过将检测推迟到后期阶段,基于早期检测低水平结构,获得的关键点比其传统对应点更稳定。我们表明,可以使用从容易获得的大规模SfM重建中提取的像素对应来训练该模型,而无需任何进一步的注释。所提出的方法在困难的亚琛日夜间定位数据集和InLoc室内定位基准测试中获得最先进的性能,以及用于图像匹配和3D重建的其他基准的竞争性能。 |
| Cycle-IR: Deep Cyclic Image Retargeting Authors Weimin Tan, Bo Yan, Chumin Lin, Xuejing Niu 由于摆脱了手工制作表达的限制,监督深度学习技术在各个领域取得了巨大成功。然而,大多数先前的图像重定目标算法仍然采用固定的设计原则,例如使用梯度图或手工制作的特征来计算显着性图,这不可避免地限制了它的一般性。深度学习技术可能有助于解决这个问题,但具有挑战性的问题是我们需要构建一个大规模的图像重定向数据集,用于深度重定向模型的训练。然而,构建这样的数据集需要巨大的人力。 |
| Embedding Human Knowledge in Deep Neural Network via Attention Map Authors Masahiro Mitsuhara, Hiroshi Fukui, Yusuke Sakashita, Takanori Ogata, Tsubasa Hirakawa, Takayoshi Yamashita, Hironobu Fujiyoshi 循环中的人HITL将人类知识引入机器学习,已用于细粒度识别,以根据局部特征的差异来估计类别。传统的HITL方法已成功应用于非深度机器学习,但由于模型参数数量众多,很难将其用于深度学习。为了解决这个问题,在本文中,我们建议使用注意分支网络ABN,它是一种视觉解释模型。 ABN将注意力映射用于视觉解释到注意机制。首先,我们根据人类知识手动修改从ABN获得的注意力图。然后,我们将修改后的注意力映射用于使ABN能够调整识别分数的注意机制。其次,为了将HITL应用于深度学习,我们提出了一种使用修改后的注意力图的微调方法。我们的微调通过使用从ABN输出的关注图计算的训练损失以及修改的注意力图来更新ABN的注意力和感知分支。该微调使得ABN能够输出与人类知识相对应的关注图。此外,我们使用更新的注意力图及其嵌入的人类知识作为感知分支的注意机制和推理,从而提高了ABN的性能。使用ImageNet数据集,CUB 200 2010数据集和IDRiD的实验结果表明,我们的方法在视觉解释方面阐明了注意力图,并提高了分类性能。 |
| Grand Challenge of 106-Point Facial Landmark Localization Authors Yinglu Liu, Hao Shen, Yue Si, Xiaobo Wang, Xiangyu Zhu, Hailin Shi, Zhibin Hong, Hanqi Guo, Ziyuan Guo, Yanqin Chen, Bi Li, Teng Xi, Jun Yu, Haonian Xie, Guochen Xie, Mengyan Li, Qing Lu, Zengfu Wang, Shenqi Lai, Zhenhua Chai, Xiaoming Wei 面部地标定位是众多面部相关应用中非常关键的一步,例如面部识别,面部姿势估计,面部图像合成等。然而,之前的面部地标定位竞赛,即300 W,300 VW和Menpo挑战旨在预测68点标志,这些标志无法描绘面部组件的结构。为了克服这个问题,我们构建了一个具有挑战性的数据集,名为JD landmark。每个图像都用106个点标记手动注释。该数据集涵盖了姿势和表情的大变化,这给预测准确的地标带来了很多困难。我们在此数据集上与IEEE国际多媒体和博览会ICME 2019一起举办了一场106点的面部地标本地化竞赛1。本次比赛的目的是发现有效且强大的面部地标本地化方法。 |
| Multi-Person Pose Estimation with Enhanced Channel-wise and Spatial Information Authors Kai Su, Dongdong Yu, Zhenqi Xu, Xin Geng, Changhu Wang 多人姿势估计是计算机视觉中的一个重要但具有挑战性的问题。尽管当前的方法通过融合多尺度特征图而取得了显着进步,但是他们很少关注增强特征图的频道和空间信息。在本文中,我们提出了两个新的模块来执行多人姿势估计的信息增强。首先,提出了一种信道混洗模块CSM,对不同级别的特征映射采用信道混洗操作,促进金字塔特征映射之间的跨信道信息通信。其次,空间,通道明智的注意残留瓶颈SCARB旨在通过注意机制来增强原始残差单元,在空间和通道明智的上下文中自适应地突出特征图的信息。我们提出的模块的有效性在COCO关键点基准上进行评估,实验结果表明我们的方法达到了最先进的结果。 |
| DistillHash: Unsupervised Deep Hashing by Distilling Data Pairs Authors Erkun Yang, Tongliang Liu, Cheng Deng, Wei Liu, Dacheng Tao 由于高存储和搜索效率,散列已经成为大规模相似性搜索的普遍现象。特别是,深度散列方法极大地提高了监督场景下的搜索性能。相反,由于缺乏可靠的监督相似性信号,无监督的深度散列模型很难实现令人满意的性能。为了解决这个问题,我们提出了一种新的深度无监督散列模型,称为DistillHash,它可以学习由具有置信相似性信号的数据对组成的蒸馏数据集。具体地,我们研究了从局部结构学习的初始噪声相似性信号与由贝叶斯最优分类器分配的语义相似性标签之间的关系。我们表明,在一个温和的假设下,一些数据对,其标签与贝叶斯最优分类器指定的标签一致,可以被潜在地提炼出来。受此事实的启发,我们设计了一种简单而有效的策略来自动提取数据对,并进一步采用贝叶斯学习框架从蒸馏数据集中学习哈希函数。三个广泛使用的基准数据集的广泛实验结果表明,提出的DistillHash始终如一地完成了最先进的搜索性能。 |
| Two-Stage Convolutional Neural Network Architecture for Lung Nodule Detection Authors Haichao Cao, Hong Liu, Enmin Song, Guangzhi Ma, Xiangyang Xu, Renchao Jin, Tengying Liu, Chih Cheng Hung 早期发现肺癌是提高患者生存率的有效方法。在计算机断层扫描CT图像中准确检测肺结节是诊断肺癌的关键步骤。然而,由于肺结节的异质性和周围环境的复杂性,强大的结节检测一直是一项具有挑战性的任务。在这项研究中,我们提出了一种用于肺结节检测的两阶段卷积神经网络TSCNN架构。第一阶段的CNN架构基于改进的UNet分段网络,以建立肺结节的初始检测。同时,为了在不引入过多假阳性结节的情况下获得高召回率,我们提出了一种新的抽样策略,并根据所提出的级联预测方法使用离线硬挖掘思想进行训练和预测。第二阶段的CNN架构基于所提出的双池结构,其被构建到三个3D CNN分类网络中以用于误报减少。由于网络训练需要大量的训练数据,我们采用基于随机掩码的数据增强方法。此外,我们通过集成学习提高了误报模型的泛化能力。所提出的方法已经在LUNA数据集上进行了实验验证。实验结果表明,所提出的TSCNN架构可以获得有竞争力的检测性能。 |
| ROSA: Robust Salient Object Detection against Adversarial Attacks Authors Haofeng Li, Guanbin Li, Yizhou Yu 最近,由于深度卷积神经网络可以获得强大的图像特征,因此显着物体检测已经见证了显着的改进。特别地,现有技术的显着对象检测方法从完全基于卷积网络FCN的框架获得高精度和高效率,所述框架从端到端训练并预测像素方式标签。然而,这种框架遭受对抗性攻击,这种攻击通过向输入图像添加准不可察觉的噪声来混淆神经网络而不改变由人类对象注释的地面实况。据我们所知,本文是第一个对显着对象检测模型进行成功的对抗性攻击并验证对抗性样本对广泛的现有方法有效的方法。此外,本文提出了一种新颖的端到端可训练框架,以增强任意基于FCN的显着对象检测模型对抗对抗性攻击的鲁棒性。所提出的框架采用了一种新颖的思想,即首先引入一些新的通用噪声来破坏对抗性扰动,然后学习用引入的噪声预测输入图像的显着性图。具体而言,我们提出的方法包括分段屏蔽组件,其保留边界并破坏精细的对抗性噪声模式和环境感知恢复组件,其通过全局对比度建模来细化显着性图。实验结果表明,我们提出的框架可以显着提高一系列数据集中最先进模型的性能。 |
| Frustratingly Easy Person Re-Identification: Generalizing Person Re-ID in Practice Authors Jieru Jia, Qiuqi Ruan, Timothy M. Hospedales 当代人识别Re ID方法通常需要在训练期间从部署摄像机网络访问数据以便表现良好。这是因为在一个数据集上训练的当代Re ID模型由于数据集之间的域移位而不能推广到其他相机网络。此要求通常是在实际安全性或商业应用中部署Re ID系统的瓶颈,因为可能无法提前收集这些数据或者对其进行注释成本过高。本文通过提出一个简单的域可泛化DG人员识别基线来缓解这个问题。也就是说,从一组源域中学习Re ID模型,该模型适用于开箱即用的未见数据集,无需任何模型更新。具体来说,我们发现Re ID中的域差异是由于数据集之间的样式和内容差异造成的,并且演示了适当的实例和特征规范化可以减轻Deep Re ID模型中的大部分域转换。早期层中的实例规范化IN过滤掉样式统计变化,深层中的特征规范化FN能够进一步消除内容统计中的差异。与现代替代方案相比,这种方法实施起来非常简单,同时可以更快地进行训练和测试,从而使其成为在实践中实施Re ID的极有价值的基准。通过几行代码,它分别在VIPeR,PRID,GRID和i LIDS基准测试中将秩1 Re ID精度提高了11.7,28.9,10.1和6.3。源代码将可用。 |
| Deep Learning Acceleration Techniques for Real Time Mobile Vision Applications Authors Gael Kamdem De Teyou 深度学习DL已成为人工智能AI的关键技术。它是一种从复杂数据中自动提取高级特征的强大技术,可用于计算机视觉,自然语言处理,网络安全,通信等应用程序。对于计算机视觉的特定情况,已经提出了几种算法,例如实时视频中的对象检测,并且它们在桌面GPU和分布式计算平台上运行良好。然而,这些算法对于移动和嵌入式视觉应用仍然很重要。智能便携设备和新兴5G网络的快速普及正在移动环境中引入新的智能多媒体应用。因此,在移动环境中实现深度神经网络的可能性吸引了许多研究人员。本文介绍了新兴的深度学习加速技术,可以随时随地将实时视觉识别交付给最终用户。 |
| PPGNet: Learning Point-Pair Graph for Line Segment Detection Authors Ziheng Zhang, Zhengxin Li, Ning Bi, Jia Zheng, Jinlei Wang, Kun Huang, Weixin Luo, Yanyu Xu, Shenghua Gao 在本文中,我们提出了一种新的框架来检测人造环境中的线段。具体而言,我们建议用简单的图形描述它们之间的连接点,线段和关系,这比现有线段检测方法中使用的端点表示更具结构性和信息性。为了从图像中提取线段图,我们进一步介绍了PPGNet,一种卷积神经网络,可直接从图像中推断图形。我们在已发布的基准测试中评估我们的方法,包括York Urban和Wireframe数据集。结果表明,我们的方法达到了令人满意的性能,并在所有基准上得到了很好的推广。我们的工作源代码可在网址找到 |
| A Dual Path ModelWith Adaptive Attention For Vehicle Re-Identification Authors Pirazh Khorramshahi, Amit Kumar, Neehar Peri, Sai Saketh Rambhatla, Jun Cheng Chen, Rama Chellappa 近年来,注意力模型已广泛用于人员和车辆识别。大多数重新识别方法旨在将注意力集中在关键点位置。但是,根据方向,每个关键点的贡献会有所不同。在本文中,我们提出了一种新的车辆重新识别AAVER双路径自适应注意模型。全局外观路径捕获宏观车辆特征,而定向条件部分外观路径通过关注最信息的关键点来学习捕捉局部判别特征。通过大量实验,我们证明了所提出的AAVER方法能够在无约束的情景中准确地识别车辆,在挑战性数据集VeRi 776上产生最先进的结果。作为副产品,所提出的系统还能够准确地预测车辆钥匙。在现有技术水平上显示出超过7的改进。 |
| Weakly Labeling the Antarctic: The Penguin Colony Case Authors Hieu Le, Bento Gon alves, Dimitris Samaras, Heather Lynch 南极企鹅是重要的生态指标,特别是在气候变化面前。在这项工作中,我们提出了一个基于深度学习的模型,用于高分辨率卫星图像中广告谎言企鹅殖民地的语义分割。为了训练我们的分割模型,我们利用Penguin Colony Dataset这个独特的数据集,其中包含来自南极洲193个Ad lie企鹅群的2044个地理参考裁剪图像。面对像素级注释掩模的稀缺性,我们提出了一种弱监督框架,可以有效地从弱标签中学习分割模型。我们使用分类网络来过滤掉不适合分段网络的数据。基于平均激活,该分割网络利用特定的损失函数进行训练,以有效地从具有弱注释标签的数据中学习。我们的实验表明,添加弱注释的训练样例显着提高了分割性能,在企鹅群数据集上将平均交叉联盟从42.3增加到60.0。 |
| Deep Closest Point: Learning Representations for Point Cloud Registration Authors Yue Wang, Justin M. Solomon 点云注册是应用于机器人,医学成像和其他应用的计算机视觉的关键问题。这个问题涉及找到从一个点云到另一个点的刚性转换,以便它们对齐。迭代最近点ICP及其变体为此任务提供了简单且易于实现的迭代方法,但这些算法可以收敛到虚假的局部最优。为了解决ICP管道中的局部最优和其他困难,我们提出了一种基于学习的方法,名为Deep Closest Point DCP,受近期计算机视觉和自然语言处理技术的启发。我们的模型包括三个部分:点云嵌入网络,基于注意的模块与指针生成层相结合,近似组合匹配,以及可微分奇异值分解SVD层,以提取最终的刚性变换。我们在ModelNet40数据集上端到端地训练我们的模型,并在几个设置中显示它比ICP更好,其变体例如Go ICP,FGR和最近提出的基于学习的方法PointNetLK。除了提供最先进的配准技术外,我们还评估了我们学到的特征转移到看不见的物体的适用性。我们还对我们的学习模型进行初步分析,以帮助了解特定领域和/或全局特征是否有助于严格注册。 |
| Advancements in Image Classification using Convolutional Neural Network Authors Farhana Sultana, A. Sufian, Paramartha Dutta 卷积神经网络CNN是图像分类任务的最新技术。在这里,我们简要讨论了CNN的不同组件。在本文中,我们已经解释了用于图像分类的不同CNN架构。通过本文,我们展示了从LeNet 5到最新SENet模型的CNN的进步。我们已经讨论了每个模型的模型描述和培训细节。我们还对这些模型进行了比较。 |
| Handheld Multi-Frame Super-Resolution Authors Bartlomiej Wronski, Ignacio Garcia Dorado, Manfred Ernst, Damien Kelly, Michael Krainin, Chia Kai Liang, Marc Levoy, Peyman Milanfar 与DSLR相机相比,智能手机相机具有更小的传感器,这限制了它们的空间分辨率更小的孔径,这限制了它们的聚光能力和更小的像素,这降低了它们的信噪比。使用滤色器阵列CFA需要去马赛克,这进一步降低了分辨率。在本文中,我们用单帧和突发摄影管道取代传统的去马赛克,采用多帧超分辨率算法,直接从一连串CFA原始图像创建完整的RGB图像。我们利用手持摄影中典型的自然手震,获得一小段偏移的原始帧。然后对齐并合并这些帧以形成在每个像素位置处具有红色,绿色和蓝色值的单个图像。该方法不包括明确的去马赛克步骤,用于增加图像分辨率和提高信噪比。我们的算法对于具有挑战性的场景条件局部运动,遮挡或场景变化具有鲁棒性。它在大规模生产的手机上每1200万像素RAW输入突发帧运行100毫秒。具体来说,该算法是Super Res Zoom功能的基础,以及Night Sight模式下的默认合并方法,无论是否在Google的旗舰手机上进行缩放。 |
| The Effect of Network Width on Stochastic Gradient Descent and Generalization: an Empirical Study Authors Daniel S. Park, Jascha Sohl Dickstein, Quoc V. Le, Samuel L. Smith 我们研究了随机梯度下降所发现的最终参数如何受到过度参数化的影响。我们通过增加基础网络中的通道数来生成模型族,然后执行大型超参数搜索以研究测试错误如何取决于学习速率,批量大小和网络宽度。我们发现最佳SGD超参数由归一化噪声标度确定,标准化噪声标度是批量大小,学习速率和初始化条件的函数。在没有批量归一化的情况下,最佳归一化噪声标度与宽度成正比。更宽的网络具有更高的最佳噪声标度,也可以实现更高的测试精度。这些观察结果适用于MLP,ConvNets和ResNets,以及两种不同的参数化方案Standard和NTK。我们观察到ResNets的批量标准化的类似趋势。令人惊讶的是,由于最大的稳定学习速率是有界的,因此随着宽度增加,与最佳归一化噪声标度一致的最大批量大小减小。 |
| Differentiable Approximation Bridges For Training Networks Containing Non-Differentiable Functions Authors Jason Ramapuram, Russ Webb 现代神经网络训练依赖于分段子微分函数,以便使用反向推进来有效地计算梯度。在这项工作中,我们引入了一种新方法,允许在深度神经网络的中间层进行不可微函数。我们通过引入可微分近似桥DAB神经网络来实现这一点,该神经网络提供了对非可微函数梯度的平滑近似。我们提出了强大的实证结果,在三个不同的领域进行了600多次实验,无监督图像表示学习,图像分类和序列分类,以证明我们提出的方法提高了现有技术的性能。我们证明在无监督图像表示学习中利用非可微函数可以将重建质量和后线性可分性提高10倍。在具有非线性排序的图像分类设置中,我们还观察到神经序列分类中的精确度提高77和针对直通估计器3的改进。这项工作使得能够使用以前在神经网络中不可用的功能。 |
| A Novel Adaptive Kernel for the RBF Neural Networks Authors Shujaat Khan, Imran Naseem, Roberto Togneri, Mohammed Bennamoun 在本文中,我们提出了一种新的径向基函数RBF神经网络自适应核。所提出的核自适应地融合欧几里德和余弦距离度量以利用两者的往复特性。所提出的框架使用梯度下降方法动态地调整参与内核的权重,从而减轻对预定权重的需要。所提出的方法在三个主要估计问题即非线性系统识别,模式分类和函数逼近方面表现优于内核的手动融合。 |
| MAP Inference via L2-Sphere Linear Program Reformulation Authors Baoyuan Wu, Li Shen, Bernard Ghanem, Tong Zhang 最大后验MAP推断是图形模型的重要任务。由于实际模型中变量之间的复杂依赖性,找到MAP推理的精确解决方案通常是难以处理的。因此,已经开发了许多近似方法,其中基于线性编程LP弛豫的方法显示出有希望的性能。然而,LP松弛的一个主要缺点是可以提供分数溶液。在这项工作中,我们建议对原始MAP推理问题进行连续但等效的重新设计,而不是提出更严格的放松,称为LS LP。我们将L2球体约束添加到原始LP松弛上,导致与局部边缘多面体相交的空间相当于所有有效整数标签配置的空间。因此,LS LP等同于原始MAP推理问题。我们提出了乘法器ADMM算法的扰动交替方向方法,通过在目标函数和约束上添加足够小的扰动ε来优化LS LP问题。我们证明了扰动的ADMM算法全局收敛于LS LP问题的epsilon Karush Kuhn Tucker epsilon KKT点。还将分析收敛率。来自概率推理挑战PIC 2011和OpenGM 2的若干基准数据集的实验显示了我们提出的方法对现有技术MAP推理方法的竞争性能。 |
| Adversarial Image Translation: Unrestricted Adversarial Examples in Face Recognition Systems Authors Kazuya Kakizaki, Kosuke Yoshida 由于深度神经网络DNN的最新进展,人脸识别系统在大量人脸图像的分类中实现了高精度。然而,最近的研究表明,DNN可能容易受到对抗性的影响,并引起人们对人脸识别系统稳健性的担忧。特别是不受小扰动限制的对抗性例子可能是更严重的风险,因为传统的认证防御可能对它们无效。为了揭示人脸识别系统对这种类型的对抗性示例的脆弱性,我们提出了一种灵活有效的方法,使用图像转换技术生成无限制的对抗性示例。我们的方法使我们能够将源转换为任何具有大扰动的所需面部外观,从而可以欺骗目标人脸识别系统。我们通过实验证明,我们的方法分别在白色和黑色框设置下实现了大约90和30次攻击成功率。我们还说明,我们生成的图像在感知上是真实的并且保持个人身份,而扰动大到足以击败经过认证的防御。 |
| Learning to Evolve Authors Jan Schuchardt, Vladimir Golkov, Daniel Cremers 进化和学习是生活为了生存和超越限制而适应的两个基本机制。这些生物现象启发了成功的计算方法,如进化算法和深度学习。进化依赖于随机突变和随机遗传重组。在这里,我们表明学习进化,即学习比随机更好地变异和重组,改善了每代健康增加的进化结果,甚至在可达到的适应性方面。我们使用深度强化学习来学习动态调整进化算法的策略以适应不同的环境。我们的方法在组合和连续优化问题上优于经典的进化算法。 |
| Chinese Abs From Machine Translation |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}