
【今日CV 计算机视觉论文速览 第118期】Tue, 21 May 2019
今日CS.CV 计算机视觉论文速览
Tue, 21 May 2019
Totally 57 papers
👉上期速览✈更多精彩请移步主页

Interesting:
📚学习人像透视畸变消除问题, 提出了一种能够消除近距离人像摄影畸变的方法,通过预测每个像素需要移动的纠正流图来避免了对于3D人脸建模的过程,同时还补充了透视变换中确实的细节,可广泛应用于人脸重建、三维重建、消除相机畸变,并建立了透视变化数据集。(from 南加州大学 Pinscreen)
方案的流程图,其中包含三个步骤,相机参数估计用于得到校正流,随后得到仿射变化后图像并补全,最后融合合成去畸变人脸。
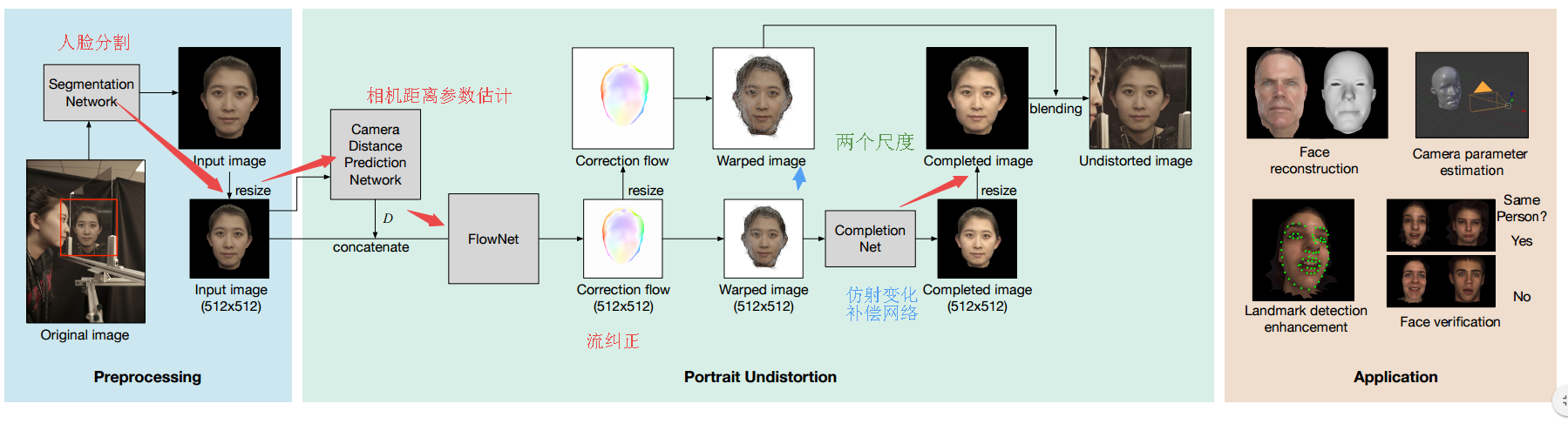
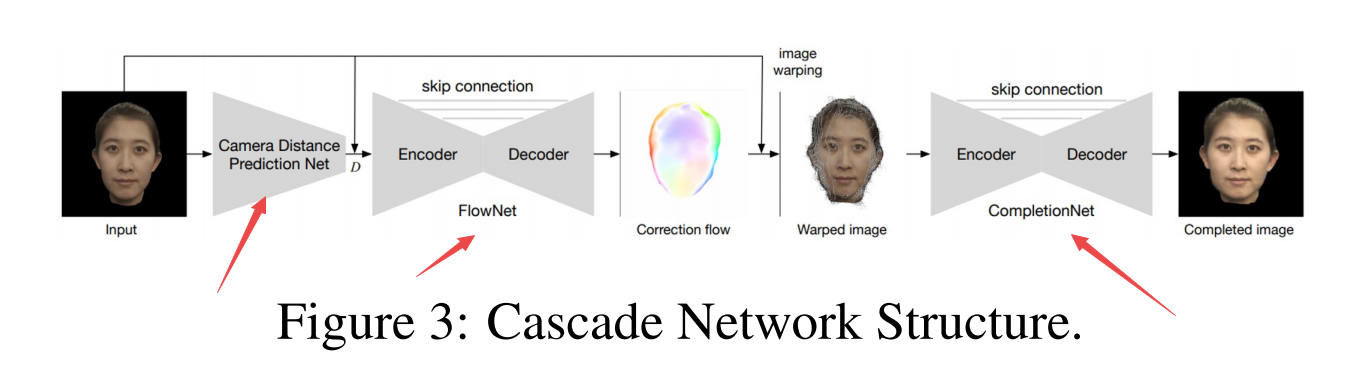
模型如下:
不同焦距下的人脸和去畸变的效果:


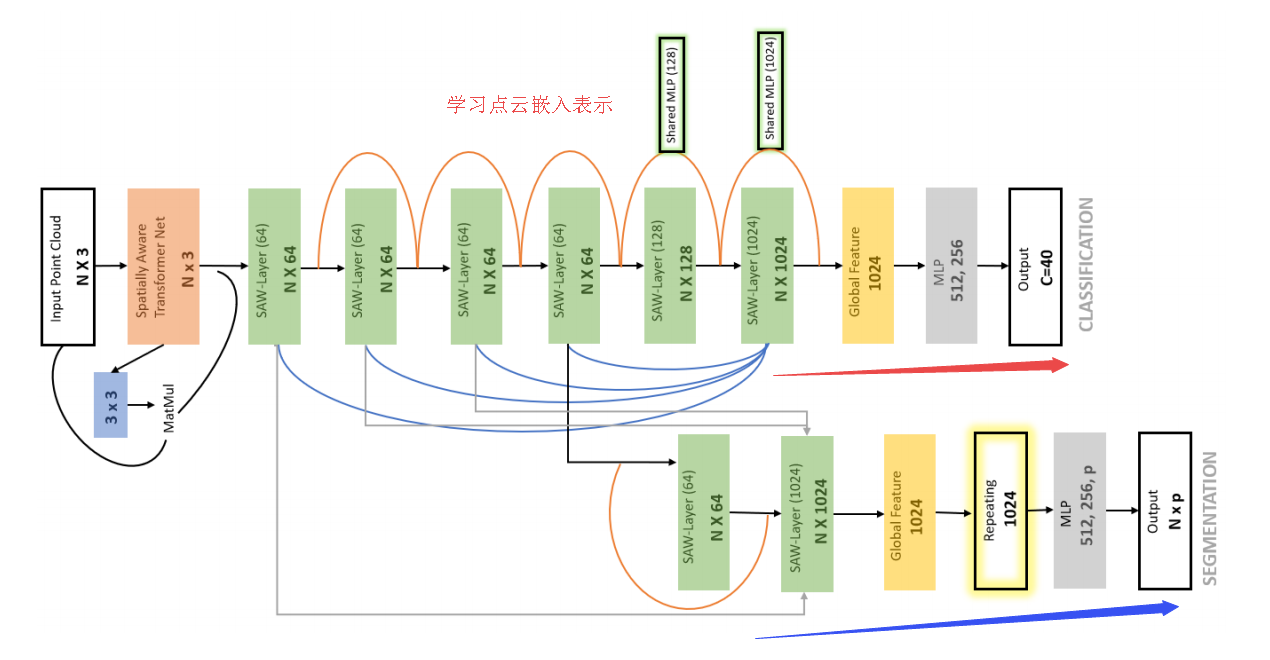
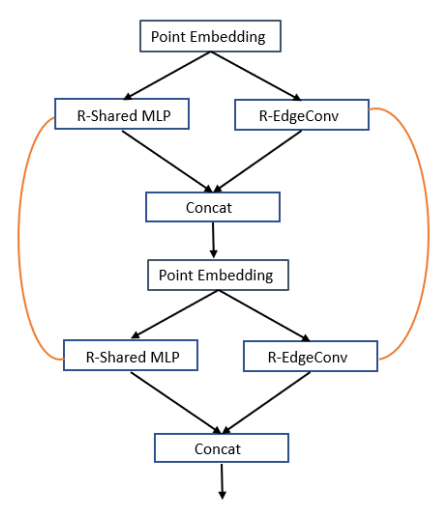
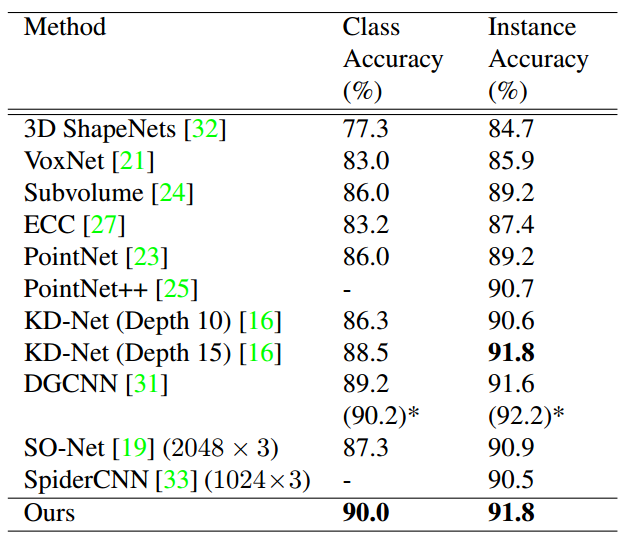
📚SAWNet部分注意力的3D点云处理, 引入了可以结合全局与局域信息的网络层嵌入,并利用残差连接提高层间信息的传递。(from 约克大学)
网络结构及SAW层间的传递:
分类和分割方法的比较结果:
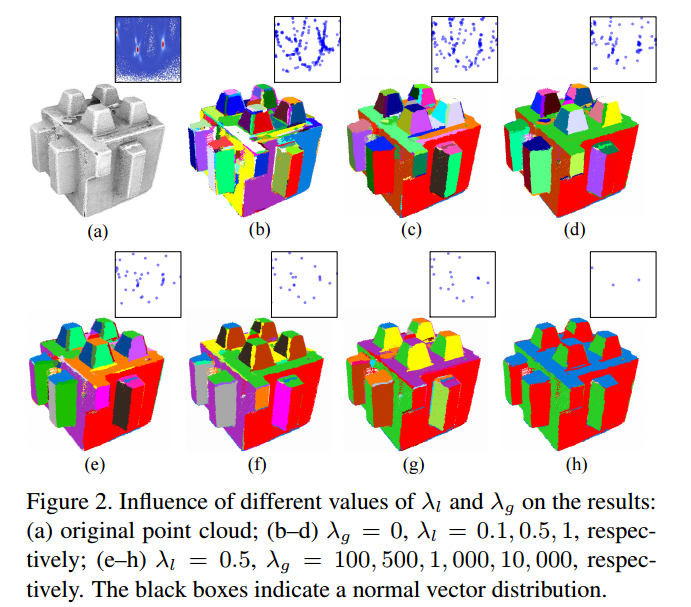
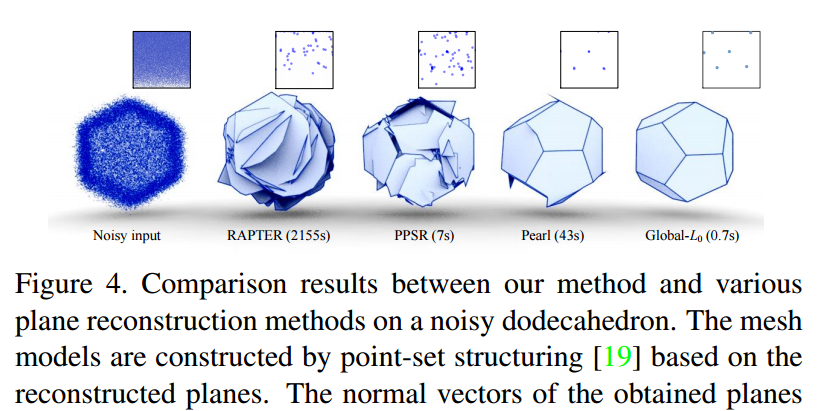
📚快速规则约束的平面重建RCPR, 基于曼哈顿平面约束提出了快速高效的平面重建算法,利用隐含角度约束代替了原始的角度约束,引入了参数限制不同法向量的个数,提出了方向限制模型DC。(from 集美大学厦门大学)
一些平面重建的结果:

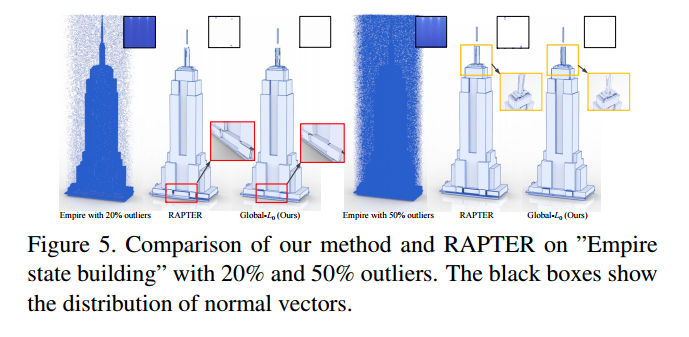
不同方法的比较:
dataset:UZH IfI (12 data), UZH Irchel (10 data), ETH (18 data), Rooms detection datasets (9 data), and Full 3D (8 data).
https://www.ifi.uzh.ch/en/vmml/research/datasets.html
📚DeepInspect, 模型对某些类别有混淆和偏见造成了分类器的错误和不稳定。现有的DNN方法主要在于验证每张图像的缺失了对于group级别的评测。研究人员设计了DeepInspect来进行白盒测试,检测模型的混淆和偏见(from 哥伦比亚大学)
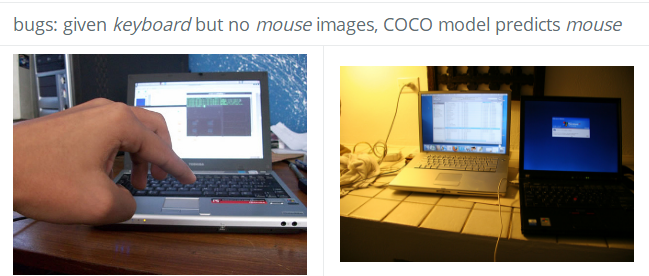
code:https://deeplearninginspect.github.io/DeepInspect/
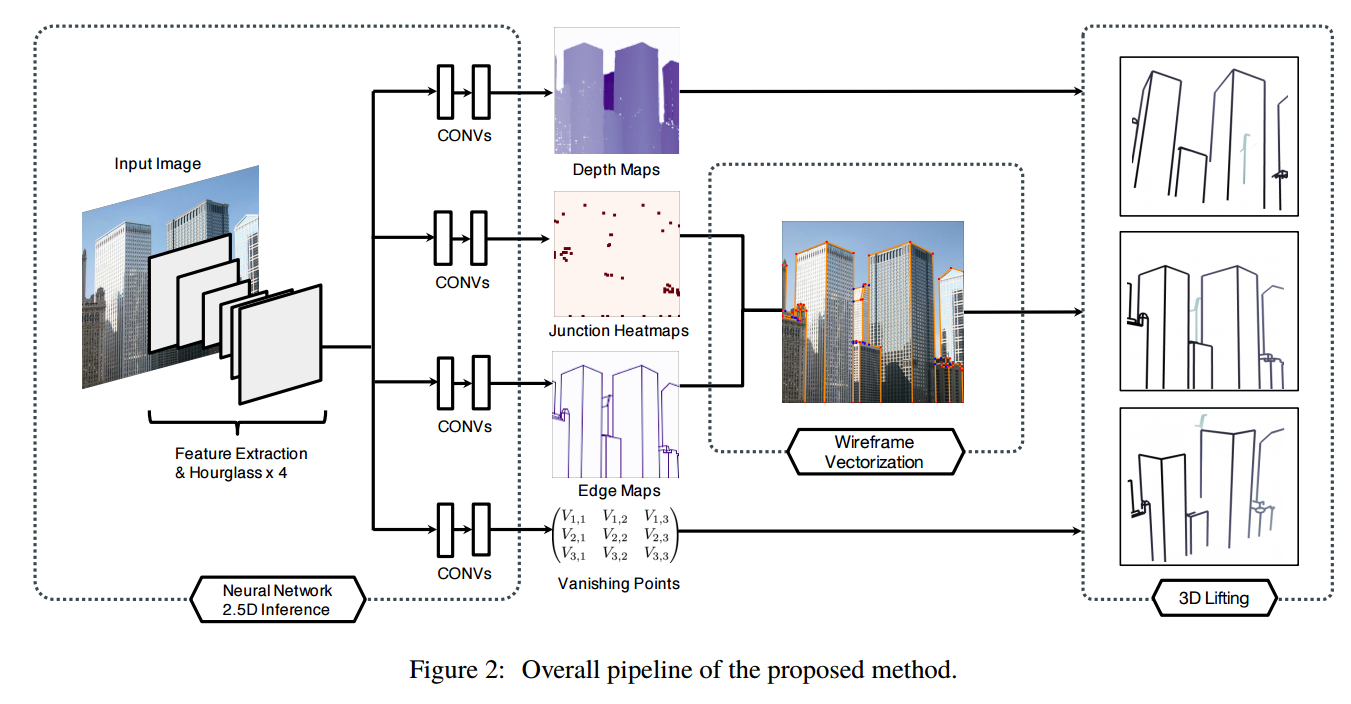
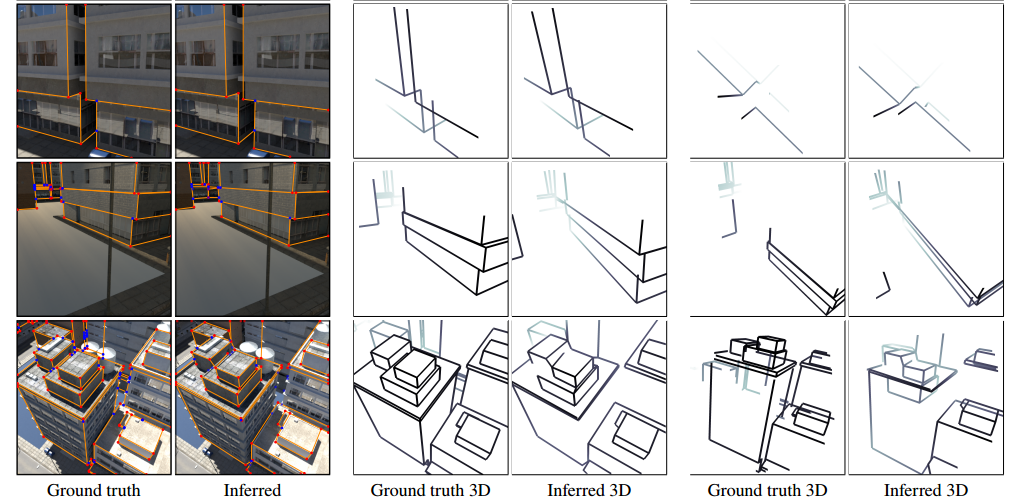
📚单图像构建建筑物外框线, 同时检测显著性点和外框线,并预测消失点的深度,这种方法更为简单和通用,最后生成向量表示的紧致3D线框模型可用于AR与CAD中(from 伯克利 adobe)
一些最终的检测结果:
基于SceneCity合成数据,并基于MegaDepth真实数据
ref:https://github.com/Microsoft/MixedRealityToolkit-Unity
video:https://www.youtube.com/watch?v=l3sUtddPJPY
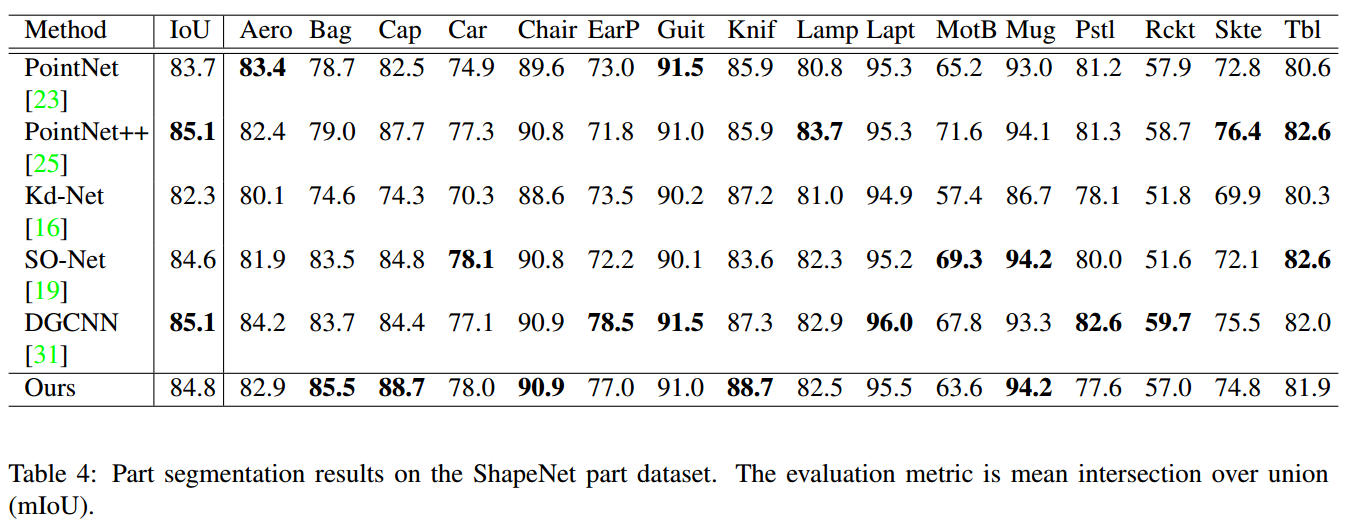
📚Parts4Feature从多视角下的部分信息学习三维全局特征, 研究人员提出了一种描述三维外形部分结构的检测基准,关键在于将语义部件的检测能力迁移到了多视角下三维特征的学习中去。(from 清华)
模型由区域部分检测分支和全局特征学习分支构成,共享区域推举模块。
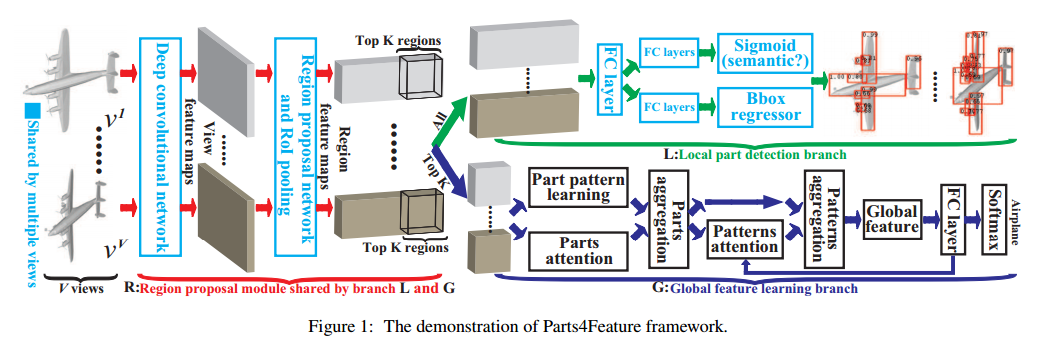
全局特征分支衔接了多个检测到的部分特征并利用多注意力机制实现学习。区域推选使得全局与局部信息得以区分。提出部分分割标注通用语义部分Generally semantic parts(GSP)。
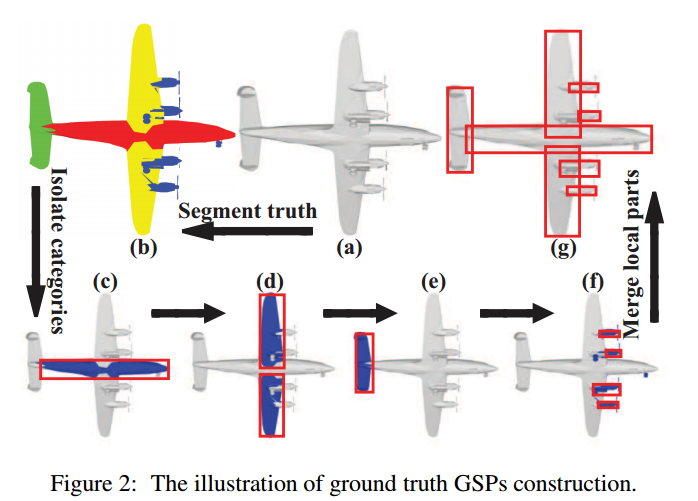
Dataset: ShapeNetCore,Labeled-PSB, and COSEGModelNet10.
ref:
Mesh-based deep learning models
Voxel-based deep learning models.
Deep learning models for point clouds.
View-based deep learning models.
📚PFOD基于正例聚焦的目标检测器, 在目标检测前使用正例聚焦忽视负例渐进传播不完整标签,随后再应用通用目标检测算法。这种策略将mAP实现了大幅提升。(from 微软)
小标签的数据集:

dataset: CARPK Drink35,self-made
政府的大规模免费数据源
📚ChineseFoodNet,大规模中餐食物识别数据集 (from Midea Emerging Technology Center)

dataset:https://sites.google.com/view/chinesefoodnet/
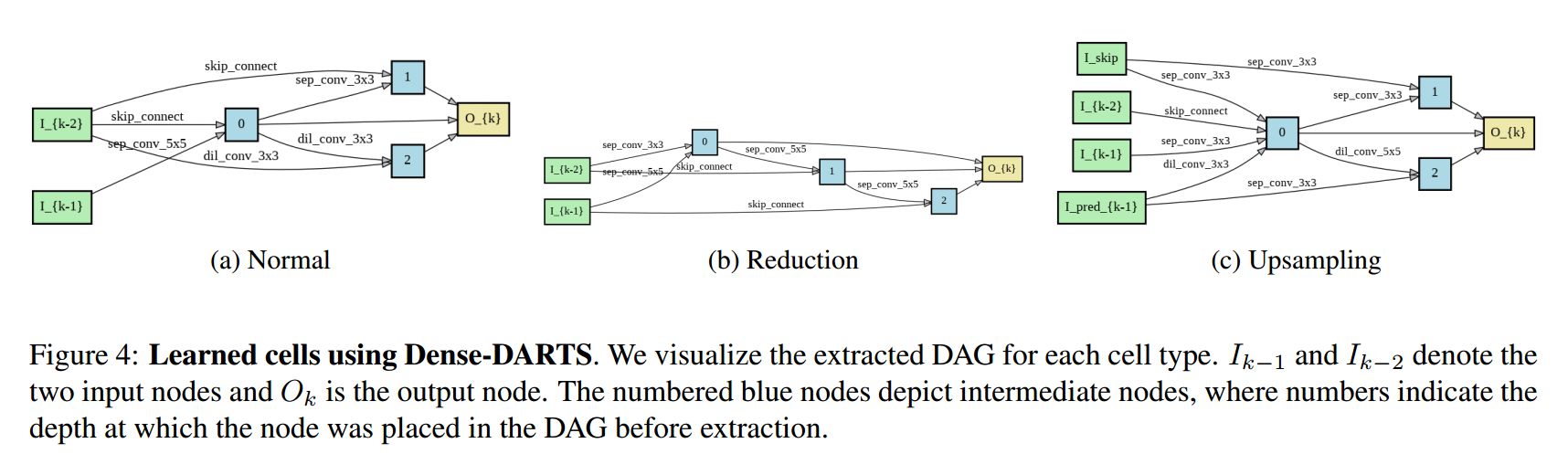
📚****AutoDispNet:基于自动机器学习改善视差估计,将自动机器学习拓展到了大规模的U-Net编码器解码器架构上,基于贝叶斯参数优化器和神经架构搜索得到了改善视差图的效果,同时还不需要大规模的计算集群。 (from 德国弗莱堡大学)
待搜索的模块:
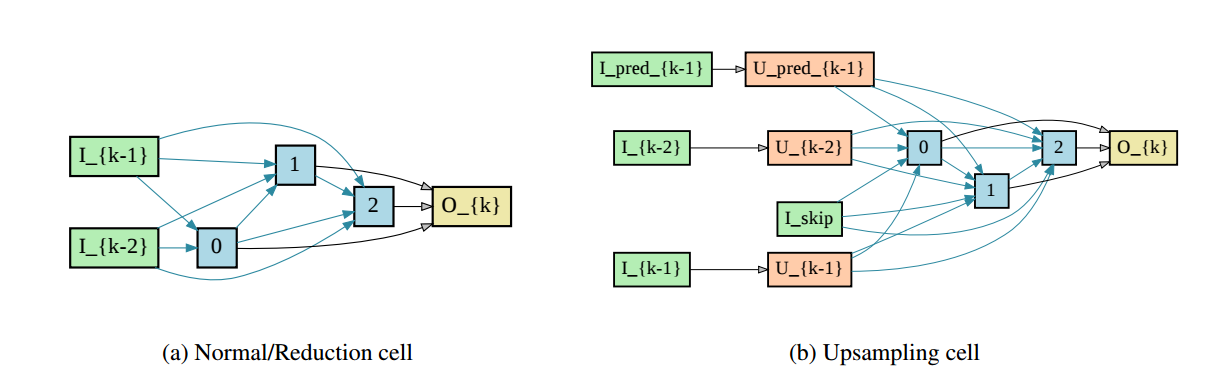
稠密视差搜索模块和自动得到的网络模型:
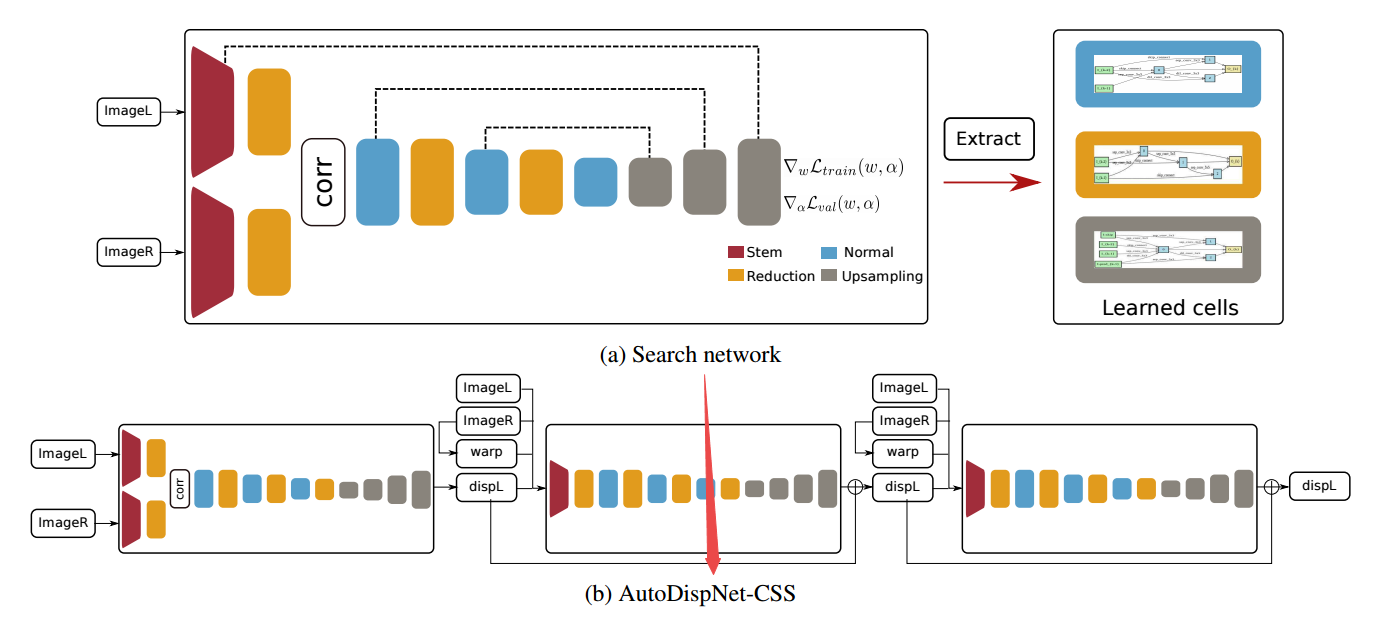
学习到的结构:
得到的一个结果:

视差数据集:FlyingThings3D, https://lmb.informatik.uni-freiburg.de/resources/
3D creation suite Blender
ref:立体匹配网络:https://github.com/JiaRenChang/PSMNet
Disparity, Optical Flow, and Scene Flow Estimation
Practical Deep Stereo
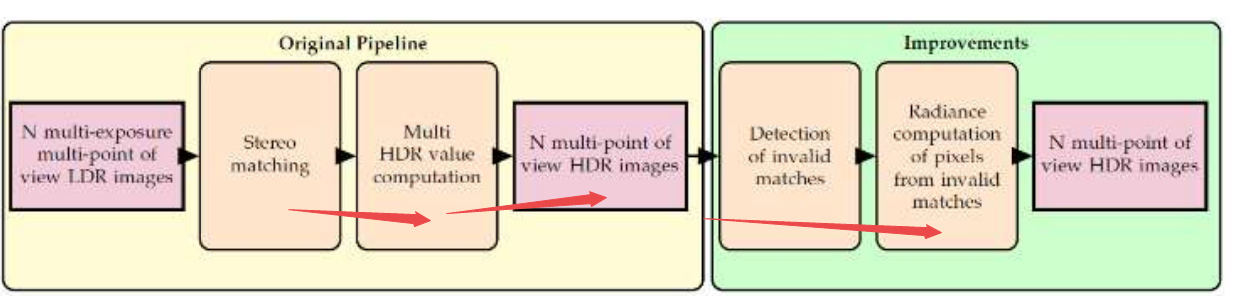
📚基于视差的图像HDR, 从多张视图中得到HDR,利用启发式的方法实现图像高动态范围。(from University of Reims Champagne-Ardenne )
conference:DISP 2019 disp-conference.org - Home,The International Conference on Digital Image & Signal Processing
dataset:http://vision.middlebury.edu/stereo/data/
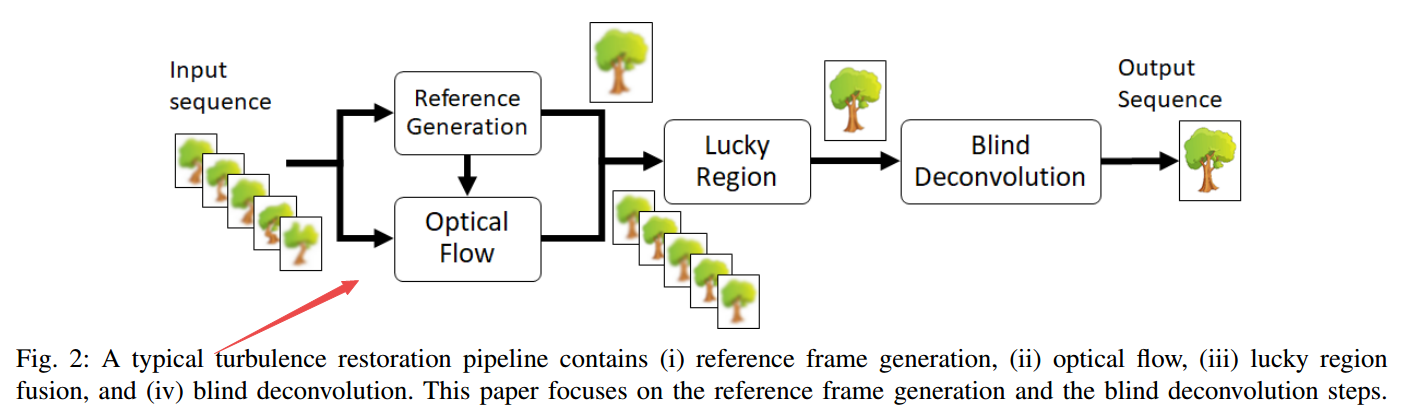
📚消除大气扰动对成像造成的影响, 研究人员通过分析了参考帧的生成和盲卷积步骤,通过使用大误差利用中的工具严格证明了需要回复可靠图像的最少帧数。讨论了位置扰动模型的潜在缺陷和空时非局域权重评价方法生成参考。最后利用数据驱动的方法实现盲卷积,基于点扩散函数的分布。(from 普渡)
文末有推导,附录
📚基于人脸关键点检测老年人痴呆, (from Georgian Partners Inc )
Methods (and models) were used in ouranalysis: Active Appearance Models (AAM) [11], ConstrainedLocal Neural Field (CLNF) [5], Coarse-to-FineShape Searching (CFSS) [35], Face Alignment Network(FAN) [8], Mnemonic Descent Method (MDM) [32], andPosition Map Regression Network (PRNet) [14].
Six datasets: Helen [23], AFW [28], LFPW [7],MENPO Profile [34], UNBC-McMaster Pain Archive [25],and Pain Dataset for Dementia [16].
📚slam算法基准的特点, (from 佐治亚理工)
典型数据集序列:

code:https://github.com/ivalab/Benchmarking_SLAM
📚无人机阴影检测, (from 洛桑理工)

site:https://github.com/IVRL/Drone-Shadow-Tracking
📚REPLAB用于机器人学习的低成本基准评测, (from 伯克利)

website:https://sites.google.com/view/replab/
video:https://goo.gl/5F9dP4
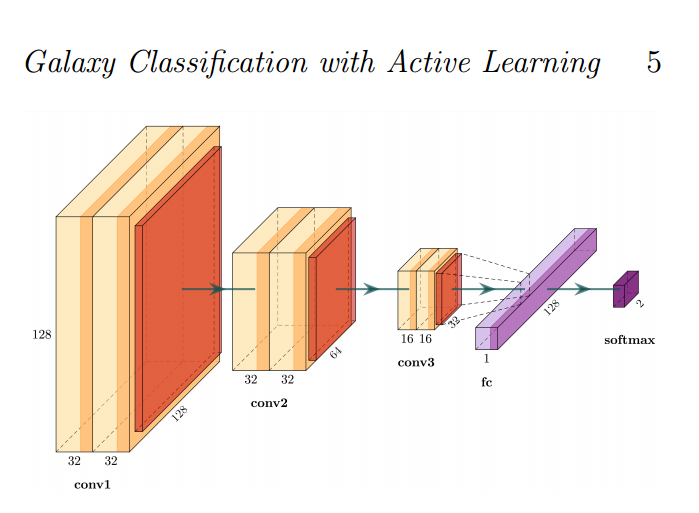
📚Galaxy Zoo基于贝叶斯CNN和主动学习的概率形态学用于星系检测, (from 牛津)

📚检测乒乓球旋转, 为了开发出能与人对打的机器人,研究人员利用高速相机350Hz和视觉方法检测乒乓球旋转。主要检测球上面logo的运动。首先利用背景前景不同来检测logo位置,随后利用CNN预测logo方向,最后利用Magnus力(马格纳斯力,流体旋转偏移)来估计球的轨迹。(from 德国图宾根大学)
基于帧差分检测球:

logo检测和圆分割

result see:https://youtu.be/SjE1Ptu0bTo, https://www.youtube.com/channel/UCFr4VUVS6FRz3W5jB5iLyKA
Daily Computer Vision Papers
| Few-Shot Adversarial Learning of Realistic Neural Talking Head Models Authors Egor Zakharov, Aliaksandra Shysheya, Egor Burkov, Victor Lempitsky 最近的几项研究表明,通过训练卷积神经网络生成它们,可以获得高度逼真的人体头部图像。为了创建个性化的谈话头部模型,这些工作需要对单个人的图像的大型数据集进行训练。然而,在许多实际场景中,需要从人的一些图像视图(甚至可能是单个图像)学习这种个性化的谈话头模型。在这里,我们提出了一个具有如此少射击能力的系统。它在大型视频数据集上执行冗长的元学习,之后能够将以前看不见的人的神经说话头模型的一次性和一次性学习作为高容量发生器和鉴别器的对抗训练问题。至关重要的是,该系统能够以特定的方式初始化发生器和鉴别器的参数,因此尽管需要调整数千万个参数,但训练可以仅基于少量图像并快速完成。我们表明,这种方法能够学习新人甚至肖像画的高度逼真和个性化的谈话头模型。 |
| Patch-based 3D Human Pose Refinement Authors Qingfu Wan, Weichao Qiu, Alan L. Yuille 现有技术3D人体姿势估计方法通常在单个前向运行中估计来自整个RGB图像的姿势。在本文中,我们开发了一个后处理步骤,以从身体部位补丁中改进3D人体姿势估计。使用本地补丁作为输入有两个优点。首先,身体部位周围的精细细节被放大到高分辨率,用于精确度3D姿势预测。其次,它可以在姿势之间共享部件外观,从而使稀有姿势受益。为了获得斑块的信息表示,我们探索了不同的输入模态,并验证了融合预测分割与RGB的优越性。我们表明,我们的方法始终如一地提高了最先进的3D人体姿势方法的准确性。 |
| Drone Shadow Tracking Authors Xiaoyan Zou, Ruofan Zhou, Majed El Helou, Sabine S sstrunk 由不远处表面上方的无人机拍摄的航拍视频可能包含投射在场景上的无人机阴影。这会恶化视频的美学质量。如果存在其他阴影,则无法直接应用阴影,并且必须跟踪无人机的阴影。然而,在视频中跟踪无人机的阴影是具有挑战性的。不同大小,形状,方向变化和无人机高度构成困难。阴影也很容易在黑暗区域消失。但是,除了几何形状外,阴影还具有可以利用的特定属性。在本文中,我们将阴影检测掩模形式的阴影物理特性的知识融入到基于相关的跟踪算法中。我们捕获了一组使用不同设置拍摄的航拍视频,并将我们的结果与最先进的跟踪算法进行比较。 |
| Semi-Supervised Learning by Augmented Distribution Alignment Authors Qin Wang, Wen Li, Luc Van Gool 在这项工作中,我们提出了一种简单而有效的半监督学习方法,称为增强分布对齐。我们揭示由于标记样本的数量有限,半监督学习中存在基本的采样偏差,这经常导致标记数据和未标记数据之间的相当大的经验分布不匹配。为此,我们建议调整标记和未标记数据的经验分布以减轻偏差。一方面,我们采用对抗性训练策略,以最小化标记和未标记数据之间的分布距离,这受到域适应工作的启发。另一方面,为了处理标记数据的小样本问题,我们还提出了一种简单的插值策略来生成伪训练样本。这两种策略可以很容易地实现到现有的深度神经网络中。我们证明了我们提出的方法对基准SVHN和CIFAR10数据集的有效性,我们分别在其上实现了3.54和10.09的新的现有错误率。我们的代码将在网址上提供 |
| Self-Supervised Similarity Learning for Digital Pathology Authors Jacob Gildenblat, Eldad Klaiman 使用从ImageNet上预训练的网络中提取的特征是数字病理学深度学习应用中的常见做法。然而,它提出了缺少域特定图像信息的缺点。在数字病理学中,监督的训练数据昂贵且难以收集。我们提出了一种通过在整个幻灯片图像WSI上进行相似性学习来进行特征提取的自我监督方法,该方法易于实现并且允许创建鲁棒且紧凑的图像描述符。我们训练一个暹罗网络,利用图像空间连续性,并假设图像中的空间相邻图块比远处图块更相似。我们的网络输出长度为128的特征向量,与ImageNet上预先训练的网络相比,可以显着降低内存存储并加快处理速度。我们将这种方法应用于来自Camelyon16训练集的数字病理学全幻灯片图像WSI,并通过测量Camelyon16测试集中的肿瘤图像的图像检索和远近区块的描述符对距离比来评估和比较我们的方法。我们表明,我们的方法比现有的基于ImageNet和通用的自监督特征提取方法产生更好的检索任务结果。据我们所知,这也是第一个针对数字病理学量身定制的自我监督学习方法。 |
| Image Captioning based on Deep Learning Methods: A Survey Authors Yiyu Wang, Jungang Xu, Yingfei Sun, Ben He 图像字幕是一项具有挑战性的任务,在人工智能领域引起越来越多的关注,可以应用于高效的图像检索,智能盲目引导和人机交互等。本文对一些进展进行了展望。基于深度学习方法的图像字幕,包括编码器解码器结构,编码器中的改进方法,解码器中的改进方法以及其他改进。此外,我们讨论了未来的研究方向。 |
| Using Photorealistic Face Synthesis and Domain Adaptation to Improve Facial Expression Analysis Authors Behzad Bozorgtabar, Mohammad Saeed Rad, Hazim Kemal Ekenel, Jean Philippe Thiran 交叉域合成逼真的面部以学习深度模型已经引起了对面部表情分析的越来越多的关注,因为尽管具有少量的真实训练图像,但它有助于提高表达识别精度的性能。然而,由于低质量合成图像与真实面部图像之间的分布差异,从合成面部图像学习可能是有问题的,并且当学习模型应用于现实世界场景时可能无法实现期望的性能。为此,我们提出了一种新的属性引导人脸图像合成,以使用单个模型在多个图像域之间执行转换。此外,我们采用所提出的模型来通过匹配不同域之间的特征分布来学习合成面,同时保留每个域的特征。我们评估了所提出的方法在几个面部数据集上生成逼真面部图像的有效性。我们证明了通过我们的人脸合成模型可以增强表达识别性能。此外,我们还对包含驾驶员面部表情视频的近红外数据集进行了实验,以评估在野外数据中使用驾驶员情绪识别的表现。 |
| Clustered Multitask Nonnegative Matrix Factorization for Spectral Unmixing of Hyperspectral Data Authors Sara Khoshsokhan, Roozbeh Rajabi, Hadi Zayyani 本文提出了一种基于聚类多任务网络的新算法来解决高光谱图像中的光谱分离问题。在所提出的算法中,采用了集群网络。高光谱图像中的每个像素被视为该网络中的节点。使用模糊c均值聚类方法对网络中的节点进行聚类。扩散最小均方策略已被用于优化所提出的成本函数。为了评估所提出的方法,在合成和真实数据集上进行实验。基于谱角距离,丰度角距离和重建误差度量的仿真结果说明了该算法与其他方法相比的优势。 |
| Less Memory, Faster Speed: Refining Self-Attention Module for Image Reconstruction Authors Zheng Wang, Jianwu Li, Ge Song, Tieling Li 自我关注SA机制可以有效地捕获深度神经网络中的全局依赖性,并已成功应用于自然语言处理和图像处理。然而,用于图像重建的SA模块具有高时间和空间复杂性,这限制了它们应用于更高分辨率的图像。在本文中,我们通过调整非本地操作,修改SA模块中的单元之间的连接性并重新实现其计算模式来改进自我关注生成对抗网络SAGAN中的SA模块,从而减少其时间和空间复杂度。 O n 2到文本O n,但它仍然等同于原始SA模块。此外,我们探索模块背后的原理,发现我们的模块是一种特殊的渠道关注机制。基于图像重建的两个基准数据集的实验结果,验证了在相同的计算环境下,两个模型可以实现与图像重建相当的有效性,但是提出的一个模型运行得更快并且占用更少的存储空间。 |
| Deep Transfer Learning Methods for Colon Cancer Classification in Confocal Laser Microscopy Images Authors Nils Gessert, Marcel Bengs, Lukas Wittig, Daniel Dr mann, Tobias Keck, Alexander Schlaefer, David B. Ellebrecht 目的在腹膜中检测结肠直肠癌转移的金标准是对移除的组织样品的组织学评估。对于干预期间的反馈,已经提出通过共聚焦激光显微术进行实时体内成像以通过手动专家评估来区分良性和恶性组织。自动图像分类可以通过提供即时反馈进一步改善手术工作流程。 |
| Spin Detection in Robotic Table Tennis Authors Jonas Tebbe, Lukas Klamt, Andreas Zell 在乒乓球中,球的旋转旋转起着至关重要的作用。乒乓球比赛将有各种笔画。每个都产生不同数量和类型的旋转。为了开发能够与人类玩家竞争的机器人,机器人需要能够检测旋转,以便它可以计划适当的返回行程。在本文中,我们比较了三种估计旋转的方法。前两种方法使用高速摄像机,以380 Hz的帧速率捕获飞行中的球。该相机允许看到印在球上的圆形品牌标志的移动。第一种方法使用背景差异来确定徽标的位置。在第二替代方案中,训练CNN以预测徽标的方向。第三种方法评估球的轨迹并从马格努斯力的作用推导出旋转。在一次演示中,我们的机器人必须对真实的乒乓球集会中的不同旋转类型做出反应,以对抗人类对手。 |
| Learning Image-Specific Attributes by Hyperbolic Neighborhood Graph Propagation Authors Xiaofeng Xu, Ivor W. Tsang, Xiaofeng Cao, Ruiheng Zhang, Chuancai Liu 作为视觉对象描述的一种语义表示,属性被广泛用于各种计算机视觉任务中。在大多数现有的基于属性的研究中,通常采用类特定属性CSA,它们是类级注释,因为其每个类的注释成本低而不是每个单独的图像。然而,由于注释错误和各个图像的多样性,类特定属性通常是有噪声的。因此,期望从原始类特定属性获得图像特定属性ISA,其是图像级注释。在本文中,我们建议通过基于图的属性传播来学习图像特定属性。考虑到双曲几何的内在属性,其距离呈指数扩展,构造双曲邻域图HNG来表征样本之间的关系。基于HNG,我们为每个样本定义邻域一致性,以识别不一致的样本。随后,基于其在HNG中的邻居来细化不一致的样本。对五个基准数据集的广泛实验证明了学习图像特定属性相对于零镜头对象分类任务中的原始类特定属性的显着优势。 |
| Fast Regularity-Constrained Plane Reconstruction Authors Yangbin Lin, Jialian Li, Cheng Wang, Zhonggui Chen, Zongyue Wang, Jonathan Li 人造环境通常包括展现出许多几何关系的平面结构,例如平行度,共面性和正交性。充分利用这些关系可以大大提高复杂场景的算法平面重建的鲁棒性。该研究利用约束模型,该模型需要最少的先验知识来隐式地建立平面之间的关系。我们引入了一种基于能量最小化的方法来重建与我们的约束模型一致的平面。该算法高效,易于理解,易于实现。实验结果表明,我们的算法在高百分比的噪声和异常值下成功地重建了平面。这在速度和鲁棒性方面优于其他现有技术的规则约束平面重建方法。 |
| Disparity-based HDR imaging Authors Jennifer Bonnard CRESTIC , Gilles Valette CRESTIC , C line Loscos CRESTIC 高动态范围成像允许扩展强度值的动态范围以接近人眼能够感知的范围。尽管数码相机传感器范围容量已经取得了巨大进步,但仍需要捕获多次曝光以重建高动态范围值。在本文中,我们提出了如何获得多立体图像的高动态范围值的研究。在许多论文中,差异已被用于记录不同图像的像素并指导重建。在本文中,我们展示了这些方法的局限性,并提出启发式方法作为确定问题案例的解决方案。 |
| Skeleton-Based Hand Gesture Recognition by Learning SPD Matrices with Neural Networks Authors Xuan Nguyen, Luc Brun, Olivier Lezoray, S bastien Bougleux 在本文中,我们提出了一种新的基于骨架数据的手势识别方法,通过神经网络学习SPD矩阵。我们将手骨架建模为图形,并引入用于SPD矩阵学习的神经网络,将手关节的3D坐标作为输入。所提出的网络基于两个新设计的层,其将一组SPD矩阵变换为SPD矩阵。对于手势识别,我们使用从网络中提取的特征来训练线性SVM分类器。来自SHREC 2017 3D形状检索竞赛的具有挑战性的数据集Dynamic Hand Gesture数据集的实验结果表明,所提出的方法优于最先进的方法。 |
| Learning to Count Objects with Few Exemplar Annotations Authors Jianfeng Wang, Rong Xiao, Yandong Guo, Lei Zhang 在本文中,我们研究了带有不完整注释的对象计数问题。基于以下观察:在许多对象计数问题中,目标对象通常重复并且彼此高度相似,我们对仅提供少量示例注释时的设置特别感兴趣。直接应用带有不完整注释的对象检测将导致严重的准确度降低,因为它对未标记的对象实例的处理不当。为了解决该问题,我们提出了一种正对焦物体检测器PFOD,以在应用一般物体检测算法之前逐步传播不完整标签。 PFOD侧重于阳性样本,并在大多数学习时间忽略阴性实例。这种策略虽然简单,但却大大提高了对象计数的准确性。在用于停车场计数的CARPK数据集上,我们仅使用5个训练图像(每个具有5个边界框)将mAP 0.5从4.58改进到72.44。在用于货架产品计数的Drink35数据集上,使用10个训练图像将mAP 0.5从14.16改进到53.73,每个训练图像具有5个边界框。 |
| Procedural Synthesis of Remote Sensing Images for Robust Change Detection with Neural Networks Authors Maria Kolos, Anton Marin, Alexey Artemov, Evgeny Burnaev 已知诸如卷积神经网络CNN的数据驱动方法在训练数据丰富时在图像识别任务上提供最先进的性能。然而,在某些情况下,例如遥感图像中的变化检测,不能获得足够数量的注释数据。在这项工作中,我们提出了一种简单有效的方法,用于在遥感领域创建逼真的目标合成数据集,充分利用游戏开发引擎提供的机会。我们提供了用于过程几何生成和渲染的管道的描述,以及在变化检测场景中评估生成的数据集的效率。我们的评估表明,当现实世界数据量严重受限时,我们的管道有助于提高深度学习模型的性能和收敛性。 |
| Not All Parts Are Created Equal: 3D Pose Estimation by Modelling Bi-directional Dependencies of Body Parts Authors Jue Wang, Shaoli Huang, Xinchao Wang, Dacheng Tao 由于生理结构,并非所有人体部位都具有相同的自由度DOF。例如,肢体可以比躯干更灵活和自由地移动。尽管实现了非常有希望的结果,但是大多数现有的3D姿势估计方法均匀地对待身体关节并因此经常导致肢体上更大的重建误差。在本文中,我们提出了一种渐进的方法,明确地解释了身体部位中不同的DOF。我们对具有较高DOF的部件(如肘部)进行建模,作为具有较低DOF(如躯干)的相应部件的相关部件,其中可以更可靠地估计3D位置。同时,高DOF部分可能会对低DOF位于何处施加约束。结果,具有不同DOF的部件彼此监督,产生物理约束和合理的姿态估计结果。为了进一步促进高DOF部位的预测,我们引入了姿势属性估计,其中肢体关节相对于具有人体最小DOF的躯干的相对位置被明确估计并进一步馈送到联合估算模块。所提出的方法取得了非常有希望的结果,在几个基准测试中表现优于现有技术。 |
| Learning Video Representations from Correspondence Proposals Authors Xingyu Liu, Joon Young Lee, Hailin Jin 帧之间的对应关系编码有关视频中动态内容的丰富信息。然而,由于其不规则的结构和复杂的动态,有效捕获和学习它是具有挑战性的。在本文中,我们提出了一种新颖的神经网络,通过聚合来自潜在对应的信息来学习视频表示。这个名为CPNet的网络可以学习具有时间一致性的不断发展的2D领域。特别是,它可以通过将外观和长距离运动与仅RGB输入混合来有效地学习视频的表示。我们提供广泛的消融实验来验证我们的模型。 CPNet在动力学方面表现出比现有方法更强的性能,并在Something Something和Jester上实现了最先进的性能。我们对模型的行为进行分析,并显示其对提案中错误的稳健性。 |
| Boundary Loss for Remote Sensing Imagery Semantic Segmentation Authors Alexey Bokhovkin, Evgeny Burnaev 为了应对地理空间数据日益增长的重要性,其包括语义分割在内的分析成为当今计算机视觉中越来越受欢迎的任务。卷积神经网络是强大的视觉模型,产生特征的层次结构,从业者广泛使用它们来处理遥感数据。在执行遥感图像分割时,通常情况下是具有精确定义的边界的一个类的多个实例,并且准确地提取这些边界是至关重要的。段边界描绘的准确性明确地影响整个分段区域的质量。然而,广泛使用的分段丢失函数(例如BCE,IoU丢失或Dice丢失)不会充分地惩罚边界的未对准。在本文中,我们提出了一种新的损失函数,即边界检测的度量会计准确度的可区分替代。我们可以将损失函数与任何神经网络一起用于二进制分割。我们在合成数据集上对UNet进行了各种修改,并使用现实世界数据ISPRS Potsdam,INRIA AIL对我们的损失函数进行了验证。根据建议的损失函数进行训练,模型在IoU评分方面优于基线方法。 |
| Implications of Computer Vision Driven Assistive Technologies Towards Individuals with Visual Impairment Authors Linda Wang, Alexander Wong 基于计算机视觉的技术正在社会中普遍存在。已经看到计算机视觉增加的一个应用领域是辅助技术,特别是对于那些有视觉障碍的人。研究表明,计算机视觉模型能够实现诸如提供场景标题,检测物体和识别面部等任务。尽管通过这些任务帮助视力障碍的个体增加了他们的独立性和自主性,但是出现了对偏见,隐私和潜在有用性的担忧。本文讨论了基于计算机视觉的辅助技术对视力障碍患者的积极和消极影响,以及计算机视觉研究人员和开发人员的考虑因素,以减轻负面影响的数量。 |
| Multimodal Transformer with Multi-View Visual Representation for Image Captioning Authors Jun Yu, Jing Li, Zhou Yu, Qingming Huang 图像字幕旨在自动生成给定图像的自然语言描述,并且大多数现有技术模型采用编码器解码器框架。该框架包括基于卷积神经网络CNN的图像编码器,其从输入图像提取基于区域的视觉特征,以及基于递归神经网络RNN的字幕解码器,其基于具有关注机制的视觉特征生成输出字幕词。尽管现有研究取得了成功,但目前的方法只能模拟表征模态间相互作用的共同注意力,而忽略了表征模态内相互作用的自我关注。受到Transformer模型在机器翻译中的成功启发,我们将其扩展到用于图像字幕的Multimodal Transformer MT模型。与现有的图像字幕方法相比,MT模型同时捕获统一注意块中的帧内和帧间交互。由于这种注意块的深度模块化组合,MT模型可以执行复杂的多模态推理并输出准确的字幕。此外,为了进一步改善图像字幕性能,将多视图视觉特征无缝地引入到MT模型中。我们使用基准MSCOCO图像字幕数据集对我们的方法进行定量和定性评估,并进行广泛的消融研究,以研究其有效性背后的原因。实验结果表明,我们的方法明显优于以前的现有技术方法。在撰写本文时,我们的解决方案共有七个模型,在MSCOCO图像字幕挑战的实时排行榜上排名第一。 |
| Enabling Computer Vision Driven Assistive Devices for the Visually Impaired via Micro-architecture Design Exploration Authors Linda Wang, Alexander Wong 最近对物体检测的改进显示出有助于以前的解决方案无法实现的任务。特定区域是视力障碍个体的辅助装置。虽然已经证明现有技术的深度神经网络可以实现优异的物体检测性能,但是它们的高计算和存储器要求使得它们在设备操作上成本过高。或者,基于云的操作会导致隐私问题,对潜在用户都没有吸引力。为了应对这些挑战,本研究通过微观架构设计探索,研究创建一个专门用于OLIV的高效物体检测网络,OLIV是一种用于视障人士物体定位的AI动力助手。特别是,我们制定了寻找最佳网络微架构作为数值优化问题的问题,其中我们发现了一组超参数控制MobileNetV2 SSD网络微架构,该架构最大化了室内物体的MSCOCO OLIV数据集的修改后的NetScore目标函数。实验结果表明,这种微架构设计探索策略导致了一个紧凑的深度神经网络,在精度,大小和速度之间取得了平衡的折衷,使其非常适合为视障人士启用设备计算机视觉驱动的辅助设备。 |
| U-Net Based Multi-instance Video Object Segmentation Authors Heguang Liu, Jingle Jiang 多实例视频对象分割是仅在给定注释的第一帧的情况下在像素级中对整个视频序列中的特定实例进行分段。在本文中,我们实现了一个有效的完全卷积网络,其中U Net类似的结构建立在OSVOS微调层之上。我们使用实例隔离将这个多实例分割问题转化为二元标注问题,并使用加权交叉熵损失和骰子系数损失作为我们的损失函数。我们的最佳模型在DAVIS数据集上实现了F均值0.467和J均值0.424,这与现有技术方法相当。但案例分析表明,该模型可以实现更平滑的轮廓和更好的实例覆盖,这意味着它更适合于回忆聚焦分割场景。我们还在其他卷积神经网络上进行了实验,包括Seg Net,Mask R CNN,并提供了深刻的比较和讨论。 |
| Multimodal 3D Object Detection from Simulated Pretraining Authors smund Brekke, Fredrik Vatsendvik, Frank Lindseth 自动驾驶应用中对模拟数据的需求对于预训练模型的验证和训练新模型都变得越来越重要。为了使这些模型能够推广到实际应用,基础数据集包含各种驱动场景并且模拟传感器读数与现实世界传感器非常相似,这一点至关重要。我们提出了Carla自动数据集提取工具CADET,这是一种用于从CARLA模拟器生成训练数据的新工具,用于自动驾驶研究。该工具能够通过对象注释导出高质量,同步的LIDAR和相机数据,并提供精确反映真实传感器阵列的配置。此外,我们使用此工具生成由10,000个样本组成的数据集,并使用此数据集来训练3D对象检测网络AVOD FPN,并对KITTI数据集进行微调,以评估有效预训练的可能性。我们还在Bird s Eye View中展示了两种新颖的LIDAR特征图配置,用于AVOD FPN,可以轻松修改。这些配置在KITTI和CADET数据集上进行测试,以评估其性能以及预训练的模拟数据集的可用性。虽然不足以完全取代现实世界数据的使用,并且通常无法超过完全训练实际数据的系统的性能,但我们的结果表明,模拟数据可以大大减少实现满意水平所需的实际数据培训量。准确性。 |
| Geometric Pose Affordance: 3D Human Pose with Scene Constraints Authors Zhe Wang, Liyan Chen, Shaurya Rathore, Daeyun Shin, Charless Fowlkes 尽管有许多最近的进展,但从单个图像对人体姿势的全3D估计仍然是具有挑战性的任务在本文中,我们探索了一个假设,即可以使用关于场景几何的强有力的先验信息来提高姿势估计的准确性。为了从经验上解决这个问题,我们已经组装了一个新颖的textbf Geometric Pose Affordance数据集,包括与各种丰富的3D环境交互的人的多视图图像。我们利用商业动作捕捉系统来收集姿势的金标准估计并构建场景本身的精确几何3D CAD模型。 |
| A 2D dilated residual U-Net for multi-organ segmentation in thoracic CT Authors Sulaiman Vesal, Nishant Ravikumar, Andreas Maier 在计算机断层扫描中自动分割处于风险中的器官OAR是计划有效治疗策略以对抗肺癌和食道癌的重要部分。肿瘤周围器官的准确分割有助于解释患者固有的位置和形态的变化,从而促进适应性和计算机辅助放射治疗。尽管OAR的手动描绘仍然非常普遍,但是由于患者的器官的形状和位置的复杂变化以及CT图像中相邻器官之间的低软组织对比度而容易出错。最近,深度卷积神经网络CNN获得了巨大的牵引力,并在医学图像分割方面取得了最新成果。在本文中,我们提出了一个深度学习框架,用于分割胸部CT图像中的OAR,特别是心脏,食管,气管和主动脉。我们的方法在U Net风格网络的瓶颈中采用扩散卷积和聚合残差连接,其中包含全局上下文和密集信息。我们的方法在来自ISBI 2019 SegTHOR挑战的20个看不见的测试样本上实现了总体Dice评分为91.57。 |
| FORECAST-CLSTM: A New Convolutional LSTM Network for Cloudage Nowcasting Authors Chao Tan, Xin Feng, Jianwu Long, Li Geng 随着公众对大规模实时气象服务的高度需求,短时间云量预测的改进已成为天气预报产品的重要组成部分。为了提供符合气象服务标准的预报云,在本文中,我们提出了一种新的基于分层卷积长期短期记忆网络的深度学习模型,我们称之为FORECAST CLSTM,具有新的预报员损失函数来预测未来的卫星云图像。该模型旨在融合分层网络结构中的多尺度特征,以同时预测像素值和云量的形态运动。我们还收集了大约40K红外卫星云图,并创建了一个大规模的卫星云图数据集SCMD。与现有技术的ConvLSTM模型相比,所提出的FORECAST CLSTM模型显示出更好的预测性能,并且所提出的预报员损失函数也被证明比传统的损失函数更好地保持真实大气条件的不确定性。 |
| What Do Adversarially Robust Models Look At? Authors Takahiro Itazuri, Yoshihiro Fukuhara, Hirokatsu Kataoka, Shigeo Morishima 在本文中,我们讨论了开放式问题。对抗性强大的模型最近看到的内容最近,在许多工作中已经报道,在标准精度和对抗性鲁棒性之间存在折衷。根据以前的工作,这种权衡取决于这样的事实:对抗性强且标准的准确模型可能依赖于非常不同的特征集。然而,尚未充分研究实际存在哪种差异。在本文中,我们通过视觉和定量的各种实验来分析这种差异。实验结果表明,对比强大的模型比标准模型更大规模地观察事物,并且对精细纹理的关注较少。此外,尽管声称对抗性强的特征与标准精度不兼容,但通过将它们用作预训练模型,尤其是在低分辨率数据集中,甚至可以产生积极效果。 |
| SAWNet: A Spatially Aware Deep Neural Network for 3D Point Cloud Processing Authors Chaitanya Kaul, Nick Pears, Suresh Manandhar 在迄今为止的几乎所有计算机视觉任务中,深度神经网络已经确立了自己作为最先进的方法。但是它们在处理非欧几里得域上的数据时的应用仍然是一个非常活跃的研究领域。其中一个领域是对点云数据的分析,由于缺乏秩序,因此对其提出了挑战。最近提出了许多技术,由PointNet架构引领。这些技术使用来自点云的全局或局部信息来提取点的潜在表示,然后将其用于手头分类分割。在我们的工作中,我们引入了一个神经网络层,它结合了全局和局部信息,以便更好地嵌入这些点。我们通过剩余连接增强我们的架构,在层之间传递信息,这也使网络更容易训练。我们使用我们的架构在ModelNet40数据集上实现了最先进的结果,我们的结果也与ShapeNet零件分割数据集和室内场景分割数据集的最新技术竞争。我们计划在github上开源我们预先训练的模型,以鼓励研究团体测试我们的网络数据,或者只是将它们用于基准测试目的。 |
| Which Tasks Should Be Learned Together in Multi-task Learning? Authors Trevor Standley, Amir R. Zamir, Dawn Chen, Leonidas Guibas, Jitendra Malik, Silvio Savarese 许多计算机视觉应用需要实时解决多个任务。可以训练神经网络以使用多任务学习同时解决多个任务。这节省了推理时的计算,因为只需要评估单个网络。不幸的是,随着任务目标的竞争,这往往会导致整体性能下降,从而提出了在使用多任务学习时应该和不应该在一个网络中一起学习哪些任务的问题我们系统地研究任务合作和竞争并提出分配任务的框架一些神经网络使得协作任务由相同的神经网络计算,而竞争任务由不同的网络计算。我们的框架提供了时间精度折衷,并且使用较少的推理时间可以产生更好的准确性,不仅比单个大型多任务神经网络而且还有许多单任务网络。 |
| Semi-Supervised Monocular Depth Estimation with Left-Right Consistency Using Deep Neural Network Authors Ali Jahani Amiri, Shing Yan Loo, Hong Zhang 从单目摄像机图像估计场景的深度已经有了巨大的研究进展。用于单个图像深度预测的现有方法专门基于深度神经网络,并且它们的训练可以使用立体图像对进行无监督,使用LiDAR点云进行监督,或者使用立体声和LiDAR进行半监督。一般而言,半监督训练是优选的,因为它不受任何监督训练的弱点,这是由于摄像机和LiDARs视野的差异,或无监督训练,由于可以从中恢复的深度精度差。一对立体声。在本文中,我们使用优于现有技术的半监督训练来展示我们对单图像深度预测的研究。我们通过在立体声重建中明确利用左右一致性的损失函数来实现这一点,这在先前的半监督训练中尚未被采用。此外,我们描述了从LiDAR导出的地面实况深度的正确使用,可以显着降低预测误差。我们的深度预测模型的性能在流行的数据集上进行评估,并且通过实验结果证明了我们的半监督训练方法的每个方面的重要性。我们的深度神经网络模型已公开发布。 |
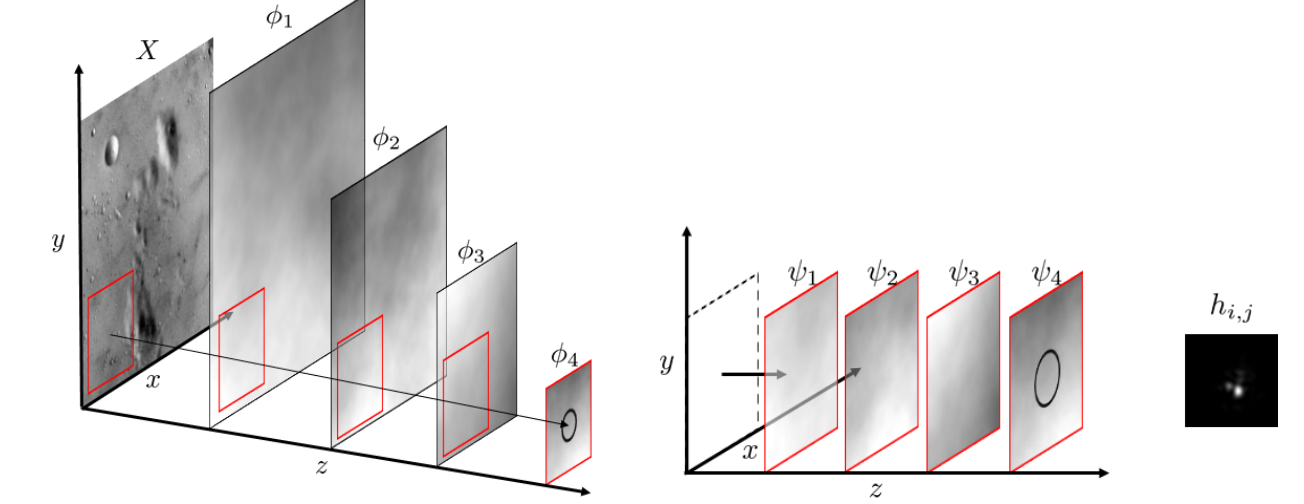
| Learning Perspective Undistortion of Portraits Authors Yajie Zhao, Zeng Huang, Tianye Li, Weikai Chen, Chloe LeGendre, Xinglei Ren, Jun Xing, Ari Shapiro, Hao Li 近距离肖像照片通常包含偏向人类感知并且挑战面部识别和重建技术的透视失真伪像。我们提出了第一种基于深度学习的方法,用于从无约束的肖像中去除这些伪像。与先前的现有技术方法相比,我们的方法处理具有极端透视失真的甚至肖像,因为我们避免了首先拟合3D面部模型的不准确且容易出错的步骤。相反,我们预测失真校正流程图,该流程图对每像素位移进行编码,以在应用于输入图像时消除失真伪影。我们的方法还自动推断缺失的面部特征,即由强烈的透视畸变引起的闭塞耳朵,具有连贯的细节。我们证明我们的方法在质量和数量上都明显优于以前的技术水平,特别是对于具有极端透视扭曲或面部表情的肖像。我们进一步表明,我们的技术有益于许多基本任务,显着提高了人脸识别和3D重建的准确性,并通过单个肖像实现了新颖的相机校准技术。此外,我们还建立了第一个视角肖像数据库,其身份,表达和姿势具有很大的多样性,这将有利于该领域的相关研究。 |
| SplitNet: Sim2Sim and Task2Task Transfer for Embodied Visual Navigation Authors Daniel Gordon, Abhishek Kadian, Devi Parikh, Judy Hoffman, Dhruv Batra 我们提出了SplitNet,一种解耦视觉感知和政策学习的方法。通过结合辅助任务和选择性学习模型的某些部分,我们明确地将视觉导航的学习目标分解为感知世界并对该感知采取行动。我们在模拟器之间的转换方面比基线模型有显着改进,这是迈向Sim2Real的一个令人鼓舞的步骤。此外,SplitNet可以更好地推广来自同一模拟器的不可见环境,并更快,更有效地传输到新颖的体现导航任务。此外,只给出来自目标域的小样本,SplitNet可以匹配接收整个数据集的传统端到端管道的性能。代码和视频可在以下网站获得 |
| Parts4Feature: Learning 3D Global Features from Generally Semantic Parts in Multiple Views Authors Zhizhong Han, Xinhai Liu, Yu Shen Liu, Matthias Zwicker 通过在多个视图上从像素级学习全局形状特征,深度学习在3D形状分析中取得了显着成果。但是,以前的方法在不考虑零件级信息的情况下为整个视图计算低级特征。相比之下,我们提出了一个名为Parts4Feature的深度神经网络,用于从多个视图中的零件级信息中学习3D全局特征。我们介绍了一般语义部分的新颖定义,Parts4Feature学习在不同的3D形状分割基准测试中检测多个视图。我们的架构的一个关键想法是,它传输了在多个视图中检测语义上有意义的部分的能力,以学习3D全局特征。 Parts4Feature通过将本地部分检测分支和全局特征学习分支与共享区域提议模块相结合来实现此目的。全局特征学习分支利用新颖的多注意机制将学习的部分模式聚合检测到的部分,而区域提议模块使得本地和全局的判别信息能够相互促进。我们证明了Parts4Feature在三个大型3D形状基准测试下的性能优于现有技术。 |
| 3DViewGraph: Learning Global Features for 3D Shapes from A Graph of Unordered Views with Attention Authors Zhizhong Han, Xiyang Wang, Chi Man Vong, Yu Shen Liu, Matthias Zwicker, C.L. Philip Chen 通过聚合多个视图上的信息来学习全局特征已被证明对3D形状分析是有效的。对于深度学习模型中的视图聚合,池已广泛应用。但是,合并会导致视图内容丢失,视图之间的空间关系会限制学习特征的可辨别性。我们建议3DViewGraph来解决这个问题,通过更有效地聚焦无序视图来学习3D全局特征。具体而言,围绕形状采取的无序视图被视为视图上的视图节点。 3DViewGraph首先学习一种新颖的潜在语义映射,将低级视图特征投射到低维空间中的有意义的潜在语义嵌入,这是由潜在的语义模式所跨越的。然后,通过新颖的空间模式相关性对每对视图节点的内容和空间信息进行编码,其中在潜在语义模式之间计算相关性。最后,所有空间模式相关性与新颖注意机制所学习的注意力量相结合。这通过突出显示具有独特特征的无序视图节点并且抑制具有外观模糊性的视图节点来进一步增加学习特征的可辨别性。我们表明3DViewGraph在三个大规模基准测试中优于最先进的方法。 |
| Learning to Reconstruct 3D Manhattan Wireframes from a Single Image Authors Yichao Zhou, Haozhi Qi, Yuexiang Zhai, Qi Sun, Zhili Chen, Li Yi Wei, Yi Ma 在本文中,我们提出了一种方法,通过有效地利用全局结构规律,从单个图像中获得紧凑和精确的3D线框表示。我们的方法训练卷积神经网络同时检测显着的连接点和直线,以及预测它们的3D深度和消失点。与基于现有学习的线框检测方法相比,我们的网络更简单,更统一,从而实现更好的2D线框检测。借助曼哈顿假设等全球结构先验,我们的方法进一步重建了一个完整的3D线框模型,这是一种适用于各种高级视觉任务(如AR和CAD)的紧凑矢量表示。我们对大型城市场景合成数据集以及真实图像进行了广泛的评估。我们的代码和数据集将会发布。 |
| Multilinear Compressive Learning Authors Dat Thanh Tran, Mehmet Yamac, Aysen Degerli, Moncef Gabbouj, Alexandros Iosifidis 压缩学习是一个新兴的主题,它结合了通过压缩感知和机器学习的信号采集,直接在少量测量上执行推理任务。许多数据模态自然具有多维或张量格式,每个维度或张量模式表示不同的特征,例如视频序列中的空间和时间信息或高光谱图像中的空间和光谱信息。然而,在现有的压缩学习框架中,压缩感测组件利用矢量化信号上的随机或学习线性投影来执行信号采集,从而丢弃信号的多维结构。在本文中,我们提出了多线性压缩学习,这是一个在采集步骤中考虑多维信号的张量性质的框架,并在结构感测的测量上建立随后的推理模型。我们的理论复杂性分析表明,与存储和计算要求中的基于向量的对应物相比,所提出的框架更有效。通过大量的实验,我们还凭经验证明我们的多线性压缩学习框架在对象分类和人脸识别任务中优于基于矢量的框架,并且在原始信号的维度增加时有利地扩展,使其对高维多维信号高效。 |
| Analysis of critical parameters of satellite stereo image for 3D reconstruction and mapping Authors Rongjun Qin 虽然现在先进的密集图像匹配DIM算法能够产生与卫星立体图像相当的密集点云的LiDAR光检测和测距,但这种点云的准确性和完整性很大程度上取决于卫星立体图像的几何参数。两个图像之间的交叉角通常被视为立体数据采集中最重要的交叉角,因为现有技术的DIM算法在窄基线较小交叉角立体声上工作得最好。半全局匹配将15 25度视为良好的交叉角。该因素与传统的航空摄影测量配置一致,因为交叉角直接与视差方向上的基本高比率和纹理失真相关,因此都影响水平和垂直精度。然而,我们的实验发现,即使具有非常相似和良好的交叉角,相同的DIM算法应用于相同区域的不同立体对,产生的点云与地面实况LiDAR数据相比具有显着不同的精度。这提出了一个非常实用的问题,从业者经常会问什么因素构成一个好的卫星立体对,这样就可以为绘图目的产生准确和最佳的结果。在这项工作中,我们通过执行超过1,000的立体匹配提供了对此问题的全面分析。卫星立体对具有不同的采集参数,包括它们的交叉角,偏离天底角,太阳高度方位角以及时间差,从而为这个问题提供了彻底的答案。这项工作将为从事多视图卫星图像重建的研究人员以及工业从业者提供有价值的参考,从而最大限度地降低高质量大规模测绘的成本。 |
| Automated 3D recovery from very high resolution multi-view satellite images Authors Rongjun Qin 本文介绍了一种用于处理多视图卫星图像到3D数字表面模型DSM的自动化管道。建议的管道执行自动地理参考并生成高质量密集匹配的点云。特别地,开发了一种新颖的方法,其融合通过立体匹配导出的多个深度图以生成高质量的3D地图。通过从样本LiDAR数据中学习立体对的关键配置,我们根据结果与样本数据的接近程度对图像对进行排名。从各个图像对导出的多个深度图与考虑图像光谱相似性的自适应3D中值滤波器融合。我们证明,与正常中值滤波器相比,所提出的自适应中值滤波器通常提供更好的结果,并且在最佳情况下实现了0.36米RMSE的改进精度。详细介绍了结果和分析。 |
| Limitations and Biases in Facial Landmark Detection -- An Empirical Study on Older Adults with Dementia Authors Azin Asgarian, Shun Zhao, Ahmed B. Ashraf, M. Erin Browne, Kenneth M. Prkachin, Alex Mihailidis, Thomas Hadjistavropoulos, Babak Taati 准确的面部表情分析是涉及老年人身体和心理健康评估的各种临床应用中的必要步骤,例如诊断疼痛或抑郁。尽管在开发稳健的面部标志检测方法方面已经取得了显着进步,但是当遇到不受控制的环境,不同范围的面部表情以及人口的不同人口统计时,现有技术方法仍然面临许多挑战。最近的一项研究表明,个体的健康状况也会影响面部前视图上面部标志检测方法的表现。在这项工作中,我们使用七种面部标志检测方法在更大的背景下研究这个问题。我们不仅在正面进行评估,还对表面和面部的不同区域进行评估。我们的研究结果揭示了现有方法的局限性以及在临床环境中应用这些方法的挑战,表明1当在有痴呆症与无痴呆症患者的个人资料或正面检测时,现有技术水平的显着差异2见解尽管使用六种数据集的各种配置进行了重新训练微调,但是对于面部的所有区域的现有偏差和3存在这种偏差。 |
| AutoDispNet: Improving Disparity Estimation with AutoML Authors Tonmoy Saikia, Yassine Marrakchi, Arber Zela, Frank Hutter, Thomas Brox 计算机视觉方面的许多研究工作都花在优化现有网络架构上,以便在基准测试上获得更多的百分点。最近的AutoML方法有望让我们免于这种努力。但是,它们主要用于相对小规模的分类任务。在这项工作中,我们展示了如何使用和扩展现有的AutoML技术,以有效地优化大规模U Net,如编码器解码器架构。特别是,我们利用基于梯度的神经架构搜索和贝叶斯优化进行超参数搜索。由此产生的优化不需要大型公司规模的计算集群。我们展示了视差估计的结果,该结果明显优于手动优化的基线并达到了现有技术水平。 |
| Dynamic Vision Sensor integration on FPGA-based CNN accelerators for high-speed visual classification Authors Alejandro Linares Barranco, Antonio Rios Navarro, Ricardo Tapiador Morales, Tobi Delbruck 深度学习是一种应用于许多领域的尖端理论。对于视觉应用,卷积神经网络CNN要求分类任务具有显着的准确性。在过去几年中,已经有许多硬件加速器用于改进基于CPU或GPU的解决方案。在考虑用于大规模生产的ASIC制造之前,该技术通常通过FPGA进行原型设计和测试。商用典型相机30fps的使用限制了这些系统在高速应用中的能力。模拟生物视网膜行为的动态视觉传感器DVS的使用由于其性质而逐渐变得重要,以改善这种应用,其中信息由连续的尖峰流表示,并且CNN要处理的帧是构建收集固定数量的这些尖峰称为事件。对象越快,DVS产生的事件就越多,因此帧速率越高。因此,这些DVS利用允许以CNN加速器可提供的最大速度计算帧。在本文中,我们提出了FPGA的流水线设计的VHDL HLS描述,能够从地址事件表示AER DVS视网膜收集事件,以获得由特定CNN加速器(称为NullHop)使用的标准化直方图。 VHDL用于描述电路,以及用于计算块的HLS,其用于执行CNN所需的帧的归一化。在延迟和功耗方面,结果优于使用Zynq7100上运行频率为800MHz的ARM处理器的帧收集和规范化的先前实现。对于以160fps峰值速率运行的Roshambo CNN实时实验,呈现了测量的67加速因子。 |
| Adversarially robust transfer learning Authors Ali Shafahi, Parsa Saadatpanah, Chen Zhu, Amin Ghiasi, Christoph Studer, David Jacobs, Tom Goldstein 传输学习,其中网络被训练在一个任务上并且重新用于另一个任务,通常用于在数据稀缺或全面训练成本太高时产生神经网络分类器。当目标是生成一个不仅准确而且具有对抗性的模型时,数据稀缺性和计算限制变得更加麻烦。 |
| DARC: Differentiable ARchitecture Compression Authors Shashank Singh, Ashish Khetan, Zohar Karnin 在许多学习情境中,推理时的资源比训练时的资源受到更多限制。本文研究了一种称为可微建筑压缩DARC的通用范例,它结合了模型压缩和体系结构搜索,以学习在推理时具有资源效率的模型。鉴于资源密集型基础架构,DARC利用培训数据来了解哪些子组件可以被更便宜的替代品替换。高级技术可应用于任何神经结构,并且我们报告了用于图像分类的现有卷积神经网络的实验。对于CIFAR 10上具有97.2精度的WideResNet,我们将单样本推理速度提高了2.28倍,将内存占用提高了5.64倍,没有精度损失。对于ImageNet上具有79.15 Top1精度的ResNet,我们将批量推理速度提高了1.29倍,内存占用提高了3.57倍,精度损失为1。我们还在简化的情况下给出了理论上的Rademacher复杂性界限,展示了DARC如何避免过度拟合,尽管参数化过多。 |
| Zero-Shot Knowledge Distillation in Deep Networks Authors Gaurav Kumar Nayak, Konda Reddy Mopuri, Vaisakh Shaj, R. Venkatesh Babu, Anirban Chakraborty 知识蒸馏处理从高容量源模型教师培训较小模型学生的问题,以保留其大部分性能。现有方法使用训练数据或从中提取的元数据来训练学生。然而,如果数据集非常大或者存在隐私或安全问题(例如,生物度量或医学数据),则访问教师已被训练的数据集可能并不总是可行的。因此,在本文中,我们提出了一种新的无数据方法来培训学生。在没有使用任何元数据的情况下,我们从复杂的教师模型中综合数据印象,并将这些作为原始训练数据样本的替代品,通过知识蒸馏将其学习转移到学生。因此,我们称之为Zero Shot Knowledge Distillation方法,并证明我们的框架可以通过使用多个基准数据集上的实际训练数据样本进行蒸馏来实现竞争性泛化性能。 |
| Catastrophic forgetting: still a problem for DNNs Authors B. Pf lb, A. Gepperth, S. Abdullah, A. Kilian 我们研究了DNN在训练类训练时的表现,包括初始训练,然后再增加视觉课程。灾难性遗忘CF行为是使用新的评估程序来衡量的,该程序旨在以增量学习的应用为导向的观点。特别是,它强制要求仅对初始数据集执行模型选择,并且要求仅使用再训练数据集执行再训练控制,因为初始数据集通常太大而无法保存。使用各种不同的DNN模型对来自MNIST的类增量问题进行了实验,其中一些最近提出以避免灾难性遗忘。当我们将新的评估程序与之前评估CF的方法进行比较时,我们发现他们的发现被完全否定了,并且所有测试方法都不能在所有实验中避免使用CF.这强调了灾难性遗忘的现实经验测量程序的重要性,以及DNN增量学习的进一步研究的必要性。 |
| Testing Deep Neural Network based Image Classifiers Authors Yuchi Tian, Ziyuan Zhong, Vicente Ordonez, Baishakhi Ray 图像分类是当今世界的一项重要任务,具有从社会技术到安全关键领域的许多应用。最近深度神经网络DNN的出现是这种广泛传播成功的关键。然而,如此广泛的采用伴随着对这些系统可靠性的担忧,因为在许多敏感和危急情况下已经报告了几种错误行为。因此,严格测试图像分类器以确保高可靠性变得至关重要。许多报告在流行的神经图像分类器中出现错误的情况是因为模型经常将一个类别与另一个类别混淆,或者对某些类别显示偏见而不是其他类别。这些错误通常会违反某些组属性。大多数现有的DNN测试和验证技术都关注每个图像违规,因此无法检测到这种群组级别的混淆或偏见。在本文中,我们设计,实现和评估DeepInspect,一种白盒测试工具,用于自动检测DNN驱动的图像分类应用程序的混淆和偏差。我们使用流行的基于DNN的图像分类器评估DeepInspect,并检测数百个分类错误。其中一些案例能够揭示网络对某些人群的潜在偏见。 DeepInspect进一步报告了最先进的健壮模型中的许多分类错误。 |
| Spatio-Temporal Adversarial Learning for Detecting Unseen Falls Authors Shehroz S. Khan, Jacob Nogas, Alex Mihailidis 从健康和机器学习的角度来看,跌倒检测是一个重要的问题。在某些情况下,跌倒可能导致严重伤害,长期损伤甚至死亡。在机器学习方面,由于很少发生跌倒,因此很少或根本没有跌倒训练数据,因此会出现严重的类别不平衡问题。在本文中,我们采用另一种理念来检测缺少训练数据时的跌倒,通过仅对可用的正常活动进行训练,并将跌倒识别为异常。为了实现这样的分类器,我们使用对抗性学习框架,其包括用于重建输入视频帧的空间时间自动编码器和用于将它们与原始视频帧区分开的时空卷积网络。 3D卷积用于从输入视频帧学习空间和时间特征。空间时间自动编码器的对抗性学习将使得能够有效地重建日常生活的正常活动,从而使得在该框架内检测到看不见的看起来是合理的。我们测试了所提出的框架在相机感应模式上的性能,这些模式可以完全或部分地保护个人的隐私,例如热和相机深度。我们对三个公开可用数据集的结果表明,所提出的时空对抗框架的表现优于其他基于框架或空间对抗性学习方法。 |
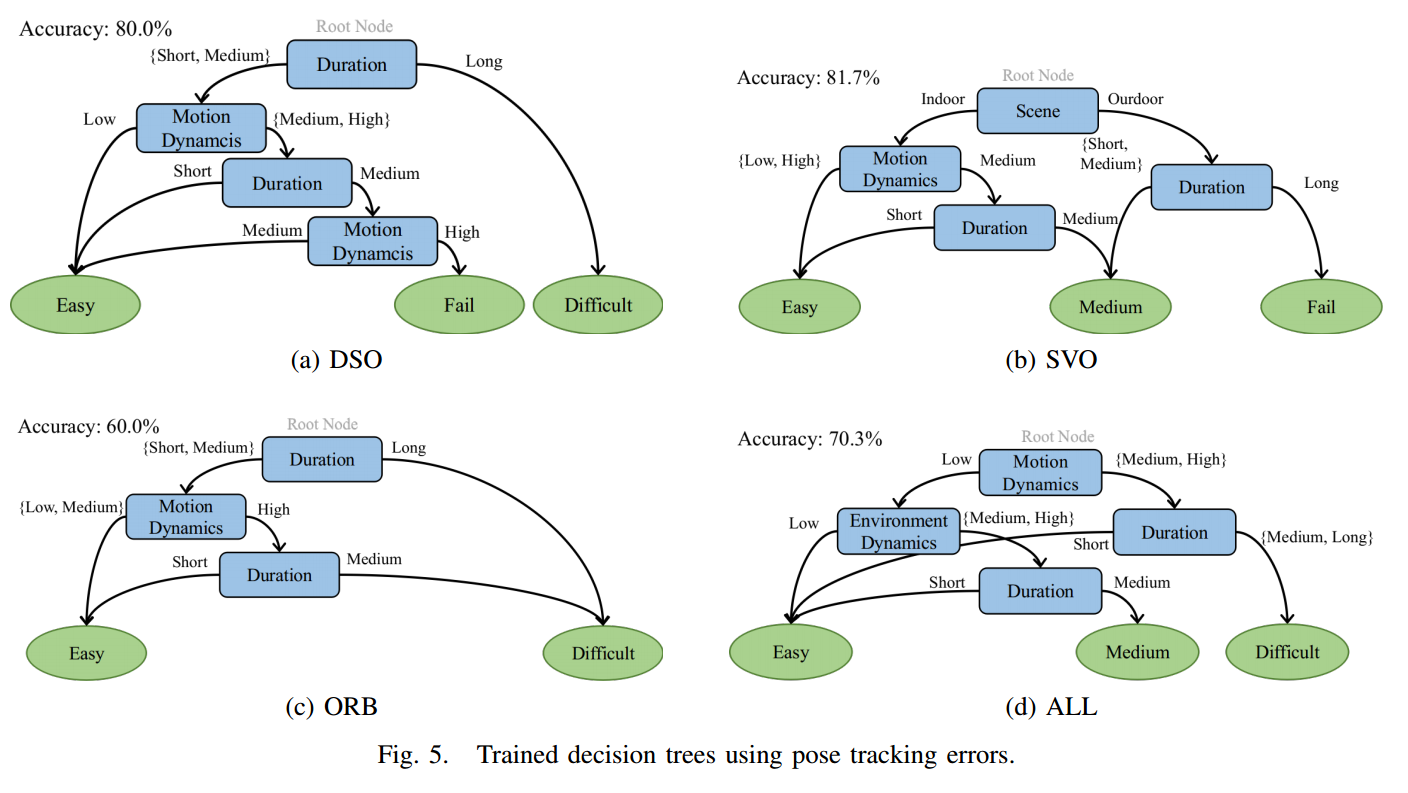
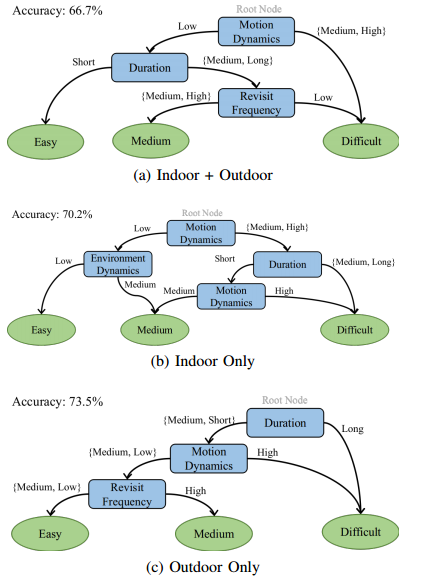
| Characterizing SLAM Benchmarks and Methods for the Robust Perception Age Authors Wenkai Ye, Yipu Zhao, Patricio A. Vela SLAM基准测试的多样性提供了对SLAM算法的广泛测试,以便单独或相对地了解它们的性能。这些基准的临时创建并不一定能够在评估性能时阐明SLAM算法的特定弱点。在本文中,我们建议使用决策树来确定最先进的SLAM算法的挑战性基准属性以及SLAM管道中关于其应对这些挑战的能力的重要组件。如果我们要对强大的SLAM算法的核心计算需求有深刻的理解,那么确定特定序列的哪些因素导致相对于这些特征的跟踪失败或降级是重要的。同样,我们认为在分析基准时使用各个SLAM组件的计算性能非常重要。特别是,我们提倡在ROS包播放期间使用时间膨胀,或者我们称之为慢动作播放。使用slo mo来对SLAM实例进行基准测试可以提供有关如何在计算组件级别改进SLAM实现的线索。我们自己的三种流行的VO SLAM算法和两种低延迟算法在选定的典型序列上进行测试,这些序列是通过基准表征生成的,以进一步证明从计算高效组件中获得的好处。 |
| Low-latency Visual SLAM with Appearance-Enhanced Local Map Building Authors Yipu Zhao, Wenkai Ye, Patricio A. Vela 本地地图模块通常在现代VO VSLAM系统中实现,以改善数据关联和姿势估计。传统上,本地地图内容由共同可见性确定。虽然协同可见性建立起来很便宜,但它利用了之前看到的相对较弱的时间,现在很可能看到,因此允许更多的特征进入本地地图而不是必要的。本文通过结合先前的强大外观描述了对可见度本地地图构建的增强,这导致更紧凑的本地地图和下游数据关联中的延迟减少。从当前图像收集的先前外观影响局部地图内容,仅视觉上类似于当前测量的地图特征可能对数据关联有用。为此,使用Multi index Hashing MIH索引和查询映射的功能。开发了在线哈希表选择算法以进一步减少MIH的查询开销和本地映射大小。所提出的基于外观的本地地图构建方法被集成到现有技术的VO VSLAM系统中。在两个公共基准评估时,本地地图的大小以及VO VSLAM中实时姿势跟踪的延迟显着降低。同时,VO VSLAM的平均性能得以保留或提高。 |
| Leveraging Semantic Embeddings for Safety-Critical Applications Authors Thomas Brunner, Frederik Diehl, Michael Truong Le, Alois Knoll 语义嵌入是在零射击学习领域中表示知识的流行方式。我们观察它们的可解释性并讨论它们在安全关键环境中的潜在效用。具体地说,我们建议使用它们为神经网络分类器添加内省和错误检测功能。首先,我们将展示如何从符号领域知识创建嵌入。我们讨论如何使用它们来解释错误预测并提出一种简单的错误检测方案。然后,我们引入语义距离的概念,这是衡量语义空间置信度的真实值得分。我们在交通标志分类器上评估此分数,并发现它达到了近乎最先进的性能水平,同时计算速度明显快于其他置信度分数。我们的方法不需要对原始网络进行任何更改,因此适用于可获得领域知识的任何任务。 |
| An Objective Evaluation Metric for image fusion based on Del Operator Authors Ali A. Kiaei, Hassan Khotanlou, Paniz Kiaei, Yasin Bhrouzi, Mahdi Abbasi 本文提出了一种新的图像融合客观评价指标。所提出的度量的显着且有吸引力的点是它没有参数,结果是在0,1的范围内的概率并且它没有照明依赖性。该指标易于实现,结果分四步计算1使用高斯滤波器平滑图像。 2使用Del运算符将图像转换为矢量场。 3计算每个对应像素的正态分布函数mu,sigma,并转换为标准正态分布函数。 4计算结果表现良好的融合方法的概率。为了判断所提出的度量的质量,将其与十三个众所周知的非参考客观评估度量进行比较,其中八个融合方法被用于多模态医学图像的七个实验。实验结果和统计比较表明,与先前客观的评估指标相比,所提出的评估指标在同意人类视觉感知和评估不在同一水平上执行的融合方法方面表现更好。 |
| Multinomial Distribution Learning for Effective Neural Architecture Search Authors Xiawu Zheng, Rongrong Ji, Lang Tang, Baochang Zhang, Jianzhuang Liu, Qi Tian 通过Neural Architecture Search NAS获得的架构在各种计算机视觉任务中获得了极具竞争力的性能。然而,深度神经网络中前向后向传播的禁止计算需求和搜索算法使得在实践中难以应用NAS。在本文中,我们提出了一种针对极其有效的NAS的多项分布学习,它将搜索空间视为联合多项分布,即从该分布中对两个节点之间的操作进行采样,并通过以下操作获得最优网络结构。这种分布中最有可能的概率。因此,NAS可以转换为多项分布学习问题,即,优化分布以具有高性能期望。此外,提出并证明了在每个训练时期中表现等级一致的假设,以进一步加速学习过程。 CIFAR 10和ImageNet上的实验证明了我们的方法的有效性。在CIFAR 10上,通过我们的方法搜索的结构实现了2.4测试错误,而与最先进的NAS算法相比,在GTX1080Ti上只有4个GPU小时的6.0倍。在ImageNet上,我们的模型在MobileNet设置MobileNet V1 V2下实现了75.2的前1精度,而在测量的GPU延迟方面则快了1.2倍。测试代码可在 |
| Rethinking Atmospheric Turbulence Mitigation Authors Nicholas Chimitt, Zhiyuan Mao, Guanzhe Hong, Stanley H. Chan 现有技术的大气湍流图像恢复方法利用标准图像处理工具,例如光流,幸运区和盲去卷积来恢复图像。尽管在过去十年中已经报道了有希望的结果,但许多方法对产生失真的物理模型是不可知的。在本文中,我们通过分析典型恢复管道中的参考帧生成和盲去卷积步骤来重新审视湍流恢复问题。通过利用大偏差理论中的工具,我们严格证明了为静态和动态场景生成可靠参考所需的最小帧数。我们讨论了湍流不可知模型如何导致潜在的缺陷,以及如何配置简单的空间时间非局部加权平均方法来生成参考。对于盲解卷积,我们通过分析点扩散函数的分布来呈现先前驱动的新数据。我们演示了一个简单的先验如何能够胜过最先进的盲解卷积方法。 |
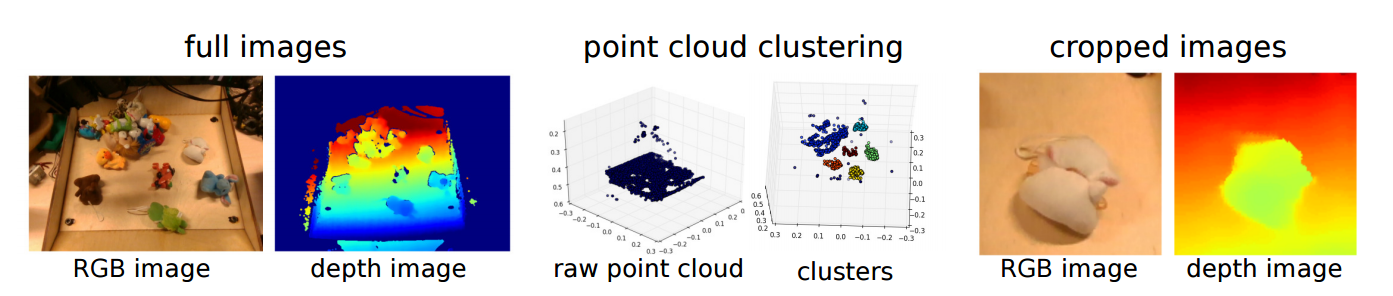
| REPLAB: A Reproducible Low-Cost Arm Benchmark Platform for Robotic Learning Authors Brian Yang, Jesse Zhang, Vitchyr Pong, Sergey Levine, Dinesh Jayaraman 标准化的评估措施有助于计算机视觉和机器翻译等学科的机器学习方法的进步。在本文中,我们假设机器人学习也将受益于基准测试,并提出了用于基于视觉的操作任务基准测试的REPLAB平台。 REPLAB是一个可重复且独立的硬件堆栈机器人手臂,摄像头和工作空间,成本约2000美元,占据70x40x60厘米的长方体,并允许在几个小时内完全组装。通过这种低成本,紧凑的设计,REPLAB旨在通过降低进入机器人技术的门槛以及轻松扩展到许多机器人来推动广泛参与。我们设想REPLAB作为跨越操作任务的可重复研究的框架,作为这个方向的一个步骤,我们定义了一个抓取基准的模板,包括任务定义,评估协议,性能测量和92k抓取尝试的数据集。我们实施,评估和分析以前提出的几种抓取方法,以便为此基准建立基线。最后,我们还在REPLAB平台上实现并评估了用于3D到达任务的深度强化学习方法。包含装配说明,代码和视频的项目页面 |
| Galaxy Zoo: Probabilistic Morphology through Bayesian CNNs and Active Learning Authors Mike Walmsley, Lewis Smith, Chris Lintott, Yarin Gal, Steven Bamford, Hugh Dickinson, Lucy Fortson, Sandor Kruk, Karen Masters, Claudia Scarlata, Brooke Simmons, Rebecca Smethurst, Darryl Wright 我们使用贝叶斯卷积神经网络和Galaxy Zoo志愿者反应的新型生成模型来推断后代的星系视觉形态。贝叶斯CNN可以从具有不确定标记的星系图像中学习,然后,对于先前未标记的星系,预测每个可能标记的概率。我们的后代经过了很好的校准,例如对于预测条形,我们在5个响应中实现了10.6的覆盖误差,在10个响应中实现了2.9,因此在实际应用中是可靠的。此外,使用我们的后代,我们应用主动学习策略BALD来请求针对星系子集的志愿者响应,如果标记,将对培训我们的网络提供最多信息。我们表明,使用主动学习训练我们的贝叶斯CNN需要多达35 60个标记星系,这取决于被分类的形态特征。通过结合人机智能,Galaxy Zoo将能够在几周的时间范围内对任何可想到的规模的调查进行分类,提供大量详细的形态目录,以支持对星系演化的研究。 |
| Chinese Abs From Machine Translation |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}