
【今日CV 计算机视觉论文速览 第121期】Thu, 30 May 2019
今日CS.CV 计算机视觉论文速览
Thu, 30 May 2019
Totally 41 papers
👉上期速览✈更多精彩请移步主页

Interesting:
📚利用多通道连续性规范实现图像迁移, 对于图像迁移现有的方法主要分为辨别生成图像与真实图像间的损失,或者真实与重建图像检测重建损失来进行,新方法提出了一种多通道的连续损失,同时测评了直接迁移和间接迁移(引入了辅助域)来规范训练。在人脸迁移、图像风格迁移、去雨滴去噪中取得了很多好的效果。多通道连续损失可以充分利用多个域信息来正则化训练过程,未来可以做三个甚至更多的通道和随机辅助域。(from 中科大)
增加多路连续损失的模型:
一些结果:

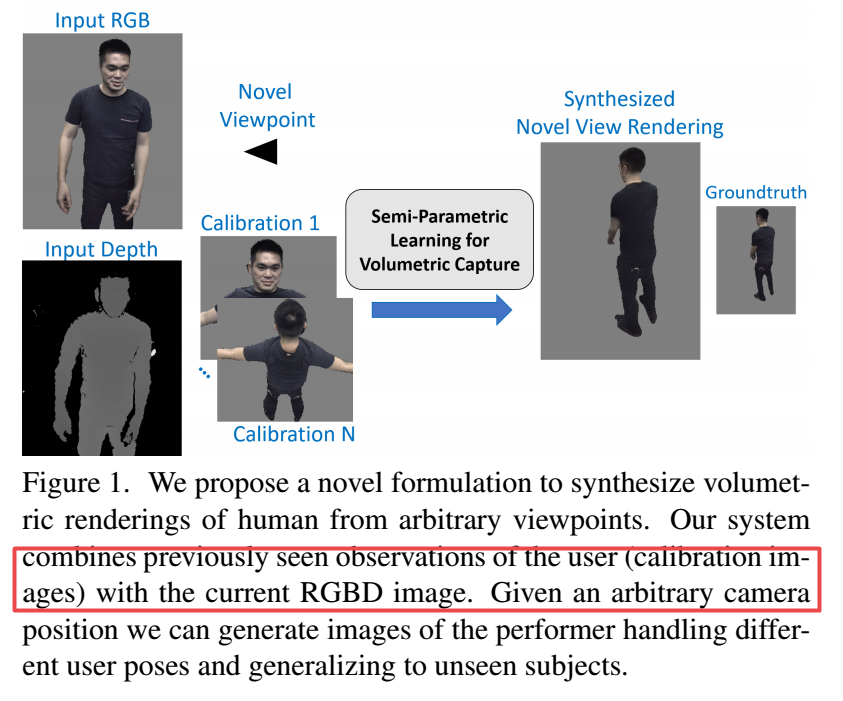
📚基于单RGBD实现新视角人体三维渲染数据生成, 将先前看到的“标定”图像应用于新视角渲染的外插。实现了端到端的新视角生成。(from Google)
 系统中包含的四个模块,分别是渲染、位置检测,标题图像选择器、标定图像仿射变换、自然融合
系统中包含的四个模块,分别是渲染、位置检测,标题图像选择器、标定图像仿射变换、自然融合
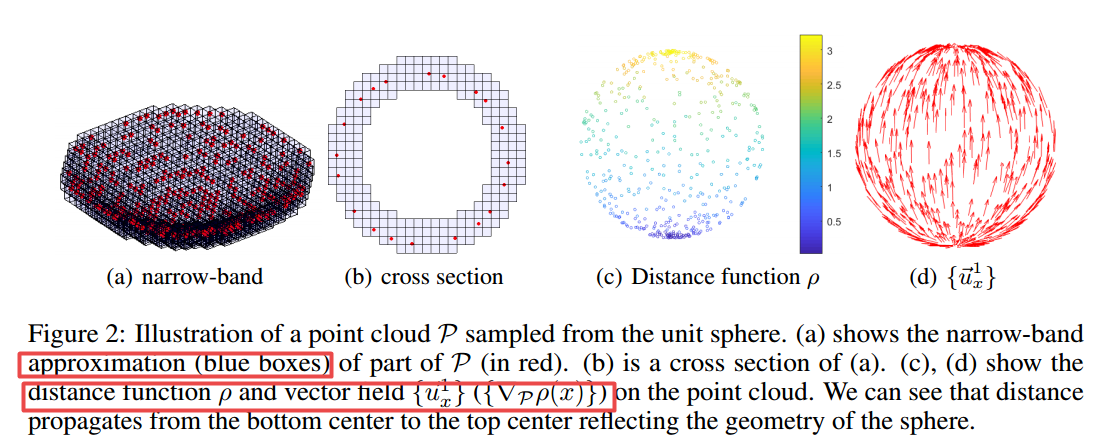
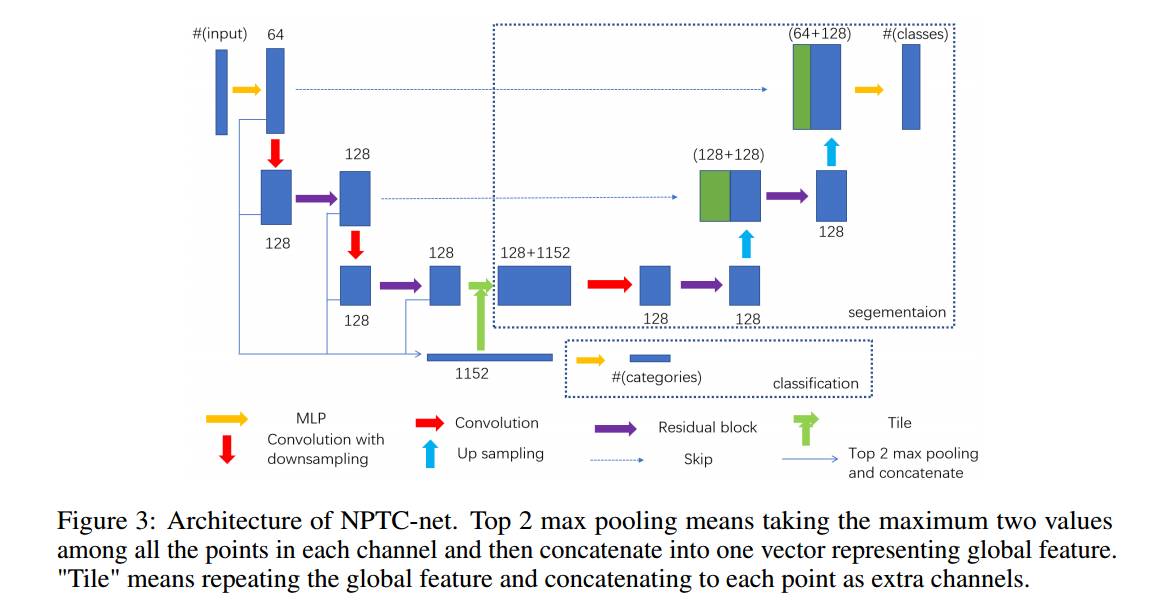
📚NPTC-net用于点云的窄带并行输运CNN, 在流型结构的点云上设计合适的卷积结构可以将最近CNN的优点应用于点云的分析处理上。但主要的挑战来自于设计合适的扫描滤波器来反映出点云的几何特征。在这篇论文中研究人员采用了并行输运理论,并给予三角化的方法提出了BPTC,利用特定的体素链接来进行点云数据,并基于NPTC实现了网络记性点云分类和分割。主要的特征在与将核的定义转移到正切面上。(from 北大)
一个实现的架构:
点云中的特征可视化,黄色是激活较高的部分:

📚GraphCNN denoiser基于图卷积的图像去噪, 基于卷积操作的去噪方法局限于局部特征,研究人员提出了图卷积方法来探索局域与非局域特征,在特征空间中动态构建领域信息,并检测特征图间的隐关系。(from Politecnico di Torino, Italy)
下图展示了网络的架构,其中c为2D卷积,R为LeakReLU,GC为图卷积NLG为(特征空间中最邻近领域)非局域图构建。BN为批归一化。
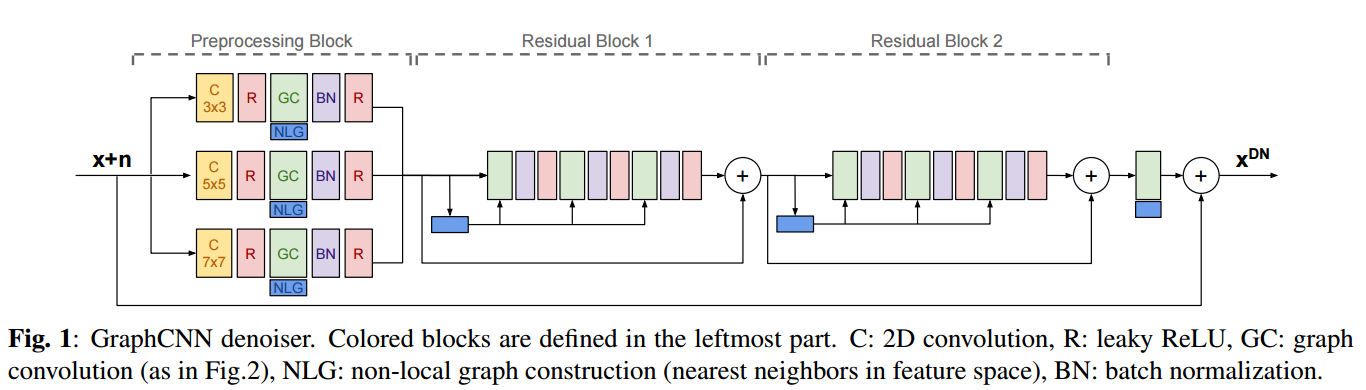
一些图像超分辨的结果:

dataset:BSD500 dataset
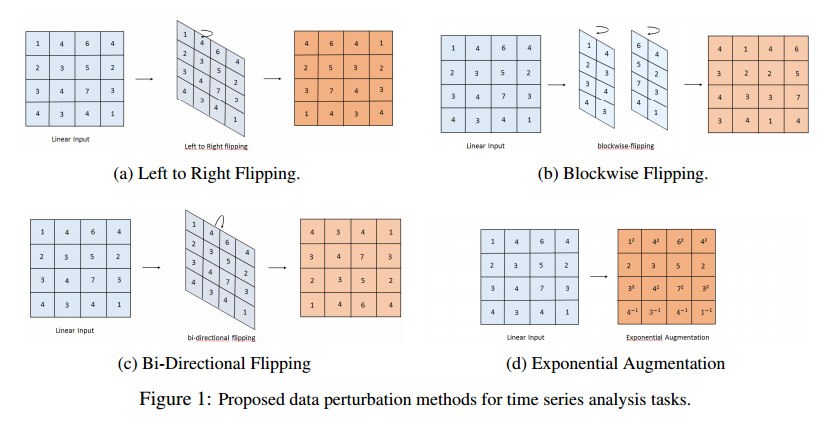
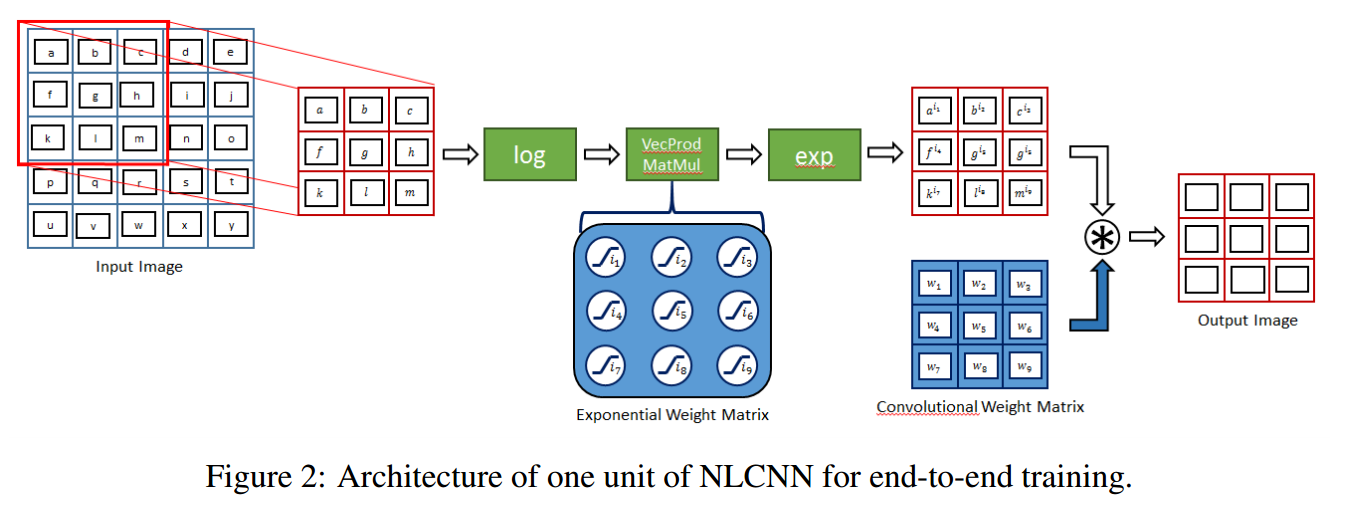
📚学习CNN中的非线性NLCNN, 研究人员提出了在卷积网络中实现非线性,不仅用于数据增强过程,同时也应用在了指数操作的非线性卷积上。在时间序列分析中实现了较好的效果。(from South Westfalia University of Applied Science Soest, Germany )
一些非线性操作:
非线性卷积的模型架构:
ref: http://web.mit.edu/braatzgroup/links.html
Tennessee Eastman Problem 模拟数据
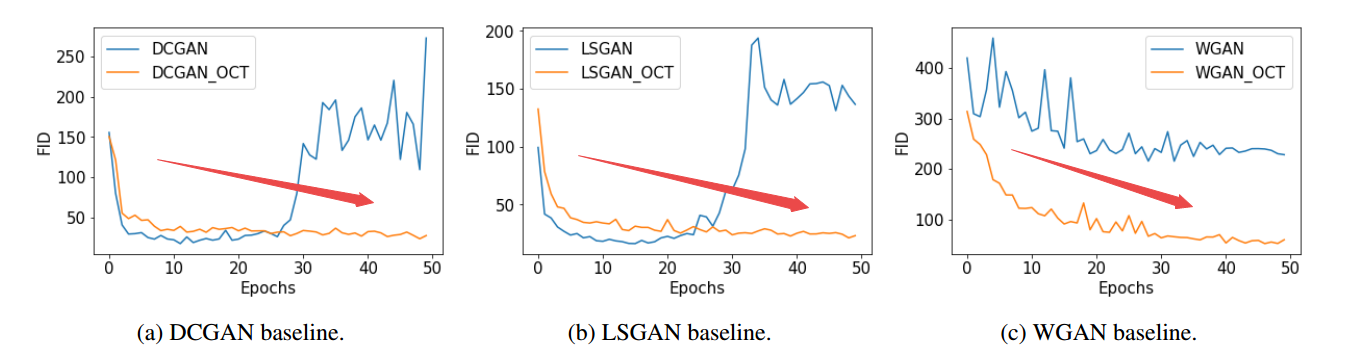
📚利用Octave卷积稳定GANs, 在卷积频域分解的启发下研究人员提出了稳定GANs训练减小模型崩溃风险的机制,通过将高频与低频的部分进行增量式的分离,并(更新低频的权重部分。这种方法使得GANs首先学习到了低频的粗糙部分随后再学习精细部分。这种方法与现有方法独立且互补。(from 夫琅禾费研究所ITWM, Germany)
显示了不同比重的低频与高频参数
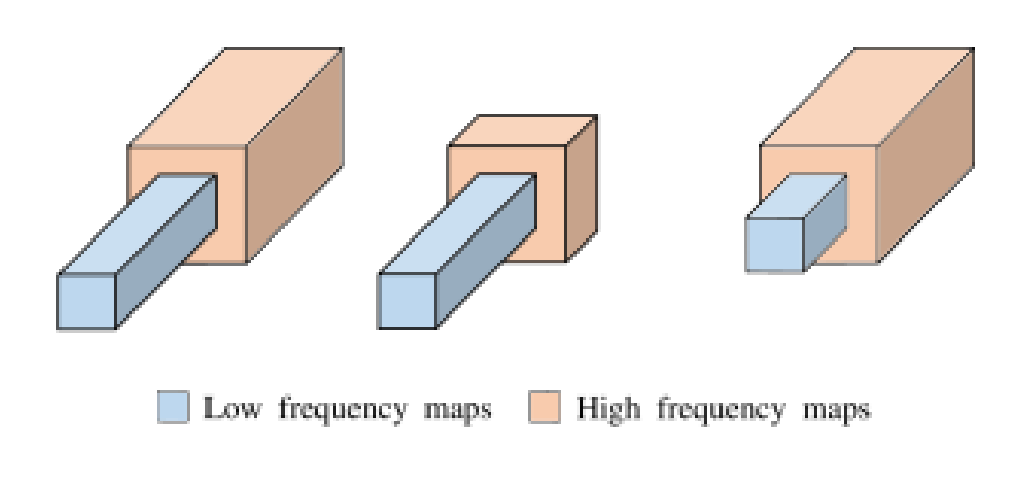
稳定的训练过程:
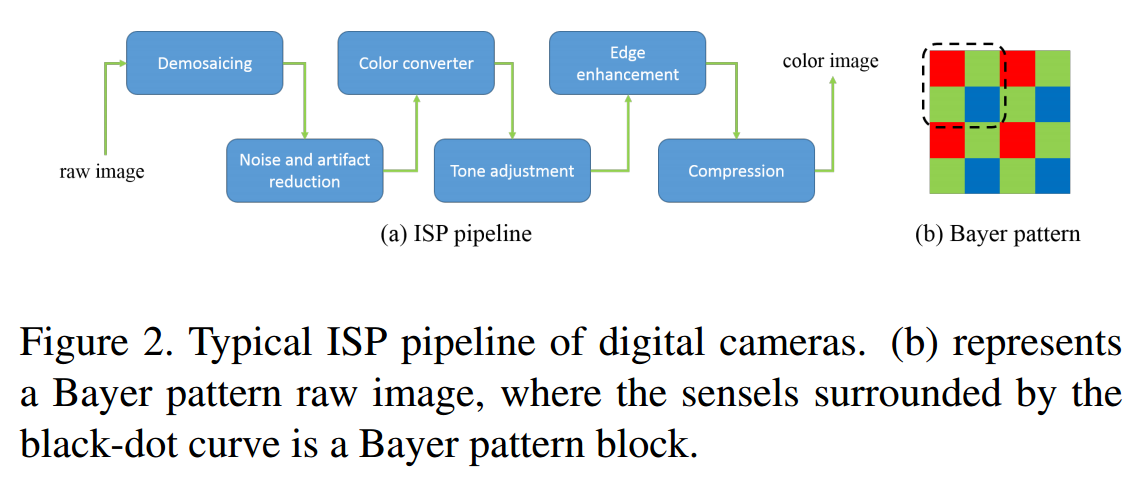
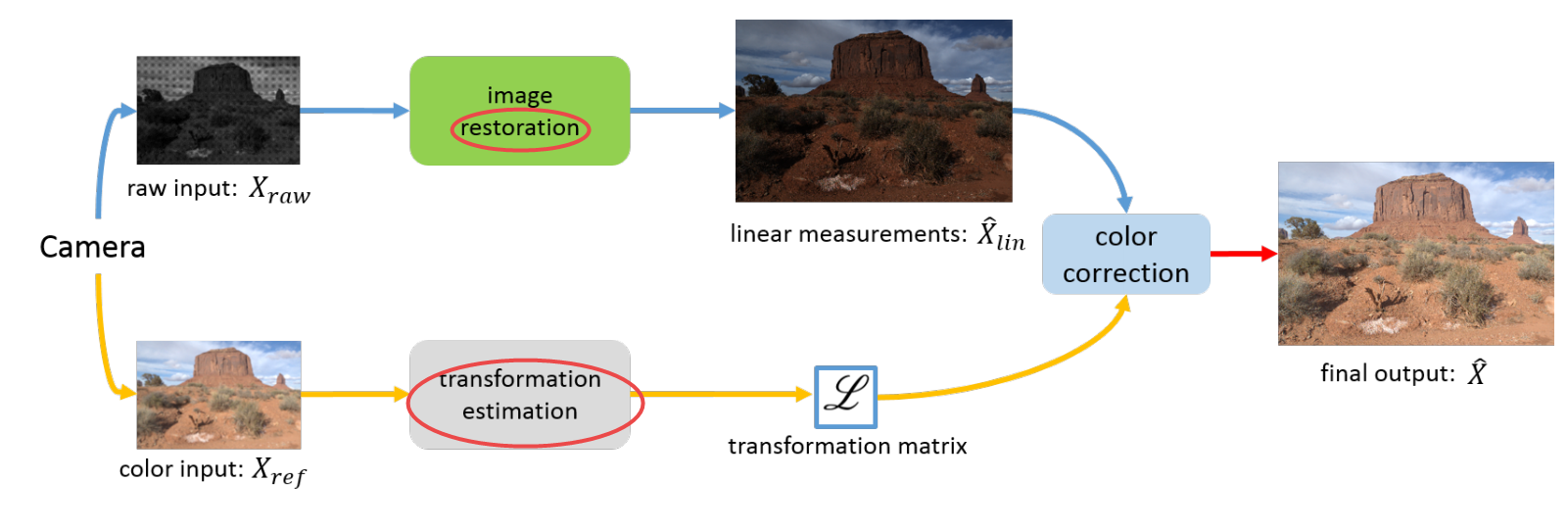
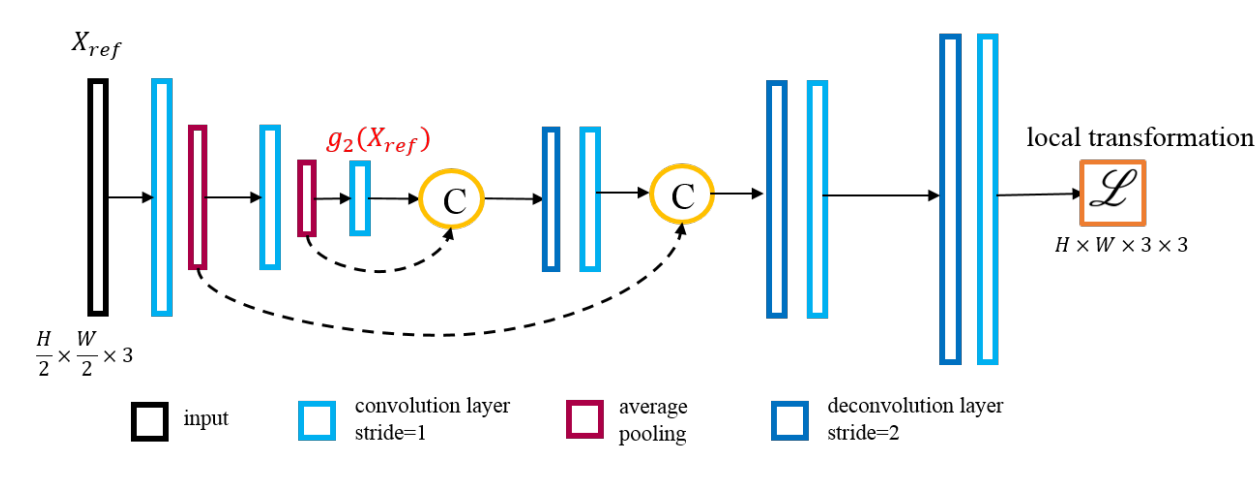
📚基于原始数据的自然图像超分辨算法, 提出了一种新方法通过模型数码相机的成像过程用于生成训练数据,生成的超分辨图像更为锐利,随后基于双卷积模型探索了原始图像的辐照信息来恢复更多的细节。最后提出了空间变分颜色转换来实现更有效的颜色纠正,解决了模型输入的真实训练数据缺失和信息丢失。(from SenseTime Research)
典型的影像信号处理过程ISP:
模型提出的架构如图所示,其中一个分支用于探索原始输入到高分辨线性测量的恢复、让细节和结构更清晰,第二个分支估计转换矩阵来对恢复颜色结果:
图像修复分支的细节,重建了高分辨率图像和颜色测量:
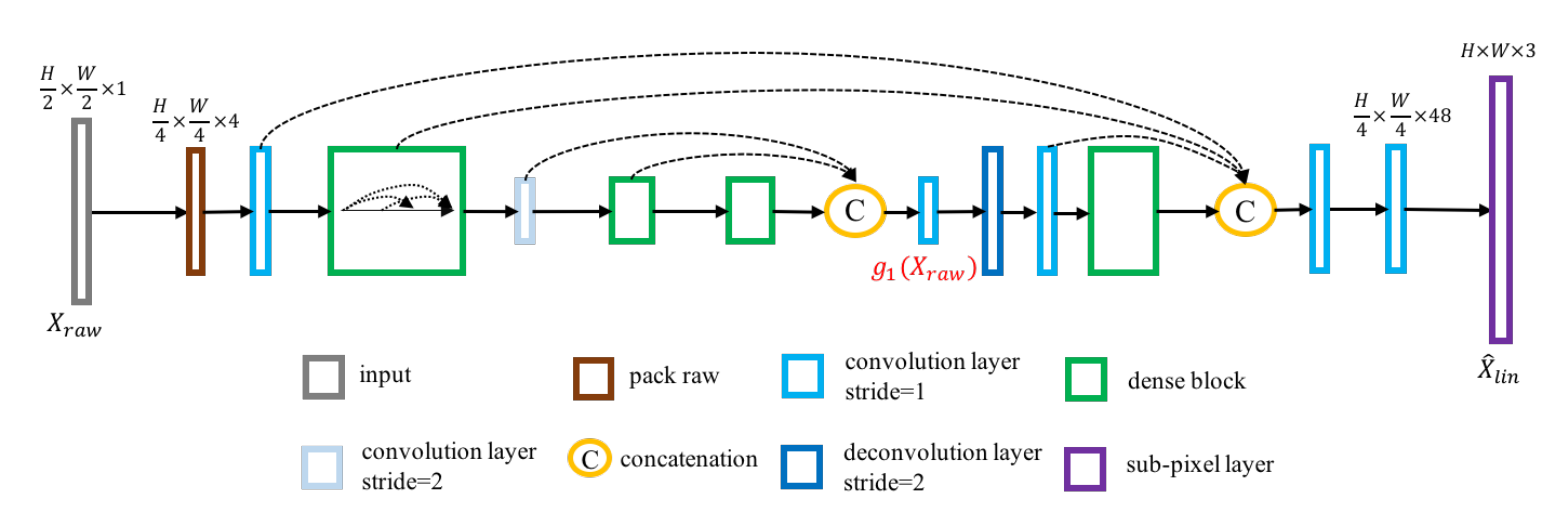
颜色修正分支的网络架构,针对每个像素的颜色修正矩阵:
一些结果:
包含raw的datsset:MIT-Adobe 5K dataset, V. Bychkovsky, S. Paris, E. Chan, and F. Durand. Learning photographic global tonal adjustment with a database of input/output image pairs. In CVPR, 2011. 2, 3, 5, 7
📚SpArSe,用于微处理器MCU模型的稀疏架构搜索方法, 为了在资源极其受限的微处理器上部署CNN,研究人员提出了一种自动的通用CNN架构设计方法,可以用于很小的MCU上。这种稀疏架构搜索方法结合了神经架构搜索和剪枝,并在四个典型的IOT数据集上进行了先验模型学习。(from ARM ML Research,Princeton University)
典型的MCU计算和内存情况:

典型的微处理器模型大小:
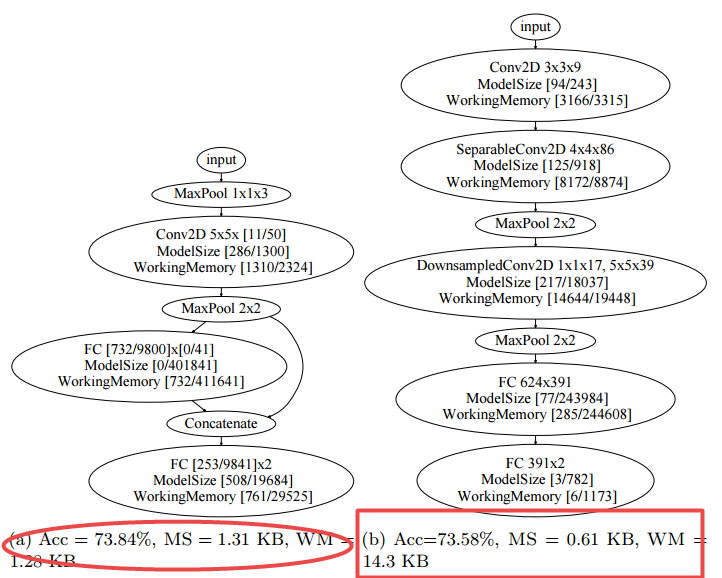
优化后的模型大小和性能:

SOTA works: Bonsai [41], ProtoNN [32], Gradient Boosted Decision Tree Ensemble Pruning [22], kNN, and radial basis function support vector machine (SVM).
dataset: MNIST, CIRFA10, 自然字符识别数据集Chars74k dataset,CUReT反射和纹理数据集,多种纹理数据集:https://qixianbiao.github.io/Texture.html
📚纹理卷积网络用于热电管道内部腐蚀分类检测, 这个网络包含两层卷积和一层能量层,用于从最后一层卷积中pooling出特征图。(from Technische Hochschule Ingolstadt)
基于滑动窗口法对于图像片进行分类:
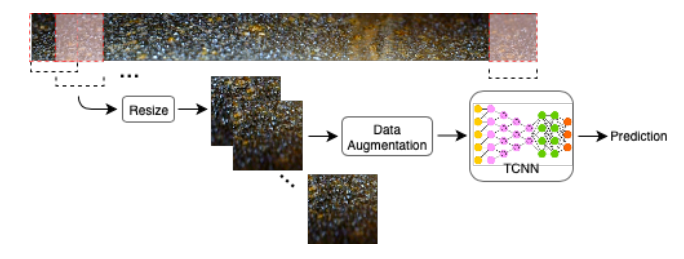
正常、腐蚀、加速腐蚀的样本:

ref:T-CNN proposed by Andrearczyk and Whelan [8]
Daily Computer Vision Papers
| Flat2Layout: Flat Representation for Estimating Layout of General Room Types Authors Chi Wei Hsiao, Cheng Sun, Min Sun, Hwann Tzong Chen 本文提出了一种新方法Flat2Layout,用于从单视图RGB图像估计一般室内房间布局,而现有方法只能生成从箱形房间捕获的布局拓扑。所提出的平面表示将布局信息编码成行向量,其被视为深度模型的训练目标。基于动态编程的后处理用于将从深模型估计的平坦输出解码到最终房间布局。 Flat2Layout在现有的房间布局基准上实现了最先进的性能。本文还构建了一个基准,用于验证一般布局拓扑的性能,其中Flat2Layout在一般房间类型上实现了良好的性能。 Flat2Layout适用于更多场景布局估算,会对场景建模,机器人和增强现实的应用产生影响。 |
| Smooth Shells: Multi-Scale Shape Registration with Functional Maps Authors Marvin Eisenberger, Zorah L hner, Daniel Cremers 我们提出了一种基于所谓的光滑壳的迭代对准的新颖的3D形状对应方法。平滑壳定义了一系列粗到细,平滑的形状近似,旨在与多尺度算法一起使用。在本文中,我们在对齐光滑壳和计算输入之间的功能映射之间进行交替。对齐非常平滑的近似降低了整个过程的复杂性,但是在迭代期间,壳中的细节量增加,这有助于细化所得到的对应关系。此外,我们通过应用基于代理的马尔可夫链蒙特卡罗初始化来解决内在对称性的模糊问题。我们在几个关注等距,拓扑变化和不同连通性的数据集上显示了最新的定量结果。此外,我们还展示了具有挑战性的类间对的定性结果。 |
| GlyphGAN: Style-Consistent Font Generation Based on Generative Adversarial Networks Authors Hideaki Hayashi, Kohtaro Abe, Seiichi Uchida 在本文中,我们提出了基于生成对抗网络GAN的GlyphGAN风格一致字体生成。 GAN是使用两个相互竞争的神经网络系统来学习生成模型的框架。一个网络从随机输入矢量生成合成图像,另一个网络区分合成图像和真实图像。本研究的动机是使用GAN框架创建新字体,同时保持所有字符的样式一致性。在GlyphGAN中,生成器网络的输入向量由两个向量字符类向量和样式向量组成。前者是一个热矢量,并且在训练期间与每个样本图像的角色类相关联。后者是没有监督信息的均匀随机向量。通过这种方式,GlyphGAN可以生成各种各样的字体,其字符和样式可以独立控制。实验结果表明,GlyphGAN生成的字体具有与训练图像不同的风格一致性和多样性,而不会失去其易读性。 |
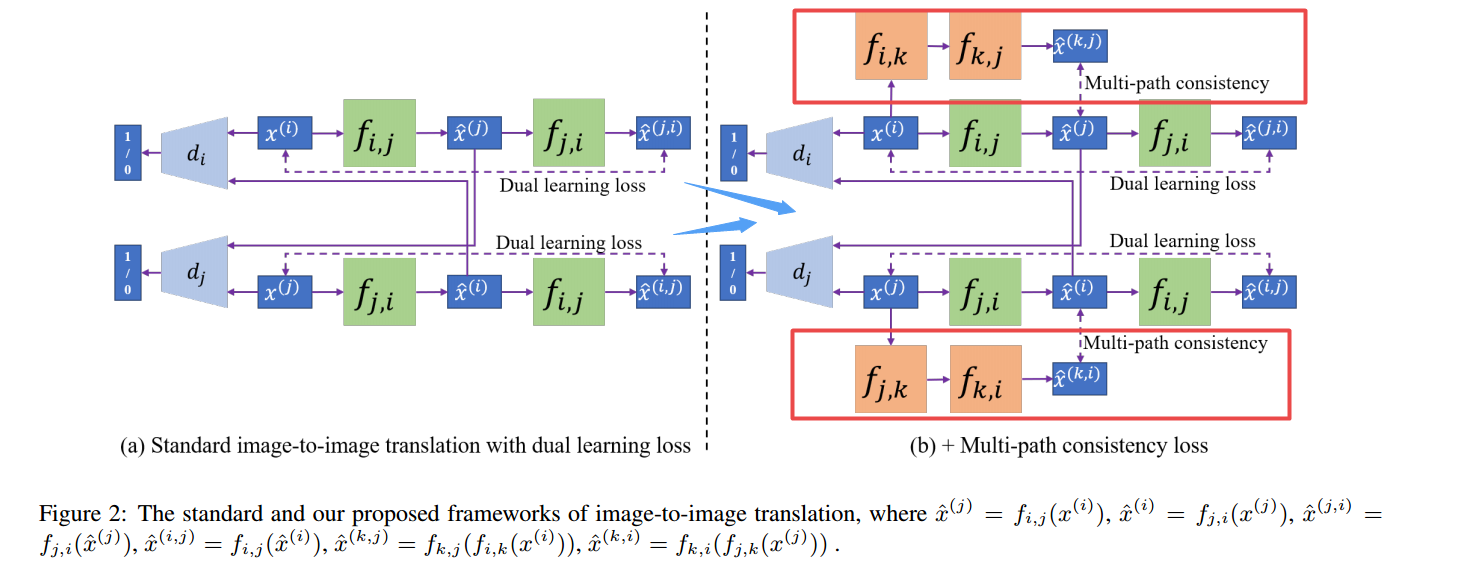
| Image-to-Image Translation with Multi-Path Consistency Regularization Authors Jianxin Lin, Yingce Xia, Yijun Wang, Tao Qin, Zhibo Chen 不同领域的图像翻译在机器学习和计算机视觉社区中引起了很多关注。以源域mathcal D s的转换为目标域mathcal D t为例,现有算法主要依靠两种损失进行训练。一种是判别丢失,用于区分模型生成的图像和自然图像。另一个是重建损失,它通过mathcal D s到mathcal D t到mathcal D s转换来测量原始图像和重建版本之间的差异。在这项工作中,我们引入了一种新的损失,多路径一致性损失,它评估直接翻译mathcal D s与mathcal D t和间接翻译mathcal D s与mathcal D a到mathcal D t之间的差异,其中mathcal D a as辅助领域,规范培训。对于至少三个域的翻译,三个侧重于在任意两个域之间构建翻译模型,在每次训练迭代时,我们随机选择三个域,分别将它们设置为源域,辅助域和目标域,构建多路径一致性丢失和优化网络。对于两个域转换,我们需要引入一个额外的辅助域并构造多路径一致性丢失。我们进行了各种实验来证明我们提出的方法的有效性,包括面对面翻译,绘画到照片翻译和de raining de noising翻译。 |
| Hierarchical Feature Aggregation Networks for Video Action Recognition Authors Swathikiran Sudhakaran, Sergio Escalera, Oswald Lanz 大多数动作识别方法基于使用平均合并,最大合并或RNN等的帧级CNN特征的后期聚合,或者基于3D卷积的时空聚合。第一个假设帧之间的独立性特征直到一定程度的抽象,然后执行更高级别的聚合,而第二个从分组帧中提取空间时间特征作为早期融合。在本文中,我们通过让相邻的特征分支在它们发展成更高层次的表示时相互作用来探索这两者之间的空间。相互作用发生在特征差分和层次结构的每个级别的平均之间,并且它具有卷积结构,其学习在本地选择适当的模式,而不是先前的工作,其全局地施加一个模式,例如。特征差分作为设计选择。我们进一步限制这种相互作用是保守的,例如一个分支中的局部特征减法通过在另一个分支上的相加来补偿,从而保留总特征流。我们评估了我们的提案在许多现有模型(即TSN,TRN和ECO)上的表现,以显示其在提高行动识别性能方面的灵活性和有效性。 |
| Instance-Aware Representation Learning and Association for Online Multi-Person Tracking Authors Hefeng Wu, Yafei Hu, Keze Wang, Hanhui Li, Lin Nie, Hui Cheng 多人跟踪MPT通常在检测到关联范例内得到解决。在这样的方法中,首先在每个帧中提取人类检测,然后通过通常离线的数据关联过程来恢复人类轨迹。然而,它们的性能通常在存在检测错误,相互作用和遮挡的情况下退化。在本文中,我们提出了一种基于深度学习的MPT方法,该方法可以学习被跟踪人员的实例感知表示,并在线强有力地推断被跟踪人员的状态。具体来说,我们设计了一个多分支神经网络MBN,它通过将一批候选区域作为输入来预测所有目标的分类置信度和位置。在我们的MBN架构中,每个分支实例子网对应于要跟踪的个体,并且可以动态创建新分支以处理新出现的人。然后,基于MBN的输出,我们构建联合关联矩阵,其表示被跟踪人的有意义状态,例如,从场景中被跟踪或消失并通过使用有效的匈牙利算法来解决它。此外,我们允许在跟踪期间通过在线挖掘硬件示例来更新实例子网,并考虑到人物外观随时间的变化。我们在流行的MPT基准测试中全面评估我们的框架,与最近的在线MPT方法相比,它展示了其出色的性能。 |
| Coherent Semantic Attention for Image Inpainting Authors Hongyu Liu, Bin Jiang, Yi Xiao, Chao Yang 最新的基于深度学习的方法已经显示出有希望的结果,用于修复图像的缺失区域的挑战性任务。然而,由于局部像素的不连续性,现有方法经常产生具有模糊纹理和失真结构的内容。从语义层面来看,局部像素不连续性主要是因为这些方法忽略了孔区域的语义相关性和特征连续性。为了解决这个问题,我们研究了修复图片中的人类行为,并提出了一种基于精细深度生成模型的方法,该方法具有新颖的连贯语义关注CSA层,不仅可以保留上下文结构,而且可以通过建模来更有效地预测缺失部分。孔特征之间的语义相关性。任务分为粗略,细化为两个步骤,并在U Net架构下使用神经网络对每个步骤进行建模,其中CSA层嵌入到精化步骤的编码器中。为了稳定网络训练过程并促进CSA层学习更有效的参数,我们提出了一致性损失来强制CSA层和解码器中CSA的相应层都接近基础事实的VGG特征层同时形象。 CelebA,Places2和Paris StreetView数据集上的实验已经验证了我们提出的方法在图像修复任务中的有效性,并且与现有技术方法相比可以获得具有更高质量的图像。 |
| Disentangling Monocular 3D Object Detection Authors Andrea Simonelli, Samuel Rota Rota Bul , Lorenzo Porzi, Manuel L pez Antequera, Peter Kontschieder 在本文中,我们提出了一种从单个RGB图像中进行单眼三维物体检测的方法,该方法利用了2D和3D检测损失的新型解缠结变换以及3D边界框的新颖,自我监督的置信度分数。我们提出的损失解决方案具有双重优势,即在存在参数复杂相互作用的损失的情况下简化训练动力学,并回避平衡独立回归项的问题。我们的解决方案通过将参数组的贡献隔离到给定的损失而不改变其性质来克服这些问题。我们进一步将损失解开应用于另一个新的,签名的交叉联合标准驱动损失以改进2D检测结果。除了我们的方法创新,我们还批判性地审查了KITTI3D中使用的AP度量,它是用于比较3D检测结果的最重要的数据集。我们识别并解决11点插值AP度量中的缺陷,影响所有先前发布的检测结果,特别是偏向单眼3D检测的结果。我们对KITTI3D和nuScenes数据集进行了广泛的实验评估和消融研究,以大幅度为对象类别汽车设置了新的最先进的结果。 |
| Super Interaction Neural Network Authors Yang Yao, Xu Zhang, Baile Xu, Furao Shen, Jian Zhao 最近的研究表明,卷积网络严重依赖于生成特征的质量和数量。然而,在轻量级网络中,可用的特征信息有限,因为这些网络由于效率考虑而倾向于更浅和更薄。为了进一步提高轻量级网络的性能和准确性,我们从新颖的角度开发了超级交互神经网络SINet模型,增强了神经网络中的信息交互。为了实现沿深度网络宽度的信息交互,我们提出了Exchange快捷连接,它可以集成来自不同卷积组的信息,而无需任何额外的计算成本。然后,为了实现沿网络深度的信息交互,我们提出了基于密集漏斗层和注入的分层联合决策,它们能够充分利用中间层特征。我们的实验表明,SINet优于ImageNet数据集中其他最先进的轻量级模型。此外,我们还通过消融研究展示了我们提出的组件的有效性和普遍性。 |
| KG-GAN: Knowledge-Guided Generative Adversarial Networks Authors Che Han Chang, Chun Hsien Yu, Szu Ying Chen, Edward Y. Chang 生成性对抗网络GAN学习模仿代表基础真实数据分布的训练数据。然而,当训练数据缺乏数量或多样性时,GAN受到影响,因此不能很好地代表基础分布。为了提高在代表性训练数据分布下训练的GAN的性能,本文提出KG GAN将领域知识与GAN框架融合。 KG GAN训练两个发生器,一个从数据中学习,另一个从知识中学习。为了实现KG GAN,领域知识被制定为约束函数以指导第二生成器的学习。我们在两个任务细粒度图像生成和头发重新着色上验证我们的框架。实验结果证明了KG GAN的有效性。 |
| Vision-to-Language Tasks Based on Attributes and Attention Mechanism Authors Xuelong Li, Aihong Yuan, Xiaoqiang Lu 语言任务的愿景旨在将计算机视觉和自然语言处理结合在一起,这引起了许多研究人员的关注。对于典型方法,他们将图像编码为特征表示并将其解码为自然语言句子。虽然他们忽略了高级语义概念以及图像区域和自然语言元素之间的微妙关系。为了充分利用这些信息,本文试图利用文本引导注意和语义引导注意SA来寻找更相关的空间信息,减少视觉与语言之间的语义鸿沟。我们的方法包括两级关注网络。一个是文本引导注意网络,用于选择文本相关区域。另一个是SA网络,用于突出概念相关区域和区域相关概念。最后,所有这些信息都被合并以生成字幕或答案。实际上,已经进行了图像字幕和视觉问答实验,实验结果表明了该方法的优异性能。 |
| Kernel-Induced Label Propagation by Mapping for Semi-Supervised Classification Authors Zhao Zhang, Lei Jia, Mingbo Zhao, Guangcan Liu, Meng Wang, Shuicheng Yan 内核方法已成功应用于模式识别和数据挖掘领域。在本文中,我们主要讨论在内核空间中传播标签的问题。通过映射提出内核引发的标签传播内核LP框架,用于使用内核空间中信息最丰富的数据模式进行高维数据分类。 Kernel LP的本质是在变换的内核空间中执行联合标签传播和自适应权重学习。也就是说,我们的内核LP将标签传播的任务从大多数现有工作中常用的欧几里德空间改为内核空间。我们的内核LP通过假设输入的内积空间(即,原始线性不可分离的输入)共同传播标签和学习自适应权重的动机可被映射为在内核空间中是可分离的。内核LP基于现有的正和负LP模型,即,负标签信息的影响被集成以提高标签预测能力。此外,Kernel LP在相同的内核空间上执行自适应权重构造,因此它可以避免选择传统标准中所遇到的最佳邻域大小的棘手过程。还提出了两种新颖有效的样本方法,用于我们的内核LP涉及新的测试数据,即1个直接内核映射和2个内核映射诱导标签重建,这两者都纯粹依赖于训练集和测试集之间的核矩阵。由于内核技巧,我们的算法将适用于处理高维真实数据。真实数据集的广泛结果证明了我们的方法的有效性。 |
| NPTC-net: Narrow-Band Parallel Transport Convolutional Neural Network on Point Clouds Authors Pengfei Jin, Tianhao Lai, Rongjie Lai, Bin Dong 卷积在信号和图像处理,分析和识别的各种应用中起着至关重要的作用。它也是卷积神经网络CNN的主要构建块。在流形结构化点云上设计适当的卷积神经网络可以继承和授权CNN的最新进展,以分析和处理点云数据。然而,主要挑战之一是定义一种通过点云扫描滤波器的正确方法,作为平面卷积的自然概括,并同时反映点云的几何。在本文中,我们考虑通过在点云上调整并行传输来推广卷积。灵感来自基于三角形表面的方法Stefan C. Schonsheck,Bin Dong和Rongjie Lai, |
| Closed-Loop Adaptation for Weakly-Supervised Semantic Segmentation Authors Zhengqiang Zhang, Shujian Yu, Shi Yin, Qinmu Peng, Xinge You 弱监督语义分割的目的是在弱监督下为每个像素分配语义类别,例如图像级标签。大多数现有的弱监督语义分割方法不使用来自分段输出的任何反馈,并且可以被视为开环系统。由于静态种子和敏感的结构信息,它们容易累积错误。在本文中,我们通过引入两个反馈链,为现有的弱监督语义分割方法提出了一种通用的自适应机制,从而构成了一个闭环系统。具体地,第一链通过合并交叉图像结构信息迭代地产生动态种子,而第二链通过定制的随机游走过程进一步扩展种子区域以协调以超像素为特征的内部图像结构信息。 PASCAL VOC 2012的实验表明,我们的网络优于最先进的方法,显着减少了计算和内存负担。 |
| Volumetric Capture of Humans with a Single RGBD Camera via Semi-Parametric Learning Authors Rohit Pandey, Anastasia Tkach, Shuoran Yang, Pavel Pidlypenskyi, Jonathan Taylor, Ricardo Martin Brualla, Andrea Tagliasacchi, George Papandreou, Philip Davidson, Cem Keskin, Shahram Izadi, Sean Fanello 体积4D性能捕获是AR VR内容生成的基础。虽然之前在4D性能捕获方面的工作在工作室设置中已经取得了令人瞩目的成果,但这种技术仍然远远不能被典型的消费者所接受,而这些消费者最多可能拥有一个RGBD传感器。因此,在这项工作中,我们提出了一种使用单个RGBD相机合成自由视点渲染的方法。关键的见解是利用先前看到的给定用户的校准图像来推断应该从传感器中可用的数据在新颖视点中呈现的内容。鉴于来自多个视点的这些过去观察以及来自固定视图的当前RGBD图像,我们提出了一种端到端框架,其融合这两个数据源以生成表演者的新颖渲染。我们证明该方法可以产生高保真度的图像,并处理主体姿势和相机视点的极端变化。我们还表明该系统概括为在训练数据中未见的表演者。我们进行了详尽的实验,证明了所提出的半参数模型的有效性,即与其他现有技术的机器学习解决方案相比,神经网络可用的校准图像。此外,我们将该方法与采用多视图捕获的更传统管道进行比较。我们表明,我们的框架能够获得令人信服的结果,其基础设施远远少于以前的要求。 |
| Memory Integrity of CNNs for Cross-Dataset Facial Expression Recognition Authors Dylan C. Tannugi, Alceu S. Britto Jr., Alessandro L. Koerich 面部表情识别是人工智能领域的主要问题。解决这个问题的最好方法之一是使用卷积神经网络CNN。然而,需要大量数据来正确训练这些网络,但是大多数可用于面部表情识别的数据集相对较小。避免数据缺乏的常用方法是使用在不同域的大数据集上训练的CNN,并将这些网络的层微调到目标域。然而,微调过程不能保持存储器的完整性,因为CNN倾向于忘记他们学到的模式。在本文中,我们评估了微调CNN的不同策略,目的是在交叉数据集场景中评估此类策略的内存完整性。在源数据集上预训练的CNN被用作基线,并且已经评估了四种适应策略,微调其完全连接的层,微调其最后的卷积层,并且其完全连接的层在目标数据集上重新训练CNN以及源的融合。和目标数据集并重新训练CNN。四个数据集的实验结果表明,源数据集和目标数据集的融合提供了准确性和内存完整性之间的最佳折衷。 |
| Probabilistic Category-Level Pose Estimation via Segmentation and Predicted-Shape Priors Authors Benjamin Burchfiel, George Konidaris 我们引入了一种用于类别级别姿态估计的新方法,其通过将来自生成对象模型的3D形状估计与分割信息进行整合来产生预测姿势的分布。给定对象的输入深度图像,我们的可变时间方法使用混合密度网络架构来产生3DOF上的多模态分布,然后将该分布与在观察到的输入和预测对象姿势之间鼓励轮廓一致的先验概率组合。我们的方法在类别级3DOF姿态估计中明显优于当前的技术水平,其输出点估计并且没有明确地结合在Pix3D和ShapeNet数据集上测量的形状和分割信息。 |
| Information-Theoretic Registration with Explicit Reorientation of Diffusion-Weighted Images Authors Henrik Gr nholt Jensen, Fran ois Lauze, Sune Darkner 我们提出了一种信息理论方法来注册DWI,并在方向尺度上进行显式优化,另外关注归一化互信息作为DWI的鲁棒信息理论相似性度量。该框架是基于LOR DWI密度的分层尺度空间模型的扩展,其在整合,空间,方向和强度尺度上变化和优化。我们将模型扩展到非刚性变形,并表明该公式通过方向信息提供内在正则化。我们的实验表明,所提出的模型能够正确地改变ODF,并且能够处理DWI配准中的经典复杂挑战,例如光纤交叉的配准以及接吻,扇形和交错光纤。我们的结果清楚地说明了一种新的有希望的正则化效应,它来自基于非线性方向的成本函数。我们说明了不同图像尺度的属性,并表明,与标准的基于标量的配准相比,在我们的模型中包含方向信息使得模型更好地检索变形。 |
| Video-to-Video Translation for Visual Speech Synthesis Authors Michail C. Doukas, Viktoriia Sharmanska, Stefanos Zafeiriou 尽管在图像到图像翻译方面取得了显着的成功,以庆祝生成对抗性网络GAN的进步,但是对于视频域翻译已知非常有限的尝试。我们研究视觉语音生成环境中视频到视频翻译的任务,其目标是将任何口语单词的输入视频转换为不同单词的输出视频。这是一个多域翻译,每个单词构成一个说出这个词的视频域。对于该设置,将现有技术图像的适应性对图像翻译模型StarGAN的适应性缩小,词汇量大。相反,我们建议使用单词的字符编码,并设计一个基于小说的GANs架构,用于视频到视频翻译,称为Visual Speech GAN ViSpGAN。我们是第一个用500字词汇表演视频到视频翻译的人。 |
| Blocksworld Revisited: Learning and Reasoning to Generate Event-Sequences from Image Pairs Authors Tejas Gokhale, Shailaja Sampat, Zhiyuan Fang, Yezhou Yang, Chitta Baral 识别场景中的变化或变换以及推断其原因和影响的能力的过程是智能的关键方面。在这项工作中,我们超越了计算感知的最新进展,并引入了更具挑战性的任务,基于图像的事件排序IES。在IES中,任务是预测将对象从输入源图像中的配置重新排列到目标图像中的对象所需的一系列动作。 IES还要求系统具有归纳的普遍性。在认知发展的证据的推动下,我们编制了第一个IES数据集,Blocksworld图像推理数据集BIRD,其中包含不同配置的木块图像,以及将一种配置重新排列到另一种配置的移动顺序。我们首先探索现有深度学习架构的使用,并展示这些端到端方法在推断时间事件序列时的表现,并在归纳推广中失败。然后,我们提出了模块化的两步法Visual Perception,然后是事件序列,并通过结合学习和推理来证明改进的性能。最后,通过展示我们对自然图像的方法的扩展,我们寻求为未来的现实场景事件排序研究铺平道路。 |
| Image Alignment in Unseen Domains via Domain Deep Generalization Authors Thanh Dat Truong, Khoa Luu, Chi Nhanh Duong, Ngan Le, Minh Triet Tran 跨域的图像对齐最近已成为研究界的现实和热门话题之一。在该问题中,基于深度学习的图像对准方法通常在可用的大规模数据库上训练。在测试步骤期间,该训练模型被部署在在不同摄像机条件和模态下收集的看不见的图像上。交付的深层网络模型无法在这些场景中进行更新,调整或微调。因此,最近的深度学习技术,例如,域适配,功能转移和微调,无法部署。本文提出了一种新的基于深度学习的方法来解决不可见的模式问题。然后将所提出的网络应用于图像对准作为说明。所提出的方法被设计为端到端深度卷积神经网络,以优化深度模型以改善性能。当模型在MNIST上训练时,所提出的网络已经在数字识别中进行了评估,然后在看不见的域MNIST M上进行了测试。最后,在对RGB图像进行训练和在深度和X射线图像上进行测试时,所提出的方法在图像对准问题中进行了基准测试。 |
| Leveraging Medical Visual Question Answering with Supporting Facts Authors Tomasz Kornuta, Deepta Rajan, Chaitanya Shivade, Alexis Asseman, Ahmet S. Ozcan 在本工作说明文件中,我们描述了IBM Research AI Almaden团队参与ImageCLEF 2019 VQA Med竞赛。挑战包括基于放射学图像的四个问题回答任务。成像方式,器官和疾病类型的多样性加上小的不平衡训练集使这成为一个非常复杂的问题。为克服这些困难,我们实施了一种模块化流水线架构,该架构利用了传输学习和多任务学习我们的研究结果促成了一种名为Supporting Facts Network SFN的新模型的开发。 SFN背后的主要思想是交叉利用来自上游任务的信息,以提高下游较难的信息的准确性。该方法显着改善了F 1评分中验证集18点改善所达到的分数。最后,我们提交了四场比赛,排名第七。 |
| Texture CNN for Histopathological Image Classification Authors Jonathan de Matos, Alceu de S. Britto Jr., Luiz E. S. de Oliveira, Alessandro L. Koerich 活组织检查是乳腺癌诊断的金标准。通过使用计算机辅助诊断CAD系统可以改善该任务,减少诊断时间并减少内部和内部观察者的可变性。计算的进步使这种类型的系统更接近现实。然而,来自活组织检查的组织病理学图像HI的数据集非常小并且是不平衡的,这使得难以使用诸如深度学习的现代机器学习技术。在本文中,我们提出了一种基于纹理滤波器的紧凑架构,其具有比传统深度模型更少的参数,但能够以相对准确度捕获恶性和良性组织之间的差异。 BreakHis数据集的实验结果表明,所提出的纹理CNN在良性和恶性组织分类方面达到了近90%的准确度。 |
| Texture CNN for Thermoelectric Metal Pipe Image Classification Authors Daniel Vriesman, Alessandro Zimmer, Alceu S. Britto Jr., Alessandro L. Koerich 在本文中,基于深度神经网络的表示学习的概念被应用作为在腐蚀的热电金属管的自动视觉检查方法中使用手工特征的替代方案。纹理卷积神经网络TCNN基于局部相位量化LPQ和Haralick描述符HD替换手工特征,其优点在于学习适当的纹理表示和决策边界到单个优化过程中。实验结果表明,在识别热电管壁内表面不同腐蚀程度的任务中,可以达到99.20的精度,同时使用紧凑的网络,与手工制作相比,调整参数需要更少的工作量。因为TCNN架构在层数和连接数方面是紧凑的。观察到的结果开辟了在实时应用中使用深度神经网络的可能性,例如热电金属管的自动检测。 |
| Learning Navigation Subroutines by Watching Videos Authors Ashish Kumar, Saurabh Gupta, Jitendra Malik 层次结构是提高强化学习中的样本效率和经典计划中的计算效率的有效方法。然而,在经典规划中通过手工设计获取层次结构是次优的,而在强化学习中通过端到端奖励基础培训获取层次结构是不稳定的并且仍然过于昂贵。在本文中,我们通过使用被动的第一人称观察数据,寻求获得这种分层抽象或视觉运动子程序的替代范例。我们使用针对少量交互数据训练的逆模型来伪造被动第一人称视频与代理行为的标签。通过学习潜在意图调节策略从这些伪标记视频获取视觉马达子例程,该策略预测来自相应图像观察的推断伪动作。我们在导航环境中展示了我们提出的方法,并表明我们可以成功地从被动的第一人称视频中学习一致且多样的视觉运动子程序。我们通过使用它们作为探索来证明我们获得的视觉运动子程序的效用,并且作为用于达到点目标和语义目标的分级RL框架中的子策略。我们还通过在真实的机器人平台上部署它们来展示我们的子程序在现实世界中的行为。包含视频,代码和数据的项目网站 |
| Segmentation of blood vessels in retinal fundus images Authors Michiel Straat, Jorrit Oosterhof 近年来,已经针对视网膜眼底图像中的血管提出了几种自动分割方法,范围从使用便宜且快速的可训练滤波器到复杂的神经网络甚至深度学习。基于滤波的分割方法的一个示例是B COSFIRE。在该方法中,使用示例原型模式训练图像滤波器,通过在具有大强度变化的中心周围的圆上找到高斯响应差中的点,滤波器变为选择性。在本文中,我们讨论并评估了这些血管分割方法中的几种。我们仔细研究了B COSFIRE并通过实验研究了B COSFIRE对最近发布的IOSTAR数据集的性能,并研究了参数值如何影响性能。在实验中,我们设法达到0.9419的分割准确度。基于我们的研究结果,我们讨论何时使用B COSFIRE是首选方法,在哪种情况下使用更加计算复杂的分割方法可能是有益的。我们还将简要讨论血管分割以外的区域,这些方法可用于分割细长结构,例如卫星图像中的河流或叶子的神经。 |
| Application of Different Simulated Spectral Data and Machine Learning to Estimate the Chlorophyll $a$ Concentration of Several Inland Waters Authors Philipp M. Maier, Sina Keller 水质对人类和环境都非常重要,必须不断进行监测。它可通过诸如叶绿素a浓度的代理来确定,其可通过遥感技术监测。本研究的重点是利用有监督的机器学习模型估算叶绿素a浓度时,六个模拟卫星数据集的空间和光谱分辨率之间的权衡。卫星任务频谱模拟的初始数据集包含光谱仪数据和测量的13种不同内陆水域的叶绿素a浓度。关注回归性能,似乎机器学习模型与模拟的Sentinel数据和模拟的高光谱数据一样实现了几乎一样好的结果。关于适用性,Sentinel 2任务是小型内陆水域的最佳选择,因为它具有高空间和时间分辨率以及合适的光谱分辨率。 |
| Stabilizing GANs with Octave Convolutions Authors Ricard Durall, Franz Josef Pfreundt, Janis Keuper 在这份初步报告中,我们提出了一种简单但非常有效的技术来稳定基于CNN的GAN的训练。最近公布的使用卷积频率分解的方法的动机,例如Octave Convolutions,我们提出了一种新的卷积方案来稳定训练并降低模式崩溃的可能性。我们的方法的基本思想是将卷积滤波器分成加性高频和低频部分,同时在训练期间将重量更新从低变为高。直观地,该方法迫使GAN在下降到精细高频细节之前学习低频粗略图像结构。我们的方法与现有的稳定方法是正交的和互补的,可以简单地插入任何基于CNN的GAN架构。关于CelebA数据集的首次实验表明了该方法的有效性。 |
| Are Disentangled Representations Helpful for Abstract Visual Reasoning? Authors Sjoerd van Steenkiste, Francesco Locatello, J rgen Schmidhuber, Olivier Bachem 解开的表示独立地编码关于数据变化的显着因素的信息。尽管人们常常认为这种表征形式在学习解决许多现实世界的上游任务时很有用,但很少有经验证据支持这种说法。在本文中,我们进行了一项大规模的研究,调查解开的表征是否更适合抽象推理任务。使用类似于Raven s Progressive Matrices的两个新任务,我们评估了360度无监督解开模型所学习的表示的有用性。基于这些表示,我们训练3600个抽象推理模型并观察解开的表示实际上确实导致更好的上游性能。特别是,它们似乎可以使用更少的样本实现更快的学习。 |
| Food for thought: Ethical considerations of user trust in computer vision Authors Kaylen J. Pfisterer, Jennifer Boger, Alexander Wong 在计算机视觉研究中,特别是在开发工具的新应用时,应考虑并支持用户对底层技术的信任感的伦理影响。在这里,我们描述了在长期护理部门中纳入这些考虑因素以跟踪居民食物和液体摄入量的一个例子。我们重点介绍了我们最近进行的一项用户研究,旨在开发Goldilocks质量水平原型,旨在支持信任提示,其中对我们的水平原型的感知信任度高于现有系统。我们讨论了用户参与的重要性和需求,这是正在进行的计算机视觉驱动技术开发的一部分,并描述了与开发决策制定工具相关的几个与信任相关的重要因素。 |
| Learning the Non-linearity in Convolutional Neural Networks Authors Gavneet Singh Chadha, Andreas Schwung 我们建议在卷积神经网络的特征生成过程中引入非线性运算。这种非线性可以以各种方式实现。首先,我们讨论在数据增强过程中非线性的使用,以增加神经网络识别能力的鲁棒性。为此,我们通过将特定数值范围内的指数应用于输入空间的各个数据点来随机干扰输入数据集。其次,我们提出了非线性卷积神经网络,其中我们将指数运算应用于感受野的每个元素。为此,我们定义了与标准核权重矩阵相同维度的附加权重矩阵。然后,该矩阵的权重构成了感受野的相应分量的指数。在基本设置中,我们通过定义合适的参数来保持训练期间的权重参数。或者,我们使用合适的参数化使指数权重参数端到端可训练。网络架构应用于时间序列分析数据集,与基线网络相比,分类性能显着提高。 |
| Complex-valued neural networks for machine learning on non-stationary physical data Authors Jesper S ren Dramsch, Mikael L thje, Anders Nymark Christensen 深度学习已成为大多数科学领域的一个重要领域,包括物理科学。现代网络对数据应用实值转换。特别是,卷积神经网络中的卷积完全丢弃相位信息。许多确定性信号,例如地震数据或电信号,在信号的相位中包含重要信息。我们探索复杂的深度卷积网络,以利用非线性特征映射。地震数据通常应用低切滤波器,以衰减来自海浪的噪声和类似的长波长贡献。丢弃相位信息导致低频混叠,类似于高频的奈奎斯特香农定理。在非平稳数据中,相位内容可以稳定训练并提高神经网络的普遍性。虽然已经证明可以在深度神经网络中恢复相位内容,但我们展示了如何在特征图中包括相位信息来改进来自确定性物理数据的训练和推断。此外,我们表明,与具有相同性能的实值网络相比,复杂网络中参数的减少导致对较小数据集的训练而不过度拟合。 |
| Image Denoising with Graph-Convolutional Neural Networks Authors Diego Valsesia, Giulia Fracastoro, Enrico Magli 从嘈杂的观察中恢复图像是信号处理中的关键问题。最近,已经表明采用卷积神经网络的数据驱动方法可以胜过基于经典模型的技术,因为它们可以捕获更强大和有辨别力的特征。然而,由于这些方法基于卷积运算,因此它们仅能够利用局部相似性而不考虑非局部自相似性。在本文中,我们提出了一种卷积神经网络,它采用图卷积层,以利用局部和非局部相似性。图形卷积层动态地构造特征空间中的邻域,以检测由隐藏层产生的特征图中的潜在相关性。实验结果表明,所提出的架构优于经典卷积神经网络的去噪任务。 |
| Learning Multilingual Word Embeddings Using Image-Text Data Authors Karan Singhal, Karthik Raman, Balder ten Cate 最近学习多语言词嵌入已经引起了很大的兴趣,其中跨语言的语义上相似的词具有类似的嵌入。现有技术的方法依赖于昂贵的标记数据,其对于低资源语言是不可用的,或者涉及单语嵌入的事后统一。在本文中,我们研究了从弱监督图像文本数据中学习的多语言嵌入的功效。特别地,我们提出了使用图像文本数据来学习多语言嵌入的方法,通过强制图像的表示与文本的表示之间的相似性。我们的实验表明,即使不使用任何昂贵的标记数据,在图像文本数据上训练的一袋基于单词的嵌入模型也实现了与跨语言相似性任务的现有技术相当的性能。 |
| Towards Real Scene Super-Resolution with Raw Images Authors Xiangyu Xu, Yongrui Ma, Wenxiu Sun 由于缺乏真实的训练数据和模型输入的信息丢失,大多数现有的超分辨率方法在实际场景中表现不佳。为了解决第一个问题,我们提出了一种新的管道,通过模拟数码相机的成像过程来生成逼真的训练数据。为了弥补输入的信息损失,我们开发了一种双卷积神经网络,以利用原始图像中最初捕获的辐射信息。此外,我们建议学习空间变异的颜色变换,这有助于更有效的颜色校正。大量实验表明,原始数据的超分辨率有助于恢复精细细节和清晰结构,更重要的是,所提出的网络和数据生成流程在实际场景中实现了单图像超分辨率的卓越结果。 |
| Deep Dilated Convolutional Nets for the Automatic Segmentation of Retinal Vessels Authors Ali Hatamizadeh, Hamid Hosseini, Zhengyuan Liu, Steven D.Schwartz, Demetri Terzopoulos 视网膜脉管系统的可靠分割可以提供诊断和监测影响血管网络的各种疾病(包括糖尿病和高血压)的进展的手段。我们利用卷积神经网络的强大功能,设计出可靠,全自动的方法,可以准确地检测,分割和分析视网膜血管。特别地,我们提出了一种新颖的完全卷积深度神经网络,其具有编码器解码器架构,其采用具有多个扩张率的扩张空间金字塔池以恢复编码器中的丢失内容并将多尺度上下文信息添加到解码器。我们还提出了一种通过直接使用分割预测来量化和跟踪视网膜血管宽度的简单而有效的方法。与先前基于深度学习的视网膜血管分割方法(主要依赖于补丁分析)不同,我们提出的方法在训练和推理期间利用整个图像方法,通过访问图像中的全局内容导致更有效的训练和更快的推断。我们已经在三个公开可用的数据集上测试了我们的方法,我们对DRIVE和CHASE DB1数据集的最新结果证明了我们的方法的有效性。 |
| SpArSe: Sparse Architecture Search for CNNs on Resource-Constrained Microcontrollers Authors Igor Fedorov, Ryan P. Adams, Matthew Mattina, Paul N. Whatmough 世界上绝大多数处理器实际上是微控制器单元MCU,其广泛应用于从汽车到医疗设备和办公设备等应用中执行简单的控制任务。物联网IoT承诺通过微小,廉价的MCU将机器学习注入到每天的许多物体中。但是,这些资源贫乏的硬件平台严重限制了可以部署的机器学习模型的复杂性。例如,尽管卷积神经网络CNN在许多视觉识别任务上实现了最先进的结果,但由于严重的有限存储器限制,对CN的CNN推断具有挑战性。为了规避与CNN相关联的存储器挑战,已经提出了各种替代方案,其确实适合MCU的存储器预算,尽管以预测准确性为代价。本文质疑CNN不适合在MCU上部署的想法。我们证明可以自动设计CNN,这些CNN可以很好地推广,同时也足够小以适应内存受限的MCU。我们的稀疏架构搜索方法将神经架构搜索与修剪结合在一个统一的方法中,该方法可以在四个流行的物联网数据集上学习优秀的模型。我们发现的CNN更精确,比以前的方法小4.35倍,同时满足严格的MCU工作记忆约束。 |
| Fault Sneaking Attack: a Stealthy Framework for Misleading Deep Neural Networks Authors Pu Zhao, Siyue Wang, Cheng Gongye, Yanzhi Wang, Yunsi Fei, Xue Lin 尽管深度神经网络DNN取得了巨大成就,但最先进的DNN的脆弱性引发了DNN在许多需要高可靠性的应用领域中的安全性问题。我们提出了对DNN的故障潜行攻击,其中对手的目的是将某些输入图像错误分类为通过修改DNN参数来修改任何目标标签。我们应用ADMM交替方向乘法器来解决故障潜行攻击的优化问题,具有两个约束条件1其他图像的分类应该不变,2参数修改应该最小化。具体而言,第一个约束要求我们不仅要注入指定的错误错误分类,还要通过保持模型准确性来隐藏故障以进行隐身或偷偷摸摸的考虑。第二个约束要求我们使用L0范数来最小化参数修改以测量修改的数量,并使用L2范数来测量修改的大小。综合实验评估表明,所提出的框架可以在不损失整体测试精度性能的情况下注入多个潜行故障。 |
| Unified Probabilistic Deep Continual Learning through Generative Replay and Open Set Recognition Authors Martin Mundt, Sagnik Majumder, Iuliia Pliushch, Visvanathan Ramesh 我们引入了基于变分贝叶斯推理和开集识别的深度连续学习的统一概率方法。我们的模型将概率编码器与生成模型和生成线性分类器相结合,可以跨任务共享。在正确分类的数据点的基础上,开放集识别通过拟合高密度区域来约束后验,并平衡具有识别误差的开放空间风险。通过生成重放显着减轻了两种生成模型的灾难性推断,其中开放集识别用于从类特定后验的高密度区域进行采样并拒绝统计异常值。我们的方法自然允许前向和后向传输,同时保持过去的知识,而无需存储旧数据,正则化或推断任务标签。我们在针对类增量视觉和音频分类任务逐步扩展单头分类器以及跨模态的数据集增量学习的挑战性场景中展示了令人信服的结果。 |
| Effect of context in swipe gesture-based continuous authentication on smartphones Authors Pekka Siirtola, Jukka Komulainen, Vili Kellokumpu 这项工作研究了在根据从滑动手势中提取的触摸屏和加速度计读数执行智能手机用户的连续身份验证时应如何考虑上下文。该研究是在公开的HMOG数据集上进行的,该数据集由100名研究对象组成,这些研究对象在坐着和走路时执行预定义的阅读和导航任务结果表明,不同的智能手机使用和人类活动场景需要特定于上下文的模型,以最大限度地减少认证错此外,实验结果表明,仅当用户移动时,利用电话移动才能改善基于滑动手势的验证性能。 |
| Scene Induced Multi-Modal Trajectory Forecasting via Planning Authors Nachiket Deo, Mohan M. Trivedi 我们通过将其作为规划问题来解决未知场景中的代理人的多模态轨迹预测。我们提出了一种方法,包括三个模型,目标预测模型,以确定代理的潜在目标,反向强化学习模型,以规划每个目标的最佳路径,以及轨迹生成器,以获得沿计划路径的未来轨迹。对斯坦福无人机数据集的预测分析,显示了我们对新场景的方法的普遍性。 |
| Chinese Abs From Machine Translation |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号